Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3
“ Запустите на своем компьютере мощный помощник с искусственным интеллектом. Он не только обладает превосходными возможностями, но и скрывает все секреты на вашем жестком диске. Интересно, как это достигается? Двигайте руками, и вы сможете выполнить излокальное LLaMA-3 за три минуты. развертывание!”
01、LLaMA-3
Недавно я экспериментировал с проектом улучшенной генерации (RAG). Я хотел попробовать перейти на более мощную модель, чтобы посмотреть, улучшится ли эффект. Я попробовал построить большую частную модель локально в качестве базовой модели. На этот раз я попробую LLama3. В следующий раз возьмем модель Qwen2 от Alibaba Tongyi Qianwen.
Еще в апреле Meta выпустила с открытым исходным кодом LLaMA-3 (Large Language Model Meta AI 3), которая превзошла передовые аналогичные модели в отрасли в нескольких ключевых тестах производительности. Она достигла общего лидерства в таких задачах, как генерация кода, и была способна выполнять сложные задачи. рассуждение, способность лучше следовать инструкциям, способность визуализировать идеи и решать многие тонкие проблемы.
Основные моменты:
- На основе более чем 15T token обучение, эквивалентное Llama 2 данныенабориз 7 более чем в два раза;
- Поддерживает длинный текст размером 8 КБ, а улучшенный токенизатор имеет словарь из 128 КБ токенов для повышения производительности;
- Самые современные показатели по широкому спектру важных показателей;
- Новые категории возможностей, включая расширенные возможности рассуждения и кодирования;
- Новые версии инструментов доверия и безопасности с Llama Guard 2, Code Shield и CyberSec Eval 2.
02. Установите Олламу
Ollama Это инструмент с открытым исходным кодом для запуска и управления большими языковыми моделями (LLM) в локальной среде. Он предоставляет разработчикам, исследователям и энтузиастам эффективную и простую в использовании платформу для быстрого экспериментирования, управления и развертывания новейших больших языковых моделей.
Технические особенности и преимущества:
- локальное развертывание:Ollama Позволяет пользователям локально запускать и запускать различные большие языки Model, такие как Llama 2、CodeLLaMA、Falcon и Mistral ждать. Это не только снижает порог использования большого языка Модельиз, но также повышает конфиденциальность и безопасность данных.
- Богатая библиотека моделей:Ollama Предоставляет предварительно созданную библиотеку из Модель для множества популярных моделей из больших языков, включая Qwen2、Llama3、Phi3 и Gemma2 ждать. Эти инструменты можно легко интегрировать в различные приложения для удовлетворения потребностей различных сценариев.
- Простой в использовании интерфейс:Ollama предоставляет что-то вроде OpenAI из API Интерфейс и интерфейс чата удобны для использования пользователями. Кроме того, оно также основано на командной Режим строкаиз запускает различные модели больших языков и обеспечивает соответствующие Python и JS SDK для простой реализации Chatbot UI。
- Настраиваемость:Ollama обладает высокой степенью настраиваемости, позволяет пользователям создавать и запускать пользовательские модели языка.
- Кроссплатформенная поддержка:Ollama поддерживать macOS、Linux и Windows (предварительная версия) и доступен на Docker Быстрая развертка. Это значительно повышает его применимость и гибкость.
Среда установки: Обычный настольный компьютер Lenovo, без графического процессора. Процесс установки не требует научного доступа в Интернет.

Официальный адрес загрузки Ollama: https://ollama.com/download. Выбирайте разные версии в зависимости от вашей операционной системы.
На Github также есть версия Docker: https://github.com/ollama/ollama.

После завершения установки проверьте версию и убедитесь, что установка прошла успешно.
ollama -v
03. Загрузите модель
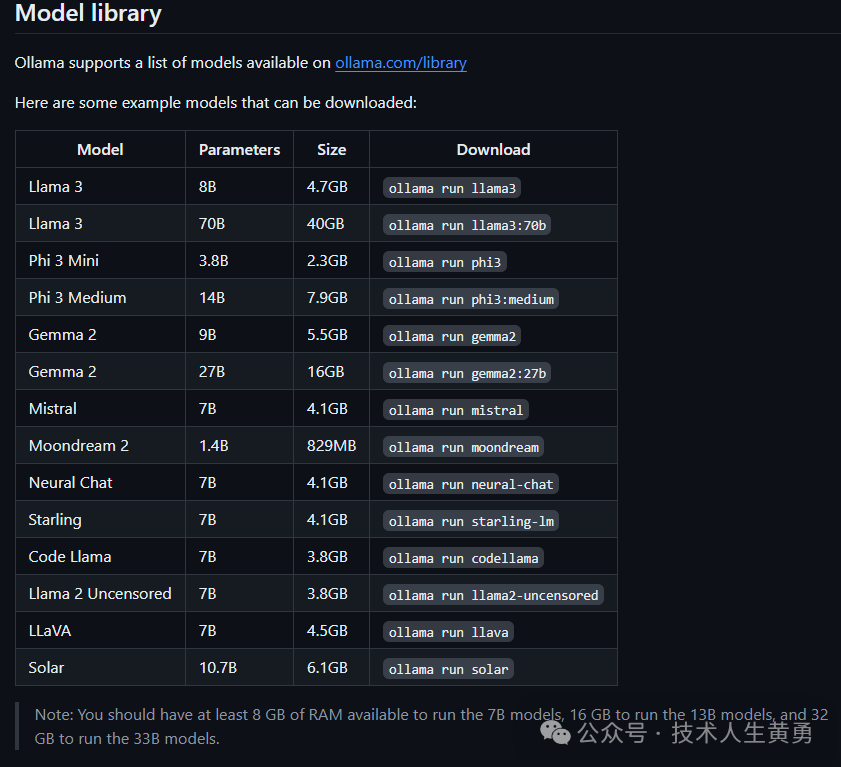
После завершения установки вы можете напрямую загрузить многие встроенные модели с открытым исходным кодом. Ниже приведены названия некоторых встроенных моделей.
Требования к памяти: не менее 8 ГБ доступной памяти для работы модели 7B, 16 ГБ для работы модели 13B и 32 ГБ для работы модели 33B.
Загрузите llama3:8b. Перед двоеточием указано название модели, а модель после двоеточия — это также размер параметра модели.
ollama pull llama3:8b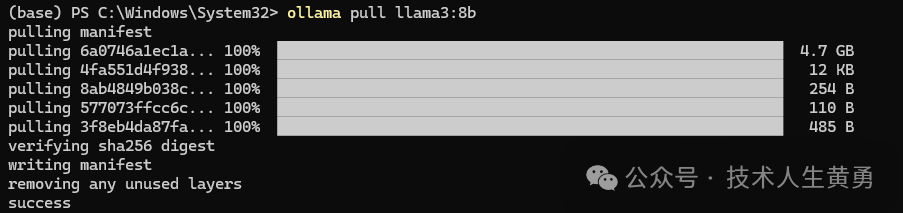
Запустите модель:
ollama run llam3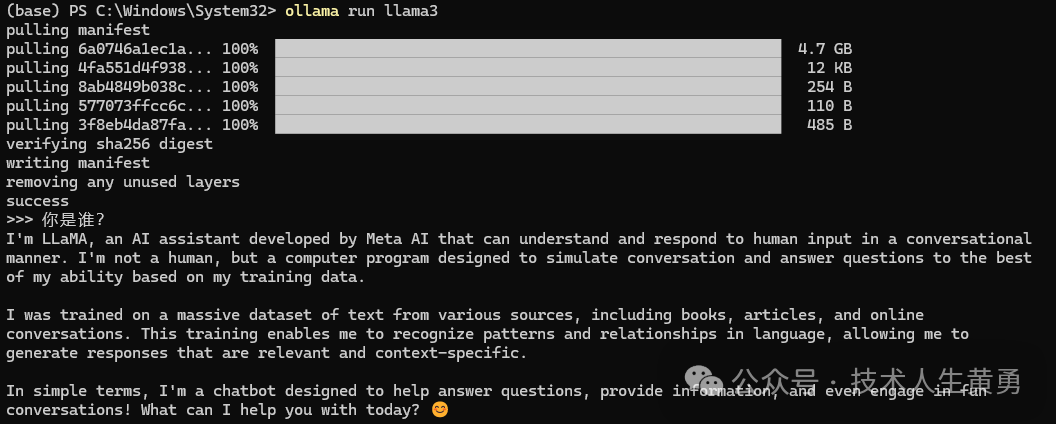
Поскольку иностранные модели по умолчанию отвечают на английском языке, вы можете указать модель, которая будет отвечать на китайском языке.
Использование командной строки, очевидно, очень неудобно. Мы используем Docker, чтобы предоставить большой модели диалоговый веб-интерфейс. Используйте следующую команду для запуска Open WebUI. Будьте осторожны, изменяя локальный путь к open-webui-data. Предварительное условие: служба Docker сначала устанавливается локально.
docker run -p 8080:8080 -e OLLAMA_BASE_URL=http://host.docker.internal:11434 --name open-webui --restart always -v open-webui-data:/DATA/ ghcr.io/open-webui/open-webui:mainПосле долгого процесса получения образа отображается интерфейс запуска.
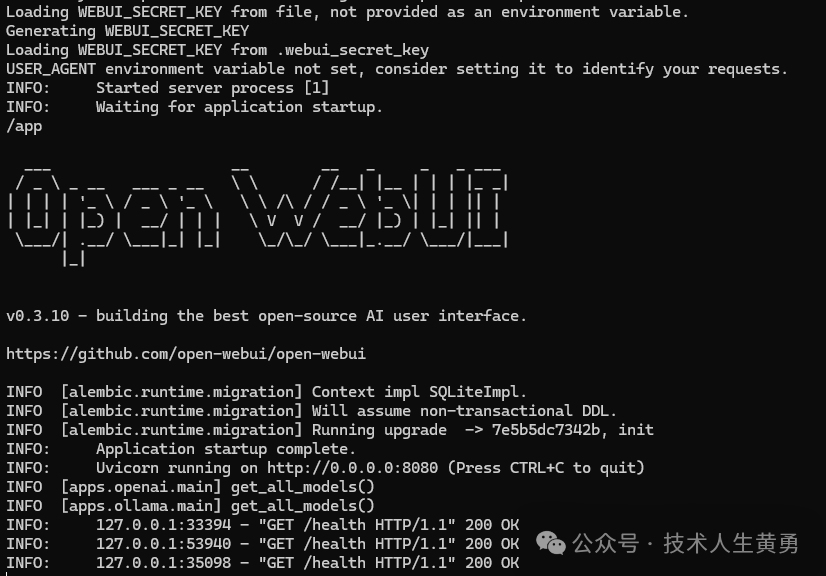
Введите http://127.0.0.1:8080 в адресную строку браузера. При первом посещении необходимо зарегистрироваться. После входа в систему вы увидите интерфейс чата, аналогичный Chat-GPT. тот, который мы только что скачали, находится в верхнем левом углу. llama3:latest.
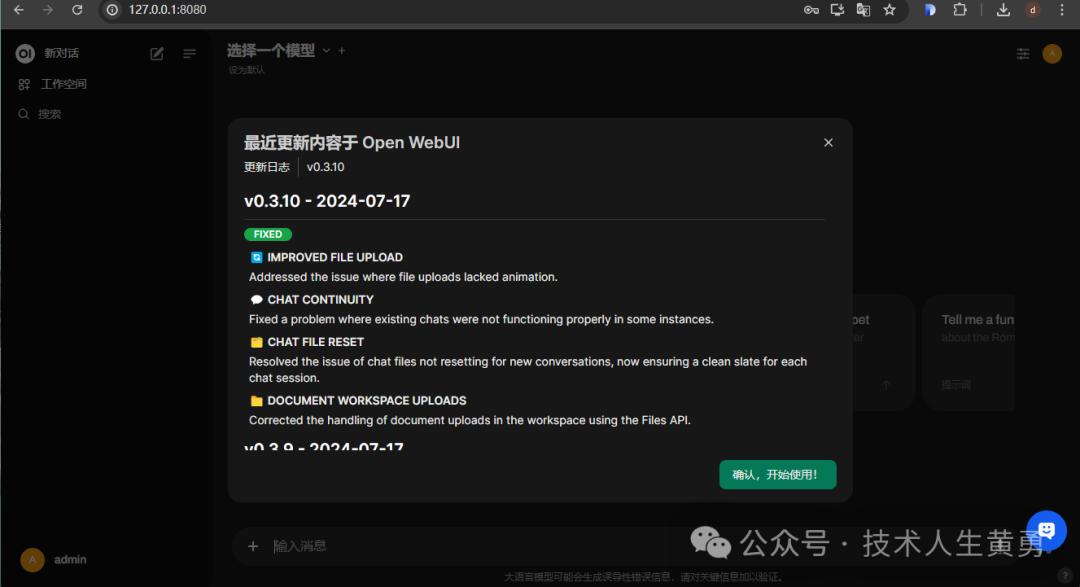
Задание одного и того же вопроса на китайском языке через веб-интерфейс избавляет от необходимости указывать большую модель для ответа на китайском языке, например взаимодействие с командной строкой.

Предоставляет услуги API для создания разговоров.
Целью создания локальной модели является использование в проекте, поэтому нам также нужен API, созданный с помощью диалога, аналогичного OpenAI. Перед его использованием нажмите «Настройки» — «Учетная запись», чтобы сгенерировать ключ API. Вы можете использовать этот ключ для вызова API.
Команда проверки скручивания из командной строки:
$ curl -X POST -H "Авторизация: ключ API носителя" -H "Тип контента: application/json" http://localhost:8080/ollama/api/generate -d '{"model":"llama3-cn :latest","stream":false,"prompt":"Кто ты? Что ты умеешь"}'
Скорость создания диалогов немного медленная. Во время самого теста вы можете видеть, как слова появляются одно за другим. Чтобы начать отвечать на приведенные выше вопросы, требуется около 1–2 секунд, и, по оценкам, это займет около 10 секунд. чтобы завершить ответ.
На данный момент у нас есть большая модель, которая не требует аппаратных ресурсов графического процессора. Содержимое разговора, данные документа и т. д. хранятся локально и принадлежат нашей частной модели.
---
Ранее рекомендовалось:
Инструкции по использованию большой модели посевов в холодном районе Бэйдахуан
Vector | График: первый график Ant с открытым исходным кодом Интерпретация проекта структуры RAG
Рекомендуйте FinGLM, проект крупной модели с открытым исходным кодом для финансового анализа.


Spring Boot: автоматическая настройка четырех артефактов
Руководство для покупателей Double Eleven: Как использовать краулерную технологию, чтобы отслеживать исторические тенденции цен и совершать рациональные покупки, не наступая на ловушку.
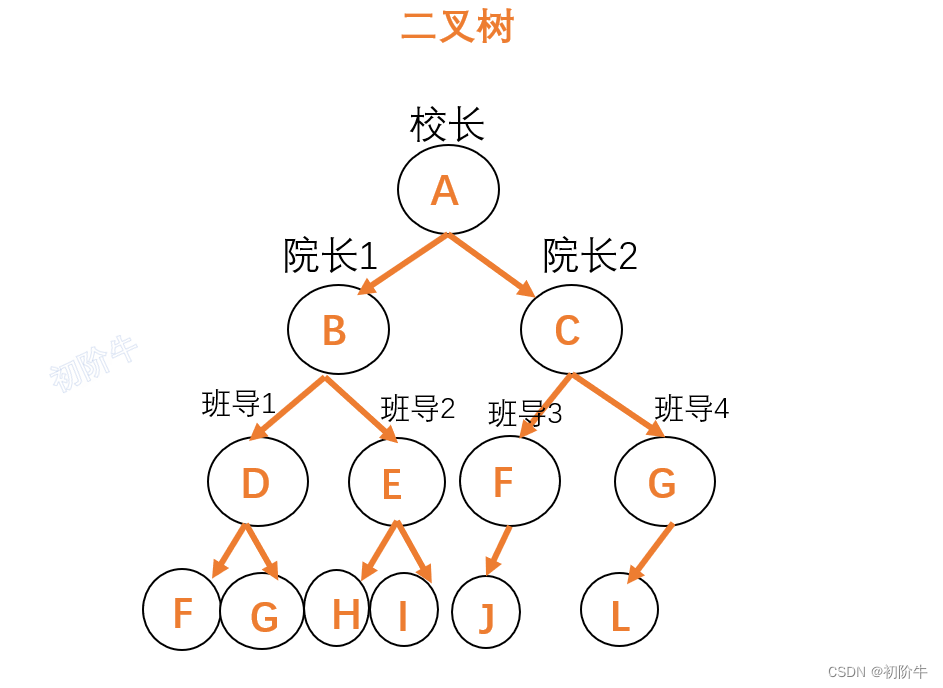
Основные операции с бинарными деревьями (как посчитать количество узлов бинарного дерева и высоту бинарного дерева)

Основы разработки серверной части FastAPI (4): ошибки документации официального сайта FastAPI, ошибки кодирования и записи важных моментов, на которые следует обратить внимание.
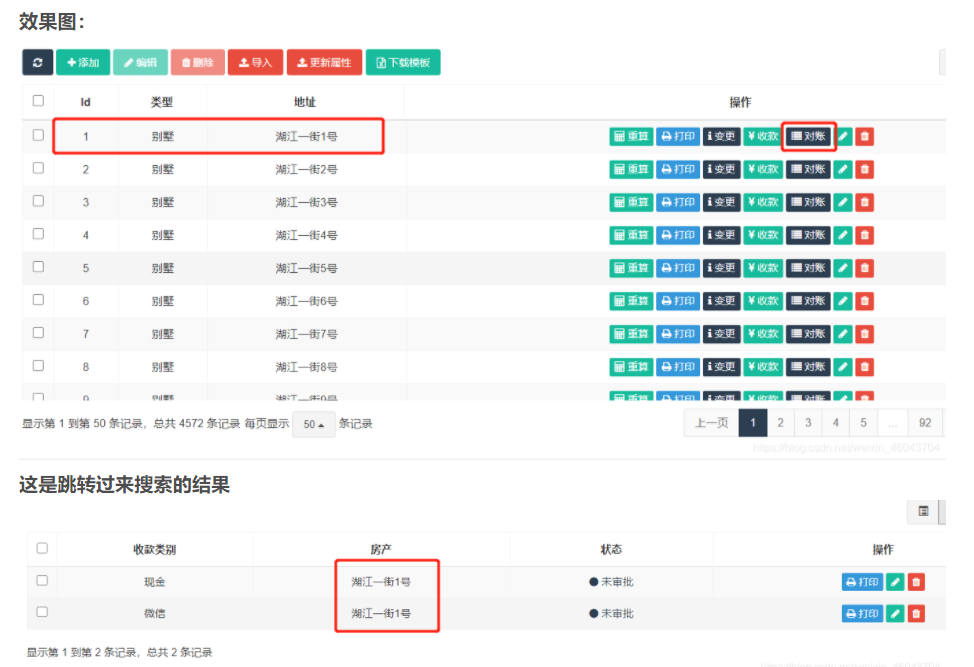
fastadmin нажимает кнопку списка, чтобы перейти на страницу с параметрами и ищет соответствующие данные

Как внедрить/получить bean-компоненты в контейнере Spring в классах, не управляемых контейнером Spring?

Весенние аннотации: подробное объяснение @ResponseBody!
Компания Huawei вступила во второй этап и готова спешить!
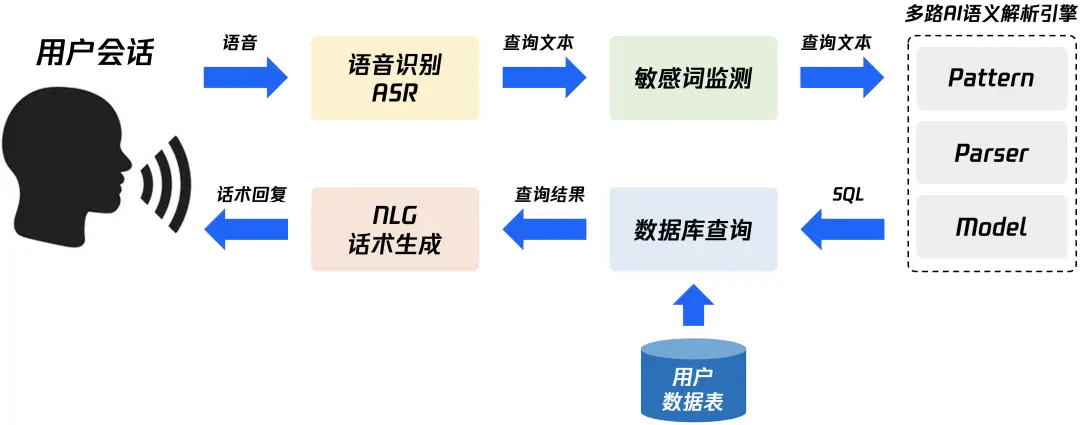
Быстро изучите в одной статье — концепцию и технологию реализации NL2SQL для передачи данных с нулевыми затратами.
Как использовать SpringBoot для интеграции EasyExcel 3.x для реализации элегантных функций импорта и экспорта Excel?

Почему транзакция не вступает в силу, когда @Transactional добавляется в частный метод?

Знание создания образов Docker: подробное объяснение команды Dockerfile.
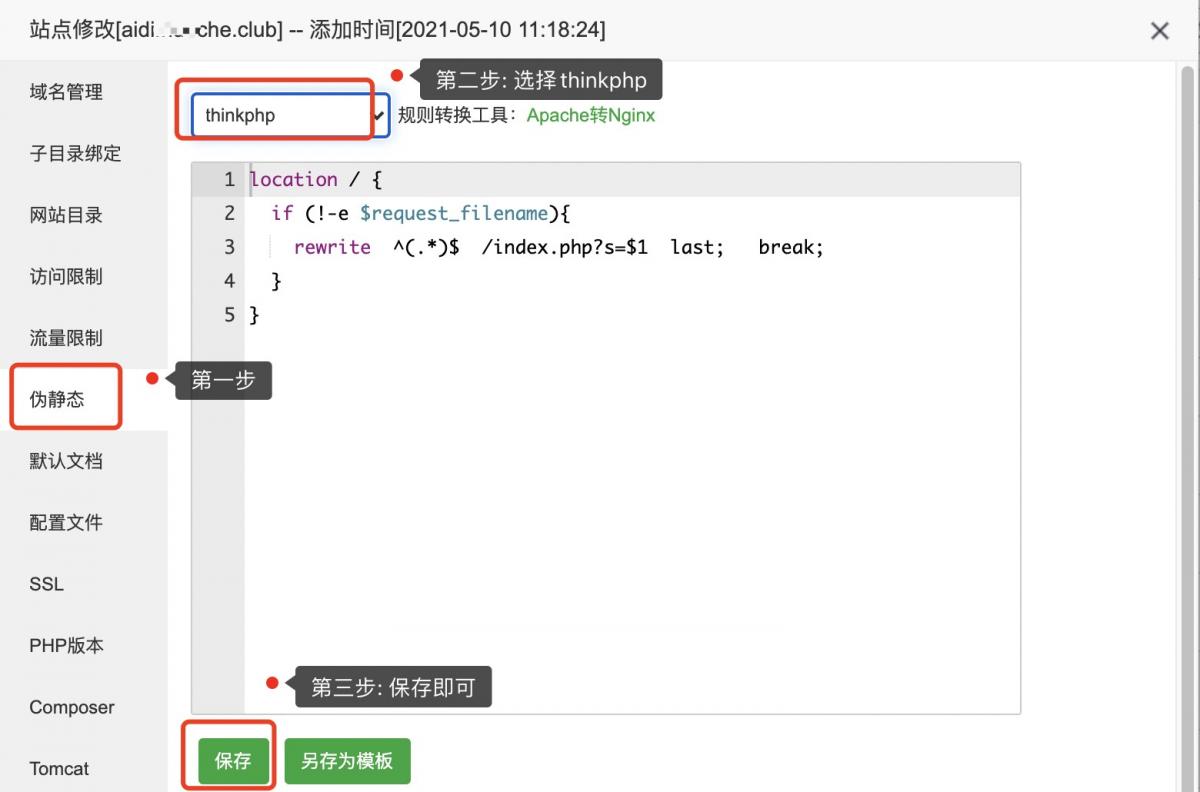
Псевдостатическая конфигурация ThinkPHP
Код изображения для загрузки апплета WeChat: последний доступный (код серверной части + код внешнего интерфейса)

Используйте растровое изображение Redis для реализации эффективной функции статистики регистрации пользователей.

[Nginx29] Обучение Nginx: буфер прокси-модуля (3) и обработка файлов cookie
[Весна] SpringBoot интегрирует ShardingSphere и реализует многопоточную вставку 10 000 фрагментов данных в пакетном режиме (выполнение операций с базой данных и таблицами).
SpringBoot обрабатывает форму данных формы для получения массива объектов
Nginx от новичка до новичка 01 - Установка Nginx через установку исходного кода

Проект flask развертывается на облачном сервере и получает доступ к серверной службе через доменное имя.

Порт запуска проекта Spring Boot часто занят, полное решение

Java вызывает стороннюю платформу для отправки мобильных текстовых сообщений

Практическое руководство по серверной части: как использовать Node.js для разработки интерфейса RESTful API (Node.js + Express + Sequelize + MySQL)
Введение в параметры конфигурации большого экрана мониторинга Grafana (2)
В статье «Научно-популярная статья» подробно объясняется протокол NTP: анализ точной синхронизации времени.

Пример разработки: серверная часть Java и интерфейсная часть vue реализуют функции комментариев и ответов.

Nodejs реализует сжатие и распаковку файлов/каталогов.
SpringBootИнтегрироватьEasyExcelСложно реализоватьExcelлистимпортировать&Функция экспорта

Настройка среды под Mac (используйте Brew для установки go и protoc)