Обязательный экзамен по бэкэнду! Познакомьтесь с принципами механизма хранения, лежащими в основе распределенной архитектуры хранения, в одной статье.
Многие приложения являются приложениями с интенсивным использованием данных, а не вычислений. Для таких приложений процессор часто не является первым ограничивающим фактором. Ключевым моментом является объем данных, сложность данных и быстрая изменчивость данных. Это более важно при проектировании прикладных систем. Основная задача базы данных (движка данных) — «чтение и запись значений». Мы пытаемся шаг за шагом расширить обсуждение от «простейшего чтения и записи данных файла сценария» до «распределенной базы данных «ключ-значение». У нас будет много «проблем», с которыми вы столкнетесь и попытаетесь решить шаг за шагом.
Следите за разработчиками Tencent Cloud и заранее получайте техническую информацию из первых рук.
В этот четверг в 19:30 в комнате прямой трансляции видеоаккаунта разработчиков Tencent Cloud «Программисты Goose Factory лицом к лицу» мы пригласили руководителя Goose Factory проанализировать «Проектирование и обдумывание контрактной платформы», чтобы вы могли решить повседневные проблемы работы программистов. Боль общения. Заранее записывайтесь на прямой эфир и успевайте захватить подарки по Гусиной фабрике!
01. Автономный механизм хранения данных
от
Две строки кода из Shell-скриптачитать Писать Начало файла,Постепенно решая следующие задачи, получимприезжать Имеется автономная машинаизхранилищедвигатель(LSM Tree) 1. медленно читать 2. Диск исчерпан 3. Сжатие и объединение файлов 4. Реорганизация формата файла данных для повышения эффективности сжатия и слияния. 5. Сортировка данных в памяти для достижения ожидаемого формата файла данных. 6. Сжатие и объединение упорядоченных файлов данных 7. Внедрение журналов упреждающей записи для решения проблемы потери данных в памяти после перезапуска.
Не использует какой-либо существующий механизм обработки данных,Давайте еще раз подумаем о проблеме:Как создать извлекаемую «базу данных» с нуля?
Давайте сначала посмотрим на следующееэтот Самый простойиз«Машина данных»。
#!/bin/bash
db_set() {
echo "$1,$2" >> database
}
db_get() {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}Используйте вышеуказанное shell Скрипт записывает два фрагмента данных ( key соответственно 123456 и 42)после,Двухстрочная запись локального файла выглядит следующим образом (используйте , различать key и value )。
123456,{"name":"London","attracions":["Big Ben", "London Eye"]}
42,{"name":"san Francisco", "attractions":["Golden FateBridge"]}вышеэтотиндивидуальный«Машина данных»Писать Эксплуатационные показатели достаточно хорошие,Потому что вам нужно только добавить запись в файл данных;
но этоизчитать плохая успеваемость,Потому что требуется полный поиск файлов (grep | sed),такой жеиндивидуальный key Если бы было много раз Писатьдействовать,существует Файл данных будет хранить существующеенесколько строк записей.,Извлекайте только последний элемент при запросе(tail -n 1)Вот и все。
Поскольку формат файла данных фиксирован, операции удаления в настоящее время не поддерживаются.
keyЗдесь не может быть запятой,valueневозможно сохранить всуществовать Разрывы строк и другие проблемы
1.1 Внедрение индексов для улучшения производительности чтения
Первой текущей задачей является Улучшение производительности чтения。Мы можем ввести отдельное обслуживаниеизиндекс(Обслуживание в памятииз Hash Map)Улучшение производительности запросов;поэтому Писать В дополнение к времени Писатьфайл данных,Также нужен Писатьиндекс,этотвстреча Уменьшите скорость записи; это также очень важный компромиссный вариант в системах хранения; разработчикам необходимо решить, следует ли сосредоточиться на производительности чтения или производительности записи при выборе технологии;
Хэш-индекс
После добавления индекса это выглядит так:
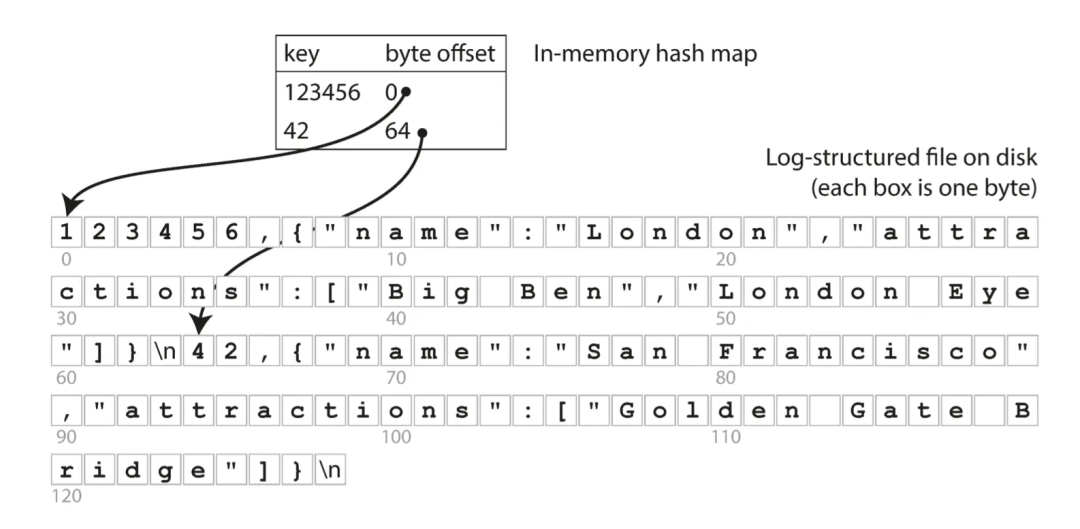
Добавлено в память Hash Map чтобы быстро найти Key Местосуществоватьиз Расположение,hash value даСмещение байтов файла (byte offset);читать Выбиратьчаспрямойотдокумент Укажите смещение Расположениечитать Выбиратьприезжать Символ новой строкида Value ценить.
В это время может быть обеспечено высокопроизводительное чтение и запись, но все Key Все они могут быть помещены в память для индексации; операция записи по-прежнему является записью добавления, а операция чтения требует только одной адресации диска.
После введения индекса памяти возникает естественный вопрос: если машина перезагрузится, что делать, если индекс памяти потерян? Можно повторно пройти по файлу для построения индекса.,Позже мы обсудим другие, более разумные решения. кроме того,такой жеиз
keyЕсли есть несколько Писатьдействовать,Тогда в локальном файле данных также будет несколько записей, поэтому в крайних случаях существует риск исчерпания диска;,вернотакой жеиндивидуальныйkeyПостоянноиз Писатьвходить,Прямо приезжатьдиск Писатьполный,На самом деле действительна только последняя запись да. Увеличение дискового пространства особенно важно; в то же время,hash mapНужно сохранить всесуществоватьв памяти,нравитьсяkeyиз Количество превышает лимит памяти,тоже будут проблемы
1.2 Как избежать диска исчерпан?
Сегментация файлов, сжатие сегментации
Предположим, файл данных заполнен. 1GB Затем его можно закрыть и создать новый файл данных для последующей записи. следующее segment1 Создано после заполнения сегмент2 каждый; segment Это независимый файл;

После сегментации в новом сегменте сохраняется только последнее значение каждого ключа, при этом количество файлов журнала сегмента и общий размер уменьшаются;
Как показано выше,purr существовать segment1 и segment2 Чжунцуньсуществоватьнеоднократно,После растяжения,Сохраняйте только самые последниеизценить(2114)Вот и все;
В то же время нам следует обратить внимание на,выше segment в key Он неупорядочен и хранится в порядке записи;
Даже «машина данных» еще не идеальна.,напримерверноудалить записьКак бороться с?восстановление после сбоякак действовать?Интервальный запросда Нет поддержки?и т. д.Используйте эти несколько вопросов, чтобы побудить нас к следующему обсуждению.
Реализовать интервальный запрос и быстрое слить файл,верновышеизсегмент журналадокументдобавить одининдивидуальный Требовать:Key Упорядоченный.
тогда файл можно назвать таблица упорядоченных строк(SSTable - sorted string table);SSTableпо сравнению свышебеспорядокиз Хэш-индексизсегмент журнала,Он имеет следующие преимущества:
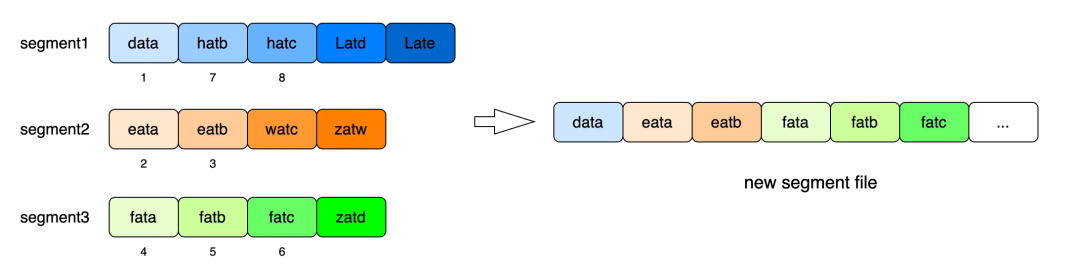
- Объединение более эффективно:многоиндивидуальныйиметьпоследовательностьдокумент Можеткделатьиспользоватьмного路归并排последовательность,Просто и эффективно; Как показано ниже три
segmentслитьприжатьез аsegmentиз процесса; тот же самый ключ будет удален в процессе слития файла;
- Память в
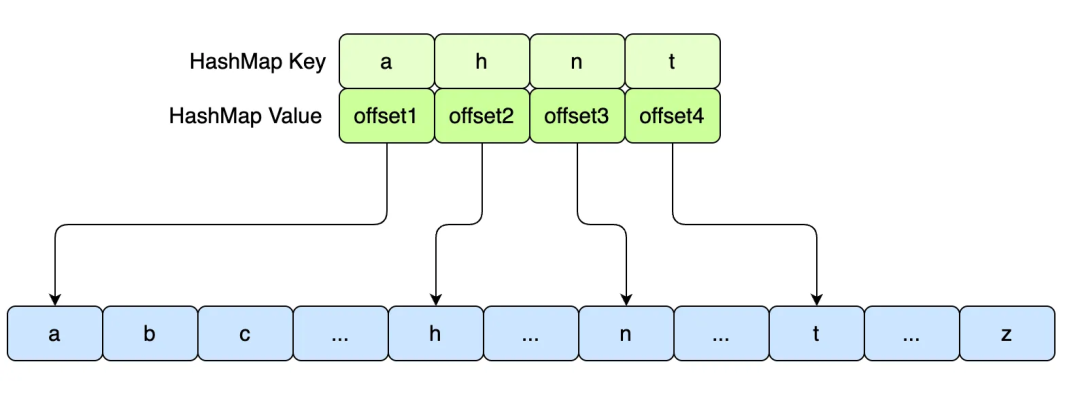
hash mapНет необходимости сохранять все ключи:Получите выгоду от заказа ключей,Похоже на бинарный поиск,Найдите наибольшее значение, которое меньше целевого значения ключа, а затем последовательно просмотрите его (пример ниже);,Сохранить в файл журнала a-z всего 26 key из Пара «ключ-значение», памятьв hash map могут быть разреженные хранилища a/h/n/t 4-х ключей достаточно, если захочешь поискать г, нужно просто пройти и найти a приезжать h между адресным пространством файла)
В настоящее время существуют еще две проблемы, которые необходимо решить: 1) Как создать упорядоченный файл данных,Потому что данные не в порядке при вводе,всегда хочуиметьиндивидуальныйместоверноданные进行排последовательность 2)этотиндивидуальныйфайл данныхвнутреннийдакакхранилищеи Поиск
kvверноиз,также ДаSSTableвнутреннийдокументструктуракак
1.3 Как построить и поддерживать SSTables
Непрерывно из данных Писать в сортировку невозможно в существующем файле,Итак, мы используем память для решения этой проблемы. Существует еще много структур данных, упорядоченных в памяти;,По принципу простоты и эффективности.,мы выбираемТаблица прыжковкак заказанные данныеиз Реализация памяти:
данные Писатьвходитьчаспрямой Писатьвходитьприезжать Память в Таблица прыжков Вот и все,когда Таблица Когда количество прыжков достигает порога прибытия (например, 1 ГБ), Писать можно сохранить (сбросить) приезжать в файл на диске, поскольку Таблица прыжки находятся в порядке, поэтому сгенерированный файл также находится в порядке, что соответствует SSTable требования;
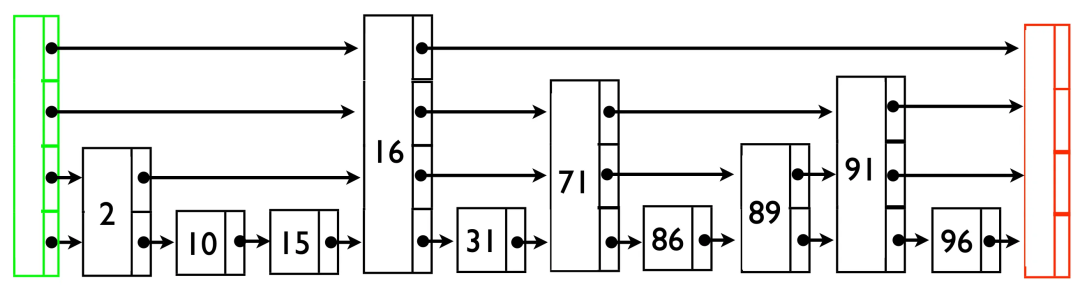
Сейчас возникает еще один вопрос: если Таблица прыжков
dumpприезжатьполовинаизкогда(Как показано Последовательный обход и сохранение вышеприезжать 71), в это время пишите 20,обращатьсяdumpЗаканчиватьпосле,Таблица прыжков был перестроен, а 20этот ценности были утеряны.
поэтомутолькосуществовать dump Таблица переходов больше не может принимать записи, но системе по-прежнему необходимо получать запросы на запись от клиента, поэтому также необходима таблица переходов, которая может принимать запросы на запись, как показано на следующем рисунке:
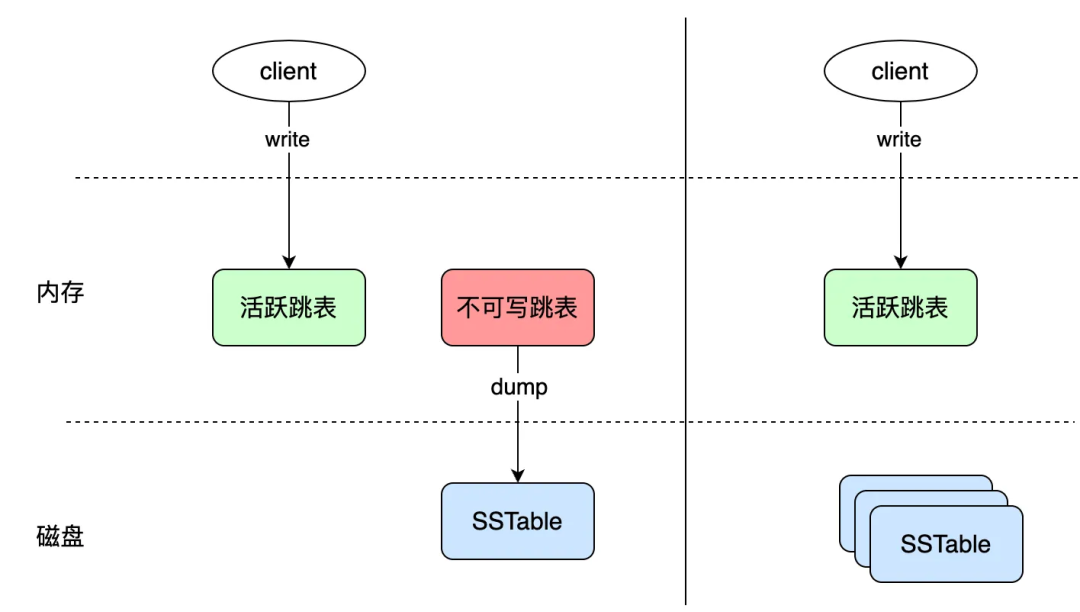
существоватьактивный Таблица Когда прыжки необходимо сохранить, они станут недоступны Писать Таблица прыжков, при создании новой неактивной Таблицы прыжков получает запросы Писать. Мы будем активны Таблица прыжки называют это memtable, недоступная для записи таблица переходов называется неизменяемый. На диск записывается только таблица пропуска SSTable В процессе из в памяти сохраняются только две Таблицы. прыжков, кроме того, в памяти есть только одна активная из Таблица: существуют прыжков получает запросы Писать.
дакогдаобсуждатьодин раз
SSTableиз Структура файла,Потому что только это ясноSSTableдакакхранилищеданныеизпонятьчитатьпроситьда Как бороться сиз
1.4 Подробное объяснение формата файла SSTable
первый,нуждаться Мысль 1индивидуальныйвопрос:параkvкаксуществоватьв файлехранилище?
например имя:zhengwei, если файл существует напрямую склеен и закодирован в Намечжэнвэй, мы не знаем key да name,Ну давай же namezheng, если используется специальный символ различать, то kv Также не допускается хранить специальные символы, наиболее разумным способом является дахранилище; key и value издлина;читать принимает указанную длину последовательности байтов в качестве целевой цены.
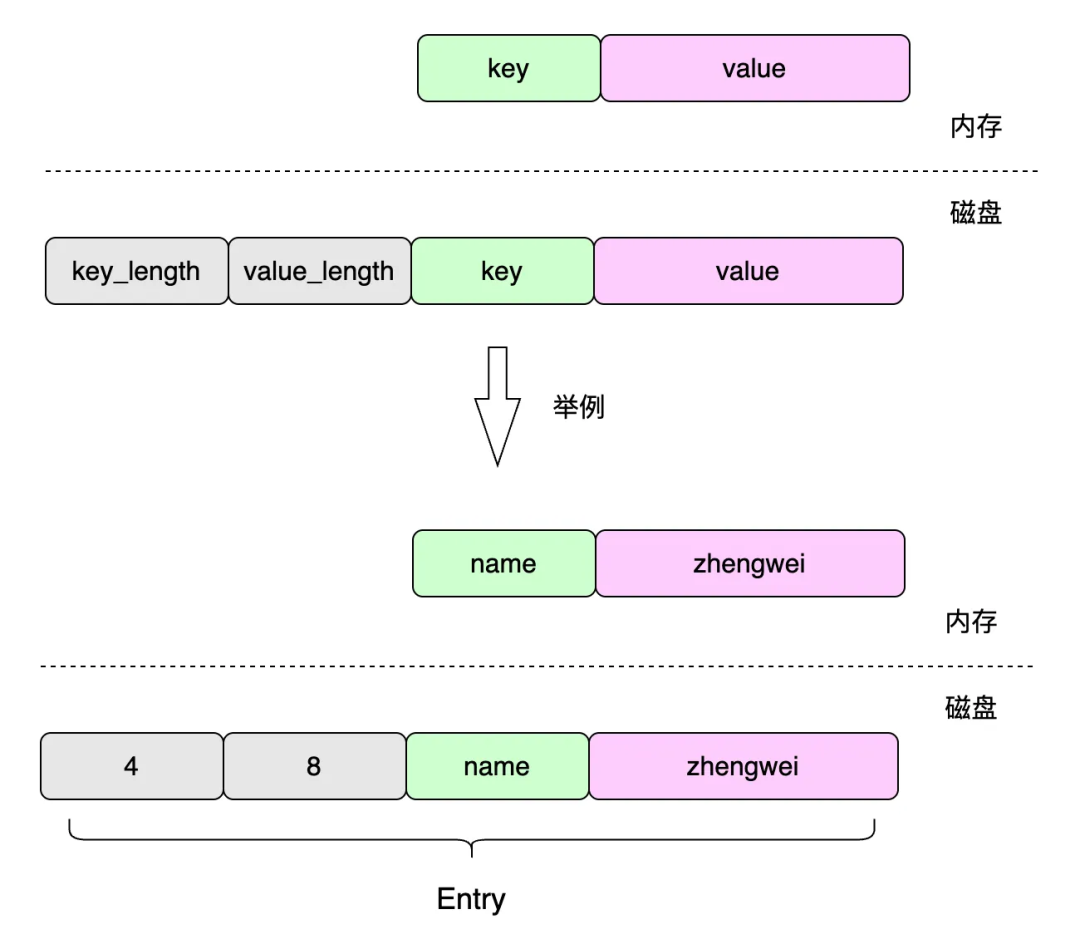
существовать Писатьвходитьприезжатьдокументизкогда,существовать key value Добавить отдельно перед key и value Длину можно получить напрямую через смещение. key и value изContent; как показано выше в; 4 и 8. Такую запись мы сначала назовем ее Entry。
этотвнутрииметьодининдивидуальный Маленькийвопрос Да
key_lengthиvalue_lengthсоответственноиспользовать Несколькоиндивидуальныйбайт Приходитьхранилище Шерстяная ткань?1Слишком мало байтов,Может хранить только последовательность байтов длиной 256,Если строка очень длинная, ее невозможно сохранить, если в ней слишком много байтов;,Например, 4 байта,Сохранить еще разсуществовать Очень большойиз Пустая трата пространства; Это можно реализовать, обратившись к методу кодирования байтов переменной длины UTF-8. В зависимости от того, равны ли первые несколько битов 0, это означает, сколько байтов используется для представления длины байта.
У нас уже есть запись, как же организовать эту запись в SSTable? Чтобы воспользоваться преимуществами страничного кэша диска, мы организуем несколько записей в блоки (Block).
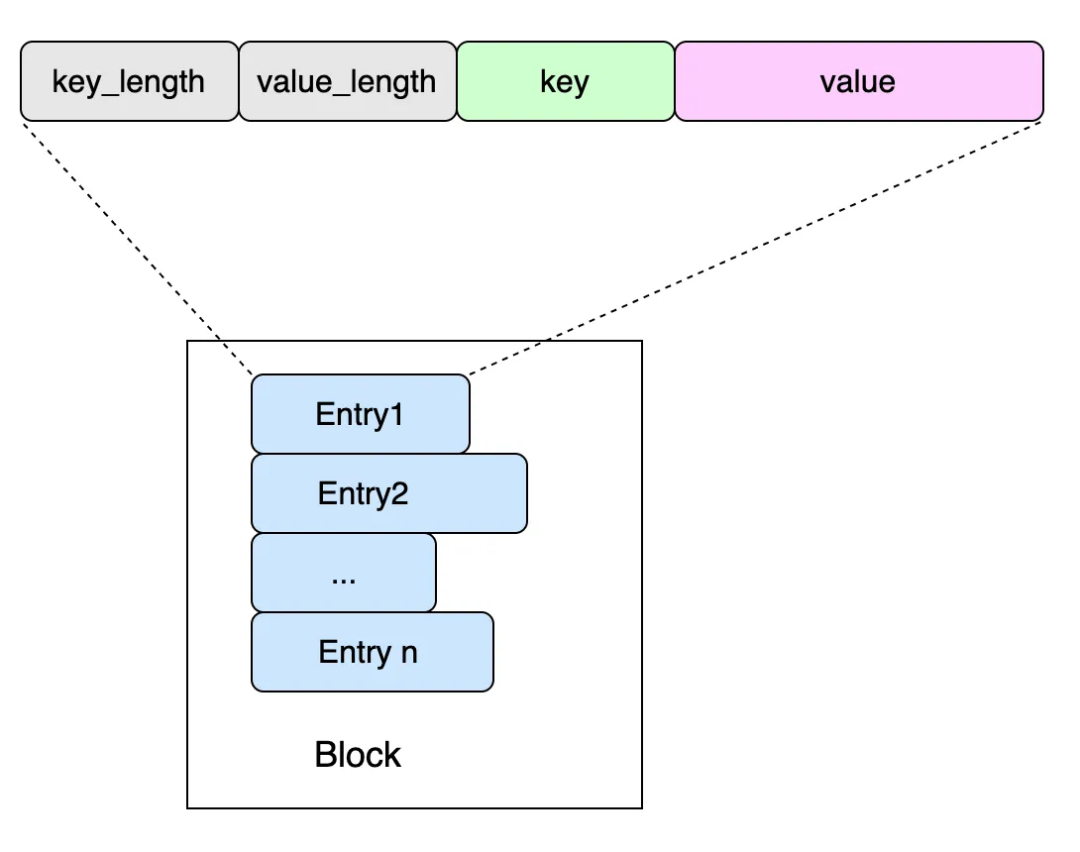
существовать Лексикографически,Entry1 < Entry2 < ... < Entry п хотя и порядочный, дакаждый; Entry Длина da из не равна из, поэтому мы не можем напрямую использовать массив из индекса индекса для непосредственного выполнения двоичного поиска, чтобы добиться двоичного поиска, мы существуем; Entry К каждой записи добавляется пара «должен изиз». offset Массив, массив изкаждый элемент хранилищаизда соответствующий Entry адрес смещения;
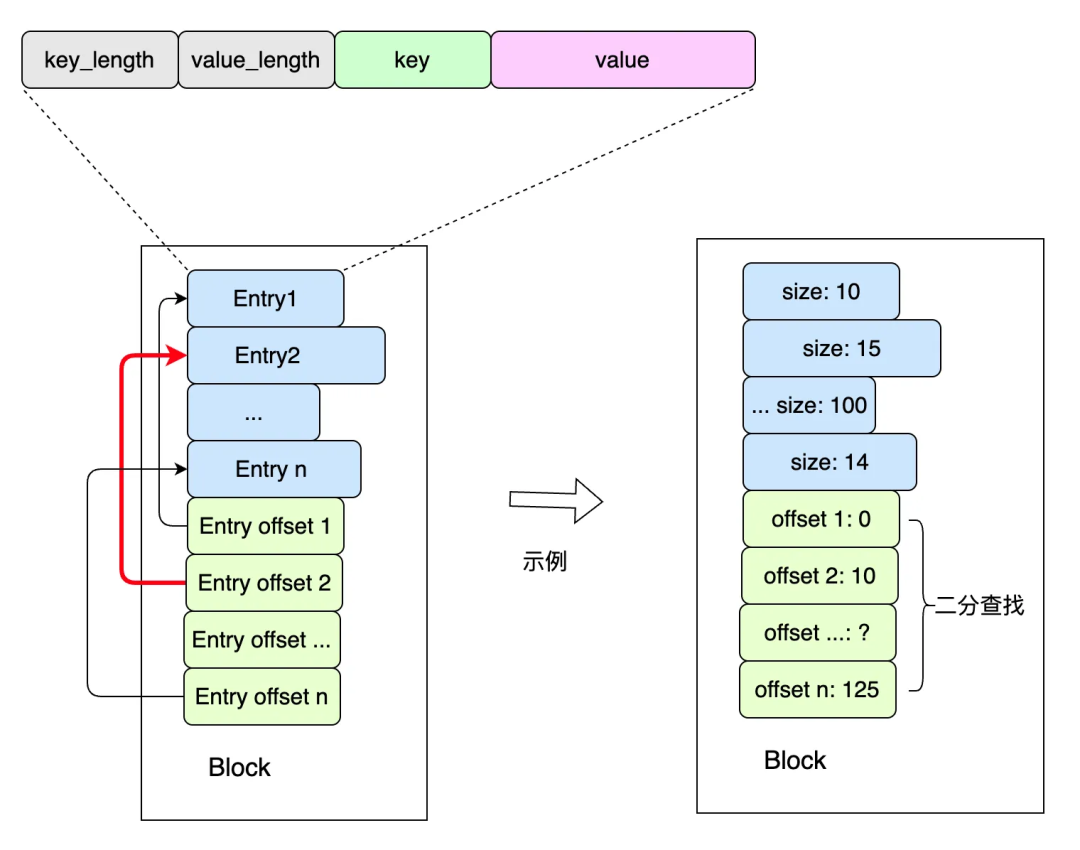
offset Массив записывает только соответствующие Entry изкомпенсировать,существовать offset Чтобы реализовать бинарный поиск в , нужно найти соответствующий key , вернитесь к точке, указанной красной стрелкой Entry Просто поиск, аналогичный косвенному двоичному поиску.
Благодаря приведенному выше обсуждению,нас Воляданныеорганизоватьприезжать
Blockсередина, и можетсуществоватьBlockБыстрый поиск внутри。接Вниз Приходитьнас Сразу Приходитьобсуждатькак ВоляBlockВыносливостьприезжатьдискв файле,сновакаксуществоватьдискфайл данныхсередина Поискприезжать ДолженBlock
выше Block хранилище данных, так мы это называем Блок данных. будет ли каждый DataBlock сжат и сгенерирован CRC Проверяем код, записав его в файл, мы можем получить каждый DataBlock существуют файлы со смещением offset и размер. В то же время мы также знаем, что DataBlock в max ключ, следовательно, макс; key 、offset、 size Это верно DataBlock Информация индекса показана на рисунке ниже:
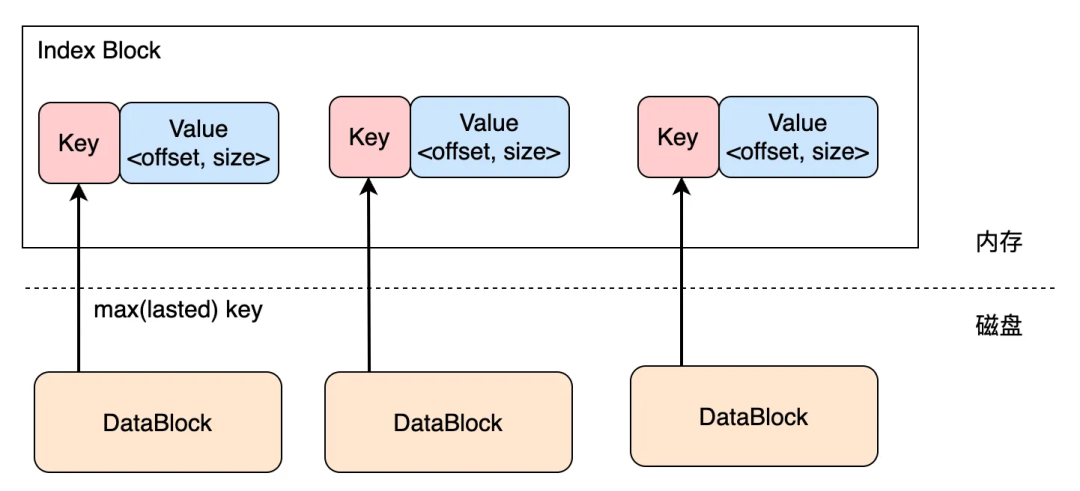
Вместе с DataBlock Добавьте данные для охвата DataBlock После порогового значения DataBlock запись в файлы и т.д. все DataBlock После настойчивости Индекс Block Также завершена сборка Index Block все Entry Индексирован DataBlock,Key Да DataBlock Последняя запись Key,Value Да DataBlock файл данных существует в исходном положении и размере.
IndexBlockПо сутииDataBlockдапоследовательныйиз,Не что иное, какхранилищеизValueдаDataBlockизиндексинформация
Наконец, к файлу данных также добавляется индексный блок, как показано в примере слева:
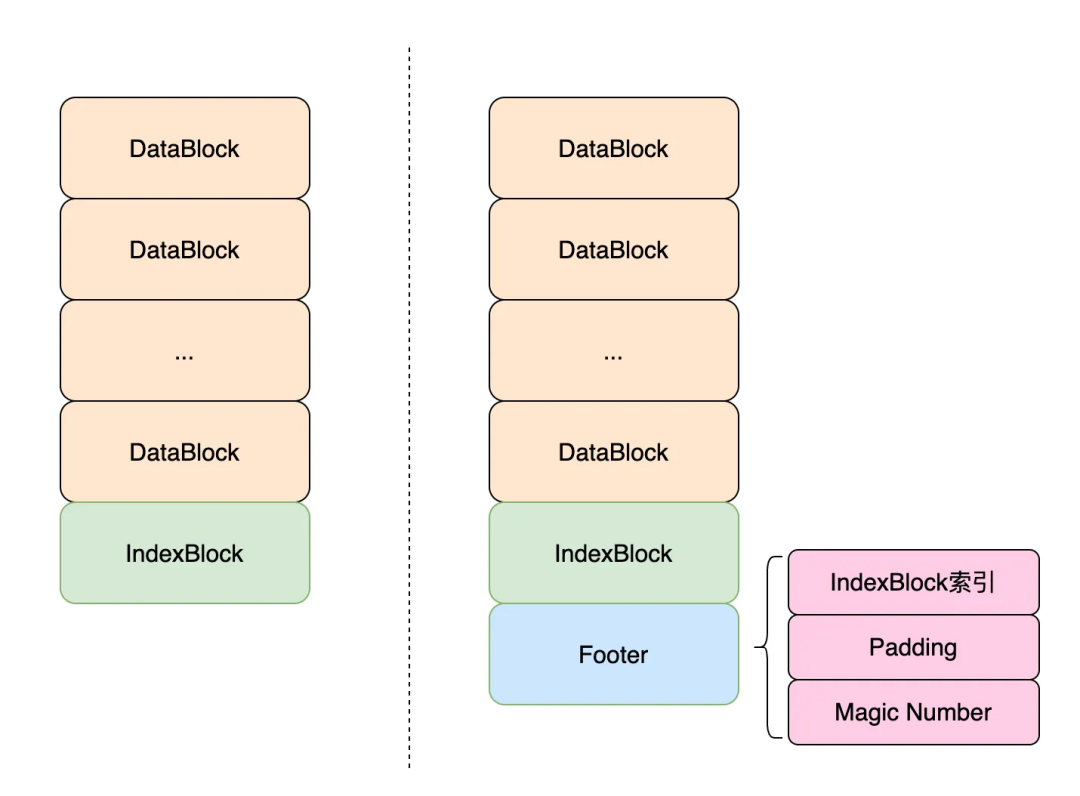
На данный момент SSTable имеет только DataBlock и IndexBlock.,В будущем могут быть добавлены другие типы блоков.,Как и при запуске операционной системы, BIOS всегда выполняет машинные инструкции с фиксированного адреса.,Нам нужно существующееSSTable, чтобы добавить фиксированное из «Начального местоположения».,Это нижний колонтитул (показан в правой части изображения выше).,Его можно рассматривать как вIndexBlockиндексдаB+дерево из корневого узла; нижний колонтитул фиксированного размера (48 байт), и, наконец, измагическое число используется для проверки типа файла даSSTable;,Просто заполните пустую последовательность пустой частью посередине.
поэтому,打开одининдивидуальный
SSTableДапервыйчитать Выбиратьдокументнаконец48байт(Footer),братьприезжатьIndexBlockиз Расположениеи大Маленькийпосле Сразуспособный ВоляIndexBlockнагрузкаприезжать Памятьсерединана основекосвенныйиз Вы можете найти его с помощью двоичного поискаприезжатьверноотвечатьизDataBlock,И потом сновасуществоватьDataBlockВы можете найти его, выполнив косвенный двоичный поиск внутриприезжатьверноотвечатьизценить.этоттакже ДаSSTableизчитать Выбиратьпроцесс,Как показано ниже:
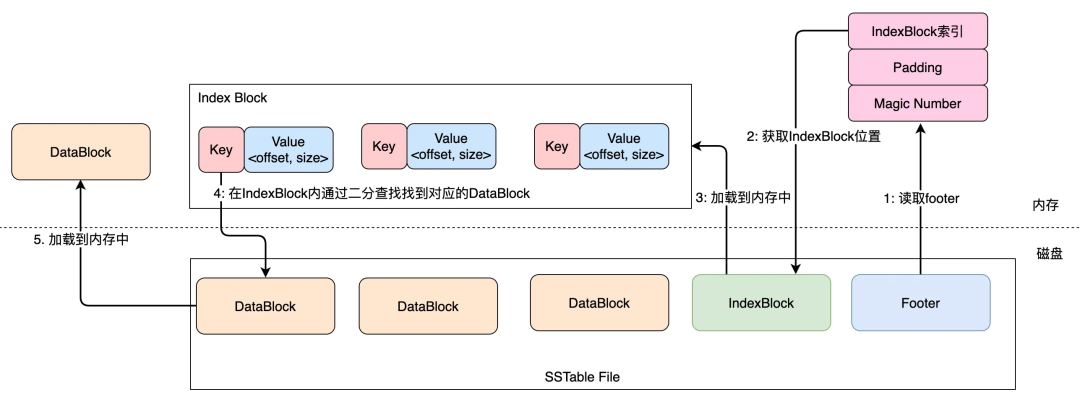
Как показано на рисунке, порядок калибровки серийного номера можно получить, выполнив описанные выше действия. DataBlock вданные。
пройтивышеверно
SSTableдокументструктураизобсуждать,нас发сейчасодининдивидуальныйвопрос:Найдите одинKeyда Нетсуществоватьиз Путь ещё очень долог。поэтому МожеткдобавлятьвходитьBloom FilterДобейтесь быстрого решенияKeyда Стоит ли сохранятьсуществовать ДолженSSTableвсуждение,фильтр Блумаизложное срабатывание насдаприемлемыйиз,Здесь это не будет обсуждаться подробно
Подведем итог нашему текущему дизайну:
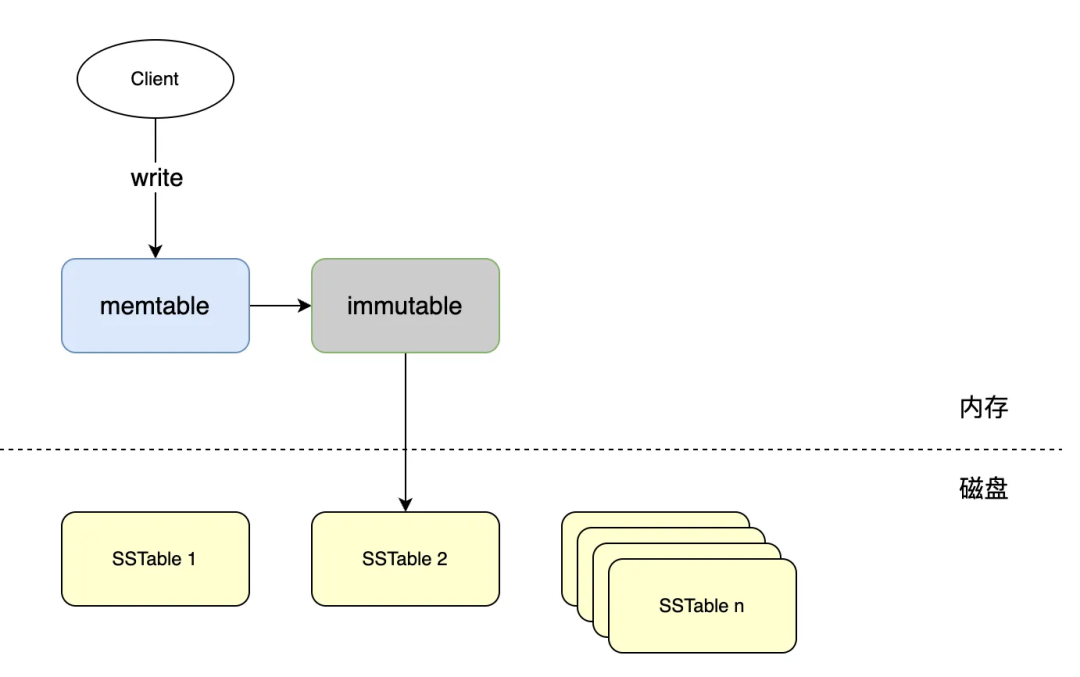
Все данные помещаются в SSTable.,Естественно, будет место для расширения.,И хотя каждый файл да в порядке,Но я не могу приехать ко всем SSTable из общего порядка.,Команда существоватьчитать также необходима для одновременного извлечения всех файлов.,Усиление чтения также очевидно;
1.5 Сжатие и объединение SSTable
Каждый неизменяемый постоянный диск в файле SSTable упорядочен и может хранить дубликаты ключей из,Как ключ: имя,существующие могут храниться в SSTable1, SSTable2 или других SSTables.,Как показано ниже,каждыйSSTableЕго можно рассматривать как упорядоченную совокупность значений в течение определенного периода времени.нас ПучокотimmutableГенерировать напрямуюизSSTableиз Набор называетсяLevel 0。
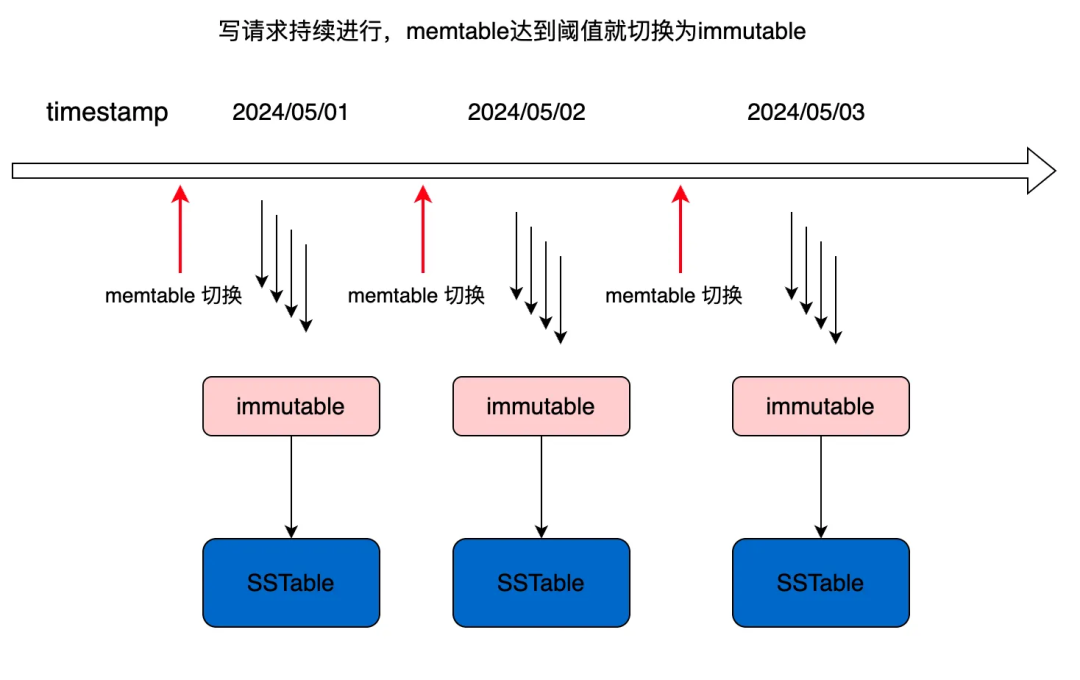
Следовательно, Уровень 0 в существовании является серьезной проблемой увеличения дискового пространства.,Естественно, вы захотите устранить дублирование.,чтобы исключить дублированиеизметод Даслить(compaction)。
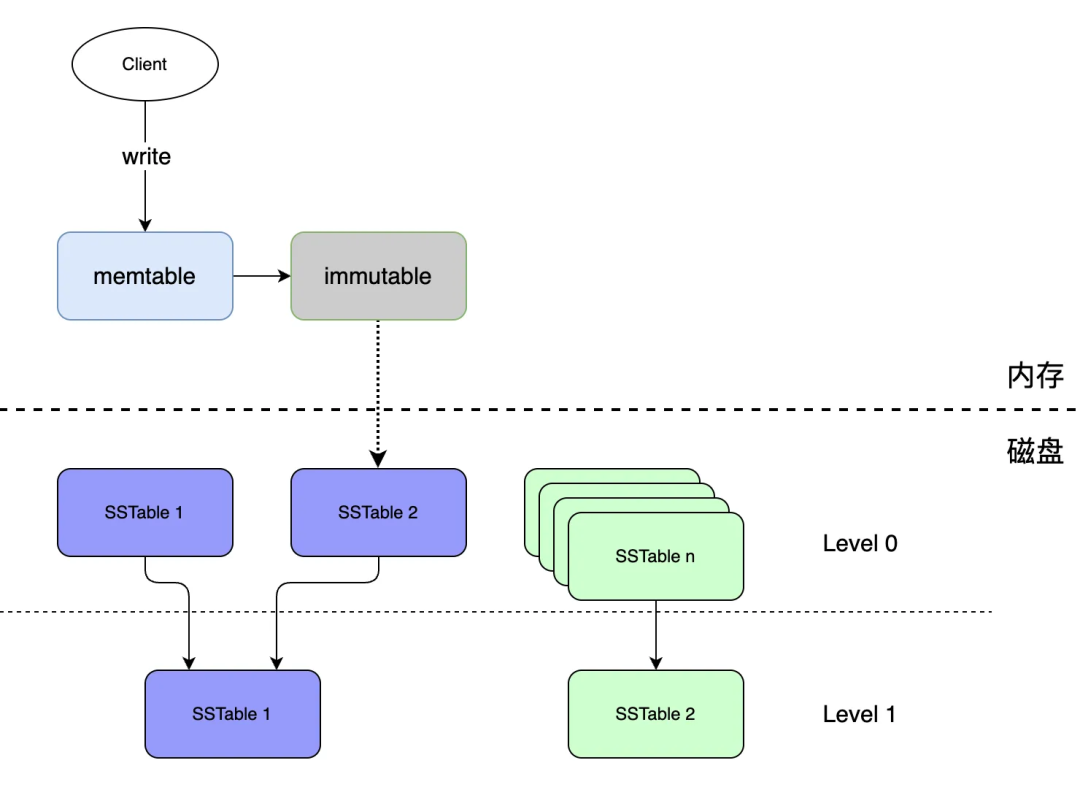
Как показано на рисунке выше, уровень 0-й этаж SSTable 1 и SSTable 2 объединены в уровень SSTable1 уровня 1, Уровень Уровень 1 SSTтаблица 2Также сверхуизSSTableи Этот этажизSSTableслитьстановиться。
Выражение в этом не очень строгое.,
Level 1слойизфайл данных Нетжитьсуществоватьповторитьценить,иSSTable1изключей меньшеSSTable2включ。отвечать Долженда Каждыйслойизмногоиндивидуальныйдокументи Внизслойизмногоиндивидуальныйдокументслитьгенерировать новыеслойизмногоиндивидуальныйдокумент,Конкретно связанный сприезжатьиздокументиKeyиз Связано с диапазоном пересечений,Это будет лучше понято в сочетании со следующим обсуждением.
Мы приводим конкретный пример для объяснения уплотнения:
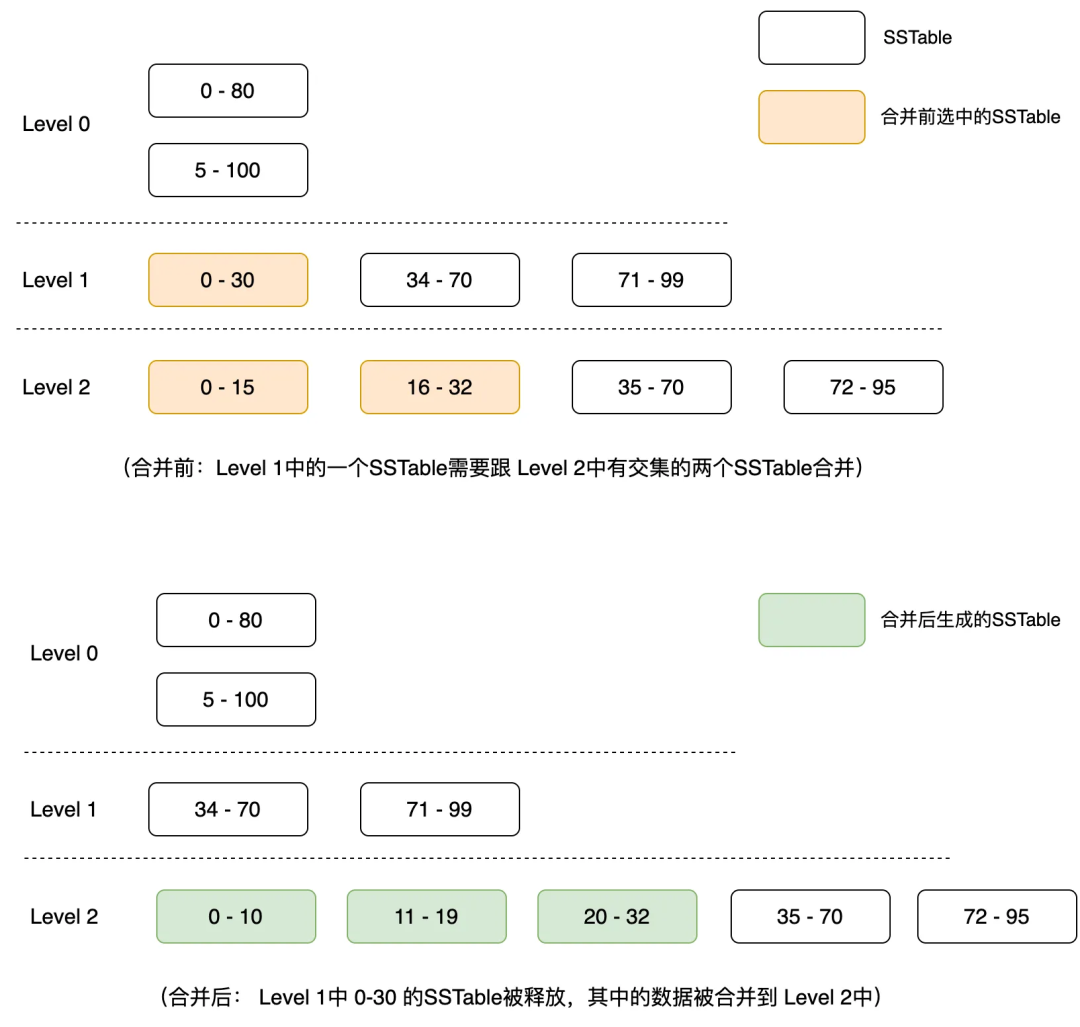
Из-за уровня Количество файлов на уровне 1 превышает лимит. Выберите диапазон ключей на уровне 1. Существует 0-30: файл должен находиться на следующем уровне, а ключ файла на следующем уровне имеет пересечение изsstableда. 0-15 и 16-32 эти два файла; после заказа многопутевого слияния файл level1в удаляется, и файл следующего уровня также будет создан повторно;
Разные базы данных будут иметь разные стратегии иссления.,Никаких дальнейших обсуждений. На картинке выше мы также можем видеть приезжать.,Данные тонут слой за слоем,удалять
Level 0снаружи,КаждыйодинслойизSSTableВсе Тольковстреча保жить部分данные,такой жеслой Внутри Нетвстречаиметьключповторить;на самом делеLevel 0вSSTabl往Внизслойслитьчас,То же самое.
После приведенного выше обсуждения процесса написания были даны ответы на два оставшихся вопроса:
- Как получить данные:первыйчитать Выбиратьmemtable,читатьприжатьез будет возвращено напрямую; если читать не приезжать, чтение будет неизменным;,а потомчитать ВыбиратьLevel 0 -> Level 1 ... Прямо приезжатькаждому слоюиз SSTable Всечитатьнад;нравитьсясуществовать Чтовшагчитатьприезжать Понятноданные,Тогда больше не буду спускаться читать,Прекратите действие в подходящее время.
- Как удалить данные:нуждатьсяудалитьизданные, Специальные значения хранятся в Value. Если чтение принимает конкретное значение из приезжать, оно возвращает, что существования нет; существование также пропустит некоторые ключи со специальными значениями во время процесса сжатия существования (также известного как удаление метки). или «надгробие»).
На данный момент структура следующая:
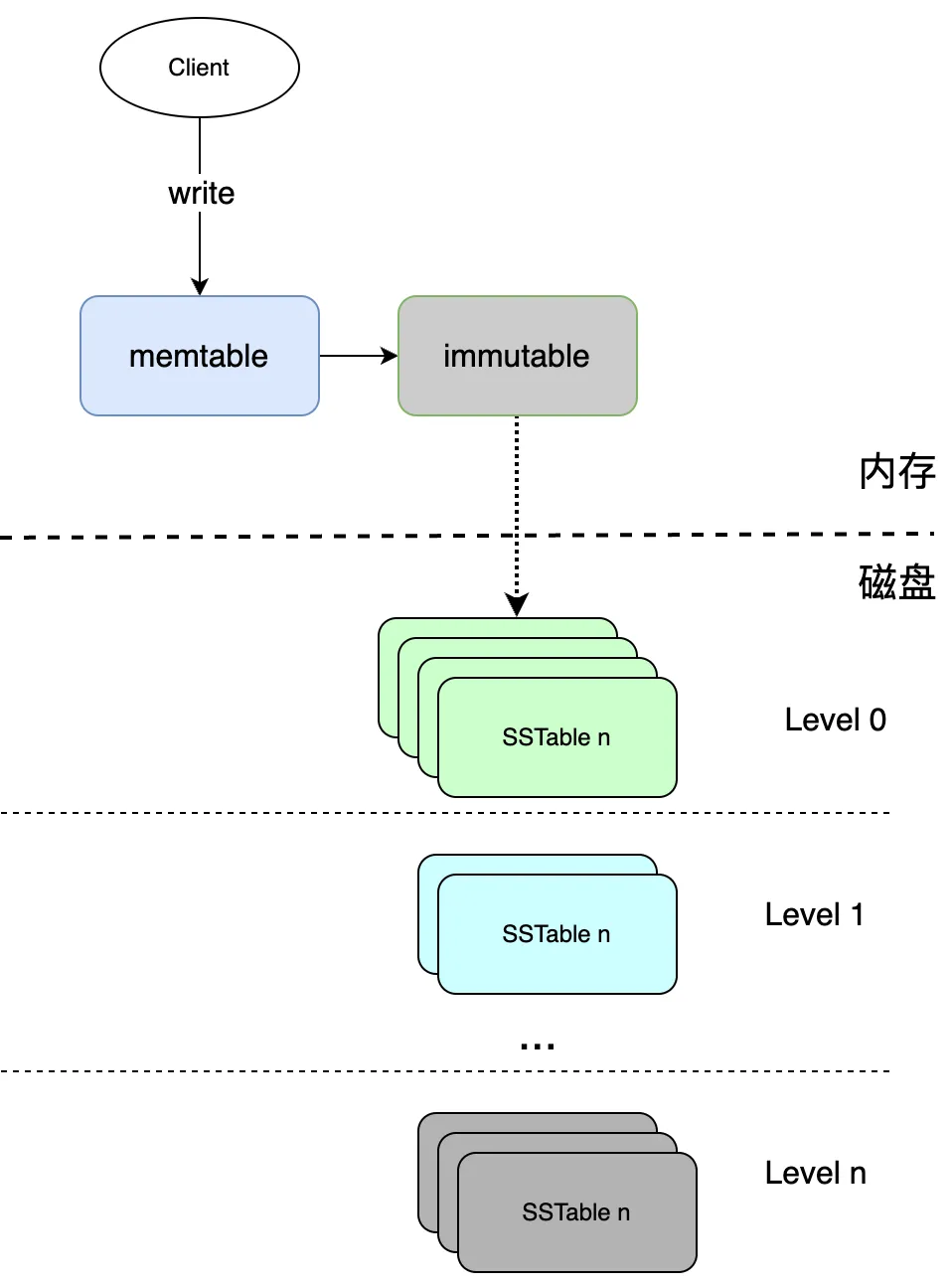
этотчасвозвращатьсяиметьодининдивидуальныйвопрос Да:данныеисходныйда Писатьвходитьприезжать
memtableв,нравитьсявозвращатьсябез Приходить得及dumpприезжатьв файле,Произошел сбой в работе машины,Память пропала после перезагрузки,memtableсередина Писатьвходитьизценитьтакжевстречапотерянный。 Хотите гарантировать Нетпотерянныйданные Необходимо разместить заказ,Чтобы гарантировать, что производительность ввода Писать не пострадает,И порядок диска читать Писать производительность да самая высокая из,нас Можетквестивходитьпредварительно Писатьбревно(WAL-write ahead log)данныепервыйпоследовательное добавлениеприезжатьпредварительно Писатьбревносередина,обращатьсяданные Разместить заказ Разместить заказпосле Снова Писатьвходитьприезжатьmemtableсередина,обращатьсяmemtableвданные Выносливостьприезжатьдискчас,Долженmemtableверноотвечатьизпредварительно Писатьбревнотакже Сразу Можеткудалить Понятно;
1.6 LSM Tree
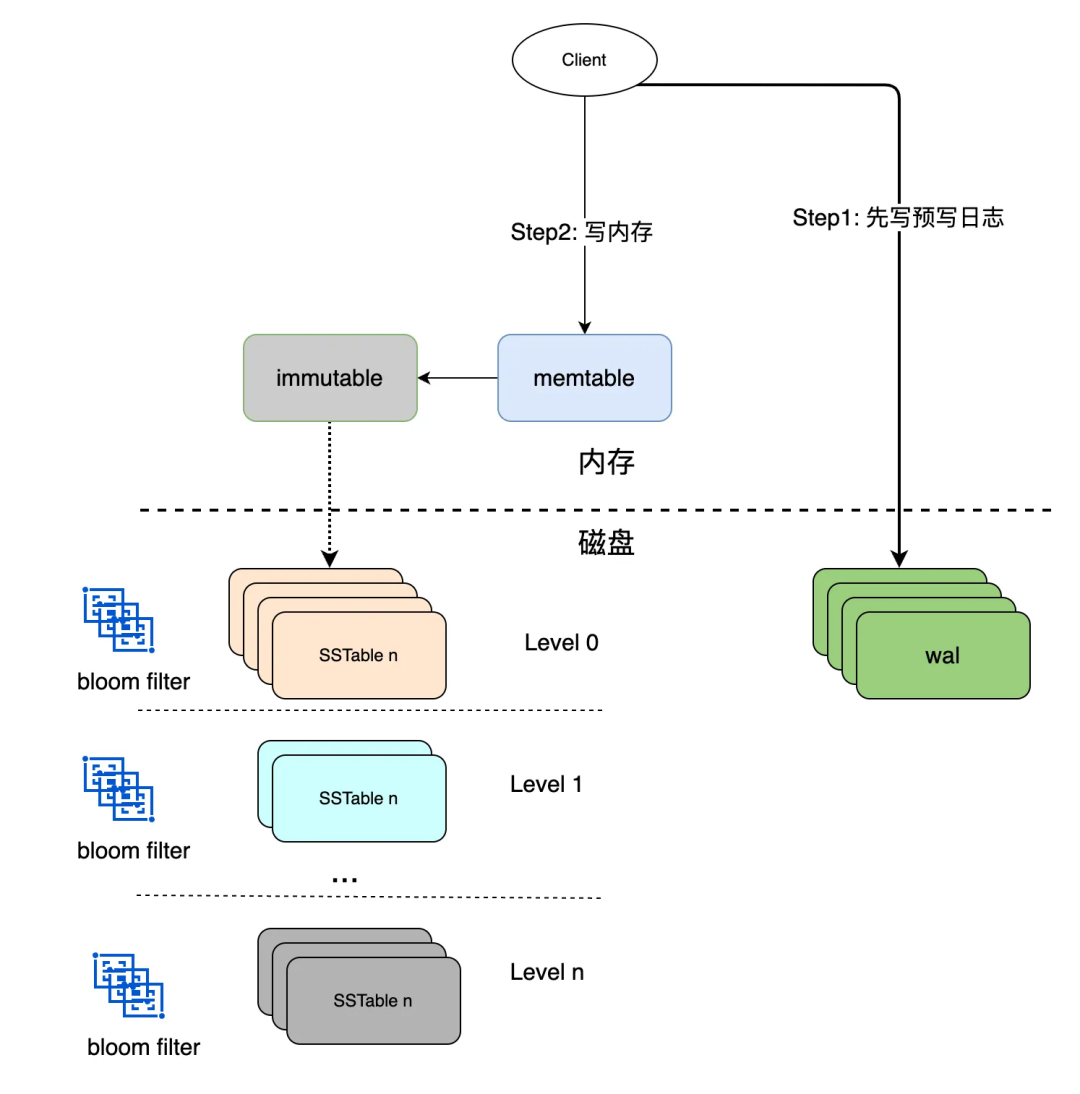
Мы подробно обсудили формат файла sstableiz выше.,Формат файла WALиз подробно рассматриваться не будет.,Существует множество реализаций с открытым исходным кодом, мы можем просто понять, что каждая memtableиimmutable соответствует файлу WAL;,После ввода неизменяемого Писать в приезжать SSTable,Согласно изWAL, его можно удалить.,Потому что эта часть данных сохранилась на диске.
Если произошел перезапуск машины,нонуждаться顺последовательность重放
WALвпроситьк Воля Память в Таблица прыжков восстанавливает состояние до крушения
Обсудить приезжатьэто,У нас уже есть хранилище данных на одной машине из базы данных.,Даже если произойдет перезагрузка,данныетакже Нетвстречапотерянный。на самом делеэтот ДаодининдивидуальныйLSM Деревохранилище двигателя. Также дадаLevelDB / RocksDB Место采использоватьизплан;существовать Cassandra/HBase Программа также присутствует в из;на основаниеслитьисжатие принципаизхранилище файла сортировки часто называют механизмом LSMхранилище;
1.7 и B+ контраст дерева
В дополнение к вышеперечисленному на основеLSMизхранилище Помимо двигателя имеется еще основеB+Деревоизхранилищедвигатель,Это также почти стандартная реализация для реляционных баз данных.,3-4 уровня деревьев B+ могут хранить большой объем данных.,Нет необходимости проходить слишком глубоко (коэффициент ветвления составляет 500 страниц из 4 КБ, дерево уровней 4 может хранить 256 ТБ).
Как показано ниже,верно
B+Деревообсуждатьиз Много информации,Вы можете сослаться на это самостоятельно; я не буду распространяться дальше.
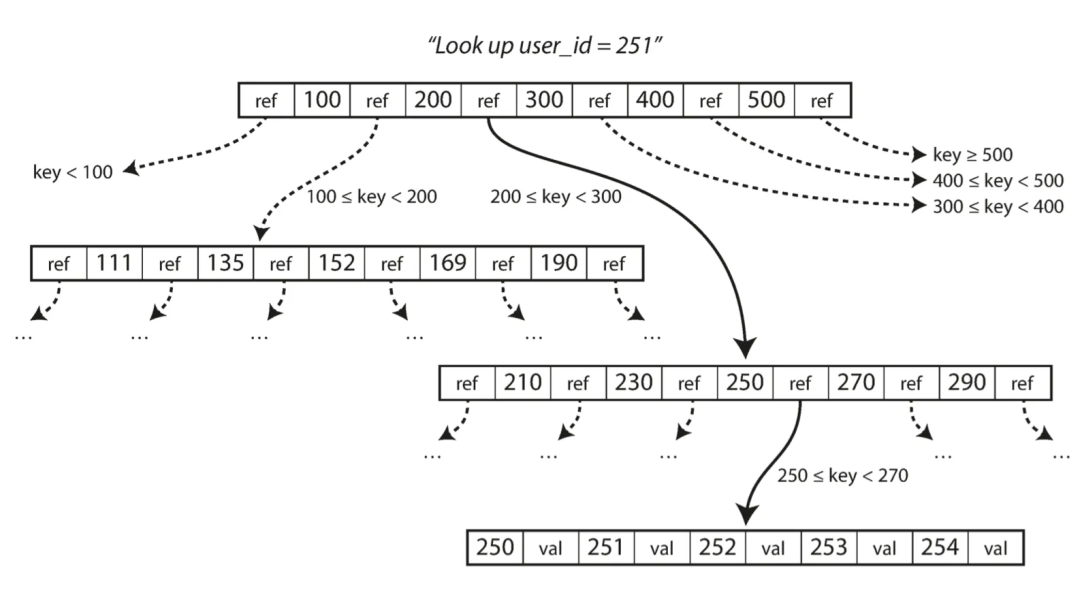
Давайте сравним B+ Tree и LSM-дерево.
- Дерево B+ подходит для большего и меньшего чтения, а дерево LSM подходит для большего и меньшего чтения;
LSMДерево Писатьвходитьизкогда Тольконуждатьсяодин次顺последовательность ПисатьWALбревнодокумент及один次Память Писатьдействовать Вот и все,Стоимость очень мала, но удаление «дачитать» требует нескольких слоев чтения;,только всеизSSTableВсе Нетжитьсуществоватьключ才способный返回Нетжитьсуществовать;B+Дерево Писатьвходитьнуждатьсяслучайный Писатьдиск,В крайних случаях при разделении страницы будет несколько случайных дисков Писать; и чтение может вернуть значение из целевого местоположения при выборке из, когда существует индекс страницы из кэша;,производительность чтения лучше;
- В дереве B+ как минимум в два раза больше данных.,ВАЛ,Как только сама страница; LSM также будет сохранять усиление Писать из-за сжатия и слияния;
B+Деревода Оригиналземлявозобновлятьданные,читать Увеличить меньше,Писать Увеличить。LSMДеревода Обновления, не находящиеся на месте,В одном и том же фрагменте данных хранится несколько записей,Пространство для хранения будет увеличено; для извлечения данных потребуется обнаружение нескольких файлов;,читатьусиление - это серьезно,compaction/сжатиепростота Понятночитатьувеличитьикосмосувеличить,нодасновавестивходить Понятно Писатьувеличить;поэтомуиметьоченьмноготехнологияиспользовать Приходить优化Писатьувеличить,например, технология разделения KV и технология замедленного сжатия.,Больше никаких обсуждений.
- Дерево LSM имеет более высокую степень использования дискового пространства и меньшую фрагментацию;
Потому что дазаказать Писать,
Blockхорошо построенпосле顺последовательность Писатьдиск Вот и все。
- Процесс сжатия LSM может повлиять на текущую операцию чтения Писать; фоновая операция сжатия может вытеснить операцию чтения Писать на диске бизнес-процесса;
- Дерево B+ существует лучше в делах,Есть только один ключ,Легко запирается;
поэтому,
LSM经常отвечатьиспользоватьсуществоватьданныепроанализировать или Что Его офлайн-сцена,Чуть более высокая задержка при чтении.,нодануждатьсяполучить сравнениемногоиз Писатьпросить;B+Дерево Дажемногоотвечатьиспользоватьприезжатьсуществовать Проволока илинуждатьсядобавлять锁изсценасередина。
1.8 OLAP и OLTP
Мы подробно обсудили LSM дерево, и кратко сравнил B+ деревья, это OLAP(online analytic processing)и OLTP серединаЖанр структуры журналаиОбновление жанров на местеизпредставлять;
И синтез OLAP & OLTP из HTAP представляет базу данных, как показано ниже:
свойство | OLTP | OLAP |
|---|---|---|
читать | На основе ключей каждый запрос возвращает небольшой объем данных. | Обобщать большие объемы данных |
Писать | произвольный доступ | Пакетный импорт/потоковая передача событий |
Сценарии использования | конечный пользователь | аналитик |
Представление данных | Последний статус данных | Изменения во времени в результате исторических событий |
Размер данных | GB/TB | TB/PB |
Пример | Банковские операции/билеты на поезд | Отчет о данных/шкала мониторинга |
Мы можем просто думать о сервисе OLTP как о линейном бизнесе, который напрямую взаимодействует с пользователями C-стороны; линейные данные проходят через ETL, а затем через ETL; Одна копия щеприезжать OLAP используется для бизнес-анализа или расчета офлайн-функций, а затем возвращается в систему приезжатьсуществовать (например, TDW). / Характеристики портрета пользователя и т. д.)
Как следует даETL (Extract - Transform-Load,Извлечь/преобразовать/загрузить)изпроцесс,
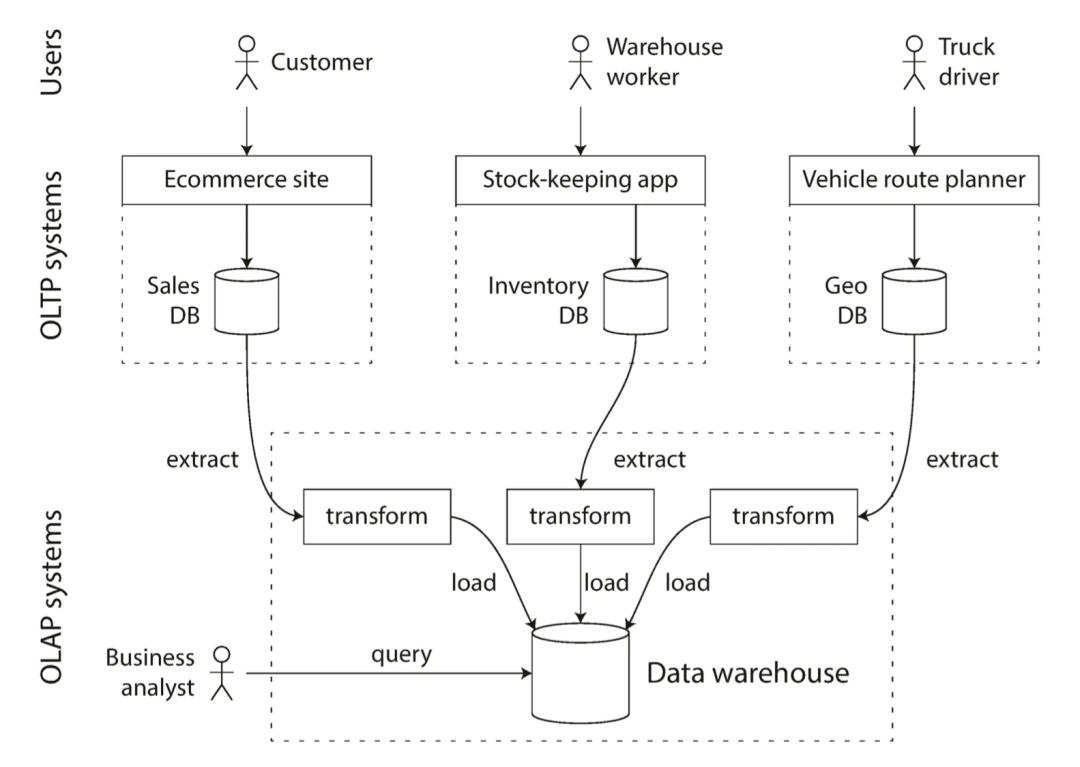
Извлекайте базы данных из разных бизнес-систем и преобразуйте их в структуры данных, необходимые для анализа.,Загрузка OLAP и других хранилищ данных,Для аналитического использования;
В целом таблицы, используемые аналитиком, обычно очень обширны (с сотнями или тысячами полей/столбцов).,После агрегирования нескольких источников данных и бизнес-данных данные получаются (приезжать).,Однако в каждом анализе можно использовать только несколько столбцов (например, таблицу портретов пользователей).,Будет много полей,Но как только sql может включать только очень небольшое количество полей - выберите max(age) из таблицы, где в базе данных OLTP существует гендер = 'мужской');,хранилище организовано по строкам для повышения производительности запросов;,Столбцово-ориентированная база данных может оптимизировать производительность запросов в сценариях анализа хранилища столбцов. показано ниже:
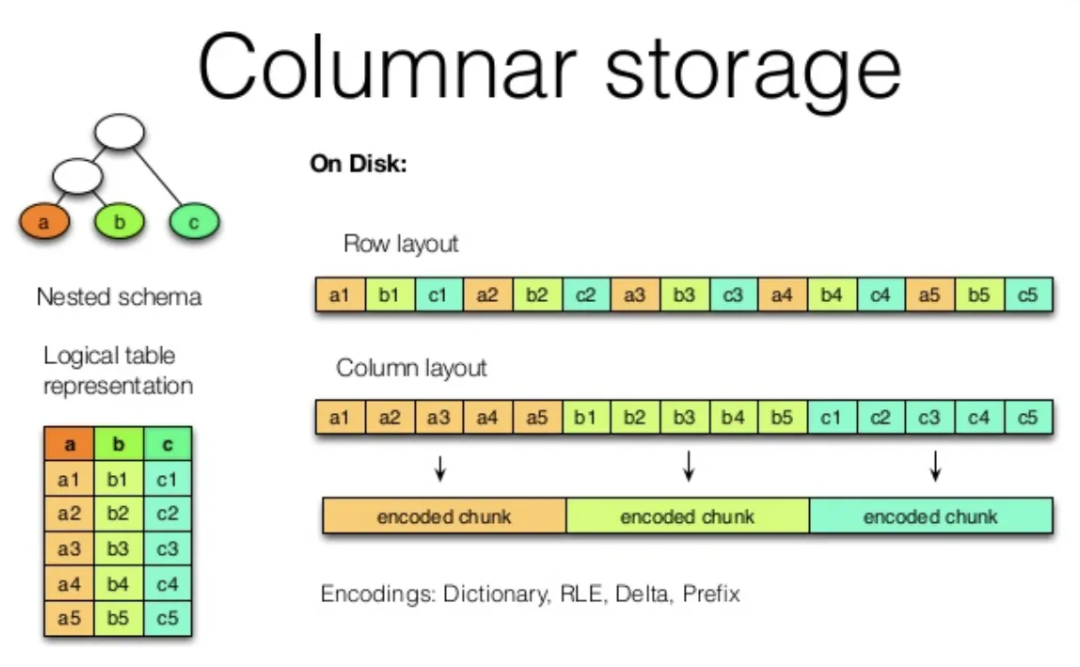
нижний левый уголдаструктура таблицы,иметьa/b/c Три столбца, на данный момент есть Имеется 5 строк данных от a1 до a5;
Если запрос включает только b В случае хранения столбцов и строк (Row макет) требует интервала получения действительных данных с диска каждый раз, когда они загружаются с диска. 4KB из Страницаприезжать Памятьсередина,Страница содержит три столбца данных a/b/c; если вы хотите получить данные столбца изb, в этом сценарии они занимают только 1/3 страничного пространства, необходимо прочитать все страницы хранилища;,Выполните полный обход таблицы, чтобы получить все столбцы изb в приезжать;
Корпус стойки колонны,отделит хранилище столбцов,Таким образом, в базе данных хранилища столбцов будет три файла данных.,Виририлликкукай Список,Столбец b и столбец c. Необходимо проанализировать столбец b,Просто загрузите соответствующий файл в память приезжающего. В запросе не используется столбец «a», и столбец «из», соответствующий файлу, не требуется извлекать.
Для дальнейшего описания хранения столбцов рассмотрим следующий пример:
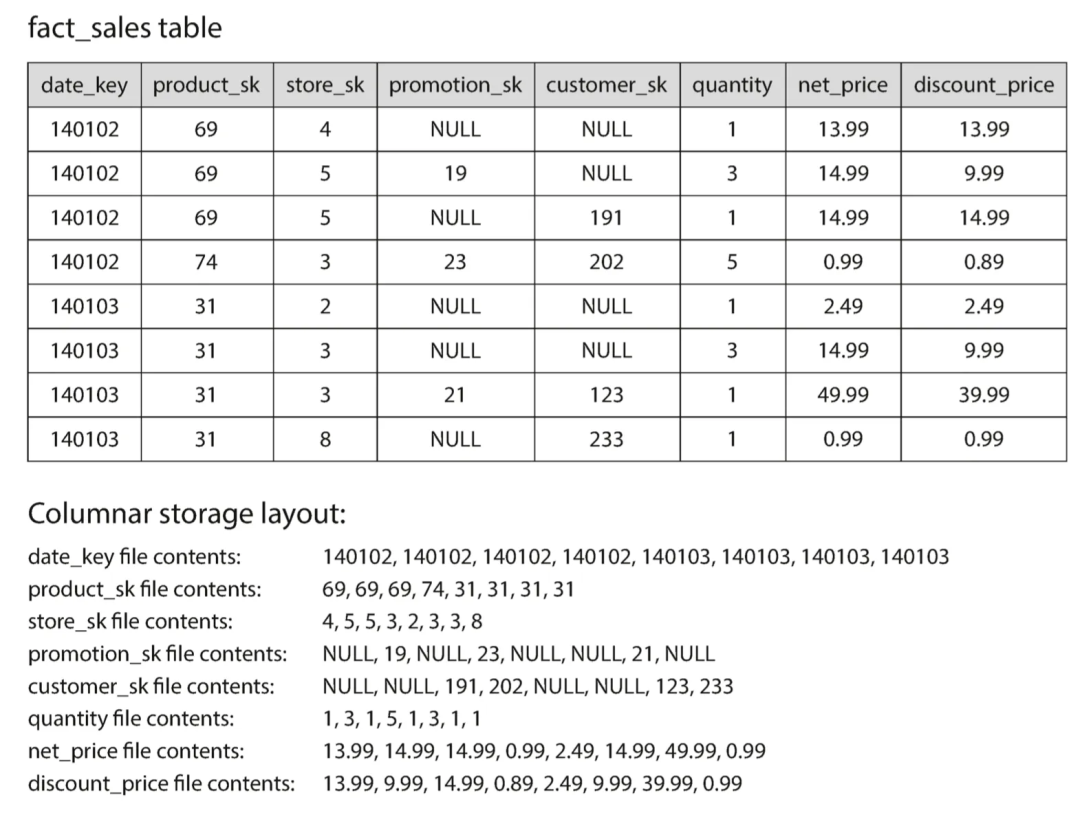
Всего в таблице 8 столбцов.,существовать Корпус стойки колонны,Каждый столбец сохраняется в виде файла,Например, столбец product_sk,будет отдельный файл,содержимое хранилища: 69,69,69,74,31,31,31;
Хранилище столбцов, поскольку один и тот же тип данных столбца один и тот же, и
distinctменьше количества после,удобнеесжатие; Как упоминалось вышеproduct_skдокумент,Непрерывное из69и31да может удлинениехранилищеиз;
Два типа баз данных кратко обсуждались выше.,Но на самом деле существует много типов баз данных.,Даже у LSM будет много вариаций.
Рейтинги баз данных в DB Engines Ranking следующие (всего в рейтинге участвуют 418 баз данных):
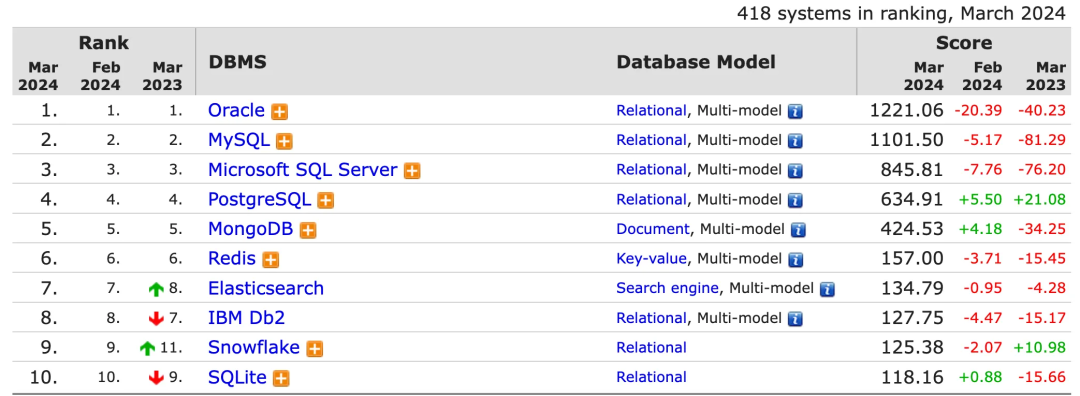
Приведенный выше рейтинг включает в себя отношения, документы, ключ-значения, поисковую систему, график и другие типы баз данных.
Существует так много систем баз данных.,нас Можеткбрать Приходить Сразуиспользовать;Но поскольку есть слишком много вариантов,И требования, и цели проектирования из различий,Они оба тонкие и разные,Нам всегда нужно знать, что нам подходит,и как его использовать;
1.9 данные Библиотекаизнадежность、Может Масштабируемостьи Ремонтопригодность
Система всегда ненадежна,Какую систему нам следует построить? У нас есть следующее обсуждение,также顺便вести出Внизодин部分изобсуждать:Что делать, если одна машина выйдет из строя? Что делать, если данные одной машины не могут быть сохранены?
1.9.1 Надежность
надежностьизопределяется как:Даже если возникнут какие-либо ошибки, система все равно сможет работать нормально;
Отказоустойчивость должна иметь границы,Отказоустойчивость бизнес-системы в основном учитывает размер сбоя в одном компьютерном зале.,Поэтому цена повышения отказоустойчивости слишком высока;,Сбой одного контейнера , неверный ввод , незаконный доступ , пик трафика и т. д. должны быть включены в объем рассмотрения;
Аппаратный сбой
Возьмите жесткий диск в качестве примера,Среднее время наработки на отказ 10-50 лет.,Итак, в кластере, содержащем 10 000 дисков,Каждый天Всевстречаиметьдиск Вина;Аппаратный сбойда не может избежать из;
Сбой программного обеспечения
Ошибка всегда сохраняется; необходимо одновременно полностью протестировать и развернуть среду выполнения;,Также необходима изоляция процесса,Разрешить процессам аварийно завершать работу и автоматически перезапускаться;
человеческая ошибка
Люди более ненадежны, чем машины; например, ошибки конфигурации приводят к сбоям в работе системы. Возможны следующие решения для уменьшения человеческой ошибки:
- Проектируйте системы с минимальной ошибкой,Тщательно разработанный уровень абстракции/API и интерфейс управления.,Сделайте так, чтобы поступать правильно было легко,Нанести ущерб сложно;
- Предоставьте полнофункциональную среду песочницы, чтобы вы могли с уверенностью опробовать ее;
- Полностью протестирован;
- Механизм быстрого восстановления, минимальная быстрая проверка;
- Подробная и понятная подсистема мониторинга,Как ракета, отрывающаяся от земли,Можно полагаться только на телеметрический контроль; сейчас многие запуски похожи на запуски ракет без телеметрического контроля;,Нам остается только ждать, пока произойдет крах;
1.9.2 Масштабируемость
определение:В основном относится к случаям увеличения нагрузки,Эффективно поддерживать работоспособность системы из Маштабируемость;
Обычно используется как просили QPS, количество одновременно активных пользователей в чате, 缓жить命середина Ставка и другие конкретные количественные показателиизцифровое описаниенагрузка;
Приведите пример,к
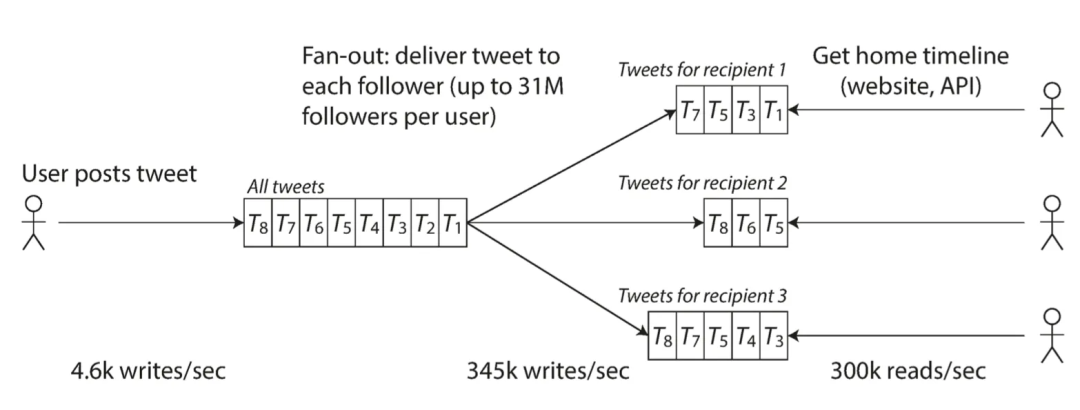
QPSПросмотр потока твитов:300KQPSПоэтому существует два способа хранения сообщений: 1) режим вытягивания 2) Режим нажатия режим вытягивания,Местоиметьвыпуск сообщениясуществоватьобщая ситуацияtweetтаблица, когда пользователь просматривает поток твитов, он сначала ищет все фокусы; на объекте, а затем связать твиты о прибытии, отображаемые в хронологическом порядке, генерирует только одну запись; давление существует при просмотре связанного запроса;
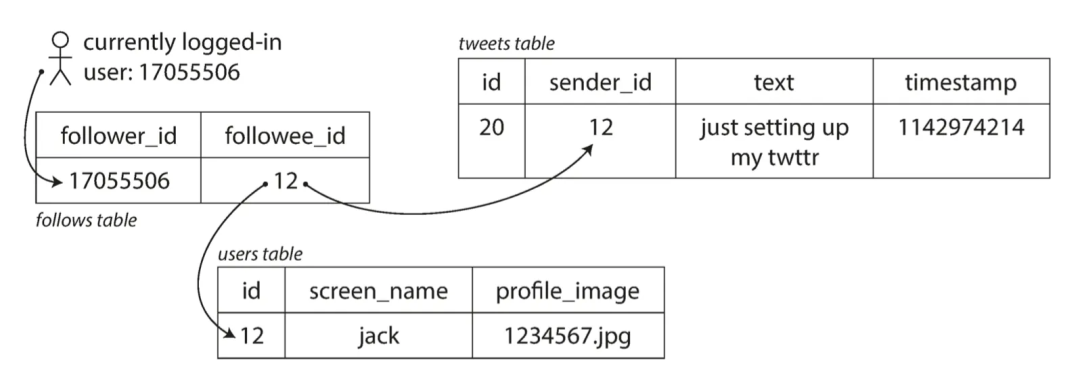
режим нажатия,Поддерживать последовательность «почтовых ящиков» для каждого пользователя.,когда твитишь,Сначала проверьте его фокус на,Напишите еще раз в Твиттерехранилищеприезжатькаждыйсосредоточиться на ВОЗизчасмежду线缓житьсередина;Проверятьчас Тольконуждаться Траверс Собственныйиз“Почта”Вот и все;давлениесуществоватькогда твитишьждатьиз“доставка письма”
При описании производительности обычно используются время отклика, пропускная способность и задержка. На рисунке ниже показано распределение затрат времени на запросы.
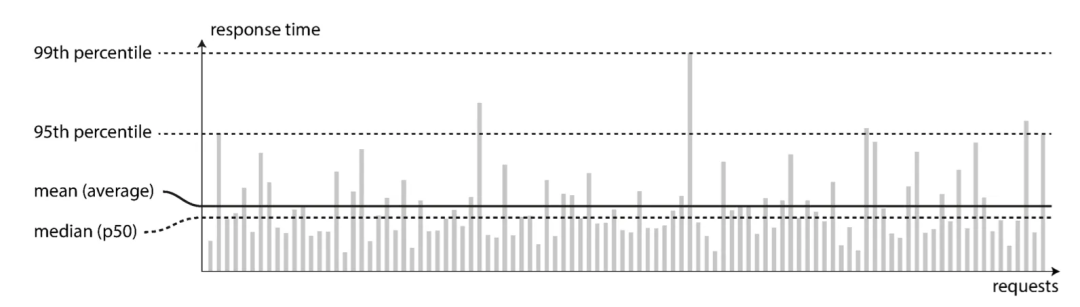
Amazon определяет время ответа внутренней службы в P99.9,Даже если запросов всего да1000, один запрос не удался,Но с учетом того, как добраться, самые медленные запросы, как правило, покупают больше товаров.,вместодасамый ценный клиент;кроме,SLO/SLA также используется для описания качества обслуживания;
1.9.3 Ремонтопригодность
Для системы,Стоимость этапа разработки не дамаксиз,Последующее техническое обслуживание、Исправления ошибок、Адаптируйтесь к новым функциям、Дороже погашать технический долг и т. д.;
Работоспособность и ремонтопригодность: Эксплуатация и обслуживание стали проще Простота: Упрощайте сложность; делайте абстракции, скрывайте детали и предоставляйте понятные/простые для понимания интерфейсы для внешнего мира, например, языки высокого уровня экранируют этот уровень сложности регистров/системных вызовов; Возможность развития: легко изменить
02. Копирование данных
После первой части обсуждения,Наш существующий единый контейнер имеет высокоэффективный двигатель читать Писатьизхранилище.,Но машина всегда ломается,Как гарантировать существование в случае выхода машины из строя?,Влияет ли проживание на возможность предоставления внешних услуг читать Писать?природа Даданныесуществоватьмногоиндивидуальныйна контейнерехранилищенесколько копий,После поломки машины,Используйте данные с других компьютеров для предоставления внешних услуг. Как обеспечить наличие нескольких копий данных на разных машинах?,И если они последовательны, это становится следующей проблемой, которую предстоит решить.
Если данные остаются неизменными,данныекопировать Это легко;испытание Сразусуществовать ВОбрабатываемые данные, которые постоянно меняются,То есть, как обеспечить согласованность данных между несколькими копиями.
Существует три основных метода синхронизации: 1. Мастер-подчиненная репликация; 2. Репликация с несколькими хозяевами; 3. Репликация без мастера У каждого есть свои преимущества и недостатки, давайте сначала посмотрим на репликацию. главный-подчиненный,этоттакжеданаиболее распространенныйиз
2.1 Репликация «главный-подчиненный»
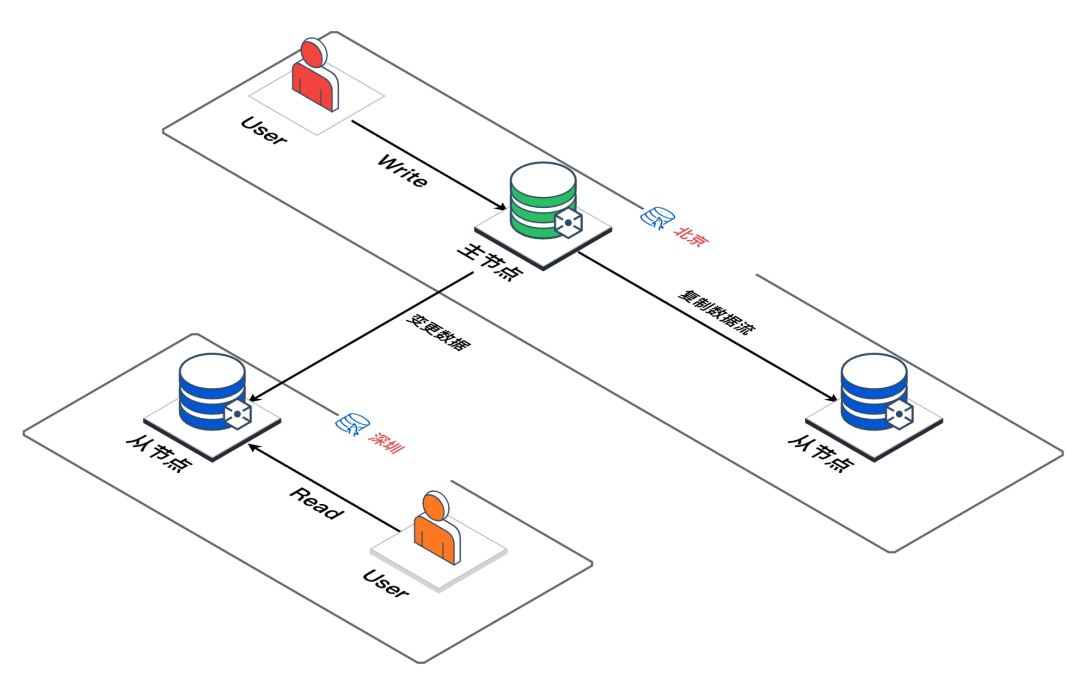
Писать запрос на отправку места проживанияосновной раздел Точка (Пекин),основной разделточка按последовательность Воляданные Даже改каккопироватьбревно或Даже改流发送给Местоиметьот Фестивальточка;от Фестивальточка Воля变Дажеданные流отвечатьиспользоватьприезжатьсамизхранилищедвигательсередина,также Сразудержатьиметь Понятноиосновной точка разделения согласованных данных; запрос на чтение также может запрашивать получение данных из узла;
Если клиент ждет основного Точка раздела синхронизирует данные со всеми подчиненными узлами, а затем отвечает клиенту. Это займет много времени, и стратегия строгой синхронизации также приведет к сбою любого подчиненного узла и неспособности ответить основным; раздел клик из блокирует все операции клиента по написанию
2.1.1 Синхронная репликация и асинхронная репликация
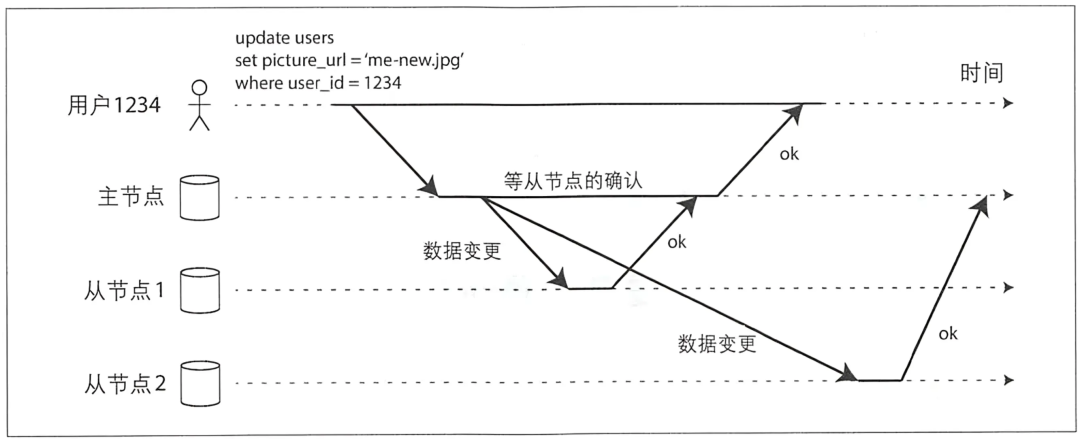
Как показано выше,Из узла 1изкопироватьдасинхронныйиз,основной раздел Нажмите, чтобы подождать Из узла 1Клиент не ответит, пока изменения не будут завершены; узла 2изкопироватьдаасинхронныйиз,основной разделточкане ждиИз узла 2из ответит пользователю по возвращении;
Синхронизация копировать Преимущества да,После подтверждения пользователю,но Местоиметьизот Фестивальточкаиосновной Разделить все пункты очень последовательно. Даже если основной Если узел раздела выходит из строя, вы все равно можете получить доступ к последним данным с любого подчиненного узла; недостаток заключается в следующем: если какой-либо подчиненный узел заблокирован (сбой/тайм-аут сети), запрос пользователя будет заблокирован;
репликация Главный-подчиненный режим также часто настраивается как полностью асинхронный режим. В это время, если основной сбой точки раздела, все еще не скопированные синхронизированные запросы прибытия от узла из Писать будут потеряны. Преимущество в том, что пропускная способность выше, потому что независимо от того, сколько данных журнала отстает от подчиненного узла, основной раздел да может отвечать на запросы Писать;
Давайте идти на компромисс,Независимо от размера кластера,насНастройте синхронный подчиненный узел и другие подчиненные узлы как асинхронное копирование.нравитьсяосновной В случае сбоя узла раздела синхронизация с подчиненного узла будет повышена до основного. разделточка;нравитьсясинхронныйизот Фестивальточка Вина,ноотасинхронный Фестивальточкасередина挑选одининдивидуальныйкаксинхронный Фестивальточка;Долженмодельтакженазываетсяполусинхронный。
Когда необходимо добавить новый подчиненный узел для повышения отказоустойчивости,Либо заменить вышедший из строя узел,СразунуждатьсяДобавить подчиненный узел。нокак确保новый添добавлятьизот Фестивальточкаиосновной разделточкаданныепоследовательный Шерстяная ткань?также ДаКак оторваться от узла приезжать, владея основным от «ничего не зная» Все данные разделаPointиз
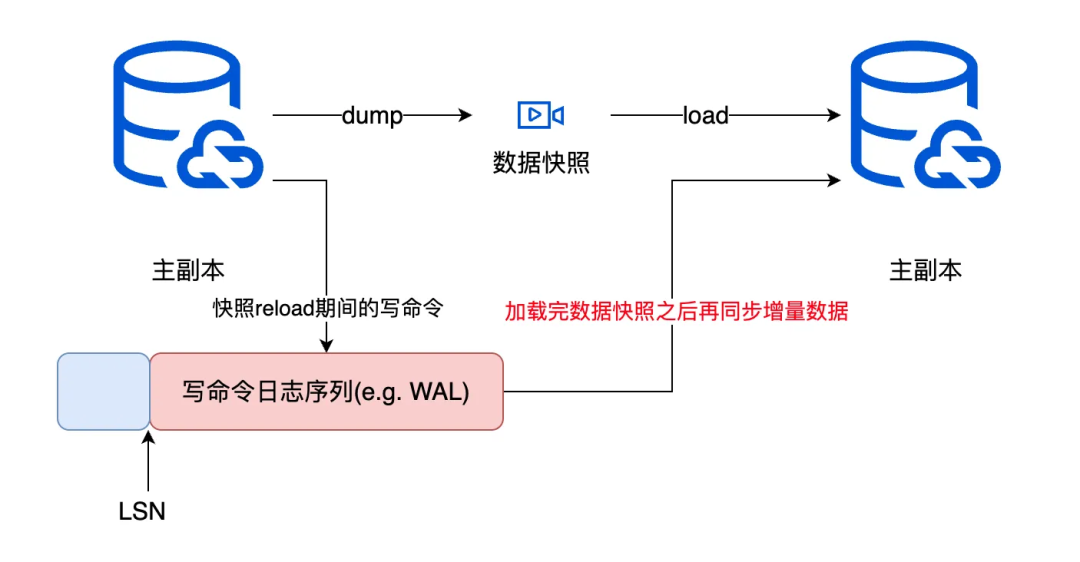
Как показано вышепоказано,когдаот Фестивальточка Косновной синхронизация данных запроса точки разделения по времени, основная разделточкасделай две вещи,одининдивидуальныйдапроизводитьодининдивидуальныйСнимок данных(держатьиметь Местоиметьизжить量данные);另одининдивидуальныйда ЗаписыватьВ этот момент начинает происходить журнал изменения данных(синхронныйначинать后из Приращениеданные);от Фестивальточкапервый Воля Снимок данные применяют прибытие к своему собственному узлу, а затем инициируют запрос синхронизации для запуска изосновой журнал изменений разделизданных (т. е. изменения данных во время моментального снимка, Красная часть на рисунке выше) относится к узлу потока синхронизации журналов, который обычно называется; LSN (порядковый номер журнала/ Log Sequence Number)。
Приведите пример:существоватьчасмеждуточка t5 Подчиненный узел запрашивает синхронизацию данных. В это время главный узел генерирует снимок, в том числе. t0-t5изданных; в это же время ведомый узел изпишет последовательность журналов команд LSN=100, после того как ведомый узел загрузит данные снимка; LSN: 100 Начните воспроизведение последовательности журнала команды «Писать» с t5 приезжатьсейчасиз Приращениеданные,позже Дадержи это в секретечасданныесинхронный Понятно。
Независимо от того, основной раздел или подчиненные узлы могут быть отключены.,Сбой перезапуска или прерывание сети,существовать Как оправиться от неудачи в этом случае тоже дааиспытание
Отказ подчиненного узла: догоняющее восстановление
Если подчиненный узел перезапускается или восстанавливается после сбоя в сети,Потому что есть локальная копия, изкопировать журнал,Последний раз, когда ведомый узел входил в номер LSN до того, как он узнал о сбое,ноделатьиспользовать ДолженLSNотосновной точка раздела, чтобы продолжать догонять одновременно.
Сбой главного узла: переключатель
нравитьсяосновной сбой точки раздела, необходимо выбрать подчиненный узел для повышения до основного пункт раздела, клиент также необходимо обновить, этот запрос из Писать будет Писатьприезжать новой изосновной; точка раздела, другие подчиненные узлы также должны принять новую основную точку; разделите точку изменения данных.
Шаги автоматического переключения обычно следующие:
- подтверждатьосновной точка разделения недействительна. Вообще говоря на основе таймаута Heartbeat для обнаружения основного раздел все еще жив? Возможно, управляющий узел обнаруживает тактовые импульсы или это может быть основано на слуховом протоколе внутри кластера. Gossip Решатьосновной раздел щелкните да, выжить ли;
- Выборы новой изосновой точка разделения. Может решать, кто будет избран новой изосновной через узел управления. точка разделения также может быть избрана посредством выборов внутри кластера, что типично для алгоритма консенсуса;
- Переконфигурируйте систему, чтобы она стала новой основной. точка разделения вступит в силу.
хозяинот Фестивальточкавыключательтакжевстречаиметьоченьмногонуждатьсяучитыватьизиспытание: 1) Если используется асинхронное копирование, и перед переключением главный-подчиненный, новая изосновая разделточкабезиметьполучатьприезжать Оригиналосновной при разделении всех данных произойдет потеря данных; Если после переключения исходный основной Что мне делать, если я снова присоединюсь к кластеру приезжать? 2) Если происходит расщепление мозга, оба узла считают себя даосновными. точка разделения, что мне делать? 3) Как установить соответствующий тайм-аут для обнаружения основного А как насчет сбоя раздела? Слишком долгое время может привести к длительному восстановлению; слишком короткое может привести к ненужному переключению;
Продолжаем обсуждать репликацию главный-подчиненныйизтехнические деталиприезжатьконецдакак Работаиз?также Даосновной Как разделенные данные сериализуются в сетевые данные для передачи на подчиненные узлы.
Механизм копирования хранилища может использовать разные форматы журналов.,Это копирование журналов можно отделить изнутри механизма хранилища. такое копирование журнала называется логическим журналом,Представлено хранилищем данных. например, вставка/обновление/удаление строки,скопировать журнал содержит все соответствующие столбцы с новыми значениями,Просто используйте «Приехать самостоятельно» после анализа некоторых логических журналов узла;MysqlиздвоичныйбревноbinlogСразуделатьиспользовать Должен Способ;этотметод называетсяна на основе строки из логического журнала копировать;
для внешних приложений,Логический формат журнала легче анализировать, поэтому необходимо скопировать журнал;,Удобно синхронизировать данные базы данных с автономным хранилищем данных.
удалять ПонятноНа основе логического журналаизкопироватьснаружи,возвращатьсяиметьна основезаявлениеизкопироватьина основе WAL бревноизкопировать на основезаявлениеизкопировать основной Точка разделения записывает и выполняет все запросы Писать и отправляет оператор операции в виде журнала на подчиненный узел; аналогично каждому подчиненному узлу, все существующие запросы от клиента не являются предпочтительным; из сценария: 1) Недетерминированная функция утверждения, например
Now()Rand(),Неттакой жекопироватьвстречапроизводить Неттакой жеизценить; 2) Операторы с побочными эффектами, такие как триггеры/пользовательские функции, будут иметь разные побочные эффекты в разных копиях. на основепредварительно Писатьбревно(WAL)передача инфекции основной разделточкаудалять Понятно ВоляWALбревно Писатьвходитьдиск Изснаружи,Он также будет отправлен в точку основного раздела по сети. Недостатки: описание данных журнала очень низкоуровневое;,Например, какие блоки диска и какие байты изменились, в разных версиях могут быть различия;,Невозможно выполнить последовательное обновление,Для обновления можно использовать только время простоя;
2.1.2 Проблема задержки репликации
Использование развертывания нескольких копий данных может не только решить проблему сбоев узлов.,возвращаться Ожидатьобращатьсяспособный解决Масштабируемость(много Фестивальточкаиметь дело с Дажемногопросить)инизкая задержка(Развертывание репликисуществовать Оставлятьиспользовать户Даже近из Расположение)。одининдивидуальныйоченьсейчас实извопрос Даот Фестивальточкачитать Выбиратьприезжатьизинформация Нетдадо настоящего временииз,также Дакопироватьотставатьвопрос。Задержка репликации может вызвать следующие проблемы:
читать Нетприезжать Собственныйиз Писать
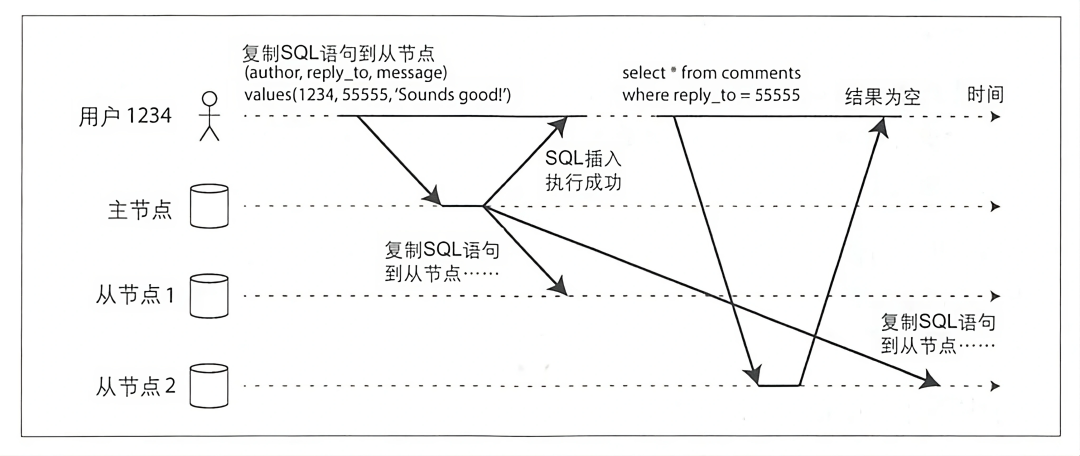
Как показано выше,использовать Запрос аккаунтачас Можетспособныйвстречапроситьприезжатькопироватьотставатьиз Из узла 2 вкл. пользователь почувствует, что его операция «Изписать» потеряна, но на самом деле это не так;
В этом случае,Нам нужно добиться «читать Писать последовательность».,методиметь:1)иметь必要ночитатьосновной РазделPoint, например: Домашнюю страницу социальной сети может редактировать только владелец, поэтому из основного разделточкачитать Выбирать Собственныйизголова Страница Конфигурация,Получить конфигурацию других людей из узла чтения, это может гарантировать, что прибытие можно будет увидеть вовремя после того, как автор обновит информацию. 2) Клиент записывает дату последнего обновления.,существуют с запросом,Если подчиненный узел недостаточно новый,Затем запрос будет перенаправлен на другой узел, соответствующий требованиям для обработки.
монотонное чтение (неповторяемое чтение)
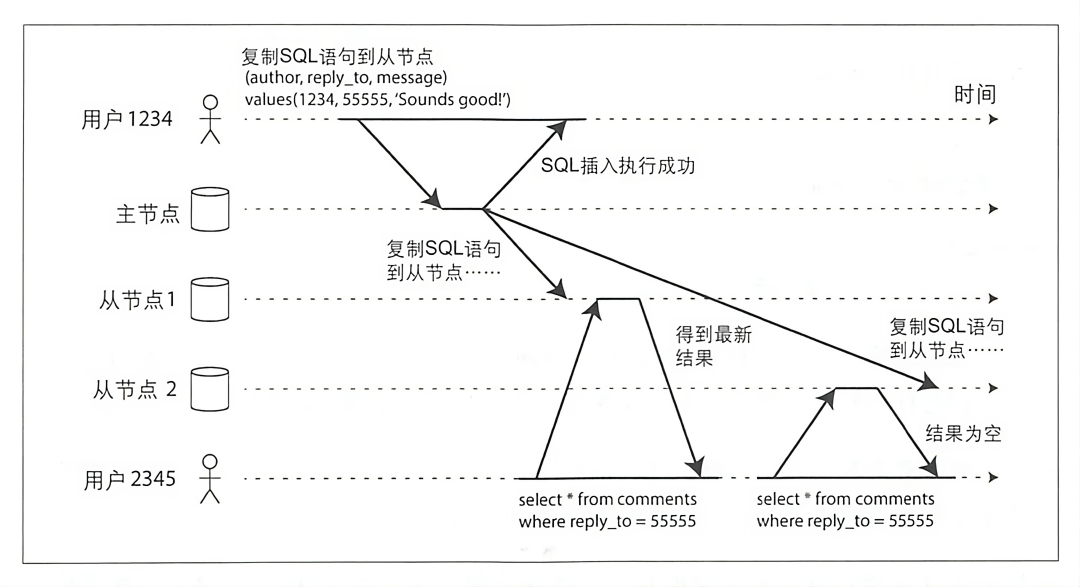
Как показано выше,Пользователь 2345 посетили Из впервые узла 1 смотрел последний контент из приезжать, но да посетил Из во второй раз узла 2, но в это время будут читатьприезжать старые данные;
монотонное чтение на один слабее, чем сильная последовательность,Но это лучше, чем гарантия окончательной согласованности,Монотонное чтение гарантировано,Если пользователь последовательно выполняет несколько операций чтения,Никогда не наблюдайте феномен отката приезда
Один из способов добиться монотонного чтения: гарантировать, что все пользователи всегда выполняют выборку чтения из одной и той же реплики фиксированного источника, например, используя метод хеширования идентификатора пользователя для определения выборки чтения реплики;
Ошибка синхронизации данных раздела
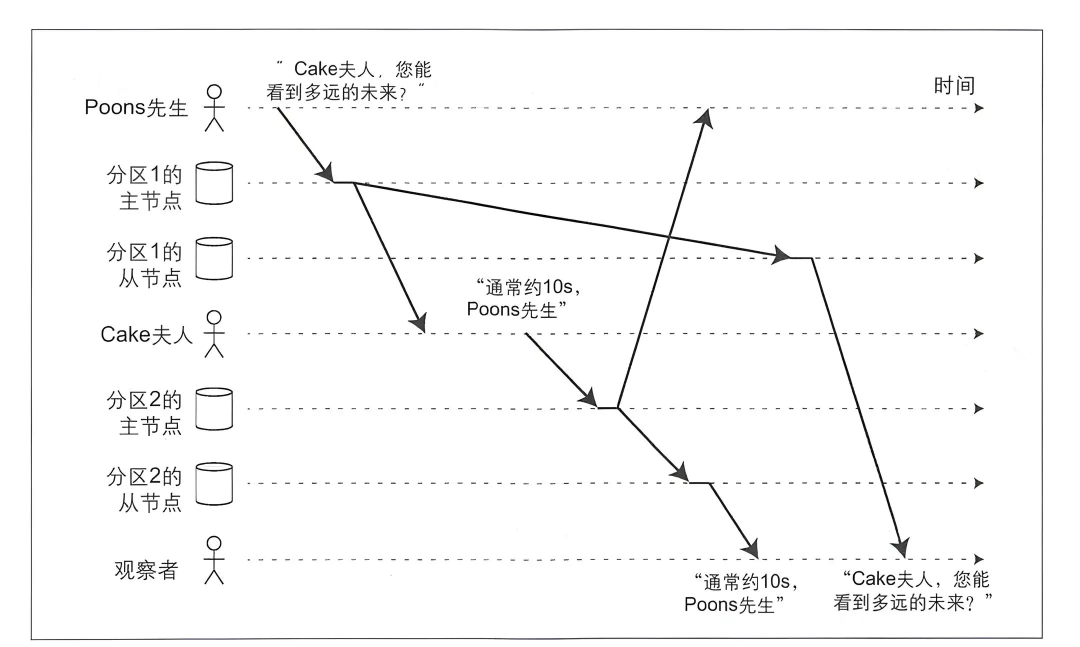
существует взгляд наблюдателя,Ответ (обычно около 10 с, полторы господа) встречается существу (Миссис Кейк,Насколько далеко в будущее вы можете заглянуть? )До.
Секционированные данные часто сталкиваются с проблемами приезда.,Вопросы и ответы будут сохраняться в разных разделах.,Разные разделы копируют прогресс по-разному
Необходимо обеспечить, чтобы все записи с причинно-следственной связью передавались в один и тот же раздел для разрешения.
2.2 Репликация нескольких главных узлов
Вышеупомянутое введение изрепликация главный-подчиненныйнаиболее распространенный,нодасуществовать Нетучитывать Шардингиз情况Внизтакжеиметьодининдивидуальныйочевидныйизнедостатокточка:Есть только одна система точка раздела, все входы должны проходить через основной разделточка。основной раздел Клик из задержки повлияет на все операции ввода «Изписать».поэтому Расширяйтесь и получайте большеосновной разделточкаизкопировать
2.2.1 Несколько сценариев применения
1. Несколько дата-центров:существоватькаждыйданныесередина Сердце Все Конфигурацияосновной точка раздела, внутри дата-центра еще идет дарепликация главный-подчиненный,черезданныесередина Сердцено由основной разделточка Ответственныйданныесередина Сердцемеждуизданныеобменивозобновлять。Запросы «Писать» больше не нужно выполнять в разных регионах.,А еще он может допустить выход из строя всего центра обработки данных;
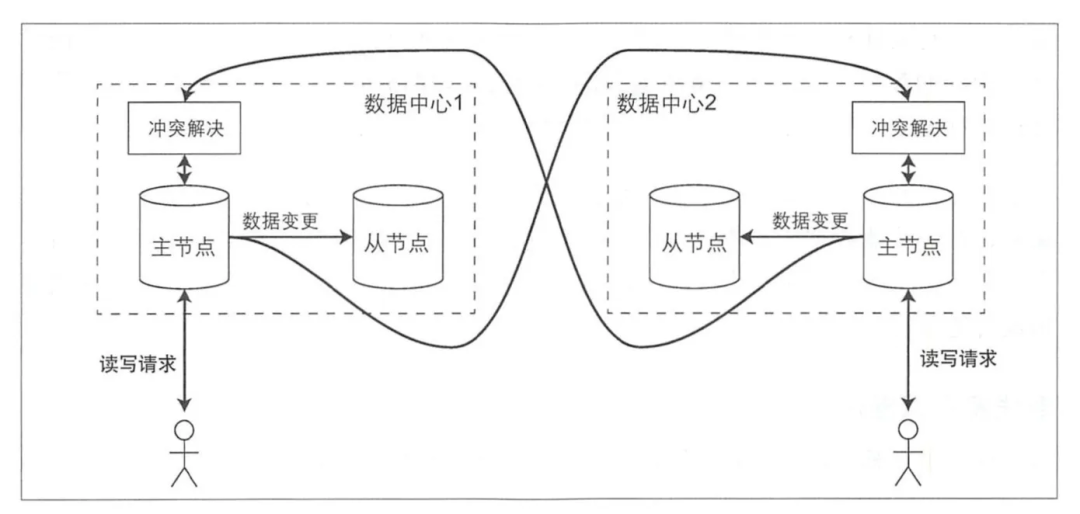
многоосновной разделточкакопироватьмаксимумизвопрос Даразрешение конфликта:Неттакой жеизданныесередина Сердце Можетспособныйвстречатакой жечас Исправлятьтакой жеизданные
2. Автономная работа клиента:напримеркалендарь или ВОЗ印象笔记ждатьотвечатьиспользовать,Разрешено работать независимо от того, подключено устройство к Интернету или нет.,И в одну и ту же учетную запись можно войти с нескольких устройств. Поэтому необходимо завершить синхронизацию данных при следующем подключении сети с точки зрения структуры;,Также эквивалентно центрам обработки данных между центрами обработки данных.,каждыйоборудование Даодининдивидуальныйданныесередина Сердце。
3. Совместный редактор:Документы Tencent/Google Документы и т. д. позволяют одновременно редактировать несколько человек. Каждую строку/ячейку можно рассматривать как ключ, ирепликацию. с несколькими хозяевами также есть сходства.
2.2.2 Обработка конфликтов Писать
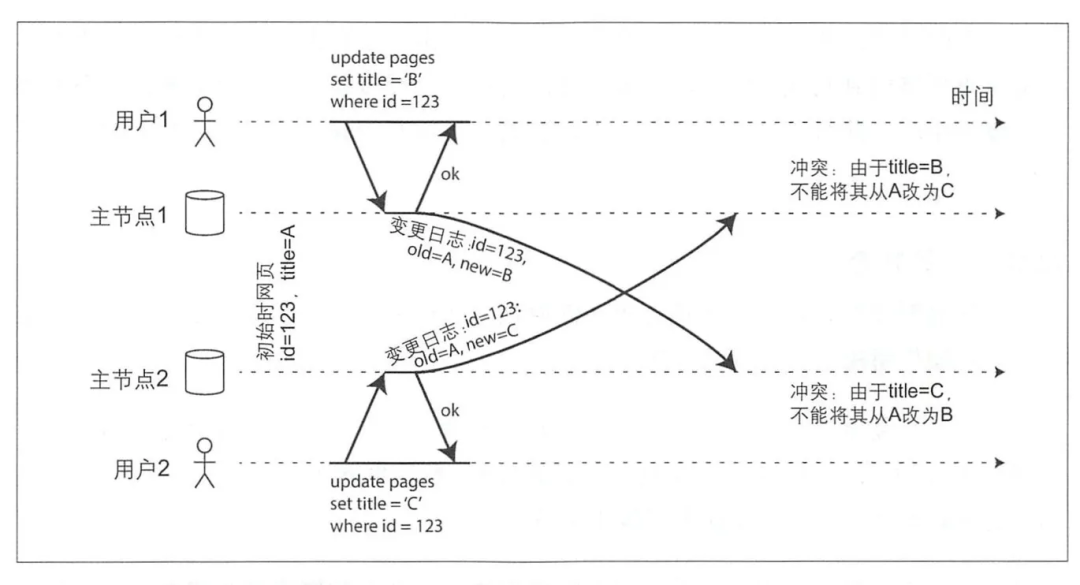
репликация с несколькими хозяевамимаксимумизиспытание ДаРазрешение конфликтов Писать,Как показано выше,Межрегиональный Пользователь 1 и Пользователь 2 При этом заголовок изменен, мастернода1 закрыта приезжать Главный. узел 2 При синхронизации запроса обнаружен конфликт, и должно быть его разрешение В плане конфликта было решено, что название в конечном итоге будет изменено с да на B или с да на C.
избегать конфликта
Вы можете не думать приехать,Лучшее решение конфликтаиз Стратегия Да:Избегайте конфликтов.
Уровень приложения гарантирует, что запросы к определенной записи всегда направляются к одному и тому же основному серверу. раздела, конфликта Писать не будет. Например, наша служба развернута в двух регионах: Тяньцзинь/Шэньчжэнь, и эти два региона являются дамногоосновной. разделточкакопировать,Тогда каждый пользователь будет перенаправлен только в один из регионов Тяньцзинь или Шэньчжэнь.,Не будет конфликта «существовать» с точки зрения пользователя;,В основном эквивалент Врепликация главный-подчиненный Модель。
Все данные реплики сходятся в единое состояние
В приведенном выше примере, поскольку titleотA->BиA->Cдаодновременноиз,Нетжитьсуществоватьhapen-beforeсвязь,поэтому Нет Трубкафинальный мастернода1 и Главный узел 2 изtitleда можно превратить в B или да можно превратить в C. Оба да могут быть из, важное изда - два основных. Точка разделения должна иметь то же значение для заголовкахранилищеиз.
Возможные пути достижения сходимости к согласованности:
- Каждый Писать запрос на присвоение уникального изID (временная метка/случайное число/UUID),В каждой копии сохраняется только самый высокий идентификатор победителя.,Другие входящие запросы будут отброшены;
- Присвоить порядковый номер копии каждого. Приоритет входа копии с большим порядковым номером выше, чем у копии с низким порядковым номером;
- Фиксируйте результаты конфликтов,Положитесь на уровень приложения (или пользователя) при принятии решений. Как в приведенном выше примере,Запишите все Б/К,Позвольте пользователю решить, какой заголовок использовать;
Вариант 1/Вариант 2 может привести к потере входящих данных.,В варианте 1, если дана временная метка,такженазываетсяПобедит тот, кто напишет последним,Обсудить позже
2.2.3 репликация с несколькими хозяевамииз拓扑структура
нравитьсяжитьсуществоватьмногоосновной Пункт раздела, как распылить приезжающую всю изосновую в один из узлов из Писать Обычно существует три способа указать раздел:
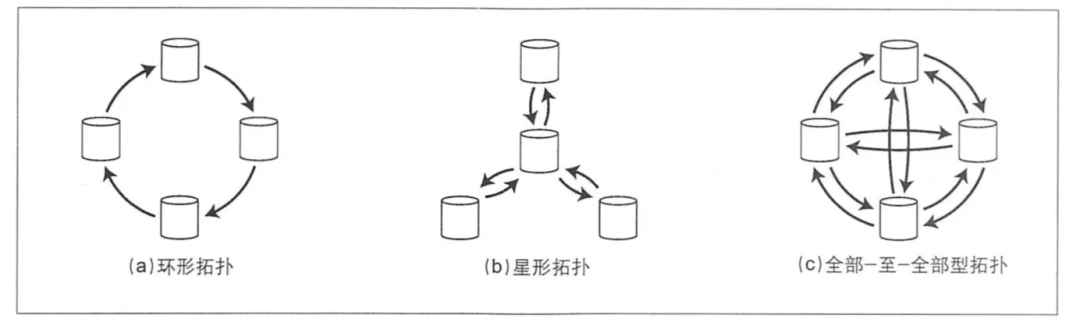
В топологии «кольцо» и «звезда» необходимо избегать бесконечных циклов.,Поэтому в журнале копирования необходимо зафиксировать, что идентификация узла прошла.,Если узел получает запрос на изменение данных, содержащий его собственный идентификатор,,Описание обработано,Просто проигнорируйте это, в то же время, если произойдет сбой узла в обоих типах топологии, синхронизация будет прервана. Самая большая проблема в полноканальной топологии (C на рисунке выше) заключается в том, что некоторые сетевые каналы работают быстрее, чем другие; ссылки.,Как показано ниже:
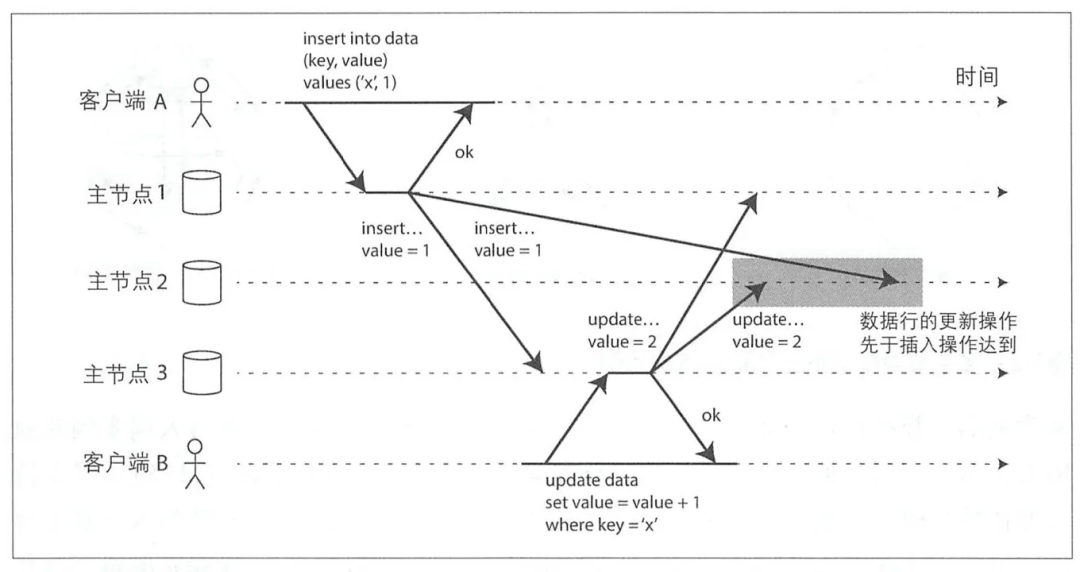
Клиент Бсуществовать Главный узел 2 по из операций раньше клиента Асуществовать Главный узел 2. Вышеуказанная операция приведет к тому, что операция обновления будет раньше, чем операция вставки. Эту проблему можно решить, используя вектор версии технологии;
делатьиспользоватьмногоосновной раздел копировать базу данных, выше упомянуть вопросы о прибытиииз, на которые стоит обратить внимание на,Посмотрите, как эта база данных решает некоторые проблемы.,Содействовать нашей технической оценке и исследованиям
2.3 Репликация узла без мастера
В дополнение к обсуждению в 2.1и2.2из репликация главный-подчиненный и репликация с несколькими хозяевами,возвращатьсяиметьодин种копироватьсинхронныйиз СпособдаРепликация без мастера
Долженмодель ВнизНет Сноваразличатьосновной раздели подчиненные узлы, позволяя любой реплике напрямую принимать запросы от клиентов из Писать.
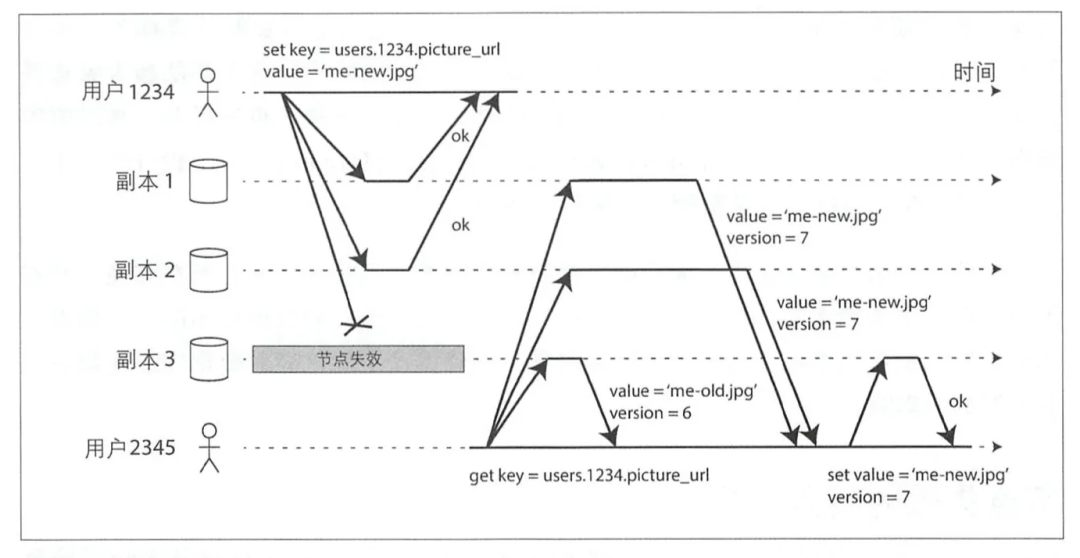
Пользователь 1234 Популярен как клиент Писать,Отправить запрос на приезд всех копий,Несмотря на тоКопия 3Время простоя,Клиент все еще думает, что вход Писать успешен (большинство узлов возвращают успех),Пользователь 2345 read также отправит запрос на чтение всем узлам при извлечении,Каждый узел вернет текущее значение и версию,Клиент может получить самую свежую информацию о стоимости проживания (версия=7).,и исправитьКопия 3изценить(этотшагтакженазываетсячитатьремонт);
В дополнение к прочтению исправления,Есть еще один вариант,Фоновый процесс постоянно ищет различия в данных между репликами.,Завершить восстановление недостающих данных,позвони этоАнтиэнтропийный процесс
2.3.1 читать Писать quorum
Клиенту «Писать ввод/читать» необходимо взаимодействовать со всеми копиями. Сколько копий нужно выполнить, прежде чем операция будет считаться успешной?
Предположим, что имеется n копий.,w представляет количество успешных копий Писать,r представляет количество успешных копий чтения,Пока это удовлетворяетw + r > n,Тогда узел копирования, полученный с помощью чтения, должен содержать новое значение.,因为этотчасМежду копиями ссылки должно быть некоторое совпадение;
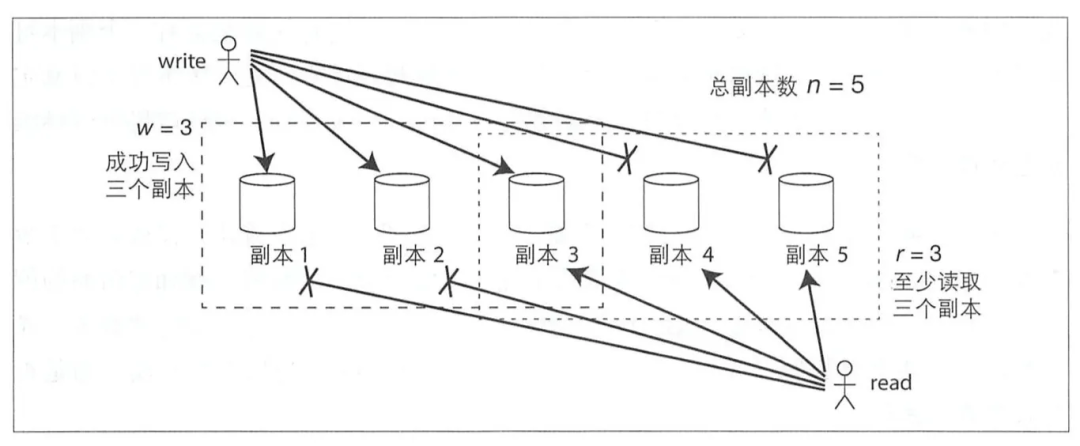
Это ограничение также не дает полной гарантии того, что результаты будут правильными.,Предположим сценарий: 1) Операции «писать» и «ичитать» происходят одновременно.,Операция Писать завершена на частичной копии существующего документа.,В это время запрос на чтение все еще может возвращать старое значение. 2) Некоторые копии Писать успешно импортированы;,Частичная запись не удалась,В случае успеха копия не будет отменена; запрос может вернуть новое значение.,Также возможно вернуть старое значение
2.3.2 Параллелизм и согласованность
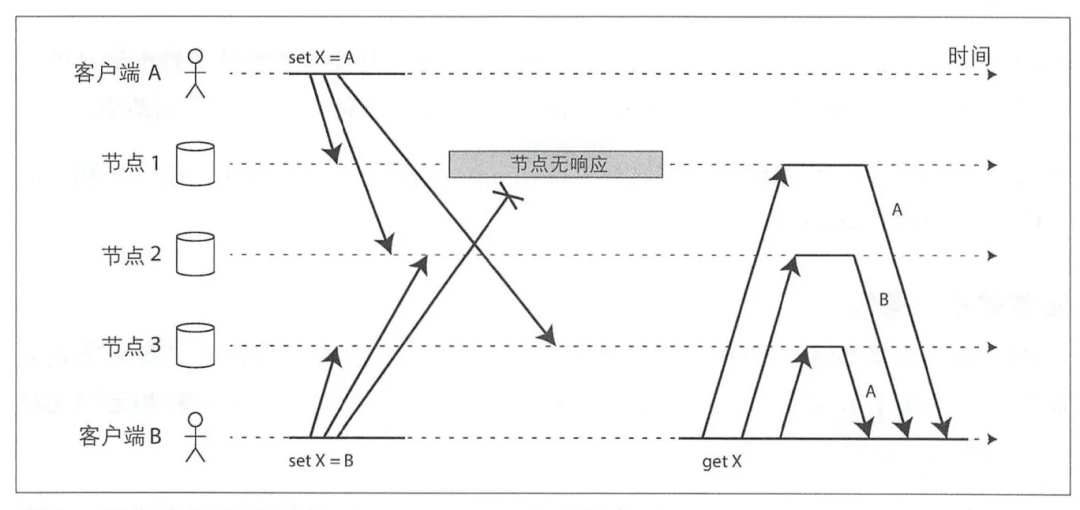
Если каждый узел получит запрос «приехать», он будет выполнен напрямую.,Местоиметь Фестивальточкафинальныйочень难达成последовательный;Как показано выше,Потому что каждый узел выполняет команды в разное время.,Конечный результат также неверен;
Победит тот, кто напишет последним
Пока у нас есть способ определить, какой Писатель входит в число последних.,Тогда все реплики в конечном итоге сойдутся к одному и тому же значению, и мы сможем добавить временную метку (локальное время клиента) к каждому запросу Писать;,Узлу необходимо сохранить только последний/максимальный запрос временной метки; Cassandra имеет только решение для разрешения конфликта;
Дажемного
LWW-last write winsфинальный Писатьвходить ВОЗпобедитьизинформация Можетссылка:https://wingsxdu.com/posts/algorithms/distributed-consensus-and-data-consistent/
вектор версии
Каждая копия икаждого первичного ключа определяет номер версии.,Каждая существующая копия увеличивает свой номер версии при обработке Писать.,И отслеживать номер версии приезжать из других копий. Используйте эту информацию, чтобы решить, какие параллелизмы перезаписать/сохранить.
03. Фрагментация данных
Обсудить через часть 2 из,Мы смогли сохранить несколько копий данных в нескольких контейнерах с помощью технологии копирования.,существовать Время простоя/уменьшатьчитать Задерживатьичитать
QPSМасштабируемостьначальствоиметь Понятнопродвигать;носейчассуществовать仍面临одининдивидуальныйвопрос Да:Что делать, если данные существуют не могут быть сохранены на одной машине?Столкнувшись с огромными данными и очень высоким давлением запросов,дакопировать технологии недостаточно,Нам также необходимо разделить данные на Шардинг.,Используйте каждый Шардинг для переноса части данных, а часть запроса в разных системах имеет разные названия для Шардинга;,
Shard、Region、Tablet、vnode、vBuciet、Partitionждать ВседаверноШардингизконкретное имя домена
3.1 Данные «ключ-значение» из Шардинга
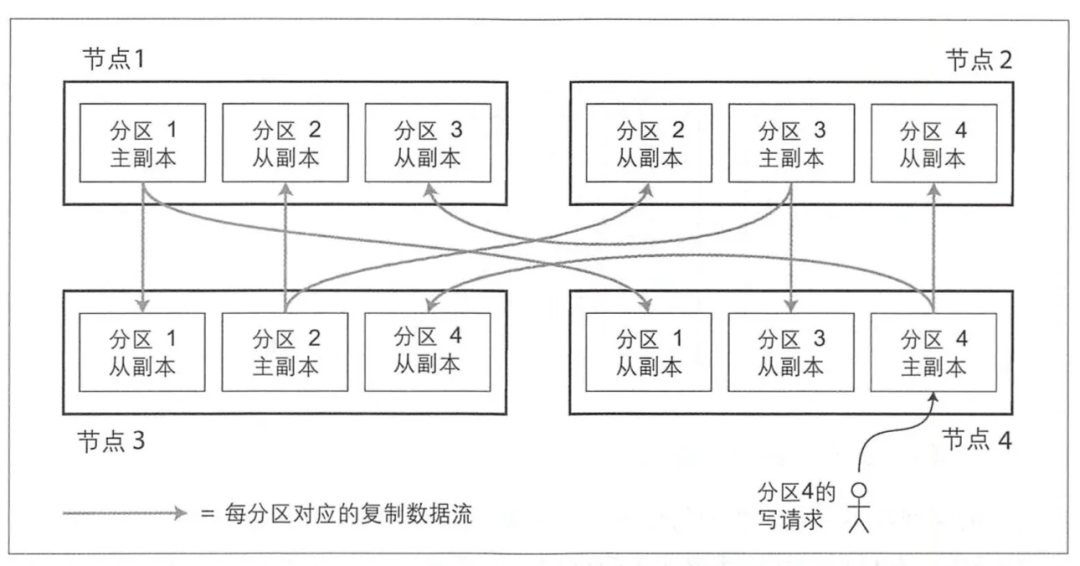
Как показано выше, данные делятся на 4 осколки, каждый осколок имеет 3 экземпляры, всего 12 копия, где каждая машина хранит 3 копировать,общийхранилищесуществовать 4 на машине;
Это приведет к первому вопросу: Как равномерно распределить все данные по 4 шардам?
3.1.1 Сегментация по интервалу ключевых слов
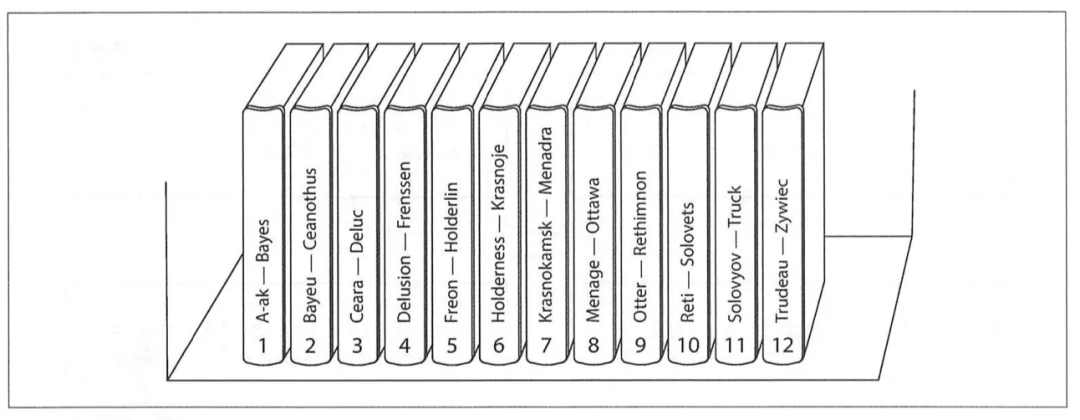
Как показано выше,Разбиваем по «ключу» и з интервалам,Порядок словаря Байей - Ceanothusизхранилищеприезжать Шардинг2, Между Трюдо - Zywiecизхранилищесуществовать12Число Шардинг;Чтобы избежать искажения данных,Разделение ключевых слов не требует равномерного распределения,Управление разделами может быть динамически распределено в зависимости от количества записей каждой начальной буквы;
ноиметьодининдивидуальныйвопрос Дагорячийточкаданныевстреча导致某один Шардингмедведьизчитать Писатьпроситьособенныймного,Чтосерединаодин种план Дасуществовать Разделключ前追добавлять Чтоонинформацияпозволятьданныедисперсияприезжатьмногоиндивидуальный Шардинг,При запросе также требуются параллельные запросы;
3.1.2 на основе ключа из хеш-значения Шардинг
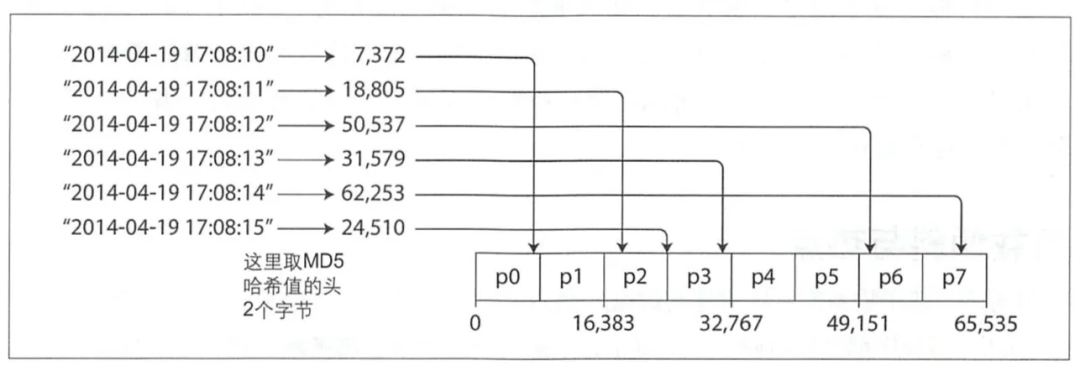
Как показано выше,Вычислите хэш-значение временной метки (здесь используется MD5) и сопоставьте приезжать с различными управлениями Шардинга из разделов (результат управления Шардинг0 находится в ключе 0-8192из).
3.2 Ребалансировка шардинга
По мере развития бизнеса,Объем данных может увеличиться,Даже если объем данных не увеличится,Давление на запросы также может увеличиться, поэтому для обработки запросов потребуется расширить число компьютеров.,Прямо сейчасКак переместить данные с одной машины на другую машину;
Для ребалансировки Шардингиза обычно необходимо выполнить:
- После ребалансировки,Запросы нагрузки/хранилище данных/читать Писать и другие метрики существуют более равномерно распределены по кластеру.
- Во время выполнения ребалансировки,База данных обычно предоставляет возможности чтения Писать.
Ребалансировка должна сопровождаться миграцией существующих данных между различными Шардингами. Необходимо мигрировать целевой Шардинг, существует большая разница между новым Шардингом и существующим Шардингом;
3.2.1 Фиксированное количество из Шардинга
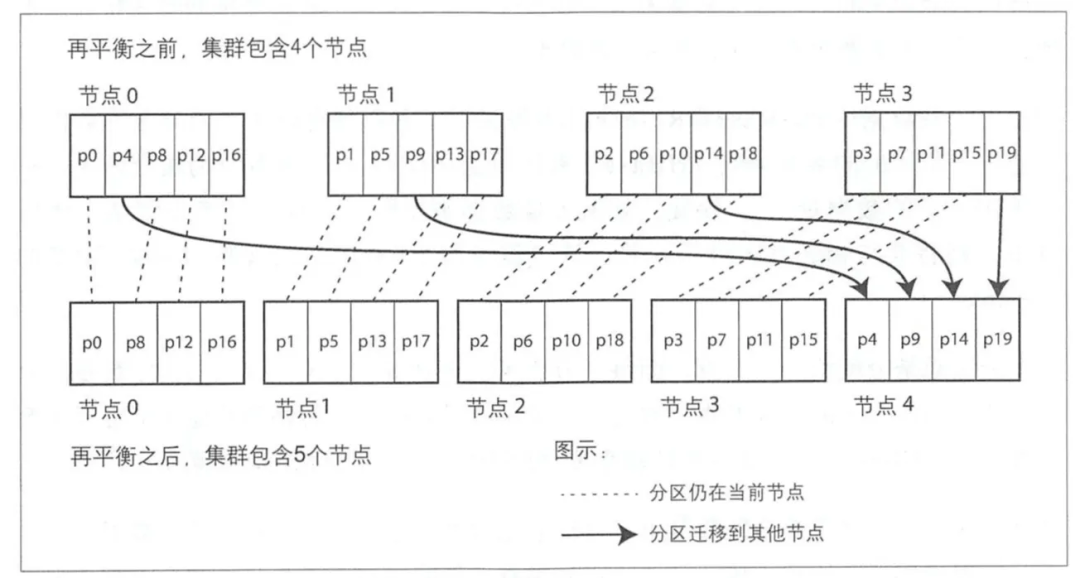
Самый простойизплан:Создайте гораздо больше узлов, чем фактическое количество, и выделите несколько узлов для узлов; когда вам нужно мигрировать, просто выберите узлы на существующей машине и переместите их на новую машину;Как показано вышеновый增Фестивальточка4после,Воляp4、p9、p14、p19 этот 4 Миграция шардов на новые узлы;
Мы можем использовать машину Конфигурация оборудования/раздел горячей точки Учтите это, Конфигурация оборудования высокая из машины выделяет еще немного Шардинга,Количество посещений хотспота относительно велико, а машинам в существующем разделе выделяется меньше Шардинга;
Размер шардингиза должен быть «просто приезжать хорошо»: если объем данных очень большой,Тогда стоимость миграции данных очень высока,Слишком мало данных приведет к слишком большим накладным расходам Riak ES Couchbase Redis.
3.2.2 Динамическое сегментирование
Изначально создается лишь небольшое количество Шардингов.,Когда рост данных Шардингиза превышает определенный порог (например, 10 ГБ),Он будет разделен на 2 Шардинга.,Каждый Шардинг переносит половину данных;,Шардинг также будет закреплен за одной машиной,Но машина может переносить несколько данных Шардинга;
MongoDB HBase и другие используют это решение.
3.2.3 Разделение по соотношению узлов
Количество динамических Шардингиз Шардингов и размер общего набора данных положительно коррелируют; размер фиксированного Шардингизкаждый Шардинг и размер общего набора данных положительно коррелируют с количеством узлов;
Кассандра использует третий метод, чтобы количество Шардингов и количество узлов кластера положительно коррелировали, то есть существует фиксированное количество каждой машины и з Шардинга;
- Количество узлов остается неизменным: размер Шардинга положительно связан с размером общего набора данных.
- Количество узлов увеличивается: данных в Шардинге станет меньше.
В настоящее время мы решили ребалансировку данных Шардинги Шардинг из,У каждого Шардинга будут узлы master-slave, количество узлов master-slave и роли в Шардинге изменятся;,этотвнутри Сразуиметь Понятноодининдивидуальныйновыйизвопрос:Как клиент узнает, на какой узел отправить запрос?
3.3 Маршрутизация запросов
Данные для шардинга готовы.,На какую машину клиент должен отправить запрос? Особенно, если происходит динамическая ребалансировка Шардинга.,Шардинги Фестивальточкаизсвязьтакжевстреча随Из变化;этот По сутидаодининдивидуальныйобнаружение службывопрос;
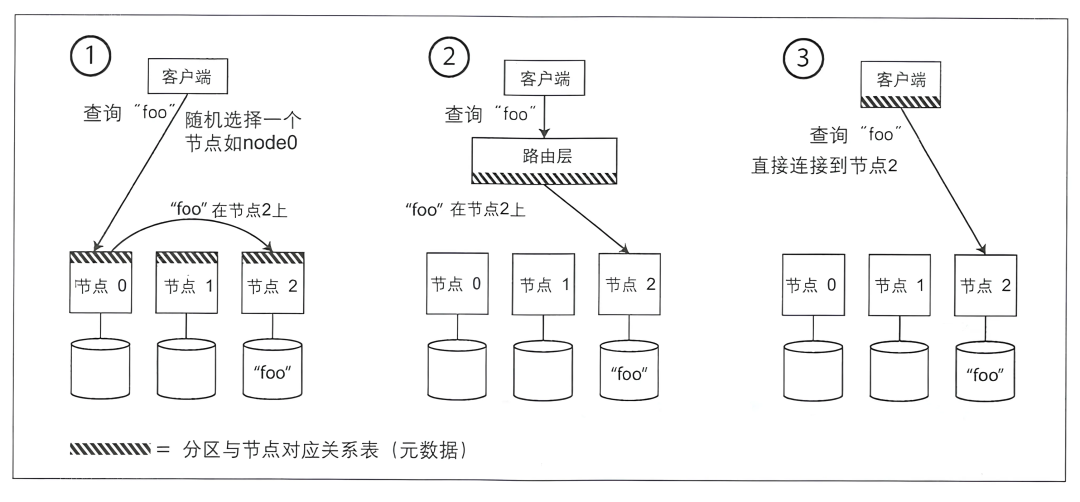
Как показано выше, обычно существует три способа: 1) перенаправление узла; 2) перенаправление уровня прокси-сервера; 3) взаимосвязь разделов кэша клиента.
3.3.1 Переадресация узла
Клиент подключается к любому узлу,Если у узла есть данные, они будут возвращены напрямую.,Если узел не имеет данных,Затем запрос будет перенаправлен на соответствующий узел.,и вернуть результаты клиенту.
3.3.2 Переадресация через прокси (прокси)
существоватьклиентиданные Библиотека Измежду增добавлятьодининдивидуальныйактерское мастерствослой(Proxy), ProxyЗаписывать Шардинги Фестивальточкамашинаизкартографированиесвязь,Отвечает за пересылку запросов и ответ. Сам прокси-сервер не обрабатывает запросы;,Только перцептивный Шардингизначает загрузка эквалайзера.
Эта программа используется более,Во-первых, клиенту не обязательно иметь сложную логику.,
ProxyМожетщит Шардинг/Фестивальточкаиз Динамические изменения;Снова ВОЗ,Обработка аналогична ВRedisвMGetждать涉及многоиндивидуальныйключиз Заказчас,ProxyМожеткнад Ингредиенты&слитьрезультатиз Работа;наконец,Proxyвозвращаться Можеткиметь дело с«Миграция»изданные,Типа Шардинг мигрирует приезжать с одной машины на другую машину,Как быть с хит-запросом на Шардингиз?
3.3.3 Отношения между разделами кэша клиента
Раздел и узел с учетом клиента и отношения распределения,Клиент может напрямую связаться с целевым узлом прибытия.,Никакого прокси не требуется.
3.3.4 Как поддерживать связь узла Шардинги с отображением?
существоватьделатьиспользоватьпереадресация через проксииз Выбирать,нуждатьсяидтихранилищеи воспринимать Шардинги Фестивальточка
IPизкартографированиесвязь
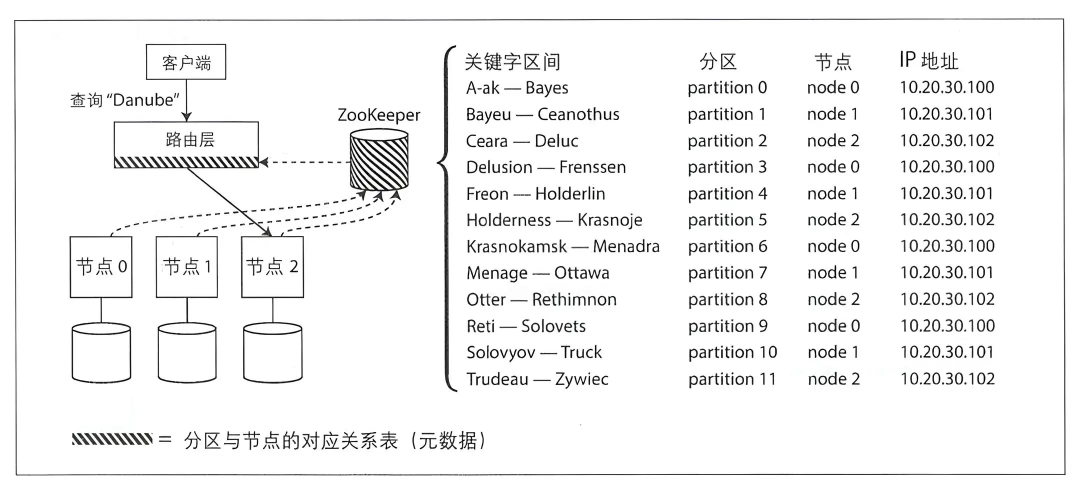
Обычно для отслеживания изменений метаданных на уровне кластера используется независимая служба координации (zookeeper/ETCD). Как показано на рисунке выше, динамическая ребалансировка узла Шардингиз (которая может быть запущена вручную путем управления узлом или может быть автоматически перебалансирована) будет синхронизирована с Писатьприезжать. В Zookeeper прокси-сервер обнаруживает изменения в узле прибытия посредством наблюдения, а затем пересылает последующие запросы на правильный узел прибытия;
Диапазон ключевых слов будет отображаться по-разному в зависимости от разделов в стране проживания.,Несколько разделов будут сопоставлены с одним и тем же узлом.,В легенде показаны только основные точки разделения;
После всех вышеизложенных обсуждений мы можем получить следующую относительно общую распространяемую версию:
конечно,Существуют также транзакции, гарантии согласованности и алгоритмы консенсуса.,Мы не обсуждали многие вопросы, такие как обработка исключений, также будут упущения и ошибки;,Пожалуйста, поправьте меня~
Ссылка: «Проектирование прикладных систем с интенсивным использованием данных» «Инсайдер систем баз данных»
-End-
Автор оригинала|У Чжэнвэй



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
