Модель контроля рисков: подробное объяснение индекса стабильности PSI (Python)
В контроле риска риск означает неопределенность. Чем сильнее неопределенность, тем более она неконтролируема. То же самое справедливо и для контроля рисков на основе данных. заключается в постоянном повышении вероятности наших шансов на победу. Конечно, никто не может быть уверен на 100%, потому что ни у кого нет Божьей точки зрения, поэтому всегда будут неправильные убийства или ошибки в процессе принятия решений по контролю рисков.
Это понимание контроля рисков на макроуровне.,Уменьшить масштаб до модели управления ветром,То же самое. Персонал по контролю рисков может быть больше озабочен индикаторами оценки, такими как фокус на эффекте AUC/KS при выполнении Модели.,Эффект превосходит все. Но на самом деле для Модели,Стабильность важнее производительности。из-за одного Модель Цикл разработки не короткий,И его будет нелегко заменить после того, как он появится в сети.,Другими словами, то, что мы делаем, не является высокочастотной вещью. Если модель нестабильна,Несмотря на то, что эффект в автономном режиме лучше, стабильность в Интернете оставляет желать лучшего.,Тогда это будет фатальным для всего результата принятия решений по управлению рисками.,Потому что в это время вы не можете гарантировать высокую вероятность выигрыша.
В этой статье будут представлены концепция и понимание индекса стабильности PSI в управлении рисками, а также способы проведения наблюдений за стабильностью точек модели и переменных, введенных в модель после запуска модели A-card.
Понимание PSI
Как специалист по управлению рисками, я считаю, что мне знаком показатель IV. Он может отражать информационную ценность переменной или пониматься как степень корреляции с целевой переменной, которая является показателем качества. переменной.
Если вы старый специалист по контролю рисков,Вы обнаружите, что формулы расчета индикаторов PSI и IV очень похожи.,Потому что суть обоих одинакова,ВсеВычислить расстояние между двумя распределениями。
PSI измеряет стабильность и надеется, что два распределения максимально близки, в то время как IV измеряет различительную способность переменных и надеется, что два распределения находятся как можно дальше друг от друга.
Итак, как только вы это поймете, формулы расчета PSI и IV станут довольно простыми для понимания.
Это PSI, что означает население. Stability Index)。Так Логика расчета PSIКаково это??
Логика расчета PSI
мы говорим о рейтинге модели Стабилизировать,Обычно относится кРаспределение оценок модели стабильно во времени.。Из этого можно сделать вывод Модель Должно быть стартовое распределение очков.,Затем с течением времени разница между распределением каждого периода времени и начальным распределением.
Точнее, для расчета устойчивости PSI требуется ссылка. Требуются два распределения: одно — фактическое (фактическое), а другое — ожидаемое (ожидаемое).
Шаги логики расчета PSI следующие:
step1:Воляпеременнаяожидаемое распределение(excepted)группирование(binning)дискретизация,статистика Доля образцов в каждом контейнере. Уведомление:
- a) Объединение может осуществляться по равной частоте, по равному расстоянию или другими методами. Различные методы объединения приведут к несколько различным результатам расчета;
- б) Для непрерывной переменной (собственная переменная、оценка моделиждать),Количество контейнеров должно быть установлено соответствующим образом.,Обычно устанавливается на 10 или 20 для дискретной переменной;,Если группировок слишком много, вы можете заранее рассмотреть возможность объединения небольших группировок;,Это может привести к тому, что размер выборки в каждой ячейке станет слишком маленьким, а количество ячеек может потерять смысл;,Это также приведет к снижению точности результатов расчетов.
step2: По одному и тому же интервалу интервала рассчитывается доля выборок в каждом интервале для фактического распределения (фактического). step3:считать Вычислите A в каждой ячейке - EwaLn(A / E), рассчитать индекс = (Фактическая доля - Ожидаемая доля)* ln(Фактическая доля / ожидаемая доля) 。 step4: Суммируйте индексы каждого интервала, чтобы получить окончательный PSI. Цитата: https://zhuanlan.zhihu.com/p/79682292
Ниже приведен пример результатов процесса расчета.
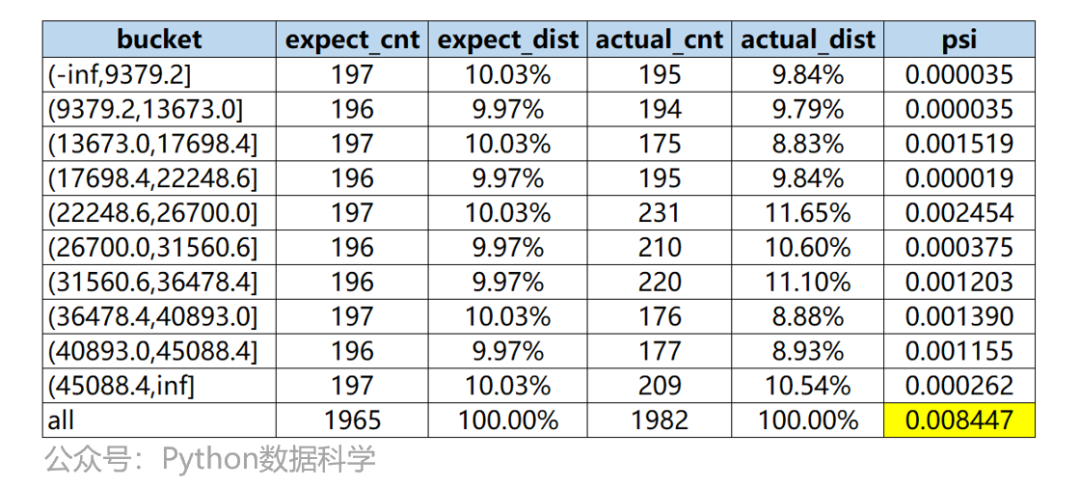
Сценарии использования PSI
Фактическое и ожидаемое распределение PSI различны в разных сценариях и типах.
Если разделить по сценариям использования, то можно выделить следующие три этапа:
- во время моделирования:Возьмите обучающие выборки какожидаемое распределение,Используйте набор тестов или выборки с течением времени (OOT) в качестве фактического распределения.
- Оттенки серого онлайн:Возьмите образцы автономного моделирования какожидаемое распределение,Используйте текущий образец в оттенках серого в качестве фактического распределения.
- Официально запущен:Возьмите образец первого месяца после выхода в Интернет, какожидаемое распределение,Возьмите ежемесячную выборку после разделения первого месяца на фактическое распределение.
Если разделить по типу, то есть два типа: модельные и формованные переменные:
- оценка модели:верно Модель Вывод вероятностного результата или дробного результата осуществляетсяPSIСтабилизироватьсекс-тест,Сценарии использования могут быть указанными выше тремя.
- значение переменной:верно Положить в формупеременнаяруководитьPSIСтабилизироватьсекс-тест,Сценарии использования также соответствуют трем вышеперечисленным.
Например, если модель была официально запущена, то из отчетов мониторинга мы обнаружили, что в последнее время процент успешных попыток растет. Такие колебания или аномалии указывают на то, что модель может разрушаться, а результаты могут отклоняться. Чтобы проверить нашу гипотезу, нам необходимо ежемесячно рассчитывать индекс стабильности PSI модели.
В целом, эталонные значения показателей стабильности PSI следующие:
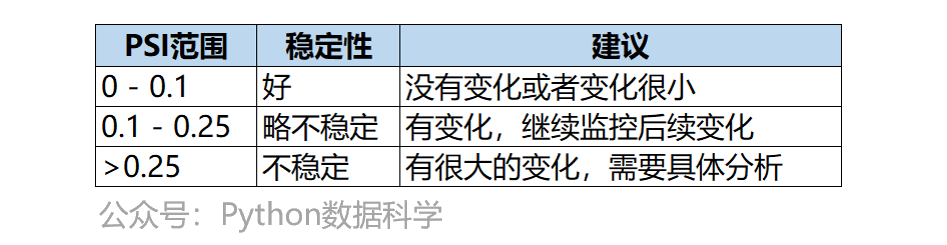
Практика Python от PSI
Ниже мы используем код Python, чтобы попрактиковаться в расчете индикатора PSI и ежемесячном расчете индикатора PSI. Это два наиболее часто используемых применения PSI, и для завершения расчета параметры можно напрямую заменить.
Ниже приведена функция расчета PSI. Для параметров требуется список ожидаемого и фактического распределения. Кроме того, вы можете установить количество группировок (по умолчанию — 10) и минимальное количество выборок (по умолчанию — 10).
df = pd.read_csv('../0-data/var_sample.csv')
def calculate_psi(base_list, test_list, bins=10, min_sample=10):
# Малый круг контроля рисков @Брат Донг
try:
base_df = pd.DataFrame(base_list, columns=['score'])
test_df = pd.DataFrame(test_list, columns=['score'])
# 1. После удаления пропущенных значений размеры выборки двух распределений
base_notnull_cnt = len(list(base_df['score'].dropna()))
test_notnull_cnt = len(list(test_df['score'].dropna()))
# Пустой разделитель
base_null_cnt = len(base_df) - base_notnull_cnt
test_null_cnt = len(test_df) - test_notnull_cnt
# 2. Минимальное количество бункеров
q_list = []
if type(bins) == int:
bin_num = min(bins, int(base_notnull_cnt / min_sample))
q_list = [x / bin_num for x in range(1, bin_num)]
break_list = []
for q in q_list:
bk = base_df['score'].quantile(q)
break_list.append(bk)
break_list = sorted(list(set(break_list))) # Сортировка после удаления дубликатов
score_bin_list = [-np.inf] + break_list + [np.inf]
else:
score_bin_list = bins
...
# 5. Обобщить результаты статистики
stat_df = pd.DataFrame({"bucket": bucket_list, "base_cnt": base_cnt_list, "test_cnt": test_cnt_list})
stat_df['base_dist'] = stat_df['base_cnt'] / len(base_df)
stat_df['test_dist'] = stat_df['test_cnt'] / len(test_df)
def sub_psi(row):
# 6. Рассчитать фунт на квадратный дюйм
base_list = row['base_dist']
test_dist = row['test_dist']
# Обработайте ситуацию, когда размер выборки в определенном интервале равен 0.
if base_list == 0 and test_dist == 0:
return 0
elif base_list == 0 and test_dist > 0:
base_list = 1 / base_notnull_cnt
elif base_list > 0 and test_dist == 0:
test_dist = 1 / test_notnull_cnt
return (test_dist - base_list) * np.log(test_dist / base_list)
stat_df['psi'] = stat_df.apply(lambda row: sub_psi(row), axis=1)
stat_df = stat_df[['bucket', 'base_cnt', 'base_dist', 'test_cnt', 'test_dist', 'psi']]
psi = stat_df['psi'].sum()
except:
print('error!!!')
psi = np.nan
stat_df = None
return psi, stat_df
Например, теперь мы хотим рассчитать стабильность единственной переменной LoanAmount, используя май в качестве ожидаемого распределения и июнь в качестве фактического распределения.
var = 'LoanAmount'
base = df.loc[df['date']=='2023-05',var]
test = df.loc[df['date']=='2023-06',var]
calculate_psi(base_list=list(base),test_list=list(test))
То же самое относится и к любым другим переменным или оценкам модели.
Выше представлен синглпеременнаяили МодельразделенныйPSIсчитать Рассчитать。Воля Вот и всесчитать Рассчитать函数calculate_psiУпаковано для созданияРассчитать PSI по месяцамфункция,Код следующий.
def psi_month_calc(train_df:pd.DataFrame, oot_df:pd.DataFrame, col_list:list, dt_name:str):
"""
@ Маленький секретный кружок контроля рисков Дон Гэ
Описание: Расчет psi набора данных oot, переменная месяц за месяцем.
Входные параметры:
:param train_df: поезд ожидает DataFrame
:param oot_df: ootactualDataFrame
:param col_list: переменнаясписок :param dt_name: Название месяца переменная
Выход:
:psi_month_table: переменная по месяцам psi на oot, dataframe
:psi_month_detail_total: Подробности помесячного пси-бинирования переменной на oot, dict
"""
month_list = sorted(oot_df[dt_name].unique())
psi_array = []
psi_month_detail_total = {}
for mt in month_list:
sub_df = oot_df.loc[oot_df[dt_name]==mt]
psi_month_detail_each = []
col_psi_dict = {}
...
# Вся информация о переменномпси-боксе удобна для последующего просмотра.
psi_month_detail_each.append(stat_df)
psi_month_detail_total[mt] = pd.concat(psi_month_detail_each)
# oot ежемесячные значения psi для всех переменных
psi_array.append(col_psi_dict)
# Сводная таблица месячной переменнойpsi на оот
psi_month_table = pd.DataFrame(psi_array).T
psi_month_table.columns = month_list
return psi_month_table, psi_month_detail_total
Например, ниже мы используем май в качестве эталона и все месяцы после мая в качестве фактического распределения для расчета индекса стабильности PSI всех переменных.
base = df.loc[df['date']=='2023-05']
test = df.loc[~(df['date']=='2023-05')]
col_list = df.columns.difference(['target','date','uid']).tolist()
psi_month_table, psi_month_detail_total = psi_month_calc(base,test,col_list,'date')
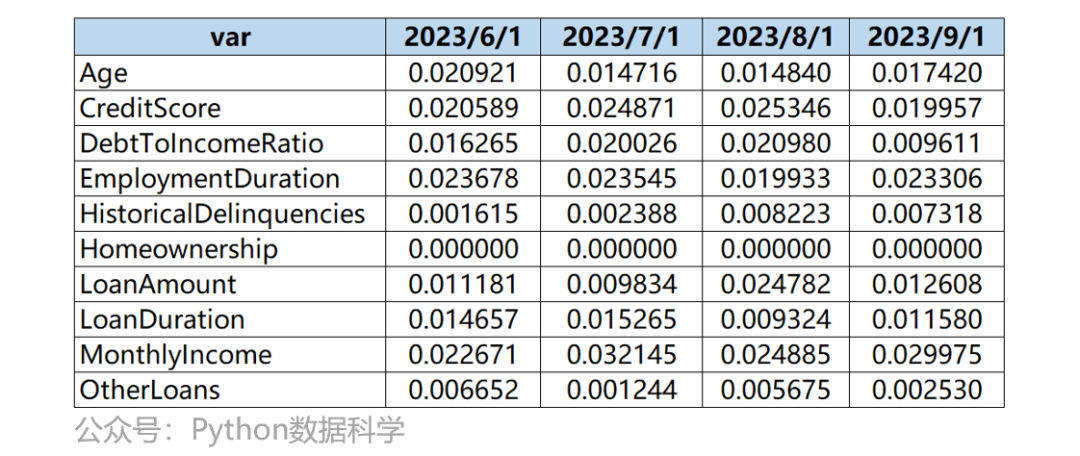
Тогда я получил два результата.
psi_month_table
Одним из них является окончательный результат PSI помесячно для всех переменных.
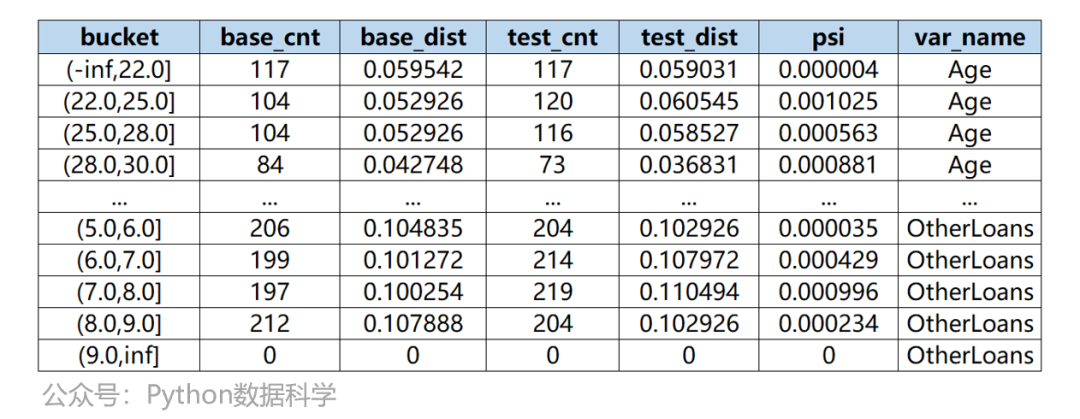
psi_month_detail_total['2023-06']
Другой — это ежемесячное группирование всех переменных, то есть получается промежуточный процесс расчета.
-- end --



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
