Обучение Hadoop: углубленный анализ магии больших данных MapReduce (1)
Обучение Hadoop: углубленный анализ магии больших данных MapReduce (1)
Предисловие
В эпоху больших данных эффективная обработка больших объемов данных стала насущной необходимостью во всех сферах жизни. Одной из основных концепций Hadoop, как важной среды обработки больших данных, является MapReduce. Сегодня мы начнем с более глубокого понимания MapReduce и исследуем его важную роль в обработке больших данных.
1. Обзор MapReduce
1.1Определение MapReduce
MapReduce — это среда программирования для программ распределенных вычислений, а также основная платформа, позволяющая пользователям разрабатывать «приложения для анализа данных на основе Hadoop».
Основная функция MapReduce — интеграция написанного пользователем кода бизнес-логики и встроенных компонентов по умолчанию в полную программу распределенных вычислений, которая одновременно выполняется в кластере Hadoop.
1.2. Преимущества и недостатки MapReduce
преимущество
1) MapReduce легко программировать. Он просто реализует некоторые интерфейсы для завершения распределенной программы. Эту распределенную программу можно распространить на большое количество пользователей. Работает на дешевых ПК. Другими словами, когда вы пишете распределенную программу, это то же самое, что и написание простой последовательной программы. Вроде. Именно благодаря этой особенности программирование MapReduce стало очень популярным.
2) Хорошая масштабируемость Когда ваши вычислительные ресурсы не могут быть удовлетворены, вы можете расширить его вычислительные возможности, просто добавив машины.
3) Высокая отказоустойчивость Первоначальное намерение MapReduce заключалось в том, чтобы обеспечить возможность развертывания программ на дешевых ПК, что требует от него высокой отказоустойчивости. Например, если одна из машин зависает, она может передать для выполнения указанную выше вычислительную задачу другому узлу, чтобы задача не вышла из строя. Более того, этот процесс не требует ручного участия и полностью выполняется внутри Hadoop.
4) Подходит для автономной обработки больших объемов данных выше уровня PB.
Он может реализовать одновременную работу тысяч кластеров серверов и предоставить возможности обработки данных.
недостаток
1) Не хорош в расчетах в реальном времени.
MapReduce не может возвращать результаты в течение миллисекунд или секунд, как MySQL. 2) Плохо разбираюсь в потоковых вычислениях.
Входные данные потоковых вычислений являются динамическими, тогда как набор входных данных MapReduce является статическим и не может изменяться динамически.
Это связано с тем, что конструктивные характеристики MapReduce определяют, что источник данных должен быть статическим.
3) Плохо справляется с вычислениями DAG (ориентированный ациклический граф).
Несколько приложений имеют зависимости, и входные данные последнего приложения являются выходными данными предыдущего приложения. В этом случае дело не в том, что MapReduce нельзя использовать, но после использования выходные результаты каждого задания MapReduce будут записываться на диск, что приведет к большому количеству дисковых операций ввода-вывода, что приведет к очень низкой производительности.
1.3 Основная идея MapReduce
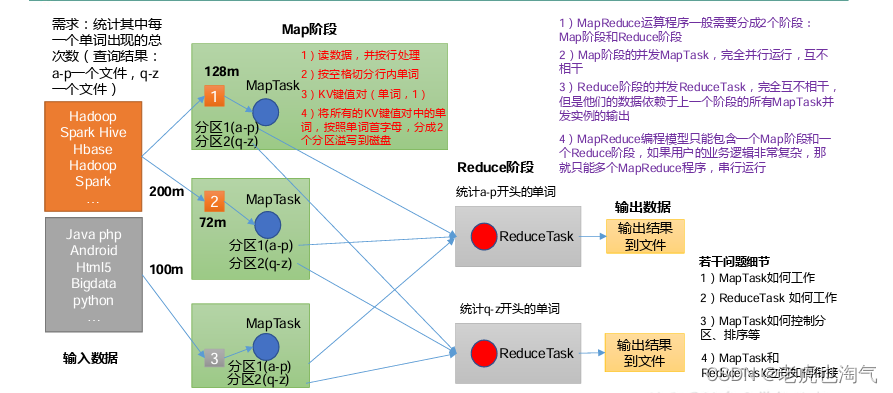
(1) Программы распределенных вычислений часто необходимо разделить как минимум на два этапа.
(2) Параллельные экземпляры MapTask на первом этапе работают полностью параллельно и независимы друг от друга. (3) Параллельные экземпляры Редуцтаск на втором этапе независимы друг от друга, но их данные зависят от выходных данных всех одновременных экземпляров MapTask на предыдущем этапе. (4)MapReduce Модель программирования может содержать только одну стадию Map и одну стадию сокращения. Если бизнес-логика пользователя очень сложна, несколько программ MapReduce можно запускать только последовательно. Краткое описание: Проанализируйте тенденции потока данных WordCount, чтобы глубже понять основные идеи MapReduce.
1.4 Процесс MapReduce
Полная программа MapReduce имеет три типа процессов экземпляров при распределенном запуске: (1) MrAppMaster: отвечает за планирование процессов и координацию состояния всей программы. (2) MapTask: отвечает за весь процесс обработки данных на этапе карты. (3) DownloadTask: отвечает за весь процесс обработки данных на этапе сокращения.
1.5 Официальный исходный код WordCount
Используйте инструменты декомпиляции, чтобы декомпилировать исходный код и обнаружить, что случай WordCount имеет класс Map, класс уменьшения и класс драйвера. и Тип данных — это сериализованный тип, инкапсулированный самим Hadoop.
1.6 Общие типы сериализации данных
Типы Java | Hadoop записываемый тип |
|---|---|
Boolean | BooleanWritable |
Byte | ByteWritable |
Int | IntWritable |
Float | FloatWritable |
Long | LongWritable |
Double | DoubleWritable |
String | Text |
Map | MapWritable |
Array | ArrayWritable |
Null | NullWritable |
1.7 Спецификации программирования MapReduce
Программа, написанная пользователем, разделена на три части: Mapper, Редюсер и Драйвер. 1. Этап картографа (1) Пользовательский Mapper должен наследовать свой собственный родительский класс. (2) Входные данные Mapper представлены в виде пар KV (тип KV можно настроить) (3) Бизнес-логика в Mapper записана в методе map(). (4) Выходные данные Mapper представлены в виде пар KV (тип KV можно настроить) (5)map()метод(MapTaskпроцесс)каждому<K,V>позвони один раз
2. Ступень редуктора (1) Пользовательский редуктор должен наследовать свой собственный родительский класс. (2) Тип входных данных Редюсера соответствует типу выходных данных Mapper, который также равен KV. (3) Бизнес-логика Редюсера написана в методе сокращения().
3. Водительский этап (4)ReduceTaskпроцесс То же самое для каждой группыkиз<k,v>Группапозвони один разreduce()метод Эквивалент клиента кластера YARN, используемый для отправки всей нашей программы в кластер YARN. Объект задания, инкапсулирующий соответствующие рабочие параметры программы MapReduce.
1.8 Практический пример WordCount
1.8.1 Локальное тестирование 1) Спрос Подсчитайте общее количество вхождений каждого слова в данном текстовом файле. (1) Введите данные

(2) Ожидаемые выходные данные Атгуигу 2 банчжан 1 класс 2 хадуп 1 Цзяо 1 SS 2 Сюэ 1 2) Анализ спроса В соответствии со спецификациями программирования MapReduce, Mapper, Редуктор и Драйвер написаны соответственно.
1. Введите данные Тгуигу Атгуигу сс сс клс клс Цзяо Банчжан Сюэ хадуп
2. Выходные данные Атгуигу 2 банчжан1 класс 2 хадуп 1 Цзяо 1 сс 2 сюэ1
3、Mapper // 3.1 Текст, переданный нам MapTask Содержимое сначала преобразуется в String atguigu atguigu // 3.2 Разделите эту строку на слова, используя пробелы atguigu atguigu // 3.3 Воляслововыходдля<слово,1> atguigu, 1 atguigu, 1
4. Редуктор // 4.1 Суммируем количество каждого ключа Атгуигу, 1 Атгуигу, 1 // 4.2 Вывод общего количества выведений ключа Атгуигу, 2
5. Водитель // 5.1 Получение информации о конфигурации и получение экземпляра объекта задания // 5.2 Указываем локальный путь, где находится jar-пакет этой программы // 5.3 Бизнес-класс Associate Mapper/Reducer // 5.4 Укажите тип kv выходных данных Mapper // 5.5 Укажите тип kv конечных выходных данных // 5.6 Укажите каталог, в котором находится исходный входной файл задания // 5.7 Укажите каталог, в котором находятся выходные результаты задания // 5.8 Отправка задания
3) Подготовка окружающей среды (1) Создайте проект maven, MapReduceDemo. (2) Добавьте следующие зависимости в файл pom.xml.
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies> (2) В каталоге src/main/resources проекта создайте новый файл с именем «log4j.properties». Заполните файл.
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n (3) Создайте имя пакета: com.atguigu.mapreduce.wordcount.
4) Написать программу (1) Написать класс Mapper
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text,
IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1 Получить ряд
String line = value.toString();
// 2 резка
String[] words = line.split(" ");
// 3 выход
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} (2) Напишите класс Редюсера
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text,
IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context
context) throws IOException, InterruptedException {
// 1 совокупная сумма
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 выход
v.set(sum);
context.write(key,v);
}
} (3) Записать класс драйвера Driver
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
// 1 Получить информацию о конфигурации и получить объект задания
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 Банка, связанная с этой программой-драйвером.
job.setJarByClass(WordCountDriver.class);
// 3 Джары, связанные с Mapper и Редюсером
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 настраиватьMapperвыходизkvтип
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 Установите окончательный выходной типkv
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 Установите пути ввода и вывода
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 Отправить работу
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
} 5) Местное тестирование (1) Сначала вам необходимо настроить переменную HADOOP_HOME и зависимости запуска Windows. (2) Запустите программу на IDEA/Eclipse.
1.8.2 Отправка на кластерное тестирование Тестирование на кластере (1) Используйте maven для сборки пакета jar, и вам необходимо добавить зависимости подключаемого модуля упаковки.
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> Уведомление:Если на проекте отображается красный крест。Щелкните правой кнопкой мыши по проекту->maven->ReimportПросто обнови。
(2) Упакуйте программу в jar-пакет.
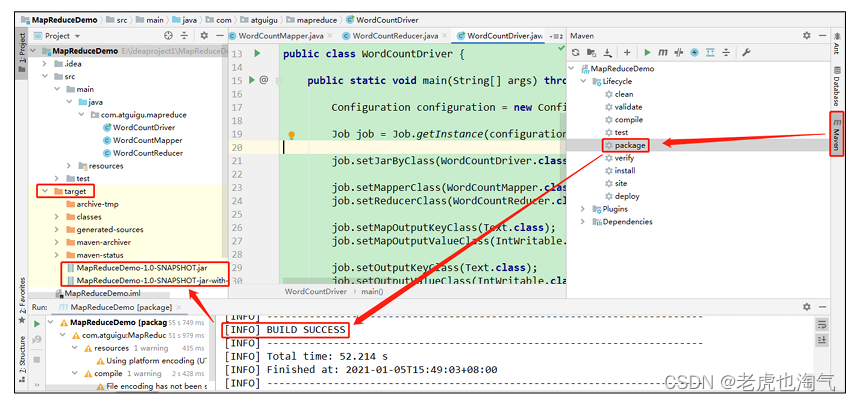
(3) Измените имя пакета jar без зависимостей на wc.jar и скопируйте пакет jar в кластер Hadoop. Путь /opt/module/hadoop-3.1.3. (4) Запустите кластер Hadoop.
[atguigu@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh (5) Запустите программу WordCount.
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar
com.atguigu.mapreduce.wordcount.WordCountDriver /user/atguigu/input
/user/atguigu/output2. Сериализация Hadoop
2.1 Обзор сериализации
1) Что такое сериализация
Сериализация заключается в преобразовании объектов в памяти в последовательности байтов (или другие протоколы передачи данных), чтобы их можно было хранить на диске. Дисковая (постоянная) и сетевая передача. Десериализация заключается в преобразовании полученной последовательности байтов (или другого протокола передачи данных) или постоянных данных на диске в в объект в памяти.
2) Почему сериализация?
Вообще говоря, «живые» объекты существуют только в памяти и исчезают при отключении питания. А «живые» предметы могут только Используется локальным процессом и не может быть отправлен на другой компьютер в сети. Однако сериализация может хранить «живые» Объект, который может отправлять «живые» объекты на удаленные компьютеры.
3) Почему бы не использовать сериализацию Java?
Сериализация Java представляет собой тяжелую структуру сериализации (Serializable). После сериализации объекта к нему будет прилагаться . Множество лишней информации (различная проверочная информация, заголовки, системы наследования и т. д.) неудобно для эффективной передачи в сети. так, Hadoop разработал собственный механизм сериализации (Writable).
4) Возможности сериализации Hadoop:
(1) Компактность: эффективное использование места для хранения. (2) Быстро: дополнительные затраты на чтение и запись данных невелики. (3) Совместимость: поддержка многоязычного взаимодействия.
2.2 Пользовательский объект bean-компонента реализует интерфейс сериализации (с возможностью записи)
Базовые типы сериализации, часто используемые в корпоративной разработке, не могут удовлетворить все потребности, например, в рамках Hadoop. Передайте объект bean, затем объект должен реализовать интерфейс сериализации. Конкретные шаги по реализации сериализации объектов bean следующие: 7 шагов. (1) Должен быть реализован интерфейс Writable.
(2) При десериализации конструктор пустых параметров необходимо вызывать рефлексивно, поэтому должен быть пустой конструктор параметров.
public FlowBean() {
super();
} (3) Перепишите метод сериализации.
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
} (4) Переписать метод десериализации
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
} (5) Обратите внимание, что порядок десериализации точно такой же, как и порядок сериализации. (6) Если вы хотите отобразить результаты в файле, вам необходимо переписать toString(), который можно разделить символом «\t» для последующего использования. (7) Если вам нужно поместить пользовательский компонент в ключ для передачи, вам также необходимо реализовать интерфейс Comparable, потому что Процесс «Перемешать» в поле MapReduce требует сортировки ключей. Подробности смотрите в примере сортировки ниже.
@Override
public int compareTo(FlowBean o) {
// Расположите в обратном порядке, от большего к меньшему.
return this.sumFlow > o.getSumFlow() ? -1 : 1;
} 2.3 Практический пример сериализации
1) Спрос Статистика общего восходящего трафика, общего нисходящего трафика и общего трафика, потребляемого каждым номером мобильного телефона. (1) Введите данные

(2) Формат входных данных:

(3) Ожидаемый формат выходных данных

2) Анализ спроса

3) Напишите программу MapReduce. (1) Напишите объект Bean для статистики трафика.
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//1 Наследовать интерфейс Writable
public class FlowBean implements Writable {
private long upFlow; //Восходящий трафик
private long downFlow; //нисходящий трафик
private long sumFlow; //Общий трафик
//2 Обеспечивает конструкцию без аргументов
public FlowBean() {
}
//3 Предоставляет методы получения и установки с тремя параметрами.
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
//4 Для реализации методов сериализации и десериализации порядок должен быть последовательным.
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
}
//5 Оверридтостринг
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
} (2) Написать класс Mapper
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean>
{
private Text outK = new Text();
private FlowBean outV = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1 Получить рядданные, конвертировать в строку
String line = value.toString();
//2 резкаданные
String[] split = line.split("\t");
//3 Захватите то, что нам нужно: номер мобильного телефона, восходящий трафик, нисходящий трафик.
String phone = split[1];
String up = split[split.length - 3];
String down = split[split.length - 2];
//4 Выход пакетаK outV
outK.set(phone);
outV.setUpFlow(Long.parseLong(up));
outV.setDownFlow(Long.parseLong(down));
outV.setSumFlow();
//5 выписать К outV
context.write(outK, outV);
}
} (3) Напишите класс Редюсера
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean>
{
private FlowBean outV = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context
context) throws IOException, InterruptedException {
long totalUp = 0;
long totalDown = 0;
//1 Просматривайте значения и накапливайте восходящий и нисходящий трафик соответственно.
for (FlowBean flowBean : values) {
totalUp += flowBean.getUpFlow();
totalDown += flowBean.getDownFlow();
}
//2 Выход пакетаKV
outV.setUpFlow(totalUp);
outV.setDownFlow(totalDown);
outV.setSumFlow();
//3 выписать К outV
context.write(key,outV);
}
} (4) Запись класса драйвера Driver
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
//1 Получить объект задания
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 Связан с этим классом драйверов
job.setJarByClass(FlowDriver.class);
//3 Ассоциированный картограф и редуктор
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4 Настройка терминала карты выходKVтип
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5 настраиватьпрограммафинальныйвыходизKVтип
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6 настраиватьпрограммаизвходитьвыходпуть
FileInputFormat.setInputPaths(job, new Path("D:\\inputflow"));
FileOutputFormat.setOutputPath(job, new Path("D:\\flowoutput"));
//7 Отправить работу
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
} 3. Принцип платформы MapReduce
3.1Ввод данных в формате ввода
3.1.1 Механизм определения параллелизма срезов и MapTask
1) Выявление вопросов
Параллелизм MapTask определяет параллелизм обработки задач на этапе Map, что, в свою очередь, влияет на скорость обработки всего задания. Подумайте: при объеме данных 1 ГБ запуск 8 MapTasks может улучшить возможности параллельной обработки в кластере. Итак, число 1К По данным, если еще и 8 MapTask запустить, улучшится ли это производительность кластера?
Чем больше параллельных задач MapTask, тем лучше? Что вызывает Факторы, влияющие на параллелизм MapTask? 2) Механизм определения параллелизма MapTask
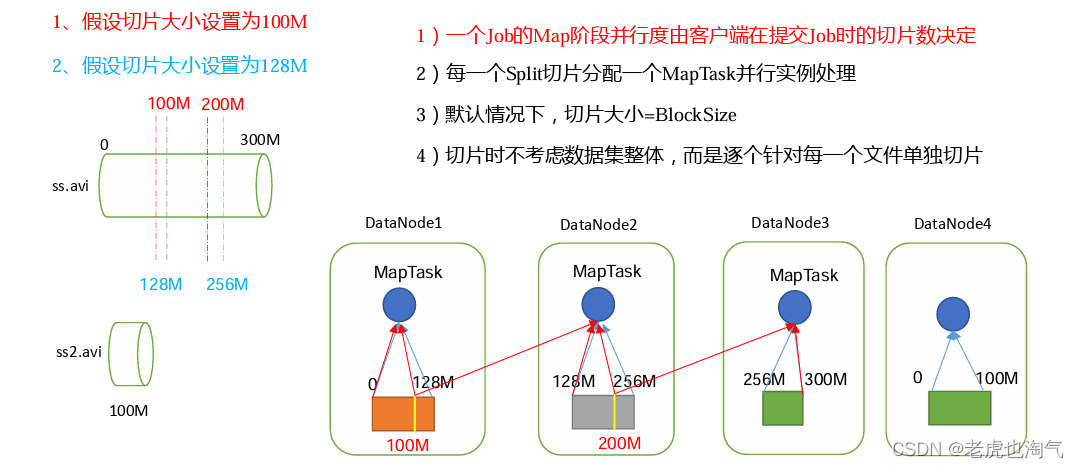
блок данных:Block HDFS физически разделяет данные на части. Блоки данных — это единицы хранения данных HDFS. Нарезка данных:Нарезка данные только логически разделяют входные данные, а не разбивают их на фрагменты на диске. хранилище. Срез данных — это единица измерения, используемая программой MapReduce для расчета входных данных. Каждый срез соответственно запускает MapTask.
3.1.2 Подробное объяснение исходного кода процесса отправки задания и исходного кода нарезки
1) Подробное объяснение исходного кода процесса подачи задания.
waitForCompletion()
submit();
// 1Установите соединение
connect();
// 1)создавать Отправить работуизактерское мастерство
new Cluster(getConfiguration());
// (1) Определите, является ли это локальной операционной средой или операционной средой кластера пряжи.
initialize(jobTrackAddr, conf);
// 2 Отправить работу
submitter.submitJobInternal(Job.this, cluster)
// 1) Создайте путь Stag для отправки данных в кластер.
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2) Получить работу и создайте путь к заданию
JobID jobId = submitClient.getNewJobID();
// 3) Скопируйте пакет jar в кластер.
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4) Рассчитать срезы и создать файлы планирования срезов.
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5) Запишите файл конфигурации XML в путь Stag.
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)Отправить работу,Вернуть статус отправки
статус = submitClient.submitJob(jobId, submitJobDir.toString(),
job.getCredentials()); 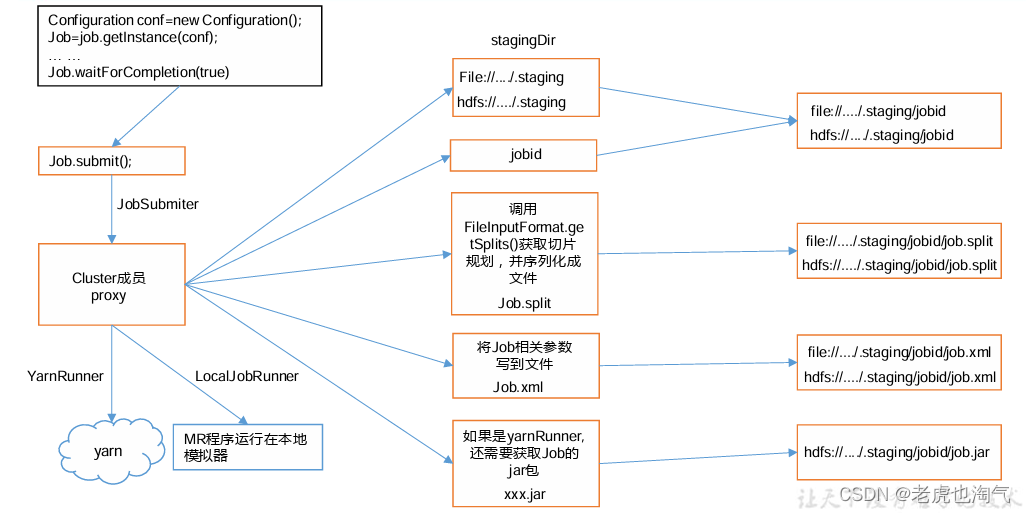
2) Анализ исходного кода фрагмента FileInputFormat (input.getSplits(job))
(1) Программа сначала находит каталог, в котором хранятся ваши данные. (2) Начните просмотр каждого файла в каталоге обработки (планирования нарезки). (3) Перейдите к первому файлу ss.txt. а) Получите размер файла fs.sizeOf(ss.txt)
б) Рассчитайте размер среза
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
в) По умолчанию размер среза = размеру блока
г) Начните вырезание, чтобы сформировать первый фрагмент: ss.txt — 0:128M Второй фрагмент ss.txt — 128:256M Третий фрагмент ss.txt — 256M:300M (Каждый раз, когда вы нарезаете фрагмент, вы должны оценить, превышает ли оставшаяся часть размер блока более чем в 1,1 раза. Если он не превышает 1,1 раза, разделите его на один фрагмент)
e) Запишите информацию о нарезке в файл планирования нарезки.
е) Основной процесс всей нарезки завершается в методе getSplit().
g) InputSplit записывает только метаданные среза, такие как начальная позиция, длина и список узлов.
(4) Отправьте файл планирования нарезки в YARN, и MrAppMaster на YARN сможет рассчитать количество открытых MapTasks на основе файла планирования нарезки.
3.1.3 Механизм нарезки FileInputFormat
1. Механизм нарезки (1) Просто нарежьте в соответствии с длиной содержимого файла. (2) Размер среза, по умолчанию равен размеру блока. (3) При нарезке не учитывается весь набор данных, а нарезается каждый файл индивидуально.
2. Анализ случая (1) Существует два файла для входных данных: файл1.txt 320M файл2.txt 10M (2) Через механизм нарезки FileInputFormat. После операции формируется следующая информация о срезе: file1.txt.split1 -- 0~128 file1.txt.split2 -- 128~256 file1.txt.split3-- 256~320 file2.txt.split1 -- 0~10M
Конфигурация параметров размера среза FileInputFormat (1) Формула расчета размера среза в исходном коде Math.max(minSize, Math.min(maxSize, blockSize)); mapreduce.input.fileinputformat.split.minsize=1 Значение по умолчанию — 1. mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue Значение по умолчаниюLong.MAXValue Поэтому по умолчанию размер среза = размеру блока. (2) Настройка размера среза maxsize (максимальное значение среза): если параметр настроен меньше, чем размер блока, срез станет меньше и будет равен настроенному значению этого параметра. minsize (минимальное значение среза): если параметр настроен больше, чем размер блока, срез можно сделать больше, чем размер блока. (3) Получить API информации о срезах
// Получаем имя файла среза Имя строки = inputSplit.getPath().getName(); // Получаем информацию о срезе в зависимости от типа файла FileSplit inputSplit = (FileSplit) context.getInputSplit();
3.1.4 TextInputFormat
1) Класс реализации FileInputFormat Подумайте: при запуске программы MapReduce форматы входных файлов включают: построчные файлы журналов, двоичные файлы. Форматирование файлов, таблиц базы данных и т. д. Итак, как MapReduce считывает эти данные для разных типов данных? Классы реализации общего интерфейса FileInputFormat включают: TextInputFormat, KeyValueTextInputFormat, NLineInputFormat, JointTextInputFormat, пользовательский InputFormat и т. д. 2) Формат ввода текста TextInputFormat — это класс реализации FileInputFormat по умолчанию. Прочитайте каждую запись построчно. Ключ — это начальное смещение байтов во всем файле, в котором хранится строка, типа LongWritable. Значением является содержимое строки, исключая любое завершение строки. символы (перевод строки и возврат каретки), тип текста. Ниже приведен пример. Например, сегмент содержит следующие 4 текстовые записи. Богатая форма обучения Интеллектуальный механизм обучения Учиться удобнее От реального спроса на более близкие к предприятию Каждая запись представлена в виде следующей пары ключ/значение: (0,Богатая форма обучения) (20,Интеллектуальная система обучения) (49,Учиться удобнее) (74,От реального спроса на более близкие к предприятию)
3.1.5 Механизм нарезки JointTextInputFormat
Механизм нарезки TextInputFormat по умолчанию в платформе предназначен для нарезки задач в соответствии с планированием файлов. Независимо от того, насколько мал файл, он будет нарезаться. представляет собой отдельный фрагмент и будет передан в MapTask, поэтому, если имеется большое количество маленьких файлов, большое количество MapTask, эффективность обработки крайне низкая. 1) Сценарии применения: Комбайн Текст Инпут Формат используется в сценариях, где имеется слишком много маленьких файлов. Он может логически сгруппировать несколько небольших файлов. За один срез несколько небольших файлов можно передать в один MapTask для обработки. 2) Установка максимального значения слайсов виртуальной памяти КомбайнTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m Примечание. Лучше всего установить максимальное значение среза виртуального хранилища в соответствии с фактическим небольшим размером файла. 3) Механизм нарезки Процесс генерации срезов состоит из двух частей: виртуального хранимого процесса и процесса нарезки.

(1) Виртуальная хранимая процедура: Сравните размеры всех файлов во входном каталоге с установленным значением setMaxInputSplitSize. Если нет. При превышении установленного максимального значения блок логически разделяется. Если входной файл превышает установленный максимум и в два раза больше, Затем отрежьте кусок с максимальным значением, когда оставшийся размер данных превышает установленное максимальное значение и не превышает максимальное значение более чем в 2 раза, в это время. Разделите файл поровну на 2 блока виртуальной памяти (чтобы не допустить слишком маленьких фрагментов). Например, если значение setMaxInputSplitSize равно 4 МБ, а размер входного файла — 8,02 МБ, он будет логически разделен на один 4М. Оставшийся размер составляет 4,02 МБ. Если логически разделить его на 4 МБ, появится небольшое виртуальное хранилище размером 0,02 МБ. файл, поэтому оставшийся файл размером 4,02 МБ делится на два файла (2,01 МБ и 2,01 МБ). (2) Процесс нарезки: (a) Определите, превышает ли размер файла виртуального хранилища значение setMaxInputSplitSize. Если он больше или равен ему, он будет один Сформировать ломтик. (б) Если он не больше, объедините его со следующим файлом виртуальной памяти, чтобы сформировать срез. (c) Тестовый пример: имеется 4 небольших файла размером 1,7 МБ, 5,1 МБ, 3,4 МБ и 6,8 МБ соответственно. файл, то после виртуального хранилища формируется 6 файловых блоков, размеры такие: 1,7М, (2,55М, 2,55М), 3,4М и (3,4М, 3,4М) В итоге получится 3 ломтика, размеры которых: (1,7+2,55)М, (2,55+3,4)М, (3,4+3,4)М
3.1.6 Практический пример объединенияTextInputFormat
1) Спрос Объедините большое количество входных небольших файлов в фрагмент для унифицированной обработки. (1) Введите данные Подготовьте 4 небольших файла.

(2) Ожидания б.txt Ожидайте, что один фрагмент обработает 4 файла. 2) Процесс реализации c.txt d.txt (1) Без какой-либо обработки запустите кейс-программу WordCount из раздела 1.8 и обратите внимание, что количество срезов равно 4.
number of splits:4 (2) Добавьте следующий код в WordcountDriver, запустите программу и обратите внимание, что количество работающих фрагментов равно 3. (a) Добавьте в класс драйвера следующий код:
// Если InputFormat не установлен, по умолчанию используется TextInputFormat.class.
job.setInputFormatClass(CombineTextInputFormat.class);
//Устанавливаем максимальное значение среза виртуальной памяти равным 4м
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); (b) Запустить if для 3 срезов.
number of splits:3 (3) Добавьте следующий код в WordcountDriver, запустите программу и обратите внимание, что количество работающих фрагментов равно 1. (а) Добавьте в драйвер следующий код:
// Если InputFormat не установлен, по умолчанию используется TextInputFormat.class.
job.setInputFormatClass(CombineTextInputFormat.class);
//Устанавливаем максимальное значение среза виртуальной памяти равным 20 м
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520); (b) Выполнить, если для 1 среза
number of splits:1 3.2 Рабочий процесс MapReduce
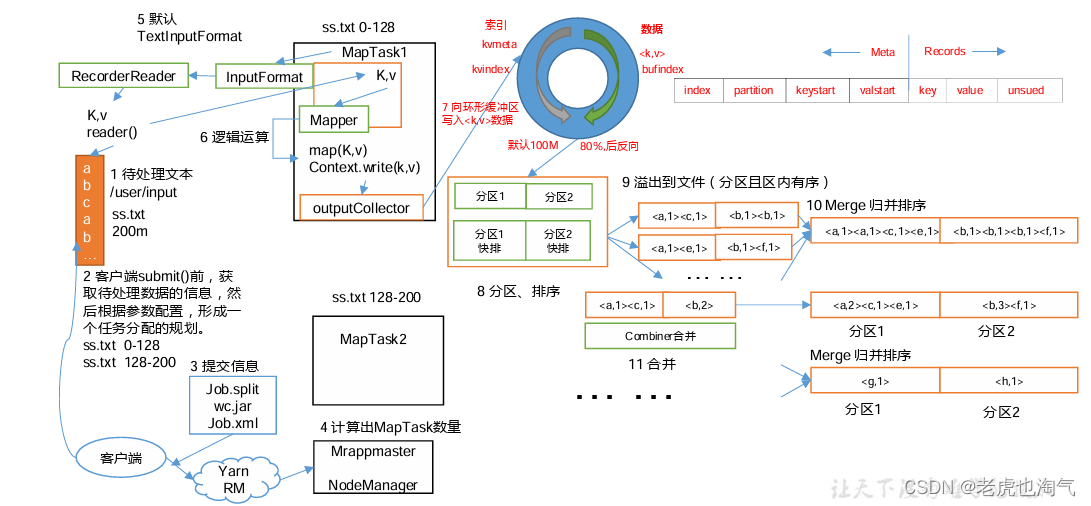
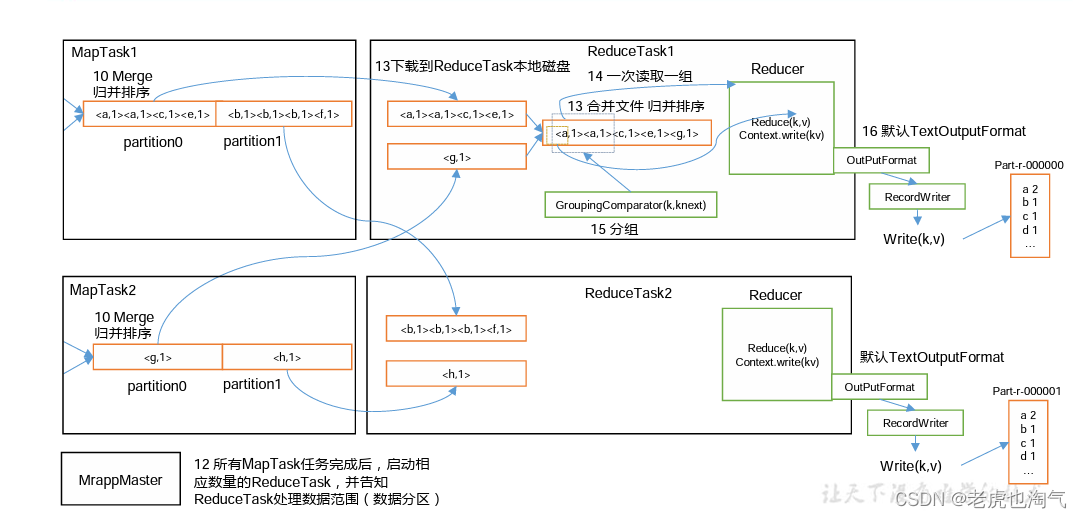
Вышеупомянутый процесс является наиболее полным рабочим процессом из всего MapReduce, но процесс перемешивания начинается только с шага 7 до шага. Шаг 16 завершается. Конкретный процесс перемешивания подробно объясняется следующим образом: (1) MapTask собирает пары kv, выводимые нашим методом map(), и помещает их в буфер памяти. (2) Файлы локального диска постоянно переполняются из буфера памяти, и могут быть переполнены несколько файлов. (3) Несколько файлов переполнения будут объединены в большой файл переполнения. (4) Во время процесса переполнения и процесса слияния необходимо вызвать Partitioner для разделения и сортировки ключей. (5) РедукцияTask обращается к каждому компьютеру MapTask для получения соответствующих данных раздела результата в соответствии с его собственным номером раздела. (6) Редуц Таск захватит файлы результатов из разных MapTask в одном разделе, а Редуц Таск объединит эти файлы (сортировка слиянием). (7) После слияния в большие файлы процесс Shuffle завершается, а затем вводится процесс логической операции уменьшитьTask. Обработка (извлеките пары ключ-значение, сгруппированные по одной, из файла и вызовите пользовательский метод уменьшения()) Уведомление: (1)Shuffle Размер буфера влияет на эффективность выполнения программы MapReduce. В принципе, размер буфера. Чем больше значение, тем меньше количество дисковых операций ввода-вывода и выше скорость выполнения. (2) Размер буфера можно настроить с помощью параметров. Параметр: mapreduce.task.io.sort.mb по умолчанию равен 100 МБ.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
