Одна статья: Как построить и оптимизировать центр облачных вычислений на графических процессорах?
В настоящее время наиболее распространенные размеры кластеров графических процессоров, развернутых в вычислительных центрах искусственного интеллекта, составляют 2048, 1024, 512 и 256, а стоимость развертывания увеличивается линейно с количеством графических процессоров. В этой статье в качестве примера для анализа будет взят относительно скомпрометированный масштаб карты 1024 GPU (H100).
01 Выбор вычислительных узлов
Вычислительные узлы — самая дорогая часть предложения на строительство вычислительного центра искусственного интеллекта. В спецификации по умолчанию (BoM) HGX H100, полученной вначале, часто используется верхняя конфигурация. В отличие от DGX, который является системным брендом NVIDIA, HGX, как авторизованная платформа NVIDIA, позволяет партнерам создавать индивидуальные системы графических процессоров. Затем, исходя из реальных потребностей бизнеса, мы можем попытаться оптимизировать затраты по следующим аспектам.
Спецификация по спецификации корпуса HGX H100 по умолчанию | |
|---|---|
компоненты и услуги | количество |
Процессоры Intel Emerald Rapids с почти максимальной производительностью | 2 |
8 H100 +4 NVSwitch HGX Baseboard + 8 SXM5 Heatsinks | 1 |
CPU RAM (per Gbyte) | 2048 |
Storage (per TByte) | 30 |
Внутренняя сетевая карта ConnectX-7 | 80 |
Bluefield-3 DPU | 2 |
материнская плата | 1 |
Шасси (корпус, кабели и т. д.) | 1 |
Охлаждение (радиатор процессора + вентилятор) | 1 |
источник питания | 8 |
Собрать&тест | 1 |
OEM-добавленная стоимость/доплата | 1 |
Итого ($): 270000+ | |
Источник: Полу Анализ
1. Выберите процессор среднего класса.
LLM обучение представляет собой GPU Очень интенсивные нагрузки, да. CPU Низкие требования к нагрузке. Процессор Пробежки — это простые задачи, такие как PyTorch ,контроль GPU другие процессы, инициализация вызовов сети и хранилища, запуск гипервизоров и т. д. Интел CPU Относительно проще правильно реализовать NCCL производительность и виртуализация, а также меньше ошибок в целом. Если используется AMD CPU , затем используйте NCCL_IB_PCI_RELAXED_ORDERING и попробуй разные NUMA NPS настройки для настройки.
2. Уменьшите объем оперативной памяти до 1 ТБ.
ОЗУ также является относительно дорогой частью вычислительного узла. Многие стандартные продукты имеют 2 ТБ оперативной памяти ЦП DDR 5, но обычные рабочие нагрузки искусственного интеллекта вообще не ограничиваются оперативной памятью ЦП и могут рассматриваться варианты ее сокращения.
3. Удалить Bluefield-3 или выбрать замену
Bluefield-3 DPU изначально был разработан для традиционных облаков ЦП. Суть продажи заключается в том, чтобы разгрузить ЦП и позволить использовать ЦП для аренды в бизнесе вместо запуска виртуализации сети. На самом деле клиентам, которые обращаются за вычислительной мощностью графического процессора, в любом случае не потребуется слишком много вычислительной мощности процессора, и вполне допустимо использовать часть ядер процессора для виртуализации сети. Кроме того, Bluefield-3 DPU довольно дорог. Использование стандартного ConnectX в качестве внешнего интерфейса или использование альтернативной смарт-сетевой карты DPU может полностью удовлетворить потребности.
Принимая во внимание вышеупомянутую оптимизацию затрат, нам удалось снизить стоимость одного сервера примерно на 5%. В кластере 1024 H100 со 128 вычислительными узлами сумма, стоящая за этим соотношением, уже значительна.
4. Уменьшите количество одноузловых сетевых карт (выбирайте внимательно)
В стандартной спецификации каждый вычислительный сервер H100 поставляется с восемью сетевыми адаптерами 400G CX-7, что обеспечивает общую пропускную способность 3200 Гбит/с на сервер. Если используются только четыре сетевых карты, пропускная способность внутренней вычислительной сети снизится на 50%. Эта корректировка, очевидно, может сэкономить деньги, но она также окажет негативное влияние на производительность некоторых рабочих нагрузок ИИ.
02 Выбор кластерной сети
Кластерные сети — второй по величине источник затрат после вычислительных узлов. Кластер NVIDIA H100, используемый в этой статье, имеет три разные сети:
- серверная сеть(вычислительная сеть,InfiniBand или RoCEv2) привыкший GPU Связь между десятками стоек масштабируется до тысяч стоек. Сеть может сделать InfiniBand или Spectrum-X Ethernet, также можно использовать других провайдеров Ethernet.
- Фронтальная сеть(управление бизнесомисеть хранения данных) Для подключения к Интернету SLURM/Kubernetes исетьхранилище для загрузки обучающих данных и Checkpoint. Сеть обычно заканчивается с каждым GPU 25-50Gb/s Работая на высокой скорости, с полностью настроенными восемью картами, пропускная способность каждого сервера с графическим процессором достигнет уровня прибытия. 200-400Gb/s。
- Сеть внешнего управлениясеть Используется для перерисовки операционной системы, мониторинга состояния узлов (например, скорости вращения вентилятора, температуры, энергопотребления и т. д.). Сервер наBMC, источник шкафа питание, коммутаторы, устройства жидкостного охлаждения и т. д. часто подключаются к приезду в эту сеть для мониторинга и управления серверами и различными другими IT оборудование.
Спецификация сети кластера HGX H100 по умолчанию. | |
|---|---|
компоненты и услуги | количество |
Вычислительная сеть InfiniBand | |
Коммутатор Quantum-2 IB (MQM9700) | 48 |
Однопортовый трансивер Nvidia LinkX IB 400G SR4 (MMA4Z00-NS4400) | 1024 |
Двухпортовый трансивер Nvidia LinkX 800G SR8 (MMA4Z00-NS) | 1536 |
Многомодовое оптоволокно Nvidia LinkX 400G | 3072 |
Стоимость внешней оптоволоконной архитектуры | |
Spectrum Ethernet Switch (SN4600) | 6 |
Трансивер Nvidia LinkX 200G QSFP56 AOC | 384 |
Трансивер Nvidia LinkX 200G | 256 |
Многомодовое оптоволокно Nvidia LinkX 100G | 512 |
Сеть внешнего управления | |
1GbE Spectrum Ethernet Switch (SN2201) | 4 |
RJ45 Cables | 232 |
Итого ($): 490 000+ | |
Источник: Полу Анализ
1. Вычислительная сеть: RoCEv2 заменяет IB
По сравнению с решением Ethernet большой емкости, InfiniBand, предоставляемый NVIDIA, несомненно, дороже, но некоторые клиенты все еще твердо уверены, что производительность Ethernet намного ниже, главным образом потому, что Ethernet требует необходимой настройки сетевых параметров без потерь и только посредством целенаправленной настройки можно производительность библиотеки коллективного общения будет раскрыта.
Однако с точки зрения влияния на эффективность бизнеса,,в настоящий момент технологического фона с использованием IBilidaRoCEv2 для задней частьвычислительная сеть Не большая разница。в конце концов, RoCE на самом деле представляет собой просто зрелый транспортный уровень IB и RDMA, портированный для проживания, который также является зрелым из Ethernet и IPсети.,Мы проанализируем и объясним это в другой статье в будущем.
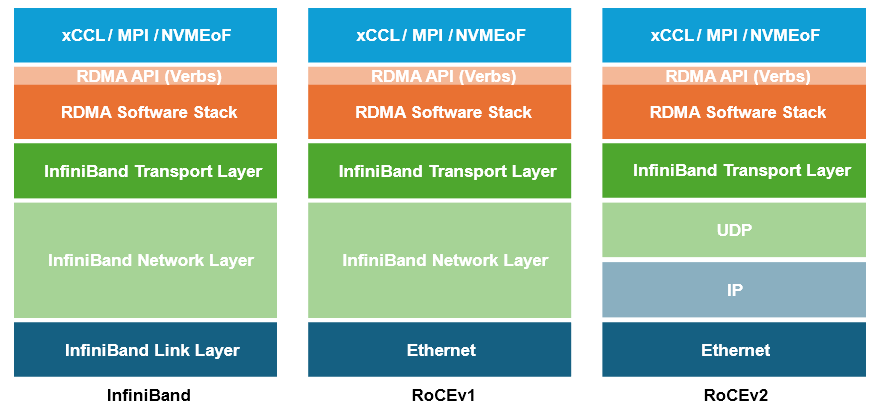
Использование Ethernet для замены IB для формирования высокопроизводительной сети без потерь в сценариях крупномасштабных вычислительных мощностей сформировало отраслевой консенсус. Горячая точка отрасли уже обратилась к тому, как лучше собирать «шерсть Ethernet»: например, начать. от стандарта Ethernet, запуск нового поколения сценариев искусственного интеллекта, новые протоколы, а также инновационные попытки некоторых производителей упростить конфигурацию сети RoCE и улучшить возможности визуализации на основе существующих стандартов протоколов.
Видеть: Easy RoCE: включите Ethernet без потерь на коммутаторах SONiC одним щелчком мыши
Будь то тестовые сценарии обучения и продвижения ИИ или существующие инженерные практики ведущих поставщиков облачных технологий, AI Ethernet имеет большое количество примеров для справки.
По статистике, в мире TOP500 значительная доля приходится на суперкомпьютеры, RoCEиIBиз. Рассчитанное на компьютере количество, ИБ Пропорция 47.8%, RoCE Пропорция 39%; Рассчитывается на основе общей пропускной способности порта, IBПропорция 39.2%,RoCE для 48,5%. Мы считаем, что по сравнению с IB Ethernet с открытой экосистемой ускорит его развитие.
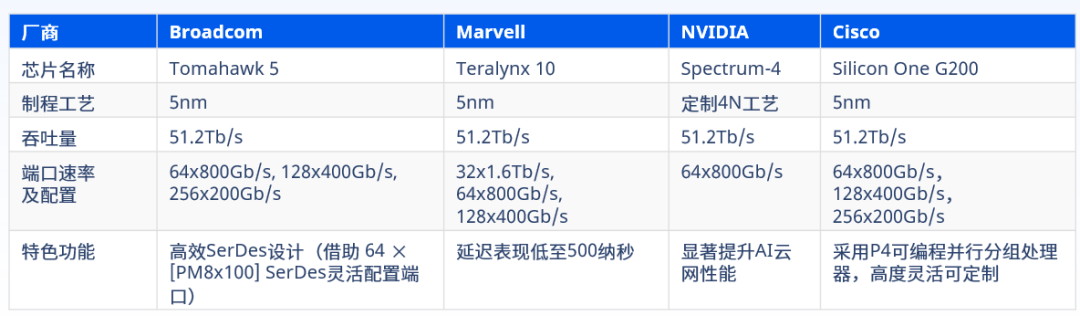
В настоящее время Broadcom в основном предлагает на рынке высокопроизводительные платформы коммутации Ethernet, подходящие для сценариев искусственного интеллекта. Tomahawk、Marvell Тералинкс и Циско Silicon One Подожди, NVIDIA Spectrum Чип используется только с платформой Spectrum-X и отдельно не продается. На всех вышеперечисленных платформах выпущены новейшие модели 51,2T и 800GbE/s. Взгляните на количество развертываний. Tomahawk Явно доминирующая производительность задержки пересылки Teralynx Даже лучше.
2. Фронтальная сеть: разумно снизить пропускную способность.
NVIDIA и некоторые OEM-производители/системные интеграторы обычно предоставляют интерфейсную сеть 2x200GbE на сервере и развертывают сеть с помощью коммутаторов Spectrum Ethernet SN4600.
Мы знаем, что эта сеть используется только для хранения и интернет-вызовов, а также для передачи внутриполосного трафика управления на основе платформ управления и планирования, таких как SLURM и Kubernetes. Она не будет использоваться для чувствительной к задержке и интенсивной пропускной способности градиентной синхронизации. 400G сетевых подключений на сервер при нормальных обстоятельствах будет намного больше, чем действительно необходимо, и есть некоторая возможность для сокращения затрат.
3. Сеть внешнего управления: используйте коммутатор Ethernet общего назначения.
NVIDIA Спецификация по умолчанию обычно включает Spectrum 1GbE Переключатели дорогие. Сеть внешнего Технология управления перемещением является относительно распространенной, и ее стоимость будет выше, если вы выберете ее на рынке. 1G Коммутатор Ethernet вполне подойдет.
03 Оптимизация архитектуры вычислительной сети
Вычислительная сеть кластера графического процессора будет обеспечивать различные коллективные коммуникации (все-сокращение, все-сбор и т. д.), генерируемые в ходе параллельных вычислений. Масштаб трафика и требования к производительности полностью отличаются от традиционных облачных сетей.
Видеть:Выявление сетевого трафика интеллектуального вычислительного центра AI - Обучение большой модели
Топология сети, рекомендованная NVIDIA, представляет собой двухуровневую сеть с «толстым деревом» с неблокируемыми соединениями, и теоретически любая пара узлов должна иметь возможность одновременно взаимодействовать на линейной скорости. Однако из-за перегрузки каналов, несовершенства адаптивной маршрутизации и задержек связи, вызванных дополнительными переходами, теоретическое оптимальное состояние не может быть достигнуто в реальных сценариях, и необходимо выполнить оптимизацию производительности.
Оптимизированная для железных дорог архитектура
В рамках архитектуры оптимизации орбиты 32 карты графических процессоров 4 серверов больше не подключены к переключателю TOR, но графические процессоры с тем же номером карты с 32 серверов подключены к соответствующим переключателям орбит, то есть все графические процессоры № 0. из 32 серверов подключены к конечному коммутатору №0, все графические процессоры №1 подключены к листовому коммутатору №1 и так далее.
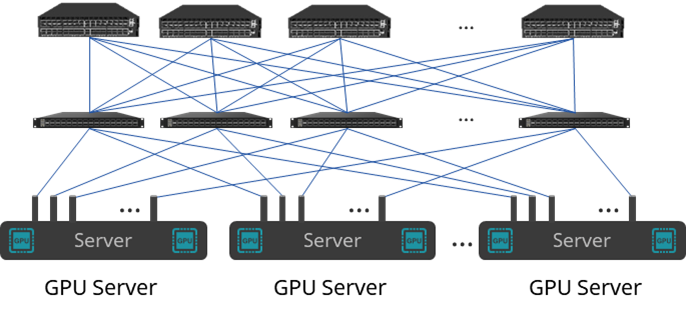
Оптимизация орбитысетьиз Основные преимуществадауменьшатьсетьскопление。потому чтодляиспользуется для AI обученный GPU Данные периодически передаются параллельно, используя коллективную связь для обмена градиентами и обновления параметров между различными графическими процессорами. Если все с одного сервера GPU оба подключены к одному и тому же ToR Коммутаторы, когда они отправляют в сеть параллельный трафик по одному и тому же каналу, вероятность возникновения перегрузки очень высока.
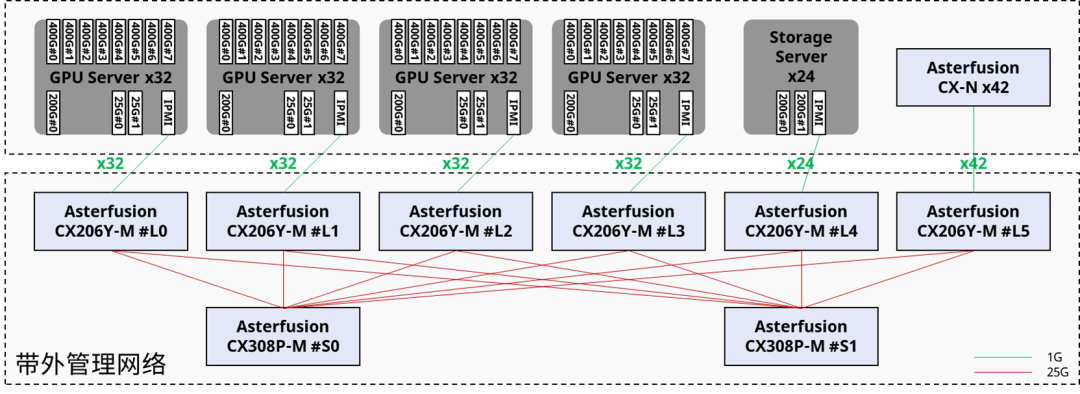
Синжунъюань(Asterfusion)данныйиз1024 карты, 128 вычислительных узлов Горизонтально масштабируемая сетьПлан правильныйдана основе Оптимизация орбитыназадиз Архитектура,Среди них 24башня CX864E-N (однокристальный коробчатый переключатель 51,2Тиз).,8башняделатьдляSpine,16башняделатьдляLeaf),Происходит межузловая связь: графические процессоры с одинаковым номером карты будут находиться на расстоянии всего одного прыжка друг от друга.
Источник: коммутатор Asterfusion CX864E-N.
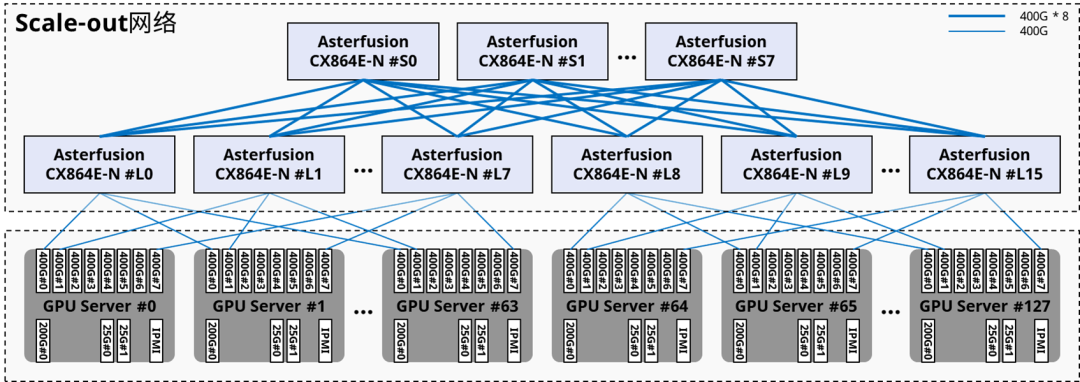
Если вы стремитесь к максимальной оптимизации затрат,для32приезжать128узлыиз Вычислительные кластеры могут быть спроектированы даже с одним слоем треков.выключательизRail-onlyсеть,Теоретически затраты на строительство сети можно сэкономить до75%。
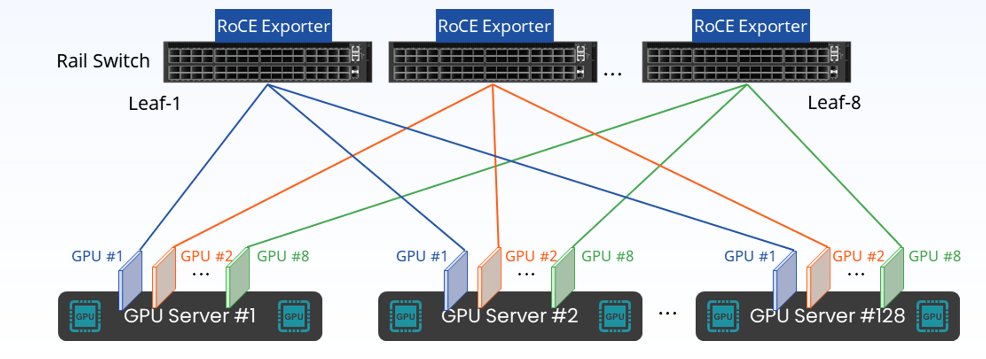
Источник: Сетевое решение Asterfusion Xingzhi AI.
Определите соответствующий уровень превышения подписки
Еще одним преимуществом орбитально-оптимизированной топологии является переподписка. В контексте проектирования сетевой архитектуры переподписка означает предоставление большей пропускной способности нисходящей линии связи. Скорость превышения подписки представляет собой соотношение емкости нисходящей линии связи (к серверам/хранилищу) и пропускной способности восходящей линии связи (к коммутаторам Spine верхнего уровня). кластер достиг даже преувеличенного соотношения 7:1.
Запланировано превышение подписки,Мы можем дополнительно оптимизировать затраты, преодолев ограничения неблокировки. Причина, по которой это возможно, заключается в том, что 8 Это происходит во внутреннем модуле, поперек трафика модуля и требования к пропускной способности относительно невелики. В сочетании с достаточно хорошими возможностями адаптивной маршрутизации и большим буферным пространством коммутатор,Мы можем спланировать подходящееиз Коэффициент переподписки составляетуменьшатьверхний слойSpineвыключательизколичество。
Однако стоит отметить, что, будь то IB или RoCEv2, в настоящее время не существует идеального решения, позволяющего избежать риска перегрузки. Оба варианта недостаточны при работе с крупномасштабным совокупным коммуникационным трафиком, поэтому переподписка не должна быть слишком агрессивной. (И лучше всего оставить достаточно портов для конечного коммутатора, чтобы можно было добавить коммутаторы позвоночника, когда в будущем трафик между модулями будет интенсивным)
Если на этом этапеда Выбирайте на базе EthernetизAIсеть Мы по-прежнему рекомендуем решение1:1из неблокирующей сетидизайн。
04 NVMe-хранилище
Количество физических серверов
Для достижения высокой доступности большинство поставщиков хранилищ рекомендуют развертывать как минимум 8 сервер хранения. 8 Каждый сервер хранения может предоставить 250GB/s приезжать 400GB/s пропускная способность хранилища, достаточная для удовлетворения 1024 башня H100 бежит дальше AI рабочая нагрузка. Мы можем начать с наименьшего доступного количества, но нам нужно обратить внимание на то, чтобы оставить достаточное количество портов NVMe в системе хранения. Драйв Бэй, источник места в стойке питания для последующего расширения по мере необходимости.
сеть хранения данных
Распространенным решением является создание выделенной сети Ethernet без потерь 200G для обеспечения производительности и физическое объединение сети в одну.

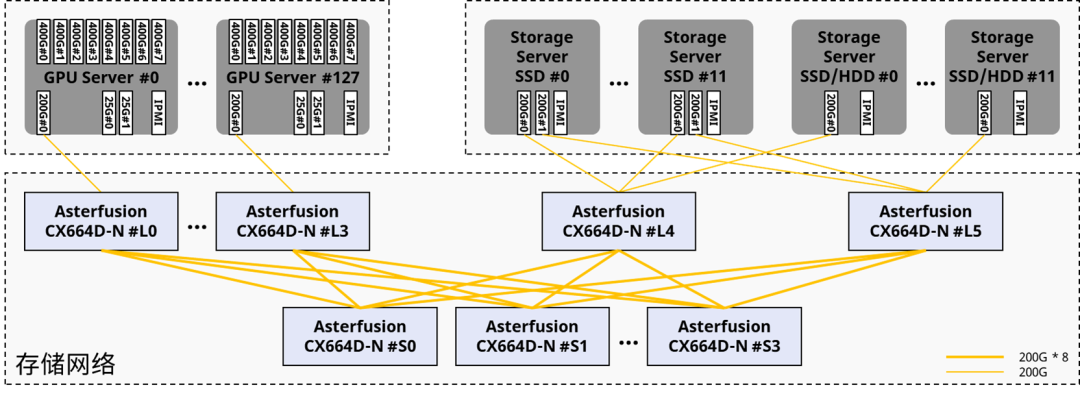
Источник: Астерфузия
сервер хранилища также доступен сзади частьвычислительная Работа по сети - обычно да привязывает сетевую карту IB. GPU 0, чтобы действовать как сетевая карта хранения. Хотя задержка и пропускная способность хорошо работают в тестах хранилища, в реальных рабочих нагрузках ИИ это влияет GPU 0 изPerformance (будут конфликты трафика, если сетевая карта IB одновременно используется в качестве сетевой карты хранилища). При возникновении сбоя диска в кластере хранилища будет запущена перестройка, которая будет происходить в вычислительном режиме. В сети возникает большой объем трафика, что приводит к более серьезным перегрузкам.
05 Внутриполосное управление
для Обеспечить высокую доступность из UFM и CPU Узлы управления, мы рекомендуем развернуть как минимум два общих x86 сервер,Используйте каналы Ethernet 25GE/10GE для подключения всех вычислительных узлов и узлов управления.,И доступ к внешней сети.

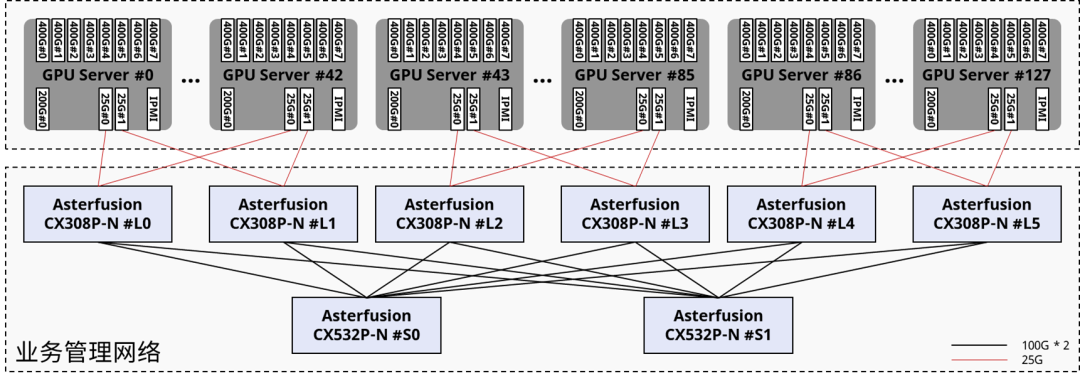
Источник: Астерфузия
По умолчаниюNVIDIA Superpod Архитектура включает в себя «NVIDIA AI Предприятие» или «База Command Manager (BCM)», рекомендованная розничная цена — 4500. Доллар США/ГПУ. БЦМ это предложение AI работаделатьпотоки Управление кластеромизпакет программного обеспечения,Эту часть стоимости программного обеспечения можно считать исключенной и выбрать другие варианты замены.,Или Пользователь может настроить.
также Внутриполосное система управления также предполагает прибытие других IT Такое оборудование, как межсетевые экраны, стойки, PDU. И т. д., эта цена не приведет к значительному увеличению затрат на строительство кластера.
06 Внеполосное управление
внеполосное Система управления в основном отслеживает, контролирует и автоматически сообщает о состоянии работы большого количества серверов через интеллектуальный интерфейс управления платформой (IPMI). IPMI может работать независимо от операционной системы и позволяет администраторам контролировать систему, когда система не включена, но подключена. питаниеиз ситуации для удаленного управления, но эта функциональность мониторинга в основном ориентирована на аппаратный уровень.
отличается от Внутриполосное управление,внеполосное Управление создало отдельный исток для передачи трафика управления физическими устройствами и не будет передавать бизнес-трафик. Обычно мы настраиваем 1 узел на каждый вычислительный узел графического процессора и хранилища. GE Соединение по ссылке IPMIизадняя часть Уровень управлениябашня。
07 Драйверы и бизнес-планировщики
драйвер графического процессора
необходимый GPU У водителя есть cuda-drivers-5xx и fabricmanager-5xx а также cuda-toolkit-12-x。
- Cuda-drivers-5xx для Ubuntu/Linux и драйвер пространства ядра, необходимый для взаимодействия с графическим процессором
- fabricmanager-5xx да отвечает за настройку узла NV структура ссылок
- Cuda-toolkit-12-x Содержит все инструменты пользовательского пространства. API
сетевой драйвер
MLNX_OFED
каждый GPU Необходимо установить на сервер Mellanox OpenFabrics Enterprise Distribution (MLNX_OFED) водитель. Этот пакет ConnectX-7 InfiniBand NIC драйвер для выполнения RDMA (Удаленный прямой доступ к памяти)и OS Обход ядра.
GPU Direct RDMA
Это включено в cuda-drivers-5xx Дополнительный драйвер ядра в , не включен по умолчанию. Без этого драйвера графический процессор нужно будет быть первым CPU RAM Приехать можно отправить только после буферизации сообщения. NIC。
давать возможность GPUDirect RDMA Команда sudo modprobe nvidia-peermem。
NVIDIA HPC-X
В основном используется для дальнейшей оптимизации связи между графическим процессором и сетевой картой.
Без вышеуказанных пакетов графический процессор может быть только 80Gbit/s из скорости отправки и получения трафика, предоставление После этих пакетов программного обеспечения скорость двухточечной отправки и получения должна быть на уровне приезжающих. Около 391 Гбит/с.
Планирование бизнеса и процедуры запуска
Большинствоиз Конечные пользователи захотят иметьГотов из коробкиизпланировщик,Может быть основан на SLURM 、K8s или других поставщиков программной платформы Tower. Вручную установите и отладьте вышеуказанную платформу с 0приезжать1, это займет минимум 1-2 дня у инженеров, не специализирующихся на этом, поэтому она простаивает из GPU Ресурсы — это реальные затраты для клиентов.
08 Многопользовательская изоляция
Ссылка на традиционный облачный опыт ЦП.,Если только заказчик не арендует весь GPU-кластер на длительный срок,В противном случае физический кластер может иметь несколько одновременных пользователей.,Таким образом, центр облачных вычислений графического процессора также должен изолировать внешний Ethernet и вычислительную сеть.,И изолируйте хранилище между клиентами.
Реализация на базе Ethernet из Мультитенантная изоляция Уже существует большое количество зрелых решений для автоматического развертывания с использованием платформ управления облаком. При использовании решения InfiniBand мультитенантная изоляция использует ключи разделов. (pKeys) Достигнуто: пропуск клиентов. pKeys чтобы получить отдельную сеть, то же самое pKeys узлы могут взаимодействовать друг с другом.
09 Виртуализация графического процессора
Традиционное облако ЦП отличается от других,Использование ИИ арендаторами облака GPU обычно арендуют каждый вычислительный узел GPU целиком.,Нет абсолютной необходимости углубляться в узлы и добиваться более мелкозернистой виртуализации. Но для дальнейшего улучшения использования ресурсов графического процессора.,Многие люди также выбирают виртуализацию графического процессора.,в настоящий момент,Технологию виртуализации графического процессора обычно разделяют на три типа: программное моделирование, Прямая монополия (п ГПУ)、Сквозное совместное использование (например, vGPU、MIG)。
Сценарий аренды вычислительных мощностей ИИ. Уровень виртуализации обычно соответствует уровню одной карты.,То есть эксклюзивный сквозной доступ (pGPU) — с использованием технологии сквозного прохода PCIe.,Непосредственно подключите всю графическую карту графического процессора физического хоста к виртуальной машине для использования.,Принцип аналогичен сквозному подключению сетевой карты.,Но этот метод требует, чтобы хост поддерживал IOMMU. (блок управления памятью,Он будет иметь возможность прямого хранилища и подключение шины ввода-вывода к основной памяти. Как традиционное из ММУ,IOMMU сопоставляет устройство, видимое с виртуального адреса, с физическим адресом прибытия)
Режим сквозной передачи pGPU эквивалентен исключительному использованию графического процессора виртуальной машиной.,Драйвер оборудования не требует изменения. Потому что для не имеет ограничений на то, что может поддерживаться изGPUколичеством.,И при этом он не кастрирует функциональность графического процессора.,В этом сквозном режиме большинство функций могут поддерживаться без изменений.
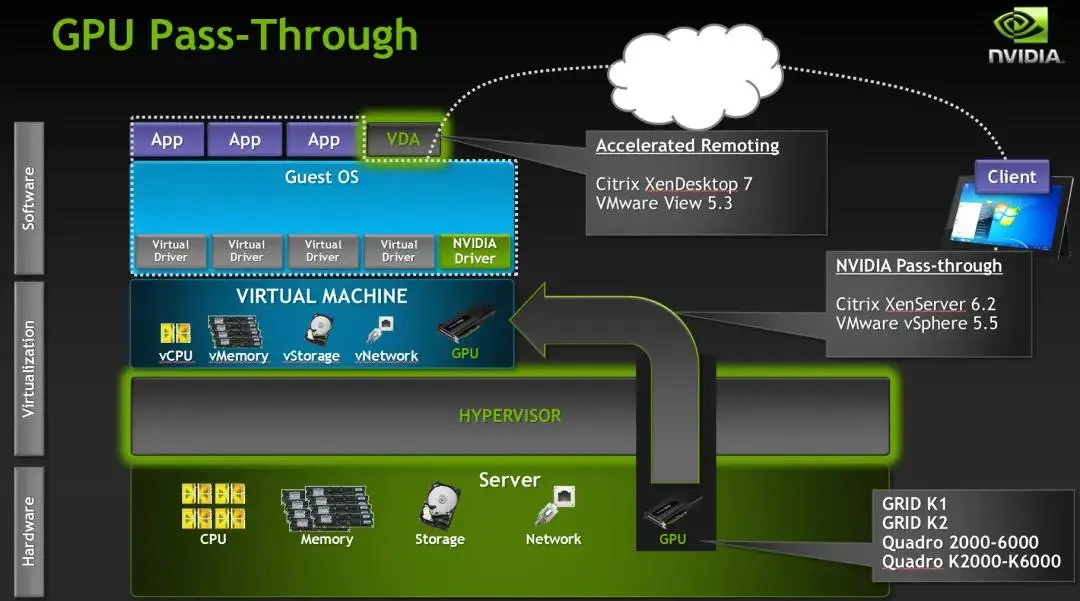
Стоит отметить, что NCCL и NVIDIA водитель в GPU Невозможно автоматически обнаружить при запуске на виртуальной машине NUMA Площадь и PCIe Топология, нужно пройти NCCL_TOPO_FILE Переменные передаются вручную /etc/nccl.confсерединаиз NUMA Площадь и PCIe файл топологии, иначе NCCL Производительность будет зависеть от пропускной способности. 50% бегать.
10 решений для мониторинга
Панель мониторинга
Что касается мониторинга, мы рекомендуем как минимум Prometheus + Grafana Создайте концентрацию из Панель Диптихи для отслеживания пользователей GPU температура、источник Индикаторы BMC, такие как использование питания,XID-ошибка,Даже бизнес исеть единый мониторинг.
Вычислительный узелиз Мониторинг включен вкаждый GPU Установите один на узел IPMI и DCGM Exporter, а затем разверните его на узле управления. Prometheus и GPU на Exporter передавать и хранить данные в базе данных. Графана соединятьприезжать Prometheus Визуализируйте собранные данные.
Мониторинг на стороне сети аналогичен. В этом сценарии преимущества использования коммутаторов SONiC очевидны. Поскольку сама программная среда представляет собой открытую контейнерную архитектуру, мы можем это сделать. docker форма запускается на переключателе exporter Чтобы получить необходимые данные о состоянии устройства, вы также можете использовать RESTful. APIвызовсеть能力集成进верхний слой Уровень управлениябашня。
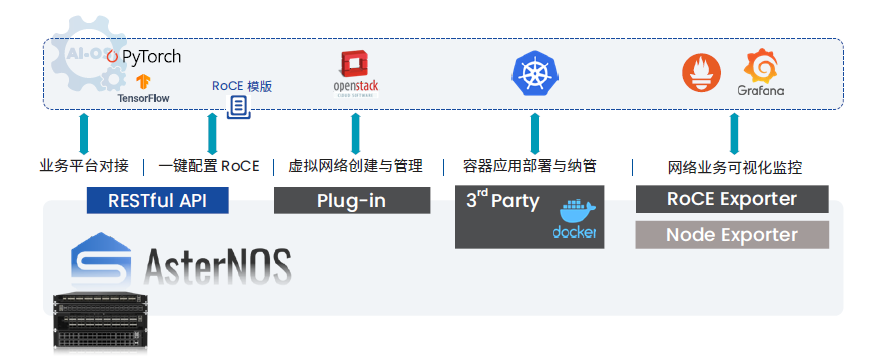
Кроме того, в сочетании с возможностью внутриполосной сетевой телеметрии (INT) можно обеспечить точный мониторинг сети RoCE за доли секунды, чтобы помочь контролировать перегрузку сети.
Источник: Prometheus + Grafana, решение RoCE для мониторинга миллисекундного уровня, предоставленное Xingrongyuan.
Распространенные ошибки
- Диагностические сообщения (dmesg)Два общих dmesg Сообщение да Кабель отключен также NIC или или легкий перегрев трансивера.
- Скрытое повреждение данных (SDC)Не собраноприезжать Диагностические сообщения и другие отчеты об ошибках,Но вывод — ошибка изрезультат умножения матрицы。Эти неправильные терминыдля Тихое повреждение данных (СДК). Конечно GPU У вас есть эта проблема? Самый простой способ - использовать? Nvidia DCGMI уровень диагностики 4 инструмент
sudo dcgmi diag -r 4。Долженинструментзахватит 95% самое обычное Тихое повреждение данныхвопрос。 - сбой NCCLобщийсбой NCCL включает в себя тупики и зависания, которые могут привести к приостановке учебных работ. 30-35 минута, затем PyTorch из NCCL watchdog Вся учебная работа будет прекращена. В связи с этим вы можете рассмотреть возможность добавления мониторинга энергопотребления, чтобы проверить, нормально ли работает AI. Дополнительные сведения об устранении неполадок NCCL см. по адресу: https://docs.nvidia.com/deeplearning/nccl/user-guide/docs. /troubleshooting.html
- Infiniband UFM из Код ошибки Обычное как 110 (ошибка символа), 112 (ссылка не работает), 329 (ссылка не работает), 702 (порт считается неработоспособным) и 918 (предупреждение об ошибке знакового бита). Если вы столкнулись с любым из приведенных выше кодов ошибок, вам следует немедленно связаться с техническими инженерами сети для дальнейшего расследования.
11 Принятие развертывания и ежедневное обслуживание
Приемочное тестирование в масштабе кластера должно длиться не менее 3-4 Еженедельно старайтесь устранять сбои компонентов узла, возникающие в период раннего отказа. Обучение искусственному интеллекту во многом зависит от сетей и HBM. и BF16/FP16/FP8 Тензорное ядро и широко используемые в настоящее время инструменты тестирования высокопроизводительных вычислений, такие как LINPACK (наиболее широко используемый эталонный тест для тестирования производительности с плавающей запятой во всем мире), не будут использовать большой объем сети и не будут занимать слишком много места. GPU из HBM память, а да только использует и тестирует GPU из FP64 основной. На всякий случай мы рекомендуем проводить приемочное тестирование таким образом, чтобы максимально имитировать реальный бизнес.
NCCL-TEST
nccl-test инструмент NVIDIA Открытый исходный код из одного для тестирования NCCL Коллективное общение изинструмент,Мы рекомендуем использовать nccl-тест, чтобы проверить, нормально ли коллективное общение, и провести стресс-тестирование скорости коллективного общения перед официальным запуском бизнеса.,Посмотрите, есть ли какие-либо недостатки или падения производительности. Подробнее об анализе логов nccl-test мы остановимся в следующей теме.
Текущее техническое обслуживание
Наиболее распространенные проблемы в кластерах включают в себя перегрузку、Графический процессор в автономном режиме、GPU HBM Ошибка и СДК и т. д. большую часть времени,Эти проблемы требуют простой аппаратной перезагрузки физического сервера.,Или это можно решить, выключив и перезапустив компьютер. Переподключение трансиверили и очистка оптоволоконного кабеля от пыли также могут решить некоторые неожиданные неисправности. В более сложных ситуациях оставьте их на усмотрение службы технической поддержки производителя.
Справочная документация:
https://www.semianalysis.com/p/ai-neocloud-playbook-and-anatomy
https://docs.nvidia.com/deeplearning/nccl/user-guide/index.html
https://ethernettechnologyconsortium.org
https://github.com/yunzhongOvO/Linpack-HPL
https://www.sohu.com/a/777143962_711053
https://asterfusion.com/alab-for-netdevops/



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
