Мысли об архитектуре системы ChatBI
Custom BI изменил эпоху традиционной разработки фиксированных отчетов под руководством ИТ-специалистов, позволяя анализировать данные по мере необходимости и получать то, что вы видите. С ростом популярности крупных моделей компании LLM объединяют технологию визуализации данных, чтобы обеспечить работу системы. интеллект и данные должны быть интегрированы с помощью методов вопросов и ответов. Взаимодействие и создание диаграмм, будь то BI-второй пилот или ChatBI, в дополнение к замене предыдущей функции помощника, которая может запрашивать только существующие данные отчета, и, что более важно, она исключает перетаскивание. и отбросить операцию создания информационной панели, чтобы вновь созданные диаграммы можно было сравнить с существующими или новыми инновационными информационными панелями.
1. Основные соображения по поводу идей реализации
1. Если большой модели нет или служба больших моделей не работает, можно ли реализовать автоматическое создание визуальной инженерии? —— Прямое разделение, большие модели не могут повлиять на основной проект, а большие модели не могут быть созданы для диаграмм. 2. Если обычный сервис большой модели может делать выводы, должны ли все вопросы и ответы проходить через сервис вывода? —— Насколько надежны и стабильны рассуждения больших моделей и сколько времени требуется на ответ? 3. Поддержка компонентов с взаимодействием SQL в качестве ядра отвечает требованиям доступности производства посредством систематического проектирования. Учитесь у[SQLChat](https://github.com/sqlchat/sqlchat), [DB-GPT](https://github.com/csunny/DB-GPT), Идея проекта с открытым исходным кодом заключается в том, чтобы взять за основу генерацию SQL, взаимодействовать с базой данных для получения данных и использовать данные. + Реализован в виде визуальных компонентов диаграммы. Независимо от того, как автоматически генерировать диаграммы для больших моделей, основными соображениями являются: во-первых, красота, во-вторых, гибкость и, в-третьих, самое главное, можно ли контролировать производительность, особенно когда большое количество данных запроса велико, есть ли пейджинг и т. д. . можно контролировать вручную с помощью человека. Полагаться на большие модели для автоматического создания диаграмм, подобных markdown/html, вероятно, не очень рационально.
2. Основная структура мышления
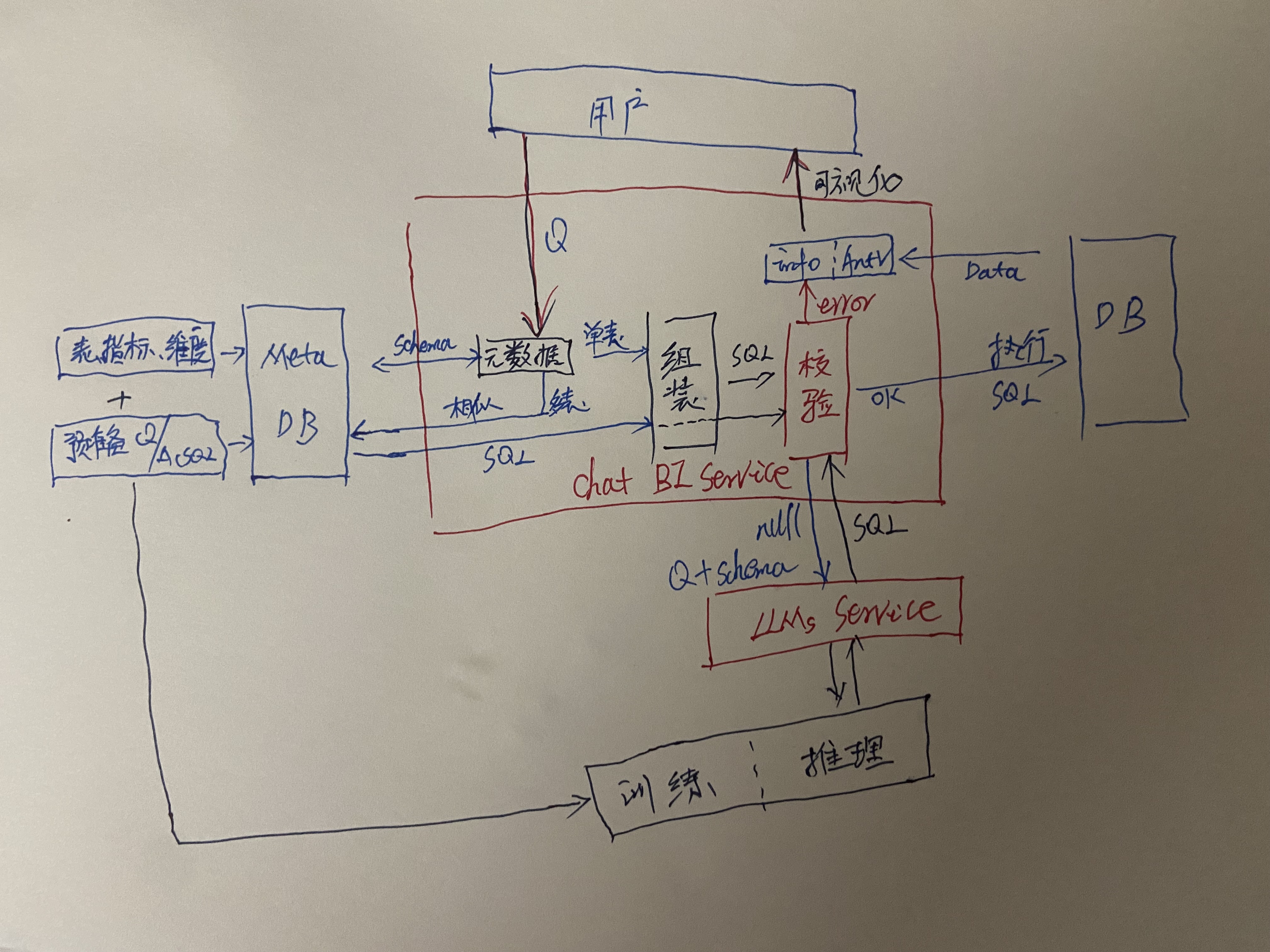
4. Описание
1. Ли ${input_dim_conditions} <= ${user_has_permission}, если нет, напрямую сообщить о недостаточном разрешении; 2. Если измерения и меры взяты из таблицы, проанализируйте условия запроса, а затем соберите шаблон SQL:
select ${input_dim_names} , ${input_metric_names} from ${get_meta_table_name} where ${input_dim_conditions} [group by $s] [order by $s];3. Если измерения и меры взяты из нескольких таблиц, найдите ответы на схожие совпадающие вопросы Sql: ①. Если имеется соответствующий sql, примените его напрямую. Единственное, что можно собрать, — это условие sql; ② Если есть похожие sql, например, если вы хотите найти шаблон sql для объединения 2 таблиц, вам нужно добавить метод подзапроса и склеить его, то есть.
select ${input_dim_names} , ${input_metric_names} from ( ${get_query_sql} ) TT where ${input_dim_conditions} [group by $s] [order by $s];Хотя здесь обычно все в порядке, все механизмы SQL поддерживают принудительное удаление предикатов, но несколько столбцов в подзапросе могут повлиять на производительность, и не все механизмы SQL поддерживают сокращение столбцов. В то же время обратите внимание, что если это объединение двух таблиц, вы не можете найти оператор SQL для объединения трех таблиц для их объединения. ③ Если sql имеет значение null или ошибка проверки, Затем оставьте это большой модели для вывода и верните вывод для генерации sql. Вся структура может иметь недостатки, но я считаю, что со временем большие модели станут более стабильными, надежными и отзывчивыми. И подразделение SQL Рождение LLM Я также верю, что альтруистические разработчики с открытым исходным кодом породят лучшие проекты ChatBI;



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
