Обзор рекомендательных систем на основе генеративных моделей (Gen-RecSys)
TLDR: Целью этого обзора является обзор основных достижений генеративных рекомендательных моделей (Gen-RecSys), включая: базовый обзор генеративных моделей, основанных на взаимодействии, применения больших языковых моделей (LLM) в генеративных рекомендательных, поисковых и диалоговых рекомендательных системах; Интеграция мультимодальных моделей обработки и генерации изображений и видеоконтента. В этой статье обсуждаются влияние и вред Gen-RecSys с целостной точки зрения и указываются проблемы, с которыми он сталкивается.

Документ: arxiv.org/abs/2404.00579. Код: github.com/yasdel/LLM-RecSys
1 История исследований
Традиционные системы рекомендаций полагаются на фиксацию предпочтений пользователей и характеристик товаров в рамках конкретной области, которая зачастую является узкой. Достижения в области генеративных моделей значительно улучшили эту ситуацию. В частности, генеративные модели изучают представления и образцы из сложных распределений данных, которые включают не только историю взаимодействия пользователя с элементом, но также текстовый и графический контент, открывая эти формы данных для новых задач интерактивных рекомендаций в качестве дополнения.
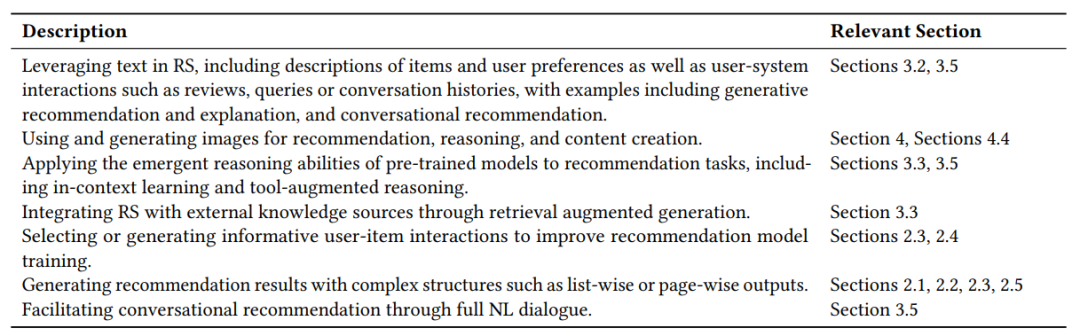
Кроме того, благодаря внедрению больших языковых моделей (LLM), таких как ChatGPT и Gemini, обработка естественного языка (NLP) достигла исключительных возможностей, включая логический вывод, контекстное обучение за несколько шагов и доступ к широко открытой информации в рамках предварительно обученных параметров. Благодаря своей универсальности эти предварительно обученные генеративные модели открывают новое пространство исследований для широкого спектра приложений рекомендаций, как показано в таблице ниже.
Суть генеративных моделей заключается в их способности моделировать и осуществлять выборку распределений данных для различных целей вывода. Это позволяет иметь два основных режима применения в рекомендательных системах:
- Модель прямого обучения. Этот метод напрямую обучает сгенерированную модель данным взаимодействия пользователя с элементом.,Например ВАЭ-CF,прогнозировать предпочтения пользователей,Вместо использования большого и разнообразного предтренировочного набора. Эти модели изучают вероятностное распределение элементов, которые могут понравиться пользователю, на основе предыдущих взаимодействий пользователя.
- Предтренировочная модель. Эта стратегия используется в разных данных (текст, изображение, видео) для понимания сложных шаблонов на предварительно обученной модели.,отношения и контекстная информация. Эта статья Система Использование предварительного обучения Модели в рекомендациях включает в себя следующие настройки:
- Ноль и мало подсказок, причем последний использует контекстное обучение (ICL) для широкого понимания без дополнительного обучения.
- тонкая настройка,Для различных рекомендательных задач,Внесите изменения в Модель, используя определенные наборы данных.
- Генерация с расширенным поиском (RAG) объединяет поиск информации и генеративное моделирование в контекстно-зависимые выходные данные.
- Встраивание последующего обучения для создания вложений или помеченных последовательностей для сложных представлений контента.
- мультимодальный подход,Используйте различные типы данных, чтобы повысить точность и актуальность рекомендаций Модели.
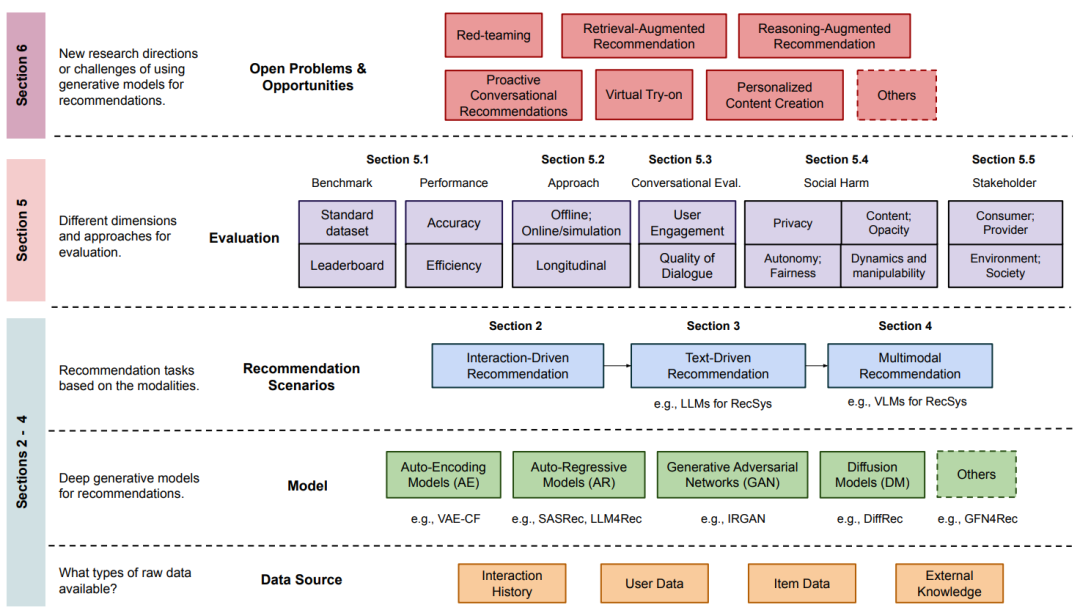
На рисунке ниже показана организационная структура опроса Gen-RecSys, представленного в этой статье. Он разделен на несколько уровней, включая источники данных, модели рекомендаций и сценарии, методы оценки системы и проблемы. В этой статье представлен системный подход, который разбивает процесс рекомендаций для исследований Gen-RecSys на отдельные компоненты и методы.
2 Модель создания системы рекомендаций на основе взаимодействия
Рекомендация на основе взаимодействия — это настройка, в которой доступно только взаимодействие пользователя с элементом (например, «Пользователь А нажимает на элемент Б»), что является наиболее распространенной настройкой для исследования рекомендательной системы. Этот параметр фокусируется на входных данных от взаимодействия пользователя с элементом и выходных данных из списков рекомендаций по элементам, а не на других более богатых входных или выходных данных (например, объяснениях рекомендаций). Несмотря на то, что глубокие генеративные модели (DGM) не используют текстовую или визуальную информацию, они по-прежнему демонстрируют свое уникальное удобство использования. Например, DGM может улучшить взаимодействие пользователя с элементами, обученного на модели, использовать шумоподавление для рекомендаций и изучить распределение рекомендуемых макетов.
В этом разделе используются данные взаимодействия пользователя с элементом для изучения парадигмы DGM для рекомендательных задач, включая модели автоматического кодирования, модели авторегрессии, генеративно-состязательные сети, модели диффузии и т. д.
2.1 Модель автокодирования
Модели автокодирования изучают и реконструируют входные данные модели, которые можно использовать для шумоподавления, обучения представлению и задач генерации.
Модель автокодирования с шумоподавлением Автоэнкодеры шумоподавления (DAE) — это группа моделей, которые учатся восстанавливать исходные входные данные из поврежденных входных данных. Традиционно Модель автокодирования с Шумоподавлением обычно имеет скрытый слой, который действует как «узкое место», например, AutoRec пытается восстановить часть наблюдаемого входного вектора. В более широком смысле, модель, подобная BERT, также считается моделью. автокодирования с шумоподавлением. Эти модели восстанавливают поврежденные (то есть замаскированные) входные данные с помощью составных блоков самообслуживания.
вариационная модель автокодирования Вариационные автоэнкодеры (VAE) — это модели, которые изучают случайные сопоставления сложных распределений вероятностей с распределениями вероятностей. Распределение обычно простое (например, нормальное распределение), из которого декодер может выполнить выборку для генерации выходных данных. VAE широко используется в традиционных рекомендательных системах, особенно в совместной фильтрации, рекомендациях последовательности и генерации кандидатов. По сравнению с автоэнкодерами с шумоподавлением (DAE), VAE часто демонстрируют превосходную производительность при совместной фильтрации благодаря более строгим предположениям моделирования, таким как VAE-CF. Кроме того, условная модель VAE (CVAE) изучает распределение списков предпочтительных рекомендаций для данного пользователя, что полезно при создании списков, выходящих за рамки жадных режимов ранжирования. ListCVAE, PivotCVAE и т. д. используют VAE для создания всего списка рекомендаций вместо индивидуального ранжирования отдельных элементов.
2.2 Авторегрессионная модель
рекурсивная авторегрессионная модель Рекуррентные нейронные сети (RNN) используются для прогнозирования следующего элемента в рекомендациях на основе сеансов и последовательностей, таких как GRU4Rec и его варианты. Кроме того, используя авторегрессионные генеративные свойства рекуррентных сетей, исследователи извлекают последовательности поведения пользователей, сгенерированные моделью, для изучения модельных атак.
авторегрессионная модель самообслуживания Модель самовнимания вдохновлена Трансформером и заменяет повторяющийся блок самообслуживанием и связанными с ним модулями. Этот набор моделей можно использовать для основанных на сеансах и последовательных рекомендаций, прогнозирования следующей корзины или прогнозирования связанных товаров, а также для атак по модели, аналогично RNN. В то же время преимущество моделей самообслуживания заключается в том, что они лучше справляются с долгосрочными зависимостями, чем RNN, и поддерживают параллельное обучение. Кроме того, модели самообслуживания являются практичным выбором для предварительно обученных моделей и больших языковых моделей, которые становятся все более популярными в рекомендательных системах.
2.3 Генеративно-состязательная сеть
Генеративно-состязательная сеть (GAN) состоит из двух основных компонентов: сети-генератора и сети-дискриминатора. Эти сети обучены состязательно для улучшения производительности генератора и дискриминатора. GAN используются для различных целей в рекомендательных системах. В настройках, основанных на взаимодействии, GAN используются для выбора насыщенных информацией обучающих выборок. Например, в IRGAN для выборки отрицательных выборок используется модель генеративного поиска. В то же время GAN объединяет предпочтения или взаимодействия пользователей для улучшения данных обучения. Кроме того, GAN показали эффективность при создании списков или страниц рекомендаций, например полностраничных настроек рекомендаций.
2.4 Диффузионная модель
Модель диффузии генерирует выходные данные в два этапа: (1) прямой процесс, который преобразует искажения входных данных в шум, и (2) обратный процесс, который итеративно восстанавливает исходные входные данные из шума. Его превосходные возможности генерации привлекают все больший интерес со стороны сообщества рекомендательных систем. Во-первых, в некоторых работах используется модель диффузии, чтобы узнать вероятность будущего взаимодействия пользователя. Например, DiffRec использует искаженный шум из исторических взаимодействий пользователя для прогнозирования будущих взаимодействий пользователя. Во-вторых, существуют также работы, направленные на использование моделей диффузии для улучшения обучающих последовательностей, что может уменьшить разреженность данных и проблемы пользователей с длинным хвостом при рекомендации последовательностей.
2.5 Другие генеративные модели
Помимо упомянутых ранее генеративных моделей, рекомендательные системы также используют другие типы генеративных моделей. Например, VASER использует нормализованные потоки (и VAE) для рекомендаций на основе сеансов. С другой стороны, GFN4Rec использует генеративную потоковую сеть для рекомендаций по спискам. Кроме того, IDNP использует нейронные процессы большой языковой модели при выработке рекомендаций по последовательностям.
3 Большие языковые модели в рекомендательных системах
Естественный язык, использующий текстовый контент, может представлять не только функции элемента или предпочтения пользователя, но также взаимодействие пользователя с системой, рекомендательные задачи и внешние знания. В частности, реальные элементы часто связаны с форматированным текстовым содержимым, включая заголовки, описания, полуструктурированные текстовые метаданные и обзоры. Аналогично, пользовательские предпочтения могут быть легко выражены на естественном языке как в традиционных системах, так и в развивающейся парадигме диалоговых рекомендательных систем: первые используют контент на естественном языке, такой как обзоры, поисковые запросы или описания понравившихся товаров, а вторые непосредственно через пользователя. Устное повествование и беседа. Предварительно обученная модель большого языка может использовать эти текстовые данные для изучения способности рассуждения генерировать и интерпретировать рекомендации по элементам на основе предпочтений пользователя. Эти предварительно обученные способности можно дополнительно улучшить с помощью подсказок, подталкивания, поиска и внешних инструментов.
3.1 Рекомендации по модели большого языка, предназначенной только для кодирования
Рекомендации по интенсивному поиску Текстовое содержимое (например, заголовок, описание или комментарии) каждого элемента рассматривается как документ, и если явный запрос от пользователя недоступен, общий подход состоит в синтезе запроса путем объединения описаний последних записей пользователя. понравившиеся предметы. Плотные средства извлечения (например, BERT, TAS-B) создают ранжированный список документов для данного запроса путем оценки сходства (например, скалярного произведения или косинусного сходства) между внедрениями документов и внедрениями запросов, кодирующими только большую языковую модель.
Рекомендация посредством объединения предпочтений элементов большой языковой модели В некоторых работах прогнозирование оценок достигается за счет совместного внедрения терминов естественного языка и описаний предпочтений в большую структуру кросс-кодировщика языковой модели. Этот подход объединенного кодирования обычно демонстрирует высокую производительность, поскольку он позволяет взаимодействовать между пользователем и представлениями элементов, но требует больше вычислительных затрат, чем плотный поиск, и поэтому лучше всего подходит для небольших наборов элементов или для изменения ранжирования.
3.2 Рекомендация, основанная на большой языковой модели
Генеративные рекомендации для больших языковых моделей основаны на предварительном обучении на больших текстовых корпусах, которые предоставляют знания о широком спектре сущностей, человеческих предпочтениях и здравом смысле, которые можно использовать непосредственно для рекомендаций, а также точно настраивать или предлагать для улучшения обобщения. и уменьшить потребность в данных по конкретной предметной области.
Рекомендация порождающих выражений нулевой и меньшей степени Он создает подсказки или инструкции с описанием предпочтений пользователя на естественном языке, чтобы рекомендовать элементы, которые могут быть предпочтительными, или прогнозировать их оценки. В целом производительность больших языковых моделей без тонкой настройки не так хороша, как у контролируемых методов совместной фильтрации, обученных на достаточном количестве данных, но она выгодна при холодном запуске. Немногие подсказки (или контекстное обучение), в которых подсказки содержат примеры пар ввода-вывода, обычно работают лучше, чем отсутствие подсказок.
Точная настройка больших языковых моделей для генеративных рекомендаций Чтобы улучшить производительность генеративных рекомендаций для больших языковых моделей и добавить знания к их внутренним параметрам, большинство работ сосредоточено на стратегиях точной настройки и настройки ключевых слов.
3.3 Получение расширенных рекомендаций
Хотя добавление знаний в большую языковую модель посредством тонкой настройки часто повышает производительность, этот подход требует большого количества параметров для хранения знаний и требует повторной тонкой настройки каждый раз при обновлении системы. Другая парадигма — генерация с расширенным поиском (RAG), которая генерирует выходные данные на основе информации, полученной из внешних источников знаний, таких как плотные ретриверы. Методы RAG лучше облегчают онлайн-обновления, уменьшают галлюцинации и, как правило, требуют меньше параметров, поскольку знания можно экстернализировать. RAG недавно были изучены на предмет рекомендаций, при этом наиболее распространенным подходом является сначала использование системы поиска или рекомендации для создания набора элементов-кандидатов на основе пользовательских запросов или истории взаимодействия, а затем приглашение большой языковой модели кодирования-декодирования для повторного анализа. ранжируйте набор элементов-кандидатов.
3.4 Генерация ввода на основе большой языковой модели
В отличие от того, как рекомендательные системы или средства извлечения используются в RAG для получения входных данных для больших языковых моделей, большие языковые модели также могут использоваться для генерации входных данных для рекомендательных систем. Например: LLM2-BERT4Rec использует встраивание текста элемента OpenAI для инициализации встраивания элемента BERT4Rec; Query-SeqRec использует встраивание запроса большой языковой модели в качестве входных данных системы рекомендаций на основе преобразователя. Tiger сначала использует большой; языковую модель для создания встраивания текста элемента, а затем количественно определить его в семантический идентификатор и, наконец, использовать идентификатор элемента исторического взаимодействия пользователя для обучения системе рекомендаций на основе T5 для создания нового идентификатора. Аналогичным образом, MINT и GPT4Rec генерируют запросы на основе истории взаимодействия с пользователем, предлагая большие языковые модели в качестве входных данных для плотных методов извлечения.
3.5 Разговорная рекомендация
Это направление изучает применение больших языковых моделей в многоходовых, многозадачных и гибридных активных рекомендательных диалогах на естественном языке. Он представляет историю разговоров как новый богатый тип данных о взаимодействии. В частности, ConvRec включает изучение и интеграцию различных диалоговых элементов, таких как управление диалогом, рекомендации, объяснения, вопросы и ответы, критика и индукция предпочтений. В то время как в некоторых исследованиях для обработки ConvRec используется одна большая языковая модель (например, GPT4), другие работы полагаются на большие языковые модели для облегчения диалога на естественном языке и интеграции вызовов к модулям рекомендаций, которые генерируют рекомендации по элементам на основе диалога или истории.
4 Генеративная мультимодальная рекомендательная система
В последние годы пользователи стали ожидать более высокого уровня взаимодействия, чем простые текстовые или графические запросы, такие как предоставление изображений продуктов, которые они хотят, а также модификации естественного языка (например, платье на изображении того же стиля, но в другом стиле). цвет). Кроме того, пользователям также нужна визуализация, чтобы понять, соответствует ли предмет сценарию использования (например, влияние одежды на тело или расстановка мебели). Этот уровень взаимодействия требует новых рекомендательных систем для выявления уникальных свойств, скрытых в каждом шаблоне.
4.1 Зачем нужна мультимодальная рекомендательная система?
Продавцы имеют мультимодальную информацию о своих клиентах и продуктах, включая описания продуктов, изображения и видео, отзывы клиентов и историю покупок. Однако существующие РС обычно обрабатывают каждый источник независимо, а затем объединяют результаты путем объединения оценок одномодальной активности.
Этот подход «поздней конвергенции» недостаточен для удовлетворения потребностей клиентов. Например, при проблеме холодного запуска очень эффективно собирать различную информацию об элементах, которая может лучше адаптироваться к новым элементам или новым пользователям. Кроме того, некоторые сценарии требуют понимания запросов пользователей. Например, для запроса «Нужен черный журнальный столик с металлическим стеклом для гостиной стоимостью до 300 долларов» системе необходимо объединить внешний вид и форму других объектов у клиента, чтобы рассуждать о внешнем виде и форме предмета. , поэтому мультимодальное понимание становится решающим.
4.2 Проблемы мультимодальных рекомендательных систем
Разработка мультимодальных рекомендательных систем сталкивается с проблемами. Во-первых, собрать данные для обучения мультимодальной системы гораздо сложнее, чем одномодальной. Во-вторых, непросто объединить различные шаблоны данных для улучшения результатов рекомендаций. Например, существующие методы отображают каждую модальность данных в общее скрытое пространство, где все модальности примерно согласованы. Однако такие методы часто собирают информацию, общую для разных модальностей, но игнорируют дополнительные аспекты, которые могут быть полезны для рекомендаций. В-третьих, для изучения мультимодальной модели требуется на порядки больше данных, чем для изучения модели для одной модальности данных.
4.3 Сравнение мультимодальных рекомендаций
Изучение мультимодальных генеративных моделей затруднено, потому что нужно не только изучить скрытые представления для каждой модальности, но также необходимо убедиться, что они согласованы. Один из способов решения этой проблемы — сначала изучить согласованность между несколькими модальностями, а затем изучить порождающую модель «хорошо согласованных» представлений. Существует два репрезентативных метода контрастного обучения CLIP и ALBEF.
Предварительное обучение контрастному языку-изображению (CLIP) — это популярный подход, задачей которого является проецирование изображения и связанного с ним текста в одну и ту же точку пространства внедрения с использованием параллельных кодировщиков изображений и текста. Это достигается за счет симметричной потери перекрестной энтропии в строках и столбцах матрицы косинусного подобия между всеми возможными парами изображения и текста в мини-пакете. Выравнивание перед объединением (ALBEF) расширяет возможности CLIP за счет объединения мультимодальных кодировщиков встраивания текста и изображений и предлагает три цели моделей предварительного обучения: контрастное обучение изображения и текста (ITC), моделирование языка в маске (MLM) и сопоставление изображения и текста. (ИТМ). Авторы также вводят дистилляцию импульса, чтобы предоставить псевдометки для компенсации потенциально неполных или ошибочных текстовых описаний в зашумленных данных обучения сети.
4.4 Генеративные мультимодальные рекомендации
Несмотря на свои преимущества, на эффективность чисто сравнительных рекомендательных систем часто влияет нехватка данных и неопределенность. Генеративные модели решают эти проблемы, накладывая соответствующую структуру на их скрытое пространство. Репрезентативные методы генерации включают в себя: мультимодальный VAE, диффузионную модель и мультимодальную модель большого языка.
Мультимодальный ВАЭ Хотя VAE можно напрямую применять к мультимодальным данным, лучший способ обучения кодировщиков и декодеров, специфичных для конкретной модальности, на больших наборах данных — это разделить входное пространство и скрытое пространство по модальности, например, для изображений и текста. Однако этот метод будет Мультимодальным. ВАЭразделен на два независимыхVAE,По одному на модальное окно. В отличие от ВАЭ,Эти две модальности выравниваются путем добавления контрастной потери между одномодальными скрытыми представлениями с ELBO в качестве цели оптимизации. Эксперименты показывают,ContrastVAE полностью моделирует неопределенность и разреженность данных,и устойчив к возмущениям в скрытом пространстве,Улучшения были сделаны на основе чистой контрастной модели.
диффузионная модель диффузионная Модель является самой продвинутой моделью поколения изображений. Хотя их также можно использовать для генерации текста, например, посредством реализации дискретного скрытого пространства с категориальными вероятностями преобразования, на практике обычно предпочитаются кодировщики текста на основе преобразователей или других моделей seq2seq. Таким образом, мультимодальная Модель текста и изображений (например, Модель генерации текста в изображение) сочетает в себе кодировщики текста с диффузионной визуализацией изображений. Модель комбинированная. Например, DALL-E использует пространство встраивания CLIP в качестве отправной точки для создания новых изображений, а Stable Diffusion использует автоэнкодер UNet для предварительной подготовки к потерям восприятия и состязательным целевым потерям на основе патчей соответственно.
Мультимодальная модель большого языка Он предоставляет пользователям интерфейс на естественном языке, упрощает выполнение пользовательских запросов различными способами и помогает визуализировать продукт в различных режимах. Учитывая сложность комплексного обучения больших генеративных моделей, исследователи часто объединяют различные предварительно обученные кодеры и декодеры для формирования системы. Другой подход, практически не требующий обучения, заключается в том, чтобы позволить «контроллеру» больших языковых моделей использовать внешние базовые модели или инструменты для обработки мультимодального ввода и вывода. Во-вторых, точная настройка инструкций — важный шаг для больших языковых моделей. Ллава это своего рода Мультимодальная модель большого языка,В качестве входных данных принимает текст и изображения.,и давать полезные текстовые ответы,Он использует простой уровень линейной адаптации для соединения кодера CLIP с декодером модели большого языка. Существуют и другие исследования, которые меняют уровень соединения с линейной проекции на двухслойную MLP.,и получил лучшие результаты.
5 Оценка воздействия и опасности
При оценке рекомендательных систем решающее значение имеют две основные цели оценки: производительность и функциональность системы, а также то, вызывает ли она проблемы с безопасностью и социальный вред.
5.1 Оценка воздействия в автономном режиме
точность Обычно используемые метрики для задач распознавания: Recall@K, точность@K, NDCG@K, AUC, ROC, RMSE, MAE и т. д. Для задач генерации вы можете учиться на технических индикаторах НЛП. Например, BLEU широко используется в машинном переводе и может использоваться для оценки объяснений, создания комментариев и рекомендаций по диалогу. ROUGE часто используется для оценки сводок, созданных компьютером, и может быть полезен при интерпретации или проверке сводок.
Вычислительная эффективность Из-за вычислительной нагрузки оцените Вычислительную Эффективность имеет решающее значение для выработки рекомендаций. Модель (либо для обучения, либо для вывода). Эта область ждет исследований.
Тестовый тест Многие существующие наборы эталонных данных для моделей дискриминационных рекомендаций по-прежнему полезны при создании моделей рекомендаций, например Movielens, Amazon Reviews、Yelp Вызов, Last.fm и Книга Пересечение, но сфера его применения очень узка. Некоторые недавние наборы данных, такие как ReDial и INSPIRED — полезные наборы данных для рекомендаций сеансов. Для сообщества рекомендаций разработка новых критериев по-прежнему требует исследований.
5.2 Онлайн и продольная оценка
Автономные эксперименты могут не дать точных результатов из-за взаимозависимости различных моделей, используемых в системе, и других факторов. Таким образом, эксперименты A/B помогают понять производительность модели по нескольким осям в реальных условиях. Помимо краткосрочного влияния на вовлеченность и удовлетворенность, платформы также хотят понять долгосрочное влияние. Это можно измерить с помощью бизнес-показателей, таких как доход и вовлеченность (затраченное время, коэффициенты конверсии и т. д.). В то же время для отражения влияния на пользователей можно использовать несколько индикаторов, таких как ежедневная/ежемесячная активность пользователей, настроения пользователей, безопасность, опасности и т. д.
5.3 Оценка сеанса
BLEU и хаос — полезные метрики для оценки диалога, которые необходимо заменить метриками, специфичными для задачи (например, отзыв) или метриками, специфичными для цели (например, измерение разнообразия ответов). Для оценки и оценки можно использовать большие языковые модели, но окончательным выбором обычно является ручная оценка. Наборы инструментов, такие как CRSLab, упрощают создание и оценку диалоговых моделей. Однако во многих случаях промышленного использования отсутствие маркированных данных затрудняет оценку.
5.4 Оценка опасностей
Милано и др. предложили шесть категорий вреда, связанного с системами рекомендаций: контент; нарушение конфиденциальности и неправомерное использование данных; угрозы человеческой автономии, прозрачности и подотчетности; вредные социальные последствия, такие как пузыри фильтров, поляризация и справедливость; . Кроме того, системы рекомендаций, основанные на генеративных моделях, могут создать новые проблемы:
- Модель большого языка использует иностранные знания,Представлены различные источники предвзятости,и их нелегко уловить существующими методами оценки.
- Воздействие на окружающую среду усиливается.
- Автоматизация создания контента и управления им может привести к вытеснению работников в таких отраслях, как журналистика, писательское мастерство и модерация контента, что приведет к социальным и экономическим потрясениям.
5.5 Комплексная оценка
Как упоминалось выше, важно тщательно оценить офлайн-метрики, онлайн-производительность и опасности рекомендательной системы. Более того, разные заинтересованные стороны (например, владельцы и пользователи платформы) могут использовать разные методы оценки. Учитывая сложность оценки Gen-RecSys, необходимо дальнейшее изучение механизма ее оценки.
6 Резюме и будущие направления
Хотя в этой статье освещаются многие направления будущей работы, особенно важны следующие проблемы и возможности Gen-RecSys:
- Тряпка. Включает: объединение данных из нескольких источников.,Комплексное обучение генератору ретриверов,и исследование альтернатив генеративного переупорядочения.
- Модель большого языка с расширенными инструментами. Основное внимание уделяется большому языку, управляемому моделью диалогового управления.、Рекомендательный модуль、внешний мыслитель、Архитектурное проектирование ретриверов и других инструментов,Особенно методы активной разговорной рекомендации.
- Персонализированная генерация контента. Например, виртуальный опыт ношения позволяет пользователям видеть эффект рекомендуемой одежды или аксессуаров на верхнюю часть тела, что повышает удовлетворенность клиентов и снижает вероятность возврата.
- Тестирование красной команды. Помимо стандартных оценок,Реальные генеративные системные рекомендации должны будут пройти тестирование красной команды (т. е. состязательные атаки) перед развертыванием.,для того, чтобысистема Наконечник для инъекции、Надежность、Проверка согласованности и другие факторы для стресс-тестирования.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
