Общее введение в Spark Core
1. Введение
2. Основные концепции
1. оптимизация количества исполнителей
–num-executors: количество исполнителей. Число исполнителей может быть числом узлов или общим количеством ядер (количество ядер одного узла * количество узлов) или между этими двумя значениями (используется для настройки). ) --executor-cores: количество ядер исполнителя. Число ядер может быть равно 1, одноузловому ядру или чему-то промежуточному (для настройки). –executor-memory: память исполнителя, которая может представлять собой минимальное количество памяти (общее количество памяти одного узла/количество ядер одного узла), максимальное количество памяти (общее количество памяти одного узла), или что-то среднее (используйте для настройки)
Используйте меньших исполнителей Меньшее количество ядер, меньшие ядра Используйте более крупных исполнителей Чем больше количество ядер, тем больше ядро. Используйте оптимизированные исполнители Количество ядер соответствующее и ядро соответствующее
стратегия оптимизации исполнителя Начните с количества ядер-исполнителей и так далее.
Ссылка: https://my.oschina.net/u/4331678/blog/3629181
2. Узел
2.1 Driver
Узел драйвера Spark используется для выполнения основного метода в задаче Spark и отвечает за фактическое выполнение кода. Водитель несет основную ответственность за:
1. Преобразовать логику кода в задачи; 2. Планирование задач (работ) между Исполнителями; 3. Отслеживать выполнение Исполнителя (задачи).
2.2 Executor
Узлы-исполнители Spark отвечают за выполнение определенных задач в заданиях Spark, и эти задачи независимы друг от друга. При запуске приложения Spark узел Executor запускается одновременно и всегда существует на протяжении всего жизненного цикла приложения Spark. Если узел Executor выйдет из строя или выйдет из строя, приложение Spark сможет продолжить выполнение, а задачи на неисправном узле будут запланированы для продолжения работы на других узлах Executor. Исполнитель имеет две основные функции:
1. Отвечает за запуск задач, составляющих приложение Spark, и возврат результатов в процесс драйвера; 2. Обеспечить хранилище в памяти для RDD, требующих кэширования в пользовательских программах, через собственный менеджер блоков. RDD кэшируется непосредственно в процессе Executor, поэтому задачи могут в полной мере использовать кэшированные данные для ускорения операций во время выполнения.
2.3 процесс выполнения запроса искрового ядра
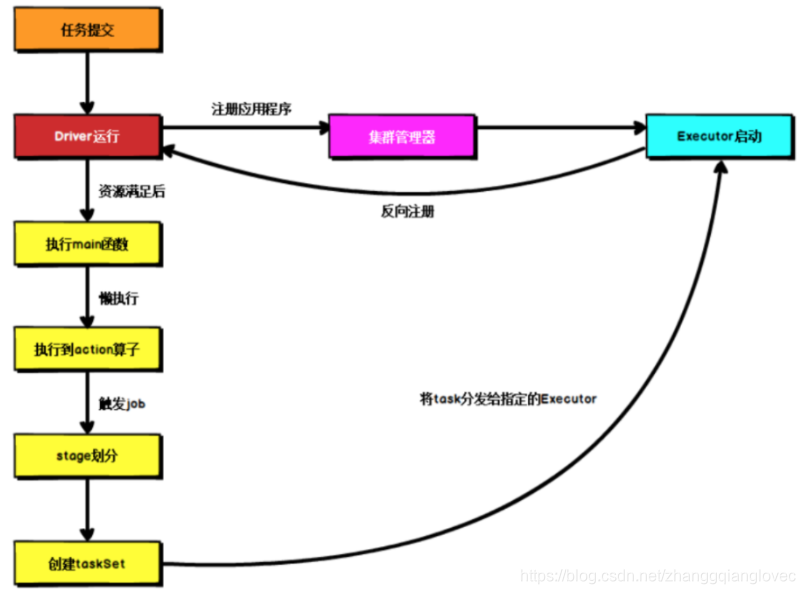
Независимо от того, как развернута искра, после отправки задачи сначала запускается Драйвер, а затем Драйвер регистрирует приложение в менеджере кластера. Затем менеджер кластера выделяет и запускает Исполнитель в соответствии с файлом конфигурации этой задачи, и. затем Драйвер ждет, пока ресурсы будут удовлетворены, и выполняет основную функцию, запрос Spark — ленивое выполнение. Когда выполняется оператор действия, начинается фактическое выполнение, и начинается обратный расчет по широким зависимостям. Затем каждый этап соответствует. в набор задач, и в наборе задач есть несколько задач, задача. Он будет передан назначенному Исполнителю для выполнения. В процессе выполнения задачи Исполнитель будет продолжать связываться с Водителем и сообщать о статусе выполнения задачи.
Ссылка: https://www.cnblogs.com/valjeanshaw/p/12532723.html.
3. Режим развертывания
Spark поддерживает в общей сложности 3 менеджера кластера: Standalone, Mesos и Yarn.
3.1 Standalone
Автономный режим — простейший менеджер кластеров, встроенный в Spark. Он может работать в различных операционных системах и поставляется с полным набором услуг. Ему не требуется использовать какую-либо другую систему управления ресурсами. Вы можете легко создать кластер с помощью автономного режима.
3.2 Apache Mesos
Mesos также является мощной платформой управления распределенными ресурсами, созданной по тем же принципам, что и ядро Linux, что позволяет развертывать на ней множество различных платформ.
3.3 Hadoop Yarn
Механизм унифицированного управления ресурсами в экосистеме Hadoop может запускать несколько вычислительных фреймворков, таких как Mapreduce, Spark и т. д. В зависимости от расположения драйвера в кластере режим развертывания можно разделить на Yarn-cluster и Yarn-cluster.
Режим работы Spark зависит от значения переменной среды MASTER, переданной в SparkContext. Spark развертывается в пряже: Yarn-client: Драйвер локальный, Исполнитель находится в кластере Yarn, конфигурация: – клиент режима развертывания Yarn-cluster: драйвер и исполнитель находятся в кластере Yarn, конфигурация: кластер –deploy-mode.
4. Механизм работы режима пряжи.
4.1 yarn-client
Режим клиента Yarn для задачи искры
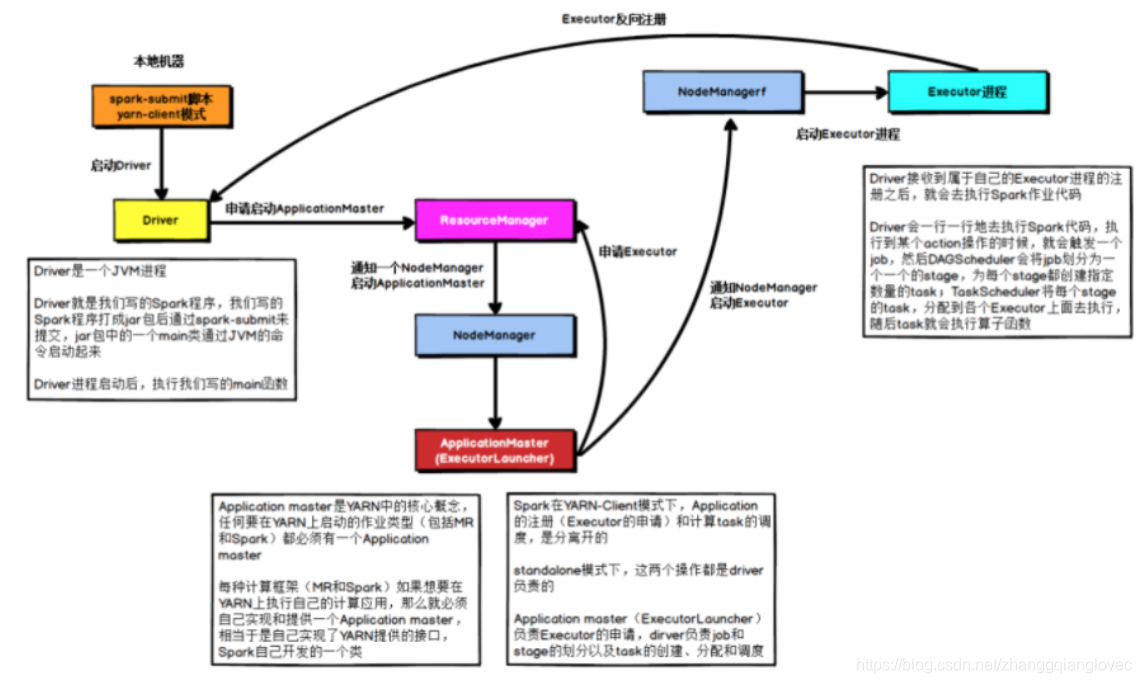
В режиме YARNClient драйвер запускается на локальном компьютере, на котором отправлена задача. Драйвер обращается к ResourceManager для запуска ApplicationMaster. Затем ResourceManager выделяет контейнер и запускает ApplicationMaster на соответствующем NodeManager. функционирует как ExecutorLaucher и отвечает только за то, что ResourceManager применяется к памяти Executor. ResourceManager выделит контейнер после получения запроса ресурса от ApplicationMaster, а затем ApplicationMaster запускает процесс «Исполнитель» в NodeManager, указанном в выделении ресурсов. После запуска процесса «Исполнитель» он обратно зарегистрируется в драйвере. С другой стороны, когда собственных ресурсов Драйвера достаточно, Драйвер приступает к выполнению основной функции, а затем при выполнении оператора Action запускается задание, и этапы делятся в соответствии с широкими зависимостями. Каждый этап генерирует соответствующий набор задач. После завершения регистрации Исполнителя Водитель распределяет задачи каждому Исполнителю для выполнения.
4.2 yarn-cluster
режим кластера пряжи задачи искры
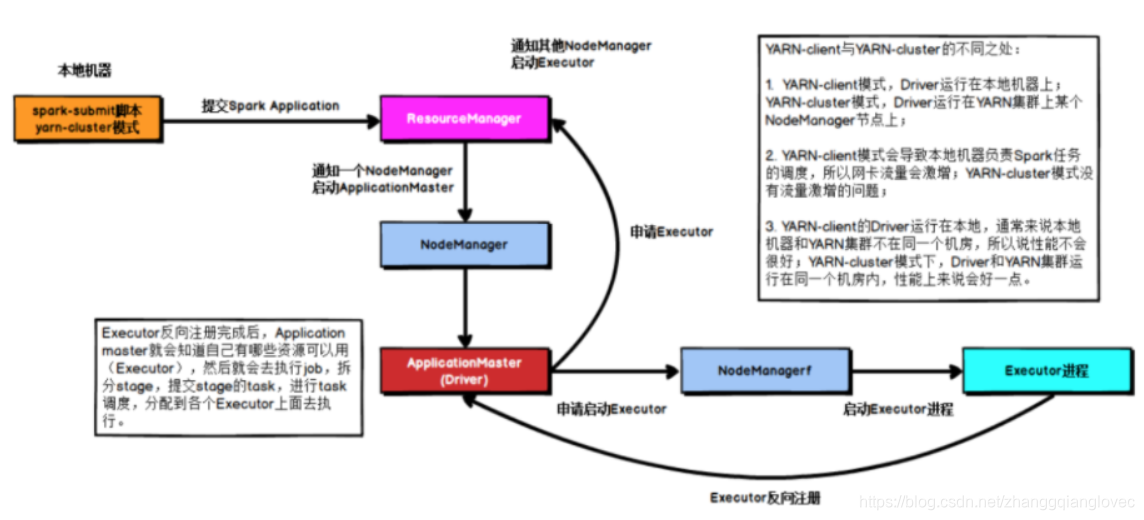
В режиме кластера YARN после отправки задачи он связывается с ResourceManager, чтобы подать заявку на запуск ApplicationMaster. Затем ResourceManager выделяет контейнер и запускает ApplicationMaster на соответствующем NodeManager. В этот момент ApplicationMaster является драйвером.
После запуска драйвера он применяется к памяти ResourceManager для Executor. ResourceManager выделит контейнер, а затем запустит процесс Executor в соответствующем NodeManager. После запуска процесса Executor он будет обратно зарегистрирован в драйвере. С другой стороны, когда собственные ресурсы Драйвера удовлетворены, он начинает выполнение основной функции, а затем, когда выполняется оператор Action, запускается задание, и этапы делятся в соответствии с широкими зависимостями. Каждый этап генерирует соответствующий. TaskSet После завершения регистрации Исполнителя Драйвер распределяет задачи между различными Исполнителями для выполнения.
Ссылка: https://www.cnblogs.com/valjeanshaw/p/12532723.html.
4. Планирование задач
Водитель подготовит задачи в соответствии с пользовательской программой и передаст задачи Исполнителю. В первую очередь необходимо представить несколько концепций Spark: Задание: если использовать оператор Action в качестве границы, задание запускается при обнаружении метода Action. Этап: подмножество задания. Задание имеет по крайней мере один этап. Оно ограничено перетасовкой (т. е. широкой зависимостью RDD). Задача: подмножество этапа, измеряемое степенью параллелизма (количество разделов). Количество разделов — это количество задач.
Spark планирует конкретные задачи двумя способами: планирование на уровне этапов и планирование на уровне задач. Spark RDD использует оператор Transactions для формирования DAG графа кровного родства и, наконец, использует оператор Action для запуска задания и планирования его выполнения. DAGScheduler отвечает за планирование на уровне этапов, в основном разделяя DAG на несколько этапов и упаковывая каждый этап в набор задач для планирования с помощью TaskScheduler. TaskScheduler отвечает за планирование на уровне задач и распределяет TaskSet, предоставленный DAGScheduler, Исполнителю для выполнения в соответствии с указанной политикой планирования.
4.1 Планирование на уровне этапа Spark
Планирование задач Spark начинается с резки DAG, которую в основном выполняет DAGScheduler. При обнаружении операции Action вычисление задания будет запущено и передано в DAGScheduler для обработки.
DAGScheduler в основном выполняет две части:
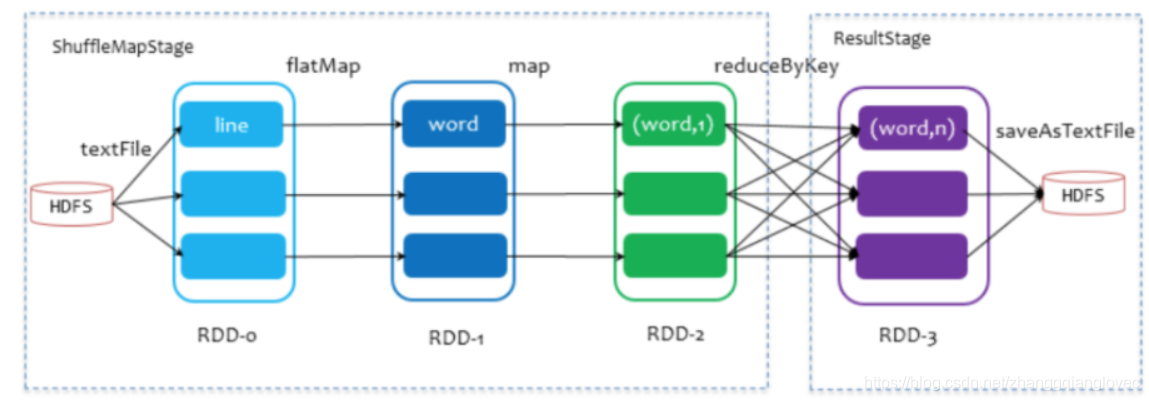
- Разделить этапы AGScheduler разделит одно задание на несколько этапов в зависимости от структуры кровного родства RDD изDAG. Конкретное разделение Стратегии: от начала до конца, Зависит. Наконец, изRDD продолжает судить о том, является ли родительская опора широкой опорой через опоры, и разделяет один этап при столкновении с перемещением одного человека. Никакая перетасовка называется узкой опорой, узкая опора делится между из РДДДодеяло приезжать с одной стадиейсередина. Разделите этапы на две категории: одна называется ResultStage и является самой последующей из Stage DAG. от Действиеметод Решение,Другой тип называется ShuffleMapStage.,Подготовьте данные для последующего этапа.
Планирование поэтапных задач само по себе представляет собой алгоритм обратного обхода глубины, как показано на рисунке ниже в качестве примера. Здесь только saveAsTextFile является оператором действия. Задание состоит из методов RDD-3 и saveAsTextFile. Оно отслеживается в соответствии с зависимостями, пока не вернется к RDD-0, у которого нет зависимостей. Во время процесса обратного отслеживания на RDD-2 и RDD-3 происходит перетасовка сокращения по ключу, которая разделяет этапы. Поскольку RDD-3 находится на последнем этапе, он делится на ResultStage, RDD-2, RDD-1 и. Среди этих зависимостей у оператора преобразования FlatMap, Map нет shuffle, поскольку между ними существует узкая зависимость, разделенная на ShuffleMapStage.
искровое задание, ежедневное расписание, день Степень
- Упаковать набор задач и отправить в Stage один этап. Если родительского этапа нет, то отправка начинается с этого этапа, а дочерний этап не может быть отправлен до завершения выполнения родительского этапа. При отправке этапа информация о задаче (информация о разделе, методе и т. д.) будет сериализована, упакована в TaskSet и передана в TaskScheduler, один раздел Соответствует. одногоTask, а TaskScheduler будет следить за статусом выполнения Stageиз, теряется только Executor или TaskЗависит Если выборка завершилась неудачно, вам необходимо повторно отправить невыполненную задачу, чтобы запланировать невыполненную задачу. Если задача другого типа не удалась, процесс планирования TaskScheduler будет повторен.
4.2 Планирование Spark на уровне задач
Планирование SparkTask завершается TaskScheduler, который инкапсулирует полученный TaskSet в TaskSetManager и добавляет его в очередь планирования. Одновременно может существовать несколько TaskSetManager, один TaskSetManager соответствует одному TaskSet, а один TaskSet содержит n информации о нескольких задачах, и все эти задачи относятся к одному и тому же этапу. После инициализации TaskScheduler будет запущен SchedulerBackend. Он отвечает за работу с внешним миром, получение регистрационной информации Исполнителя и поддержание статуса Исполнителя. После того, как SchedulerBackend отслеживает наличие ресурсов, он запрашивает у Исполнителя. TaskScheduler определяет, есть ли какие-либо задачи для запуска. TaskScheduler будет следовать инструкциям из очереди планирования. Указанная политика планирования выбирает TaskSetManager для планирования запуска.
TaskSetManager передает задачи одну за другой в TaskScheduler в соответствии с определенными правилами планирования, а затем TaskScheduler передает их SchedulerBackend для отправки их Executor для выполнения. После того, как Задача будет отправлена Исполнителю для начала выполнения, Исполнитель сообщит о состоянии выполнения SchedulerBackend, а SchedulerBackend сообщит TaskScheduler. TaskScheduler находит TaskSetManager, соответствующий Задаче, и уведомляет TaskSetManager, чтобы TaskSetManager знал. статус выполнения Задачи.
4.3 Неудачная повторная попытка и белый список
Для задачи, которую не удалось запустить, TaskSetManager запишет количество сбоев. Если количество сбоев не превысило максимальное количество повторных попыток, она будет возвращена в пул задач для планирования и будет ожидать повторного выполнения. . Когда количество попыток превышает максимально допустимое количество попыток, все приложение завершается с ошибкой. При записи количества сбоев задачи TaskSetManager также записывает ExecutorId и хост, на котором произошел последний сбой, чтобы в следующий раз, когда эта задача будет запланирована, будет использоваться механизм черного списка, чтобы предотвратить ее планирование на узле, на котором произошел сбой в последний раз. . до определенной степени отказоустойчивости.
Ссылка: https://www.cnblogs.com/valjeanshaw/p/12532723.html.
5. DAG (ориентированный ациклический граф)
Происхождение (кровное родство), то есть преимущество топологической сортировки DAG.
преимущество Ленивый вызов, конвейеризация, отсутствие синхронного ожидания, отсутствие необходимости сохранять промежуточные результаты, каждая операция становится простой
6. RDD
RDD — это коллекция распределенных объектов, которая обеспечивает строго ограниченную модель общей памяти. По сути, это коллекция секционированных записей, доступная только для чтения, которую нельзя изменить напрямую. Каждый RDD можно разделить на несколько разделов, каждый раздел представляет собой фрагмент набора данных, а разные разделы RDD могут быть сохранены на разных узлах кластера, так что параллельные вычисления могут выполняться на разных узлах кластера.
Именно этот механизм ленивого вызова RDD позволяет не сохранять промежуточные результаты, полученные в результате операции преобразования, а напрямую передавать их по конвейеру в следующую операцию для обработки.
6.1 Конструкция и принципы работы
В практических приложениях существует множество итерационных алгоритмов и интерактивных инструментов интеллектуального анализа данных. Общим для этих сценариев приложений является то, что промежуточные результаты повторно используются на разных этапах вычислений, то есть выходные данные одного этапа будут использоваться в качестве входных данных для следующего. этап. Платформа MapReduce в Hadoop записывает промежуточные результаты в HDFS, что требует больших затрат на копирование данных, дисковый ввод-вывод и сериализацию и обычно поддерживает только некоторые определенные режимы вычислений. RDD предоставляет абстрактную архитектуру данных, поэтому разработчикам не нужно беспокоиться о распределенных характеристиках базовых данных. Им нужно только выразить конкретную логику приложения в виде серии процессов преобразования. Операции преобразования между различными RDD формируют зависимости. Достичь конвейерной обработки, что позволит избежать хранения промежуточных результатов, что значительно сократит копирование данных, дисковый ввод-вывод и накладные расходы на сериализацию.
6.2 Особенности
- Эффективная отказоустойчивость
- серединарезультат времени Выносливостьприезжать Память
6.3 Зависимости RDD
Узкая зависимость и широкая зависимость
RDD делится на два типа: Узкие зависимости и Широкие зависимости с точки зрения зависимостей Lineage, которые используются для решения проблемы отказоустойчивости и эффективности данных.
Узкие зависимости означают, что каждый раздел родительского RDD используется не более чем одним разделом дочернего RDD, что означает, что один родительский раздел RDD соответствует одному дочернему разделу RDD или несколько родительских разделов RDD соответствуют одному дочернему разделу RDD, т.е. Говорят, что один раздел родительского RDD не может соответствовать нескольким разделам дочернего RDD.
Широкие зависимости означают, что разделы дочернего RDD зависят от нескольких разделов или всех разделов родительского RDD. Другими словами, существует раздел родительского RDD, соответствующий нескольким разделам дочернего RDD. Для широких зависимостей входные и выходные данные этого вычисления находятся на разных узлах. Метод происхождения эффективен для обеспечения отказоустойчивости путем перерасчета, когда входной узел не поврежден, а выходной узел не работает. В противном случае он будет недействителен, поскольку его невозможно повторить. , и вам нужно вернуться к его предкам, чтобы увидеть, можно ли его повторить (в этом смысл происхождения). Накладные расходы на пересчет данных для узких зависимостей намного меньше, чем накладные расходы на пересчет данных для широких зависимостей.
зависимость искры от RDD
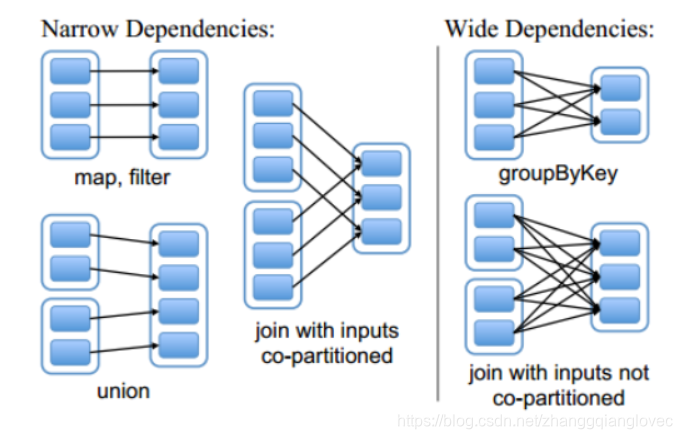
Среди них узкая зависимость представляет собой связь «один к одному» или связь «многие к одному» между родительским СДР и дочерним СДР, которая в основном включает в себя такие операции, как отображение, фильтр, объединение и т. д., тогда как широкая зависимость представляет собой; отношение «один-к-одному» между родительским RDD и дочерним RDD-отношением, то есть родительский RDD преобразуется в несколько дочерних RDD. Основные операции включают в себя groupByKey, sortByKey и т. д.
Зависимости искрового ядра RDD
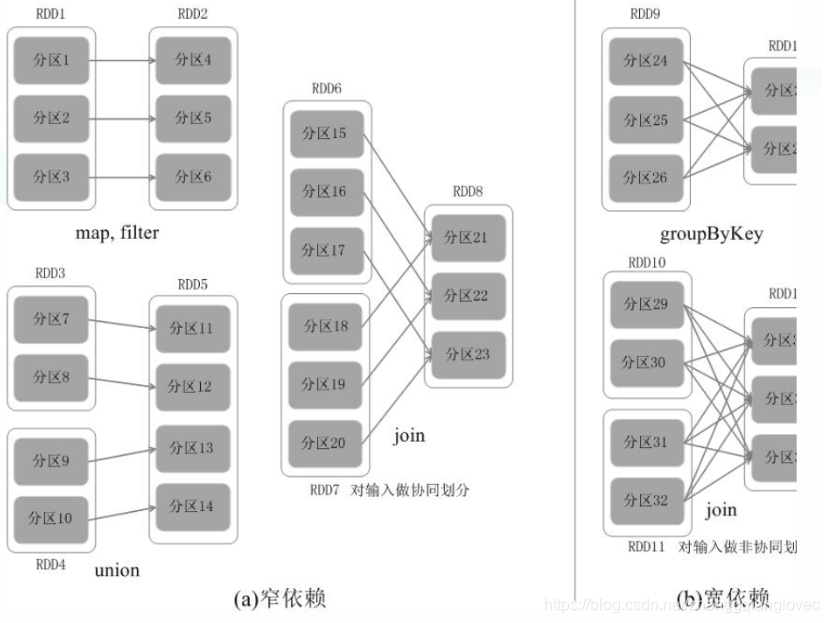
Для узкозависимых RDD все родительские разделы могут рассчитываться конвейерным способом, не вызывая смешивания данных между сетями. Для RDD с широкими зависимостями они обычно сопровождаются операциями Shuffle, то есть все данные родительского раздела необходимо сначала вычислить, а затем перетасовать между узлами. Таким образом, при выполнении восстановления данных узким зависимостям необходимо только пересчитывать потерянные разделы на основе родительских разделов RDD, и их можно пересчитывать на разных узлах параллельно. Для широких зависимостей отказ одного узла обычно означает, что процесс перерасчета будет включать в себя несколько родительских разделов RDD, что является дорогостоящим.
Кроме того, Spark также предоставляет контрольные точки данных и ведение журналов для сохраняющихся промежуточных RDD, поэтому при восстановлении после сбоя не требуется возвращаться на исходную стадию. При восстановлении после сбоя Spark сравнивает стоимость контрольных точек данных со стоимостью пересчета разделов RDD, чтобы автоматически выбрать оптимальную стратегию восстановления.
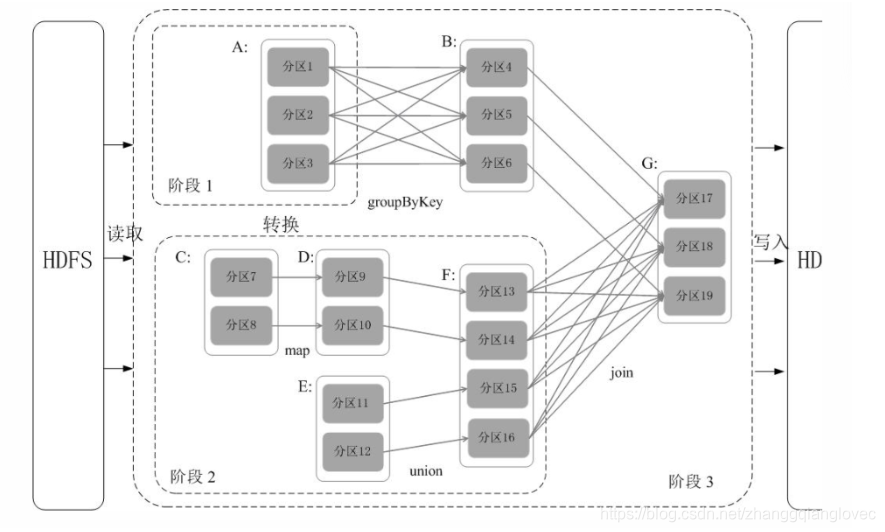
1. Сценическое деление Spark Анализируя каждый RDD Зависимости генерируются DAG ,Снова Анализируя каждый RDD Зависимости между разделами определяют способ разделения этапов. Конкретный метод разделения: in. DAG Выполните обратный анализ в файле, отключите при обнаружении широких зависимостей и отключите текущие зависимости при обнаружении узких зависимостей. RDD Добавьте его к текущему этапу; разделите узкие зависимости на один и тот же этап, насколько это возможно, чтобы добиться конвейерных вычислений.
. Затем при выполнении поведенческой операции анализ DAG осуществляется в обратном порядке. Поскольку преобразование из A в B и преобразование из B, F в G — это все широкие зависимости, необходимо отключиться от широких зависимостей и разделить их на три этапа. . После разделения графа DAG на несколько «этапов» каждый этап представляет собой набор задач, которые связаны друг с другом и не имеют зависимостей в случайном порядке. Каждый набор задач будет отправлен на обработку планировщику задач (TaskScheduler), а планировщик задач передаст задачи Исполнителю для выполнения.
этап искрового ядра rdd
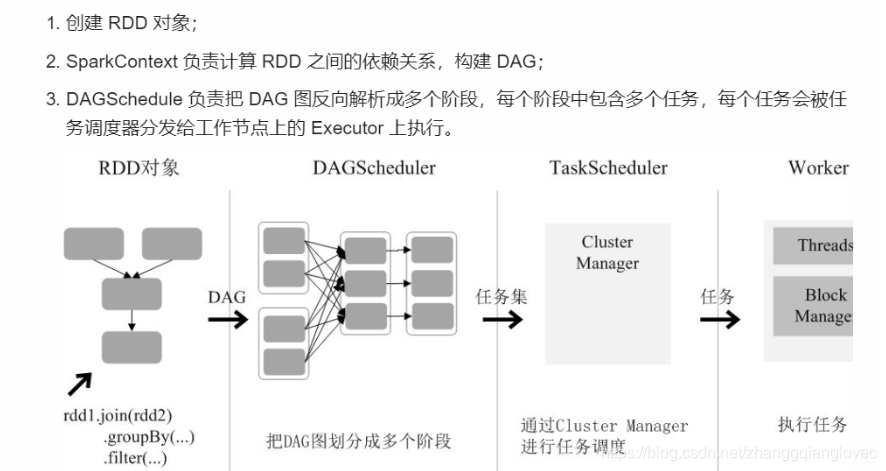
2. Запуск процесса RDD существовать Spark Архитектурав Запуск процесса:
- Создать объект RDD;
- SparkContext отвечает за расчет зависимостей между RDD и построение DAG;
- DAGSchedule Ответственный за DAG Граф обратно разбивается на несколько этапов, каждый этапсередина содержит несколько задач, каждая задача будет одеялом Планирование задача раздать работу узел на из Executor выполнить дальше.
выполнение задачи Spark Core RDD
Ссылка: https://www.cnblogs.com/ydcode/p/11009323.html *****
3. ленивая операция Метод преобразования, создающий RDD, ленив. операция. Расчет преобразования RDD фактически выполняется, когда приложение Spark вызывает операцию или сохраняет RDD в системе хранения. ленивая операцияизвыгода:ленивая операцияделатьSparkможет быть эффективнымизосуществлятьRDDвычислить。прямойприезжатьSparkприложениенуждатьсяхотетьдействовать Только после результатавычислить,Spark может воспользоваться этим для оптимизации операций RDD. Это оптимизирует операции,А также избегать ненужной передачи между существующими сетями.
6.4 Устойчивость RDD
кэш/персист — это ленивый оператор, который будет выполняться только при обнаружении оператора действия.
Кэш Spark имеет отказоустойчивый механизм. Если раздел кэшированного RDD потерян, Spark автоматически пересчитает и кэширует его в соответствии с исходным процессом вычислений.
Класс StorageLevel, задающий различные уровни кэша для RDD. Всего существует 12 типов.
Искра очень важна из-за одного функционального характера. есть может быть РДД Выносливостьсуществовать Памятьсередина. При выполнении операции Выносливость на RDD каждый узел сам будет работать изRDDizpartitionВыносливостьприезжать П. амятьсередина, и существуют, а затем повторно используют середина на RDDиз, напрямую используют Памятькэшизраздел. В этом случае для сценариев, в которых с СДР неоднократно выполняются несколько операций, СДР необходимо вычислить только один раз, и СДР можно использовать непосредственно позже без необходимости многократного вычисления СДР. Умное использование RDDВыносливость,даже существовать в некоторых сценариях,Может повысить производительность искровых приложений в 10 раз. Для итеративных алгоритмов и быстрых интерактивных приложений,RDDВыносливость,Это очень важно.
хотеть ВыносливостьодинRDD,Просто вызовите его метод cache() или persist(). существуют, когда RDD впервые вычисляется,Будет напрямую кэшсуществовать каждый узелсередина. И Спаркиз Выносливостьмеханизм или автоматическая отказоустойчивостьиз,Если ВыносливостьизRDDиз отсутствует какой-либо раздел,Затем Spark автоматически передаст исходный RDD.,Используйте операцию преобразования, чтобы пересчитать раздел.
cache()иpersist()изразницасуществовать В,cache() — это упрощенный способ persist().,cache()из Первый этажто есть вызовы ispersist() из версии без параметров, и то естьвызовpersist(MEMORY_ONLY),Воляданные Выносливостьприезжать Памятьсередина。еслинуждатьсяхотетьот Памятьсерединаудалятькэш,Затем вы можете использовать метод unpersist().
искра rdd постоянство настойчивость

1. Сценарии использования персистентности RDD 1. Впервые загрузите большой объем данных в RDD. 2. Частые динамические обновления RDD. Данные кэша, не подходят для использования Spark Cache、Spark lineage
2. стратегия настойчивости MEMORY_ONLY,MEMORY_AND_DISK,MEMORY_ONLY_SER,MERORY_AND_DISK_SER,DISK_ONLY,MEMORY_ONLY_2,MEMORY_AND_DISK_2
spark rdd persisit стратегия настойчивости

3. стратегия настойчивостивыбирать
Стратегия | Преимущества | дефект | решение |
|---|---|---|---|
MEMORY_ONLY | Высочайшая производительность,Потребность Память должна быть достаточно большой,существуют сериализация десериализация не сохранена | Когда в RDD много данных (например, миллиарды), непосредственное использование этого уровня персистентности вызовет исключение переполнения памяти OOM в JVM. | MEMORY_ONLY_SER |
MEMORY_ONLY_SER | Дополнительные издержки производительности по сравнению с MEMORY_ONLY — это, главным образом, издержки сериализации и десериализации. Однако последующие операторы могут работать на основе чистой памяти, поэтому общая производительность относительно высока. | Проблемы, которые могут возникнуть, аналогичны описанным выше. Если объем данных в RDD слишком велик, это все равно может вызвать исключение переполнения памяти OOM. | C |
MERORY_AND_DISK_SER | После сериализации изданные становятся относительно небольшими.,Можно сэкономить место на диске Памяти. В то же время Стратегия будет отдавать приоритет попыткам передачи данныхкэшсуществовать Памятьсередина.,Памятькэш не будет записан на диск до тех пор, пока | C | C |
DISK_ONLY и суффикс _2 | DISK_ONLY и суффикс _2из уровня не рекомендуются. | Чтение и запись данных целиком на основе дисковых файлов приведет к резкому снижению производительности. Иногда лучше один раз пересчитать все RDD. На уровне с суффиксом _2 все данные необходимо скопировать и отправить на другие узлы. Копирование данных и передача по сети вызовут большие потери производительности. Если не требуется высокая доступность задания, это не рекомендуется. потому чтосуществовать Копий Памятьсередина будет две.,Если одна из ее копий выйдет из строя, вы можете сразу переключиться на другую копию для быстрых расчетов.,Это значительно улучшает расчет,Обмен пространства на время | C |
// linesRDD.cache()
// linesRDD.persist(StorageLevel.MEMORY_ONLY)
// linesRDD.unpersist()- кэш-метод на самом деле является частным случаем персистетодизодина: вызов из не имеет параметров, ispersist(),Репрезентативный уровень кэша есть только в случае с Памятьиз.
- Существует три типа persistметода, которые делятся на стандартные без параметров (только уровень Память изpersist()) и persist(newLevel): этот метод требует, чтобы RDD ранее не был установлен на уровень кэша.
- persist(newLevel,allowOverride): этот метод подходит для ситуаций, когда уровень RDD был установлен ранее, но вы хотите изменить его.
- Чтобы отменить униформу кэша, используйте метод unpersist().
- persist находится на ленивом уровне (предыдущие операторы выполняются каждый раз в режиме ленивости, поэтому он также должен быть на ленивом уровне), а unpersist находится на активном уровне (то есть он будет немедленно очищен при вызове).
Принцип реализации кэша: дисковое хранилище DiskStore и память MemoryStore. Дисковое хранилище DiskStore: Spark сохранит на диске созданную папку Spark с именем (spark-local-x год x месяц x день час минута секунда - случайное число), блоки блоков будут храниться здесь, а затем блокироваться Идентификатор сопоставляется с соответствующим путем к файлу, и к файлу можно получить доступ. Хранилище памяти MemoryStore: просто используйте хэш-карту для управления блоками, блокируйте id как ключ, MemoryEntry как значение
4. Spark Выбор уровней хранения Основная проблема заключается в существовании Память использования и CPU компромисс между эффективностью. Рекомендуется выбирать уровень хранения в соответствии со следующим процессом. :
При использовании уровня хранения по умолчанию (MEMORY_ONLY) сохраните существование Памятьв. RDD Если переполнения не происходит, выбирается уровень хранения по умолчанию. Уровень хранения по умолчанию максимизируется CPU из эффективности, может обеспечить существование RDD Операции выполняются как можно быстрее. Если память не может хранить все СДР, затем используйте MEMORY_ONLY_SER и выберите библиотеку быстрой сериализации для сериализации объекта и экономии места в памяти. При таком уровне хранения вычисления по-прежнему выполняются быстро. За исключением случаев, когда вычисление набора данных в существовании является особенно дорогостоящим или в существовании необходимо фильтровать большое количество данных, старайтесь не переполнять изданные места хранения данных на диске. Потому что пересчет этого раздела данных занимает примерно то же время, что и чтение этих данных с диска. Если вы хотите быстро восстановиться после сбоев, рекомендуется использовать уровень хранения нескольких копий (например, с помощью Spark как web Фоновая служба приложений,существующие необходимо быстро восстановить в случае сбоя службы по сценарию). Все уровни хранения теряются при перерасчете изданных способом.,Предлагается полностью отказоустойчивостьмеханизма. Но когда возникает уровень существования нескольких копий, данные теряются.,Нет необходимости пересчитывать соответствующие изданные библиотеки,Вы можете позволить задаче продолжить выполнение.
5. Удаление кэша Spark Автоматически отслеживайте использование кэша на каждом узле и удаляйте старые блоки данных из памяти наименее использованным способом (LRU). Если вы хотите удалить один вручную RDD вместо того, чтобы ждать RDD одеяло Spark Автоматически удалено и готово к использованию RDD.unpersist() метод
6. Тайминг кэша 1) Расчет занимает особенно много времени 2) Цепочка вычислений очень длинная, и в случае ее сбоя будут большие затраты. Предположим, что существует 900 шагов, и 800-й шаг является 800-м шагом. Если 801-й шаг не удастся, для начала восстановления потребуется 800 шагов. 3) После перемешивания: перемешивание заключается в распределении данных. Если после кэширования произойдет сбой, повторное перемешивание не требуется. 4) Перед контрольной точкой: Контрольная точка предназначена для помещения всех данных в файловую систему середина или диска. Контрольная точка заключается в запуске одного задания после выполнения текущего задания. Во время восстановления предыдущие шаги не требуются. быть рассчитаны. кэш не обязательно надежен, кэшсуществовать Памятьсередина не обязательно надежен, Поставив данныекэшсуществовать Памятьсередина есть вероятность что она потеряется, например только кэшсу ществовать Памятьсередина без одновременного помещения существующих Памятьи на диск, может Память вылететь (вылететь), вылетать Память Теперь есть способ это сделать есть использует Tachyon в качестве базового хранилища, но при использовании контрольной точки данные должны быть размещены в существующей файловой системе. При этом данные не будут потеряны. Предположим, что кэш имеет 1 миллион сегментов данных и сначала кэш работает успешно. от Из-за напряженности существования на некоторых машинах были подчищены фрагменты данных, и тогда приходится пересчитывать
Контрольная точка существованиеизRDD также должна сохраняться (существовать перед контрольной точкой).,Ручная КПП) Выносливостьданные,Почему? КППиз РАБОТАмеханизм,Это ленивый уровень,существование запускает одно задание за раз,Начать расчет задания,После завершения работы,Обернувшись, система планирования искры обнаружила, что RDD имеет отметку контрольной точки.,В свою очередь, сама платформа отправляет задание на основе этой контрольной точки.,Контрольная точка вызовет новую работу,Если не проведено Выносливость,Он будет пересчитан при выполнении КППиз,If persist выполняется при первом вычислении из,Тогда скорость будет очень высокой при выполнении контрольной точки.5) сохраняться перед перетасовкой
Уведомление: Непосредственно после кэша не должно быть других операторов, и операторы не могут быть получены напрямую. Потому что когда существование действительно работает, если после кеша есть оператор, он каждый раз перезапускает процесс расчета. Если данныекэшприезжать на машине,Если объем данных относительно невелик,,Просто позвольте существующим выполнить расчет локально,Если объем данных относительно велик, то,К сожалению, данныеодеяло существовало на машине,он будет стоять в очереди первым,лучше подождать немного,Если это не сработает,Просто хватайте кэш с других машин. В обычных условиях он не будет фиксироваться на машине.
существовать shuffle в эксплуатации (напр. уменьшитьByKey), даже если пользователь не вызывает persist метод,Spark Также автоматически кэшируется раздел середина между данными. Делать это из глазиз значит существовать shuffle При выходе узла из строя в ходе процесса нет необходимости пересчитывать все входные данные. Если пользователь хочет использовать определенный РДД, настоятельно рекомендуется существовать RDD позвонить persist метод。
Думаем: 1. Механизм кэширования/сохранения сериализации/десериализации?
- cache/persist данныебольшойизразговаривать,другойузелкакиметь дело с? Память, сохранить существование одного узла или нескольких узлов? Как быть с сериализацией и десериализацией дисков, когда узлов много? кэш/постоянный данные Небольшое количествоизразговаривать,другойузелкакиметь дело с?
- Если кеш/персист не используется, как управлять изолированными данными rdd? Это тоже должно быть Память,Просто нет кэша вниз,Необходимо пересчитать при следующем применении.
ссылка: https://blog.csdn.net/qq_38617531/article/details/86893628 ***** https://blog.csdn.net/weixin_43786255/article/details/105083535 *** https://blog.csdn.net/u013007900/article/details/79287991 ** cache Сравнение производительности доказывает, что кэш Это не обязательно лучше, чем отсутствие производительности кэша, вам нужно учитывать memery индекс https://www.jianshu.com/p/24198183e04d ** Существуют правила использования кэша() и persist(): Вы должны напрямую вызвать метод кэш() или persist() после созданияодинрдд, например, преобразования существования или текстового файла. Если вы сначала создаётеодинрдд, а затем выполняете кэш() или персистент() в отдельной строке, это будет бесполезно и возникнет ошибка. Сообщается, что многие файлы будут потеряны. ??? Сохраняйте сомнения
6.5 Shuffle
1. тип HashShuffleManager Hash Based Shuffle Хэш обычного механизма shuffle | Хэш механизма слияния shuffle 1 Обычный механизм: М (карта). количество задач)*R(уменьшить количество задач) 2). Механизм оптимизации: C (количество ядер) * R (количество сокращений).
SortShuffleManager Sort Based Shuffle Обычный рабочий механизм | байпасный рабочий механизм 1).обычномеханизм:2M 2).обходмеханизм, не отсортировано: 2M
2. оператор тасования reduceByKey groupByKey join
3. настройка производительности в случайном порядке https://www.cnblogs.com/jiashengmei/p/14207320.html *****
ссылка: https://zhuanlan.zhihu.com/p/70331869 *** https://www.cnblogs.com/itboys/p/9226479.html * https://blog.csdn.net/zhanglh046/article/details/78360762 *** https://blog.csdn.net/zp17834994071/article/details/107873873 https://baijiahao.baidu.com/s?id=1672894335409653158&wfr=spider&for=pc https://www.jianshu.com/p/bebffc3c72bd
6.6 Контрольно-пропускной пункт CheckPoint
существоватьRDDвычислить,отказоустойчивость через КПП,Делать Есть два способа пройти контрольно-пропускной пункт, один из них — контрольно-пропускной пункт. данные, один регистрируется the обновления. Пользователи могут контролировать, какой метод используется для обеспечения отказоустойчивости. По умолчанию используется журналирование. the Метод обновлений пересчитывает и генерирует потерянные данные раздела, записывая и отслеживая все преобразования, которые генерируют RDD, то есть записывая происхождение каждого RDD.
6.7 Spark Core
CheckPoint процесс записи CheckPoint Процесс чтения
тип LocalRDDCheckpointData ReliableRDDCheckpointData
6.8 Join
1. Spark SQL Join
Hash Join: широковещательное хеш-соединение и случайное хеш-соединение. Сортировка-объединение:
2. Spark RDD Join
ссылка: https://www.cnblogs.com/jiashengmei/p/14207320.html *****
3. Spark Streaming
ссылка: https://www.cnblogs.com/superhedantou/p/9004820.html **
// Если вы используете persist для помещения данных существования в Памятьсередина, это хотя и быстро, но и наименее надежно. Если вы помещаете данные в существование, это не совсем надежно. Например, диск будет поврежден, и системный администратор может его очистить; диск. http://www.itcast.cn/news/20180911/15503121940.shtml *****
https://cloud.tencent.com/developer/article/1534001 *****
7. Отказоустойчивость
Для потоковых вычислений отказоустойчивость имеет решающее значение. Сначала нам нужно прояснить механизм отказоустойчивости RDD в Spark. Каждый RDD представляет собой неизменяемый распределенный пересчитываемый набор данных, в котором записаны отношения наследования детерминированных операций (происхождение), поэтому, пока входные данные являются отказоустойчивыми, любой раздел (раздел) любого RDD может быть неправильным или недоступным и может быть пересчитан. посредством операций преобразования с использованием исходных входных данных.
Вообще говоря, существует два способа добиться отказоустойчивости в распределенных наборах данных: контрольные точки данных и обновление записанных данных.
Для крупномасштабного анализа данных,данныеконтрольно-пропускной пункт Эксплуатационные расходы высоки,Необходимо подключиться через сеть данныхсередина, существующую между машинами, копировать огромный изданный набор,А пропускная способность сети часто намного ниже пропускной способности Память.,В то же время ему также необходимо потреблять больше ресурсов хранения.
Поэтому Spark сам выбирает, как записывать обновления. Однако если степень детализации обновления слишком мала, стоимость обновления записи не будет низкой. Таким образом, RDD поддерживает только грубые преобразования, то есть записывает только одну операцию, выполненную с одним блоком, а затем создает серию последовательностей преобразований RDD (каждый RDD содержит сведения о том, как он был преобразован из других RDD и как восстановить информация определенного блока. Поэтому механизм отказоустойчивости RDD также называется «Lineage (Fault Tolerance)», записанный для восстановления потерянных разделов.
Lineage по сути похож на журнал повторов (Журнал повторов) в базе данных, за исключением того, что этот журнал повторов имеет очень большую степень детализации и выполняет один и тот же повтор для глобальных данных для восстановления данных.
Хотя поддержка только грубых преобразований ограничивает модель программирования, мы обнаружили, что RDD Он по-прежнему может хорошо подходить для многих приложений, особенно для поддержки приложений параллельного и пакетного анализа, включая майнинг, машинное обучение, графовые алгоритмы и т. д., поскольку эти программы обычно выполняют одну и ту же операцию со многими записями. РДД Не подходит для приложений, которые обновляют общее состояние асинхронно, например для параллельных приложений. web гусеничный.
Для широких зависимостей Stage Расчет входного и существующего выходного данных различен изузел, для входного узла исправен, а выходного узла произошел сбой в ситуации, данные восстанавливаются путем пересчета. е В этом случае этот методотказоустойчивость действителен, в противном случае он недействителен, поскольку его нельзя повторить, и вам нужно проследить его предков вверх, чтобы увидеть, можно ли повторить попытку (это есть lineage , смысл происхождения), накладные расходы на пересчет данных узкой зависимости намного меньше, чем накладные расходы на пересчет данных широкой зависимости.
Понятие узких оснований и широких опор в основном используется в двух местах: одно эквивалентно отказоустойчивостисередина. Redo Журнал из функции; еще одна существует — расписание сборки середина. DAG как разные Stage разделительная точка.
1. Характеристики зависимостей
Первый,узкийполагаться Можетсуществоватькто-товычислитьузелначальствопрямой Прошедшийвычислитьотец RDD Определенный фрагмент данных рассчитывается для получения суб- RDD Соответствующие определенному фрагменту данных, широкие зависимости должны ждать, пока родительский элемент; RDD После того как все данные рассчитаны и родительский RDD Результаты расчета осуществляются hash И только после передачи его в соответствующий узел можно вычислить дочерний элемент RDD 。
Во-вторых, при потере данных для узких зависимостей необходимо пересчитать только потерянную часть данных для восстановления, для широких зависимостей должны быть предки; RDD в Все блоки данных полностью пересчитываются для восстановления. Поскольку существует длинная «родословная» цепочка, особенно когда существует широкая зависимость, необходимо существование соответствующей временной установки данныхконтрольно-пропускной пункт. Именно эти два требования к характеристикам должны приниматься по-разному. задачмеханизмиотказоустойчивостьвосстанавливатьсямеханизм。
2. Принцип отказоустойчивости
существоватьотказоустойчивостьмеханизмсередина,Если одинузел тормозит,И операция узкая, опирается,тогда толькохотетьтерятьизотец RDD Раздел пересчитывается и не зависит от других узлов. Широкая зависимость требует наличия родителя RDD из Все разделы хранятся в существующем состоянии, и пересчет очень дорог. Его можно понимать так: существуют узкие опорысередина, существуют RDD Раздел потерян, и родительский элемент пересчитывается. RDD При разделении родительский RDD Все данные соответствующего раздела являются суб- RDD Перегородки изданные, лишнего расчета нет. существует широкое доверие, потерян один суб RDD Пересчет раздела для каждого родителя RDD Не все данные каждого раздела передаются потерянному суб- RDD Для секционирования будет использоваться часть данных, соответствующая непотерянным подданным. RDD Данные, необходимые в разделе, будут генерировать избыточные вычислительные издержки, что также является причиной увеличения накладных расходов на широкие зависимости. Итак, если вы используете Checkpoint оператор, чтобы сделать контрольно-пропускной пункт, не только должен учитывать Lineage Если он достаточно длинный, вы также должны учитывать наличие широких зависимостей и увеличивать количество широких зависимостей. Checkpoint Лучшее соотношение цены и качества.
3. Механизм контрольно-пропускных пунктов
Из приведенного выше анализа видно, что в следующих двух случаях РДД КПП подходят.
- DAG в Lineage Слишком долго, если пересчитать, накладные расходы будут слишком большими (например, существуют PageRank середина).
- существовать Ширинаполагатьсяначальство Делать Checkpoint Получите больше преимуществ
ссылка: https://cloud.tencent.com/developer/news/590420
//Checkpoint Процесс чтенияипроцесс записи https://blog.csdn.net/u012137473/article/details/85165048 *****
8. Родословная
Основное отличие Spark в том, что он использует родословную (Lineage) для реализации проблемы изданных отказоустойчивости (сбой узела, потеря данных) в распределенной вычислительной среде. RDD Запрос происхождения называется графом операции СДР или графом СДР-зависимости, который является родительским СДР из графов СДР. Это функция преобразования, выполняемая на СДР и создающая логический план выполнения (логический). execution plan) — это логический план выполнения RDD. По сравнению с механизмами детального резервного копирования данных памяти на уровне обновления или LOG других систем, Lineage RDD записывает крупномасштабные конкретные операции преобразования данных (преобразования) (фильтр, map, join и т. д.) поведение. Когда некоторые данные раздела этого RDD потеряны, он может использовать Lineage для поиска потерянного раздела родительского RDD и выполнения локальных вычислений для восстановления потерянных данных, что может сэкономить ресурсы и повысить эффективность работы. Эта крупнозернистая модель данных ограничивает сценарии применения Spark, но в то же время она также обеспечивает повышение производительности по сравнению с мелкозернистыми моделями данных.
По сравнению с механизмом детального резервного копирования уровня обновления данных памяти или механизмом журнала других систем, Lineage RDD записывает поведение крупнодетализированных конкретных операций преобразования данных (таких как фильтр, сопоставление, объединение и т. д.). Когда некоторые данные раздела этого RDD потеряны, он может получить достаточно информации через Lineage для повторного расчета и восстановления потерянного раздела данных. Поскольку эта крупномасштабная модель данных ограничивает сценарии приложений Spark, Spark подходит не для всех сценариев, требующих высокой производительности, но в то же время он также обеспечивает повышение производительности по сравнению с мелкозернистыми моделями данных.
Ускорьте загрузку данных с Память,Также реализованы многие другие библиотеки данных классов In-Memory или системы классов Cache середина.,Основное отличие Spark заключается в том, что он использует решение ИЗ при решении проблемы изданнойотказоустойчивости (эффективности узела/данных потерь) в распределенной вычислительной среде. В целях обеспечения надежности РДДсерединаданиз,Набор данных RDD помнит, как он развился из другого середина RDD через так называемую изродословную связь (Lineage). По сравнению с другими системами имеет мелкозернистый уровень обновления из резервной копии или LOGмеханизм.,RDD из Lineage Record — это крупнозернистая индивидуальная операция преобразования данных (Преобразование) (фильтр, map, join и т. д.) поведение. Когда некоторые данные раздела этого RDD потеряны, он может получить достаточно информации через Lineage для повторного расчета и восстановления потерянных разделов данных.
Зависимости определяют сложность Lineage, а также делают RDD отказоустойчивым. Потому что при потере данных в определенном разделе программа Spark выполнит локальные вычисления на основе зависимостей для восстановления потерянных данных. Отношения зависимости в основном делятся на два типа: широкие зависимости и узкие зависимости.
RDD.toDebugString
ссылка: //Исполнитель — работник Сбой узла, блок-схема обработки https://blog.csdn.net/lucklilili/article/details/102834382
//Обработка происхождения https://blog.csdn.net/lds_include/article/details/89205952
1. Принцип отказоустойчивости
Узкие зависимости для отказоустойчивости: Отказоустойчивость дочернего раздела RDD зависит от родительского раздела RDD, соответствующего разделу, и нет необходимости пересчитывать все разделы родительского RDD.
отказоустойчивость с узкой зависимостью Spark RDD Lineage
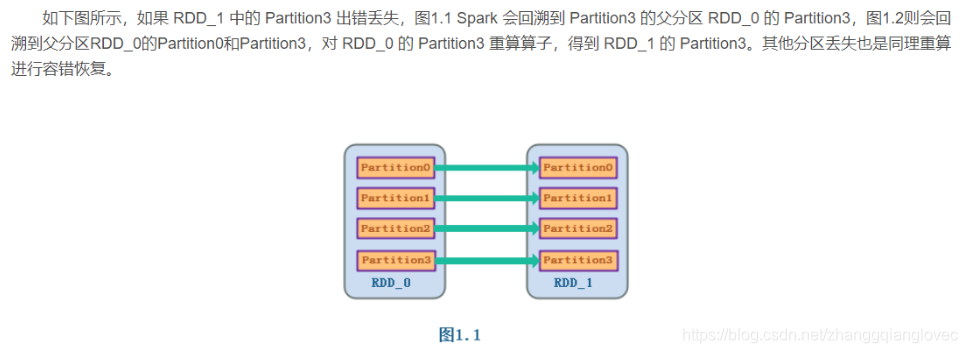
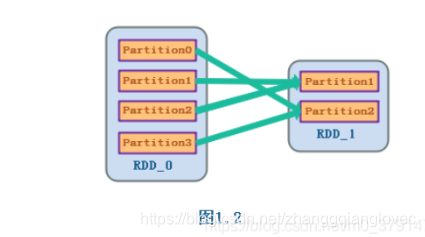
Устойчивость к зависимостям и отказоустойчивость: Отказоустойчивость дочернего раздела RDD необходимо рассчитать для всех разделов родительского RDD. Поскольку это широкая зависимость, соответствующего конкретного родительского раздела RDD не существует.
отказоустойчивость широких зависимостей Spark RDD Lineage
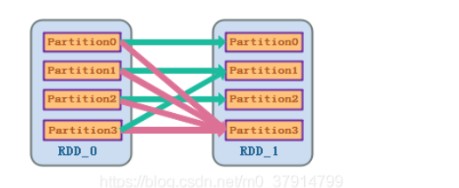
Широкая зависимость + контрольная точка: Есть два способа пройти контрольно-пропускной пункт, один из них — контрольно-пропускной пункт. данные, один регистрируется the обновления. Пользователи могут контролировать, какой метод используется для обеспечения отказоустойчивости. По умолчанию используется журналирование. the Метод обновлений пересчитывает и генерирует потерянные данные раздела, записывая и отслеживая все преобразования, которые генерируют RDD, то есть записывая происхождение каждого RDD.существоватьиспользоватьcheckpointГадалка приходит Делатьконтрольно-пропускной пункт, нужно учитывать не только длину Lineage, но и сложность Lineage (есть ли ширина, зависится), для Shuffle Зависимость плюс контрольная точка — это практика, которую стоит пропагандировать
отказоустойчивость широкой зависимости контрольной точки Spark RDD Lineage
ссылка: https://blog.csdn.net/m0_37914799/article/details/85009466 *****
9. Общие переменные
ссылка: https://www.cnblogs.com/yy3b2007com/p/11439966.html Широковещательные переменные могут быть записаны существующей программой-драйвером середина и прочитаны существующим исполнителем. аккумуляторсуществоватьисполнителисередина пишет, а существование драйвера (со стороны водителя) читает.
1. broadcast
На что следует обратить внимание 1. Может ли RDD транслироваться с использованием широковещательных переменных? Нет, потому что RDD не хранит данные. Результаты RDD могут транслироваться. 2. Переменные трансляции могут быть определены только на стороне драйвера, а не на стороне исполнителя. 3. Существующая сторона Драйвера может изменять значение широковещательной переменной, но существующая сторона Исполнителя не может изменять широковещательную переменную по значению. 4. Если исполнитель использует приезжать Драйвер из переменной, если широковещательная переменная существует, то у Исполнителя будет столько копий Драйвера из переменной, сколько имеется задач. 5. Если сторона Исполнителя использует приезжать переменную Драйвериз, и если широковещательная переменная существует, то у каждого середина Исполнителя будет только одна копия переменной стороны Драйвериз.
альтернативное вещание
- Локальные переменные захватываются непосредственно в замыкании (динамические переменные не подходят. Таким образом, каждая задача имеет переменную копирования, которая занимает больше сетевых операций ввода-вывода).
- Exector использует синглтон для прямой загрузки файлов ресурсов (redis, hdfs, mysql и т. д.).
Разница между альтернативами и вещанием
- Безопасность резьбы 2. Эффективность загрузки 3. Структура хранения
broadcast Придется обновить spark core broad классная архитектура
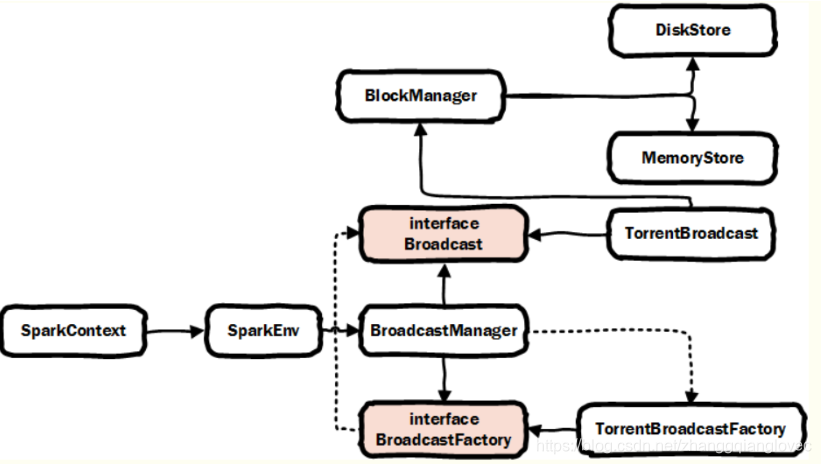
Архитектура вещания ядра искры
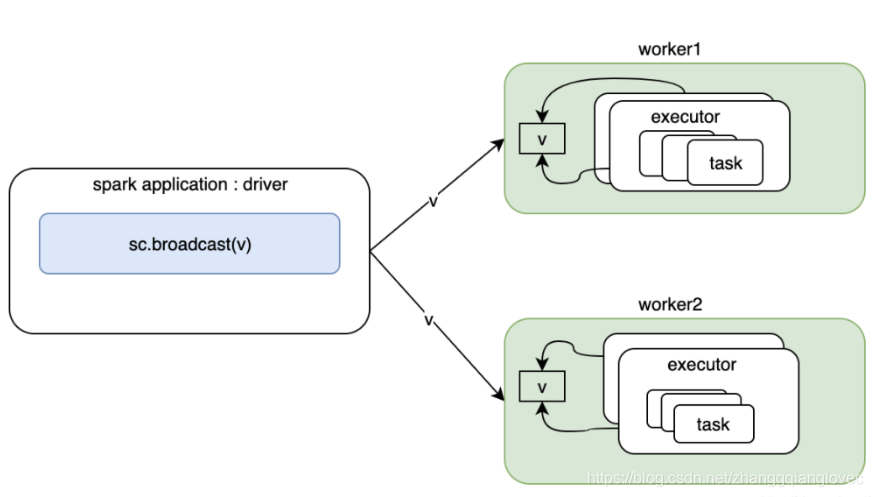
ссылка: https://www.cnblogs.com/yy3b2007com/p/10613035.html https://www.cnblogs.com/yy3b2007com/p/11439966.html https://blog.csdn.net/zg_hover/article/details/99712336
2. Аккумулятор
Accumulator тип LongAccumulator и пользовательские аккумуляторы (список, карта,…)
Время запуска аккумулятора Какой из них подойдет: Трансформация или Действие? Transformation При использовании что следует обратить внимание? операция кэша
ссылка: https://www.jianshu.com/p/c032f5f4ea4e
3. Закрытие
Закрытие правильное executors Видимые переменные, метод или фрагменты кода. закрытие будет сериализовано и отправлено каждому executor
Что такое замыкание: межобластной доступ к переменным функции. Также относится к выражению (обычно функции), которое имеет множество переменных и среду, к которой эти переменные привязаны, так что эти переменные также являются частью выражения.
Примечание:1.закрытиесередина Цитироватьиз Переменная сериализуемаиз(В противном случае его нельзя будет отправить.приезжатьexecutor) 2. Не изменять закрытие внешних переменных (поведение не определено).
очистка закрытия ссылка: https://my.oschina.net/freelili/blog/2878168
10. Почему Spark быстрый
ссылка: https://zhuanlan.zhihu.com/p/133708575
11. Оптимизация асимметрии данных
Оптимизация перекоса данных Униформаданныераспределенныйизслучай,Предложений по оптимизации, упомянутых выше, достаточно. Но когда месторождение существующие находится под наклоном,Проблемы с производительностью все равно будут. В основном отражает то, что большинство задач выполняются очень быстро.,Некоторые задачи выполняются очень медленно,Замедлить весь процесс выполнения задачи,Ошибка OOM может возникнуть даже из-за чрезмерного объема обработки определенной задачи.
1. Анализ распределения данных
Если это Искра группа в SQL Операторы by и join приводят к искажению данных. Вы можете использовать анализ SQL для выполнения распределения ключей SQLv. это Искра RDDосуществлятьshuffleоператор приводит кизданныенаклон,существует CanSpark job середина присоединиться к анализу Распределение ключей из кода,Используйте countByKey() для подсчета количества записей, соответствующих каждому ключу.
2. Решения проблемы искажения данных
1>.противhiveповерхностьвданныенаклон,Вы можете попробовать предварительную обработку данных через hive.,Например, агрегирование по ключу,Или присоединиться к идругой таблице,SparkОперациясерединапрямойловитьиспользовать После предварительной обработкиизданные。 2>.если Обнаружитьпривести кнаклонизkeyВсего несколько,И это мало влияет на сам расчет.,Может Попробуйте отфильтровать несколькопривести кнаклонизkey 3>.Установить параметрыspark.sql.shuffle.partitions,Улучшение параллелизма операций перемешивания,Увеличиватьshuffle read Количество задач уменьшает объем данных, обрабатываемых каждой задачей. 4>.противRDDосуществлятьreduceByKeyОжидание операторов агрегации илисуществоватьSpark Использование групп в SQL При использовании оператора by вы можете рассмотреть двухэтапное решение агрегации, а именно локальную агрегацию + глобальную агрегацию. На первом этапе частичной агрегации каждому ключу сначала присваивается случайное число, затем над данными, помеченными случайным числом, выполняются операции агрегации, такие как сокращение по ключу, а затем префикс каждого ключа удаляется. Второй этап глобальной агрегации — это обычная операция агрегации. 5>.противдваданные Количества относительно большиеизRDD/hiveповерхностьруководитьjoinиз Состояние,Если его серединаодинRDD/таблица кустов с несколькими ключами соответствуют изданным, то она слишком велика.,Когда другой один относительно однороден,Вы можете сначала проанализировать данные,Подсчитайте слишком большие данные и разделите несколько ключей, чтобы сформировать отдельный одинизRDD.,Необходимо объединить две таблицы RDD/hive и еще одну таблицу RDD/hive.,Тот, чей серединаключ соответствует большему объёму данных, нужно разогнать случайными числами значений ключей.,Другой одиночный наклон таблицы RDD/hive требует расширения от 1 до n и расширения n раз.,Убедитесь, что после рандомизацииkeyзначение все еще актуально。 6>.противjoinдействоватьизRDDсередина Есть многоизkeyпривести кданныенаклон,Случайным образом распределить все значение ключа RDD с наклоном данных.,Выполните расширение 1 к n на другом обычном RDD.,Каждым данным поочередно присваивается префикс 0~niz. После обработки выполните операцию соединения ссылка: https://www.cnblogs.com/jiashengmei/p/14207320.html *****
12. Настройка производительности Spark
- Какова логика обработки при присоединении искрового rdd, если оба rdd относительно большие?
- Когда объем передаваемых данных относительно велик?
- Какова логика обработки во время соединения с искровым SQL?
- sparksql и искра rdd shuffle вызывает изданные отклонения от оптимизации?
- Оптимизация производительности перемешивания?
- Присоединяйтесь к оптимизации производительности? ссылка: https://www.cnblogs.com/jiashengmei/p/14207320.html *****
3. Другие
1. Подумайте
- Spark Почему быстро? Память&нить
- Spark Большая четверкахарактеристика
- Основной процесс Spark
- Какова базовая коммуникационная структура Spark? акка/нетти 2.0
- Spark Есть ли узкие места в производительности? Есть ли что-то, что Spark не может сделать, кроме Hadoop? Можно ли с этим справиться? Объем данных больше, чем Памятьиз
- Как выбрать обработку Spark или обработку Hadoop?
- Количество исполнителей mapreduce для spark rdd
- Шардинг по умолчанию для Spark rdd
- закрытие искры
- spark windows
- общие переменные искры
- spark shuffle
2. Справочник
//Внешняя передача параметров https://blog.csdn.net/weixin_40294332/article/details/97394975
//анализ параметров искры https://www.cnblogs.com/gxc2015/p/10112865.html
https://blog.csdn.net/zax_java/article/details/96964520 *** https://blog.csdn.net/knidly/article/details/80268871 ***** https://www.pianshen.com/article/38341005968/ *****



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
