Научите вас шаг за шагом, как создать веб-сайт для создания текста, изображений и видео.
С момента выпуска модели Stable Diffusion в прошлом году «генерация текста и изображений с помощью искусственного интеллекта» действительно стала технологией, которую могут использовать обычные люди.
Однако в последнее время некоторые пользователи сети используют реальные фотографии в Интернете, чтобы постоянно кормить модель для самостоятельного обучения. Результаты его обучения могут быть настолько фальшивыми, что вы даже не узнаете, какие снимки были созданы ИИ или сделаны реальными людьми.

Чтобы принести пользу большинству читателей, эта статья научит вас, как создать собственный реальный веб-сайт с искусственным интеллектом с нуля.
1. Создайте свой собственный веб-сайт с искусственным интеллектом.
Я уже написал статью,Вы можете развернуть веб-сайт для создания воспроизводимых текстовых изображений локально.。Здесь мы также можем использовать его напрямуюGitHubсклад:stable-diffusion-webui
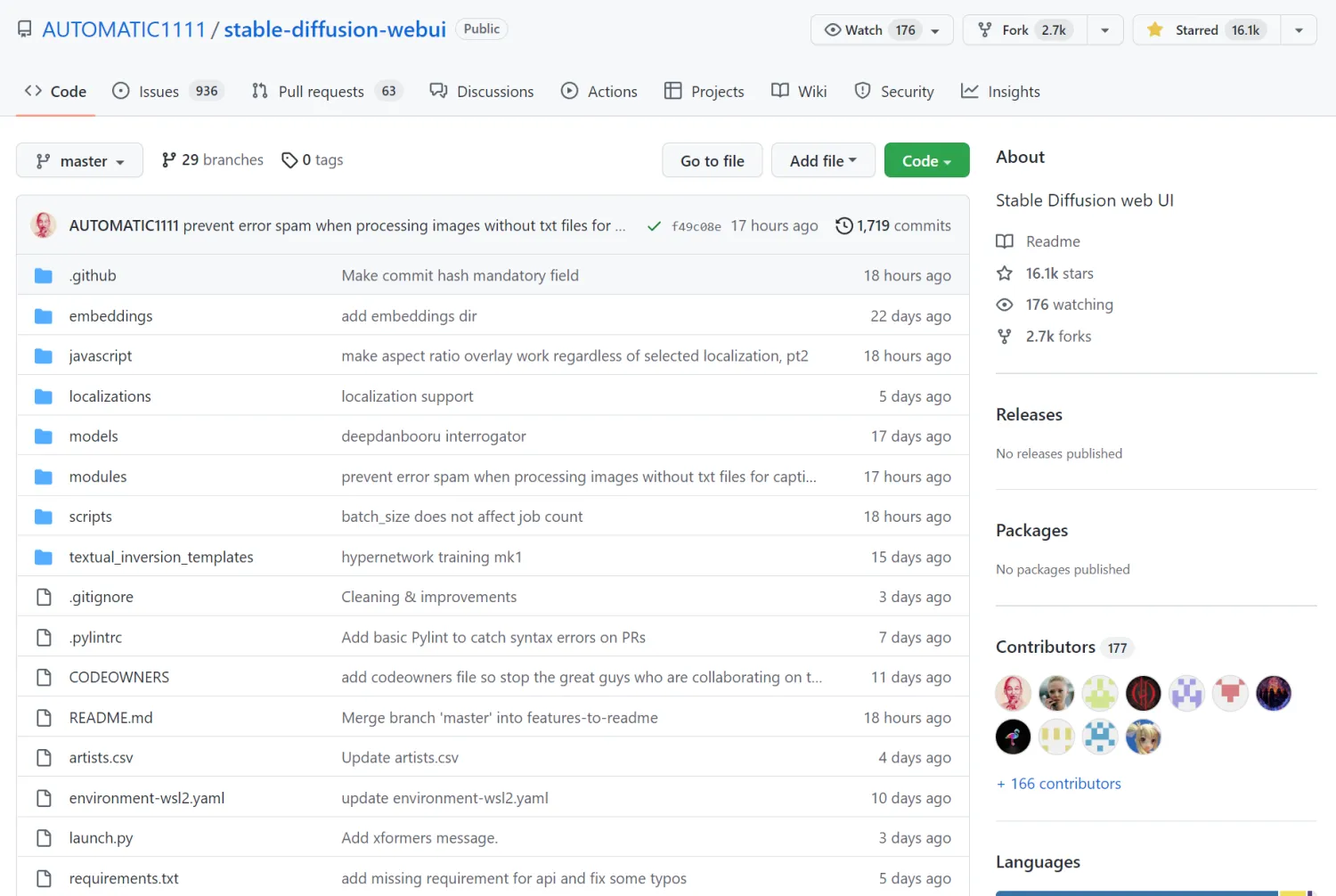
- Установите Python 3.10.6 на свой компьютер. Если другие версии Python уже установлены, вы можете использовать conda для установки дополнительной версии виртуальной среды 3.10:
conda create -n novelai python==3.10.6 - Загрузите код для этого репозитория:
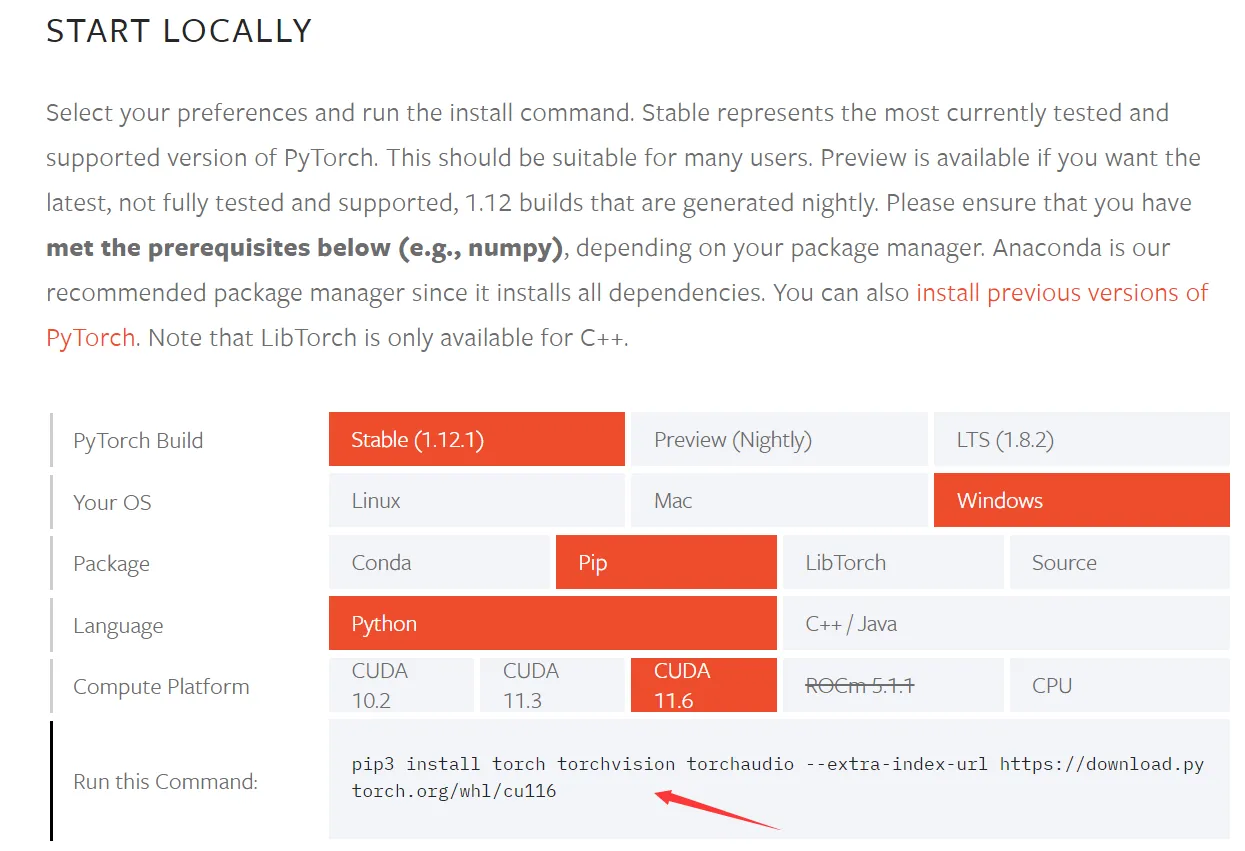
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui- Установите соответствующую версию Pytorch для графического процессора и войдите на сайт напрямую:https://pytorch.org/get-started/locally/, скопируйте соответствующую команду
Войдите в только что созданную виртуальную среду «novelai»:
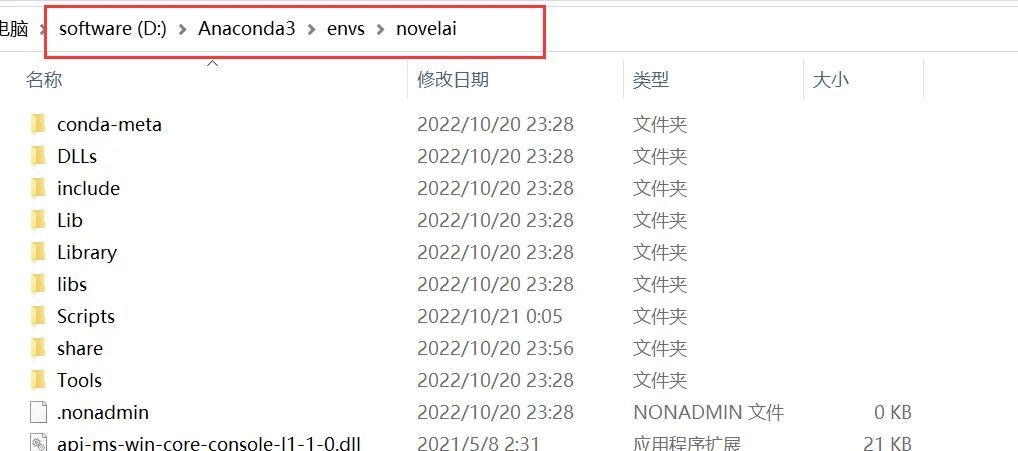
、
Выполните команду прямо сейчас:
./python -m pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116- После успешной установки вы можете проверить, может ли работать ваша собственная версия Pytorch.
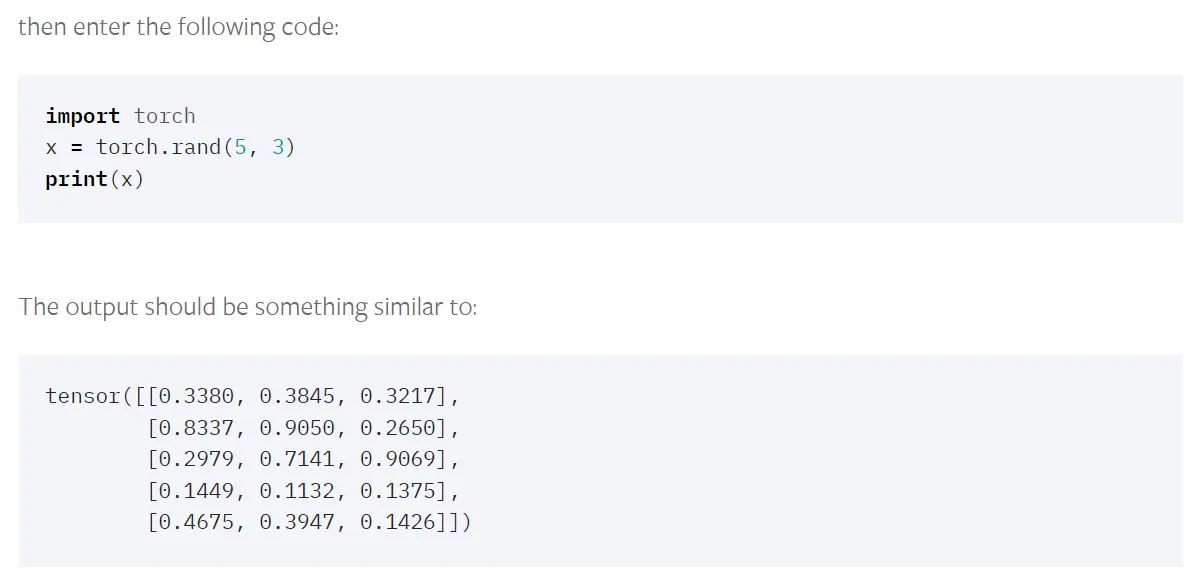
- Введите папку кода репозитория Github, который вы только что скачали, и установите сторонние зависимости:
python -m pip install -r requirements.txt2. Загрузка модели
После того, как у вас есть веб-сайт, вам необходимо скачать соответствующую модель ИИ для его эффективной генерации.
Некоторые пользователи сети использовали большое количество фотографий в Интернете для тренировки моделей и поделились ими на сайте.
https://civitai.com/
Этот знаменитый сайт известен как «Станция С», и на нем собрано множество неожиданных моделей.
На этом сайте мы можем найти множество уже обученных моделей. Например, найдите модель, которая генерирует изображения реальных людей: ChilloutMix.
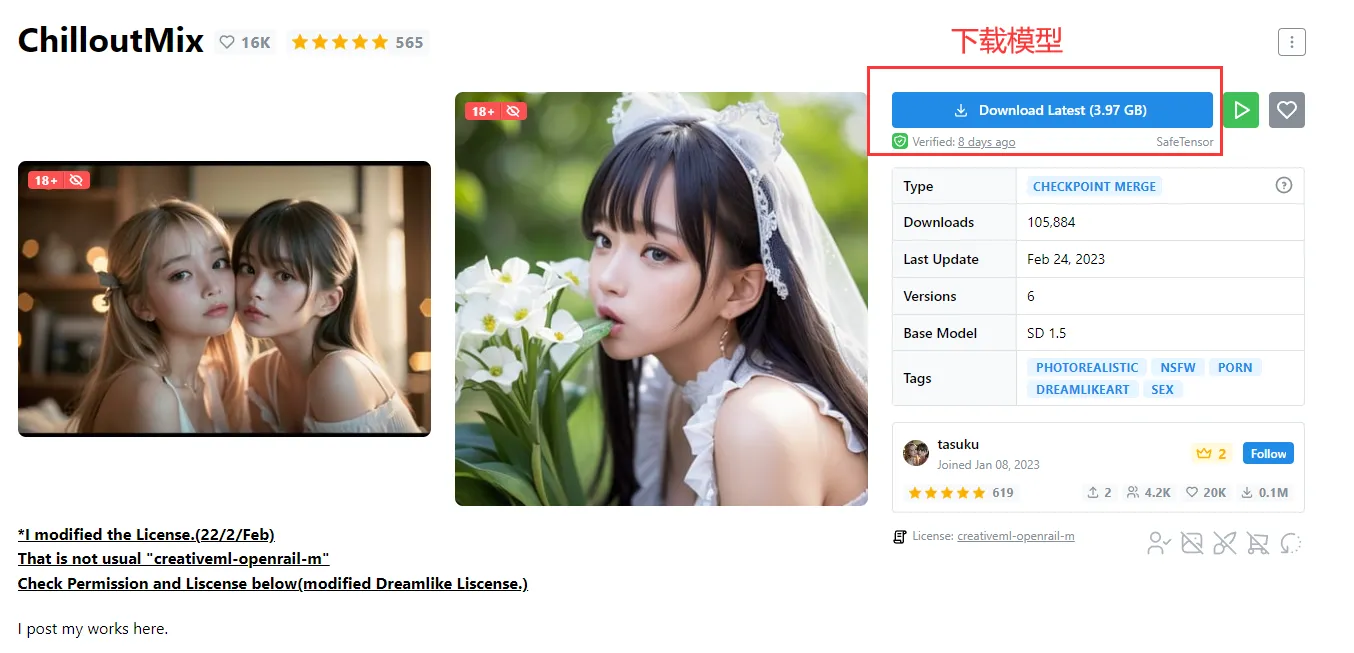
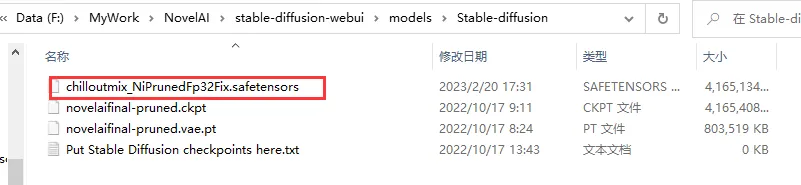
Загрузив соответствующую модель с веб-страницы, поместите ее в каталог проекта: models/Stable-diffusion.
3. Скачайте китайский плагин
Проект Stable-Diffusion-Webui также поддерживает загрузку сторонних плагинов. Например, мы можем скачать соответствующий китайский плагин.
Адрес его загрузки следующий:
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN
После входа на указанный выше сайт мы можем скачать установочный пакет плагина:
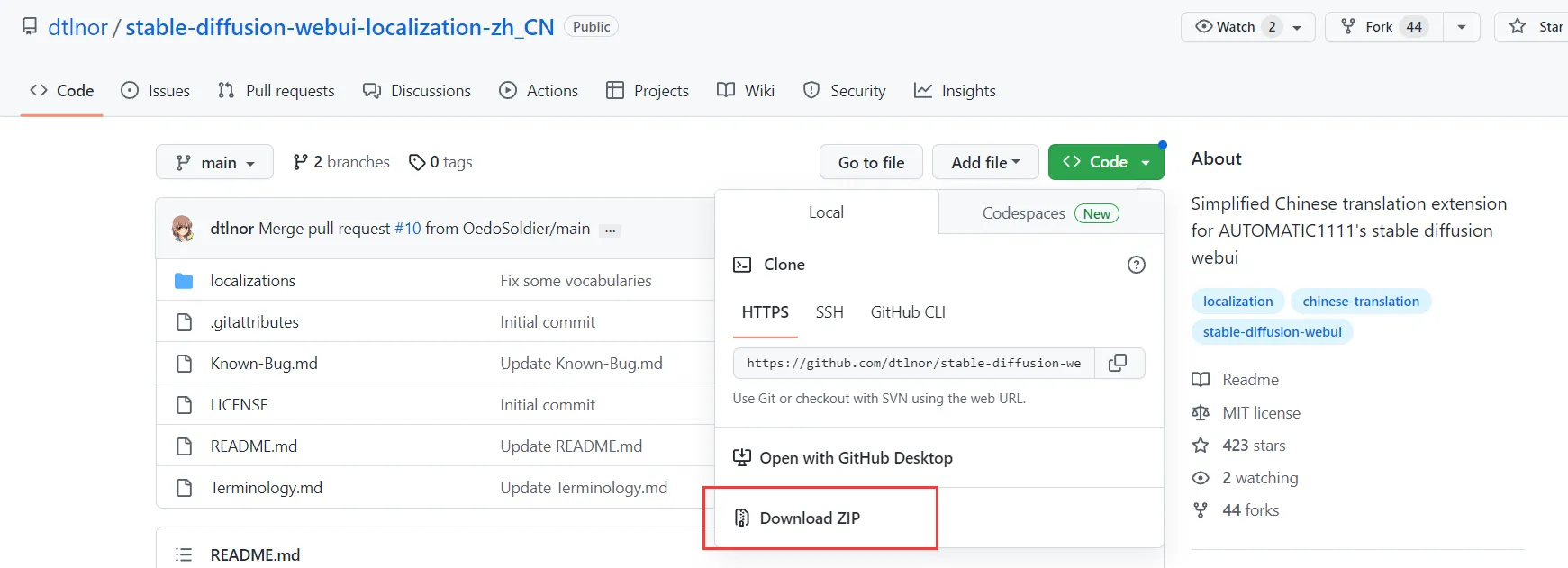
Затем разархивируйте файл и поместите его в каталог расширений:
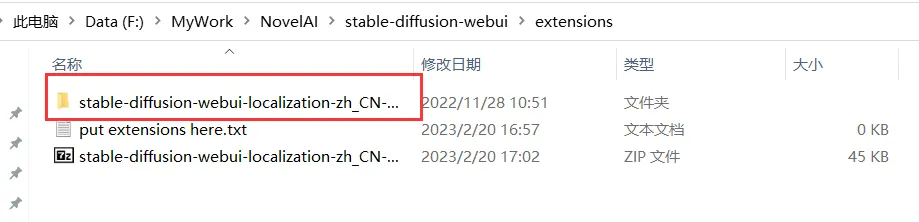
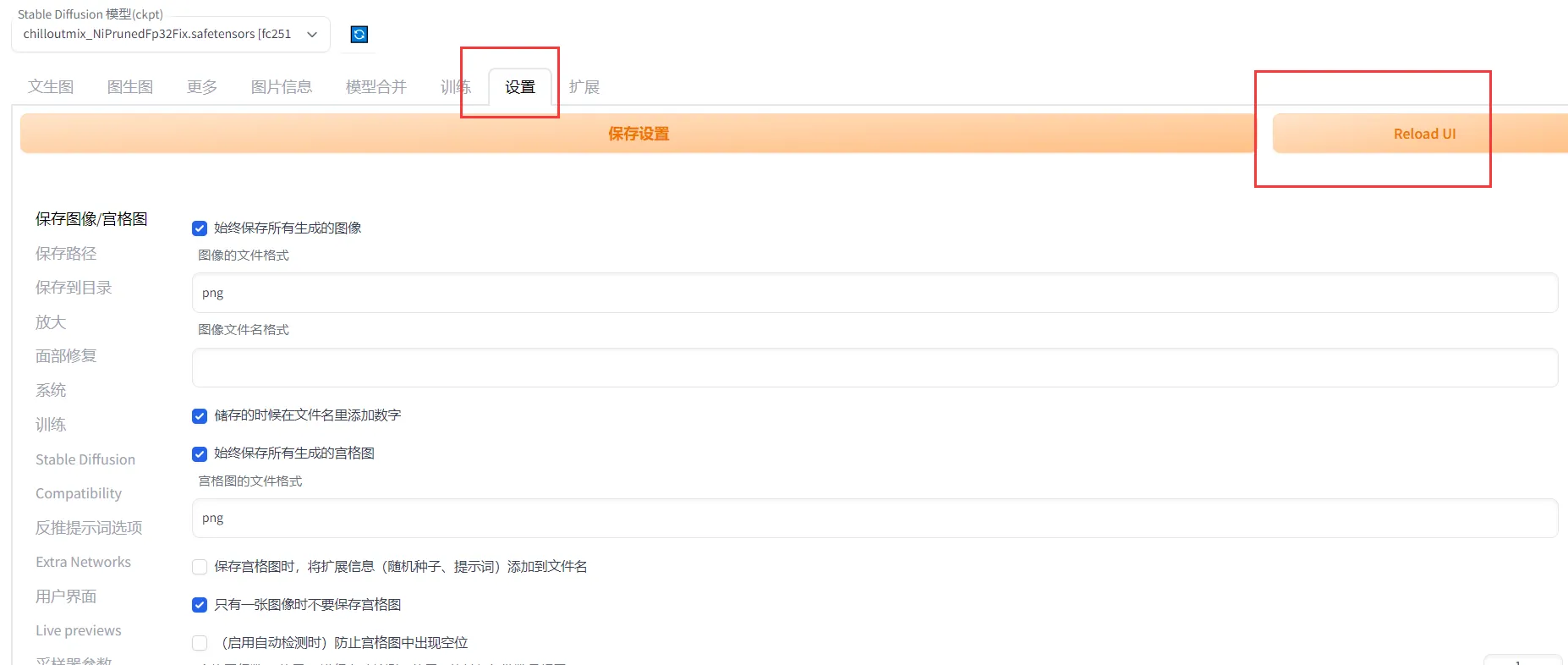
Затем вам необходимо перезапустить веб-сервис:
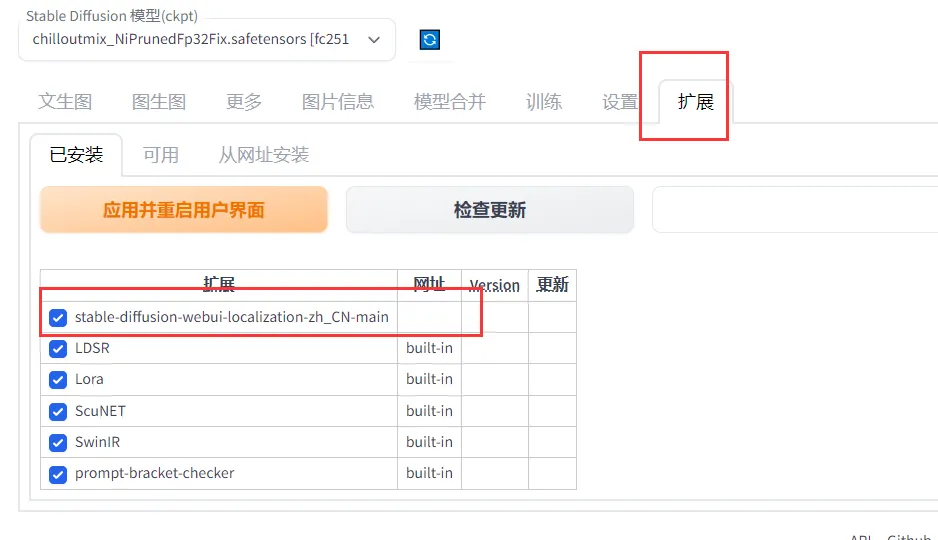
Здесь в расширении проверяем плагин:
В разделе «Настройки» найдите zh_CN. Наконец, вам нужно перезапустить веб-страницу, чтобы изменения вступили в силу:
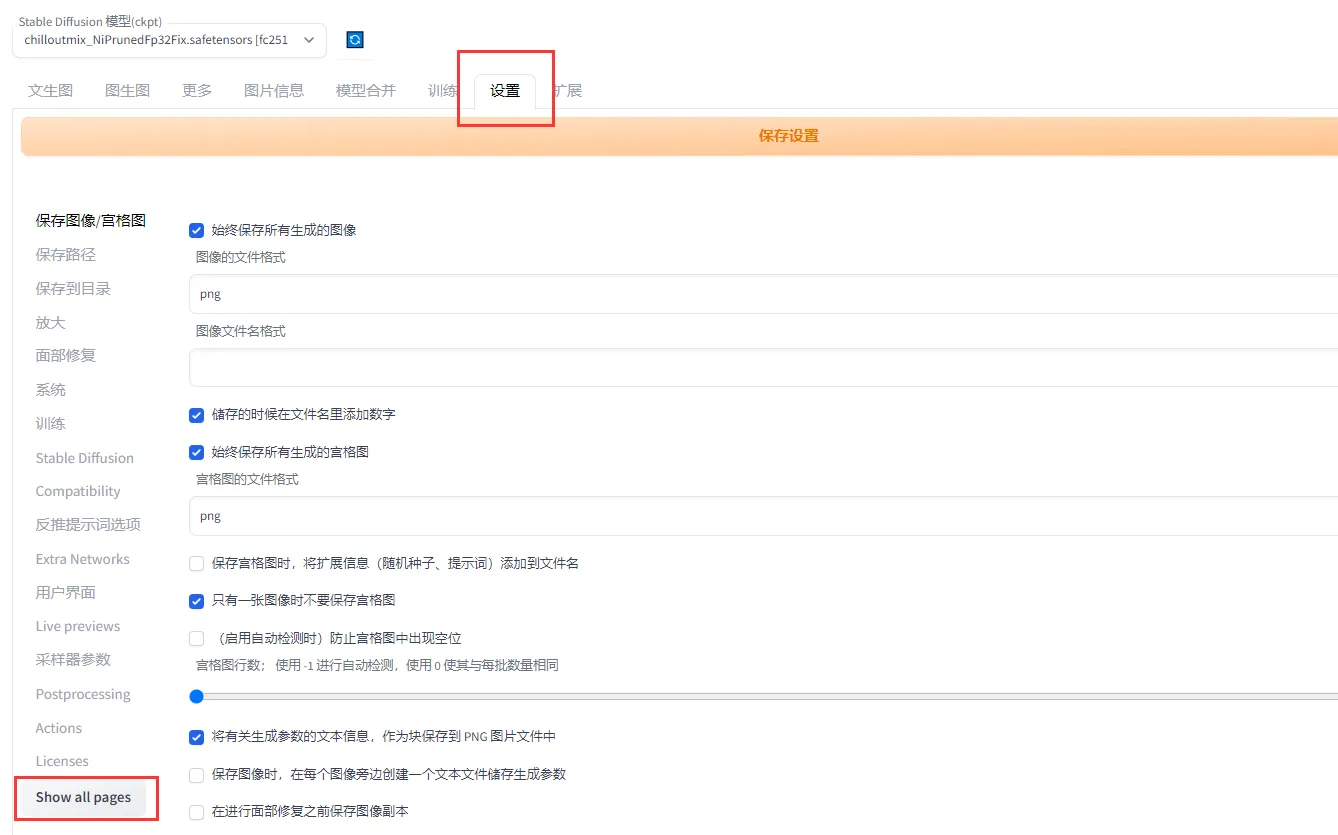
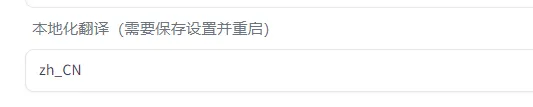
4. Создайте фотографию своего реального человека
Запустите основную программу «launch.py» и подождите определенное время, пока не появится адрес веб-страницы.
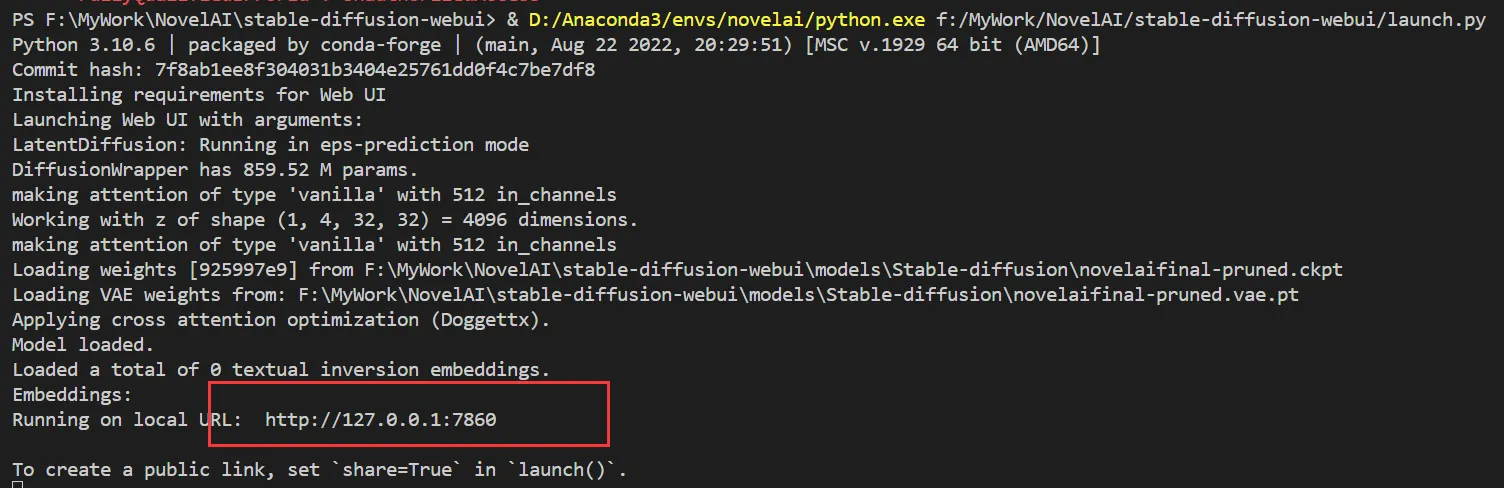
После открытия URL-адреса иногда модель может не обновиться, поэтому попробуйте перезапустить ее несколько раз.
Вам нужно выбрать модель, которую вы только что скачали: ChilloutMix.
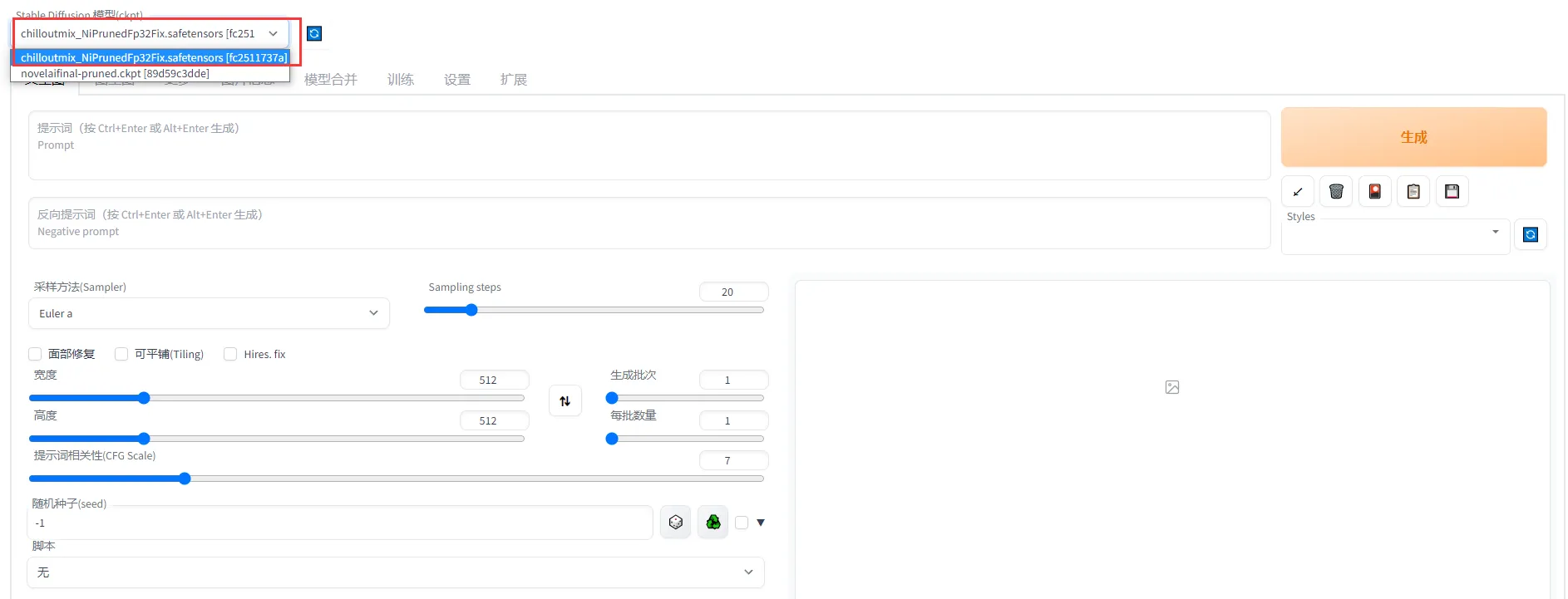
Таким образом, мы завершили предварительную работу по развертыванию. Далее я подробно научу вас, как создавать нужные вам картинки.
4.1 Создание реальных изображений
На станции c многие мастера использовали promt для генерации изображений, поэтому мы можем обратиться к ним.
Например, найдите красивую картинку и скопируйте следующие слова-подсказки:

Слова-подсказки помещаются в поле слов-подсказок, а отрицательные слова-подсказки помещаются в соответствующее поле. При этом настройте соответствующие параметры, и наконец вы сможете генерировать реальные картинки:
4.2 Генерация изображений разных стилей
На станции C также доступно для скачивания множество моделей Лоры. Это небольшая модель, которая поможет вам скорректировать свой стиль рисования. В основном он используется в Prompt.
Например, модель Lora Genshin Impact мы можем скачать на сайте:
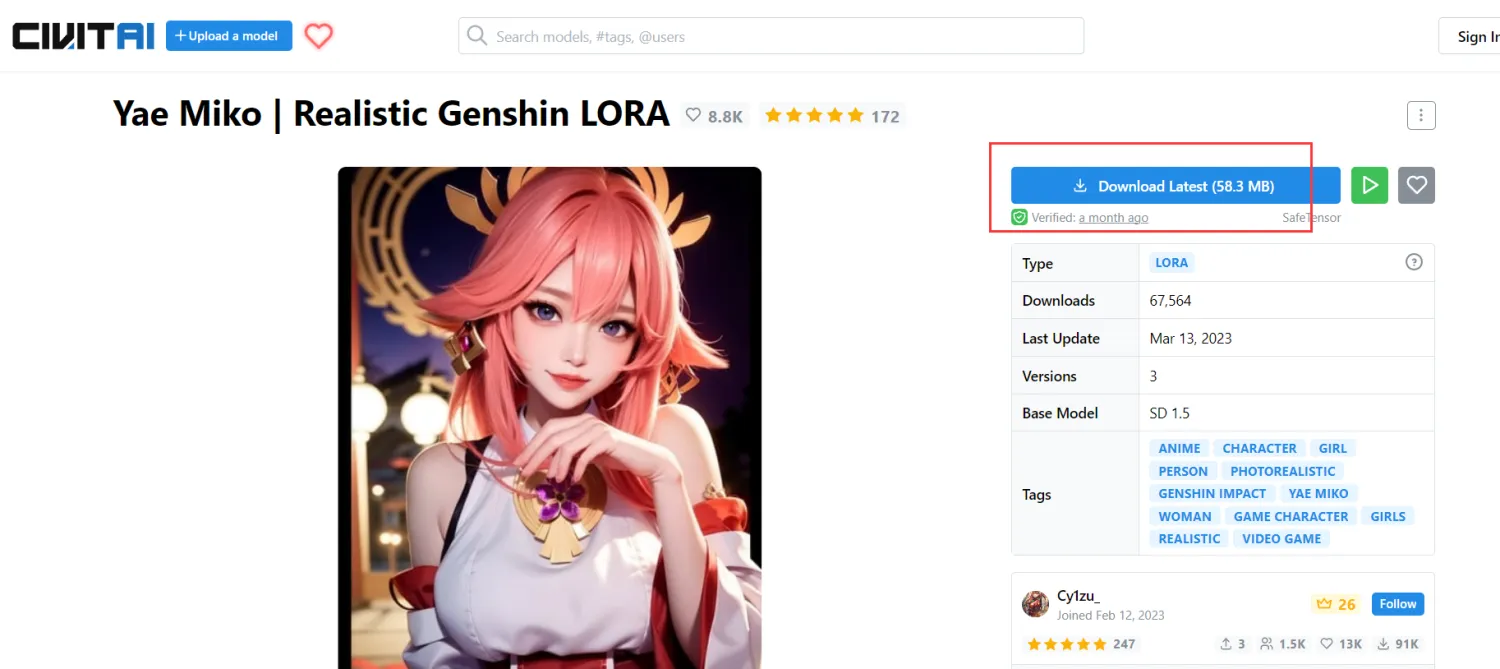
После завершения загрузки поместите модель в путь models/Lora:

Следуйте инструкциям на рисунке. После выбора модели в поле вы увидите конкретную подсказку:
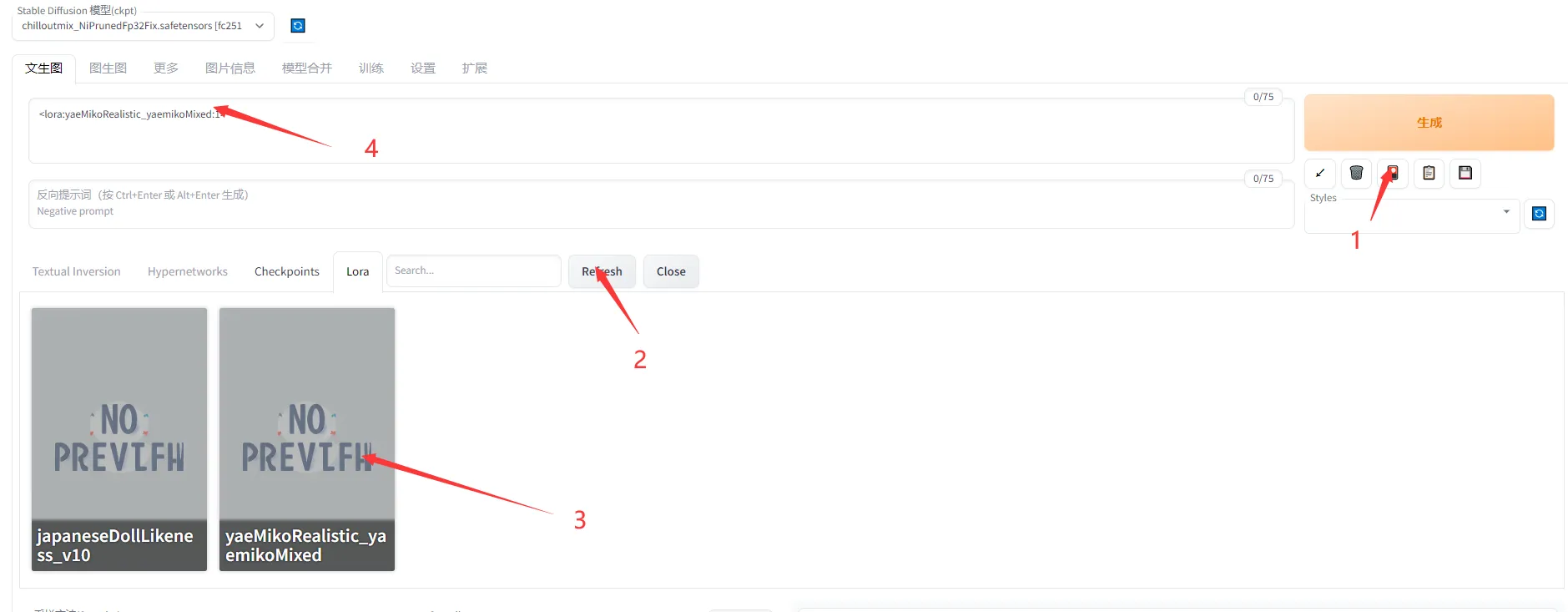
предпринимать шагиПодскажите слова в 4.1Присоединяйтесь здесь,Вы можете создать картинку в стиле Genshin:
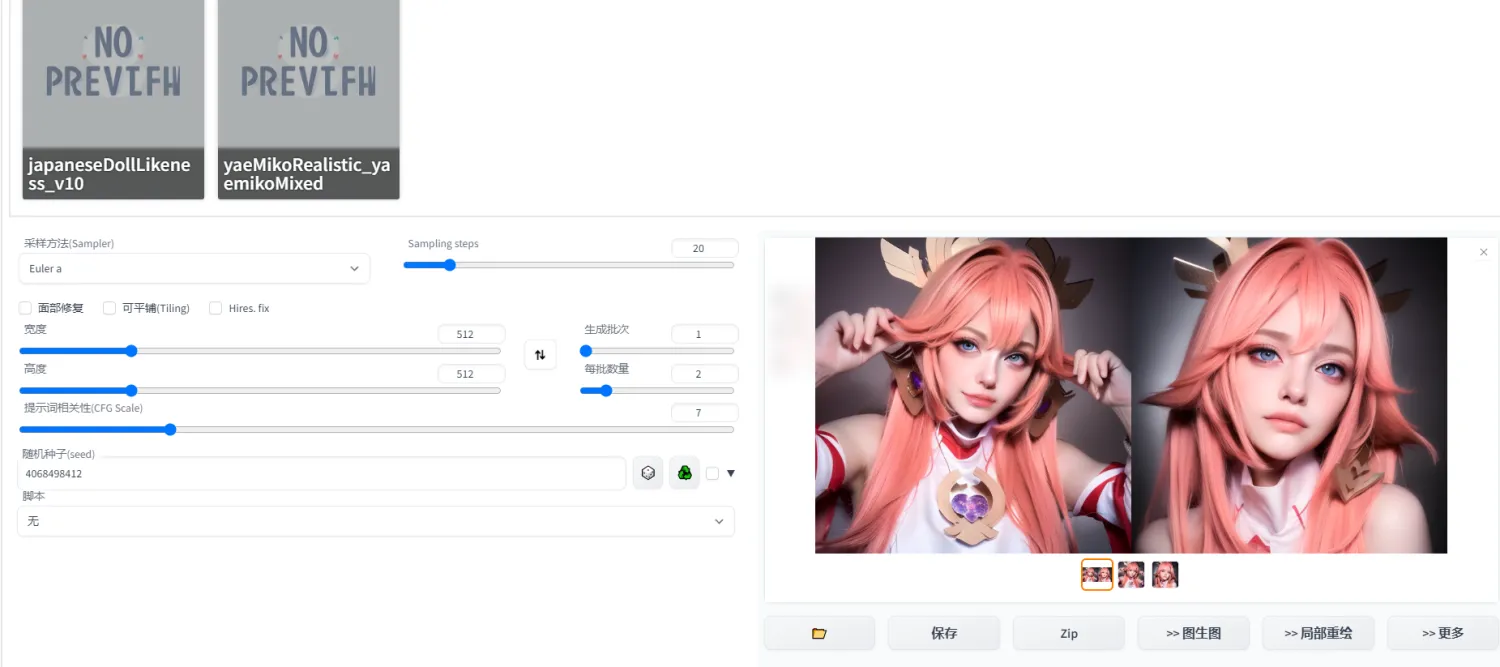
4.3 Создание анимационного видео
Для начала необходимо установить плагин“deforum”,Этот плагин может создавать видеоанимацию из нескольких сгенерированных изображений.
https://github.com/deforum-art/deforum-for-automatic1111-webui
В текущем каталоге стабильного распространения выполните следующую команду
git clone https://github.com/deforum-art/deforum-for-automatic1111-webui extensions/deforumВы обнаружите, что в расширениях появились новые плагины:
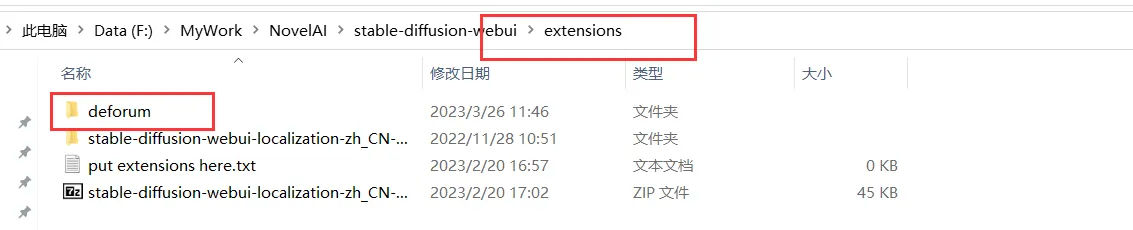
В то же время перезапустите новую веб-страницу и обнаружите дополнительную опцию deforum:
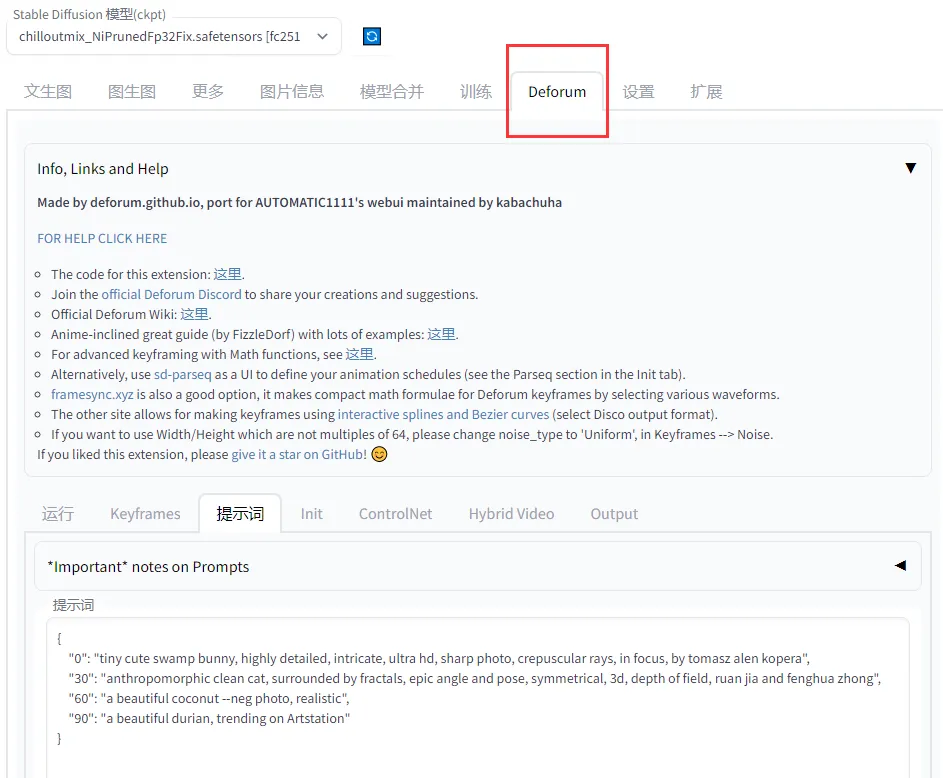
Сначала мы можем выполнить простую генерацию в слове-подсказке, оператор заполнен по умолчанию:
{
"0": "tiny cute swamp bunny, highly detailed, intricate, ultra hd, sharp photo, crepuscular rays, in focus, by tomasz alen kopera",
"30": "anthropomorphic clean cat, surrounded by fractals, epic angle and pose, symmetrical, 3d, depth of field, ruan jia and fenghua zhong",
"60": "a beautiful coconut --neg photo, realistic",
"90": "a beautiful durian, trending on Artstation"
}Окончательно сгенерированное видео выглядит следующим образом:

Шаблон слова подсказки объясняется следующим образом:
//Abstracted Example
{
"0": "Prompt A --neg NegPompt"
"12": "Prompt B"
}Где «0» и «12» указывают ключевые кадры, которые необходимо разрешить при интерполяции.
Подсказки A и B являются положительными подсказками, а NegPrompt — отрицательными.
Конечно, мы также можем напрямую использовать модель, загруженную со станции C выше, для создания живой анимации.

5. Пусть изображения, которые вы создадите, говорят сами за себя
Из вышесказанного мы получили сгенерированное изображение
Затем мы сможем использовать это изображение для создания собственного видео с речью ИИ.
Войдите по этому URL:
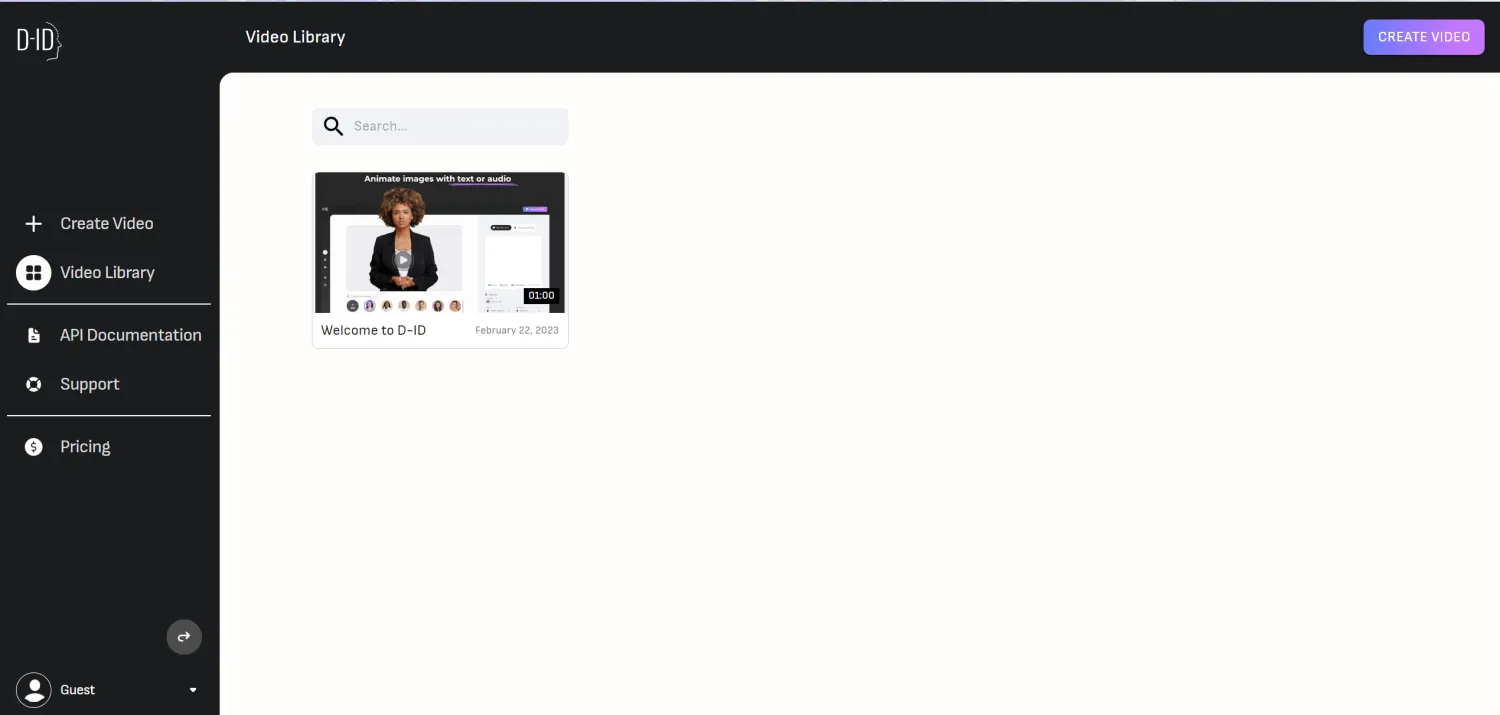
Выберите изображение, которое вы только что создали, затем введите то, что вы хотите сказать, и оно будет создано:
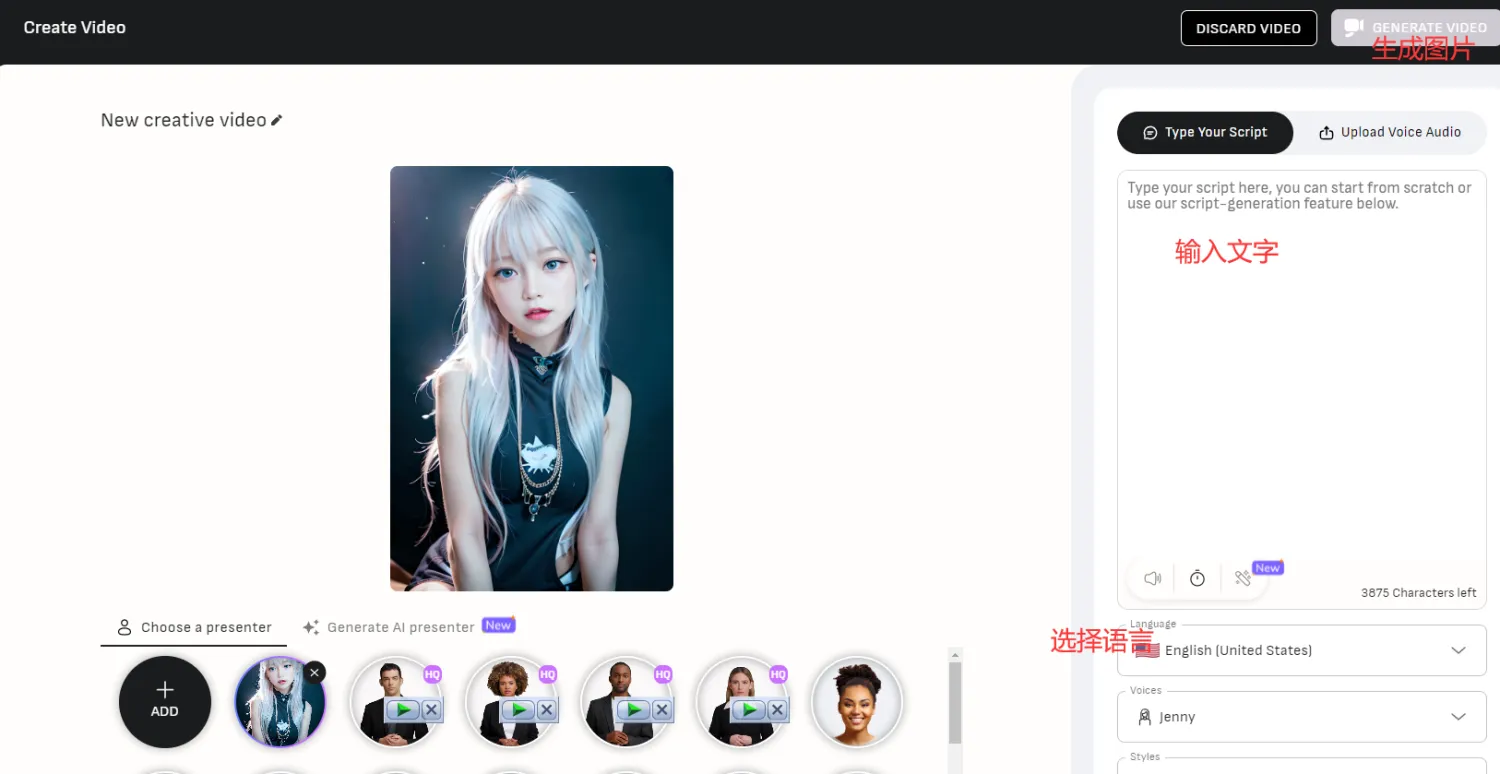
Наконец, вы можете получить более реалистичное видео разговора ИИ реального человека.

С помощью этой технологии двумерные видеоролики или даже видеоролики с речью реального человека можно создавать партиями. Это революционная технология для отрасли AICG. Я считаю, что в будущем эту технологию можно будет продвигать во многих областях.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
