На дворе 2023 год. Стоит ли нам по-прежнему использовать FSDP PyTorch для обучения больших моделей?

Волна обучения больших моделей, запущенная ChatGPT, вызвала у многих студентов желание попробовать обучение больших моделей. При поиске базовых показателей обучения они, должно быть, обнаружили, что базы кода для обучения больших моделей, как правило, используют DeepSpeed (MMEngine v0.8.0 также поддерживает). Удобно!, ColossalAI (MMEngine тоже будет поддерживать его в следующей версии!) и других фреймворков для обучения больших моделей, но нативный FSDP от PyTorch мало кого волнует. (FullyShardedDataParallel). Почему это? Неужели FSDP недостаточно для экономии видеопамяти? Скорость обучения слишком медленная? Или это бесполезно? Пожалуйста, наберитесь терпения и прочитайте эту статью, я верю, что вы что-то получите.
https://github.com/open-mmlab/mmengine
(Все могут использовать его. Если вы найдете его полезным, пожалуйста, зажгите звездочку)
Прошлая и настоящая жизнь ССДП
Реализация FSDP заимствована у FairScale. Когда PyTorch разрабатывает крупномасштабные функции, он обычно создает новую библиотеку для обеспечения некоторой поддержки проверки и сбора отзывов от пользователей. Это справедливо для FairScale, Dynamo (краеугольного камня PyTorch 2.0) и torchdistx. По мере развития этой функции она (возможно) будет объединена с PyTorch. По сравнению с официальным кратким введением PyTorch в FSDP в учебнике, FairScale явно работает лучше. Перед официальным введением я опубликую введение в FairScale. Возможно, вы захотите подумать, действительно ли вам нужен FSDP (другое крупномасштабное обучение). То же самое касается и рамок)
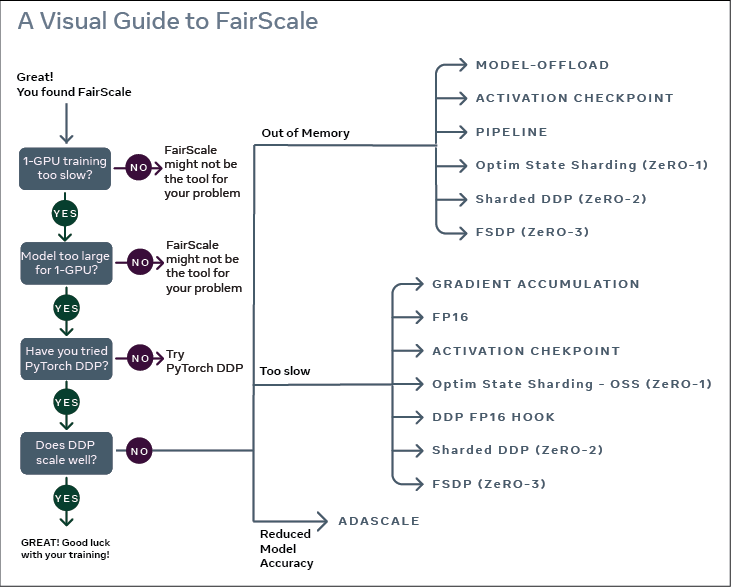
Введение в Зе РО
Студенты, которые видели картинку выше, обязательно обнаружат, что FairScale определяет FSDP как ZeRO3. Учитывая, что некоторые друзья могут быть не очень знакомы со стратегией оптимизации больших моделей серии ZeRO, вот краткое введение:
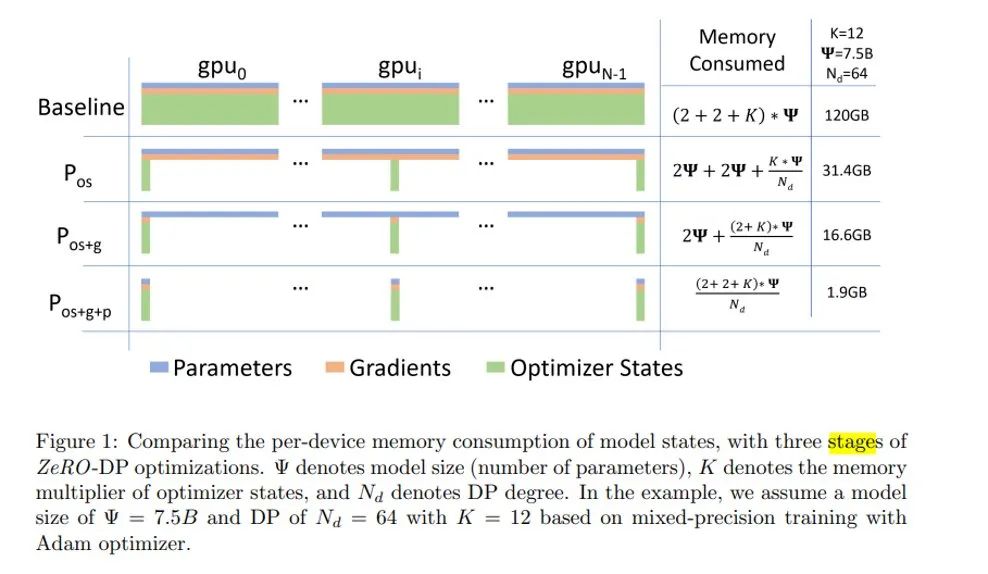
При обучении модели использование памяти можно грубо разделить на три части: значение активации, вес модели, градиент модели и состояние оптимизатора. Для визуальных моделей значения активации занимают наибольшую часть памяти, поэтому использование обучения смешанной точности может значительно снизить использование памяти для значений активации (fp16). Однако для больших языковых моделей или мультимодальных моделей оптимизация использования памяти последних трех более важна.
Если взять в качестве примера PyTorch, то при использовании DistributedDataParallel память фактически будет выделяться в каждом процессе для параметров модели, градиентов модели и состояния оптимизатора, и эти данные будут обновляться синхронно во время процесса обучения. Хотя этот подход может достичь цели ускорения обучения за счет параллелизма данных, его стратегия распределения памяти явно очень плоха. Поскольку параметры каждого процесса одинаковы, почему каждый процесс должен сохранять полные параметры? Поэтому ZeRO выступает за то, чтобы каждый процесс сохранял только часть параметров, а затем все собирал их в каждый процесс при использовании. ZeRO имеет трехэтапную стратегию оптимизации, а именно:
- ZeRO1: Шардируется только состояние сервера Пучокоптимизации
- ZeRO2:вернооптимизация Статус сервера + Градиентное шардинг
- ZeRO3: Статус счетчика + градиент + Параметры модели для шардинга
Взяв в качестве примера модель с параметрами 7,5 B (φ), давайте просто посчитаем использование памяти для параметров модели, градиентов модели и состояния оптимизатора:
обучение fp32:
Размер параметра модели — φ, его градиент — также φ, а в случае Адама состояние оптимизатора — 2φ. Если это обычное обучение fp32, фактическая занятая память равна (1 + 1 + 2)φ * 4: 16 φ байт (4 — размер памяти, занимаемый данными fp32);
тренировка fp16:
Если включено обучение смешанной точности, чтобы обеспечить точность обновления параметров, необходимо поддерживать состояние оптимизатора на уровне fp32. Кроме того, необходимо сохранить дополнительную копию параметров модели fp32, поэтому занятость видеопамяти составляет 2φ. (параметры модели) + 2φ (градиент модели) + 8φ (состояние оптимизатора) + 4φ (копия параметра модели fp32, реализация deepspeed хранится в оптимизаторе): 16φ байт.
С этой точки зрения, я думаю, вы сможете понять, почему модель 7.5B на картинке выше может занимать до 120B видеопамяти и почему серия ZeRO настолько эффективна.
FSDP - ZeRO3?
Более конкретно, FairScale сказал, что FSDP эквивалентен оптимизации ZeRO3, поэтому мы могли бы также прочувствовать это на простом примере (в этом примере оптимизатор выбирает SGD, потому что Адам из PyTorch проделал много оптимизации, и его фактическое использование памяти будет значительно выше теоретического). Перед формальным тестом давайте сначала посмотрим на тесты обучения fp32 с одной картой, обучения fp16 с одной картой и обучения DDP fp16:
Одна карта fp16 + fp32
class Layer(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Sequential(
*(nn.Linear(10000, 10000) for _ in range(10))
)
def forward(self, x):
return self.linear(x)
def test_fp32():
model = Layer().cuda()
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for i in range(10):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
print(f'step memory allocate: {memory / 1e9:.3f}G')
def test_fp16():
torch.cuda.init()
model = Layer().cuda()
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
with autocast(device_type='cuda'):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
print(f'memory allocated: {memory / 1e9:.3f}G')После запуска кода я обнаружил, что использование памяти выглядит следующим образом:
- fp32: 12.035G
- fp16: 14.035G
Что? усилок использование видеопамяти на 2G больше? Как это рассчитывается? Здесь нельзя не упомянуть реализацию усилителя. Усилитель PyTorch не меняет тип весов модели, то есть он по-прежнему сохраняется в fp32, но выбирает преобразование весов fp32 в fp16 до и после прямого обратного хода оператора белого списка для расчета значения активации fp16 и градиент fp16, где градиент fp16 будет дополнительно преобразован в fp32, чтобы обеспечить точность обновления параметров.
Но поскольку веса и градиенты по-прежнему сохраняют fp32, а состояние оптимизатора должно оставаться неизменным, зачем здесь лишний 2G? Причина в том, что веса fp16 для прямых и обратных операций кэшируются, и эта часть реализована в коде C++ amp. Кэшированный градиент fp16 является источником дополнительных 2G.
Чтобы сохранить эти параметры, вам необходимо передать в автокаст кэш_enabled=False.
def test_fp16():
torch.cuda.init()
model = Layer().cuda()
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
with autocast(device_type='cuda', cache_enabled=False):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
print(f'memory allocated: {memory / 1e9:.3f}G')Таким образом, потребление памяти 12.235G,Базовыйи fp32 Последовательно и в соответствии с ожиданиями.
Обучение DDP
DDP только создает и обновляет модели в каждом процессе. Использование памяти по-прежнему должно составлять 12 ГБ, верно?
def _test_ddp_fp16():
rank = dist.get_rank()
model = DistributedDataParallel(Layer().cuda())
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
with autocast(device_type='cuda', cache_enabled=False):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
if rank == 0:
print(f'memory allocated: {memory / 1e9:.3f}G')Однако результат:
16.036G
Принцип также очень прост. Когда ddp выполняет вычисление градиента и синхронизацию градиента, ему требуется сегмент (подробности см. в предыдущем описании DDP). В блоке будет храниться копия градиента, поэтому он будет потреблять около 4 ГБ дополнительно). видеопамять.
Обучение ФСДП
Когда мы используем FSDP, нам необходимо выбрать стратегию шардинга модели, настроив параметр auto_wrap_policy, иначе оптимизация памяти может достичь только уровня ZeRO-stage1. Как настроить auto_wrap_policy и соответствующие принципы будут подробно описаны в последующих главах.
from torch.distributed.fsdp.wrap import _module_wrap_policy
def _test_fsdp_fp16():
rank = dist.get_rank()
fsdp_model = FullyShardedDataParallel(
module=Layer(), device_id=rank,
auto_wrap_policy=partial(
_module_wrap_policy,
module_classes=nn.Linear))
optimizer = SGD(fsdp_model.parameters(), lr=0.1, momentum=0.9)
data = torch.ones(10000).cuda()
for _ in range(10):
optimizer.zero_grad()
output = fsdp_model(data)
loss = output.sum()
loss.backward()
optimizer.step()
memory = max_memory_allocated()
if rank == 0:
print(f'step memory allocate: {memory / 1e9:.3f}G')
torch.cuda.reset_max_memory_allocated()Результат — 1,524 ГБ, а использование памяти в основном эквивалентно эффекту оптимизации ZeRO3.
Причина, по которой мы провели этот анализ использования памяти, состоит в том, чтобы надеяться, что каждый сможет рационально взглянуть на оптимизацию видеопамяти при переключении с DDP на FSDP.
Стратегия шардинга FSDP
В предыдущей главе мы упоминали, что нам нужно указать стратегию сегментирования модели через auto_wrap_policy, так как же работает этот параметр? И почему без этого параметра эффект оптимизации может достичь только ZeRO-этапа1.
Подобно DistiributedDataParallel, FSDP также реализует логику разделения параметров через оболочку модели: FullyShardedDataParallel. Обернутая модель станет корневым модулем fsdp, и когда корневой модуль fsdp будет построен, он рекурсивно обернет подмодуль в дочерний модуль fsdp в соответствии с определенной пользователем auto_wrap_policy:
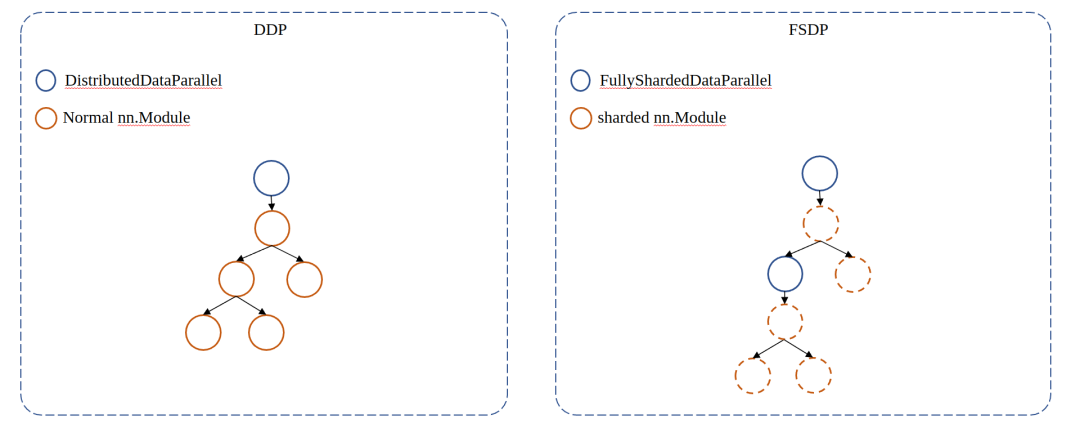
Если взять в качестве примера официально реализованную _module_wrap_policy, то ключевой параметр module_classes используется для указания того, какой тип подмодуля должен быть обернут в дочерний модуль fsdp.
def _module_wrap_policy(
module: nn.Module,
recurse: bool,
nonwrapped_numel: int,
module_classes: Set[Type[nn.Module]],
) -> bool:
"""
This auto wrap policy wraps every module that is an instance of any type in
``module_classes`` as its own FSDP instance. The root module given by
``module`` is always wrapped as an FSDP instance regardless. Since the
wrapping proceeds bottom up, each FSDP instance manages the parameters in
its subtree excluding any already managed by a child FSDP instance.
Args:
module (nn.Module): Current module being considered.
recurse (bool): If ``False``, then this function must decide whether
``module`` should be wrapped as an FSDP instance or not. If
``True``, then the function is still recursing down the module
tree as a part of the DFS.
nonwrapped_numel (int): Parameter numel not yet wrapped.
module_classes (Set[Type[nn.Module]]): Set of module classes that are
wrapped as FSDP instances.
Returns:
``True`` if ``recurse=True``, and whether ``module`` should be wrapped
if ``recurse=False``.
"""
if recurse:
return True # always recurse
if inspect.isclass(module_classes):
module_classes = (module_classes, )
return isinstance(module, tuple(module_classes))В предыдущей главе мы указали его как nn.Linear, что означает, что каждый nn.Linear будет заключен в дочерний модуль fsdp.
Все модули fsdp запускают параметры unshard (всех сборок) и shard во время процесса пересылки.
1. Переадресация корневого модуля fsdp будет собирать параметры различных процессов на этапе предварительной пересылки и регистрировать некоторые перехватчики pre-backward и post-backward-hook. Затем на этапе пост-пересылки освобождаются параметры, не принадлежащие текущему рангу.
Среди них pre-backward-hook снова собирает параметры перед выполнением в обратном направлении, а post-backward-hook отвечает за реализацию уменьшения-разброса градиента, то есть синхронизацию градиента + распределение градиента.
Следует отметить, что fsdp-module forward не будет дополнительно собирать параметры дочернего модуля fsdp.
По сравнению с дочерним модулем fsdp, перенаправление корневого модуля fsdp также будет выполнять некоторую дополнительную инициализацию потока cuda и другую работу, и никаких дополнительных расширений здесь выполняться не будет.

2. дочерний модуль fsdp из вперед
Основная логика в основном такая же, как у корневого модуля fsdp.
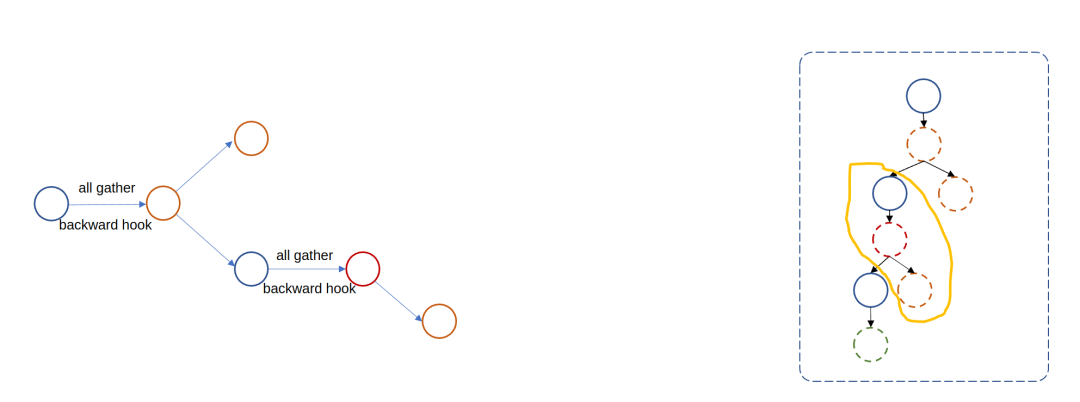
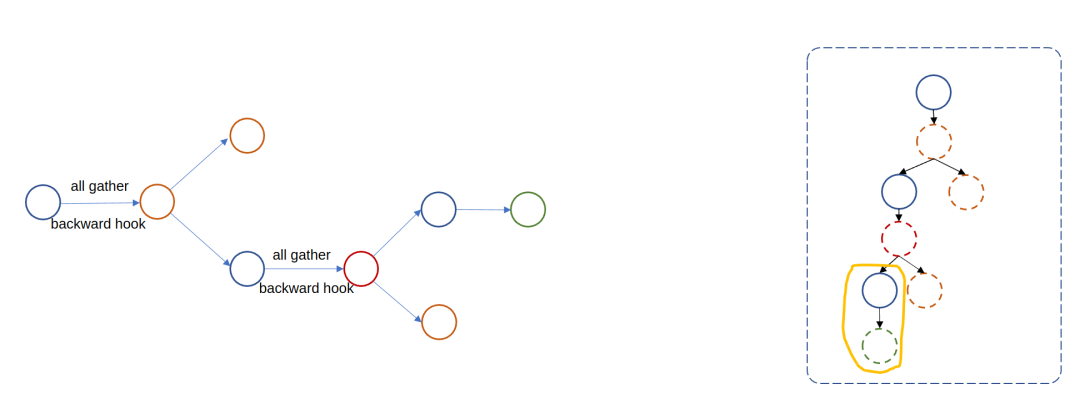
Видно, что модуль fsdp каждый раз собирает только некоторые параметры, что соответствует нашим ожиданиям. Так что же произойдет, если мы не установим auto_wrap_policy? То есть дочернего модуля fsdp нет.
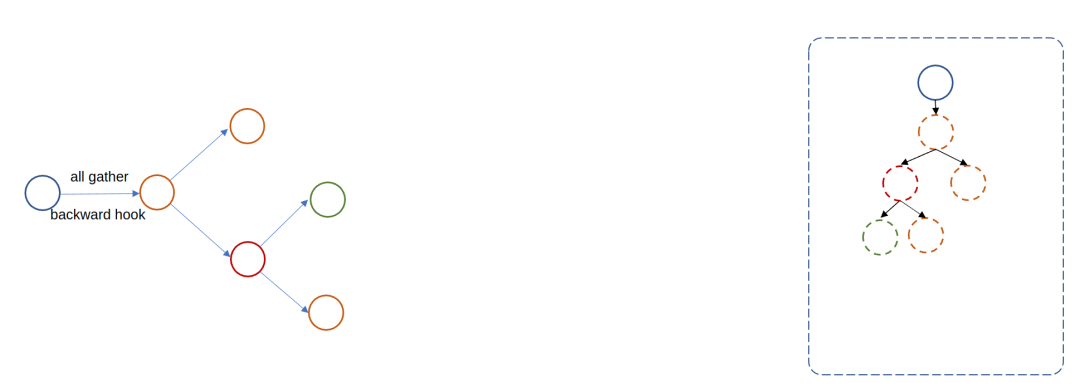
На переднем этапе корневой модуль fsdp будет собирать все параметры напрямую, а это означает, что невозможно сэкономить видеопамять путем сегментирования параметров в ZeRO-stage3. Однако сегментирование градиентов и состояний оптимизатора по-прежнему возможно в ZeRO1 и ZeRO2. Причина в том, что прямая фаза по-прежнему будет регистрировать пост-обратный хук, поэтому логика уменьшения-разброса градиента все равно будет работать. При построении оптимизатора передаются параметры корневого модуля fsdp, поэтому оптимизатор будет напрямую обновлять фрагментированные параметры и записывать состояние фрагментированных параметров, поэтому оптимизация состояния фрагментированного оптимизатора также эффективна.
auto_wrap_policy должен соответствовать определенным спецификациям интерфейса и принимать следующие параметры:
- модуль: модуль, доступ к которому осуществляется при рекурсивном обходе подмодуля.
- рекурсия: после определения того, что подмодуль является дочерним модулем fsdp, следует ли в дальнейшем рекурсивно определять, нужно ли обертывать подмодуль подмодуля в дочерний модуль fsdp.
- nonwrapped_numel: Значение этого параметра — количество параметров текущего модуля, которые не нужно фрагментировать. Какие параметры не нужно фрагментировать? Вообще говоря, он содержит две части, а именно фрагментированные параметры и параметры, указанные пользователем, которые необходимо игнорировать (ignored_params). На основе этого параметра можно реализовать политику переноса на основе размера, например официально реализованную size_based_auto_wrap_policy.
FSDP дает пользователю право настраивать параметр auto_wrap_policy. Хотя масштабируемость улучшается, это также незаметно увеличивает стоимость обучения FSDP. Например, какую роль играет auto_wrap_policy и каковы значения нескольких его входных параметров? Члены ССДП неизбежно почувствуют это в замешательстве.
Однако, если стоимость использования FSDP ограничивается этим, я считаю, что все по-прежнему готовы его изучить и использовать. Однако некоторые неявные соглашения и некоторые странные отчеты об ошибках очень обескураживают.
ФСДП кровь и слезы проб и ошибок
Риски замены субмодуля
В предыдущей главе мы упоминали, что fsdp заменит подмодуль дочерним модулем fsdp после упаковки. Вы можете быть удивлены, увидев это. Если мой родительский модуль обращается к некоторым атрибутам или методам подмодуля, то подмодуль заменяется модулем fsdp. . Не вызовет ли это ошибку атрибута? В этом случае FSDP ловко перегружает метод __getattr__:
def __getattr__(self, name: str) -> Any:
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self._fsdp_wrapped_module, name)Таким образом, для неопределенных атрибутов они будут найдены в подмодуле. Однако при этом все еще существуют риски.
- Если атрибут, к которому вы обращаетесь, имеет то же имя, что и атрибут самого дочернего модуля fsdp, вы можете получить неверный атрибут.
- Если вы напрямую получаете доступ к параметрам подмодуля и выполняете над ним некоторые операции. Поскольку параметр собирается на предварительном этапе, то, что вы непосредственно получаете на этом этапе, является фрагментированным параметром, и существует высокая вероятность того, что будет сообщено об ошибке.
- Если вы не вызвали метод __call__ дочернего модуля fsdp напрямую, например:
class Layer(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.processor = nn.Linear(1, 1)
self.linear1 = nn.Linear(1, 1)
self.linear2 = nn.Linear(1, 1)
def forward(self, x):
return self.linear1(x) + self.linear2(x)
class ToyModel(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.linear = nn.Linear(1,1)
self.layer = Layer() # встречаодеяло auto wrap policy обозначениедля child fsdp module
def forward(self, x):
y = self.linear(self.layer.processor(x))
return self.layer(y)Предположим, что слой заключен в модуль fsdp. Поскольку пересылка self.layer.processor вызывается напрямую в ToyModel.forward, поскольку в этот момент пересылка слоя не запускается, параметры в Layer.precessor все еще находятся в рабочем состоянии. выделенное состояние Сообщить об ошибке.
Другой пример – такая ситуация:
class A:
...
def loss(self, inputs: torch.Tensor, data_samples: List[DataSample]) -> dict:
feats = self.extract_feat(inputs)
return self.head.loss(feats, data_samples)
class B:
...
def loss(self, feats: Tuple[torch.Tensor], data_samples: List[DataSample], **kwargs) -> dict:
cls_score = self(feats) # Не ушел FSDP из forward
losses = self._get_loss(cls_score, data_samples, **kwargs)
return lossesПредположим, что тип self.head в классе A является классом B и заключен в дочерний модуль fsdp. Тогда при выполнении self.head.loss потеря класса B будет найдена непосредственно через метод __getattr__ FSDP. В этот момент локальная переменная self уже является экземпляром класса B, а не FSDP, поэтому она не будет выполнена. когда self(feats) Ввод вперед FSDP запускает сбор всех параметров, что в дальнейшем вызывает ошибку.
Оптимизатор для нескольких групп параметров
Оптимизатор PyTorch поддерживает настройку различных гиперпараметров, таких как скорость обучения и импульс, для разных параметров модели. Процесс установки, вероятно, выглядит так:
param_groups = []
for module in model.modules():
if isinstance(module, nn.BatchNorm2d):
param_groups.append({'param': module.weight, lr=0.01})
param_groups.append({'param': module.bias, lr=0.1})
elif:
optimizer = SGD(param_groups, lr=0.1)Однако проблема существования заключается в том, что,До PyTorch 2.0,После получения root-доступа к модулю fsdp,child fsdp module После завершения сборки исходные параметры, такие как миллиарды весов, миллиарды смещений, в свою очередь fsdp module Все неразрезанные параметры преобразуются в один большой flatten параметры. Например, если в предыдущей главе example , если не указано auto_wrap_policy, то сохранится только самый внешний слой root fsdp модуль. тогда все linear слоистый parameters будут объединены в один большой flatten параметры, вставьте root_fsdp_module Вниз:
rank = dist.get_rank()
fsdp_model = FullyShardedDataParallel(
module=Layer(), device_id=rank,
# auto_wrap_policy=partial(
# _module_wrap_policy,
# module_classes=nn.Linear),
)
print(list(fsdp_model.parameters()))В настоящее время для каждого ранга будет распечатан только один параметр:
[Parameter containing:
Parameter(FlatParameter([-4.6519e-05, -6.2861e-03, 3.9519e-03, ..., -3.2763e-03,
7.1111e-04, -8.2136e-03], device='cuda:3', requires_grad=True))]Поэтому в PyTorch 2.0 раньше, когда-то использовался FSDP, сложно установить разные скорости обучения для каждого параметра, потому что fsdp wrap Несколько параметров будут объединены в один параметр. после gradient Обновления сегментов и параметров также основаны на flatten tensor достичь.
Поскольку обновление параметров также реализовано на основе сглаживания тензора, FSDP требует, чтобы параметры, атрибуты dtype и require_grad в каждом модуле fsdp были унифицированы, в противном случае его невозможно объединить в большой сплющенный тензор.
В PyTorch 2.0 в FSDP добавлен параметр use_orig_params. Когда этот параметр включен, исходные параметры не будут удалены в процессе переноса FSDP, но память исходных параметров будет указывать на определенную область сглаживания параметров. Это отличное обновление, которое позволяет пользователям по-прежнему получать доступ к параметрам перед сегментированием и устанавливать различные гиперпараметры оптимизатора без дополнительного потребления графической памяти. После введения этого параметра само собой разумеется, что ограничение на единый атрибут require_grad для всех параметров модуля fsdp также должно быть снято. К сожалению, PyTorch 2.0 не скорректировал эту часть логики. Однако эта проблема была исправлена. основная ветка, я думаю, скоро будет выпущена. Грядущий PyTorch 2.1 сможет решить эту проблему.
Стабильность интерфейса для FSDP
Хотя FSDP был бета-функцией еще в PyTorch 1.11, по сей день модуль FSDP все еще находится в состоянии быстрой итерации. Разработчики FSDP также начали обсуждение в феврале 2023 года, представив некоторые концепции дизайна и внутреннюю реконструкцию.
Кроме того, внешние интерфейсы FSDP также обновляются относительно быстро. Если вы откроете документ API PyTorch FSDP, вы обнаружите, что многие интерфейсы помечены устаревшей меткой. Но в целом новый интерфейс действительно намного проще в использовании и более гибок, чем старый интерфейс. Интеграция FSDP в MMEngine на этот раз также разработана на основе нового интерфейса.
Подвести итог
- FSDP В плане экономии видеопамяти эффект действительно тот же, что и ZeRO3 Эквивалентно, но следует отметить, что обороты существуют на смешанной точности, тренироваться (автоприведение) из случая, когда требуется Пучок. cache_enabled установлен на Flase。
- С точки зрения простоты использования, FSDP имеет относительно высокую стоимость начала работы. Пользователям необходимо понимать логику модуля переноса FSDP, роль auto_wrap_policy и некоторые ограничения. Если вы недостаточно знакомы с логикой и ограничениями самого FSDP и структурой модели, могут возникнуть ошибки, а сообщение об ошибке не будет тесно связано с реальной причиной ошибки, что затрудняет отладку.
- PyTorch 2.0 значительно упрощает использование FSDP благодаря параметру use_ori_params, но ограничение на унификацию атрибутов require_grad все еще существует. Чтобы решить эту проблему, дождитесь обновления PyTorch 2.1 и укажите use_orig_params=True. Но если вам нужно временное решение, вам нужно внести некоторые изменения в auto_wrap_policy. Поскольку это модификация, основанная на внутреннем протоколе FSDP, она может быть не очень стабильной, поэтому я не буду здесь вдаваться в подробности.
В целом, ФСДП Это действительно неудовлетворительно с точки зрения простоты использования, но с точки зрения гибкости оно оставляет пользователям больше возможностей для работы. Однако я считаю, что с учетом этого. PyTorch Я считаю, что непрерывная итерация FSDP постепенно станет более гармоничным DDP Так же полезно. MMEngine Также буду внимательно следить FSDP Обновляйте тенденции, сохраняйте гибкость существования и старайтесь максимально снизить порог пользователя. Итог предлагает набор простых и удобных в настройке лучших практик.
Если вам интересно, вы можете нажать на дополнительные обновления. Если у нас будет возможность, мы можем дополнительно поговорить о концепции дизайна FSDP, логике построения параметров сглаживания, правилах нарезки параметров и параллельном методе расчета градиента. синхронизация градиента в FSDP. Давайте поговорим о том, как бороться с ошибкой, выдаваемой FSDP на протяжении 300 раундов (надеюсь, PyTorch сможет сэкономить несколько раундов после обновления).
Что, вы все еще хотите увидеть комплексный анализ DeepSpeed, ColossalAI и FSDP? MMEngine также поддерживает DeepSpeed в версии v0.8.0. Мы также представим DeepSpeed в следующий раз. Вы можете уделить больше внимания MMEngine и нажать на звездочку. Я верю, что в ближайшем будущем вы сможете свободно переключаться между FSDP, DeepSpeed и ColossalAI с помощью всего нескольких строк кода и ощутить преимущества и недостатки различных. рамки обучения самостоятельно.
https://github.com/open-mmlab/mmengine
(Все могут использовать его. Если вы найдете его полезным, пожалуйста, зажгите звездочку)

5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API

Весенние аннотации: подробное объяснение @Service!
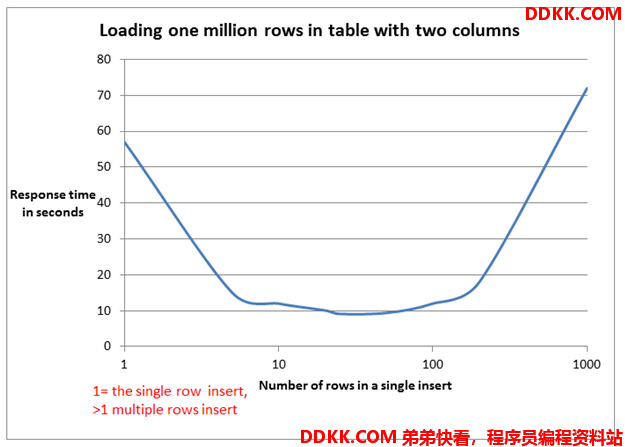
Пожалуйста, не используйте foreach для пакетной вставки в MyBatis. Для 5000 фрагментов данных потребовалось 14 минут. .

Как создать проект Node.js с помощью npm?
Mybatis-plus использует typeHandler для преобразования объединенных строк String в списки списков.

Не удалось установить программное обеспечение Mitsubishi. Возможно, возникла проблема с реестром.

Разрешение ошибок проекта SpringBoot 3 mybatis-plus: org.apache.ibatis.binding.BindingException: неверный оператор привязки
Более краткая проверка параметров. Для проверки параметров используйте SpringBoot Validation.

Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!

HTML можно преобразовать в word_html для отображения текстовых документов.
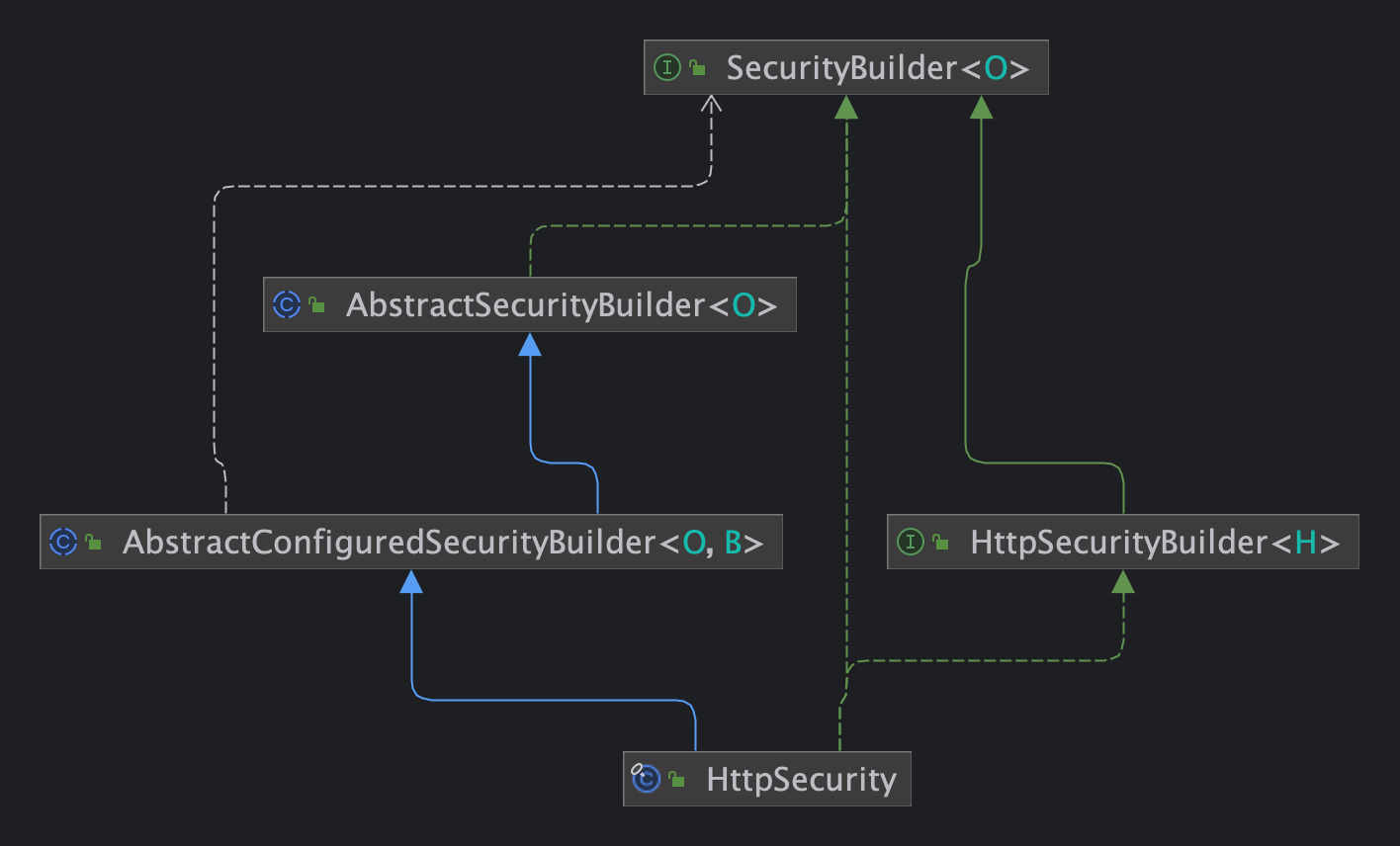
Статья Spring Security 6.x для быстрого понимания принципов настройки
Не забудьте изменить имя каждого модуля RUOYI один раз, чтобы избежать мошенничества ~~~
Научите вас шаг за шагом, как интегрировать систему обслуживания клиентов Hunyuan AI Q&A от 0 до 1.

Подробное объяснение Gzip: принципы и применение алгоритмов сжатия.
