Очистка эликсиров в 5–7 раз быстрее с использованием чипа Mac M1 для ускорения работы Pytorch. Полное руководство.
В мае 2022 года PyTorch официально объявил, что официально поддерживает ускорение моделей в версии Mac с чипом M1. Официальные данные сравнения показывают, что по сравнению с ЦП скорость алхимии на М1 можно ускорить в среднем в 7 раз.
Ух ты, можно так сильно ускориться без отдельного графического процессора. Мне не терпелось приобрести MacBook с чипом M1 и протестировать воду, а также собрать нужную и важную информацию, которую я задумал, в эту статью.
Ключевое слово ответа на серверную часть общедоступной учетной записи: M1. Вы можете получить исходный код блокнота Jupyter из этой статьи.
1. Принцип ускорения
- Вопрос 1: почему чип Mac M1 можно использовать для ускорения Pytorch?
Потому что чип Mac M1 — это не простой чип ЦП, а интегрированный чип, который включает в себя множество компонентов, таких как ЦП (центральный процессор), графический процессор (графический процессор), NPU (движок нейронной сети) и унифицированный блок памяти. Поскольку чип Mac M1 объединяет компоненты графического процессора, его можно использовать для ускорения Pytorch.
- Вопрос2, сколько видеопамяти имеет графический процессор на чипе Mac M1?
Чип Mac M1 использует единый блок памяти для центрального и графического процессоров. Таким образом, объем памяти, который может использовать чип Mac M1, равен объему памяти компьютера Mac.
- Вопрос 3, использование Mac Ускорение чипа M1 pytorch Требуется установка куда бэкэнд?
Нет, CUDA адаптирована к графическому процессору Nvidia. Серверная часть ускорения, адаптированная к графическому процессору в чипе Mac M1, — это mps, который уже доступен в соответствующей операционной системе Mac и не требует установки отдельно. Просто установите соответствующий Pytorch.
- Вопрос 4. Почему некоторое программное обеспечение, которое можно установить на компьютеры Mac с чипом Intel, нельзя установить на компьютеры Mac с чипом M1?
Чтобы обеспечить высокую производительность и энергосбережение, чип Mac M1 в своей базовой конструкции использует упрощенный набор команд, называемый архитектурой Arm, который отличается от полного набора команд архитектуры x86, используемого широко используемыми процессорными чипами, такими как Intel. Поэтому некоторое программное обеспечение, разработанное на основе набора инструкций x86, нельзя использовать непосредственно на компьютере с чипом Mac M1.

2. Конфигурация среды
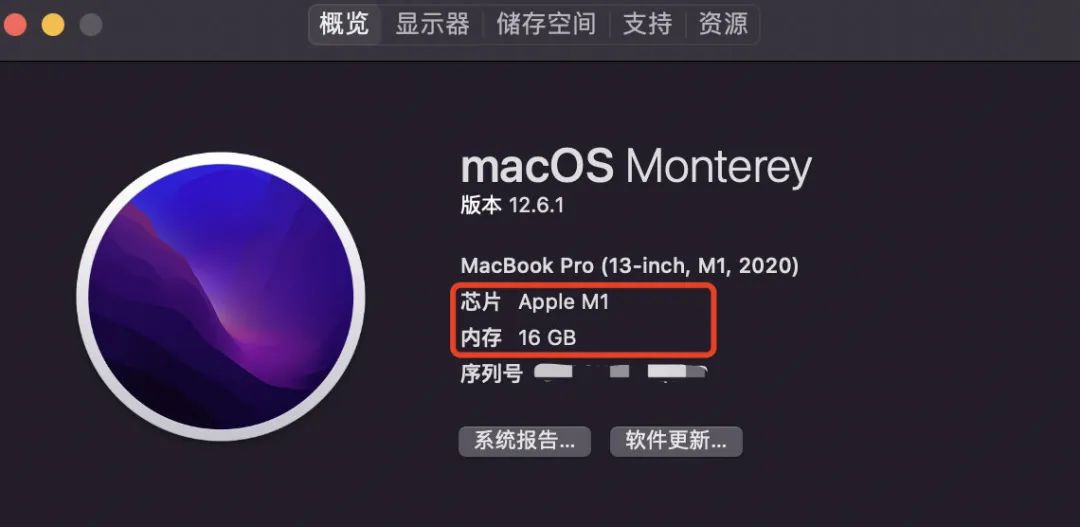
0, проверьте модель Mac
Нажмите в левом верхнем углу рабочего столаmacикона——>Об этой машине——>Обзор,Убедитесь, что это чип m1,Разберитесь с объемом памяти (желательно более 16 ГБ).,8G может быть недостаточно).
1. Загрузите miniforge3 (под miniforge3 можно понимать общественную версию miniconda/annonconda, обеспечивающую более стабильную поддержку чипа M1)
https://github.com/conda-forge/miniforge/#download
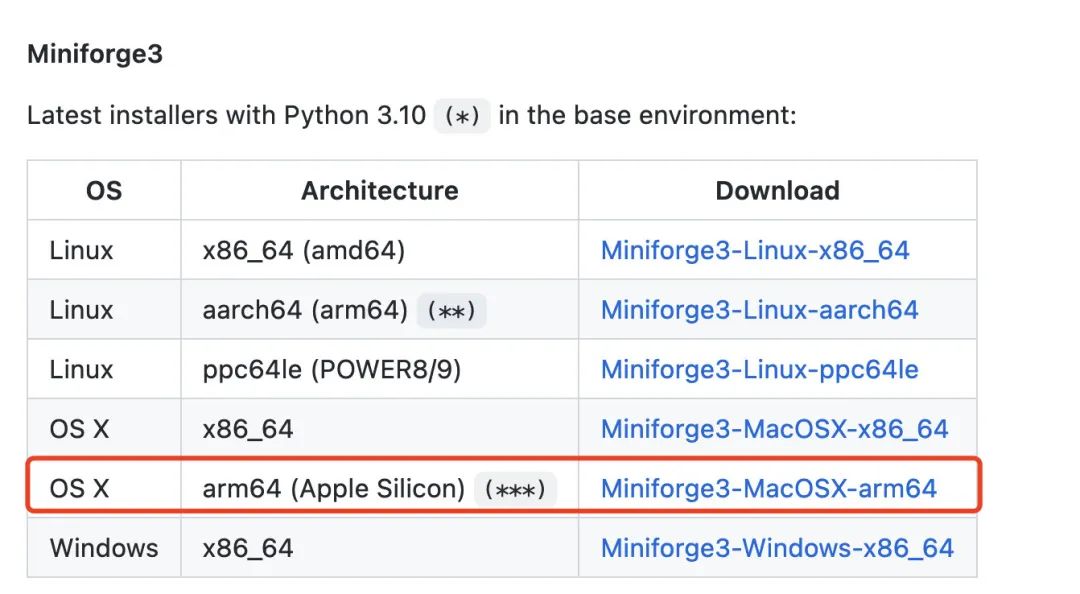
Примечание. Annoconda также выпустила официальную поддержку чипа Mac m1, начиная с мая 2022 года, но по-прежнему рекомендуется использовать выпущенный сообществом miniforge3, который имеет открытый исходный код и более стабилен.
2. Установите минифорж3
chmod +x ~/Downloads/Miniforge3-MacOSX-arm64.sh
sh ~/Downloads/Miniforge3-MacOSX-arm64.sh
source ~/miniforge3/bin/activate
3. Установите pytorch (версия v1.12 официально поддерживает серверную часть mps для ускорения графического процессора чипа Mac m1).
pip install torch>=1.12 -i https://pypi.tuna.tsinghua.edu.cn/simple
4. Тестовая среда
import torch
print(torch.backends.mps.is_available())
print(torch.backends.mps.is_built())
Если результат верен, поздравляем с успешной настройкой.
3. Пример кода
Ниже приведен пример распознавания рукописных цифр, демонстрирующий полный процесс использования серверной части MPS графического процессора Mac M1 для ускорения Pytorch.
Основная операция очень проста, аналогична использованию CUDA. Перед тренировкой просто переместите модель и данные в torch.device("mps").
import torch
from torch import nn
import torchvision
from torchvision import transforms
import torch.nn.functional as F
import os,sys,time
import numpy as np
import pandas as pd
import datetime
from tqdm import tqdm
from copy import deepcopy
from torchmetrics import Accuracy
def printlog(info):
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print(str(info)+"\n")
#================================================================================
# 1. Подготовьте данные
#================================================================================
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="mnist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=128, shuffle=False, num_workers=2)
#================================================================================
# 2. Определите модель
#================================================================================
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=64,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=64,out_channels=512,kernel_size = 3))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(512,1024))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(1024,10))
return net
net = create_net()
print(net)
# Показатели оценки
class Accuracy(nn.Module):
def __init__(self):
super().__init__()
self.correct = nn.Parameter(torch.tensor(0.0),requires_grad=False)
self.total = nn.Parameter(torch.tensor(0.0),requires_grad=False)
def forward(self, preds: torch.Tensor, targets: torch.Tensor):
preds = preds.argmax(dim=-1)
m = (preds == targets).sum()
n = targets.shape[0]
self.correct += m
self.total += n
return m/n
def compute(self):
return self.correct.float() / self.total
def reset(self):
self.correct -= self.correct
self.total -= self.total
#================================================================================
# 3. Модель обучения
#================================================================================
loss_fn = nn.CrossEntropyLoss()
optimizer= torch.optim.Adam(net.parameters(),lr = 0.01)
metrics_dict = nn.ModuleDict({"acc":Accuracy()})
# ======================== Переместите модель в mps================== = ==========
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
net.to(device)
loss_fn.to(device)
metrics_dict.to(device)
# ====================================================================
epochs = 20
ckpt_path='checkpoint.pt'
Связанные настройки #early_stopping
monitor="val_acc"
patience=5
mode="max"
history = {}
for epoch in range(1, epochs+1):
printlog("Epoch {0} / {1}".format(epoch, epochs))
# 1,train -------------------------------------------------
net.train()
total_loss,step = 0,0
loop = tqdm(enumerate(dl_train), total =len(dl_train),ncols=100)
train_metrics_dict = deepcopy(metrics_dict)
for i, batch in loop:
features,labels = batch
# ======================== Переместить данные в mps=================== = =========
features = features.to(device)
labels = labels.to(device)
# ====================================================================
#forward
preds = net(features)
loss = loss_fn(preds,labels)
#backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
#metrics
step_metrics = {"train_"+name:metric_fn(preds, labels).item()
for name,metric_fn in train_metrics_dict.items()}
step_log = dict({"train_loss":loss.item()},**step_metrics)
total_loss += loss.item()
step+=1
if i!=len(dl_train)-1:
loop.set_postfix(**step_log)
else:
epoch_loss = total_loss/step
epoch_metrics = {"train_"+name:metric_fn.compute().item()
for name,metric_fn in train_metrics_dict.items()}
epoch_log = dict({"train_loss":epoch_loss},**epoch_metrics)
loop.set_postfix(**epoch_log)
for name,metric_fn in train_metrics_dict.items():
metric_fn.reset()
for name, metric in epoch_log.items():
history[name] = history.get(name, []) + [metric]
# 2,validate -------------------------------------------------
net.eval()
total_loss,step = 0,0
loop = tqdm(enumerate(dl_val), total =len(dl_val),ncols=100)
val_metrics_dict = deepcopy(metrics_dict)
with torch.no_grad():
for i, batch in loop:
features,labels = batch
# ======================== Переместить данные в mps=================== = =========
features = features.to(device)
labels = labels.to(device)
# ====================================================================
#forward
preds = net(features)
loss = loss_fn(preds,labels)
#metrics
step_metrics = {"val_"+name:metric_fn(preds, labels).item()
for name,metric_fn in val_metrics_dict.items()}
step_log = dict({"val_loss":loss.item()},**step_metrics)
total_loss += loss.item()
step+=1
if i!=len(dl_val)-1:
loop.set_postfix(**step_log)
else:
epoch_loss = (total_loss/step)
epoch_metrics = {"val_"+name:metric_fn.compute().item()
for name,metric_fn in val_metrics_dict.items()}
epoch_log = dict({"val_loss":epoch_loss},**epoch_metrics)
loop.set_postfix(**epoch_log)
for name,metric_fn in val_metrics_dict.items():
metric_fn.reset()
epoch_log["epoch"] = epoch
for name, metric in epoch_log.items():
history[name] = history.get(name, []) + [metric]
# 3,early-stopping -------------------------------------------------
arr_scores = history[monitor]
best_score_idx = np.argmax(arr_scores) if mode=="max" else np.argmin(arr_scores)
if best_score_idx==len(arr_scores)-1:
torch.save(net.state_dict(),ckpt_path)
print("<<<<<< reach best {0} : {1} >>>>>>".format(monitor,
arr_scores[best_score_idx]),file=sys.stderr)
if len(arr_scores)-best_score_idx>patience:
print("<<<<<< {} without improvement in {} epoch, early stopping >>>>>>".format(
monitor,patience),file=sys.stderr)
break
net.load_state_dict(torch.load(ckpt_path))
dfhistory = pd.DataFrame(history)
В-четвертых, используйте торчкерас для поддержки Mac. Ускорение чипа M1
Я представил поддержку чипов Mac m1 в последней версии torchkeras 3.3.0. Когда появятся доступные чипы/графические процессоры Mac m1, они будут использоваться для ускорения по умолчанию без какой-либо настройки.
Примеры использования следующие. 😋😋😋
!pip install torchkeras>=3.3.0
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader
import torchkeras #Attention this line
#================================================================================
# 1. Подготовьте данные
#================================================================================
import torchvision
from torchvision import transforms
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="mnist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=128, shuffle=False, num_workers=2)
for features,labels in dl_train:
break
#================================================================================
# 2. Определите модель
#================================================================================
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=64,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=64,out_channels=512,kernel_size = 3))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(512,1024))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(1024,10))
return net
net = create_net()
print(net)
# Показатели оценки
class Accuracy(nn.Module):
def __init__(self):
super().__init__()
self.correct = nn.Parameter(torch.tensor(0.0),requires_grad=False)
self.total = nn.Parameter(torch.tensor(0.0),requires_grad=False)
def forward(self, preds: torch.Tensor, targets: torch.Tensor):
preds = preds.argmax(dim=-1)
m = (preds == targets).sum()
n = targets.shape[0]
self.correct += m
self.total += n
return m/n
def compute(self):
return self.correct.float() / self.total
def reset(self):
self.correct -= self.correct
self.total -= self.total
#================================================================================
# 3. Модель обучения
#================================================================================
model = torchkeras.KerasModel(net,
loss_fn = nn.CrossEntropyLoss(),
optimizer= torch.optim.Adam(net.parameters(),lr=0.001),
metrics_dict = {"acc":Accuracy()}
)
from torchkeras import summary
summary(model,input_data=features);
# if gpu/mps is available, will auto use it, otherwise cpu will be used.
dfhistory=model.fit(train_data=dl_train,
val_data=dl_val,
epochs=15,
patience=5,
monitor="val_acc",mode="max",
ckpt_path='checkpoint.pt')
#================================================================================
# 4. Модель оценки
#================================================================================
model.evaluate(dl_val)
#================================================================================
# 5. Используйте модель
#================================================================================
model.predict(dl_val)[0:10]
#================================================================================
# 6. Сохраните модель
#================================================================================
# The best net parameters has been saved at ckpt_path='checkpoint.pt' during training.
net_clone = create_net()
net_clone.load_state_dict(torch.load("checkpoint.pt"))
Пять, чип M1 с процессором и Nvidia Сравнение скорости графического процессора
Используйте приведенный выше код в качестве примера для запуска на процессоре, чипе Mac m1 и графическом процессоре Nvidia.
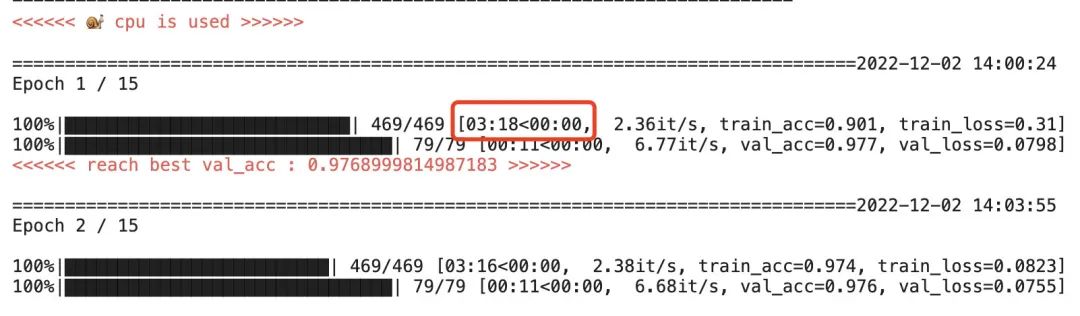
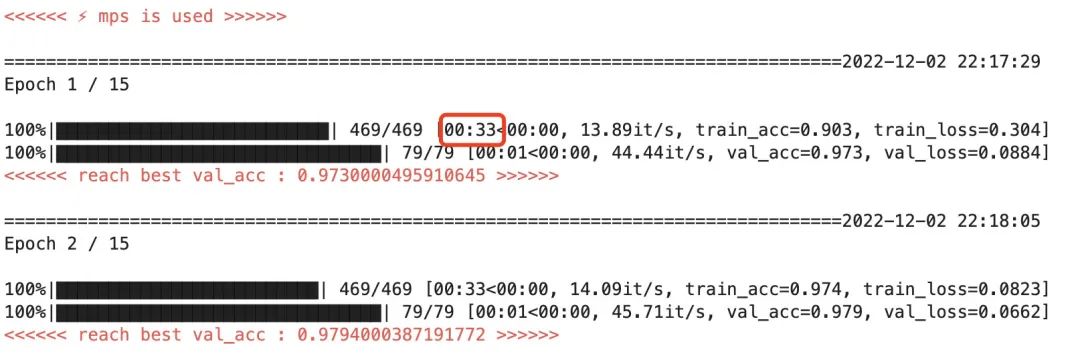
Скриншот полученной скорости бега выглядит следующим образом:
Чистый эффект работы процессора
Эффект ускорения чипа Mac M1
Эффект ускорения графического процессора Tesla P100
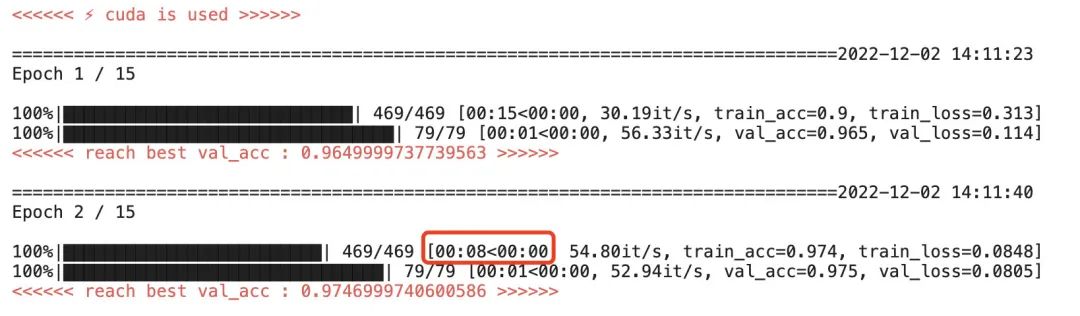
Для запуска эпохи на чистом процессоре требуется около 3 минут и 18 секунд.
При использовании чипа mac m1 для ускорения одна эпоха составляет около 33 с, что примерно в 6 раз быстрее, чем при работе на процессоре.
Это эквивалентно среднему ускорению процесса обучения в 7 раз, показанному на официальном сайте pytorch.
При использовании ускорения графического процессора Nvidia Tesla P100 одна эпоха составляет около 8 с, что примерно в 25 раз быстрее, чем работа процессора.
В целом, чип Mac M1 значительно ускоряет процесс обучения глубокому обучению, обычно примерно в 5–7 раз.
Однако по сравнению с высокопроизводительным графическим процессором Tesla P100, который чаще всего используется на предприятиях, разница в скорости обучения все равно составляет от 2 до 4 раз. Его можно рассматривать как мини-версию графического процессора.
Поэтому чип Mac M1 больше подходит для локального обучения некоторых моделей малого и среднего размера, быстрой итерации идей, и им довольно приятно пользоваться.
Особенно если вы изначально планировали сменить компьютер, использовать Mac для разработки будет намного проще, чем использовать Windows.
Друзья, нуждающиеся в помощи, рекомендуют купить это, автономный канал JD.com, чип Mac Book Pro M1, унифицированную память 16 ГБ, чего в принципе достаточно для небольшой алхимии.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
