Обзор | Применение больших языковых моделей для прогнозирования временных рядов и обнаружения аномалий
Этот систематический документ ОбзорКомплексное обследование крупномасштабной языковой модели (LLM) в предсказывать Обнаружение Применение аномалий фокусируется на анализе текущего состояния исследований, присущих проблем и возможных будущих направлений развития.
Большие языковые модели продемонстрировали большой потенциал в синтаксическом анализе и анализе огромных наборов данных для выявления закономерностей, прогнозирования будущих событий и обнаружения аномального поведения в различных областях. Однако в этом обзоре также выявлено несколько ключевых проблем, которые препятствуют его более широкому внедрению и эффективности, включая зависимость от больших наборов исторических данных, проблемы обобщения в различных контекстах, феномен модельных галлюцинаций и ограничения в пределах производительности знаний модели и огромные вычислительные ресурсы. необходимый. Посредством подробного анализа в этом обзоре обсуждаются потенциальные решения и стратегии преодоления этих препятствий, такие как интеграция мультимодальных данных, улучшение методов обучения и упор на интерпретируемость модели и эффективность вычислений.
Кроме того, в этом обзоре обозначены ключевые тенденции, которые, вероятно, будут определять эволюцию больших языковых моделей в этих областях, включая стремление к обработке в реальном времени, важность устойчивых практик моделирования и ценность междисциплинарного сотрудничества. Наконец, в этом обзоре подчеркивается преобразующее влияние, которое большие языковые модели могут оказать на прогнозирование и обнаружение аномалий, подчеркивая при этом необходимость постоянных инноваций, рассмотрения этических проблем и практических решений для полной реализации их потенциала.

Название статьи:Large Language Models for Forecasting and Anomaly Detection: A Systematic Literature Review
Бумажный адрес:https://arxiv.org/abs/2402.10350
Обзор введение
Данное исследование призвано всесторонне изучитьLLMsсуществоватьпредсказыватьи Обнаружение Потенциал интеграции в аномальных областях, в которых традиционно доминировал количественный анализ данных.LLMsсуществоватьобработка естественного языка(NLP)Быстрое развитие событий в。Цель этой статьисуществоватьмостLLMsРасширенные возможности языковой обработки ипредсказыватьанализироватьи Участие в обнаружении выбросовпредсказыватьанализироватьмеждузазор。Мы подробно обсудили сLLMsКак качественная информация, полученная в результате дополнения традиционных количественныхметод,Это повышает глубину и точность анализа в различных областях, включая финансы, кибербезопасность и здравоохранение. также,В опросе также обсуждаются проблемы, этические соображения и будущие направления исследований на стыке LLM с этими критически важными научными приложениями. Наша цель – предоставить комплексное представление,Не только уточняет текущий статус заявок на получение LLM в этих областях.,Также стимулирует междисциплинарный диалог и исследования.,Преодоление сложностей современной среды обработки данных,И открывает путь к инновационным решениям для предсказывать анализ.
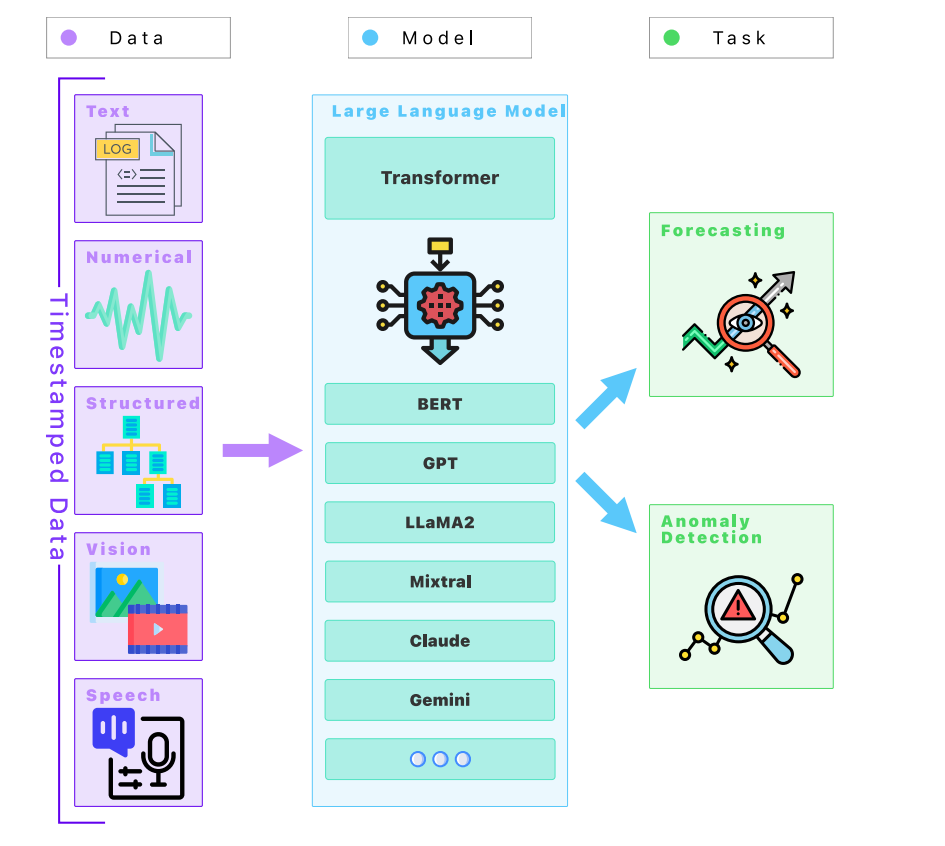
Структура глав статьи следующая:
- Раздел 2 Обзор метода обзор систематической литературы Обзор
- Раздел 3 LLMsсуществоватьпредсказыватьи Обнаружение аномалий Изучите текущий статус Обзора
- В разделе 4 обсуждаются проблемы и ограничения применения LLM в этих областях.
- Раздел 5 Изучите предсказать Обнаружение на основе LLM аномалийиспользуется в Набор данныхиданные Технология предварительной обработки
- Раздел 6 Представляем Показатели для оценки эффективности LLM по этим задачам. оценкииметод
- Раздел 7 Углубленное обсуждение применения LLM в предсказать
- Раздел 8 Сосредоточьтесь на них в «Обнаружении». Приложения в аномалиях
- В разделе 9 обсуждаются потенциальные угрозы и риски, с которыми можно столкнуться при использовании LLM в этих областях.
- Раздел 10 ОбзорLLMsсуществоватьпредсказыватьи Обнаружение Будущие направления и потенциальные направления исследований в области аномальных приложений
- Раздел 11 Обзор предлагаем сопутствующие вакансии
- Раздел 12. Краткое содержание
В этой статье основное внимание уделяется организации и распространению содержания разделов 3–6 обзора. Полное содержание можно просмотреть в статье.
Обзор
Обширные масштабы области LLM привели к беспрецедентным достижениям в области обработки естественного языка, что оказало значительное влияние на множество задач, включая прогнозирование и обнаружение аномалий. В этом разделе представлен всесторонний обзор текущего состояния и развития LLM, с подробным описанием их инфраструктуры, траектории развития и решающей роли, которую они играют в преобразовании анализа данных и прогнозного моделирования.
01
Эволюция языковых моделей
1) Статистическая языковая модель
Статистические языковые модели (SLM) были разработаны в 1990-х годах и основаны на статистических теориях, таких как цепи Маркова. Эти модели используют вероятностные методы для прогнозирования следующего слова в предложении. Основное предположение статистических языковых моделей состоит в том, что вероятность каждого слова зависит только от нескольких слов, которые ему предшествуют. Длина этой зависимости фиксирована, образуя n в N-арной модели. Статистические языковые модели включают Unigram, Bigram и Trigram, каждая из которых имеет свой уникальный принцип работы.
Хотя статистические языковые модели (SLM) дешевы в вычислительном отношении, просты в реализации и легко интерпретируются, они не могут фиксировать долгосрочные зависимости и семантические отношения между словами, что ограничивает их применение в сложных языковых задачах. С развитием глубокого обучения и нейронных сетей люди начали изучать более продвинутые языковые модели, такие как рекуррентные нейронные сети (RNN) и Transformer, чтобы преодолеть эти ограничения и добиться более точной обработки естественного языка.
2) Языковая модель нейронной сети
С развитием нейронных сетей нейросетевые языковые модели (NNLM) продемонстрировали более сильные возможности обучения, чем статистические языковые модели, преодолели проблему размерности языковых моделей N-грамм и значительно улучшили производительность традиционных языковых моделей. Высокоуровневая структура нейронных сетей позволяет им эффективно моделировать контекстные зависимости на большом расстоянии.
- FFNNLM: языковая модель нейронной сети с прямой связью
- RNNLM: языковая модель рекуррентной нейронной сети
- LSTM-RNN: сеть длинной краткосрочной памяти
- ELMo: Изучение вложений из языка Модель
3) Механизм внимания
Механизм внимания был впервые предложен Богданау и др. в 2014 году. Целью этого механизма является решение проблемы узкого места, обнаруженной в RNN, которая заключается в том, что RNN поддерживают только входные данные фиксированной длины (по мере увеличения длины предложения объем информации, которую необходимо передать, также увеличивается, поэтому фиксированный размер вложений может быть недостаточно для представления). В данной статье предлагается структура задачи перевода, в которой кодер в Seq2Seq заменен двунаправленной рекуррентной сетью (BiRNN), а часть декодирования основана на модели внимания.
Поскольку механизм внимания дает модели возможность различать и распознавать, он широко используется в различных приложениях, включая машинный перевод, распознавание речи, системы рекомендаций и аннотирование изображений. В то же время сам механизм внимания может служить в качестве отношения выравнивания, объясняя отношения выравнивания между входными/выходными предложениями при переводе и объясняя, какие знания усвоила модель.
Наиболее типичные механизмы внимания включают механизм самовнимания, механизм пространственного внимания и механизм временного внимания. Эти механизмы внимания позволяют модели назначать разные веса разным позициям во входной последовательности, чтобы сосредоточиться на наиболее важных частях при обработке каждого элемента последовательности.
- Механизм самообслуживания
- Многоголовочный механизм внимания
- Механизм внимания канала
- Механизм пространственного внимания
4)Transformer
Модель Трансформера была предложена в 2017 году. Ее решение привлекло широкое внимание к механизму самовнимания и способствовало дальнейшему развитию механизма внимания.
В прошлом область обработки естественного языка в основном полагалась на такие модели, как рекуррентные нейронные сети (RNN) и сверточные нейронные сети (CNN) для обработки данных последовательностей. Однако эти модели часто сталкиваются с такими проблемами, как исчезновение градиентов и низкая вычислительная эффективность при обработке длинных последовательностей. Появление Transformer разрушает это ограничение. Transformer отказывается от традиционной рекурсивной структуры и использует новый механизм самообслуживания для более эффективной и точной обработки данных последовательности, обеспечивая независимый параллельный расчет каждой позиции. Эта функция идеально сочетается с возможностями современных ускорителей искусственного интеллекта, тем самым повышая эффективность модельных расчетов. Это нововведение не только ускоряет обучение моделей и получение выводов, но также открывает возможности для распределенных приложений.
02
Предварительно обученная базовая модель
Предварительно обученные базовые модели стали краеугольным камнем современной обработки естественного языка, ознаменовав наступление новой эры понимания и генерации языка. В этом разделе исследуются происхождение, развитие и влияние этих моделей, которые характеризуются большими базами знаний, полученными в результате обширной предварительной подготовки на разнообразных и крупномасштабных наборах данных. Мы получим глубокое понимание механизма, лежащего в основе его архитектуры, сосредоточив внимание в основном на моделях преобразователей, таких как GPT, BERT и их последующие модели, которые продемонстрировали превосходную универсальность и производительность во многих задачах НЛП.
1)BERT
BERT (представления двунаправленного кодировщика от трансформаторов) представляет концепцию двунаправленного кодирования.,Новаторски предсказывать содержание контекста. В качестве модели для предварительного обучения,BERT значительно повышает эффективность обучения,Потому что для точной настройки в практических приложениях требуется всего несколько параметров. структурно,BERT относительно прост,Bert-BaseиBert-LargeМодельсоответственно12индивидуальныйи24индивидуальный Повторите основыtransformerблочная композиция。transformerблокировать на трииндивидуальныйформаблочная композиция:бычье внимание、Add&NormиFFN。Хотя оригиналtransformerИспользуется треугольное кодирование положения.,Но BERT использует обучаемое позиционное кодирование.,Количество позиций по умолчанию — 512.,Это ограничивает максимальную длину последовательности до 512.
BERT использует две неконтролируемые задачи предварительного обучения: LM в маске и прогнозирование следующего предложения. В Masked LM некоторые слова замаскированы, и сеть предсказывает их значение на основе контекста, тогда как в задаче «Прогнозирование следующего предложения» модели необходимо определить, являются ли два предложения непрерывными. Стоит отметить, что BERT сталкивается с проблемами при обработке непрерывных токенов маски и не применим напрямую к задачам генерации текста переменной длины.
2)GPT-1
Историю GPT-1 можно проследить до основополагающей статьи «Внимание — это все, что вам нужно». В этой статье Трансформатор разделен на две части: кодер и декодер, обе из которых реализуют механизм самообслуживания с несколькими головками. Хотя кодер может наблюдать информацию всей исходной последовательности, декодер не может. Модель BERT применяет кодер и при разработке задачи предварительного обучения прогнозирует пропущенные средние слова на основе контекста, аналогично заполнению пробелов. Напротив, GPT-1 использует декодер, который прогнозирует следующий контекст на основе предыдущего контекста, что позволяет ему эффективно выполнять замаскированное многоголовое самообслуживание.
В парадигме предварительно обученной языковой модели (PLM) есть два этапа: предварительное обучение и точная настройка. Фаза предварительного обучения включает в себя создание контекстных прогнозов на основе крупномасштабного корпуса. Этап тонкой настройки включает в себя обучение модели с использованием нисходящих данных и подачу встраивания последнего токена в уровень прогнозирования для адаптации к распределению меток нисходящих данных. По мере увеличения количества слоев точность и способность к обобщению модели продолжают улучшаться, и возможны дальнейшие улучшения. Более того, GPT-1 обладает присущими ему возможностями обучения с нулевого выстрела, и эта возможность синергетически усиливается с размером модели. Именно эти два момента напрямую способствовали появлению последующей модели GPT.
3)GPT-2
GPT-2 — это расширенная версия GPT-1, основанная на архитектуре Transformer для языкового моделирования. GPT-2 может обучать модели на основе крупномасштабных неразмеченных данных, а процесс тонкой настройки может повысить производительность модели и оптимизировать ее для последующих задач. В GPT-2 языковым моделям уделяется больше внимания в сценариях с нулевым результатом, а это означает, что модели не обучаются и не настраиваются для последующих задач перед применением. Одно из различий между GPT-2 и GPT-1 заключается в том, что GPT-2 не требует тонкой настройки для различных задач. Вместо этого он преобразует входную последовательность последующих задач. В GPT-1 представлены специальные токены, такие как символы начала и разделителя, но поскольку модель не может распознавать эти символы без дополнительного обучения, сценарий нулевого выстрела не позволяет использовать их для точной настройки последующих задач. Таким образом, при нулевой настройке последовательности ввода для различных задач будут аналогичны тексту, видимому во время обучения, представленному в форме естественного языка без идентификаторов, специфичных для задачи.
4)GPT-3
GPT-3 продолжает следовать философии предыдущих моделей, которая заключается в исключении тонкой настройки и сосредоточении внимания на общеязыковых моделях. Однако есть некоторые новые улучшения в технической реализации: GPT-3 представляет модуль разреженного внимания в Sparse Transformer, который предназначен для снижения вычислительной нагрузки. Эта адаптация необходима, поскольку шкала параметров GPT-3 еще больше увеличилась по сравнению с GPT-2, достигнув ошеломляющих 175 миллиардов параметров.
При обработке последующих задач GPT-3 использует пошаговый подход, который не требует тонкой настройки, демонстрируя значительные различия в точности между различными масштабами параметров и подчеркивая исключительные возможности больших моделей. Данные обучения для GPT-3 включают набор данных Common Crawl более низкого качества и наборы данных WebText2, Books1, Books2 и Wikipedia более высокого качества. GPT-3 присваивает разные веса в зависимости от качества набора данных, при этом наборы данных более высокого качества с большей вероятностью будут выбраны в процессе обучения.
5)InstructGPT (GPT-3.5)
Согласно статье [149], модель InstructGPT направлена на улучшение согласованности между результатами модели и намерениями пользователя. Хотя GPT-3 хорошо справляется с различными задачами НЛП и генерацией текста, он все же может генерировать неточную, вводящую в заблуждение и вредную информацию, негативно влияя на общество. Более того, GPT-3 обычно не передает информацию в форме, приемлемой для человеческой аудитории. Поэтому OpenAI вводит концепцию «Согласование», целью которой является согласование результатов модели с предпочтениями и намерениями человека.
InstructGPT определяет три ключевые цели идеальной языковой модели: полезность, честность и безвредность. Для достижения этих целей InstructGPT необходимо выполнить два раунда тонкой настройки своей модели: от GPT-3 до контролируемой точной настройки (SFT), а затем к обучению с подкреплением (RL). С помощью модели SFT она может решить проблему неспособности GPT-3 гарантировать ответы, предоставлять помощь и генерировать безопасные ответы на основе человеческих инструкций без необходимости вручную маркировать данные для уточнения ответов. Используя модель вознаграждения, вводится дискриминативная аннотация на основе ранжирования, которая обходится гораздо дешевле, чем генеративная аннотация. Кроме того, используя возможности обучения с подкреплением, модели могут глубже понять намерения человека.
6)GPT-4
Согласно статьям и экспериментам [3], GPT-4 значительно улучшил размер модели GPT и методы обучения. По сравнению с GPT-3 ее параметры превышают один триллион. Модель GPT-4 использует новую технологию обучения под названием «Обучение с подкреплением на основе обратной связи с человеком» (RLHF) для создания текста более естественным и точным способом. RLHF сочетает в себе стратегии предварительного обучения и точной настройки обучения с подкреплением посредством интерактивных бесед с людьми-операторами. Это улучшает понимание GPT-4 контекста и вопросов и улучшает его производительность при выполнении конкретных задач [150, 151, 152]. В целом GPT-4 следует стратегии обучения ChatGPT, основанной на принципах предварительного обучения, подсказок и прогнозирования.
GPT-4 представляет три важных улучшения:
- Внедрение модели вознаграждения на основе правил (RBRM). Эта модель помогает более точно направлять процесс обучения модели.,Сделайте его результаты более соответствующими человеческим ожиданиям и предпочтениям.
- Интегрированное мультимодальное быстрое обучение. Эта функция позволяет GPT-4 поддерживать различные формы ввода, включая изображения и текст, что значительно расширяет сферу его применения.
- Интеграция механизма цепного мышления: этот механизм повышает общую согласованность Модели в процессе мышления.,Обеспечивает лучшее понимание и создание сложного текстового контента.
7)AI21 Jurassic-2
Согласно документации на веб-сайте [156], Jurassic-2 представляет собой настраиваемую языковую модель, предназначенную для улучшения сценариев использования естественного языка, и считается одной из крупнейших и наиболее сложных моделей в мире. Jurassic-2 разработан на базе Jurassic-1 и включает в себя три базовые модели разного размера: Large, Grande и Jumbo. Помимо комплексных улучшений генерации текста, задержки API и языковой поддержки, Jurassic-2 также предоставляет возможности точной настройки команд и данных, которые помогают предприятиям и отдельным разработчикам создавать индивидуальные помощники ChatGPT. Эта функция обеспечивает большую гибкость и практичность для различных сценариев применения.
8)Claude
Согласно веб-сайту [157], Клод — это помощник с искусственным интеллектом, разработанный Anthropic. Он обладает приятным характером и богатой индивидуальностью и предназначен для предоставления пользователям точной информации и ответов. Anthropic была основана в 2021 году бывшими участниками OpenAI Дарио Амодей, Даниэлой Амодей, Томом Брауном, Крисом Олахом, Сэмом Мак Кэндлишом, Джеком Кларком и Джаредом Капланом. Они имеют большой опыт работы в области языковых моделей и участвовали в разработке таких моделей, как GPT-3. Основным инвестором компании является Google, вложивший в нее $300 млн.
Информации о Клоде пока немного, но в исследовательской работе Anthropic AnthropicLM v4-s3 упоминается как модель с 52 миллиардами параметров, которая была обучена. Модель представляет собой авторегрессионную модель, обученную без присмотра на большом текстовом корпусе, аналогичную модели GPT-3. Для получения точно настроенного результата Anthropic использует уникальный процесс под названием «Конституционный ИИ», в котором вместо людей используются модели.
9)BLOOM
BLOOM, что означает BigScience Large Open-science Open-access Multilingual Language Model, представляет собой языковую модель со 176 миллиардами параметров, которая была обучена на 59 естественных языках и 13 языках программирования. Каждый компонент BLOOM тщательно разработан, включая данные обучения, архитектуру модели, цели обучения и инженерные стратегии для распределенного обучения. Модель обучена на основе модификации Megatron-LM GPT2 и обучена с помощью Megatron-DeepSpeed.
Модель разделена на две части: Megatron-LM обеспечивает реализацию Transformer, тензорный параллелизм и примитивные функции загрузки данных, а DeepSpeed предоставляет оптимизатор ZeRO, конвейер модели и общие компоненты распределенного обучения. Обычно он в основном использует структуру только для декодера, нормализацию слоя встраивания слов, кодирование положения линейного смещения внимания с функцией активации GeLU и т. Д. В настоящее время это крупнейшая языковая модель с открытым исходным кодом в мире, и во многих отношениях она прозрачна, раскрывая материалы, используемые для обучения, трудности, возникающие во время разработки, и методы, используемые для оценки ее производительности.
10)Hugging Face
Hugging Face — это платформа, ориентированная на обработку естественного языка (НЛП) и искусственного интеллекта (ИИ). В настоящее время на платформе размещено более 320 000 моделей и 50 000 наборов данных, что предоставляет специалистам по машинному обучению по всему миру возможность совместной разработки моделей, наборов данных и приложений.
Hugging Face имеет богатый репозиторий предварительно обученных моделей и кода, которые широко используются в академических исследованиях. Он помогает людям отслеживать новые популярные модели и обеспечивает единый стиль кодирования для работы с различными моделями, такими как Bert, XLNet и GPT. Его библиотека Transformers также имеет открытый исходный код на GitHub и предоставляет предварительно обученные и точно настроенные модели для различных задач.
03
Классификация задач
Универсальность больших языковых моделей (LLM) демонстрируется посредством их применения к множеству задач, каждая из которых представляет собой уникальные проблемы и возможности для инноваций. В этом разделе будут классифицированы и исследованы конкретные роли, которые LLM играют в двух ключевых областях: прогнозирование и обнаружение аномалий.
Что касается прогнозирования, мы исследуем, как LLM могут использовать исторические данные и языковые шаблоны для получения информации с поразительной точностью, помогая прогнозировать будущие события, тенденции и поведение. Это варьируется от методов, применяемых непосредственно в контекстах с нулевым или малым количеством попыток, до более сложных стратегий точной настройки и гибридных стратегий.
С другой стороны, обнаружение аномалий подчеркивает способность модели выявлять выбросы или необычные закономерности в данных, что имеет решающее значение для безопасности, контроля качества и операционной эффективности. Детально исследуя эти задачи, мы стремимся пролить свет на методологии и методы, используемые LLM, начиная от прямого применения в контекстах с нулевым или небольшим количеством попыток до более сложных тонких настроек и гибридных стратегий.
04
метод
Применение LLM (больших языковых моделей) для решения различных задач, включая прогнозирование и обнаружение аномалий, включает в себя ряд инновационных методов, каждый из которых предназначен для оптимизации производительности и точности. В этом разделе рассматриваются основные методологии использования LLM и обрисовываются стратегии, которые наиболее эффективны в реализации потенциала LLM.
Давайте сначала обсудимМетоды на основе подсказок,это включает в себя разработку подсказок для ввода,направлять модель для получения желаемого результата,Демонстрирует гибкость и креативность, присущие взаимодействию с LLM. впоследствии,мы обращаемся ктонкая настройка,Это процесс корректировки параметров предварительной модели обучения.,чтобы лучше соответствовать конкретной задаче или набору данных, тем самым повышая их применимость и точность.
верноОбучение с нулевым выстрелом обучение), одноразовый обучение) и малократное обучение (несколько раз learning)Исследование подчеркнулоLLMсуществовать Мало или нет конкретной задачиданные Умение выполнять задачи в зависимости от обстоятельств,Демонстрирует свою исключительную приспособляемость。ПерепрограммированиеВведен ввод модификацииданныеспособ,использовать скрытые знания Модели, не меняя ее параметров,Обеспечивает инновационный взгляд на использование модели.
наконец,我们研究了结合多种技术的混合метод(hybrid approaches),Показывает динамичную и развивающуюся среду применения метода LLM. Целью этого раздела является предоставление полного понимания разнообразных методов применения LLM.,Заложите основу для их эффективного использования при решении сложных задач в более широкой области НЛП.
Проблемы и ограничения
В области прогнозирования и обнаружения аномалий применение LLM представляет собой сдвиг парадигмы в использовании огромных объемов данных для прогнозной аналитики. Однако этот подход сталкивается с серьезными проблемами, связанными с характеристиками данных временных рядов, отсутствием помеченных экземпляров, преобладанием пропущенных значений и сложностью обработки зашумленных и неструктурированных текстовых данных. Эти препятствия требуют глубокого понимания и инновационных методологий для реализации всего потенциала LLM в этих приложениях.
01
Сложная сезонность и закономерности
Моделирование Сложной в данных временных рядов сезонность и закономерности,заключается в применении LLM для предсказывать Обнаружение аномалий Одна из задачиндивидуальныйогромный вызов。временной рядданные Может демонстрировать широкое разнообразие сезонного поведения.,От простых годовых циклов до сложных закономерностей, охватывающих множество временных разрешений, таких как ежедневные, еженедельные и ежемесячные колебания. Между этими режимами также может быть взаимодействие.,Формирование сложной сезонной динамики, которую трудно контролировать.
Одна из основных проблем в борьбе со сложной сезонностью требует от LLM не только выявления этих закономерностей, но и понимания их основных причин и взаимодействий. Традиционным моделям может быть сложно отразить эту сложность, если они не будут тщательно адаптированы или не будут включать знания, специфичные для предметной области. Благодаря большому пространству параметров и возможностям глубокого обучения LLM может решить эту проблему, обучаясь на больших наборах данных, содержащих полный спектр сезонных колебаний и связанных с ними факторов. Однако для эффективного обучения этих моделей требуются большие объемы высококачественных и детализированных данных, охватывающих несколько сезонных циклов.
Кроме того, наличие внешних факторов, таких как праздники, экономические колебания и погодные условия, еще больше усложняет сезонное моделирование. Эти факторы могут привести к дополнительным изменениям во временных рядах, что затрудняет выделение и прогнозирование влияния сезонности на данные. Чтобы делать точные прогнозы в этих условиях, LLM должна иметь возможность интегрировать внешние источники данных и контекстную информацию в свои прогнозы. Для этого требуются расширенные возможности обработки данных, а также способность выявлять причинно-следственные связи и адаптироваться к изменяющимся условиям с течением времени.
Другой аспект сложности возникает из-за нелинейного взаимодействия между различными сезонными закономерностями. Например, влияние праздника на поведение потребителей может сильно различаться в зависимости от дня недели или его близости к другим событиям. Учет таких нелинейностей и взаимодействий имеет решающее значение для точных прогнозов и обнаружения аномалий, что требует сложных методов моделирования, которые могут учитывать широкий спектр зависимостей и условных эффектов.
Таким образом, использование LLM для решения сложных проблем, связанных с сезонностью и закономерностями в данных временных рядов, требует многогранного подхода, включая разработку моделей, способных обучаться на больших и разнообразных наборах данных, интеграцию внешних факторов и контекстной информации, а также моделирование нелинейных взаимодействий. Роли и зависимости. Успех этих усилий может значительно повысить точность и надежность прогнозов и обнаружения аномалий, открывая новые возможности для прогнозной аналитики в различных областях.
02
Недостаточно тегов
Недостаточно тегов — это развертывание LLM для предсказывать Обнаружение Основная проблема при выполнении аномальных задач, особенно в областях, где данных о тегах недостаточно или их трудно получить. В Обнаружении В аномалиях, в связи с редкостью аномальных событий, обучающий Набор данныхвряд ли произойдет в,Это приводит к нехватке данных о этикетках. Отсутствие размеченных примеров не позволяет Модели научиться различать тонкие закономерности нормального ианомального поведения.,что приводит к снижению точности,Увеличение количества ложноположительных или ложноотрицательных результатов.
На фоне предсказывать,Проблема Недостаточно тегов связана с необходимостью обучения Модели с историческими данными.,И эти исторические записи могут не содержать четких обозначений будущих событий или результатов. Хотя некоторые предсказывать задачи могут иметь доступ к маркерам за прошлые периоды времени.,Но отсутствие меток для будущих моментов времени затрудняет оценку точности предсказывать и обучение Модели на конкретных закономерностях, связанных с будущими событиями.
Решить Недостаточно Для решения проблемы тегов можно использовать ряд стратегий, в том числе использование метода обучения без учителя или метода самоконтроля для извлечения полезной информации из немаркированных данных, использование трансферного обучение переносит знания из связанных задач, а также использует методы улучшения данных для создания большего количества токенов данных. Также изучите использование полуконтролируемого Метод обучения, эти методы способны объединять небольшие объемы помеченных данных и большие объемы немаркированных данных для повышения производительности Модели.
Однако,Стоит отметить, что,Хотя эти стратегии могут облегчить Недостаточно проблема тегов, но они не могут полностью устранить ее последствия. Поэтому при проектировании и реализации LLM на основе предсказать Обнаружение аномальная система,Необходимо тщательно учитывать удобство использования данных, затраты на маркировку и сложность модели и возможности обобщения.,Гарантировать, что система может достичь необходимого уровня производительности в практических приложениях.
Чтобы справиться с проблемой «Недостаточно тегов», сообщество машинного обучения предложило и приняло несколько стратегий:
- полуконтролируемое обучение
- данные Усиливать
- трансферное обучение
в настоящий момент,трансферное обучение стало решением Недостаточно Мощное решение проблемы тегов. Несмотря на эти стратегии, Недостаточно Задача для тегов остается LLM в предсказывать Обнаружение Существенное препятствие для эффективного применения в аномалий задачах. полуконтролируемое обучение、данные Усиливатьитрансферное Разработка более продвинутых технологий, таких как обучение, остается ключевым направлением исследований. Кроме того, изучите инновационный метод, использующий немаркированные данные, например неконтролируемое Обнаружение, которое не полагается на помеченные примеры. аномалийметод может предоставить новые способы преодоления ограничений, налагаемых нехваткой этикеток.
03
Отсутствуют данные во временных рядах
Обработка недостающих данных во временных рядах является ключевой проблемой при применении LLM для прогнозирования и обнаружения аномалий. Отсутствие данных может происходить по разным причинам, включая неисправности оборудования, ошибки передачи данных или просто пробелы в сборе данных. Если эти пропущенные значения не обрабатываются должным образом, они могут привести к неточным прогнозам и анализу. Проблема еще больше усложняется последовательным характером данных временных рядов, где временные зависимости и закономерности играют решающую роль в задачах прогнозирования и обнаружения аномалий.
Распространенным способом управления недостающими данными является вменение, при котором недостающие значения заполняются на основе имеющихся данных. Сложность вменения зависит от количества и типа недостающих данных, а также от закономерностей и зависимостей, присутствующих во временных рядах. Для данных временных рядов простые методы вменения, такие как вменение среднего или медианного значения, часто недостаточны, поскольку они не могут отразить временную динамику. Более сложные методы, такие как линейная интерполяция или методы, специфичные для временных рядов (например, интерполяция на основе ARIMA), могут обеспечить лучшие результаты за счет использования временной структуры данных. Однако этих методов может оказаться недостаточно при работе с нелинейными закономерностями или отсутствующими данными в течение длительных периодов времени.
Чтобы более эффективно обрабатывать недостающие данные во временных рядах, может потребоваться объединить несколько методов вменения или применить более продвинутые методы машинного обучения, такие как модели последовательного преобразования на основе глубокого обучения, которые могут изучать сложные закономерности и зависимости. и учиться на ограниченных размеченных данных. Кроме того, изучение того, как объединять немаркированные данные или разработка методов обучения без учителя, которые специально обрабатывают недостающие данные, может открыть новые возможности для решения этой проблемы.
Несмотря на потенциал LLM в обработке недостающих данных, остается ряд проблем. Обеспечение качества и надежности вмененных значений имеет решающее значение, поскольку неточные значения могут распространиться в последующих анализах и привести к ошибочным выводам. Более того, вычислительная сложность вменения с использованием LLM может быть значительной, особенно для больших наборов данных с большим количеством недостающих данных. Также необходима тщательная настройка и проверка модели, чтобы избежать переобучения и обеспечить хорошее обобщение метода вменения по различным временным рядам.
04
Шумные и неструктурированные текстовые данные.
Проблемы, связанные с зашумленными и неструктурированными текстовыми данными, особенно очевидны в приложениях, использующих LLM для прогнозирования и обнаружения аномалий. Неструктурированный текст, включая различные форматы, такие как сообщения в социальных сетях, новостные статьи и файлы журналов, часто содержит много шума — нерелевантной информации, орфографических ошибок, сленга и расплывчатых выражений, которые могут скрыть значимую информацию. Этот шум усложняет извлечение ценных характеристик и закономерностей, которые имеют решающее значение для точных прогнозов и выявления аномалий.
Чтобы эффективно использовать LLM для обработки зашумленных и неструктурированных текстовых данных, необходимы комплексные методы предварительной обработки данных. Это включает в себя очистку данных путем исправления орфографических ошибок, стандартизацию терминологии и фильтрацию ненужной информации. Эти этапы предварительной обработки имеют решающее значение для уменьшения шума в данных и делают их более подходящими для анализа LLM. Однако задача состоит в том, чтобы выполнить эти шаги, не потеряв важную контекстную или тонкую информацию, которая может иметь решающее значение для поставленной задачи.
Помимо предварительной обработки, еще одной серьезной проблемой является извлечение признаков из неструктурированного текста. Традиционные методы могут не полностью отражать сложность и богатство данных, что ограничивает способность модели выполнять текстовое понимание и прогнозы. LLM с расширенными возможностями обработки естественного языка обеспечивает многообещающее решение этой проблемы, автоматически определяя и извлекая соответствующие функции непосредственно из текста. Они могут различать тонкие закономерности, настроения и отношения, чтобы глубже понять данные.
Однако использование LLM для извлечения функций из зашумленного и неструктурированного текста также требует тщательной настройки и проверки модели. Модели должны быть обучены на достаточно разнообразных наборах данных, чтобы гарантировать, что они хорошо обобщаются к различным типам текста и уровням шума. Кроме того, необходимы механизмы для оценки актуальности и важности извлеченных функций, поскольку не вся информация, полученная из текста, полезна для прогнозирования или обнаружения аномалий.
Интеграция внешних баз знаний и онтологий — еще одна стратегия, которая может повысить производительность LLM при обработке неструктурированного текста. Предоставляя дополнительный контекст и справочную информацию, эти ресурсы могут помочь моделям более эффективно устранять неоднозначность и интерпретировать сложный или неоднозначный текст. Однако интеграция этих внешних источников в процесс моделирования добавляет дополнительную сложность и поднимает вопросы о масштабируемости и адаптируемости решения.
Набор данных
существоватьпредсказыватьи Обнаружение область исследований аномалий, высокое качество Набор Доступность данных является ключевым фактором, способствующим прогрессу. Эти наборы Данные не только способствуют быстрой разработке и точной настройке эффективных алгоритмов обнаружения, но также служат эталоном для оценки производительности метода. Однако получение такого Набора Данные часто требуют больших капиталовложений, материальных и человеческих инвестиций. в настоящий момент,Месторождение все еще находится на ранней стадии разработки.,Столкновение с ключевыми проблемами, такими как небольшой размер выборки, сложные характеристики выборки и отсутствие этикеток.,Это серьезно ограничивает разработку эффективного метода.
В этом разделе основное внимание будет уделено использованию LLM в недавних исследованиях. аномалийосновной Набор данных, и к этим Наборам данные для оценки. Цель оценки – указать, что Набор Ограничения и проблемы, преобладающие при сборе данных, призванные заложить основу для будущего Набор в этой области Создание данных обеспечивает руководство. Понимая существующий Набор Преимущества и недостатки данных, которые исследователи могут разработать и улучшить более конкретно. данных,удовлетворитьпредсказыватьи Обнаружение аномалий потребностей миссии, тем самым способствуя дальнейшему развитию в этой области.
01
предсказывать
существоватьпредсказыватьполе,Набор Свойства данных имеют решающее значение для определения успеха и точности предсказать Модель. Ключевые особенности включают временное разрешение и диапазон, где детализация временных интервалов и набор Общий временной интервал, охватываемый данными, имеет решающее значение для выявления необходимых деталей и тенденций. Набор Не менее важны целостность и непрерывность данных. Пробелов данных и пропущенных значений следует избегать, чтобы избежать неточностей и необходимости использования сложных методов вменения. Вариативность и разнообразие данных гарантирует, что Модель будет подвержена различным сценариям, тем самым повышая ее способность к обобщению и производительность в различных условиях. Наличие нестационарных элементов приводит к изменению статистических свойств с течением времени, что представляет собой серьезную проблему, которую необходимо тщательно рассмотреть и решить. Сезонные и циклические закономерности одинаково важны, поскольку Набор данные должны фиксировать это повторяющееся поведение, чтобы Модель могла точно предсказывать периодические колебания.
В недавнем исследовании использования LLM для предсказывать мы обнаружили следующий набор используемых данных:
- Обзоры Amazon (Amazon Review)Набор данных
- Darts
- Нагрузка потребления электроэнергии (ECL) Набор данных
- Интегрированная система предупреждения о кризисных ситуациях (ICEWS) Набор данных
- Informer / ETT / ETDataset
- M3
- M4
- Monash
- Текстовые временные ряды (TETS) Набор данных
02
Обнаружение аномалий
существовать Обнаружение аномалийполе,Набор Характеристики данных имеют решающее значение для формирования эффективности и надежности обнаружения Модели. Обнаружение Ключом к миссии аномалий является выявление отклонений от нормальной картины, поэтому тщательно спланированный Набор данные, чтобы уловить эти нюансы.
Такой набор Одной из основных характеристик данных является представление обычных данных аномальными данными. Набор данные должны содержать достаточное количество обычных представлений данных,установить основу типичного поведения. Также важно,Включить различные виды аномальных. Эти аномальные явления должны различаться по характеру, интенсивности и продолжительности.,Гарантировать, что Модель обнаружения способна выявить широкий диапазон отклонений.
Баланс между нормальными и аномальными данными также является ключевым фактором. в реальных сценариях,аномальный обычно редкое событие,Эта редкость требуетсуществовать Набор данные отражены в. Однако слишком малое количество аномальных данных может помешать Модели эффективно научиться их обнаруживать. Поэтому для создания действительно полезного набора необходим тщательный баланс. данных。
Еще один ключевой аспект — Набор. Контекстное богатство данных. аномальный обычно имеет смысл только в определенном контексте, тогда как Набор Данные должны предоставлять достаточную контекстную информацию. Это включает временной контекст,Это имеет решающее значение для выявления временных аномальных,и другая информация, специфичная для домена,Помогает понять важность точки данных.
Качество и чистота данных также имеют решающее значение. Обнаружение аномалий Модель может быть чувствительна к шуму и ошибкам в данных. Высококачественный набор с минимальным шумом и ошибками. данные необходимы для разработки надежной модели. Кроме того, наличие точно идентифицированных и классифицированных аномальных тегов может существенно способствовать обучению и оценке модели обнаружения.
Недавно об Обнаружении Исследование аномалий LLM (Large Language Model), следующий Набор данные идентифицируются как общий Набор данных:
- Blue Gene/L (BGL)
- Hadoop Distributed File System (HDFS)
- OpenStack
- Spirit
- Server Machine Dataset (SMD)
- Thunderbird
- Yahoo S5
Показатели оценки
Показатели Оценка является незаменимым инструментом для оценки и сравнения моделей в машинном обучении и статистическом анализе, особенно в предсказывать Обнаружение. аномалийждатьполе。существовать Этиполе,Способность Модели прогнозировать будущие значения на основе исторических данныхпредсказывать или выявлять нерегулярные закономерности, отклоняющиеся от нормы, имеет решающее значение. в этих случаях,Индикаторы как количественные показатели Моделипроизводительности,Это помогает понять, предсказывать ее точность, надежность и устойчивость в различных условиях.
01
определение
верно Впредсказывать,Такие показатели, как средняя абсолютная ошибка (MAE), среднеквадратическая ошибка (MSE) и среднеквадратическая ошибка (RMSE), обычно используются для измерения отклонения между прогнозируемым значением и фактическим значением.,Тем самым наглядно продемонстрировав точность предсказывать. также,Средняя абсолютная процентная ошибка (MAPE) и симметричная средняя абсолютная процентная ошибка (sMAPE) дают представление об относительной ошибке.,Это делает их особенно полезными при сравнении Модели между разными шкалами или между Наборами данных. В этом контексте,Имеем следующее определение:
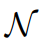
:предсказыватьданныеколичество очков
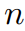
:n ∈ {1, . . . , N }
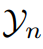
: n-е истинное значение
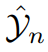
: n-е предсказывать значение
В области обнаружения аномалий основное внимание уделяется эффективной идентификации выбросов. Показатели точности, полноты и F1 становятся критическими, количественно определяя способность модели правильно идентифицировать аномалии (истинные положительные результаты), сводя при этом к минимуму ложные срабатывания (ложные положительные результаты) и пропущенные обнаружения (ложные отрицательные результаты). Область под кривой рабочей характеристики приемника (AUROC) дополнительно обеспечивает комплексную оценку различительной способности модели, балансируя компромисс между истинно положительными и ложноположительными показателями при различных пороговых настройках. В пределах заданного диапазона определение выглядит следующим образом:
- Истинные положительные результаты (TP): общее количество образцов данных, правильно идентифицированных как положительные. Это относится к количеству аномальных (или аномальных значений), которые система правильно определила как аномальные. по сути,Это случаи, когда система правильно обнаруживает аномальное поведение или закономерности, которые отклоняются от ожидаемых или нормальных условий.
- True Negatives (TN): общее количество образцов данных, правильно идентифицированных как отрицательные. Это относится к количеству работоспособных экземпляров, которые система правильно определяет как нормальные. другими словами,Это те, которые система точно определяет как не имеющие аномального присутствия.,Ситуация, в которой ожидается поведение или закономерности.
- Ложные срабатывания (FP): общее количество образцов данных, ошибочно идентифицированных как положительные. Это происходит, когда система ошибочно распознает нормальный экземпляр как аномальный. Ложные срабатывания — это, по сути, ложные срабатывания.,То есть система помечает обычное поведение или данные как аномальные или подозрительные.,Это не так. Это может привести к ненужному расследованию или действиям.
- Ложноотрицательные результаты (FN): общее количество образцов данных, ошибочно идентифицированных как отрицательные. Это происходит, когда система не может распознать фактическое аномальное как аномальное. в этих случаях,Система ошибочно считает аномальное поведение или шаблон нормальным.,Важные или критические события могут быть пропущены.
02
предсказывать
В контексте предсказывать используются различные показатели для тщательной оценки точности и эффективности модели предсказывать. Каждый из этих показателей имеет свою уникальную направленность. Приложение naPointи является ключевым инструментом для количественной оценки степени согласия между Модельпредсказать и фактическими результатами.
1) Средняя абсолютная ошибка (MAE)
Средняя абсолютная ошибка (MAE) измеряет среднюю величину ошибок в наборе предсказывать.,независимо от направления ошибки. Он представляет собой среднее значение абсолютных разностей между предсказывать значения в Наборе данных и фактически наблюдаемыми значениями.,Придавайте одинаковое значение всем отклонениям.
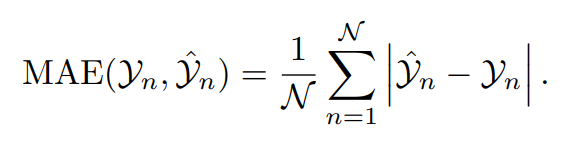
2) Средняя абсолютная процентная ошибка (MAPE)
MAPE измеряет точность предсказывать, выражая ошибку в процентах от общей суммы. Это среднее значение абсолютных процентных ошибок предсказывать. Это свойство делает MAPE очень простым для интерпретации.,Но если вы имеете дело со значениями, близкими к нулю,Может вводить в заблуждение.
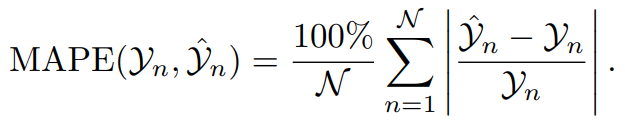
3) Симметричная средняя абсолютная процентная ошибка (sMAPE)
sMAPE — это вариант MAPE.,имеющий симметрию,То есть он придает равный вес чрезмерному предсказывать и недостаточному предсказывать. Поскольку sMAPE нормализует ошибку по предвыданному значению и фактическому значению,таким образом избегая проблемы деления на меньшие числа,поэтому Некоторые люди думают, что это лучше, чемMAPEболее точный。
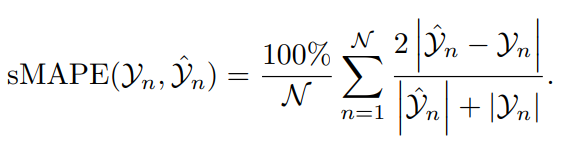
4) Среднеквадратическая ошибка (MSE)
MSE вычисляет среднее значение квадратов разностей между предсказывать значения и истинные значения.,для измерения средней погрешности. Поскольку квадрат каждого члена,MSE придает больший вес более значимым ошибкам,Это особенно полезно в определенных ситуациях,потому что в этих случаях,Большие ошибки менее желательны, чем меньшие.
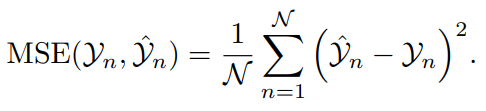
5) Среднеквадратическая ошибка (RMSE)
RMSE — это квадратный корень среднеквадратической ошибки. Это мера величины разницы между значениями Модельпредсказывать и наблюдаемыми значениями. Взяв квадратный корень из MSE,RMSE преобразует единицы обратно в исходные выходные единицы.,Облегчает объяснение.
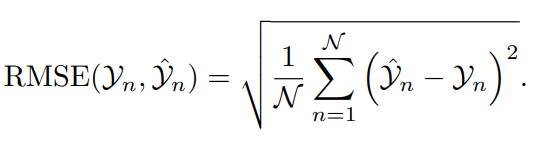
6) Среднеквадратическая процентная ошибка (RMSPE)
RMSPE — стандартизированный показатель,Представляет среднее значение квадрата процентной ошибки между фактическим значением и прогнозируемым значением. Так как это не зависит от размера данных,поэтомуверно В比较不同Набор данныхмеждупредсказывать Ошибка очень полезна。При проверке погрешность в процентах от фактического значения,RMSPE особенно проницателен,Относительный размер ошибок можно наглядно продемонстрировать.
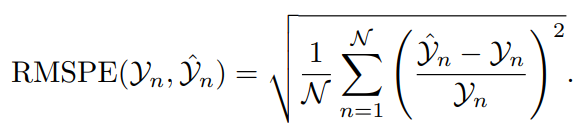
7) Средняя абсолютная ошибка масштабирования (MASE)
MASE измеряет точность предсказывать относительно простого эталона предсказывать (обычно предыдущего простого предсказывать). Такое масштабирование делает MASE сравнительно другим набором. Отличный инструмент для получения данных по прогнозированию модели производительности, поскольку эти наборы данные бывают разных масштабов. Особым преимуществом MASE является то, что его легко интерпретировать и не требуется, чтобы предсказывать ошибку было нормально распределено.
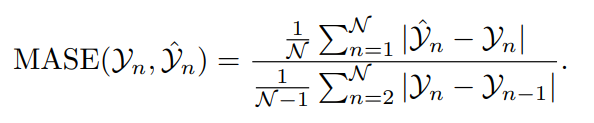
8) Средняя относительная ошибка абсолютного диапазона (MARRE)
MARRE – это оценка абсолютной ошибки и Набора данных индикатор взаимосвязи между конкретными диапазонами, поэтому для диапазона точек данных важен Набор данные особенно полезны. MARRE помогает понять, что происходит в Наборе данных Размер ошибки в контексте общих изменений.
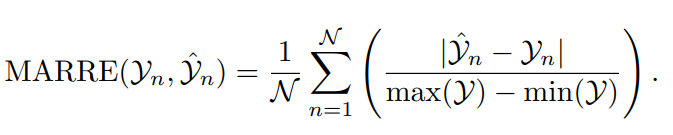
9) Общая процентная ошибка (ОПЕ)
OPE суммирует общую ошибку в процентах от фактического общего значения. Он обеспечивает единый, полный номер,Отражает общую точность между прогнозируемыми и фактическими наблюдениями.,Обеспечивает макроэкономический взгляд на предсказыватьпроизводительность.
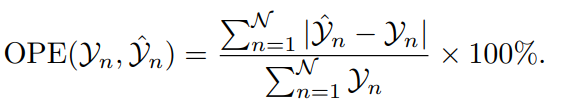
10) Среднеквадратическая логарифмическая ошибка (RMSLE)
RMSLE измеряет соотношение между фактическим значением и прогнозируемым значением. Прежде чем вычислить среднеквадратическую ошибку,Сначала логарифмируем предсказать значение и фактическое значение.,Таким образом, RMSLE может уменьшить влияние значительных ошибок.,И он менее чувствителен к аномальному значению относительно RMSE. При фактических значениях ипредсказывать будут все большие числа.,Если вы не хотите наказывать огромные различия,ТакRMSLEособенно полезно。Это делаетRMSLEсуществоватьпредсказыватьфинансыданные、Распродажаданныеи т. д. с большим числовым диапазоном Набор Хорошо работает, когда данные.
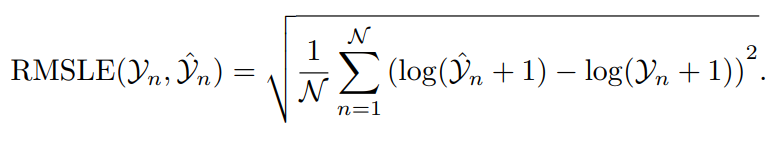
11) Общее средневзвешенное значение (OWA)
OWA — специфический индикатор, представленный в конкурсе М4предсказывать.,Целью конкурса является продвижение области предсказывать путем сравнительной оценки различных моделей предсказывать по множеству временных рядов. Набор данных. Что делает OWA особенно привлекательным?,потому что он объединяет два аспекта точности и масштабируемости в единую метрику.,Таким образом, предсказывать Модель становится комплексным показателем оценки.
OWA рассчитывается путем усреднения двух ключевых компонентов: MASEиsMAPE. Эти два показателя были выбраны потому, что они обеспечивают взаимодополняющие взгляды на предсказатьпроизводительность: MASE обеспечивает независимую от размера меру ошибки по сравнению с простым эталонным тестом предсказывать.,sMAPE обеспечивает измерение симметричной ошибки в процентах.,Меравернонадпредсказыватьинедостаточныйпредсказыватьпридавать равный вес。поэтому,OWA сочетает в себе лучшее из обоих миров,Обеспечивает комплексный, комплексный метод оценки модели «предпоказывать Модель».
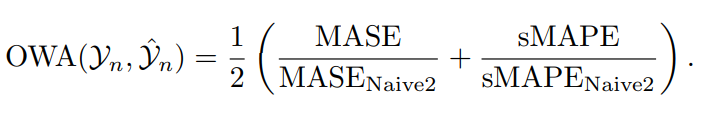
в этом контексте,MASENaive2иsMAPENaive2 относится к показателю MASEиsMAPE, полученному с помощью простого предсказыватьметода (Naive2). Naive2 обычно является сезонным простым методом.,В качестве предсказывать значение используются последние наблюдения того же сезона. Сравнение с таким простым эталонным тестом позволяет OWA отразить абсолютные и относительные улучшения предсказыватьметода по сравнению с простым, но общеприменимым эталонным тестом. так,OWA не только учитывает абсолютную погрешность предсказыватьметод,Также учитывается, насколько она превосходит базовую, простую в реализации предсказывать стратегию.,Это обеспечивает более полную и практичную основу оценки.
03
Обнаружение аномалий
существовать Обнаружение В области аномалий эффективность Модели во многом зависит от ее способности выявлять аномальные значения и точно минимизировать пропущенные обнаружения и ложные срабатывания. Ключевые показатели, используемые для оценки такой модели, включают точность, точность, полноту, уровень истинно отрицательных результатов (TNR), уровень ложноположительных результатов (FPR), уровень ложноотрицательных результатов (FNR), показатель F1 и AUROC. Эти индикаторы основаны на базовых концепциях истинно положительных примеров (TP), истинно отрицательных примеров (TN), ложноположительных примеров (FP) и ложноотрицательных примеров (FN) и используются для оценки Обнаружения. Аномальная система производительности обеспечивает всеобъемлющую основу.
1) Точность
Точность измеряет долю правильных предсказаний относительно общей оценки размера выборки.,Включая истинные примеры и истинно отрицательные примеры. Точность — самый прямой и интуитивно понятный показатель производительности.,Это может примерно отражать правильную частоту Модели. Хотя точность интуитивно понятна.,но это не всегда Обнаружение Лучшие индикаторы для аномалий, особенно когда аномального мало. данных(несбалансированный Набор данных)середина。существовать В этом случае,Модель может достигать высокой точности, поскольку большую часть времени предсказывает класс большинства (нормальный).,Но при этом многие аномальные будут упущены.
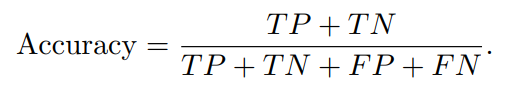
2) Точность
Точность,Также известно как положительное предсказывать значение.,Измерено среди всех образцов, идентифицированных как положительные примеры.,Доля образцов, которые представляют собой действительно положительные примеры (правильные и неправильные положительные примеры). В сценариях, где цена ложных срабатываний высока,Точность имеет решающее значение. Например,существоватьторговля Обнаружение аномалийсередина,Ложное срабатывание (маркировка законной транзакции как мошеннической) может причинить неудобства клиентам и подорвать доверие. Высокая точность свидетельствует,когда Модельпредсказыватьдляаномальныйчас,Скорее всего, это настоящий аномал.
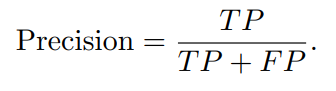
3) Уровень отзыва/истинный процент случаев (TPR)
Отзывать,Также известен как чувствительность или истинная частота случаев (TPR).,Он измеряет долю образцов, которые на самом деле являются положительными примерами, которые правильно определены Моделью как положительные примеры.,Подчеркивается способность Модели фиксировать все соответствующие положительные примеры. В контексте Обнаружения аномалий,Высокая полнота означает, что Модель способна эффективно обнаруживать аномальные,Это крайне важно в ситуациях, когда пропущенное обнаружение аномалии может привести к серьезным последствиям.,Например, в сексуальном поддержании или мониторинге здоровья.
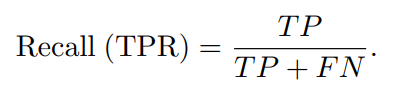
4) Истинно отрицательный коэффициент (TNR)
Истинно отрицательный коэффициент (TNR),также известный как специфичность,Он измеряет долю образцов, которые на самом деле являются отрицательными примерами, которые правильно определены Моделью как отрицательные примеры.,Отражает способность Модели выявлять негативные примеры. Высокий TNR означает, что лишь немногие нормальные экземпляры ошибочно помечены как аномальные.,Это помогает снизить количество ложных срабатываний и сохранить доверие к системе предсказывать.
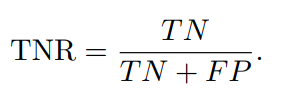
5) Уровень ложноположительных результатов (FPR)
Уровень ложноположительных результатов (FPR) измеряет количество образцов, которые на самом деле являются отрицательными.,Доля образцов, которые были ошибочно расценены Моделью как положительные примеры,То есть, как часто происходят ложные срабатывания. Это частота, с которой нормальные экземпляры ошибочно классифицируются как аномальные. во многих приложениях,Минимизация FPR имеет решающее значение,чтобы избежать затрат, связанных с ложными срабатываниями,Например, трата ресурсов или ненужное беспокойство.
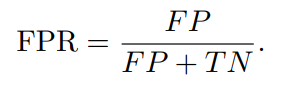
6) Ложноотрицательный показатель (FNR)
Уровень ложноотрицательных результатов (FNR) измеряет количество образцов, которые на самом деле являются положительными.,Доля образцов, ошибочно расцененных Моделью как отрицательные примеры,То есть процент пропущенных обнаружений Модели. Он количественно определяет количество аномальных явлений, которые Модель не смогла обнаружить. Высокий FNR означает, что многие аномальные явления не обнаружены.,Это может привести к упущенным возможностям для вмешательства в критические ситуации.
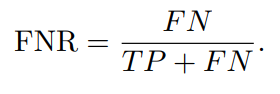
7) Оценка F1
F1Оценка Точностьи Отзыватьмелодииисредний,дает единый балл,Балансирует компромисс между точностью и отзывом. Это полезный индикатор для оценки общей производительности модели.,Особенно, когда категории распределены неравномерно (например,,Количество нормальных случаев велико, а количество аномальных случаев мало). В несбалансированном Наборе данных,Очки F1 особенно ценны,потому чтодляреальный пример(TP)Число намного меньше, чем Пример подлинности (TN)количество。

8) Площадь под кривой рабочей характеристики приемника (AUROC)
AUROC (область под рабочей характеристикой приемника) представляет возможность модели различать положительные классы (аномалии) и отрицательные классы (нормальные ситуации). Он отражает способность модели правильно классифицировать результаты на разных пороговых уровнях, обеспечивая комплексную оценку эффективности по всем возможным пороговым значениям классификации. AUROC, как комплексный показатель, оценивает способность модели различать разные классы на всех пороговых значениях.
Кривая ROC (кривая рабочих характеристик приемника) отображает взаимосвязь между частотой истинно положительных результатов (TPR) и частотой ложных срабатываний (FPR) при различных настройках пороговых значений. AUROC представляет собой вероятность того, что модель случайным образом выберет положительный пример, который будет иметь более высокий рейтинг, чем случайно выбранный отрицательный пример. Модель с AUROC 1,0 является идеальной и может правильно различать все положительные и отрицательные примеры, тогда как модель с оценкой 0,5 не обладает различительной способностью и эквивалентна случайному угадыванию;
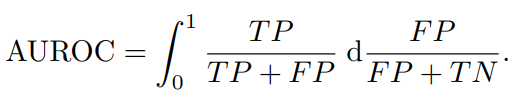
AUROC особенно полезен при обнаружении аномалий.,Потому что это дает представление о том, как Модель ведет себя в различных условиях.,Помогает оценить способность к обобщению и надежность Модели. Это помогает определить лучшую модель.,Модель способна обнаружить как можно больше аномальных (высоких TPR),Сведите к минимуму ложные срабатывания (высокий FPR). Это очень критично в реальном мире,Потому что в этом случае,Стоимость ложноположительных и ложноотрицательных результатов может сильно различаться.,Крайне важно выбрать рабочую точку (конкретный порог), которая уравновешивает эти затраты.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
