Новейшая и самая мощная оценка технических индикаторов большой модели DeepSeek v2.
Недавно компания DeepSeek из Ханчжоу выпустила модель MoE второго поколения DeepSeek-V2. Судя по различным показателям, она находится на лидирующем уровне, по сравнению с моделями с открытым исходным кодом или моделями с закрытым исходным кодом, она находится в первом эшелоне. сильный конкурент передовых крупных моделей, таких как GPT-4, Wenxin 4.0, Qwen1.5 72B, LLaMA3 70B и так далее. Эта статья познакомит вас с этим.
Размер параметра и производительность
DeepSeek-V2 содержит 236B (миллиардов) параметров, каждый токен активирует 2,1B параметров и поддерживает длину контекста до 128K. С точки зрения производительности, он находится в одном эшелоне с моделями с закрытым исходным кодом, такими как GPT-4-Turbo и Wenxin 4.0, в китайской комплексной оценке возможностей, а его комплексные возможности на английском языке находятся в том же эшелоне с моделью с открытым исходным кодом LLaMA3-70B. .
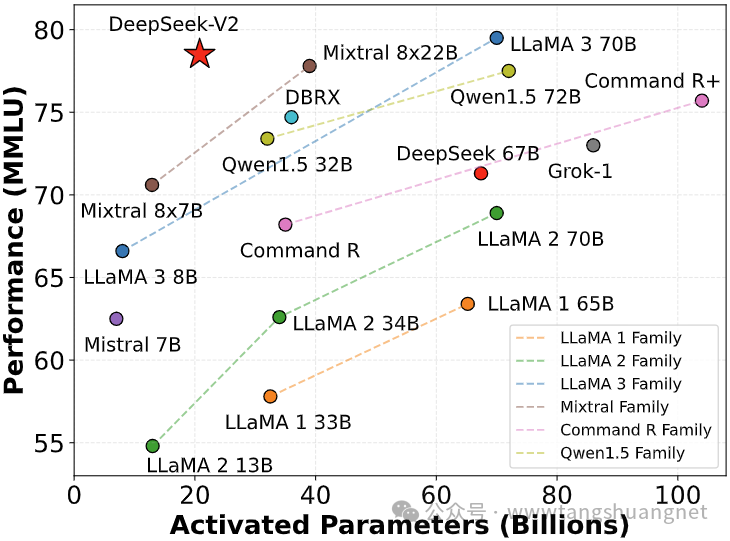
длина контекста
Открытый исходный Код Модель поддерживает длину до 128К. контекста, а чат и API поддерживают длину 32 КБ. контекста, помогает решать сложные задачи, требующие большого количества контекстной информации.
знание китайского языка
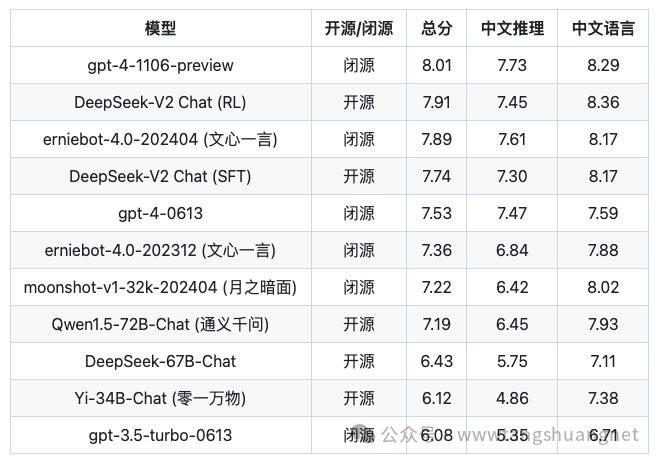
Китайская комплексная способность (AlignBench) является самой сильной среди моделей с открытым исходным кодом и находится в том же эшелоне оценки, что и модели с закрытым исходным кодом, такие как GPT-4-Turbo и Wenxin 4.0.
Возможность программирования
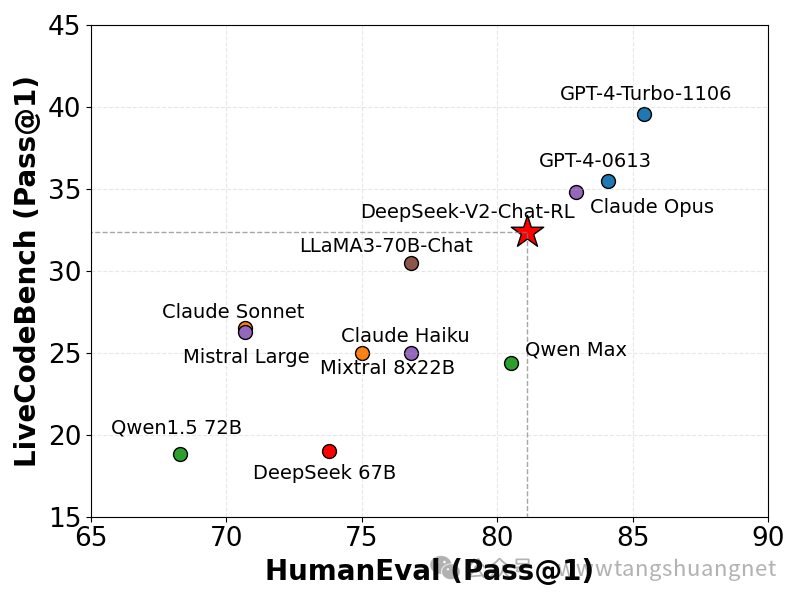
Хорошо справляется с программированием задач и логическим рассуждением.,Подходит для технических областей и сценариев применения, требующих принятия сложных решений. Официально поставить кодера на видное место,Видно, что команда уверена в своей команде.
цена API
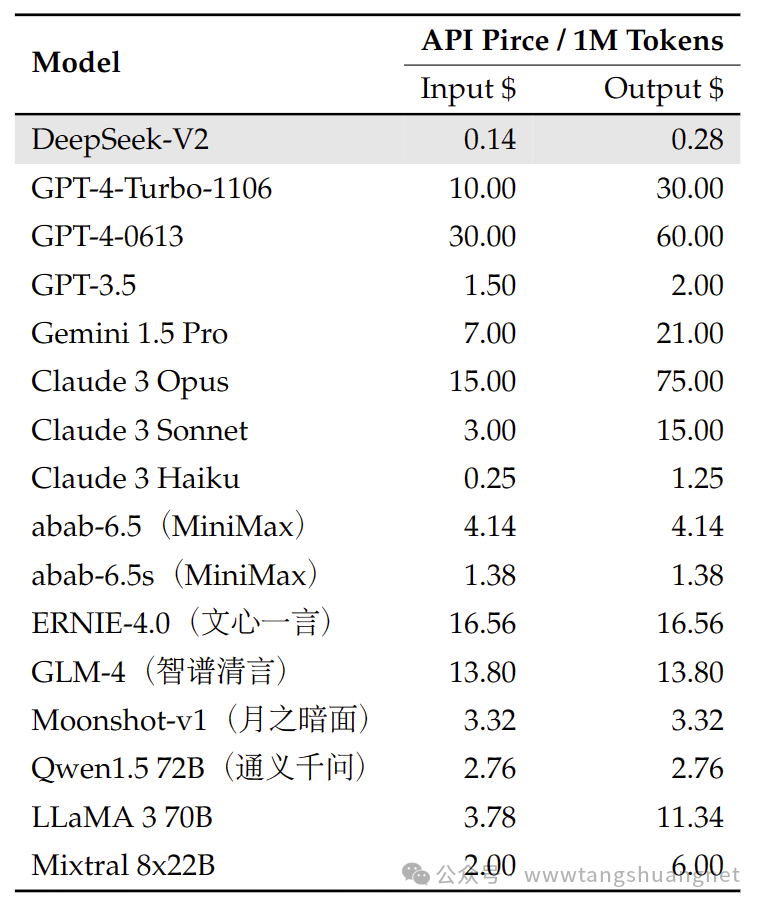
Цена API DeepSeek-V2 составляет 1 юань (0,14 доллара США) за миллион входных токенов и 2 юаня (0,28 доллара США) за миллион выходных токенов, что является конкурентоспособной ценой.

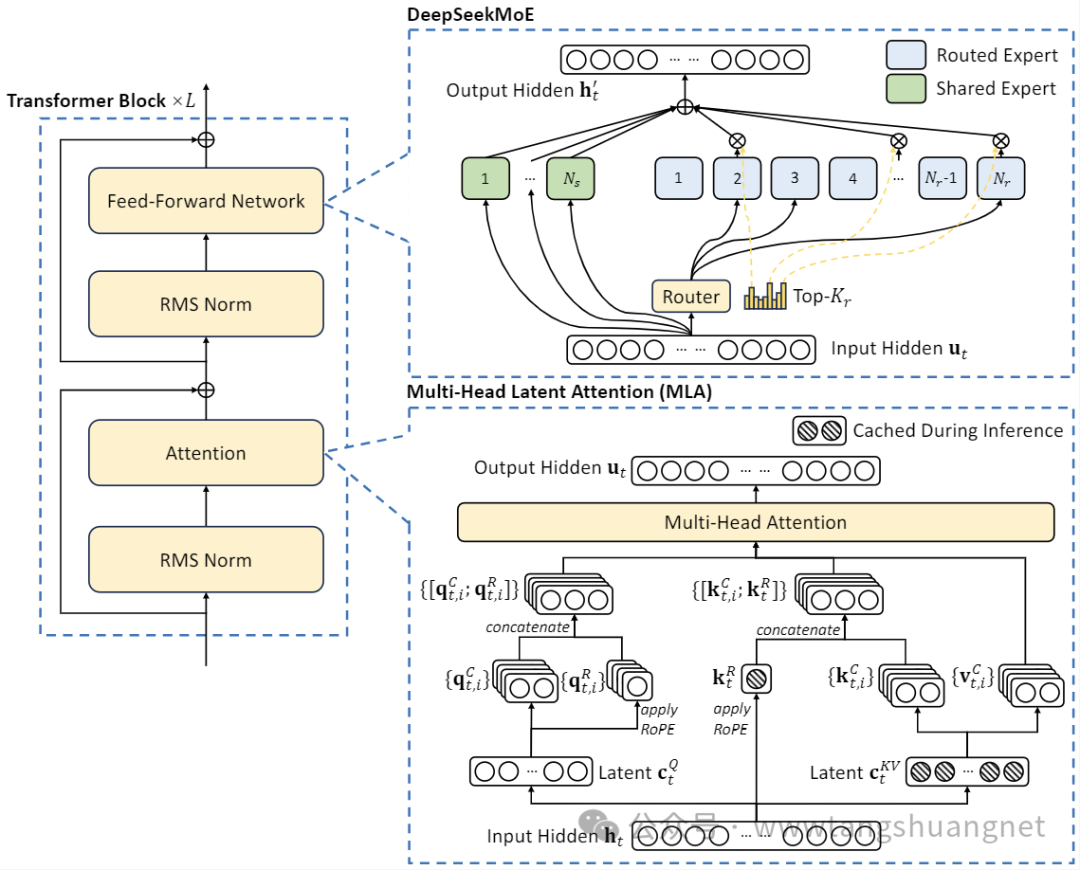
Модельная архитектура
DeepSeek-V2 использует архитектуру MoE. В частности, он внедряет инновационный механизм самообслуживания в архитектуре Transformer, предлагает структуру MLA (Multi-head Latent Attention) и использует технологию MoE для дальнейшего сокращения объема вычислений и повышения эффективности рассуждений. .
коммерческий
Протокол «Открытый исходный код» — MIT, и отмечается, что серия V2 поддерживает коммерческий.
Заключение
Чрезвычайно конкурентоспособная цена и, казалось бы, хорошая производительность данных заинтересовали меня этой компанией. Познакомившись с ней, я узнал, что эта компания является независимой компанией Magic Square, которая сама занимается количественной оценкой ИИ. Как инвестор, я обнаружил, что ИИ. имеет большой потенциал, создала независимый бизнес, создала новый бренд для расширения модели и изучила различные возможности. Я думаю, что среди нынешних основных сервисов больших моделей хорошая модель должна иметь следующие моменты: 1. Открытый исходный код, 2. Низкая цена, 3. Хорошее понимание китайского языка, 4. Архитектурная поддержка больших контекстных окон и лучшая производительность. Если оставить в стороне известные зарубежные модели, то эмоционально я больше поддерживаю превосходные отечественные модели. В области ИИ больше приложений ИИ, которые можно создать в китайском контексте, не только позволят обычным разработчикам использовать их с меньшими затратами. Стоимость перехода на путь ИИ также позволит большему количеству обычных людей насладиться удобством, предоставляемым ИИ.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
