Несколько способов и анализ создания индекса elasticsearch
1. Создайте индекс, используя API создания индекса.
1. Укажите имя индекса для создания индекса.
PUT test_index
Когда elasticsearch возвращает true, это означает, что мы успешно создали индекс с именем test_index в elasticsearch, и при его создании для индекса не были указаны поля.
Затем мы просматриваем детали этого индекса:
GET test_index{
"test_index": {
"aliases": {},
"mappings": {
"dynamic_templates": [
{
"message_full": {
"match": "message_full",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "match_only_text"
}
}
},
{
"message": {
"match": "message",
"mapping": {
"type": "match_only_text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
},
"settings": {
"index": {
"refresh_interval": "10s",
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "200ms",
"trace": "20ms",
"debug": "50ms",
"info": "100ms"
}
},
"source": "1000"
}
},
"translog": {
"sync_interval": "5s",
"durability": "async"
},
"provided_name": "test_index",
"max_result_window": "65536",
"creation_date": "1700017444301",
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"number_of_replicas": "1",
"uuid": "YAIUJ64oTYuQpEjMvQK_Rg",
"version": {
"created": "8080199"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_hot,data_warm,data_cold"
}
}
},
"search": {
"slowlog": {
"threshold": {
"fetch": {
"warn": "200ms",
"trace": "50ms",
"debug": "80ms",
"info": "100ms"
},
"query": {
"warn": "500ms",
"trace": "50ms",
"debug": "100ms",
"info": "200ms"
}
}
}
},
"number_of_shards": "1"
}
}
}
}Мы видим, что в сопоставлениях индексов, за исключением конфигурации сопоставления, поставляемой с динамическим шаблоном, нет других сопоставлений индексов. В то же время параметры индекса шаблона default@template также адаптируются.
Теперь мы вручную вставляем в индекс фрагмент данных.
PUT /test_index/_doc/1?pretty
{
"name":"Чжан Сан",
"age":23,
"remark":"Люблю учиться, люблю читать, люблю жизнь"
}В это время elasticsearch возвращает следующую информацию, сообщающую нам, что часть данных с «_id», равным 1, была успешно создана в индексе test_index. «_version» данных также равна 1. Выполнение было успешным на 2 сегментах. и не удалось на 0 осколках.

Теперь мы повторно выполняемGET test_index,Мы обнаружили, что при отображении индекса,Есть дополнительный раздел свойств.,В свойствах уже есть «имя», «возраст», «от рекомендаций». три поля. В то же время elasticsearch автоматически сопоставляет типы полей с этими тремя полями.
{
"test_index": {
"aliases": {},
"mappings": {
"dynamic_templates": [
{
"message_full": {
"match": "message_full",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "match_only_text"
}
}
},
{
"message": {
"match": "message",
"mapping": {
"type": "match_only_text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
},
"remark": {
"type": "keyword"
}
}
}
}На этом этапе мы можем получить данные, которые мы вставили с помощью запросов. Вы можете видеть, что elasticsearch вернул нам совпадающие данные.
GET test_index/_search
{
"query": {
"term": {
"age": {
"value": "23"
}
}
}
}
Когда мы использовали другой запрос, используя match для запроса текущих данных, мы обнаружили, что elasticsearch не возвращает нам данные.
GET test_index/_search
{
"query": {
"match": {
"remark": "читать"
}
}
}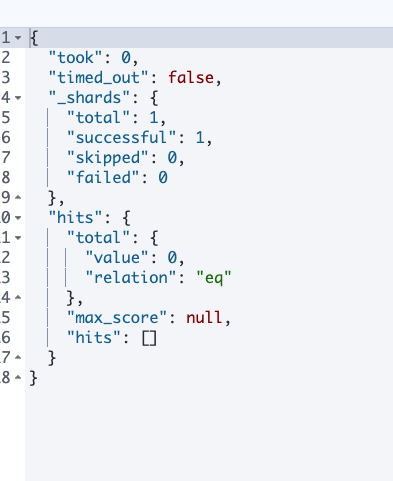
Проверив сопоставление индекса, мы обнаружили, что тип поля примечания, определяемый elasticsearch, — ключевое слово. Из предыдущей статьи мы знаем, что ключевое слово не может быть сегментировано. Поэтому мы не можем найти данные с помощью запроса на совпадение. Так как же нам действовать при создании индекса?
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
},
"remark": {
"type": "keyword"
}
}Когда мы создаем индекс, мы вручную ограничиваем типы полей индекса.
PUT /test_index_new
{
"mappings": {
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"remark": { "type": "text" }
}
}
}После PUT того же фрагмента данных мы выполнили запрос на совпадение по индексу test_index_new и обнаружили, что данные можно найти нормально.
GET test_index_new/_search
{
"query": {
"match": {
"remark": "читать"
}
}
}
Использование создания индекса вручную имеет следующие основные преимущества и недостатки.
преимущество:
- Гибкость: при создании индекса вручную мы можем самостоятельно устанавливать параметры и типы сопоставления индекса. Включая количество сегментов индекса, количество копий, типы полей, анализаторы, используемые для указанных полей, и другие конфигурации параметров. Он может лучше удовлетворить потребности конкретных бизнес-сценариев.
- Настраиваемость: при создании индекса можно выполнить соответствующую оптимизацию параметров на основе характеристик данных и требований запроса. Выбирайте подходящие типы полей, чтобы повысить производительность чтения и записи, а также релевантность сопоставления запросов.
- Управление версиями. Когда бизнесу необходимо сохранить несколько версий данных, мы можем вручную создать несколько индексов версий для управления данными. Это также облегчает последующие операции, такие как миграция или откат различных версий данных.
недостаток:
- Требуется ручное управление индексами: при создании индекса пользователи должны понимать значение и использование связанных с индексом конфигураций и использовать их с соответствующими инструментами. Могут потребоваться дополнительные работы.
- Склонен к ошибкам: создание индексов вручную может привести к человеческой ошибке. Если во время создания индекса возникают ошибки, это может повлиять на производительность индекса и работу системы.
- Требуется обслуживание. Индексы, созданные вручную, требуют обслуживания вручную. Если структура индекса или требования к полям изменяются, вам необходимо вручную настроить параметры индекса и сопоставление.
думать:
В конкретных бизнес-сценариях создание индексов вручную может лучше удовлетворить потребности нашего бизнеса. Когда бизнес растет, необходимо создавать все больше и больше индексов вручную. Есть ли более удобный способ создания индексов?
2. Используйте шаблоны индексов для автоматической адаптации индексов.
Мы можем заранее определить параметры индекса и сопоставление для различных бизнес-индексов, определив шаблоны индексов. Когда индекс будет создан, он будет адаптирован к соответствующему шаблону путем чтения «index_patterns» в шаблоне. Для удовлетворения различных потребностей в индексировании в разных бизнес-сценариях.
В следующем коде мы создаем шаблон с именем test_template. Приоритет шаблона равен 1, что в основном адаптируется к индексу, начинающемуся с «test». В настройках индекса мы устанавливаем количество первичных шардов индекса на 3 и количество реплик на 1. В сопоставлениях индексов мы ограничили типы трех полей: «имя», «возраст» и «примечание». Когда elasticsearch возвращает true, это означает, что создание шаблона завершено.
PUT _template/test_template
{
"order": 1,
"index_patterns": ["test*"],
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"remark": { "type": "text" }
}
}
}
Теперь мы заново создаем индекс с именем test_template_index, ничего не указывая. Давайте посмотрим на отображение индекса.
PUT test_template_indexВ это время мы обнаружили при сопоставлении индекса, что этот индекс автоматически адаптировал параметры индекса, которые мы ранее указали в шаблоне для имени индекса, начинающегося с «теста», при сопоставлении. Это значительно облегчает создание индексов и управление ими.
{
"test_template_index": {
"aliases": {},
"mappings": {
"_source": {
"enabled": false
},
"dynamic_templates": [
{
"message_full": {
"match": "message_full",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "match_only_text"
}
}
},
{
"message": {
"match": "message",
"mapping": {
"type": "match_only_text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"age": {
"type": "integer"
},
"name": {
"type": "text"
},
"remark": {
"type": "text"
}
}
},
"settings": {
"index": {
"refresh_interval": "10s",
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "200ms",
"trace": "20ms",
"debug": "50ms",
"info": "100ms"
}
},
"source": "1000"
}
},
"translog": {
"sync_interval": "5s",
"durability": "async"
},
"provided_name": "test_template_index",
"max_result_window": "65536",
"creation_date": "1700030711762",
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"number_of_replicas": "1",
"uuid": "cTiJp67xThSwpavbV3Hlog",
"version": {
"created": "8080199"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_hot,data_warm,data_cold"
}
}
},
"search": {
"slowlog": {
"threshold": {
"fetch": {
"warn": "200ms",
"trace": "50ms",
"debug": "80ms",
"info": "100ms"
},
"query": {
"warn": "500ms",
"trace": "50ms",
"debug": "100ms",
"info": "200ms"
}
}
}
},
"number_of_shards": "3"
}
}
}
}Использование создания индекса вручную имеет следующие основные преимущества и недостатки.:
преимущество:
- Автоматизация: параметры индекса и сопоставление полей можно заранее определить с помощью шаблонов, а объем ручных операций можно уменьшить за счет адаптации шаблона. Убедитесь, что индексы, созданные в одном и том же бизнес-сценарии, имеют согласованную структуру и конфигурацию параметров.
- Единообразие. Благодаря адаптации шаблона индекса вы можете гарантировать, что индексы, созданные конкретными бизнес-индексами, будут иметь одинаковые настройки и сопоставления. Он может эффективно обеспечить согласованность структуры данных. Особенно важно в кластерах эластичного поиска с большим количеством индексов.
- Упрощенное управление: адаптация шаблона индекса может значительно снизить нашу рабочую нагрузку по созданию и обслуживанию индексов. Нам нужно поддерживать лишь небольшое количество шаблонов индексов. Нет необходимости управлять настройкой каждого индекса индивидуально.
недостаток:
- Ограничения: Шаблон индекса имеет определенные ограничения по гибкости индекса, поскольку метод адаптации шаблона индекса используется для создания индексов с общими характеристиками. Предопределенные методы не могут удовлетворить потребности специальных индексов. Если встречаются специальные индексы, требуются дополнительные модификации.
FAQ
После создания шаблона индекса при создании индекса вы обнаружили, что параметры в шаблоне не адаптированы к созданному индексу?
Причины и идеи по устранению неполадок:
- Проверьте конфигурацию index_patterns в шаблоне и проверьте, правильно ли настроен подстановочный знак. Когда шаблон индекса адаптируется к индексу, он использует index_patterns, чтобы определить, управляется ли индекс текущим шаблоном.
- Отметьте «заказ» в шаблоне. «Заказ» представляет приоритет шаблона. Чем больше значение «заказ», тем выше приоритет шаблона. Когда шаблоны адаптируются к индексу, в первую очередь адаптируются шаблоны с высоким приоритетом.
- Проверьте, имеют ли другие шаблоны индексов, значение «index_patterns» которых настроено как «*», более высокий приоритет, чем шаблон индекса для конкретного бизнеса.
ЯсуществоватьучаствоватьНа третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 года будет проводиться конкурс сочинений. Сформируйте команду и примите участие, чтобы разделить приз!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
