Начните работу с IceBerg Data Lake за 5 минут
1. Фон айсберга
В связи с диверсификацией требований к хранению и обработке больших данных вопрос о том, как создать единое хранилище озера данных и выполнять на нем различные формы анализа данных, стал важным направлением для предприятий по созданию экосистемы больших данных. Проект Apache Iceberg, инициированный Netflix, имеет табличные форматы с поддержкой ACID и стал популярным направлением в области больших данных и озер данных.
Apache Iceberg — это продукт с открытым исходным кодом, разработанный Netflix и вошедший в инкубатор Apache 16 ноября 2018 года. Озеро данных Netflix изначально было построено с помощью Hive, но после обнаружения множества недостатков в конструкции Hive оно начало разрабатывать собственный Iceberg. Проблемы, возникающие при использовании улья, заключаются в следующем:
- Массивные операции с разделами отнимают много времени.
- Метаданные управляются MySQL и HDFS, а атомарность самой операции записи гарантировать сложно;
- Hive Metastore не имеет статистической информации на уровне файлов, поэтому фильтр можно перенести только на уровень раздела для анализа потери производительности верхнего уровня.
- Сложная семантическая зависимость Hive от базовой файловой системы делает данных сложно построить на более дешевом S3.
В целом, основные требования Netflix к созданию «Айсберга» можно резюмировать следующим образом:
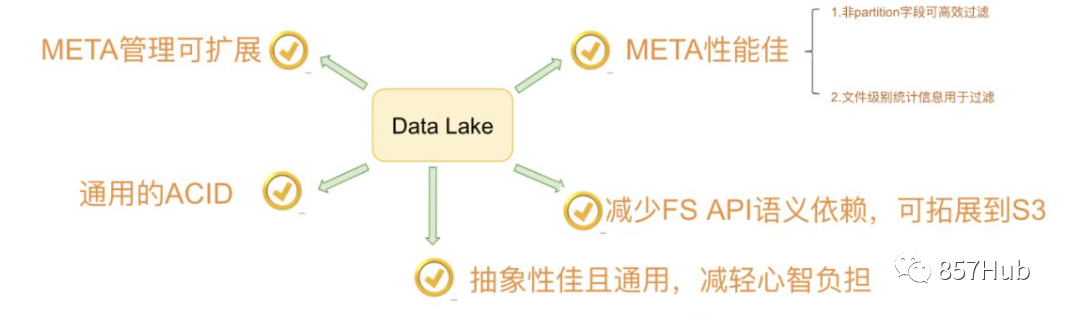
2. Знакомство с Айсбергом
2.1 Что такое Айсберг?
Apache Iceberg — это новый формат для отслеживания очень больших таблиц, разработанный специально для хранилищ объектов, таких как S3. Иметь следующие возможности:
- метод организации данных, основанный на формате хранилища
- Предоставление возможностей ACID и предоставление определенных характеристик транзакций и возможностей параллелизма.
- предоставляет возможности модификации данных на уровне строк
- Обеспечьте точность схемы и предоставьте определенные возможности расширения схемы.
2.2 Функциональные особенности Айсберга
- Эволюция схемы: поддерживает добавление, удаление, обновление или переименование без побочных эффектов.
- Скрытые разделы: могут предотвратить ошибки пользователя, которые приводят к сообщениям об ошибках или очень медленным запросам.
- Эволюция макета раздела: макет таблицы можно обновлять по мере изменения тома или шаблонов запросов.
- Управление снимками: обеспечивает повторяющиеся запросы, использующие один и тот же снимок таблицы, или позволяет пользователям легко проверять изменения.
- Откат версии: позволяет пользователям быстро исправлять проблемы путем сброса таблиц в хорошее состояние.
- Быстрое сканирование данных: читайте таблицы или находите файлы без использования распределенного механизма SQL.
- Оптимизация сокращения данных: используйте элементы таблицы data для сокращения файлов данных с использованием статистики на уровне разделов и столбцов.
- Хорошая совместимость: можно использовать в любой облачной системе и HDFS.
- Поддержка транзакций: изоляция сериализации, изменения таблиц являются атомарными, читатели никогда не увидят частичные или незафиксированные изменения.
- Высокий параллелизм: модуль записи с высоким параллелизмом использует оптимистичный параллелизм и будет повторять попытки, чтобы обеспечить успешность совместимых обновлений, даже если запись конфликтует.
2.3 Поддержка механизма вычислений/движка SQL
2.3.1 Flink
Apache Iceberg поддерживает как DataStream API Apache Flink, так и Table API для записи записей в таблицы Iceberg. В настоящее время Iceberg и Apache Flink 1.11.x интегрированы. Поддерживаемые функции следующие:
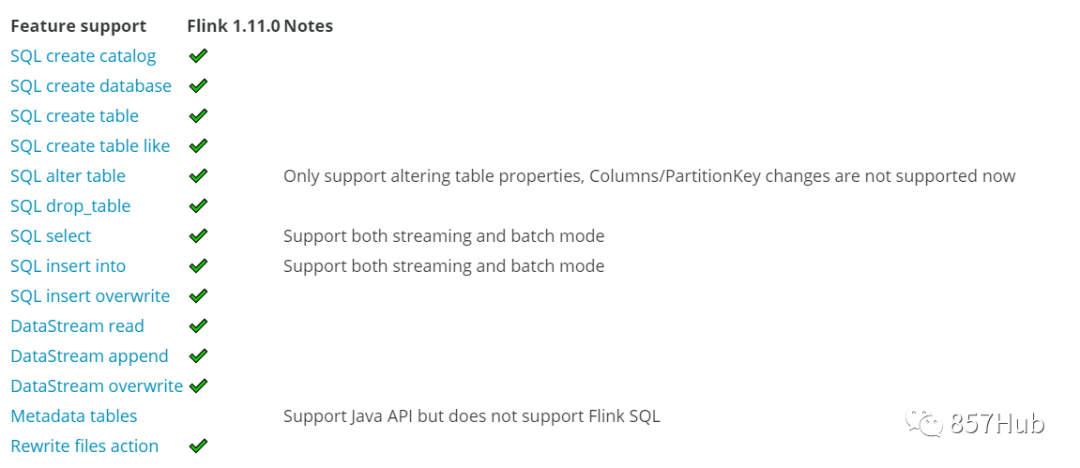
2.3.2 Spark
Iceberg использует API DataSourceV2 Apache Spark для реализации источника данных и каталога. Spark DSv2 — это развивающийся API, который обеспечивает различные уровни поддержки в версиях Spark:

2.3.3 Trino
Trino — это вычислительный механизм MPP на основе памяти. Благодаря параллельным вычислениям в памяти можно значительно повысить скорость вычислений. В сочетании с некоторыми оптимизациями (такими как сокращение, удаление предикатов и т. д.) он может решать вычислительные задачи с большими объемами данных. . Ответ второго уровня. Таблицами Iceberg можно управлять, настроив коннектор Iceberg в Trino.
3. Основные принципы Айсберга
3.1 Основные понятия Айсберга
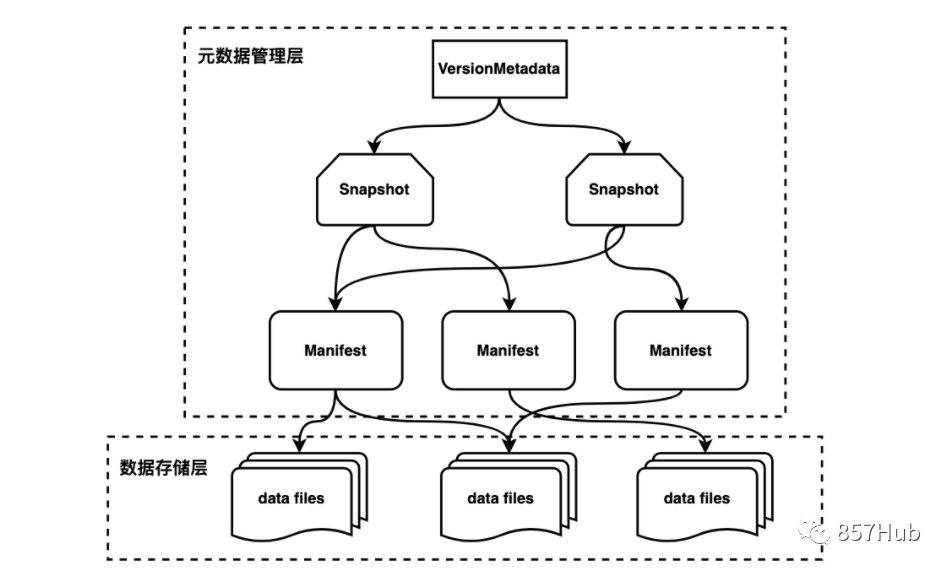
На рисунке показана структура таблицы айсберга, а связанные с ней понятия следующие:
- VersionMetadata
Хранит метаданные текущей версии (вся информация о снимках).
- Snapshot(Manifest list)
Файлы моментальных снимков, также известные как файлы манифеста, хранятся в формате avro и начинаются с snap-. Каждое обновление будет генерировать файл списка, отражающий состояние таблицы на определенный момент. Snap*.avro хранит список файлов манифеста, каждый из которых занимает одну строку. В каждой строке хранится путь к файлу манифеста, диапазон разделов файлов данных, хранящихся в файле манифеста, сколько файлов данных было добавлено, сколько файлов данных было удалено и другая информация. Эту информацию можно использовать для обеспечения фильтрации во время запроса.
- Manifest
Файл манифеста на самом деле является файлом метаданных, в котором указан список файлов данных, составляющих моментальный снимок. Каждая строка представляет собой подробное описание каждого файла данных, включая состояние файла данных, путь к файлу, информацию о разделах, статистическую информацию на уровне столбца (например, максимальное и минимальное значения каждого столбца, количество нулевых значений, и т. д.), размер файла и его содержимое. Такая информация, как количество строк данных. Статистическая информация на уровне столбца может предоставить данные для оператора во время сканирования, чтобы можно было отфильтровать ненужные файлы.
Файл манифеста хранится в формате avro, поэтому он заканчивается суффиксом .avro, например d5ba704c-1453-4f18-9077-6944baa1b3f2-m0.avro.
Каждое обновление создает один или несколько файлов манифеста.
- Datafile
Файлы данных — это файлы, которые фактически хранят данные в таблице Apache Iceberg, обычно в каталоге данных каталога хранения данных таблицы. Если у нас формат файла паркет, то файл заканчивается на .parquet,
Например, 00000-0-0eca9076-9c03-4077-baa9-e68769e15c58-00001.parquet — это файл данных.
3.2 Дизайн снимка айсберга
Основная идея: отслеживать все изменения в таблице на временной шкале.
- Снимок представляет собой полную коллекцию файлов таблиц.
- Каждая операция обновления создает новый снимок.
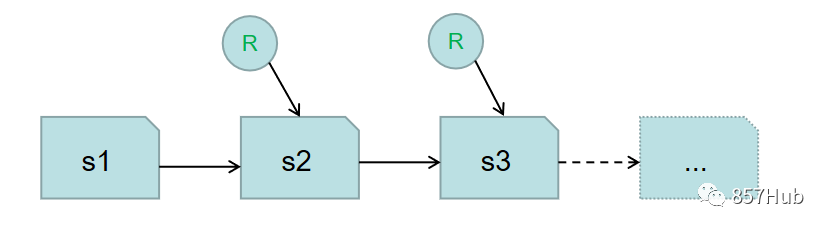
изоляция моментальных снимков
- Операции чтения применяются только к текущему сгенерированному снимку.
- Операция записи создаст новый изолирующий снимок и автоматически зафиксирует его после завершения записи.
3.3 Метаданные айсберга
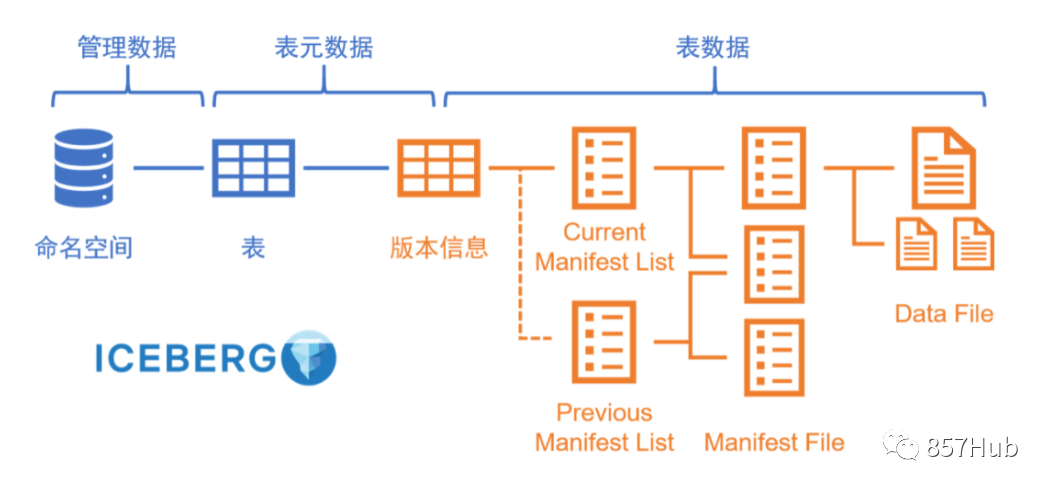
Iceberg предоставляет абстрактный интерфейс на уровне таблицы и хранит информацию метаданных таблицы в файлах (а не через HMS). На рисунке выше метаданные HMS хранят входную информацию таблицы айсберга. То есть информация о пути ввода метаданных текущей версии таблицы айсберга. В практических приложениях, как показано на рисунке ниже, информация о метаданных порядка таблицы хранится в HMS, а содержимое хранимой информации Metadata_location= hdfs://node1:9000/user/hive/warehouse/orders/metadata/00009-7aa28ddf -34fe -496b-8888-3b806a8edb7a.metadata.json — это текущая запись метаинформации моментального снимка таблицы заказов. previous_metadata_location — это запись о предыдущем снимке.



RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
