Новый SOTA для семантической сегментации: 80,5 млн единиц + 62,8 кадров в секунду! Хуаке и Мейтуан совместно предложили одноветвевую архитектуру сегментации рассуждений SCTNet, исходный код которой скоро станет открытым!
Современные методы семантической сегментации в реальном времени обычноПримите дополнительные семантические ветви для реализации богатого контекста на расстоянии.。Однако,Дополнительные ветки приводят к ненужным вычислительным затратам и замедляют вывод.。Чтобы устранить эту дилемму,Мы предлагаем SCTNet, одноветвевую CNN с семантической информацией преобразователя для сегментации в реальном времени.。

https://arxiv.org/abs/2312.17071 https://github.com/xzz777/SCTNet
SCTNet сохраняет эффективность облегченной одноветвевой CNN, в то же время,Он также имеет богатое семантическое представление семантических ветвей. Учитывая превосходную способность преобразователя извлекать контекст на расстоянии,SCTNetВоляtransformerкак смысловая ветвь, используемая только для обучения。С помощью предлагаемого трансформаторного блока CNN CFBlock и модуля выравнивания семантической информации SCTNet может собирать богатую семантическую информацию из ветви трансформатора во время обучения.。в процессе рассуждения,Требуется только развертывание одноветвевого CNN. Мы провели обширные эксперименты с Cityscapes, ADE20K и COCO-Stuff-10K.,Результаты показывают,Наш подход выходит на новый современный уровень.
Основные положения этой статьи включают в себя следующие три пункта:
- Мы предлагаем SCTNet, новую одноветвевую сегментацию в реальном времени. Извлекайте богатую семантическую информацию, изучая выравнивание семантической информации от Transformer до CNN.,SCTNet поддерживает высокую скорость вывода легковесной одиночной CNN, в то же время,Высокая точность с трансформатором.
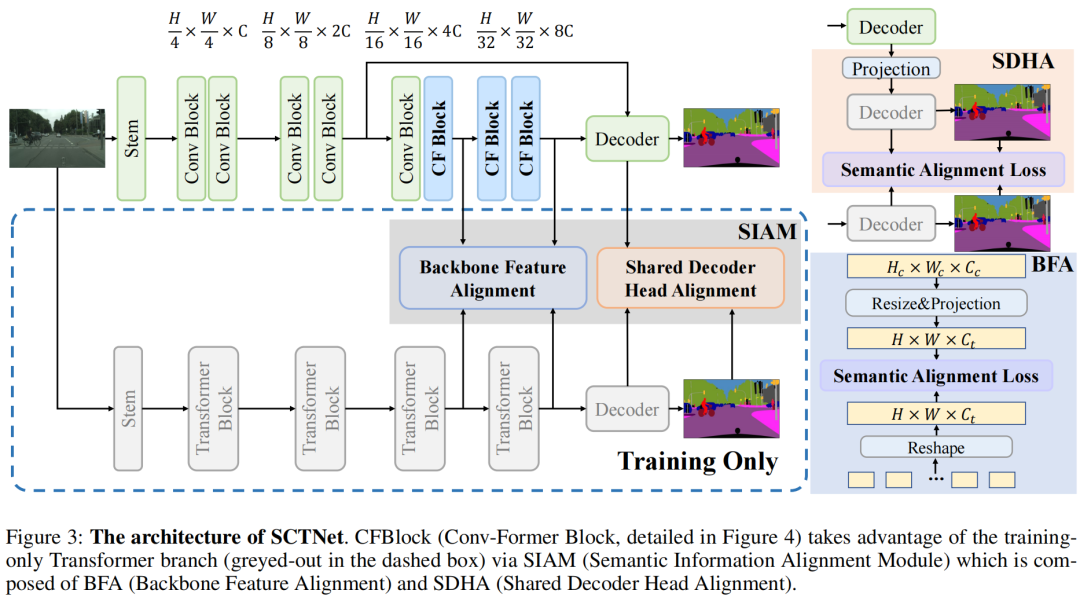
- Чтобы уменьшить семантический разрыв между функциями CNN и функциями Transformer, мы разработали CFBlock (блок ConvFormer), который может захватывать контекст на большом расстоянии, используя только операции свертки. Кроме того, мы предлагаем SIAM (модуль выравнивания семантической информации) для более эффективного согласования функций.
- ВГородские пейзажи、Обширные эксперименты с ADE20K и COCO-Stuff-10K. показывают,Предлагаемая SCTNet превосходит существующие современные методы семантической сегментации в реальном времени.. SCTNet открывает новый взгляд на повышение скорости семантической сегментации в реальном времени и производительности.
План этой статьи
Чтобы снизить вычислительные затраты и получить богатую семантическую информацию, мы разбираем две популярные отраслевые архитектуры на:
- Ветка CNN выполняет логический вывод;
- Ветка Transformer используется для семантического выравнивания на этапе обучения.
Backbone Чтобы повысить скорость вывода, SCTNet использует типичную иерархическую магистраль CNN. Модуль Stem сети SCTNet состоит из двух свертков 3×3; Первые два этапа состоят из сложенных друг на друга остаточных модулей; последние два этапа состоят из предлагаемого CFBlock. CFBlock использует несколько тщательно разработанных операций свертки для выполнения функций удаленного захвата контекста, аналогичных блокам Transformer. Decoder Head Заголовок декодирования состоит из DAPPM и заголовка сегментации. Для дальнейшего обогащения контекстной информации автор добавил DAPPM после Stage4. Затем автор объединяет выходные данные S2 и S4 и передает их в головку сегментации. Training Phase как мы все знаем,Transformer превосходно улавливает глобальный семантический контекст。 с другой стороны,Было показано, что CNN более подходят, чем преобразователи, для моделирования иерархической локальной информации.。 Вдохновленные преимуществами Transformer и CNN, мы исследуем возможность оснащения сети сегментации в реальном времени преимуществами обоих. Мы предлагаем одноветвевую CNN, которая учится согласовывать свои функции с функциями мощного Трансформатора.。 Такое выравнивание функций позволяет одноветвевой CNN извлекать богатый глобальный контекст и подробную пространственную информацию. Конкретно,SCTNet использует преобразователь, который действует только на этапе обучения в качестве семантической ветви для извлечения мощного глобального семантического контекста. Модуль выравнивания семантической информации контролирует ветвь свертки для выравнивания высококачественного глобального контекста из преобразователя.。 Inference Phase Чтобы избежать огромных вычислительных затрат обеих ветвей,На этапе вывода развертывается только ветвь CNN.。 Используя семантическую информацию, ориентированную на преобразователь, одноветвевая CNN может генерировать точные результаты сегментации без необходимости использования дополнительной семантики или дорогостоящего плотного слияния. Более конкретно,Входное изображение подается в одноветвевую иерархическую сверточную магистраль. Головка декодера улавливает особенности магистрали и выполняет простое сращивание для классификации пикселей..
Эксперимент в этой статье
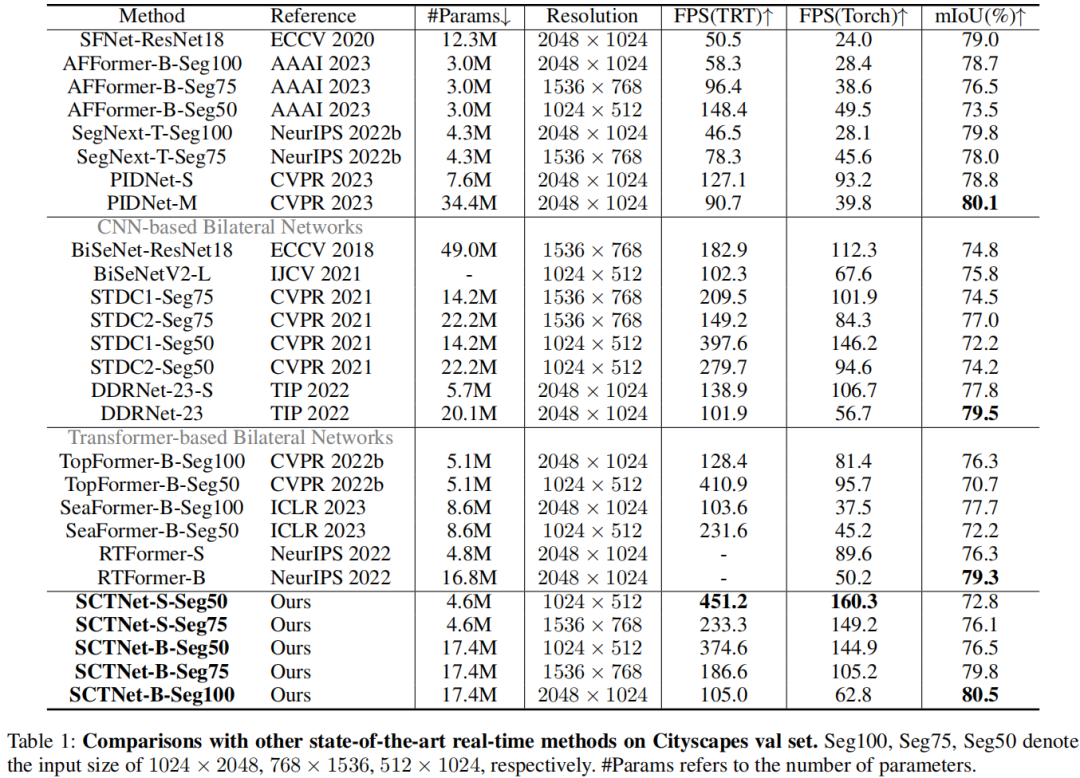
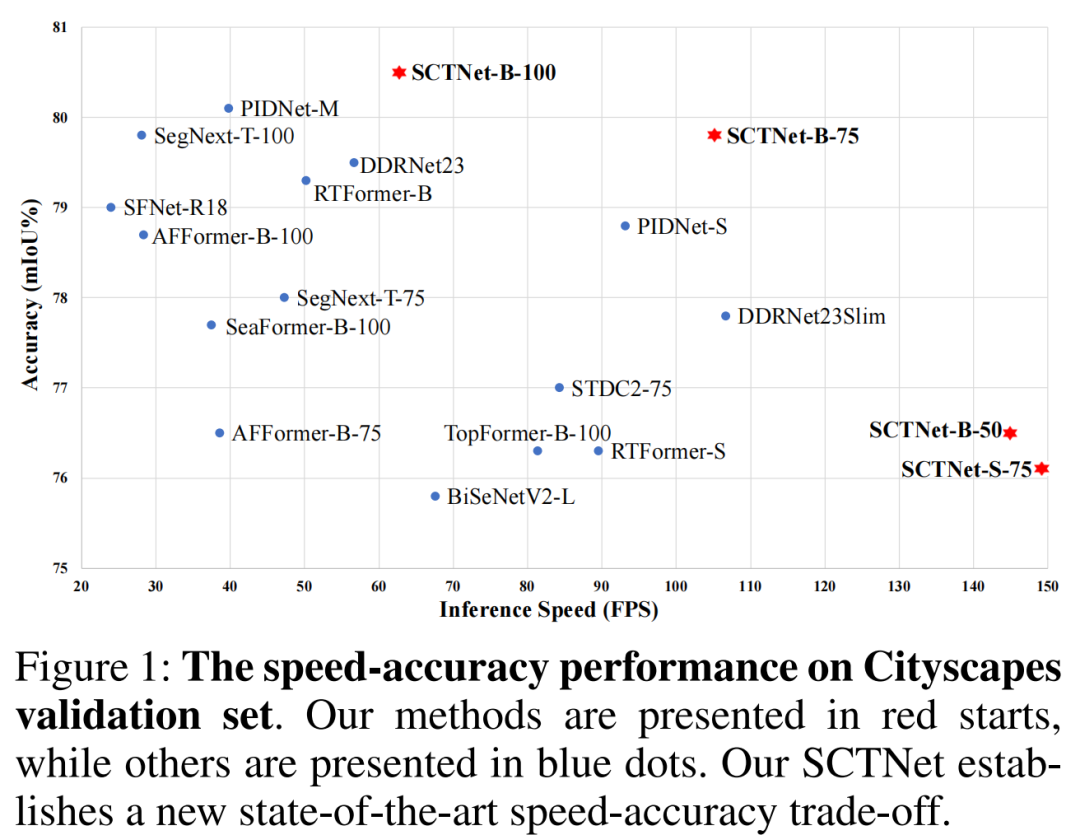
На приведенном выше рисунке и в таблице показано сравнение производительности различных решений по семантической сегментации Cityscapes. Как видно из них:
- Предлагаемая SCTNet значительно превосходит другие схемы сегментации в реальном времени и обеспечивает наилучший баланс скорости и точности;
- Предлагаемый SCTNet-B-Seg100 достиг 80,5% mIoU и скорости 62,8 кадров в секунду.,достигатьСегментация новых SOTA в реальном времени;
- Предлагаемый SCTNet-B-Seg75 достиг 79,8% mIoU, что является более точным, чем RTFormer-B и DDRnet-23, и в два раза быстрее;
- при всех входных разрешениях,Кроме того, предлагаемая SCTNet-B имеет лучшие показатели, чем другие решения;,SCTNet-S также достиг лучшего баланса производительности, чем STDC2, RTFormer-S, SeaFormer-B и TopFormer-B.
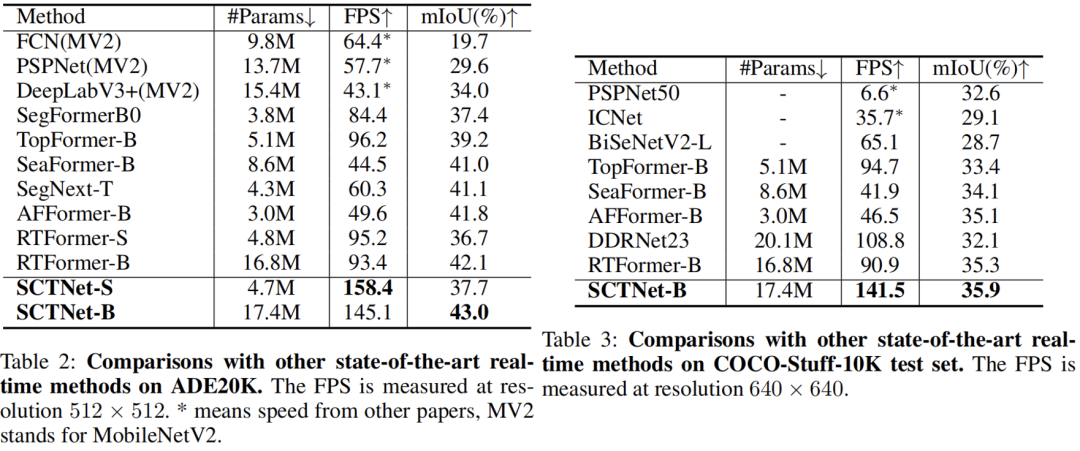
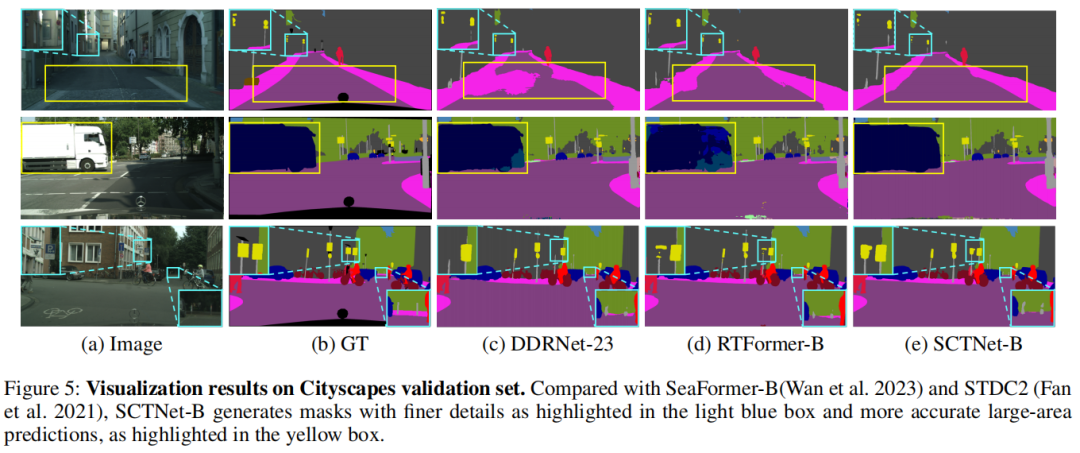
В таблице выше показано сравнение различных схем сегментации наборов данных ADE20K и COCO-Stuff-10K.,Это очевидно:Предлагаемая сеть SCTNet также обеспечивает лучший баланс скорости и точности.。

[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API

Весенние аннотации: подробное объяснение @Service!
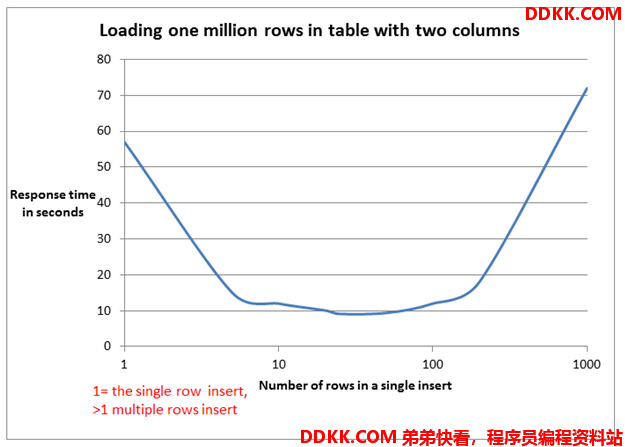
Пожалуйста, не используйте foreach для пакетной вставки в MyBatis. Для 5000 фрагментов данных потребовалось 14 минут. .

Как создать проект Node.js с помощью npm?
Mybatis-plus использует typeHandler для преобразования объединенных строк String в списки списков.

Не удалось установить программное обеспечение Mitsubishi. Возможно, возникла проблема с реестром.

Разрешение ошибок проекта SpringBoot 3 mybatis-plus: org.apache.ibatis.binding.BindingException: неверный оператор привязки
Более краткая проверка параметров. Для проверки параметров используйте SpringBoot Validation.

Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!
