Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).
введение
Для модели с большим языком эффект плохой из-за проблемы,Раньше люди в основном занимались переобучением, тонкой настройкой и быстрым улучшением.,Но это не лучше для проприетарных, быстрых обновленийизданные Решение,Для этого появляется генерация расширения поиска (RAG).,Преодоление разрыва между здравым смыслом LLM и собственными знаниями.
В этой статье, которой я поделюсь с вами сегодня, я познакомлю вас с концепцией и теорией RAG и покажу, как использовать LangChain для оркестровки, языковую модель OpenAI и Weaviate. 矢量база данных(Вы также можете создать свою собственную Milvusвекторную база данных) для достижения простотыиз RAG трубопровод.
Как получить эту статью Исходный код,отвечать:исходный код РАГ
Что такое РАГ?
Полное название RAG — Retrival-Augmented Generation, а китайский перевод — Retrival Enhanced Generation. Это концепция предоставления внешних источников знаний для больших моделей, которая позволяет им генерировать точные и контекстуальные ответы, одновременно уменьшая иллюзию модели.
Проблема с обновлением знаний
Современные LLM принимают большие объемы обучающих данных и хранят обширные знания здравого смысла в весах нейронной сети. Однако когда мы заставляем большую модель генерировать знания, выходящие за рамки обучающих данных, например новейшие знания, знания по конкретной предметной области и т. д., выходные данные LLM могут привести к неточным фактам. Это то, что мы часто называем модельной иллюзией. Как показано ниже:

Поэтому важно преодолеть разрыв между здравым смыслом больших моделей и другими базовыми знаниями, чтобы помочь LLM генерировать более точные и контекстуальные результаты, одновременно уменьшая галлюцинации.
Решение
Традиционно нейронные сети настраиваются так, чтобы адаптироваться к конкретной информации, относящейся к конкретной предметной области. Хотя этот метод эффективен,Но это требует больших вычислительных ресурсов,и требует технических знаний,Мешает гибко адаптироваться к меняющейся информации.
В 2020 году Льюис и др. предложили более гибкую технологию под названием «генерация с расширенным поиском» (RAG) для наукоемких задач НЛП [Справочный документ: https://arxiv.org/abs/2005.11401]. В этой статье исследователи объединяют генеративную модель с модулем извлечения, чтобы предоставить дополнительную информацию из внешних источников знаний, и эту информацию можно легко обновлять и поддерживать.
Проще говоря, RAG — это экзамен с открытой книгой для студентов LLM. На экзаменах с открытой книгой учащиеся могут принести справочные материалы, например учебники или конспекты, которые они смогут использовать для поиска необходимой информации для ответов на вопросы. Идея экзаменов с открытой книгой заключается в том, что тест фокусируется на способности учащегося рассуждать, а не на его способности запоминать конкретную информацию.
Аналогичным образом, фактические знания отделены от возможностей рассуждения LLM и хранятся во внешних источниках знаний, к которым можно легко получить доступ и обновить:
- «Знание параметров»:узнал во время обученияиз Знание,Неявное хранилище в нейронной сети из весов.
- «Непараметрические знания»:хранилище在外部Знание源中,Напримервекторная база данных。
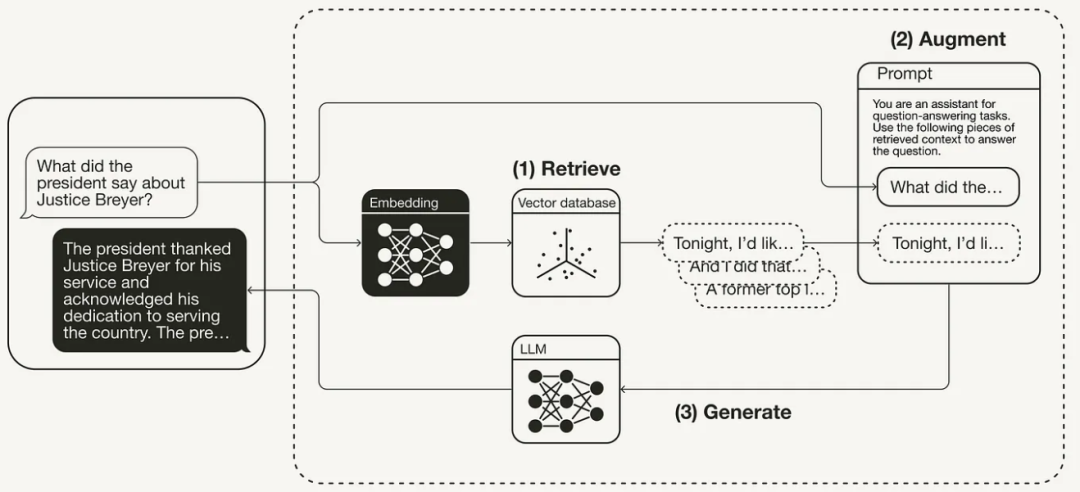
Общий рабочий процесс RAG показан на рисунке ниже:
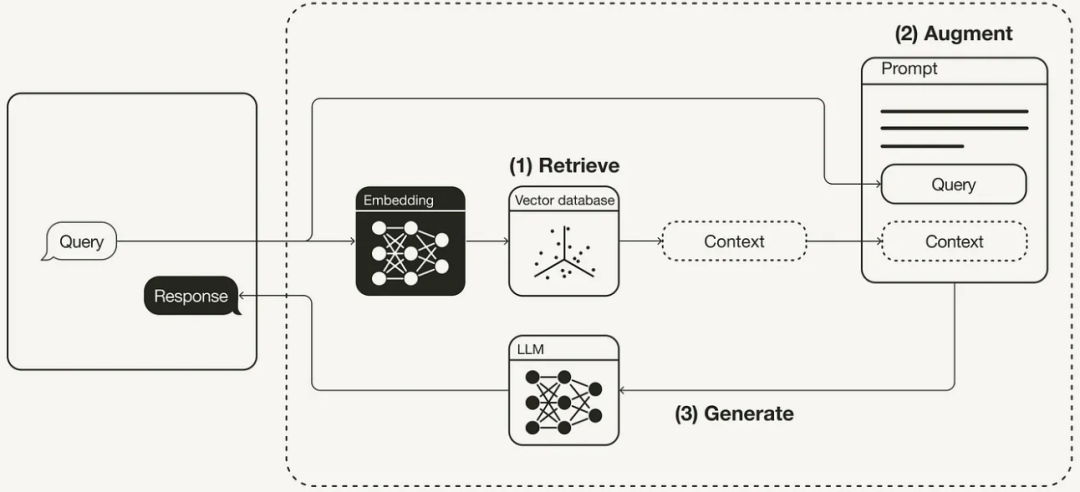
"Забрать" Извлекайте соответствующий контекст из внешних источников знаний на основе запросов пользователей. Для этого используйте встраивание Модели, чтобы встроить пользовательский запрос в тот же файл, что и Векторная. база данные из дополнительного контекста то же самое из векторного пространства. Это позволяет выполнить поиск по сходству и возвращает векторную базу. данные, наиболее близкие к изbefore k объект данных.
«Увеличение» Пользовательский запрос и полученный дополнительный контекст заполняются в шаблоне приглашения.
«Создать» Наконец, запрос на улучшение поиска передается LLM。
LangChain внедряет RAG
Вышеизложенное знакомит с генерацией и принципом работы RAG. Далее мы покажем, как использовать LangChain в сочетании с OpenAI LLM и векторной базой данных Weaviate для реализации RAG Pipeline на Python.
Базовая подготовка среды
1. Установите все соответствующие пакеты Python, на которые необходимо положиться, включая langchain для оркестрации, интерфейс большой модели openai и клиент векторной базы данных weaviate-client.
pip install langchain openai weaviate-client
2. Чтобы подать заявку на учетную запись OpenAI, вам необходимо получить ключ OpenAI API, как показано на рисунке ниже:
3. Создайте файл .env в корневом каталоге проекта для хранения соответствующих файлов конфигурации, как показано на рисунке ниже.
4. В основной каталог загрузите информацию о файле конфигурации. Здесь используется пакет python-dotenv.

векторная база данных
Далее необходимо подготовить векторную базу Данные служат хранилищем всей дополнительной информации из внешних источников знаний. Векторная база данныхзаполняется следующими шагамииз:1)нагрузкаданные;2)данные Разбивка на части;3)Блочное хранилище。
«Загрузить данные»:Здесь я выбрал статью под названием «Борьба за разрушение сферы».изроман,ввод как документ . Документ имеет текстовый формат txt. Чтобы загрузить текст, используйте здесь. LangChain из TextLoader。
from langchain.document_loaders import TextLoader
loader = TextLoader('./бой, разбивающий небо.txt')
documents = loader.load()
«Разбиение данных»:Поскольку документ слишком длинный в исходном состоянии(около5Ван Син),Невозможно поместиться в большое контекстное окно Модельиз.,Поэтому его необходимо разделить на более мелкие части. Лангчейн Существует множество встроенных разделителей текста. используется здесь chunk_size ок. 1024 и chunk_overlap до 128 из CharacterTextSplitter для сохранения непрерывности текста между блоками.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
chunks = text_splitter.split_documents(documents)
«Хранилище блоков данных»:Включение блоков перекрестного текстаиз Семантический поиск,Необходимо создать векторное встраивание для каждого блока.,Затем соедините их вместе с встраиваемым хранилищем. Для создания векторных вложений,Можно использовать OpenAI Вставьте модель и используйте Weaviate векторная база данные для выполнения хранилища. Позвонив .from_documents() векторная база данных автоматически заполнит блоки.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
реализация RAG
«Шаг первый: получение данных» Сохранение данных в векторную базу данныхназад,Вы можете определить его как компонент ретривера.,Этот компонент получает соответствующий контекст на основе семантического сходства между пользовательским запросом и внедренным блоком.
retriever = vectorstore.as_retriever()
«Шаг второй: оперативное улучшение» После завершения извлечения данных вы можете дополнить свои подсказки соответствующим контекстом. В ходе этого процесса необходимо подготовить шаблон приглашения. Подсказки можно легко настроить с помощью шаблонов подсказок, как показано ниже.
from langchain.prompts import ChatPromptTemplate
template = """Вы робот-помощник вопросов и ответов. Чтобы ответить на вопрос, используйте следующую информацию, полученную из контекста. Если вы не знаете ответа, просто скажите, что не знаете. Вопрос: {вопрос}, контекст: {контекст}, ответ:
"""
prompt = ChatPromptTemplate.from_template(template)
«Шаг третий: генерация ответов» использовать RAG Конвейер выстраивает цепочку между средством извлечения, шаблоном приглашения и LLM связаны вместе. определенный RAG цепь, вы можете назвать это.
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = «Кто двоюродный брат Сяо Яна?»
res=rag_chain.invoke(query)
print(f'Ответ: {res}')
Вкратце, процесс генерации RAG показан на рисунке ниже:
Подвести итог
В этой статье представлены RAG Концепция и некоторые теории, лежащие в ее основе, реализованы в этой статье с помощью Python и LangChain. Интерфейс OpenAIизChatGPT (можно собрать чатGLM3 самостоятельно), векторная база Weaviate данные(Мильвус можно построить самостоятельно )、OpenAI Встроенная модель реализована RAG трубопровод.

Быстро изучите в одной статье — концепцию и технологию реализации NL2SQL для передачи данных с нулевыми затратами.
Как использовать SpringBoot для интеграции EasyExcel 3.x для реализации элегантных функций импорта и экспорта Excel?

Почему транзакция не вступает в силу, когда @Transactional добавляется в частный метод?

Знание создания образов Docker: подробное объяснение команды Dockerfile.
Псевдостатическая конфигурация ThinkPHP
Код изображения для загрузки апплета WeChat: последний доступный (код серверной части + код внешнего интерфейса)

Используйте растровое изображение Redis для реализации эффективной функции статистики регистрации пользователей.

[Nginx29] Обучение Nginx: буфер прокси-модуля (3) и обработка файлов cookie
[Весна] SpringBoot интегрирует ShardingSphere и реализует многопоточную вставку 10 000 фрагментов данных в пакетном режиме (выполнение операций с базой данных и таблицами).
SpringBoot обрабатывает форму данных формы для получения массива объектов
Nginx от новичка до новичка 01 - Установка Nginx через установку исходного кода

Проект flask развертывается на облачном сервере и получает доступ к серверной службе через доменное имя.

Порт запуска проекта Spring Boot часто занят, полное решение

Java вызывает стороннюю платформу для отправки мобильных текстовых сообщений

Практическое руководство по серверной части: как использовать Node.js для разработки интерфейса RESTful API (Node.js + Express + Sequelize + MySQL)
Введение в параметры конфигурации большого экрана мониторинга Grafana (2)
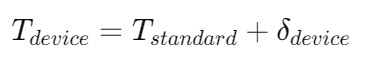
В статье «Научно-популярная статья» подробно объясняется протокол NTP: анализ точной синхронизации времени.

Пример разработки: серверная часть Java и интерфейсная часть vue реализуют функции комментариев и ответов.

Nodejs реализует сжатие и распаковку файлов/каталогов.
SpringBootИнтегрироватьEasyExcelСложно реализоватьExcelлистимпортировать&Функция экспорта

Настройка среды под Mac (используйте Brew для установки go и protoc)
Навыки разрешения конфликтов в Git
Распределенная система журналов: развертывание Plumelog и доступ к системе

Артефакт, который делает код элегантным и лаконичным: программирование на Java8 Stream
Spring Boot(06): Spring Boot в сочетании с MySQL создает минималистскую и эффективную систему управления данными.

Как использовать ArrayPool

Интегрируйте iText в Spring Boot для реализации замены контента на основе шаблонов PDF.

Redis реализует очередь задержки на основе zset

Получить текущий пакет jar. path_java получает файл jar.