Метаданныепрактика управления&Родословная данных
Что такое метаданные? Узкая интерпретация метаданных Метаданные — это данные, используемые для описания данных. В широком смысле, помимо тех бизнес-данных, которые непосредственно считываются и записываются бизнес-логикой, может быть вся другая информация/данные, необходимые для поддержания работы всей системы. называемые метаданными. Например, информация о схеме таблиц данных, кровное родство задач, информация о взаимоотношениях сопоставления разрешений между пользователями и сценариями/задачами и т. д.
Цель управления этой дополнительной информацией метаданных состоит, с одной стороны, в том, чтобы позволить пользователям более эффективно извлекать и использовать данные, а с другой стороны, в том, чтобы позволить менеджерам платформ более эффективно выполнять обслуживание и управление системой.
Отправная точка хороша, но обычно эта информация метаданных разбросана по различным системам и процессам платформы, и управление ими может в большей или меньшей степени осуществляться с помощью инструментов, решений или логики процессов самих различных подсистем. Так для чего же используется платформа управления метаданными, которую мы называем? Должна ли вся информация быть собрана или необходима в системе для единого управления? Какие конкретные данные должны быть включены в область управления платформой управления метаданными? Давайте обсудим соответствующий контент ниже.
Чем управляет платформа управления метаданными?
Первым шагом в управлении данными является сбор информации. Очевидно, что без данных невозможно проводить анализ, а также невозможно эффективно управлять и улучшать каналы передачи данных платформы. Поэтому очень важной функцией платформы управления метаданными является сбор информации. Что касается того, какую информацию собирать, это зависит от потребностей бизнеса и целевых задач, которые нам необходимо решить.
Независимо от того, сколько информации будет собрано, если ее невозможно использовать, это просто пустая трата места для хранения. Следовательно, платформа управления метаданными также должна учитывать, как отображать эту информацию метаданных в соответствующей форме. Кроме того, как предоставлять эту информацию метаданных окружающим вышестоящим и нижестоящим системам в виде услуг, чтобы действительно помочь платформе больших данных завершить управление качеством. .замкнутая работа.
Какую информацию следует собирать? Хотя не существует абсолютного стандарта, для платформ разработки больших данных общая информация метаданных включает в себя:
- Структура таблицы данных Информация о схеме
- Хранение пространства данных, записи чтения и записи, владение разрешениями и другая различная статистическая информация.
- Данные о кровном родстве
- Информация о бизнес-атрибутах данных
Давайте обсудим эти четыре пункта подробно ниже.
Структура таблицы данных Информация о схеме
Информацию о структуре таблицы легко понять. Информация метаданных в узком смысле обычно относится к этой части контента. Это действительно самая важная часть контента в системе управления метаданными.
Однако, будь то компоненты хранения данных SQL или NoSQL, большинство из них имеют возможность управлять схемами таблиц и запрашивать их. Также легко понять, что без этих возможностей сами эти системы не смогут нормально работать, не так ли? Например, информация о собственной структуре таблицы Hive изначально хранится во внешней базе данных БД. Hive также предоставляет синтаксис, такой как «показать таблицу» и «описать таблицу», для запроса этой информации. Так почему же нам нужно заниматься разработкой системы управления метаданными для управления этой информацией?
Существует много возможных причин для этого, и необходимость централизованного управления может быть одной из причин, но более важная причина заключается в том, что, по сути, методы управления метаданными в этих системах обычно разрабатываются с учетом функционального функционирования системы. сама система. Другими словами, они не существуют для целей управления качеством данных. Из-за разного позиционирования потребностей они обычно не могут напрямую удовлетворить потребности управления качеством данных с точки зрения функциональной формы или средств взаимодействия.
Приведу очень простой пример: я хочу знать историю изменений структуры таблицы. Очевидно, что большинство систем сами по себе не будут проектировать такую функцию. И даже если некоторые функции доступны, другие окружающие вышестоящие и нижестоящие бизнес-системы часто не подходят для получения такого типа информации непосредственно из системы, потому что, если это будет сделано, безопасность системы, а также прямая взаимная зависимость и связь часто будут нарушены. быть проблемой.
Таким образом, сбор информации о структуре таблиц — это не только простое обобщение информации, но, что более важно, с точки зрения управления платформой и потребностей бизнеса, то, как организовать и обобщить данные для облегчения системной интеграции и достижения конечной ценности для бизнеса.
Место для хранения данных, записи чтения и записи, право собственности и другая различная статистическая информация.
Этот тип информации может включать, помимо прочего: сколько места в хранилище занимают данные, были ли они недавно изменены, кто и когда использовал данные, кто имеет полномочия управлять данными и просматривать их и т. д. Кроме того, вы также можете включить статистическую информацию, например, сколько таблиц было добавлено вчера, сколько таблиц было удалено и сколько разделов было создано.
В обычных рабочих процессах большинству людей такая информация может быть не нужна или не интересна. Но когда дело доходит до темы управления качеством данных, эта информация часто является незаменимой и важной информацией для оптимизации системы и бизнеса, контроля безопасности данных, устранения неполадок и т. д., поэтому этот тип информации обычно также можно классифицировать по перспектива аудита.
Подобно информации о структуре таблиц, для сбора и управления этим типом информации аудита обычно функции конкретных базовых компонентов управления хранилищем данных сами по себе не могут напрямую удовлетворить наши потребности, и их необходимо собирать единообразно с помощью специализированной платформы управления метаданными. обработка и управление.
Данные о кровном родстве
Что такое информация о происхождении или информация о происхождении. Проще говоря, это отношения восходящего и нисходящего источника и места назначения между данными, откуда данные поступают и куда они отправляются. Какой смысл знать эту информацию? Он имеет широкий спектр применений. Простейший пример: если есть проблема с фрагментом данных, вы можете проверить восходящий канал на основе кровного родства, чтобы увидеть, в каком канале возникла проблема. Кроме того, мы также можем устанавливать зависимости между задачами, которые производят эти данные, посредством кровного родства данных, тем самым помогая планированию работы системы планирования, или использоваться для определения того, на какие последующие данные может повлиять невыполненная или ошибочная задача и т. д.
Анализ кровного родства данных кажется простым, но сделать это непросто, поскольку источники данных разнообразны, средства обработки данных и используемые вычислительные платформы также могут быть разными. Кроме того, не все системы есть у всех. врожденная способность получать необходимую информацию. Для разных систем степень детализации анализа кровного родства может быть разной. Некоторые могут делать это на уровне таблицы, а некоторые даже на полевом уровне.
Возьмем в качестве примера стол-улей.,Анализируя план выполнения сценария куста,Это можно сделать относительно точноиз Уровень целевого поляиз Родословная данныхсвязьиз。И если этоMapReduceДанные, сгенерированные задачей,снаружи,Вы сможете примерно оценить соотношение чтения и записи на уровне каталога, анализируя информацию журнала, выводимую задачей MR.,Это косвенно выводит зависимость данных от крови.
Информация о бизнес-атрибутах данных
Первые три типа информации,В определенной степени ее можно получить из информации, которой обладает сама базовая система, с помощью технических средств.,Или его можно получить путем вторичной обработки и анализа посредством определенного процесса. Напротив,Информация о бизнес-атрибутах данных,Обычно не имеет ничего общего с операционной логикой самой базовой системы.,В большинстве случаев его необходимо будет получить извне другими способами.
Итак, что же представляет собой информация о бизнес-атрибутах? Наиболее распространенными из них являются, например, информация о статистическом уровне таблицы данных, для чего используется эта таблица, конкретные статистические методы каждого поля, описание бизнеса, бизнес-метки, записи исторических изменений логики сценария, причины изменений и т. д. и т. д. Кроме того, вас также может беспокоить, кто отвечает за разработку соответствующей таблицы данных, бизнес-отдел конкретных данных и т. д.
Если вся вышеуказанная информация должна быть заполнена разработчиком данных добровольно, это не невозможно, но явно недостоверно. В конце концов, для большинства студентов естественной реакцией на выполнение работы, отличной от основных звеньев работы по разработке данных, является не выполнять ее, если они могут. Чем меньше проблем, тем лучше. Если нет спецификации системы процессов и если не создается фактическая ценность, то заполнение соответствующей информации может легко стать обузой или простой формальностью.
Поэтому, хотя эту часть информации часто приходится вводить вручную с помощью внешних средств, все же необходимо рассмотреть возможность ее максимальной интеграции с процессом, чтобы сделать их незаменимой частью развития бизнеса. Например, сбор части информации может быть встроен в процесс разработки соответствующих данных посредством спецификаций процесса разработки общей платформы данных. Например, записи исторических изменений могут быть обязательными при изменении сценария задачи или схемы формы; информация о бизнес-лидерах может быть автоматически отображена и заполнена посредством текущего направления деятельности разработчика и принадлежности к группе разработки. Информация о статистических методах должна быть стандартизирована и определена с помощью системы управления стандартными показателями, насколько это возможно;
В целом, Информация о бизнес-атрибутах данных,Оно должно в первую очередь служить бизнесу,Поэтому их сбор и демонстрация должны быть максимально интегрированы с бизнес-средой.,Только таким образом можно будет по-настоящему использовать эту часть Метаданной информации.
Введение в системные решения, связанные с управлением метаданными
Apache Atlas
Решения для систем управления метаданными с открытым исходным кодом, распространенные в сообществе, такие как Apache Atlas, продвигаемый Hortonworks, его основные архитектурные идеи показаны на рисунке ниже.
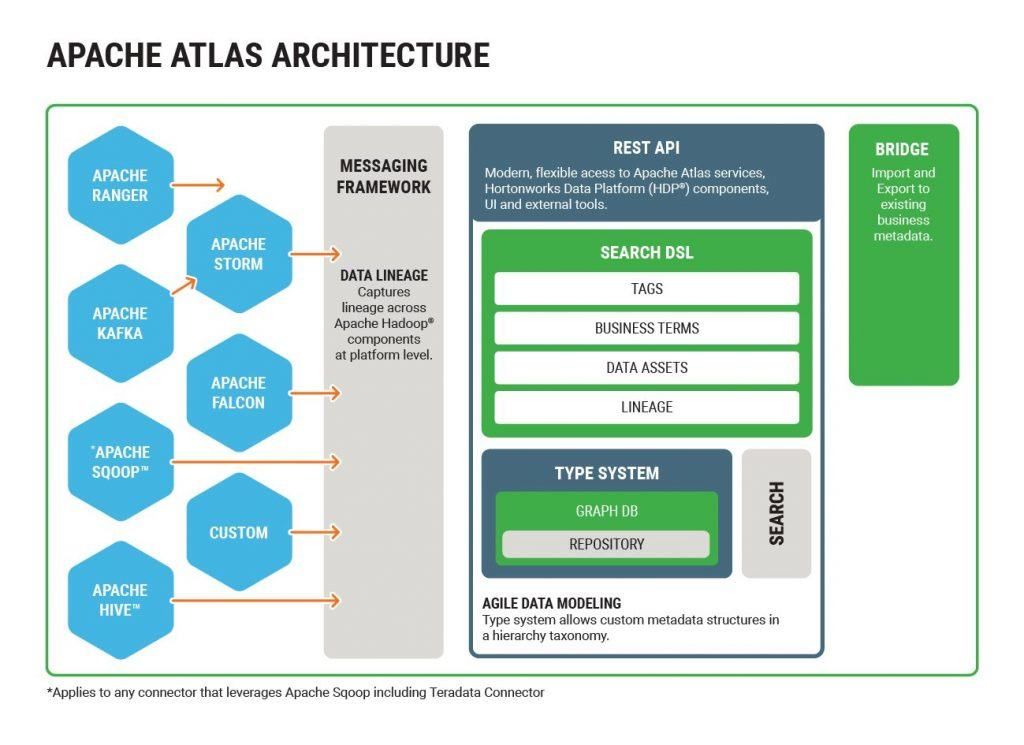
Архитектурную схему Atlas можно назвать вполне типичной. По сути, этот тип системы обычно состоит из трех основных компонентов: сбора метаданных, хранения и отображения запросов. Кроме того, будет использоваться серверная часть управления для настройки и управления общим процессом сбора метаданных, определения формата метаданных и развертывания услуг.
В соответствии с реализацией Atlas, Atlas собирает информацию метаданных из нескольких источников данных с помощью различных плагинов-перехватчиков/мостов, определяет формат информации метаданных с помощью набора настраиваемых систем типов и выполняет полнотекстовый анализ метаданных с помощью поисковых систем. и условного извлечения. Помимо встроенной консоли пользовательского интерфейса, Atlas также может предоставлять внешние сервисы в виде Rest API.
Общий дизайн Atlas ориентирован на сбор данных о родственных связях и управление базовой информацией в измерениях таблиц и информации о бизнес-атрибутах. С этой целью компания Atlas разработала универсальную систему типов для описания этой информации. К основным базовым типам Type относятся DataSet и Process. Первый используется для описания различных источников данных, а второй — для описания процесса обработки данных, например задачи ETL.
Существующая реализация Bridge в Atlas с точки зрения источников данных в основном охватывает Hive, HBase, HDFS и Kafka. Кроме того, существуют Bridges, адаптированные для Sqoop, Storm и Falcon, но эти три больше основаны на Process Starting с точки зрения . окончательными источниками данных по-прежнему являются указанные выше четыре источника данных.
Конкретная реализация Bridge в основном реализуется через вышеупомянутое базовое хранилище и механизм Hook в соответствующих процессах вычислительного механизма, таких как Hive SQL Post Execute Hook, сопроцессор HBase и т. д., а собранные данные передаются в Atlas. Сервер через очередь сообщений Kafka или других подписчиков для потребления.
Что касается управления бизнес-информацией, Atlas позволяет пользователям заполнять бизнес-информацию о данных или маркировать данные, настраивая информацию атрибута типа, что облегчает последующую целевую фильтрацию и поиск данных.
Наконец, Atlas можно использовать вместе с Ranger, что позволяет Ranger динамически авторизовать данные с помощью определяемых пользователем тегов данных в Atlas. По сравнению со статической авторизацией на основе путей или имен таблиц/имен файлов этот подход на основе тегов иногда может быть более эффективным. гибкий подход к управлению разрешениями в конкретных сценариях.
В целом реализация Atlas относительно разумна с точки зрения структурных принципов. Однако на данном этапе конкретная реализация Atlas все еще остается относительно грубой, и многие функции доступны, но не идеальны. Кроме того, Atlas не выполняет большого объема работы в процессе аудита данных, а его возможности интеграции и применения в общем бизнес-процессе обработки данных также очень ограничены. Сам проект «Атлас» уже давно находится в статусе инкубатора, поэтому всем нужно работать сообща, чтобы помочь ему улучшиться.
Cloudera Navigator Data Management
Еще одним распространенным решением является Navigator, который в основном продвигается в версии Cloudera CDH. По сравнению с Atlas общая реализация Navigator более зрелая и больше похожа на законченное решение. Однако Navigator не является открытым исходным кодом, так что это неудивительно. , если вам придется что-то продать за деньги, у вас будет больше мотивации это улучшать ;)
Позиционированием продукта Navigator является управление данными, которое, по сути, управляет данными посредством управления метаданными. Однако окружающие инструменты и вспомогательные средства являются относительно полными, а интеграция продукта с серверной частью управления Cloudera Manager также является относительно тщательной. По сравнению с Atlas общая архитектура компонентов Navigator также более сложна. Общая компонентная архитектура Навигатора показана на рисунке ниже.
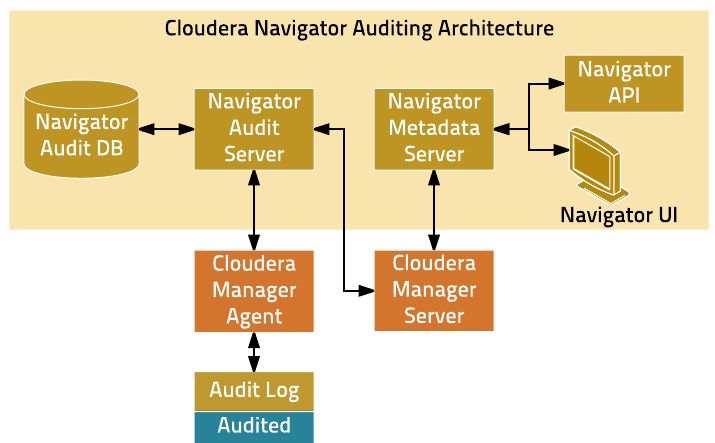
Навигатор предназначен для управления данными,Поэтому будет проделана дополнительная работа по управлению аудитом данных.,В дополнение к сбору и управлению информацией о родословной в Hive/Impala и других таблицах,Navigator также можно настроить для сбора записей операций чтения и записи, включая HDFS.,Yarn/Spark/PigИнформация, включая статистику выполнения заданий。NavigatorОн также предоставляет пользователям различные представления статистического анализа и инструменты управления запросами для анализа этих данных.。
С точки зрения базовой реализации Navigator также получает соответствующую информацию от запущенных процессов различных базовых систем через хуки или плагины. Но в отличие от Atlas, процесс сбора и передачи метаданных Navigator не записывает эту информацию в очередь сообщений. Вместо этого он в основном записывает ее в локальный файл журнала, где находятся соответствующие сервисы, через эти плагины, а затем Cloudera Manager развертывает агент. на каждом сервисном узле считывает, фильтрует, анализирует, обрабатывает и передает эту информацию на Сервер аудита.
Кроме того, Navigator также собирает и анализирует некоторую информацию метаданных из источников, не являющихся журналами, через независимый сервер метаданных и предоставляет унифицированные внешние службы управления конфигурацией метаданных. Пользователи также могут настраивать стратегии политики, позволяющие серверу метаданных автоматически выполнять маркировку данных для пользователей на основе определяемых пользователем правил, тем самым улучшая возможности автоматического и автономного управления данными.
В целом интеграция продуктов между Navigator и Cloudera Manger относительно полная. Если вы используете пакет семейства дистрибутивов CDH для управления своим кластером, использование Navigator должно быть хорошим выбором. Однако, если это самоуправляемый кластер или самостоятельная платформа разработки больших данных, вам будет сложно использовать глубоко интегрированный и настраиваемый Навигатор. Но в любом случае для самостоятельно разрабатываемых систем управления метаданными в целом. Дизайнерская идея Навигатора тоже стоит поучиться.
Практика системы управления метаданными Могуджие
могуджиебольшие Общая идея системной архитектуры системы управления «Метаданные» платформы данных относительно аналогична вышеупомянутой системе. Однако, объективно говоря, развитие нашей системы представляет собой процесс постепенного расширения с развитием потребностей общего развития. платформа, поэтому с точки зрения управления данными. С точки зрения, это не так сосредоточено, как две вышеупомянутые системы. Универсальная применимость системы типов формата данных. Например, управление информацией схемы,Основное внимание уделяется управлению информацией табличного типа.,Такие как Улей,HBaseждать,а не полностью универсальная система типов. Но относительно,Что касается внешних услуг,Мы также будем уделять больше внимания взаимосвязи между метаданными системами управления и требованиями к приложениям бизнес-систем.,Архитектура похожа,Ниже приводится краткое введение в форму взаимодействия с продуктом, а также некоторые специальные настройки функций и эффектов.
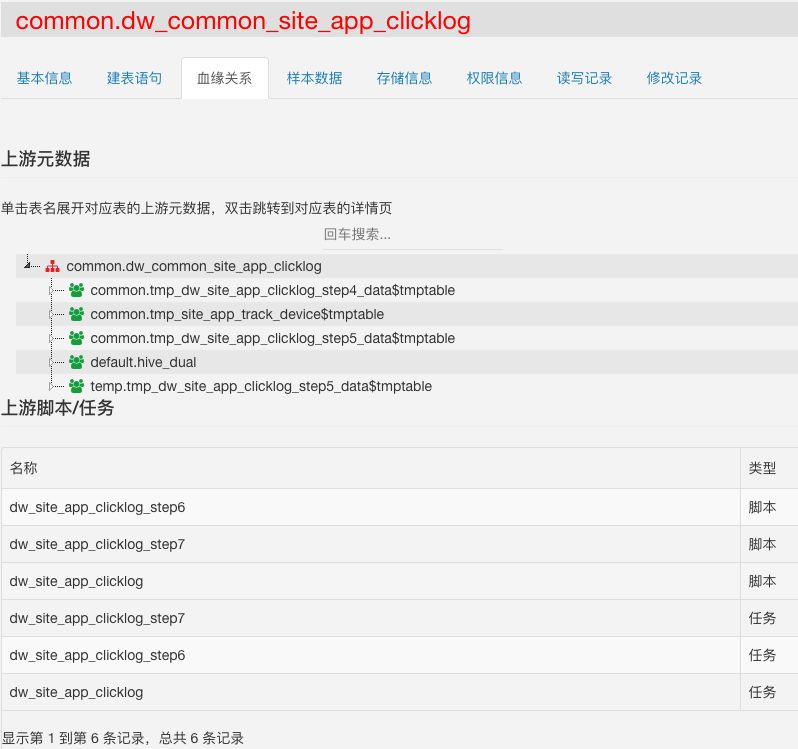
Как показано на рисунке, это частичный интерфейс запроса информации метаданных таблицы Hive в серверной части нашей системы управления метаданными. Он в основном предоставляет пользователям различную базовую информацию о схеме, информацию о бизнес-тегах, информацию о кровном родстве, образцы данных и аудит. такую информацию, как базовая емкость хранилища, разрешения, а также записи изменений чтения и записи.
Помимо управления информацией метаданных таблиц, одной из основных функций нашей системы управления метаданными является управление «бизнес-группами». Целью разработки бизнес-группы является управление всей платформой разработки больших данных в качестве разработчика. Платформа разработки больших данных. Организационная форма автономного подразделения управления. Вся работа по управлению данными и задачами делегируется бизнес-группе и управляется администратором бизнес-группы.
отМетаданныеС точки зрения системы управления,Управление бизнес-группой,Включает сопоставление данных и задач с собственностью бизнес-группы.,Отношения сопоставления разрешений ролей внутри бизнес-групп и т. д.,также,Адаптироваться к быстрым изменениям в бизнесе,Он также предоставляет пользователям такие функции, как передача права собственности на активы данных.
Вообще говоря, функции управления бизнес-группами необходимо сочетать с другими компонентами платформы разработки больших данных, такими как интеграция с интегрированной платформой разработки IDE, чтобы обеспечить функции управления многопользовательской средой разработки на основе бизнес-групп на платформе разработки. и, в качестве другого примера, он объединен с системой планирования для реализации управления квотами вычислительных ресурсов во время планирования задач на основе информации о владении бизнес-группой задачами и данными.
наконец,Об отслеживании кровного родства в данных,Еще несколько слов. В Атласе и навигаторе,Информация, связанная с данными и информацией, связанной с кровью, получается в основном с помощью перехватчиков времени выполнения, поддерживаемых самой вычислительной платформой.,напримерhiveизhookОн находится на этапе синтаксического анализа.,stormизhookнаходится вtopology этап отправки.
Преимущество этого метода заключается в том, что анализ отслеживания родословной основан на информации о фактически выполняемых задачах. Если плагин полностью развернут, проблем с упущениями не возникнет. Однако у этого метода также есть много проблем, которые нелегко устранить. решить, например
- Как обновить кровное родство, которое было исторически зависимо, но больше от него не зависит
- Для задачи, которая еще не запускалась, информацию о родословной невозможно получить заранее.
- Временные скрипты или неверная логика скриптов загрязняют данные о кровном родстве.
Подводя итог, можно сказать, что кровные родства собираются на основе информации времени выполнения. Из-за отсутствия статической бизнес-информации определение и обновление жизненного цикла и достоверности кровных родств будет сложной проблемой, которая также ограничивает применение определенными ограничениями. масштаб.
Наш подход заключается в том, что информация о родословной собирается не автоматически во время выполнения, а при сохранении сценария. Поскольку платформа разработки единообразно управляет сценариями задач всех пользователей, мы можем выполнять статический анализ сценариев, а бизнес-информация, статус выполнения и жизненный цикл самих сценариев известны платформе разработки. Таким образом, это может в определенной степени решить проблемы, упомянутые выше.
Конечно, у этого решения есть и свои недостатки, которые необходимо преодолеть. Например, если контроль над сценарием отсутствует, анализ кровного родства может быть не полностью охвачен; быть основаны на реальном пробеге. Анализируются примеры. Однако эти недостатки не являются для нас ключевыми проблемами с точки зрения спроса, либо их можно в определенной степени решить за счет поддерживающего строительства периферийных систем.
Отказ от ответственности:Опубликовано через этот общедоступный аккаунтиз Оригинал статьи опубликован на официальном аккаунте.,Или отредактируйте и систематизируйте отличные статьи, найденные в Интернете.,Авторские права на статью принадлежат первоначальному автору,Он предназначен только для изучения и ознакомления читателей. Для неоригинальных статей, которыми поделились,Некоторые потому, что настоящий источник не может быть найден.,Если источник указан неправильно или использованные в статье изображения, ссылки и т.п. включают, помимо прочего, программное обеспечение, материалы и т.п.,Если есть нарушения,Пожалуйста, свяжитесь с серверной частью напрямую,Опишите конкретные статьи,Серверная часть устранит неудобства как можно скорее.,Глубоко сожалею.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
