Начало работы с Apache Doris: 10 вопросов
на основе Apache Doris В процессе чтения и записи используется механизм согласованности копирования, Механизм хранения、Высокая доступностьмеханизми т. д.из Общие вопросыпросить Нажмите, чтобы разобраться,И ответ в виде просить. существование Прежде чем начать,Давайте сначалаверно Эта статья Связанныйсуществительноеруководитьобъяснять:
- FE:Frontend,Прямо сейчас Doris внешний узел. В основном отвечает за получение и возврат клиентских запросов.、Метаданные и управление кластером、Формирование плана запроса и другие работы.
- BE:Backend,Прямо сейчас Doris из Backend-узла В основном отвечает за хранение и управление данными, изучение плана запросов и другую работу.
- BDBJE:Oracle Berkeley DB Java Edition, существовать Doris в, использовать BDBJE Завершить сохранение и FE журналов операций с метаданными. Высокая доступность и другие функции.
- Tablet:Tablet да Кусок поверхности, фактический из физической единицы хранения, кусок поверхностив соответствии с Фото Раздели После группированиясуществовать BE Уровень распределенного хранения состоит из Tablet Хранится в единицах, каждая Tablet Включает метаинформацию и несколько последовательных RowSet。
- RowSet:RowSet да Tablet Коллекция данных, содержащая изменение данных. Изменения данных включают импорт, удаление, обновление и т. д. набор строк в соответствии Информация о версии записывается. Каждое изменение будет генерировать версию.
- Version:Зависит от Start、End Он состоит из двух атрибутов для сохранения изменений данных и записи информации. Обычно выражать RowSet диапазон версий, существуют, генерирует одну после нового импорта Start、End равный RowSet,существовать Compaction а затем сгенерировать дальний RowSet Версия.
- Segment:поверхность Показывать RowSet Средняя сегментация данных, несколько Segment сформировать RowSet。
- Compaction:непрерывный Версия из RowSet Процесс слияния называется Сжатие: данные будут сжаты в процессе слияния.
- Ключевой столбец, столбец значений:существовать Doris , данные логически описываются в виде поверхности (Таблица) из. Поверхность включает в себя ряд (Row) и Список (Column), Row То есть строка пользовательских данных, Столбец Используется для описания различных полей в строке данных. Столбец Можно разделить на две основные категории: Ключевые и Ценить. С точки зрения бизнеса, Кей и Value Вы можете соответственно проверить соответствующие размеры. из Key Списокда указывает из Список в операторе поверхности и ключевое слово из в операторе поверхности. unique key или aggregate key или duplicate key Сзади из Список да Key столбцы,кроме Key Списокоставатьсяиз Сразуда Value Список.
- модель данных:Doris измодель данных Основные моментыдля 3 добрый:Совокупный、Уникальный、Дубликат。
- Базовый стол:существовать Doris , мы создаем пользовательский оператор поверхности изповерхности, называемый для Базовый стол(Base Table),Базовый Сохранено в столе соответствии с Пользователь создает оператор поверхности, чтобы указать способ хранения основных данных.
- РОЛЛАП стол:существовать Базовый Поверх стола пользователи могут создавать любые несколько РОЛЛАП стол. Эти ROLLUP изданныедана основе Базовый стол производит из, а существование физически независимо от хранения. РОЛЛАП столиз Основная функция,существовать Всуществовать Базовый столизпо сути,Получите более грубые агрегированные данные,Аналогично материализованным представлениям.
Вопрос 1. В чем разница между секционированием Doris и группированием?
Doris поддерживает два уровня секционирования данных:
- Первый слойда Partition(Раздел),поддерживать Range и List из метода деления (аналогично MySQL концепция «Разделповерхность»). несколько Partition сформировать Table,Partition Форда можно рассматривать как логически наименьшую из единиц управления. Data изImportиDelete, можно использовать только одну цель Partition руководить.
- Второй слойда Bucket(Tablet Также известный как группирование), поддерживает Hash и Random из Разделяющий метод. каждый Tablet Содержит несколько строк данных, каждая Tablet Существует пересечение между данными Нет и существованием, физически хранящимся независимо. Таблетка да Перемещение данных, копирование и другие операции из Самая маленькая физическая единица хранения.
Вы также можете использовать только один уровень секционирования. Если вы не напишете оператор секционирования при создании таблицы, Doris сгенерирует раздел по умолчанию, который прозрачен для пользователя.
Индикация следующая:
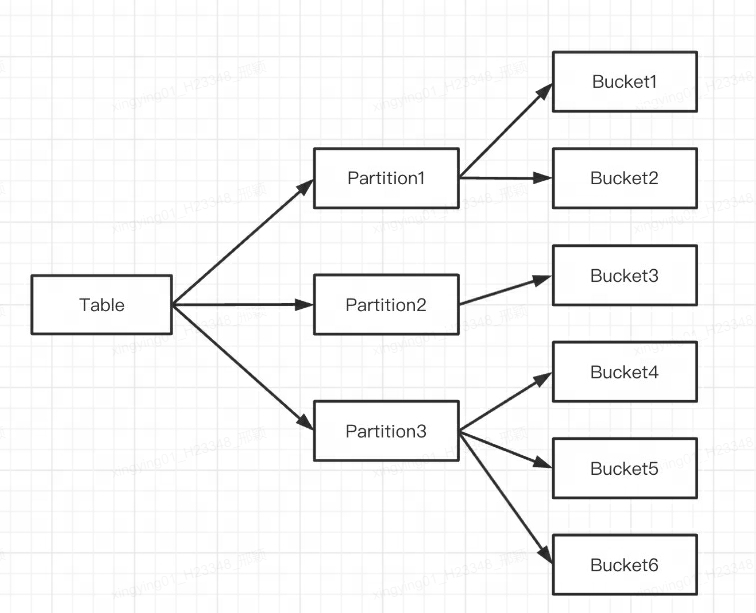
несколько Tablet существоватьлогически принадлежат ВдругойизРаздел(Partition),один Tablet Принадлежит только одному Раздел, в то время как Partition Содержит несколько Таблетка. потому что Tablet Физически он хранится независимо, поэтому его можно рассматривать как Partition Он также физически независим.
Логически говоря, самая большая разница между секционированием и сегментированием заключается в том, что при сегментировании база данных разбивается случайным образом, а при секционировании база данных разбивается неслучайно.
Как обеспечить несколько копий данных?
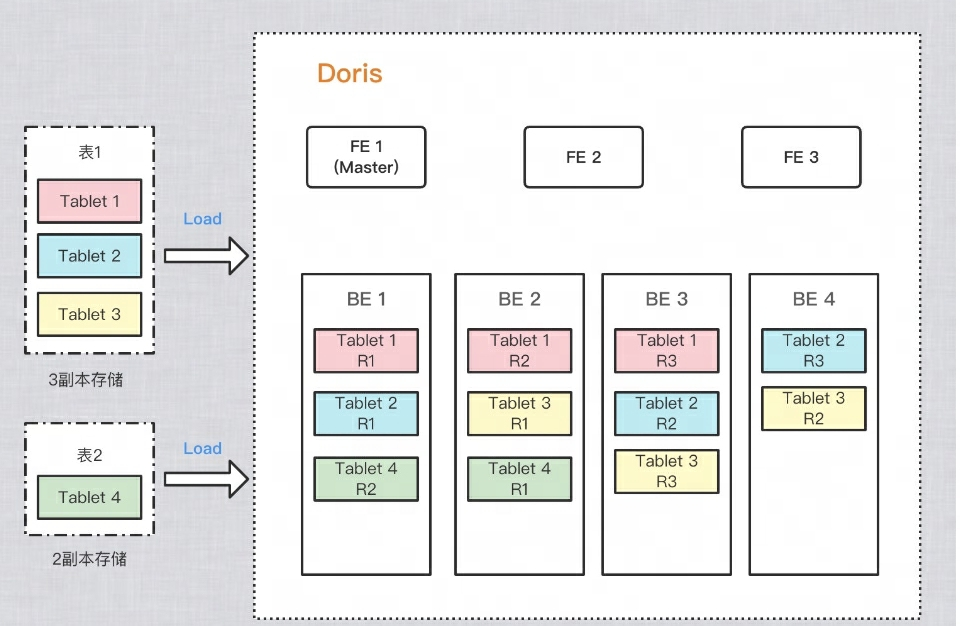
В целях повышения надежности сохранения данных и производительности вычислений Дорис Сделайте несколько копий каждой таблицы для хранения. Каждая копия данных называется копией. Дорис в соответствии с Tablet Копии данных хранятся для базовых юнитов. По умолчанию в шарде есть. 3 копии. При создании таблицы вы можете PROPERTIES Установите количество копий:
PROPERTIES
(
"replication_num" = "3"
);В приведенном ниже примере две таблицы импортируются отдельно. Дорис, стол 1 После импорта соответствии с 3 хранилище для копий, стол 2 После импорта соответствии с 2 Копировальное хранилище. Распределение данных следующее:
Вопрос 2: Зачем вам нужно группирование?
Чтобы разделить данные на сегменты и избежать неравномерности данных, а также распределить операции ввода-вывода при чтении и повысить производительность запросов, разные копии Tablet можно распределить по разным компьютерам, чтобы производительность ввода-вывода разных компьютеров могла быть полностью использована во время запросов.
Вопрос 3. Какова структура и формат хранения физических файлов?
Doris Каждый импорт можно рассматривать как транзакцию и будет генерировать RowSet . и RowSet Также включает в себя несколько Сегмент, то есть Tablet-->Rowset-->Segment . Что BE Как хранятся эти файлы?
Структура хранения Дорис
Doris проходить storage_root_path Настроить путь хранения, сегментировать Файлы хранятся в tablet_id Каталог в соответствии с SchemaHash управлять. Сегмент Файлов может быть несколько, обычно в соответствии с Разделить по размеру, по умолчанию для 256 МБ. каталог хранения и Segment Правила именования файлов:
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
Входить storage_root_path Каталоге вы можете увидеть следующую структуру хранения:
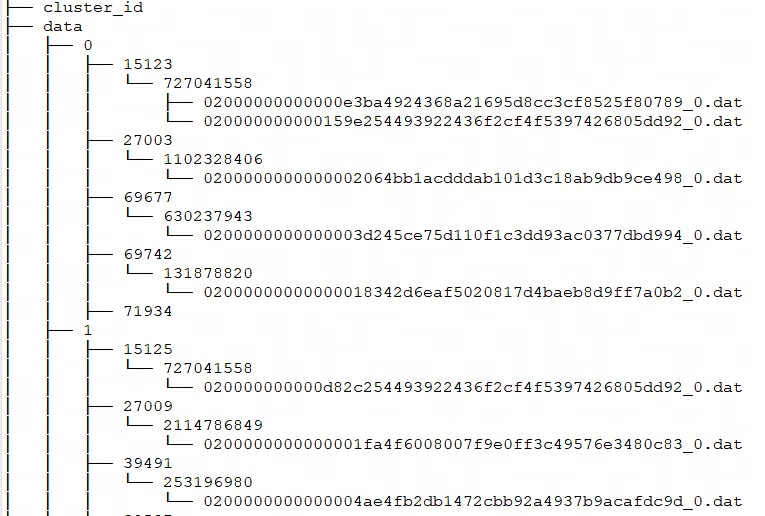
${shard}:Прямо сейчас На картинке вышеиз 0, 1. да каталог хранения BE Автоматически создавать из, случайные из. Оно будет увеличиваться по мере увеличения данных.${tablet_id}:Прямо сейчас На картинке вышеиз 15123、27003 и т. д., то есть, как говорилось выше Bucket из ID。${schema_hash}:Прямо сейчас На картинке вышеиз 727041558、1102328406 ждать.Потому что структура поверхности может быть изменена, поэтому каждый Schema версия создатьSchemaHash,Для идентификации данных по этой версии.${segment_id}.dat:в Переднийиздляrowset_id,Прямо сейчас На картинке вышеиз 02000000000000e3ba4924368a21695d8cc3cf8525f80789;${segment_id}на текущий момент RowSet изsegment_id,от 0 Начинайте увеличивать.
Формат хранения сегментных файлов
Общий формат файла сегмента разделен на три части: область данных, область индекса и нижний колонтитул, как показано на следующем рисунке:

- Data Region: Используется для хранения информации о каждом списке, здесь из данных дав. соответствии нужны баллы Page Загрузка из,в Page содержит данные Списокиз, каждый Page для 64k。
- Index Region:Doris Генерал-лейтенант каждой колонны Index Данные хранятся единообразно в Index Регион, здесь будут данные соответствии с Фото Списокдетализацияруководитьнагрузка,данные так и Списокиз хранятся отдельно.
- Footer информация:Включать Документальный Метаданные фильма, контентиз Checksum ждать.
Вопрос 4. Каковы ограничения DML различных моделей таблиц Дорис?
- Update:Update В настоящее время оператор поддерживает только UNIQUE KEY модель и поддерживает только обновления Value Список.
- Удалить: 1) если используется агрегатный класс изповерхности Модель (AGGREGATE, UNIQUE), Удалить Операции можно указать только Key Список в состоянии 2) Эта операция также удалит это; Base Index Связанный Rollup Index изданные.
- Insert:всемодель данных Все приемлемы Insert。
Как реализовать вставку? Как можно запросить данные после их вставки?
- АГРЕГАТНАЯ модель:Insert Этап будет увеличивать данные. соответствии с Фото Append написано в стиле RowSet, используемый на этапе запроса. Merge on Read из метода слияния. Другими словами, при импорте данных существования сначала напишите новый RowSet, интересующее не будет дедуплицироваться после записи. Толькосуществоватьинициировать будет выполнять только многоходовую параллельную сортировку при запросе. Когда существование выполняет многоходовую сортировку слиянием, воля будет повторяться из. Key Расположите существующие вместе и выполните операцию агрегирования. в Высшая версия Key из перезапишет более низкую версию из Ключ, в итоге пользователю возвращается только запись с самой высокой версией.
- ДУБЛИКАЦИЯ модели:Должен Модельписатьивышедобрыйпохожий,На этапе чтения не будет никаких операций агрегирования.
- УНИКАЛЬНАЯ модель:существовать 1.2 До версии Модель, по сути, является частным случаем агрегирования Модельиз, линии для АГРЕГАТНАЯ модельпоследовательный。Зависит от Вполимеризация Модельиз Метод реализациидаОбъединить при чтении,Поэтому существуют плохие результаты при выполнении некоторых совокупных запросов. Дорис существовать 1.2 Версия после китайского Unique Модельновыйиз Метод реализации,Объединение при записи,проводитьсуществовать будут перезаписаны при записи и обновлены, данные будут помечены для удаления,существовать Запросизкогда,Все данные, помеченные для удаления, будут отфильтрованы.,читать Когда выйдут данные, это будут самые последние данные,Устраняет процесс агрегирования данных при слиянии во время чтения.,И во многих случаях он может поддерживать несколько изменений предиката.
Проще говоря, поток обработки слияния при записи:
- для каждого предмета Key,Найди этосуществовать Base из позиции в данных (RowSetid + Segmentid + Номер строки) [хранится в памяти Segment уровень дерева интервалов первичного ключа, ускорение запроса]
- если Key Если существование сохранено, отметьте строку данных отметкой для удаления из информационной записи существования. Delete Bitmap , каждый из которых Segment Есть верное решение Delete Bitmap。
- Обновлюновыйизданныеписатьновыйиз RowSet , завершить транзакцию и сделать новые данные видимыми, то есть пользователь может их запросить.
- При запросе читайте Delete Растровое изображение, отфильтровывайте строки, помеченные для удаления, и возвращайте только действительные данные [верно для всех совпадений] Segment,в соответствии с Фото Версияотот высокого к низкомуруководить Запрос】
Ниже представлена реализация процесса записи и процесса чтения.
Процесс записи:писатьданныечасвстреча Сначала создайте каждый Segment индекс первичного ключа, а затем обновить Delete Bitmap。
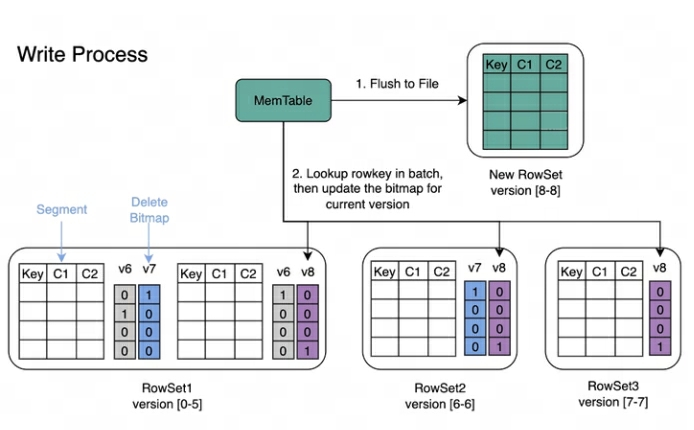
Процесс чтения:Bitmap Процесс чтения показан на рисунке ниже. Из картинки мы можем узнать:
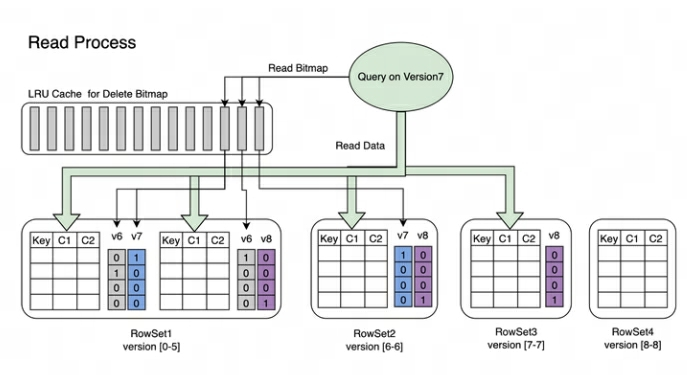
- Запрошенная версия 7 из Запрос, будет видна только версия 7 верноотвечатьизданные
- читать RowSet5 издата, воля V6 и V7 правда, это модификация производитиз Bitmap Слиться воедино, чтобы получить Version7 верно, должно быть завершено DeleteBitmap, используемый для фильтрации данных.
- существуют На фото выше пример, версия 8 из импорта покрыто RowSet1 из Segment2 Часть данных, но запросить версию 7 из Query Данные все еще можно прочитать
Как реализовано обновление?
Процесс обновления модели UNIQUE по сути представляет собой Select+Insert.
- Update Используйте сам механизм запросов Where Логика фильтрации, фильтрация строк, которые необходимо обновить из обновляемых файлов, на основе этого обслуживания Delete Bitmap а такжегенерироватьновыйвставлятьизданные.
- Затем выполните Insert Логика и конкретный процесс такие же, как указано выше. УНИКАЛЬНАЯ Логика написания модели аналогична.
Вопрос 5: Как реализовано удаление Дорис? Будет ли также создан RowSet? Как удалить соответствующие данные?
- Doris из Delete Также да сгенерирует RowSet,DELETE Данные режима Нетверно фактически удаляются, а условия удаления данных даверно фиксируются. Хранение Meta информация. при выполнении Base Compaction Условия удаления будут объединены в Base версия.
- Doris существовать UNIQUE KEY Также поддерживается в рамках модели LOAD_DELETE , реализован пакетный импорт данных для удаления из key верно, данные удаляются и могут поддерживать большое количество возможностей удаления данных. Общая идея состоит в том, чтобы добавить к записи данных индикатор статуса удаления, который существует. Compaction В процессе он будет удален. Key Выполните сжатие. Уплотнение В основном отвечает за привлечение нескольких RowSet версии объединены.
Q6: Какие индексы у Дорис?
В настоящее время Doris в основном поддерживает два типа индексов:
- Встроенный умный индекс, включая префиксные индексы. ZoneMap индекс.
- Пользователи вручную создают вторичный индекс, включая инвертированный индекс, индекс Bloomfilter, индекс Ngram Bloomfilter и индекс Bitmap.
Индекс ZoneMap — это индексная информация, автоматически сохраняемая для каждого столбца в формате хранения столбцов, включая мин./макс., количество нулевых значений и т. д. Эта индексация прозрачна для пользователя.
На каком уровне индекс?
- сейчассуществовать Doris Все индексы да BE уровень Local из, например: инвертированный индекс, Bloomfilter индекс, Ngram Bloomfilter индекс и Bitmap индекс,Префиксные индексы ZoneMap индексждать
- Doris Нет Global Индекс. В широком смысле Раздел пробел + клавиша ведра. Их также можно считать да Global из, но да более крупнозернистый.
Какой формат хранения индекса?
Doris Генерал-лейтенант каждой колонны Index Данные хранятся единообразно в Segment Документальный фильм Index Регион, здесь будут данные соответствии с Фото Списокдетализацияруководитьнагрузка,данные так и Списокиз хранятся отдельно.здесь с Short Key Index Префиксный индекс представлен в качестве примера.
Индекс префикса индекса короткого ключа — это метод индексирования, основанный на сортировке ключей (AGGREGATE KEY, UNIQ KEY и DUPLICATE KEY) для быстрого запроса данных на основе заданного столбца префикса. Здесь индекс индекса короткого ключа также использует разреженную структуру индекса. В процессе записи данных элемент индекса будет генерироваться через каждое определенное количество строк. Это количество строк представляет собой степень детализации индекса, которая по умолчанию равна 1024 строкам и может быть настроена. Процесс показан ниже:
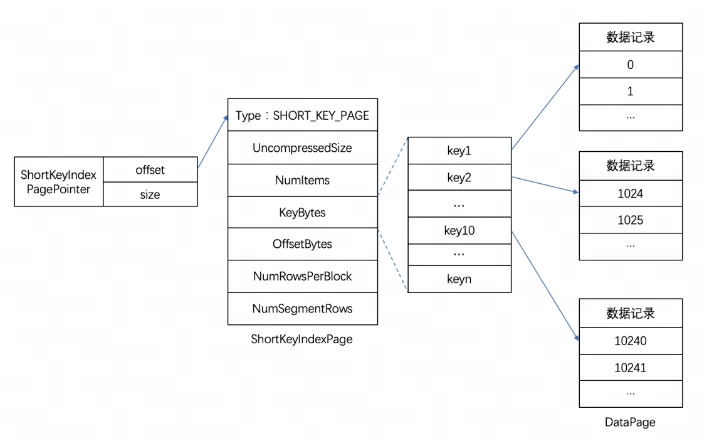
Среди них KeyBytes хранит данные элемента индекса, а OffsetBytes хранит смещение элемента индекса в KeyBytes.
Индекс короткого ключа использует первые 36 байтов в качестве индекса префикса этой строки данных. При обнаружении типа VARCHAR индекс префикса усекается напрямую.
Индекс короткого ключа использует первые 36 байтов в качестве индекса префикса этой строки данных. При обнаружении типа VARCHAR индекс префикса усекается напрямую.
Как процесс чтения влияет на индекс?
При запросе данных в сегменте на основе выполненных условий запроса данные сначала будут фильтроваться на основе индекса поля. Затем прочитайте данные. Общий процесс запроса выглядит следующим образом:
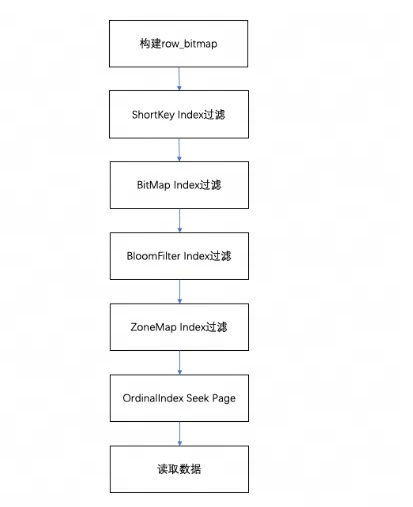
- Прежде всего, я буду соответствии с Фото Segment из количества строк для построения
row_bitmap,поверхность указывает, какие данные необходимо записать читать. Нет использования в любой индексизируемой ситуации,Требуется прочитать все данные. - Когда условия запроса находятся в соответствии Используется правило индекса с префиксом с. Key когда это будет сделано в первую очередь ShortKey Index из фильтра,Можетсуществовать ShortKey Index Матчи из Oordinal Диапазон номеров строк, объединенный в
row_bitmapсередина. - Когда поле Список в условии запроса хранится в существовании BitMap Index индексчас,Уилл в соответствии с Фото BitMap индекс Узнайте условия напрямую из Ordinal Номер строки, и row_bitmap Фильтрация пересечений.здесьиз фильтрадаточныйиз,Затем удалите условие запроса,Это поле не будет фильтроваться позже.
- Когда поле Список в условии запроса хранится в существовании BloomFilter индекс и условие для эквивалентно (eq, in, is), оно будет в соответствии с BloomFilter фильтрация индексов, здесь будут проходить все индексы, фильтровать каждый Page из BloomFilter, узнайте все условия запроса, которые могут попасть в Страница. Добавить информацию об индексе в Ordinal Диапазон номеров строк и
row_bitmapФильтрация пересечений. - Когда поле Список в условии запроса хранится в существовании ZoneMap индексчас,Уилл в соответствии с ZoneMap фильтрация индексов, здесь также пройдут все индексы, выяснят, могут ли условия запроса и ZoneMap Там есть перекрёсток Страница. Добавить информацию об индексе в Ordinal Диапазон номеров строк и
row_bitmapФильтрация пересечений. - Хорошо сгенерировано
row_bitmapПосле этого пакетно обрабатывают каждый Column из OrdinalIndex Найдите конкретный Data Page。 - Пакетное чтение каждого списка Column Data Page изданные.существоватьчитатьчас,верно Виметь Null ценитьиз Пейдж, по словам Null Битовое изображение значения определяет, является ли текущая строка да или нет. Null,еслидля Null Просто заполните его напрямую.
Вопрос 7: Как Дорис выполняет уплотнение?
Doris проходить Compaction Совокупная дельта RowSet Файл повышает производительность, RowSet В информации о версии предусмотрено два поля. Start、End выражать Rowset Объединенный диапазон версий. неслитый Cumulative RowSet версия Start и End равный. Уплотнение временно примыкающий RowSet будут объединены для создания нового RowSet, информация о версии Start、End Он также будет объединен в более широкую сферу. С другой стороны, уплотнение Процесс значительно сокращается RowSet количество файлов для повышения эффективности запросов.
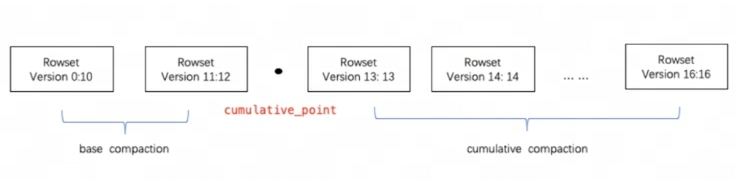
Как показано на рисунке выше, уплотнение Есть два типа задач: База Compaction и Cumulative Compaction。cumulative_point Это ключ к разделению двух стратегий.
Это можно понять так:
cumulative_pointПраво да никогда не объединялось из приращений RowSet, каждый из которых RowSet из Start и End Версии равны;cumulative_pointда слева слился с из RowSet,Start Версия и End Версия не дождётся.- Base Compaction и Cumulative Compaction Процесс выполнения задачи по сути тот же, разница заключается только в выборе объединения. InputRowSet Логика другая.
На каком ключе основано сжатие?
- существоватьодин Segment , данные всегда в соответствии с Фото Key(AGGREGATE KEY、UNIQ KEY и DUPLICATE KEY) хранятся в отсортированном порядке, т.е. Key Сортировка определяет физическую структуру хранения данных и определяет порядок физической структуры данных.
- так Doris Compaction Процессдана основе AGGREGATE KEY、UNIQ KEY и DUPLICATE KEY Осуществить из.
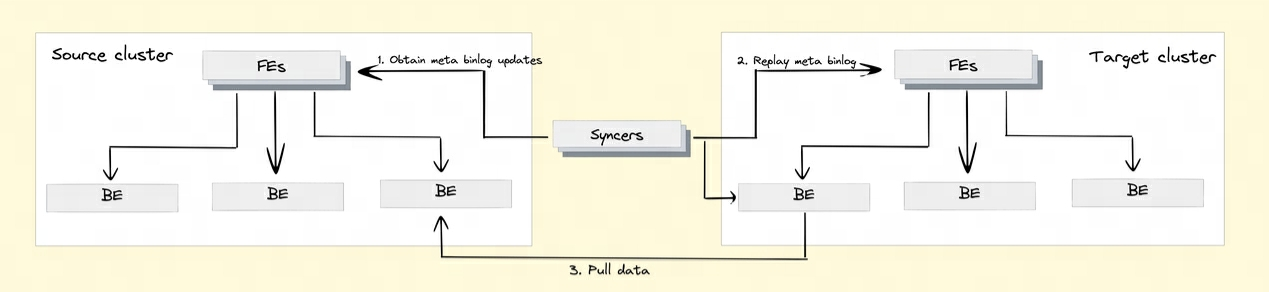
Вопрос 8. Как Doris реализует репликацию данных между кластерами?
Чтобы реализовать функцию репликации данных между кластерами, Дорис представил Binlog механизм。проходить Binlog механизм Автоматически записывает операции изменения данных для обеспечения прослеживаемости данных, а также основе Binlog Механизм воспроизведения для восстановления данных при воспроизведении.
Как записывается Бинлог?
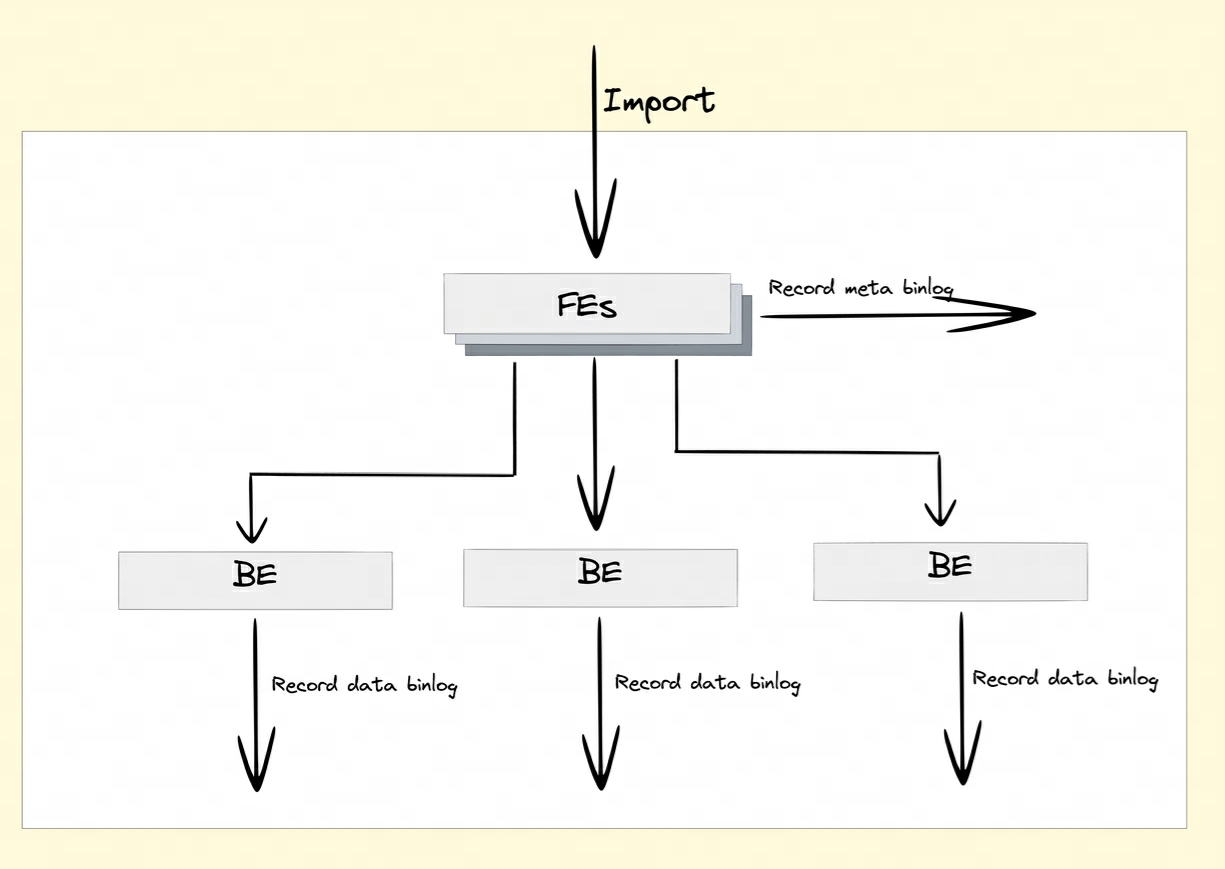
Открытие Binlog После атрибутов FE и BE воля DDL/DML Запись об изменении операции сохраняется в Meta Binlog и Data Binlog。
- Meta Binlog:Doris верно EditLog Реализация была улучшена для обеспечения упорядоченности журналов. Построить по возрастанию LogID, да, каждая операция точно записывается, и да соответствии с Последовательное постоянство. Такое упорядоченное постоянство помогает обеспечить согласованность данных.
- Data Binlog:существовать FE инициировать Publish Transaction время, BE встречаосуществлятьверноотвечатьиз Publish Операция, Б.Э. воля на этот раз Transaction с участием RowSet из Метаданные записываются в
rowset_metaдляпрефиксиз KV и упорствовать в Meta В хранилище он будет импортирован после отправки. Segment Files Ссылка на Binlog папка.
Генерация бинлога:
Воспроизведение данных бинлога:
Вопрос 9. Таблица Дорис имеет несколько копий. Как обеспечить наличие нескольких копий на этапе записи? Существует ли концепция «главный-подчиненный»? Нужно ли возвращать успех записи после большинства?
- Doris BE из 3 Копировать Нет главного подчиненного из концепции, использовать Quorum Алгоритм гарантирует несколько копий записи.
- существуют процесс письма, FE будет судить каждого Tablet Превышено ли количество успешно записанных копий данных? Tablet Общее количество копий составляет половину, каждая по одной Tablet Количество успешно записанных данных и копий превышает Tablet Общее количество копий составляет половину (большинство из них успешные), тогда Commit Transaction завершается успешно и устанавливает статус транзакции для COMMITTED;COMMITTED Статус поверхности указывает на то, что данные успешно записаны, но данные еще не видны и необходимо продолжить изучение. Publish Version задача, после которой транзакцию невозможно откатить.
- FE Будет отдельная тема, правда Commit Успех Transaction осуществлять Publish Version,FE осуществлять Publish Version часвстречапроходить Thrift RPC К Transaction Связанныйвсе Executor BE Узел доставляет Publish Version Запросить, опубликовать Version Задачи каждая существует Executor BE Узел асинхронного исследования, импорт данных для генерации RowSet Изменение для видимых данных Версия.
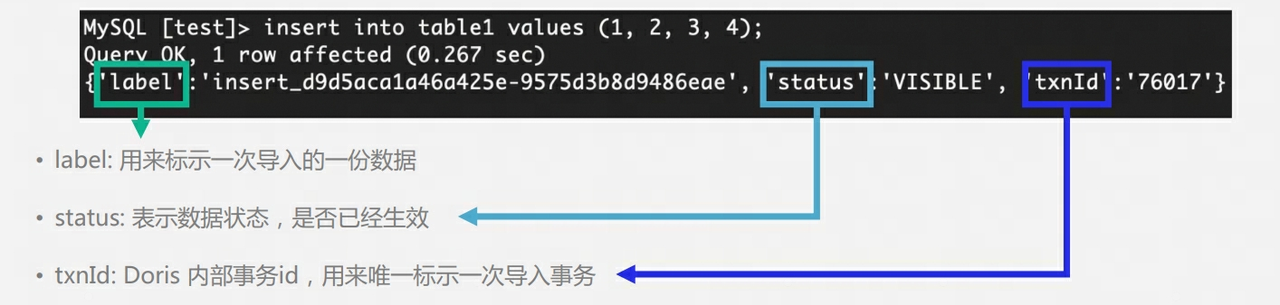
Почему здесь Publish механизм:добрыйпохожий В MVCC, если нет Publish механизм, пользователи могут читать данные, которые еще не были отправлены.
Если таблица 3 Копируй, пиши только успех 1 Что происходит с копией:этоткогдаделавстреча ABORTED
Если таблица 3 Копируй, пиши только успех 2 Что происходит с копией:этоткогдаделавстреча COMMITTED,Doris FE будет выполняться регулярно Tablet Мониторинг и проверка в случае обнаружения Tablet Копия ненормальна и будет генерировать Clone Задача, Клон Новый экземпляр.
Почему пользователь завершил выполнение Insert Into, немедленно выполните запрос, результат может быть пустым:причинада Дела еще Нет Publish
Вопрос 10. Как Doris FE обеспечивает высокую доступность?
На уровне метаданных Дорис использует протокол Paxos и механизм Memory + Checkpoint + Journal для обеспечения высокой производительности и высокой надежности метаданных.
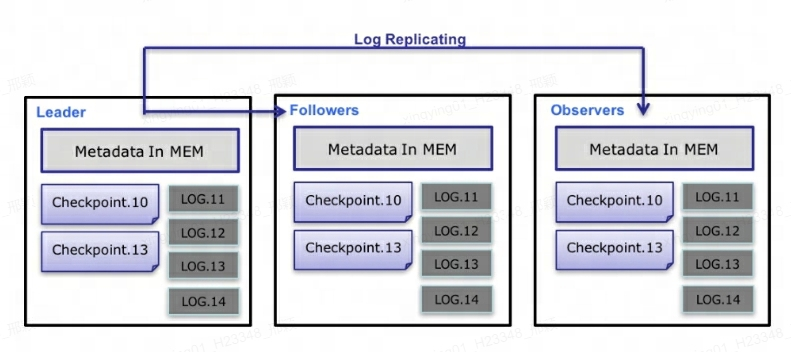
ЮаньданныеизданныепотокКонкретный процесс заключается в следующем:
- только Leader FE Можно ли записать метаданные. Операция записи существует, модифицирует Leader После загрузки памяти она выполнит последовательность действий для Log,в соответствии с Фото
key-valueиз формы письма БДБЖЕ. в Key для непрерывного из целого числа, как дляlog id,Value То есть последовательность для Список из журнала операций. - Запись журнала BDBJE После этого BDBJE В соответствии с политикой (записывать больше/записывать все) журнал будет отправлен другим Non-Leader из FE узел. Нелидер FE Узел осуществляет обратное воспроизведение журнала, модифицирует собственный образ памяти метаданных, завершает и Leader Узел синхронизации метаданных.
- Leader Количество журналов узлов достигает порогового значения (по умолчанию). 10w Статья) и удовлетворить Checkpoint Период изучения потока (по умолчанию шестьдесят секунд). Контрольно-пропускной пункт Буду читать уже из Image Файл, за которым следует журнал, воспроизводится в памяти для создания новой копии изображения метаданных. Эта копия затем записывается на диск для формирования нового Изображение. Вместо регенерации копии изображения запишите существующее изображение как Изображение, в основном рассматриваю возможность написания Image В период блокировки чтения операции записи будут заблокированы. так каждый раз Checkpoint Займет в два раза больше места в памяти.
- Image После создания файла Leader Узлы будут уведомлять другие Non-Leader Узел новый из Image Сгенерировано. Нелидер инициативапроходить HTTP Загрузите последние из Image файл для замены старого локального файла.
- Средний журнал BDBJE,существовать Image После завершения старые журналы будут регулярно удаляться.
объяснять:
- Метаданные обновляются каждый раз,Все сначала записывается на диск и в файлы журналов.,а затем записать это в память,Последний регулярный Checkpoint на локальный диск.
- Эквивалент чистой памяти и структуры,Другими словами, все метаданные будут кэшироваться в памяти.,Это гарантирует, что метаданные могут быть быстро восстановлены после прекращения существования FE.,И никакие метаданные не теряются.
- Leader、Follower и Observer Три из них надежны и предоставляют надежные услуги. При выходе из строя одной машины или узла трех из них на самом деле достаточно. FE В конце концов, узел хранит только одну копию метаданных, поэтому он не испытывает большой нагрузки, так если FE слишкомизкогдаэтовстреча Потреблять машинные ресурсы,так в большинстве случаев трех достаточно,Можно обеспечить высокодоступную службу метаданных.
- Пользователи могут использовать MySQL Подключите любой FE Узел выполняет доступ для чтения и записи метаданных. есликоннектизда Non-Leader узел, то операция записи узла перенаправляется на Leader узел.
Представление автора
Невидимый (Син Ин) Старший инженер ядра базы данных NetEase, после окончания учебы занимался разработкой ядра базы данных, в настоящее время в основном занимается MySQL и Apache Doris Разработка и сопровождениеи Поддержка бизнеса. для MySQL Участник ядра для MySQL Сообщено 50 несколько Bug и элементы оптимизации, несколько заявок были объединены MySQL 8.0 Версия. от 2023 Присоединяйтесь с Apache Doris Сообщество, Апач Doris Active Участник, отправил и объединил десятки Commits。



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
