Новый прорыв в модели векторизации текста: acge_text_embedding занимает первое место в C-MTEB
На волне искусственного интеллекта модели больших языков (LLM), такие как GPT4, Claude3 и Llama 3, несомненно, являются наиболее привлекательными тенденциями. Благодаря предварительному обучению на огромных объемах данных эти модели усвоили богатые языковые знания и шаблоны, продемонстрировав удивительные возможности. С точки зрения поддержки применения этих крупномасштабных языковых моделей важность модели векторизации текста (модель внедрения) очевидна.
Недавно,Я просматривал Huggingface и обнаружил это,Отечественная модель векторизации текста собственной разработки.acge_text_embedding(В дальнейшем именуемый“acgeМодель”)Авторитетный китайский эталон оценки семантических векторов в отрасли.C-MTEB(Chinese Massive Text Embedding Бенчмарк) занял первое место. Сегодняшняя статья будет посвящена следующим вопросам, которые помогут вам интерпретировать и применять модель acge_text_embedding:
• Что такое acge-модель векторизации текста? Каков принцип? • Каких эффектов может достичь модель acge и каких достижений она достигла? • Какова связь между прорывом в модели векторизации текста и созданием RAG для расширенного поиска?
1. Новый прорыв в модели векторизации текста — модель acge.
1.1. Модель векторизации текста.
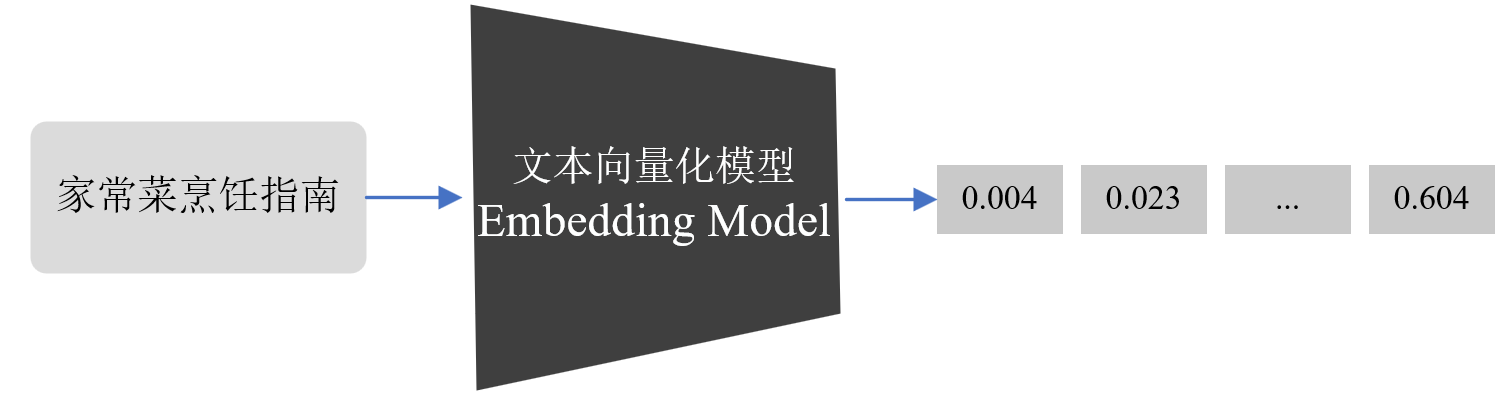
Модель векторизации текста является основной технологией обработки естественного языка (NLP). Она может преобразовывать дискретные данные большой размерности, такие как слова, предложения или элементы изображения, в непрерывные вектора низкой размерности, тем самым преобразуя текстовые данные в формат, который можно обрабатывать. с помощью компьютеров. Как показано на рисунке ниже, модель векторизации текста может представлять текстовую информацию в векторы, которые могут выражать семантику текста путем преобразования «Руководства по домашнему приготовлению пищи» в числовые векторы.
Когда текстовая информация преобразуется в векторную форму, выходные результаты могут дополнительно обеспечить надежную поддержку для множества последующих задач, таких как:
- поиск:Векторизация делаетпоиск Механизм может ранжироваться на основе векторного сходства между строками запроса и документами.поискрезультат,Лучшие результаты обычно наиболее релевантны строке запроса.
- кластеризация:в текстекластеризация По заданию,Векторизацию можно использовать для измерения сходства между текстами.,Тем самым группируя текст по разным категориям или кластерам.
- рекомендовать:Векторизация помогает создавать представления пользователей и элементов.,Позволяет системе передачи основываться на историческом поведении или предпочтениях пользователя.,Вычислить сходство между вектором пользователя и вектором элемента,Тем самым предоставляя пользователям соответствующие элементы.
- Обнаружение аномалий:существовать Обнаружение аномалий По заданию,Векторизацию можно использовать для отображения текстовых данных в векторное пространство.,И выявляйте выбросы, которые отличаются от нормального поведения, измеряя расстояние или сходство между текстовыми векторами и нормальными данными.
- измерение разнообразия:через векторизацию,Может анализировать распределение текстовых данных в векторном пространстве.,Тем самым оценивается разнообразие текстовых данных.
- Классификация:Векторизация преобразует текстовые данные в числовые векторные представления.,Это позволяет алгоритму классификации классифицировать на основе сходства между текстовыми векторами и различными категориями классифицировать на наиболее похожие теги или категории. Модель acge — это современные модели векторизации текста.
1.2. Краткое описание модели acge.
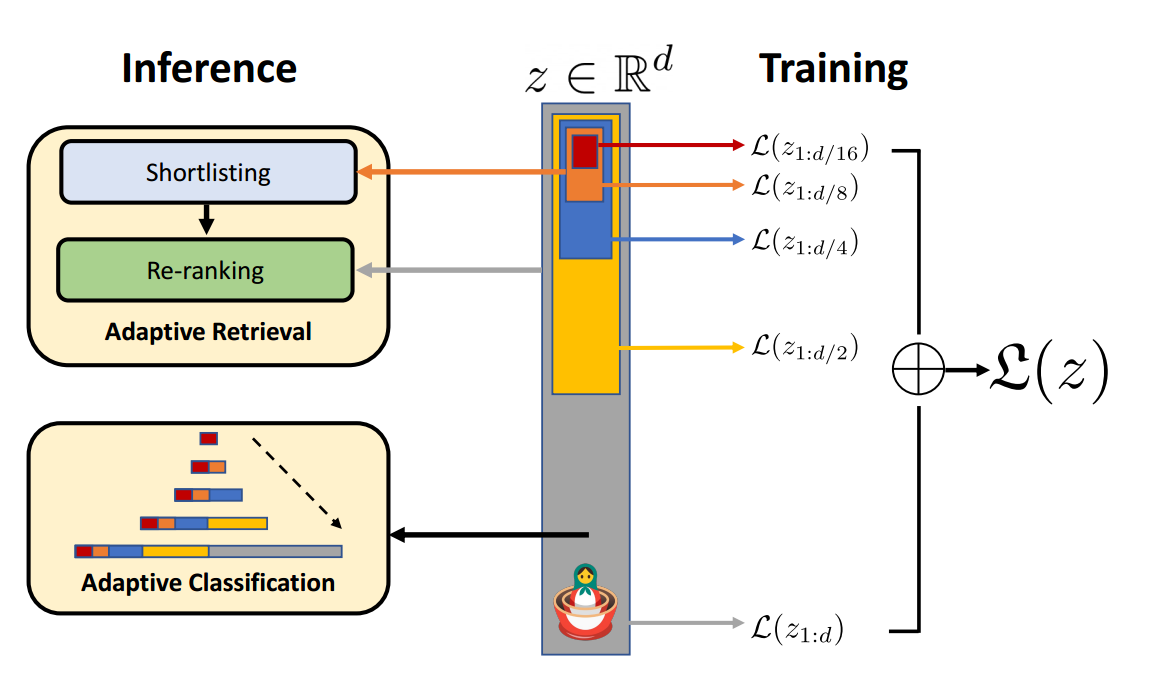
на основной раме,acge_text_embeddingМодель主要использовать了俄罗斯套娃表征学习(Matryoshka Representation Learning,(далее MRL) представляет собой гибкую структуру обучения представлению.

Подобно структуре русской матрешки, вектор внедрения, созданный MRL, также является вложенной структурой, целью которой является создание вложенного вектора представления с многоуровневой структурой, где каждый меньший вектор является частью большего вектора и может быть независимо использован для различных целей. задачи. Во время обучения MRL вычисляет множественные потери на основе векторов заданных размерностей [64,128,...,2048,3072]. Это позволяет пользователям вводить параметры измерений в соответствии с их фактическими потребностями во время вывода для получения векторов указанных размеров.
Задачу оптимизации MRL можно выразить так:
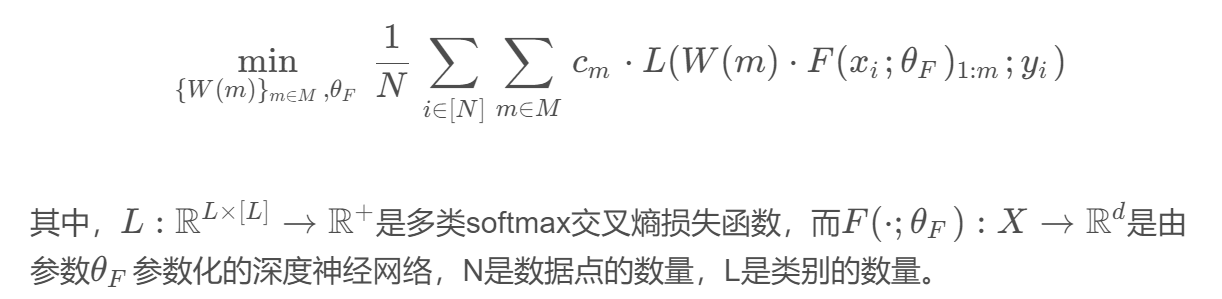
Основная идея этого метода заключается вИнформация обучения с разной степенью детализации позволяет вектору внедрения адаптироваться к потребностям различных вычислительных ресурсов, сохраняя при этом точность и полноту, и может легко вписываться в большинство структур обучения представлению.,и может быть расширен для решения различных стандартных задач компьютерного зрения и обработки естественного языка.
использоватьТехнология MRL,Провести обучение,Получение представлений в разных измерениях,Модель acge реализует иерархическое представление от грубого до точного.,Это обеспечивает гибкое представление, не требующее дополнительных затрат во время вывода и развертывания. кроме того,В конкретной практике,Целевое обучение для разных задач,acgeМодель使用стратегическое обучениеметод обучения,Значительно улучшен поиск、кластеризация、Производительность при выполнении таких задач, как сортировка;представлятьНепрерывное обучениеметод обучения,Преодолеть проблему катастрофического забывания в нейронных сетях,Это позволяет итерациям обучения модели достигать относительно превосходного пространства сходимости.
2. Оценка эффекта модели acge
2.1. Воспроизведение результатов модели ACGE.
Далее мы воспроизводим результаты модели acge. Модель acge предоставляет предварительно обученные модели для пробного использования и воспроизведения производительности. Сначала установите зависимость предложение_трансформеры:
!pip install --upgrade sentence_transformersПосле завершения установки мы можем установить исходный текст source_text на «Руководство по домашнему приготовлению», а целевой текст target_text, сходство которого мы хотим вычислить, с [«Рецепт яичницы с помидорами», «Рецепт фермерской жареная свинина», «Шанхай Бэньбан «Традиционные способы приготовления блюд», «Руководство по эксплуатации автомобиля – осмотр, ремонт, разборка и обслуживание»] для испытаний:
from sentence_transformers import SentenceTransformer
# Если у вас нет доступа к HuggingFace, вы можете сначала загрузить модель в автономном режиме на свой локальный компьютер.
model = SentenceTransformer('acge_text_embedding')
source_text = ["Руководство по домашней кулинарии"]
target_text = ["Как приготовить яичницу с помидорами", «Рецепт фермерской жареной свинины», «Традиционные технологии приготовления местных блюд в Шанхае», «Руководство по ремонту автомобилей – Осмотр, ремонт, разборка и обслуживание»]
embs1 = model.encode(source_text, normalize_embeddings=True)
embs2 = model.encode(target_text, normalize_embeddings=True)
similarity = embs1 @ embs2.T
print(similarity)Вы также можете попробовать это через API, указанный на Huggingface:
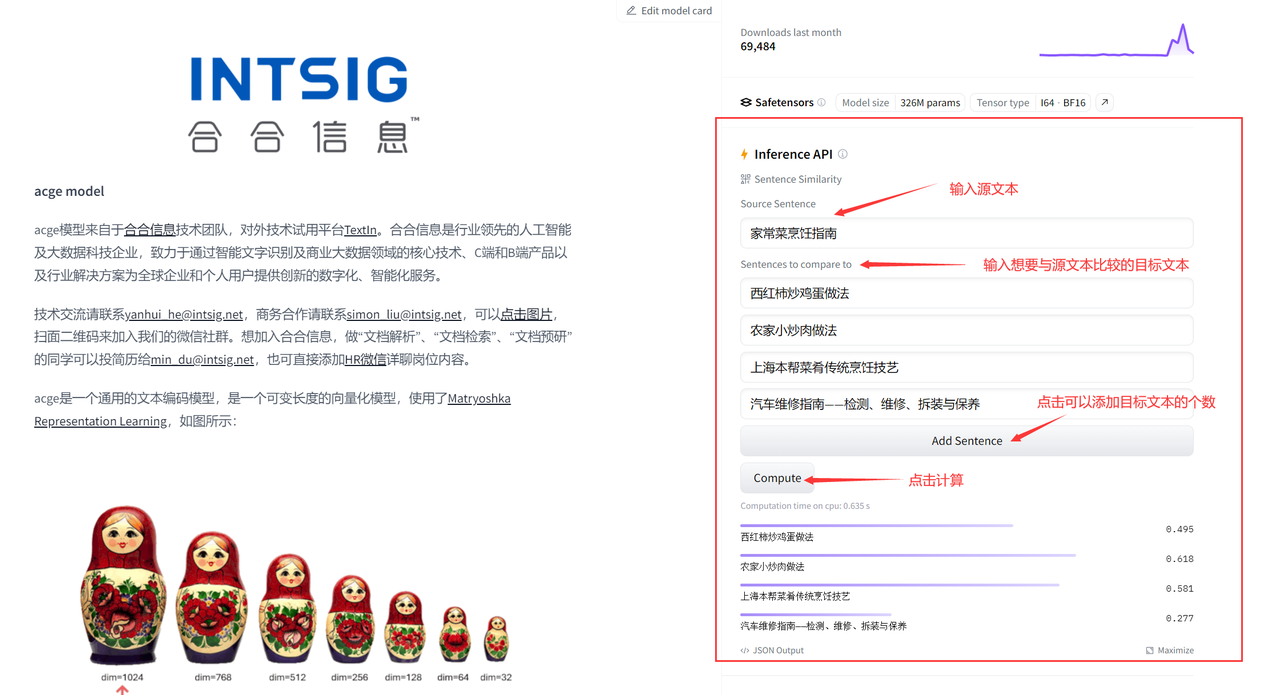
Окончательные результаты расчета следующие:
Как приготовить яичницу с помидорами: 0,495 Как приготовить жареную свинину в фермерском доме: 0,618 Традиционные приемы приготовления местных шанхайских блюд: 0,581 Руководство по обслуживанию автомобиля - осмотр, ремонт, разборка и обслуживание: 0,277
Среди них числовое значение представляет собой семантическую корреляцию между исходным текстом и целевым текстом. Чем ближе значение сходства к 1, тем сильнее семантическая корреляция между текстами. В этом примере мы видим, что тексты в разных полях. связаны друг с другом. Результаты оценки сходства исходного текста «Руководство по приготовлению домашних блюд».
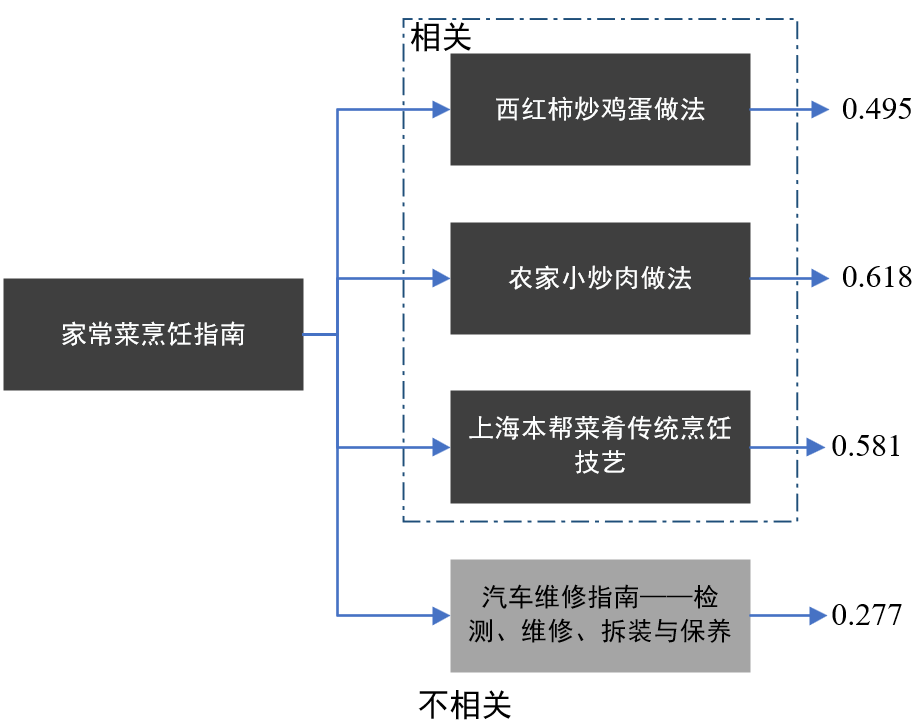
Для текстов кулинарной тематики (таких как «Как приготовить яичницу с помидорами», «Как приготовить жареную свинину по-фермерски», «Традиционные приемы приготовления местных блюд в Шанхае») модель векторизации текста показывает высокое значение сходства, который показывает, что эффективность модели в определении семантической связи между текстами в кулинарной сфере. Эта модель может обеспечить точную оценку сходства текстов со схожей тематикой или семантикой, что имеет большое значение для таких задач, как классификация текстов и системы рекомендаций. Однако для текста, связанного с ремонтом автомобилей, значение сходства ниже, поскольку текст менее семантически связан с исходным текстом. Это подчеркивает еще одно преимущество модели, заключающееся в ее способности улавливать семантические особенности в разных областях на основе текстового контента, тем самым эффективно различая тексты.
Это показывает, что модель acge может эффективно извлекать семантические характеристики из текста и преобразовывать их в векторные представления, а также точно измерять семантическую корреляцию между текстами.
2.2. Повторение оценки C-MTEB.
C-MTEB — это эталон для комплексной оценки универсальности китайских моделей векторизации. Он собирает 35 общедоступных наборов данных, охватывающих шесть основных категорий задач. Он собирает 35 общедоступных китайских наборов данных, охватывающих классификацию, кластеризацию, поиск, сортировку, сходство текста и STS. и другие типы задач, обеспечивая унифицированные стандарты оценки и мощную поддержку исследования китайских моделей векторизации.
Следующее воспроизводит эффект модели acge на C-MTEB. Сначала используйте pip для установки зависимости C_MTEB:
pip install -U C_MTEBЗатем введите следующий код для оценки acge_text_embedding:
import torch
import argparse
import functools
from C_MTEB.tasks import *
from typing import List, Dict
from sentence_transformers import SentenceTransformer
from mteb import MTEB, DRESModel
class RetrievalModel(DRESModel):
def __init__(self, encoder, **kwargs):
self.encoder = encoder
def encode_queries(self, queries: List[str], **kwargs) -> np.ndarray:
input_texts = ['{}'.format(q) for q in queries]
return self._do_encode(input_texts)
def encode_corpus(self, corpus: List[Dict[str, str]], **kwargs) -> np.ndarray:
input_texts = ['{} {}'.format(doc.get('title', ''), doc['text']).strip() for doc in corpus]
input_texts = ['{}'.format(t) for t in input_texts]
return self._do_encode(input_texts)
@torch.no_grad()
def _do_encode(self, input_texts: List[str]) -> np.ndarray:
return self.encoder.encode(
sentences=input_texts,
batch_size=512,
normalize_embeddings=True,
convert_to_numpy=True
)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--model_name_or_path', default="acge_text_embedding", type=str)
parser.add_argument('--task_type', default=None, type=str)
parser.add_argument('--pooling_method', default='cls', type=str)
parser.add_argument('--output_dir', default='zh_results',
type=str, help='output directory')
parser.add_argument('--max_len', default=1024, type=int, help='max length')
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
encoder = SentenceTransformer(args.model_name_or_path).half()
encoder.encode = functools.partial(encoder.encode, normalize_embeddings=True)
encoder.max_seq_length = int(args.max_len)
task_names = [t.description["name"] for t in MTEB(task_types=args.task_type,
task_langs=['zh', 'zh-CN']).tasks]
TASKS_WITH_PROMPTS = ["T2Retrieval", "MMarcoRetrieval", "DuRetrieval", "CovidRetrieval", "CmedqaRetrieval",
"EcomRetrieval", "MedicalRetrieval", "VideoRetrieval"]
for task in task_names:
evaluation = MTEB(tasks=[task], task_langs=['zh', 'zh-CN'])
if task in TASKS_WITH_PROMPTS:
evaluation.run(RetrievalModel(encoder), output_folder=args.output_dir, overwrite_results=False)
else:
evaluation.run(encoder, output_folder=args.output_dir, overwrite_results=False)Как вы можете видеть на https://huggingface.co/spaces/mteb/leaderboard, модель acge уже находится в списке C-MTEB (Chinese Massive Text Embedding Benchmark), наиболее полного и авторитетного китайского теста оценки семантических векторов в мире. отрасли занял первое место по результату.
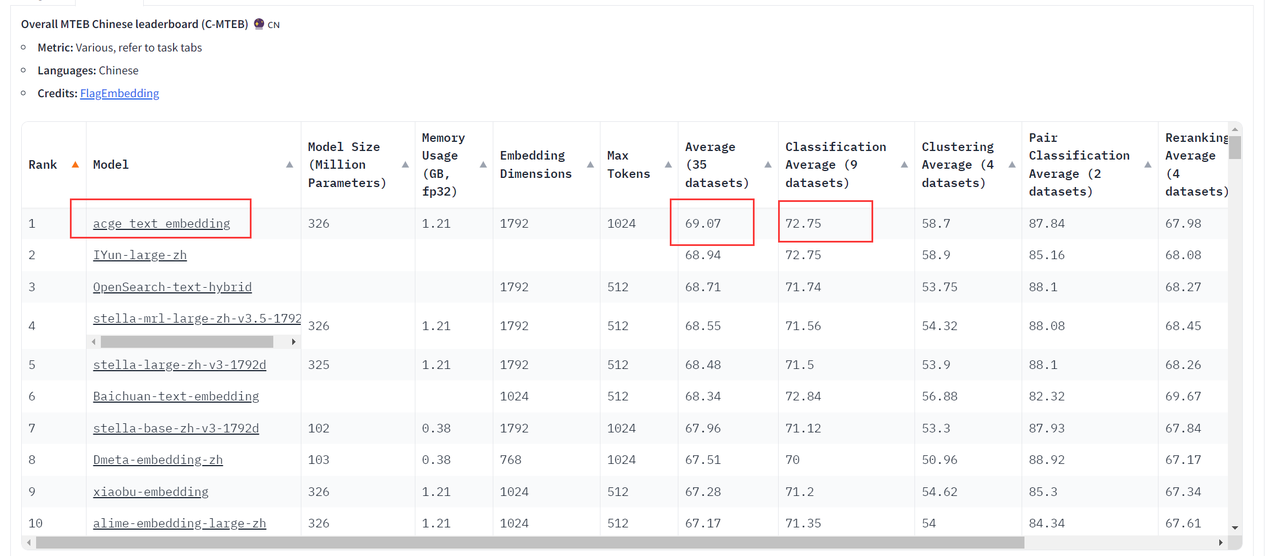
Как видно из приведенной выше таблицы, модель acge_text_embedding находится в разделе «Классификация». Average (9 datasets)”в этой колонке,acge_text_embedding получил оценку 72,75.,показыватьОтличная производительность при выполнении текстовых задач по классификации.,Получен наивысший балл 69,07 в столбце «Среднее (35 наборов данных)».,показыватьВ целом отличная производительность на нескольких наборах данных,Кроме того, относительно скромный размер модели и объем памяти,Хороший баланс между размером модели и эффективностью вычислений.。
По сравнению с внедрением текста в Байчуань, он превосходит производительность и обладает большей гибкостью при решении разнообразных задач. По сравнению с OpenSearch-text-гибридом Alibaba Cloud, acge_text_embedding более универсален и может применяться для различных задач обработки текста.
Кроме того, по словам членов команды разработчиков Hehe Information, по сравнению с традиционными моделями вертикальной предметной области с предварительным обучением или точной настройкой, модель acge поддерживает построение моделей общей классификации в различных сценариях, повышает точность извлечения информации из длинных документов, и имеет относительно низкую стоимость применения. Он может помочь крупным моделям быстро создать ценность в различных отраслях и обеспечить надежную техническую поддержку для повышения производительности.
3. Прорыв в моделях векторизации текста и улучшение поиска для создания RAG.
На сегодняшний день крупномасштабные языковые модели, такие как GPT4, Claude3 и Llama 3, все лучше справляются с различными задачами. Однако в применении все еще существуют определенные ограничения:
- ограничения знаний:现有的主流大Модель的训练集基本都是构建于网络公开的数据,Но когда вы спрашиваете подробности о недавнем событии или глубокие знания в конкретной области,,Пока модель будет стремиться сгенерировать ответ,Но поскольку он не имел прямого контакта с соответствующей информацией об этом инциденте,,Детали неточны.
- проблема с галлюцинациями:всеAIМодель的底层原理都是基于数学概率,Выходные данные модели по существу представляют собой серию числовых операций.,Большие модели – не исключение.,Так что иногда говорит ерунду серьезно,Этот видпроблема с галлюцинациями Очень легко привести к неправильному восприятию информации.
- Безопасность данных:Для бизнеса,Безопасность данных имеет решающее значение,Ни один бизнес не хочет рисковать утечкой данных,Загрузите данные своего частного домена на стороннюю платформу для обучения.
Чтобы справиться с такими сценариями приложений, возникла модель генерации с расширенным поиском RAG. Основная идея модели RAG заключается во внедрении механизма поиска на этапе генерации для извлечения соответствующей информации из заранее определенной базы знаний и ее объединения. сгенерированный текст. Этот метод может восполнить недостаток LLM в конкретных областях или новейших знаний, тем самым повышая точность и релевантность создаваемого текста. Его основной процесс заключается в следующем:

В процессе RAG модель векторизации отвечает за кодирование информации в коллекции документов в векторное представление и помогает извлекать наиболее релевантные фрагменты документа при запросе пользователя. Содержимое этих фрагментов документа включается во вводимые пользователем данные и руководства. большой язык Модель генерирует ответы на основе этих фрагментов документов.
Пользователи могут спросить что-то вроде“Нужно ли добавлять сахар в яичницу с помидорами? Насколько это уместно?”Такой вопрос。существовать Этот вид情况下,Модель векторизации может переводить ключевые характеристики, такие как различные ингредиенты, методы приготовления и вкусовые предпочтения, на «язык», понятный машине, а затем фиксировать и понимать взаимосвязь между ними.,Например, в каких рецептах они часто появляются вместе?,Каковы вкусовые особенности этих рецептов? так,Выстраивая связи между основными понятиями в смежных областях, RAG может легко извлекать соответствующую информацию из массивных данных о кулинарии, тем самым имея больше шансов получить наиболее релевантные фрагменты документов, соответствующие запросам пользователей.。Окончательный сгенерированный ответ более точен.、власть,И это может лучше удовлетворить потребности пользователей.
Модель acge — это именно такая векторизованная модель.,Он обладает хорошей способностью к пониманию текста и способностью к обучению представлению.,можетПреобразуйте семантическую информацию документов в высококачественные векторные представления.,Эффективно фиксируйте семантическую и содержательную информацию документов.,Это помогает модели точно извлечь фрагменты документов, соответствующие запросу.
Ожидается, что с улучшением модели acge в задачах векторизации текста проблемы галлюцинаций и своевременности будут решены, а удобство использования больших моделей также будет эффективно улучшено, тем самым лучше обслуживая такие отрасли, как финансы, консалтинг и образование. Обеспечьте поддержку интеллектуального обслуживания клиентов, вопросов и ответов, контроля рисков соответствия, маркетингового консультирования и других сценариев в других отраслях.
десятилетия назад,Вопрос о временах, поднятый Тьюрингом“Can machines think?”Превращение искусственного интеллекта из научной фантастики в реальность,Это заложило основу для последующего развития искусственного интеллекта. после,Бесчисленные пионеры информатики начали деконструировать формирование человеческого интеллекта,Надеюсь найти признаки машинного интеллекта. по сей день,Мы снова стоим в новой отправной точке,Машины могут не только «думать»,Больше возможностей для изучения новых знаний и частной базы знаний,Ведите с нами естественный и непринужденный разговор.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
