Обновление архитектуры кластера версии Elasticsearch 7.14 для горячих и холодных кластеров
Роль узла Elasticsearch (роль узла)
master
Он играет роль главного узла и имеет полномочия управлять кластером. Когда узлу предоставляется эта роль, он может быть избран главным узлом.
node.roles: [ master ]использовать
Отвечает за легкие операции в масштабе кластера, такие как создание или удаление индексов, отслеживание того, какие узлы являются частью кластера, и принятие решения о том, какие сегменты каким узлам назначены.
voting-only
В роли мастера есть еще одна роль — только для голосования. Следует отметить, что эта роль в основном используется для голосования при выборе главного узла в кластере. Фактически он не берет на себя другие обязанности главного узла (например, управление метаданными кластера и координацию операций кластера). В определенной степени это может упростить нагрузку на главный узел и позволить главному узлу больше сосредоточиться на управлении кластером.
node.roles: [ data, master, voting_only ]использовать
1. Выборы главного узла:
• Узлы только для голосования участвуют в голосовании по выборам главного узла, чтобы обеспечить более стабильный и надежный процесс выборов. Однако на самом деле они не возьмут на себя ответственность за мастерноду.
2. Стабильность кластера:
• Добавление узлов только для голосования может помочь достичь необходимого минимального количества главных узлов (minimum_master_nodes), тем самым улучшая стабильность кластера, особенно если количество главных узлов невелико.
3. Упрощение загрузки главного узла:
• Разделив голосование на выборах и фактические обязанности главного узла, можно разгрузить главный узел, позволяя ему сосредоточиться на задачах управления кластером.
data
Он играет роль узла данных, который используется для сохранения данных и выполнения операций, связанных с данными, таких как CRUD, агрегирование поиска и т. д. После получения роли данных узел будет иметь самые высокие разрешения узла данных. Будет иметь функциональность любого узла данных.
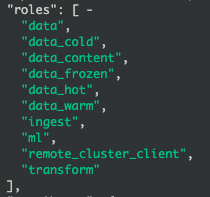
node.roles: [ data ]Если нам нужно указать конкретный уровень данных для узла,Например, укажитеdata_content,data_hot,data_warm,data_cold, ordata_frozen,тогда узел больше не будет иметь роли общих данных dataРоль。
data_content
Узлы роли data_content предназначены для хранения и обработки данных контента. Эти узлы обычно используются для хранения активных наборов данных и часто запрашиваемых данных, таких как содержимое веб-сайта, информация о пользователях и т. д.
node.roles: [ data_content ]использовать
1. Хранить активные данные:
• Узел data_content подходит для хранения активных наборов данных, к которым необходимо часто обращаться и обновлять. Обычно они настраиваются с более высокими параметрами производительности для обработки частых операций чтения и записи.
2. Улучшение производительности запросов:
• Поскольку эти узлы хранят данные активного контента, им обычно требуется высокая производительность запросов для удовлетворения требований к низкой задержке и высокой пропускной способности.
3. Упрощение управления данными:
• Отдельное хранение данных контента от холодных данных, горячих данных и т. д. помогает упростить управление данными и оптимизировать распределение ресурсов.
data_hot
Узлы в роли data_hot предназначены для хранения и обработки недавно проиндексированных и часто запрашиваемых данных. Узел data_hot обычно используется в сценариях обработки данных, которые обрабатывают запросы с высокой скоростью записи и низкой задержкой, например данные журнала в реальном времени, данные последних транзакций и т. д. Узлы, используемые для этой роли, обычно используют жесткие диски SSD в качестве носителей данных. Это используется для реализации сценариев реального времени, с малой задержкой и других бизнес-сценариев.
node.roles: [ data_hot ]использовать
1. высокая скорость записи:
• Узел data_hot используется для обработки частых операций записи, включая индексацию и запись данных в реальном времени. Эти узлы обычно оснащены высокопроизводительным оборудованием для поддержки быстрой записи данных и построения индексов.
2. Запрос с низкой задержкой:
• Поскольку узел data_hot хранит последние и активные данные, ему необходимо обеспечить быстрое время ответа на запрос, чтобы удовлетворить потребности запросов с малой задержкой.
3. кратковременное хранение:
• Данные на узлах data_hot обычно хранятся в течение короткого периода времени, а затем перемещаются на узлы data_warm или data_cold с помощью политики управления жизненным циклом индекса (ILM).
data_warm
Когда индекс слоя горячих данных больше не обновляется часто или запросов всего несколько, мы можем назначить роль data_warm узлу для хранения этого типа данных. Узлы в роли data_warm используются для хранения старых данных, к которым больше не часто обращаются, но которые все еще необходимо сохранять. Эти узлы обычно настраиваются на относительно недорогом оборудовании и подходят для хранения данных, переданных с узла data_hot. Роль data_warm играет важную роль в управлении жизненным циклом данных (ILM), помогая оптимизировать затраты на хранение и производительность запросов.
node.roles: [ data_warm ]использовать
1. Хранить старые данные:
• Узел data_warm хранит данные, которые еще необходимо сохранить, но к которым обращаются реже. Данные перемещаются из узлов data_hot в узлы data_warm для оптимизации хранения и эффективности запросов.
2. Оптимизируйте затраты на хранение:
• Эти узлы обычно настраиваются на менее дорогом оборудовании большей емкости, чтобы снизить нагрузку на хранилище.
3. Распределить нагрузку запросов:
• Перемещая менее часто используемые данные на узлы data_warm, вы можете снизить нагрузку на узлы data_hot, тем самым повышая производительность запросов во всем кластере.
data_cold
data_cold Узлы роли предназначены для хранения исторических данных, к которым редко обращаются. Основное использование этих узлов — Оптимизируйте. затраты на хранения, сохраняя при этом доступность данных. data_cold Узлы обычно настраиваются на недорогом оборудовании и подходят для долгосрочного хранения данных, которые необходимо сохранять, но редко запрашивают.
node.roles: [ data_cold ]использовать
1. Хранить исторические данные:
• Узел data_cold используется для хранения исторических данных, доступ к которым осуществляется очень редко. Эти данные по-прежнему ценны для бизнеса, но их редко запрашивают.
2. Оптимизируйте затраты на хранение:
• Эти узлы обычно настраиваются на недорогом оборудовании, чтобы минимизировать накладные расходы на хранение и при этом гарантировать доступность данных при необходимости.
3. Долгосрочное хранение данных:
• Узел data_cold подходит для хранения данных, которые необходимо хранить в течение длительного времени, например, для архивирования данных, требуемого в соответствии с требованиями законодательства.
data_frozen
Узлы в роли data_frozen предназначены для хранения архивных данных, к которым редко обращаются. Если нам нужно назначить узлу роль замороженного слоя data_frozen, рекомендуется использовать выделенный узел в качестве замороженного узла.
node.roles: [ data_frozen ]ingest
Узел с ролью приема. Узлы с ролью приема, в основном используемые для предварительной обработки и обработки документов, могут выполнять конвейер приема, который позволяет преобразовывать и обрабатывать документы перед их индексацией. Конвейер Ingest позволяет вам выполнить ряд процессов с вашими данными, прежде чем они попадут в Elasticsearch, например синтаксический анализ, преобразование или обогащение данных. Если процесс предварительной обработки сложен, рекомендуется настроить выделенный узел приема.
использовать
1. Предварительная обработка документов:
• Документы могут быть предварительно обработаны через конвейер Ingest перед индексацией в Elasticsearch. Например, вы можете анализировать строки журнала, извлекать поля, выполнять очистку и форматирование данных и многое другое.
2. сложная обработка данных:
• Используйте различные процессоры Ingest для выполнения сложных задач обработки данных, таких как анализ регулярных выражений, анализ Grok, обработка дат, переименование полей, удаление полей, добавление полей и т. д.
3. Снизить нагрузку на клиента:
• Перенос логики обработки данных с клиента на Elasticsearch упрощает код и логику клиентских приложений.
ml
Elasticsearch поддерживает выполнение задач машинного обучения. Если нам нужно выполнить связанные API машинного обучения, нам необходимо предоставить узлу роль ml, чтобы указать, что этот узел является узлом машинного обучения. При настройке роли ml рекомендуется также настроить на узле роль Remote_cluster_client. Избегайте ошибок, когда задания машинного обучения используют данные межкластерного поиска. Всем подходящим узлам, поиск которых необходимо выполнить в кластере, необходимо предоставить роль Remote_cluster_client.
node.roles: [ ml, remote_cluster_client]remote_cluster_client
Узлы в роли Remote_cluster_client используются для связи и координации с удаленными кластерами. Эта роль обычно используется в таких сценариях, как межкластерный поиск (CCS) и межкластерная репликация (CCR), позволяя одному кластеру подключаться в качестве клиента к другому удаленному кластеру для операций запроса или репликации.
node.roles: [ remote_cluster_client]использовать
1. Межкластерный поиск (Межкластерный поиск) Search, CCS):
• Позволяет искать и запрашивать данные из удаленных кластеров внутри локального кластера. Узлы в роли Remote_cluster_client отвечают за установление соединений с удаленными кластерами и выполнение запросов.
2. Межкластерная репликация Replication, CCR):
• Позволяет репликацию индексов данных из одного кластера в другой удаленный кластер. Узел с ролью Remote_cluster_client отвечает за связь с удаленным кластером и выполнение репликации данных в этом сценарии.
3. Единые запросы и управление:
• Настраивая удаленный кластер, узлы, использующие роль Remote_cluster_client, могут выполнять межкластерные операции в локальном кластере, упрощая сложность запросов к распределенным данным и управления ими.
transform
Узлы в роли преобразования используются для управления и выполнения задач преобразования данных. Преобразования данных (Transforms) — это функция Elasticsearch, используемая для преобразования данных из одного формата или структуры в другой. Роль преобразования играет ключевую роль в создании, выполнении и управлении задачами преобразования данных.
node.roles: [ transform, remote_cluster_client ]использовать
1. Агрегация и обобщение данных:
• Узел актера преобразования может объединять необработанные данные в обобщенные данные. Например, данные журнала могут быть объединены в ежедневную или почасовую статистику.
2. Сводные данные:
• Преобразование данных позволяет преобразовывать плоские записи в многомерные данные (например, сводные таблицы) для лучшего анализа и визуализации данных.
3. Преобразование в режиме реального времени и пакетное преобразование:
• Ролевой узел преобразования поддерживает преобразование данных в реальном времени и пакетное преобразование данных и может адаптироваться к различным сценариям и потребностям приложений.
4. Сложные расчеты и обработка:
• Преобразование данных может включать сложные вычисления и логику обработки для преобразования необработанных данных в более полезный и структурированный формат.
Однорежимный кластер Elasticsearch
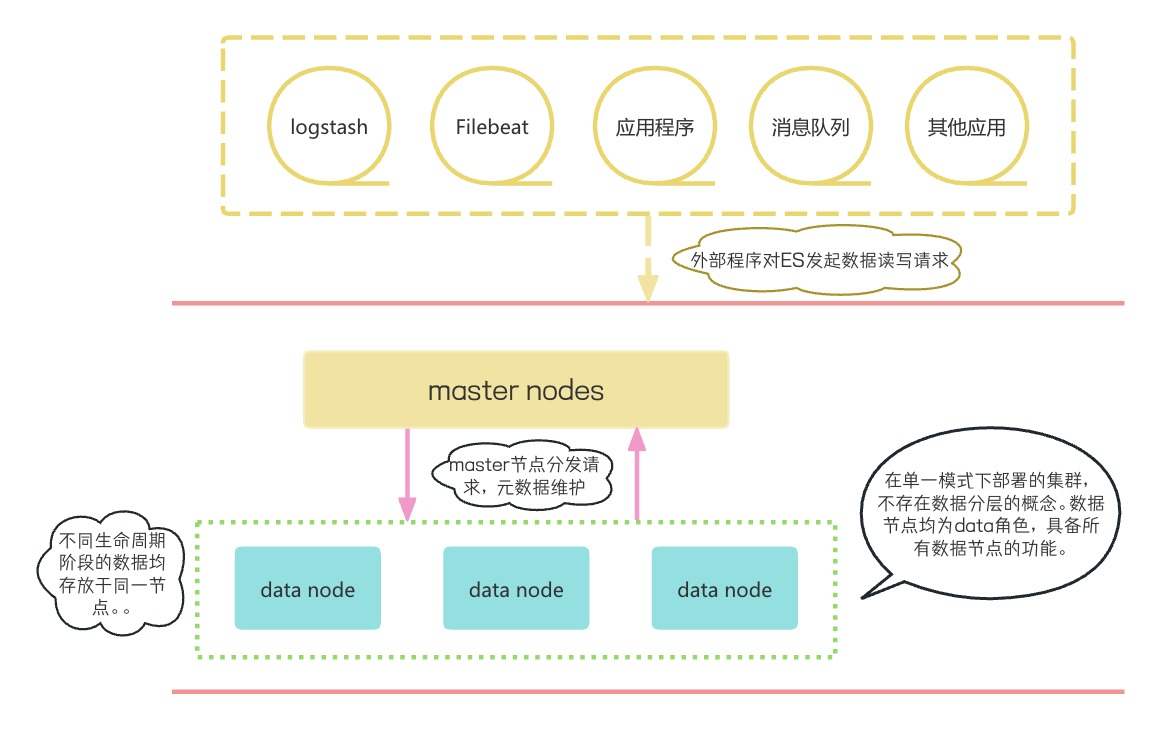
В одномодовом кластере узлы данных объединены в общие роли данных, а node.role настраивается как данные. При настройке ролей используйте следующие методы:
#существоватьelasticsearch.ymlсерединадобавить Настройте узел как роль общих данных со следующей конфигурацией.
node.data: trueПосле завершения настройки запустите службу ES, и вы обнаружите, что узел данных имеет все роли уровня данных.
В одномодовом кластере не существует концепции многоуровневого хранения данных в индексе, и данные индекса на разных стадиях жизненного цикла хранятся в одном слое узлов данных. Все операции с данными выполняются на общих узлах данных. Например: запись новых данных, резервное копирование снимков и т. д.
Горячие и холодные кластеры Elasticsearch
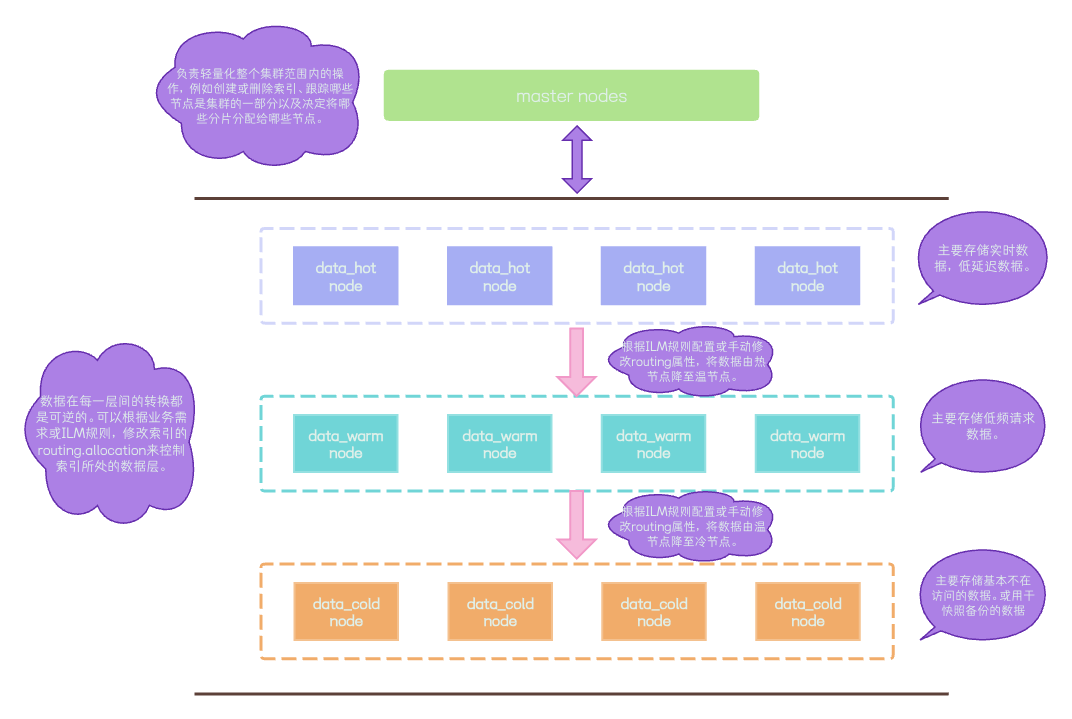
В горячем и холодном режиме,Мы внедрили слой горячих данных в кластере,теплый слой данных,с холодным слоем данных. В обычной производственной среде,Просто используйте слой горячих данных степлый слой данных。В соответствии с потребностями бизнес-системы,Мы можем конкретно определить Стратегию жизненного цикла ILM.,Какие пороговые значения и условия могут быть ограничены в правилах?,Индексы выполняют различные действия жизненного цикла.,Например: Индексное охлаждение,Замораживание индекса и другие операции. Если наш кластер не настроен для жизненного цикла ILM,Мы также можем использовать ручную модификациюcluster.routing.allocationЗначения параметров маршрутизации для охлаждения индексаили Прочие операции。
Конфигурация роли узла уровня горячих данных
Добавьте следующее содержимое в elasticsearch.yml:
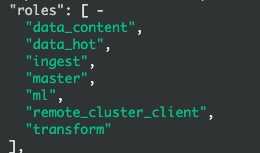
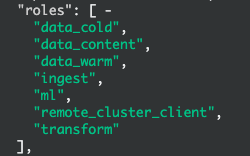
node.roles: [data_content,data_hot,remote_cluster_client,ingest,transform,ml]Здесь мы используем статические методы для ограничения ролей узла.
Если наш кластер представляет собой смешанное развертывание узлов горячих данных и главных узлов, использующих один и тот же узел, нам также необходимо добавить главную роль к узлу.
node.roles: [master,data_content,data_hot,remote_cluster_client,ingest,transform,ml]После добавления роли перезапускаем службу elasticsearch. После перезапуска роль горячего узла будет такой, как показано на рисунке:
Конфигурация роли узла уровня холодных данных
Добавьте следующее содержимое в elasticsearch.yml:
node.roles: [data_content,data_warm,remote_cluster_client,ingest,transform,ml]После добавления роли перезапускаем службу elasticsearch. После перезапуска роль холодного узла показана ниже:
На что следует обратить внимание
- Node.role, используемый в «горячих» и «холодных» кластерах, принадлежит статически заданным ролям узлов.,во время настройки,нельзя использовать с
node.data:true;node.master:true;Используйте одновременно。Если оригиналymlдокументсередина Эти две строки настроены,После обязательна аннотация,Настройка node.role. - При обновлении конфигурации роли модификация узла следует принципу сначала изменения узла данных, а затем изменения главного узла. Это позволяет избежать потери кластера из-за предварительного изменения роли главного узла, что влияет на использование кластера эластичного поиска бизнес-системой.
- Изменение роли узла в кластере требует перезапуска службы elasticsearch на узле. После перезапуска требуется восстановление сегмента. Рекомендуется вносить изменения в непиковые периоды.
Охлаждение и восстановление индекса Elasticsearch
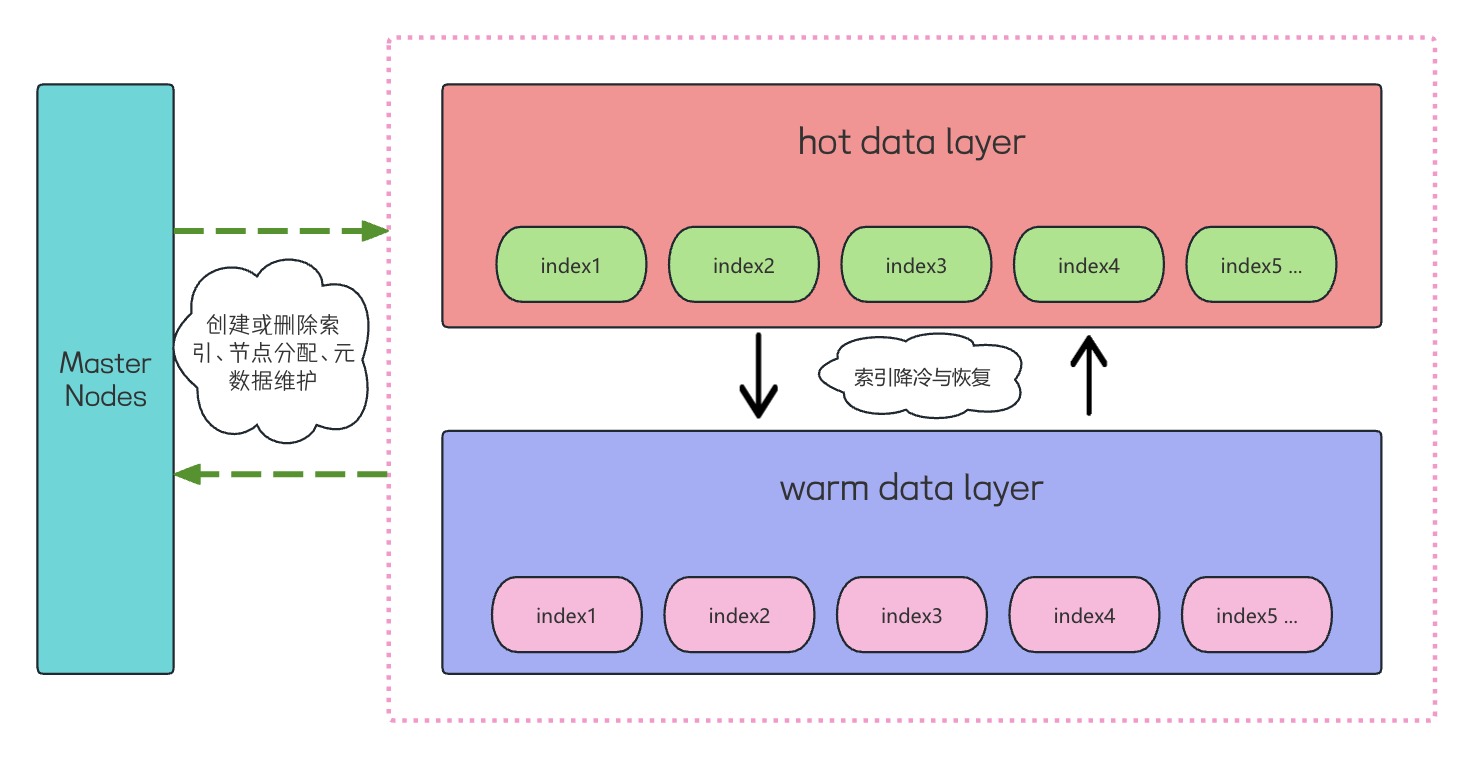
Индексное ручное охлаждение
После обновления кластера до многоуровневой архитектуры «горячего» и «холодного» мы можем использовать следующий оператор для ручного охлаждения фондового индекса.
PUT indexname/_settings
{
"index.routing.allocation.include._tier_preference": "data_warm"
}Охлаждение и восстановление индекса обратимы и в основном достигаются за счет изменения свойств уровня данных маршрутизации индекса.
Стратегия жизненного цикла ILM
Если вам нужно использовать Стратегию жизненного цикла ILM для полностью автоматического размещения индекса, перейдите в мою статью https://cloud.tencent.com/developer/article/2356835, чтобы узнать больше.
Ключевые понятия, которые нужно понять
node.role:Узловой Роль,Используется для управления разрешениями, которые имеют узлы в кластере. В соответствии с потребностями нашего бизнес-сценария,Настройте соответствующие роли для узлов,Обеспечить хорошую производительность и стабильную работу кластера.
index.routing.allocation.include._tier_preference:Используется для назначения индексов кластерам.серединадоступные уровни。Согласно указанной нами конфигурации,Распределите сегменты индекса по соответствующим узлам. По сути, он используется для управления приоритетом сегментов индекса между указанными уровнями хранения. Этот параметр является одной из конфигураций распределения индексного маршрута.,Указывая разные уровни,Распределением и хранением данных в кластере можно гибко управлять. Например: установите значение параметра «горячий».,Затем, когда индекс выделяется на узле,Он будет выделен тому data_hotupel, который первым соответствует условиям.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
