Обзор технических принципов и структуры большой модели ChatBi «Диалог с базой данных» в одной статье.
Предисловие
Я писал о NL2SQL в прошлом выпуске. Я считаю, что друзья, прочитавшие его, должны быть очень заинтересованы в исследовании и разработке больших моделей на уровне офиса взаимодействия с данными. На рынке также есть много коммерческих продуктов, таких как Alibaba Cloud. анализ ГБИ:
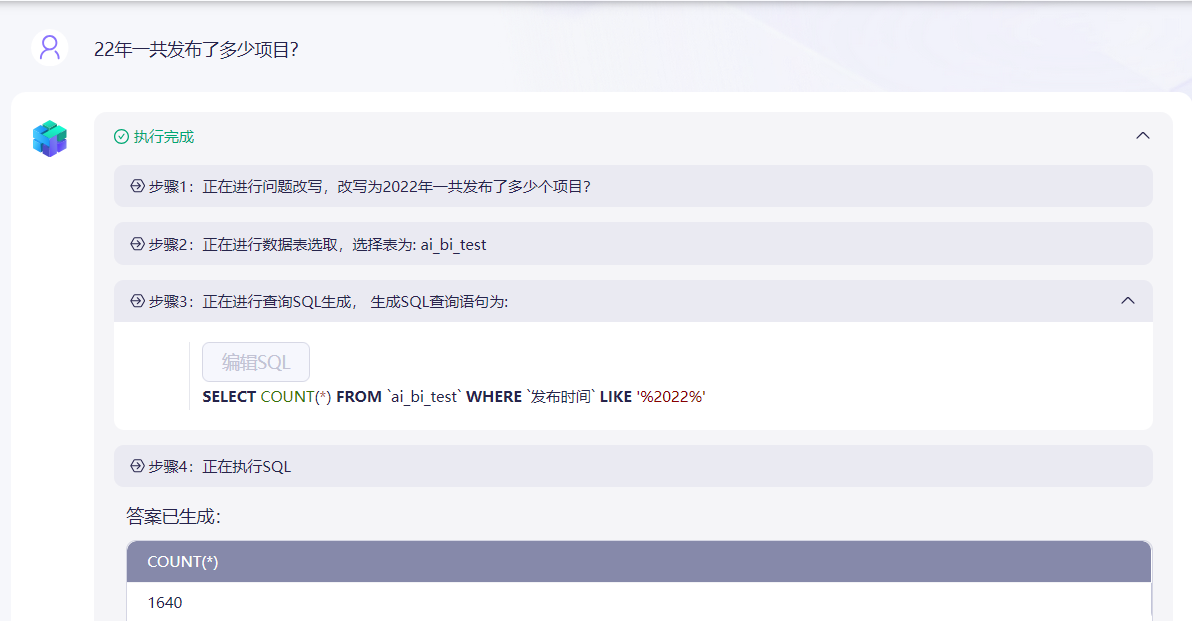
ChatBI от Tencent Cloud:
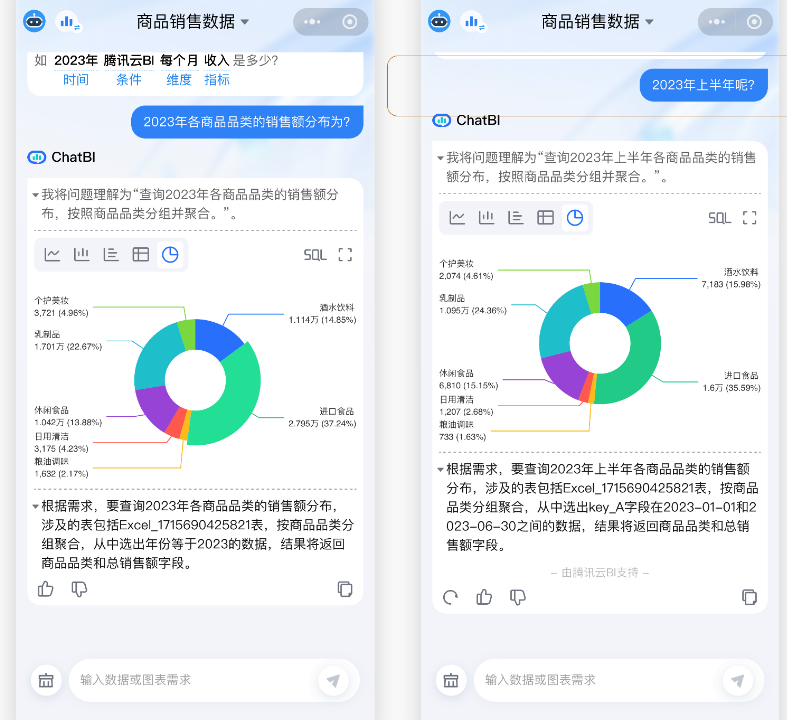
Можно сказать, что подобные продукты наиболее актуальны для бизнеса.
существуют во многих бизнес-сценариях,Что больше всего беспокоит пользователей, так это то, как быстро получить окончательные результаты данных.,Вместо понимания того, как данные извлекаются и обрабатываются. Сложный процесс сбора обучающих данных часто является дорогостоящим барьером.,А снижение этой стоимости напрямую связано с привлекательностью продукта и конверсией пользователей. Для наших технических специалистов,Хотя мышление в области НИОКР является основой,Но услуги, которые мы разрабатываем, в конечном итоге предназначены для лучшего удовлетворения потребностей бизнеса. С развитием технологий,Преобразование естественного языка в SQL (NL2SQL) стало будущей тенденцией разработки данных.,Это позволяет пользователям получать необходимые им данные с минимальными затратами на обучение.。ChatBIЭто конкретное проявление этой тенденции.,Это не только снижает технический порог,Это также значительно улучшило пользовательский опыт и конкурентоспособность продукта.,Сделайте анализ данных более интуитивным и эффективным.
Итак, в этой статье мы изучим такие технологии, как DB-GPT, как принципы продукта и структуры, которые объединяют LLM с базами данных, чтобы помочь нам по-настоящему применить их в нашем собственном бизнесе.
1.Что такое БД-GPT
DB-GPT — это среда разработки приложений для обработки данных искусственного интеллекта с открытым исходным кодом, использующая AWEL (язык выражений агентских рабочих процессов) и агентов. Разработан для упрощения создания приложений с большими моделями, особенно тех, которые связаны с базами данных. Он помогает предприятиям и разработчикам более удобно разрабатывать большие приложения на основе моделей за счет интеграции множества технических возможностей, таких как управление несколькими моделями (SMMF), оптимизация эффектов Text2SQL, оптимизация платформы RAG и совместная работа с несколькими агентами. Кроме того, DB-GPT также представляет AWEL (Agent Workflow Orchestration) для автоматизации сложных рабочих процессов и снижения рабочей нагрузки на кодирование, необходимой разработчикам. Вступая в эпоху Data 3.0, это означает, что разработчики могут быстро создавать свои собственные эксклюзивные приложения для обработки данных с меньшим количеством кода и более высокой эффективностью для продвижения бизнес-инноваций.
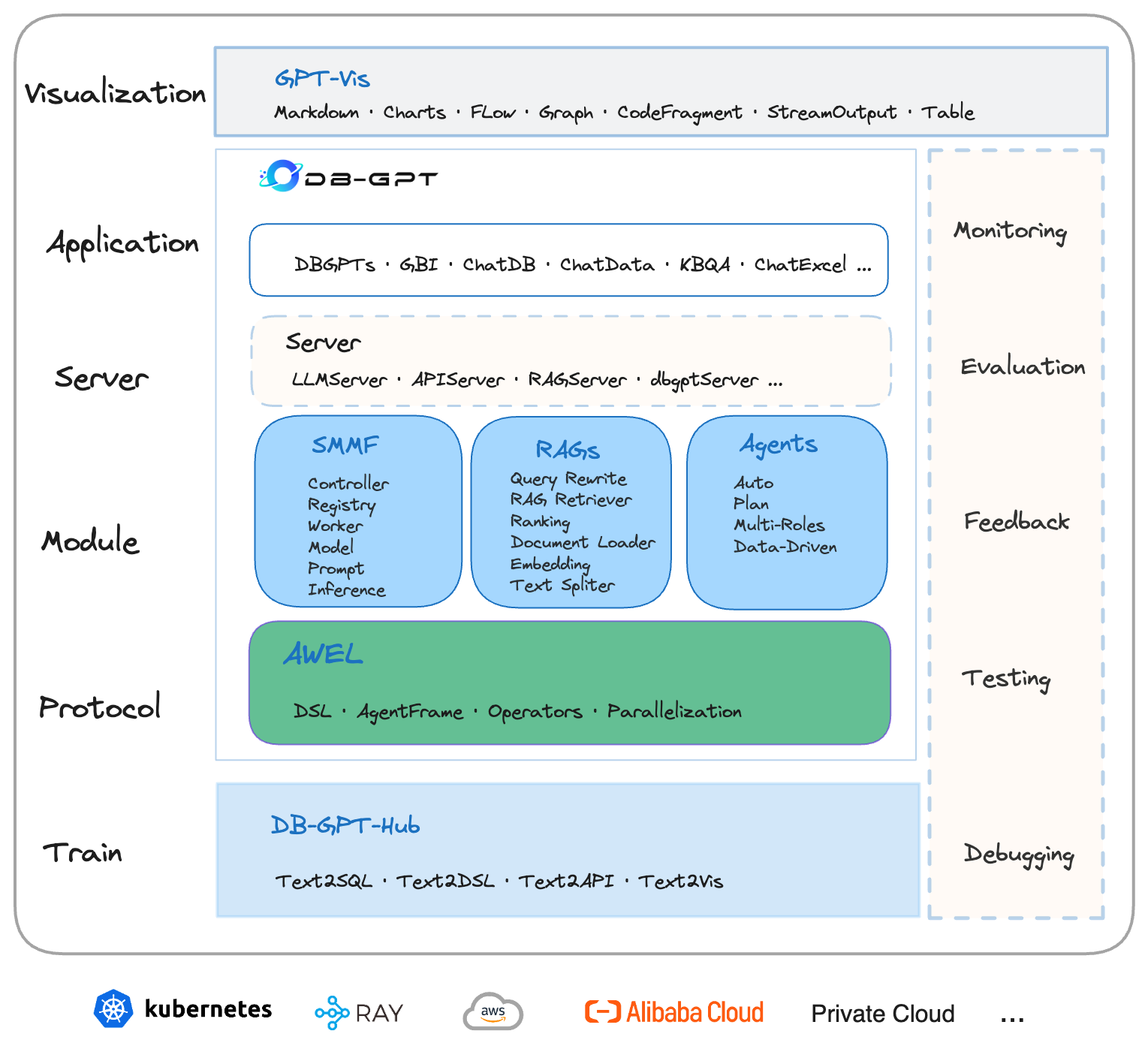
В этой статье в основном подробно объясняется система DB-GPT и дается подробное описание всей структуры искусственного интеллекта. Давайте посмотрим на всю архитектуру DB-GPT на рисунке выше.
1. Тренироваться
В нижней части рамки находится DB-GPT-Hub,Это базовый уровень для обучения модели и подготовки данных. Оно включает в себя обучение различным техническим навыкам.,нравиться Text2SQL、Text2DSL、Text2API、Text2Vis ждать. Этот уровень обеспечивает мощную поддержку обучения для модулей и приложений верхнего уровня, обеспечивая эффективность и точность модели.
2. Протокол (уровень протокола)
AWEL (язык оркестрации рабочих процессов агента):AWEL Это язык протокола, используемый для определения рабочих процессов агентов и управления ими. На этом уровне AWEL предоставил DSL (предметно-ориентированный язык), AgentFrame (фреймворк агента), Operations (операторы), Parallelization (распараллеливание) и другие функции. Эти компоненты делают оркестрацию и выполнение рабочих процессов более гибкими и эффективными.
3. Модуль (слой модуля)
Уровень модуля содержит три основных основных модуля:
- SMMF (многомодельная структура управления):Ответственный за управлениеи Запланируйте несколько моделей。он содержит Контроллер、Реестр、Рабочий、Модель、Подсказка (слово подсказки)、Inference(рассуждение)и другие компоненты,Обеспечьте эффективное сотрудничество и работу нескольких моделей.
- RAG (модули генерации дополнительных дополнений):включать Query Rewrite (перезапись запроса), RAG Ретривер, Рейтинг, Документ Loader (загрузчик документов), Embedding (встраивание), Text Сплиттер (разделитель текста) и т. д. в основном используются для повышения точности и релевантности контента.
- Агенты (интеллектуальный агентский модуль):Отвечает за межагентное сотрудничество.и Выполнение задачи,включать Auto (автоматизация), Plan (планирование), Multi-Roles (множество ролей), Data-Driven (управление данными) и другие возможности.
4. Сервер (уровень обслуживания)
Уровень сервиса включает в себя несколько компонентов сервиса, таких как LLMServer(Сервис больших языковых моделей)、APIServer(APIСлужить)、RAGServer(RAGСлужить)а также dbgptServer(DBGPTСлужить)ждать。Эти Служить Компоненты совместно поддерживают работу приложений верхнего уровня.,Обеспечить стабильность и масштабируемость системы.
5. Приложение (прикладной уровень)
Уровень приложений показывает множество конкретных приложений, созданных на основе DB-GPT, в том числе DBGPTs、GBI、ChatDB、ChatData、KBQ4、ChatExcel ждать. Эти приложения ориентированы на различные потребности бизнеса и используют базовые технологии и сервисы для реализации автоматизированных процессов, от запросов на естественном языке до анализа данных.
6. Визуализация (уровень визуализации)
Верхний слой — это слой визуализации. GPT-Vis,этовключать Понятно Markdown、Charts、Flow、Graph、CodeFragment、StreamOutput、Table и другие инструменты визуализации. Эти инструменты помогают пользователям более интуитивно понимать и отображать результаты анализа данных.
7. Поддержка и интеграция
Платформа также интегрирует несколько облачных сервисов и технологий контейнеризации, таких как Kubernetes, Ray, AWS, Alibaba Cloud и Private Cloud, для поддержки кроссплатформенного и мультисредового развертывания и эксплуатации.
8. Доступность
С правой стороны рамки также выделена опора. Мониторинг、Оценка、Обратная связь、Тестирование и Отладка Инструменты и механизмы для обеспечения надежности системы и постоянной оптимизации.
Эта структура показывает DB-GPT Ее мощные функции и гибкость позволяют разработчикам использовать эту платформу для эффективной разработки и развертывания сложных приложений искусственного интеллекта, особенно в средах, управляемых базами данных. Вынимаем ключ основной модуль для обсуждения исследований.
основной модуль
1.1 SMMF
Многомодельная структура управления (SMMF, Multi-Model Management Framework) — это ключевой компонент DB-GPT для управления и оптимизации нескольких больших языковых моделей (LLM). Его основная функция — предоставить разработчикам эффективный и гибкий способ одновременного управления несколькими моделями.,Тем самым улучшая производительность и эффективность приложений с большими моделями.,Особенно в сценариях, связанных с базами данных.
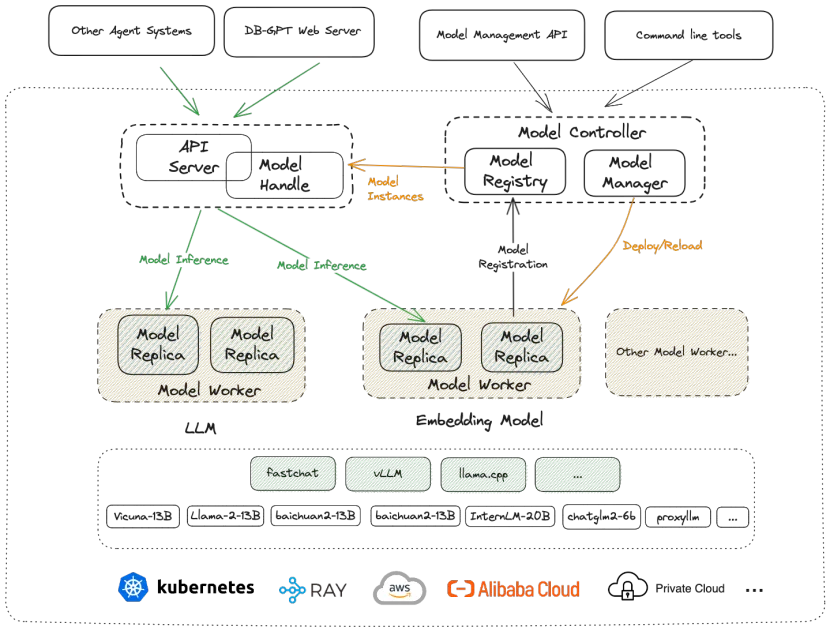
В приложениях уровня предприятия SMMF особенно подходит для сценариев, когда необходимо одновременно обрабатывать несколько задач или интегрировать несколько моделей. Например, интеллектуальной системе обслуживания клиентов может потребоваться одновременная обработка запросов клиентов на естественном языке, рекомендаций по продуктам и анализ настроений. Для выполнения каждой из этих задач могут потребоваться разные модели. SMMF может помочь предприятиям гибко управлять этими моделями и динамически корректировать их в соответствии с реальными потребностями для обеспечения эффективной работы системы.
1.2 RAG(Retrieval Augmented Generation)
как следует из названия,это своего родаПоиск(Retrieval)игенерировать(Generation)комбинированные технологии。Все начинается с использования огромной базы знаний.ПоискПредоставьте наиболее актуальную информацию по заданному вопросу.,а затем на основе этой информациигенерироватьотвечать。Преимущество этого заключается в том, что,Это позволяет модели не только полагаться на существующие знания.,Внешние данные также можно использовать в режиме реального времени для предоставления более точных и полных ответов.
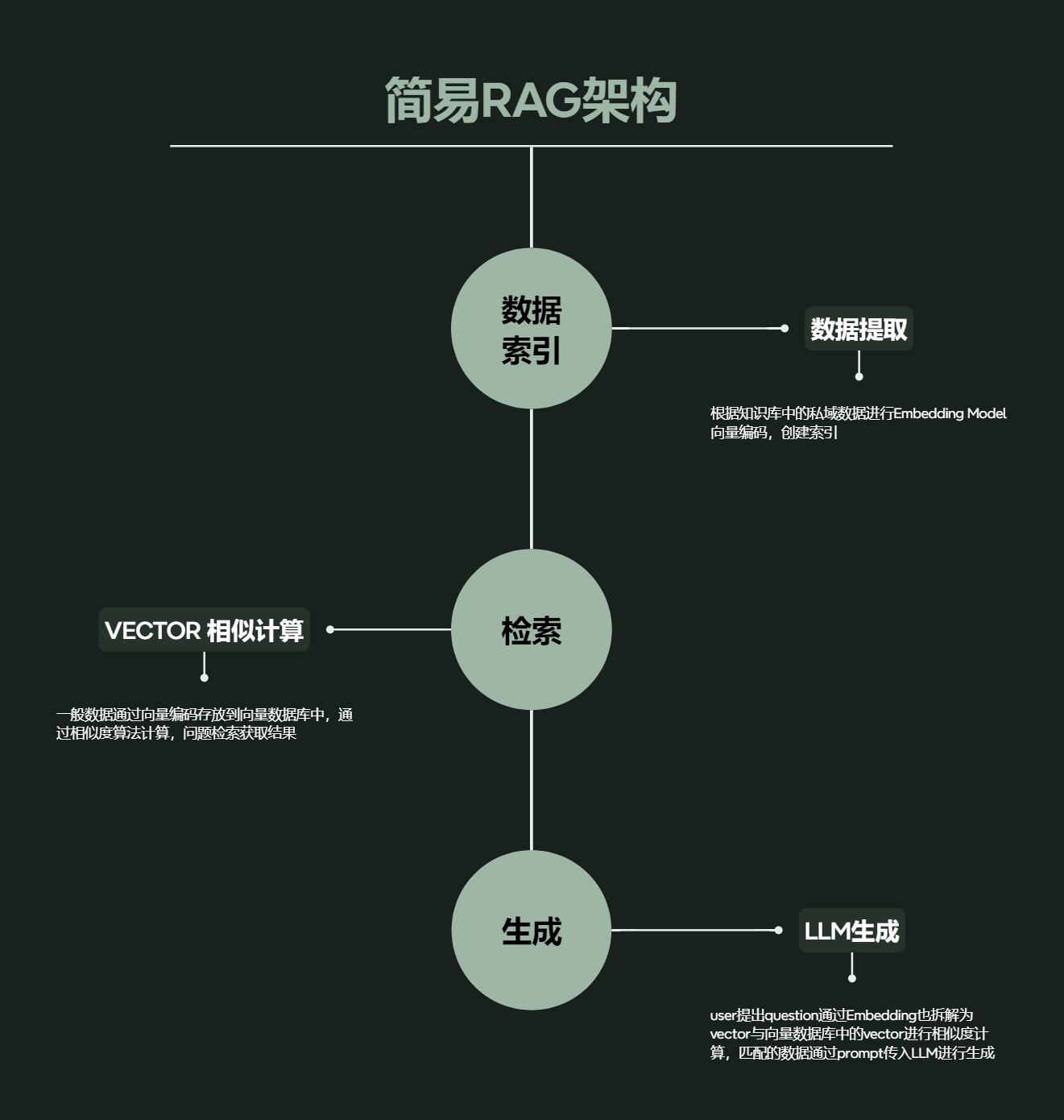
Традиционные модели генеративного языка могут давать неточные или неполные ответы из-за отсутствия знаний по конкретной предметной области при работе с широкими темами или сложными запросами к базе данных. Объединив технологию поиска информации, платформа RAG сначала извлекает информацию, связанную с запросом, из соответствующих баз знаний или баз данных, а затем вводит эту информацию в генеративную модель. Этот метод эффективно компенсирует недостаток знаний о генеративной модели в конкретной области, тем самым повышая точность генерируемого контента.
существовать DB-GPT Средний, тряпка Фреймворк позволяет системе динамически обрабатывать сложные запросы на естественном языке. Для сложного запроса RAG Сначала выполните поиск по соответствующей схеме базы данных или записи данных, затем объедините эту информацию с запросом пользователя, чтобы сделать более точный и контекстно-зависимый SQL-запрос. Эта способность позволяет DB-GPT существование является более гибким и мощным при работе с разнообразными потребностями пользователей.
1.3 Agents
Автоматизация:Автоматизация – это Agents Одна из основных функций модуля. Это позволяет агенту существовать без вмешательства человека.,На основе предопределенных правил или моделей,Самостоятельно выполнять задачи. Эта возможность значительно повышает эффективность системы.,Уменьшает необходимость в ручных операциях,Особенно при работе с повторяющимися задачами.,Функции автоматизации позволяют значительно повысить скорость выполнения и точность рабочих процессов.
План:Функция планирования позволяет агенту выполнять задачи в соответствии с входными данными.и Цель,Самостоятельно формулировать и корректировать планы выполнения задач. Агент анализирует сложность задачи, требования ко времени и ограничения ресурсов.,придерживаться оптимального плана выполнения. Эта функция особенно важна в сложных многоэтапных задачах.,Это может гарантировать, что задачи выполняются эффективно в соответствии с оптимальным путем.
Мульти-роли:Эта функция позволяет одному агенту выполнять несколько ролей.,Или выполните сложную задачу посредством сотрудничества нескольких агентов. Многофункциональная функция обеспечивает гибкое распределение задач.,Убедитесь, что каждое задание выполняется наиболее подходящим персонажем или агентом. Такая гибкость позволяет системе справляться с разнообразными потребностями бизнеса и сложностью задач.
Управляемый данными:Управление данными означает, что агент может принимать решения на основе данных в реальном времени.и Выполнение задачи。Эта возможность позволяет агенту динамически корректировать свое поведение.,адаптироваться к изменениям в окружающей среде или обновлениям данных,Тем самым повышается точность и своевременность выполнения задач. Возможности управления данными гарантируют, что система сможет справиться с неопределенностью и динамическими изменениями.,Он по-прежнему может поддерживать эффективную и стабильную работу.
Агенты могут использовать RAGs Информация, предоставляемая модулем, расширяет возможности более точно понимать запросы пользователей и отвечать на них. Также можно использовать с SMMF Совместная работа модулей, динамический вызов и управление несколькими моделями гарантируют, что наиболее подходящая модель будет использоваться в различных сценариях задач для достижения наилучших результатов. Такая масштабируемость обеспечивает DB-GPT Платформа может адаптироваться к различным сложным сценариям применения и предоставлять индивидуально настраиваемые решения.
1.4 Автоматизированная точная настройка
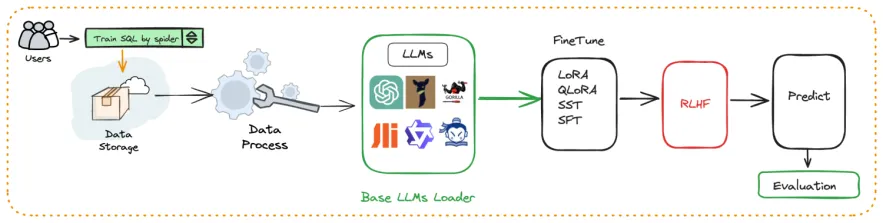
Вокруг больших языковых моделей、Набор данных Text2SQL、LoRA/QLoRA/Pturningждать Построено с использованием методов тонкой настройки Автоматизированная точная настройка облегченного фреймворка, Сделайте тонкую настройку TextSQL такой же удобной, как сборочный конвейер.
1.Хранение и обработка данных (Данные Storage & Data Process)
Исходные данные пользователя сохраняются первыми,Обычно включает крупномасштабные наборы данных SQL-запросов для обучения.,Например, набор данных Spider. Набор данных Spider — это эталонный набор данных, широко используемый для задач преобразования текста в SQL.,Содержит большое количество SQL-запросов и соответствующих им описаний на естественном языке. Следующий,Сохраненные данные пройдут этап обработки данных.,Включая очистку, форматирование и предварительную обработку.,Чтобы гарантировать, что данные могут эффективно использоваться последующими моделями большого языка (LLM). Этот шаг имеет решающее значение,Потому что качественная обработка данных позволяет существенно улучшить обучающий эффект модели.
2. Загрузка большой языковой модели (Base LLMs Loader)
существоватьэтот этап,Загружаются предварительно обученные базовые модели большого языка (LLM). К этим моделям относятся GPT OpenAI, LLaMA Meta, BERT Google и т. д. Эти базовые модели были предварительно обучены на крупномасштабных данных.,Обладание мощными способностями к пониманию естественного языка,Однако существующие показатели в конкретных областях могут нуждаться в дальнейшей оптимизации.
3. Тонкая настройка
Модель оптимизирована с помощью нескольких различных методов тонкой настройки.,Включая LoRA (низкоранговое адаптивное), QLoRA (квантованное низкоранговое адаптивное), SST (пошаговое обучение масштабированию) и SPT (пошаговое прогрессивное обучение) и т. д. Эти методы могут сохранить мощные возможности исходной модели.,Внесите более детальные настройки в свою модель.,Сделайте так, чтобы он лучше справлялся с конкретными задачами. Например, предметно-ориентированный SQL,Улучшите эффект практического применения модели.
4. Обучение с подкреплением и обратной связью с человеком (RLHF)
RLHF(Reinforcement Learning with Human Feedback):существовать После тонкой настройки,Модель дополнительно оптимизируется за счет обучения с подкреплением в сочетании с обратной связью от человека. Этот процесс постоянно корректирует модель, учитывая фактические отзывы пользователей.,Сделайте содержание ограниченности более соответствующим ожиданиям пользователей. от RLHF,Модели не только лучше понимают намерения пользователей,Может продолжать совершенствоваться,реагировать на меняющиеся потребности.
5. Прогнозируйте и оценивайте & Evaluation)
- предсказывать:точно настроенныйиRLHFОкончательная модель будет использоваться в реальных условиях.предсказывать Задача,Например, решения для SQL-запросов или других сложных задач.
- Оценивать:наконец,Эффективность модели будет измеряться с помощью ряда показателей.,Чтобы гарантировать, что его результаты будут точными и эффективными.,и как ожидалось.
Итак, в следующей главе мы полностью развернем и создадим всю DB-GPT на облачном сервере вычислительной мощности для использования, а также проведем некоторую практическую проверку в соответствии с бизнесом.
Если есть какие-либо ошибки, пожалуйста, оставьте сообщение для консультации. Большое спасибо.
Это все по этому вопросу. Я застрял. Если у вас есть вопросы, оставьте сообщение для обсуждения. Увидимся в следующем выпуске.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
