Meta научит вас использовать Llama2 за 5 шагов: самое простое обучение большой модели, которое я когда-либо видел
Отчет о сердце машины
Монтажер: Чжао Ян
Эта статья представляет собой обучающий блог по использованию Llama2, запущенный на официальном сайте Meta. Он научит вас использовать Llama2 за 5 простых шагов.
В этом блоге Meta исследует пять шагов по использованию Llama 2, чтобы пользователи могли в полной мере использовать преимущества Llama 2 в своих собственных проектах. В то же время в нем подробно представлены ключевые концепции, методы установки и доступные ресурсы Llama 2, а также представлен пошаговый процесс настройки и запуска Llama 2.
Llama 2 с открытым исходным кодом Meta включает веса моделей и исходный код с параметрами от 7B до 70B. Llama 2 имеет на 40% больше обучающих данных и вдвое большую длину контекста, чем Llama, а Llama 2 предварительно обучен на общедоступных онлайн-источниках данных.

Схема описания параметров Llama2

Схема описания процесса Llama2
Llama 2 превосходит другие модели открытого языка по множеству внешних тестов, включая рассуждение, кодирование, проверку знаний и проверку знаний. Llama 2 бесплатен для исследовательского и коммерческого использования.
5 шагов по использованию Llama 2 описаны в следующем разделе. Существует несколько способов локальной настройки Llama 2, и в этой статье обсуждается один из методов, который позволит вам легко настроить и быстро начать использовать Llama.
Начните работу с Llama2
Шаг 1: Предварительные условия и зависимости
В этой статье Python будет использоваться для написания сценариев для настройки и выполнения задач конвейера, а также модели Transformer и библиотеки ускорения, предоставленной Hugging Face.
pip install transformers
pip install accelerateШаг 2. Загрузите веса модели.
Модель, использованную в этой статье, можно найти в репозитории Meta Llama 2 Github. Загрузка модели через этот репозиторий Github требует двух шагов:
- Посетите веб-сайт Meta, примите лицензию и отправьте форму. Вы получите предварительно подписанный URL-адрес по электронной почте только после того, как запрос будет одобрен;
- Клонируйте базу знаний Llama 2 локально.
git clone https://github.com/facebookresearch/llamaЗапустите скрипт download.sh (sh download.sh). При появлении запроса введите заранее указанный URL-адрес, который вы получили по электронной почте.
- Выберите для загрузкииз Модель Версия,Например 7б-чат. Тогда вы можете скачать tokenizer.model и включая веса llama-2-7b-chat Оглавление.
Запустите ln -h ./tokenizer.model ./llama-2-7b-chat/tokenizer.model, чтобы создать ссылку на токенизатор, который будет использоваться на следующем этапе преобразования.
Преобразование веса модели для работы с Hugging Face:
TRANSFORM=`python -c"import transformers;print ('/'.join (transformers.__file__.split ('/')[:-1])+'/models/llama/convert_llama_weights_to_hf.py')"`
pip install protobuf && python $TRANSFORM --input_dir ./llama-2-7b-chat --model_size 7B --output_dir ./llama-2-7b-chat-hfMeta предлагает переделанные гири Llama 2 на Hugging Face. Чтобы использовать загрузки в Hugging Face, вам необходимо запросить загрузку, выполнив описанные выше действия и убедившись, что вы используете тот же адрес электронной почты, что и ваша учетная запись Hugging Face.
Шаг 3. Напишите скрипт Python
Затем создайте скрипт Python, который будет содержать весь код, необходимый для загрузки модели и выполнения вывода с помощью Transformer.
Импортируйте необходимые модули
Во-первых, вам необходимо импортировать в скрипт следующие необходимые модули: LlamaForCausalLM — класс модели Llama 2, LlamaTokenizer подготавливает необходимые запросы для модели, конвейер используется для генерации выходных данных модели, а torch используется для внедрения PyTorch. и укажите тип данных, который вы хотите использовать.
import torch
import transformers
from transformers import LlamaForCausalLM, LlamaTokenizerЗагрузить модель
Затем загрузите модель Llama с загруженными и преобразованными весами (в этом примере они хранятся в ./llama-2-7b-chat-hf).
model_dir = "./llama-2-7b-chat-hf"
model = LlamaForCausalLM.from_pretrained (model_dir)Определите и создайте экземпляры задач токенизатора и конвейера.
Перед окончательным использованием убедитесь, что входные данные подготовлены для модели. Этого можно добиться, загрузив токенизатор, связанный с моделью. Добавьте в свой скрипт следующее, чтобы инициализировать токенизатор из того же каталога модели:
tokenizer = LlamaTokenizer.from_pretrained (model_dir)Далее, необходим метод, который даст модели возможность рассуждать. Модуль конвейера может указать тип задачи, необходимый для запуска задачи конвейера (генерация текста), модель, необходимую для вывода (модель), определить точность использования модели (torch.float16), устройство для запуска задачи конвейера (device_map). и другие конфигурации.
Добавьте в свой скрипт следующее, чтобы создать экземпляр задачи конвейера, используемой для запуска примера:
pipeline = transformers.pipeline (
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)Запуск задач конвейера
После определения задачи конвейера вам также необходимо предоставить несколько текстовых подсказок в качестве входных данных для генерации ответов (последовательностей) при запуске задачи конвейера. Задача конвейера в приведенном ниже примере устанавливает для do_sample значение True, что позволяет указать стратегию декодирования, которая выбирает следующий токен из распределения вероятностей по всему словарю. В примере сценария в этой статье используется выборка top_k.
изменив max_length Вы можете указать длину ответа, который хотите сгенерировать. Воля num_return_sequences Параметр установлен на значение больше, чем 1. Можно создать несколько выходных данных. Добавьте следующее в существующий Скрипт, чтобы предоставить входные данные и способ Запуска. задач Информация о транспортировке:
sequences = pipeline (
'I have tomatoes, basil and cheese at home. What can I cook for dinner?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=400,
)
for seq in sequences:
print (f"{seq ['generated_text']}")Шаг 4: Запустите ламу
Теперь скрипт готов к запуску. Сохраните скрипт, вернитесь в среду Conda и введите
python < Скриптимя >.py и нажмите Enter, чтобы запустить скрипт.
Как показано на рисунке ниже, начинается загрузка модели, отображающая ход выполнения задачи конвейера, а также введенные вопросы и ответы, сгенерированные после запуска скрипта:
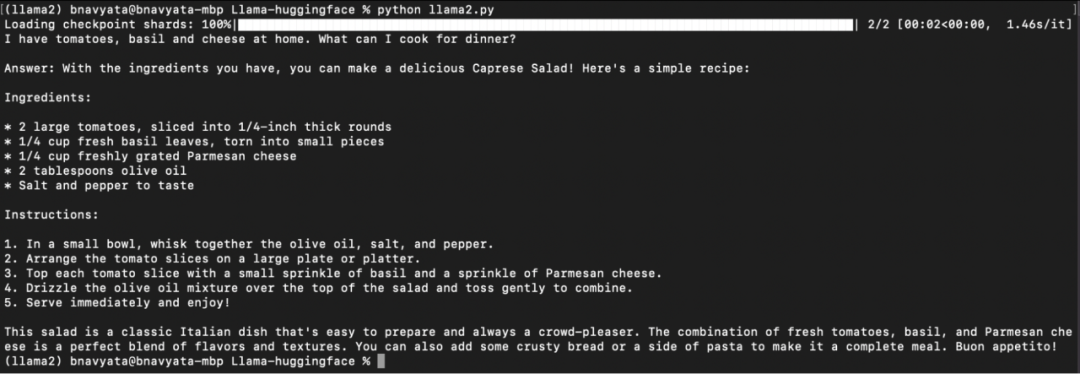
Запустите 2-7b-chat-hf локально.
Теперь можно настроить и запустить локально. Llama 2. Попробуйте разные подсказки, указав их в строковом параметре существования. Вы также можете использовать существование Загрузить модель укажите имя модели для загрузки других Llama 2 Модель. Дополнительные ресурсы, упомянутые в следующем разделе, помогут вам узнать больше. Llama 2 Информация о том, как это работает, и различные ресурсы, которые помогут начать работу.
Шаг 5. Улучшите возможности
Чтобы узнать больше о том, как работает Llama 2, методе обучения и используемом оборудовании, см. статью Meta «Llama 2: Open Foundation and Fine-Tuned Chat Models», в которой эти аспекты рассматриваются более подробно.
Адрес статьи: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Получите исходный код модели из репозитория Meta Llama 2 Github, где показано, как работает модель, и простейший пример загрузки модели Llama 2 и выполнения вывода. Здесь вы также найдете инструкции по загрузке, настройке модели и примеры запуска моделей завершения текста и чата.
Адрес репо: https://github.com/facebookresearch/llama
Узнайте больше о модели, включая архитектуру модели, предполагаемое использование, требования к аппаратному и программному обеспечению, данные обучения, результаты и лицензии на карточке модели.
Адрес карты: https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
Примеры того, как быстро начать тонкую настройку и как выполнить вывод для точно настроенной модели, представлены в репозитории Meta llama-recipes на Github.
Адрес репо: https://github.com/facebookresearch/llama-recipes/
Ознакомьтесь с недавно выпущенным инструментом искусственного интеллекта для кодирования Meta Code Llama — моделью искусственного интеллекта, созданной на основе Llama 2 и настроенной для возможности генерировать и анализировать код.
Адрес Кодовой Ламы: https://about.fb.com/news/2023/08/code-llama-ai-for-coding/
Прочтите Руководство по ответственному использованию, в котором представлены лучшие практики и рекомендации по ответственному созданию продуктов на основе больших языковых моделей (LLM), охватывающие каждый этап разработки от начала до развертывания.
Адрес гида: https://ai.meta.com/llama/responsible-use-guide/
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.


Flask Learning-9. 2 способа включения режима отладки (debug mode).
Руководство по настройке самостоятельного сервера для Eudemons Parlu

40 вопросов для собеседований по SpringBoot, которые необходимо задавать на собеседованиях! При необходимости ответьте на вопросы для собеседования SpringBoot [предлагаемый сборник] [легко понять]
Через два года JVM может быть заменен GraalVM.

Разрешение циклических зависимостей Spring Bean: существует ли неразрешимая циклическая ссылка?

Разница между промежуточным программным обеспечением ASP.NET Core и фильтрами
[Серия Foolish Old Man] Ноябрь 2023 г. Специальная тема Winform Control Элемент управления DataGridView Подробное объяснение
.NET Как загрузить файлы через HttpWebRequest

[Веселый проект Docker] Обновленная версия 2023 года! Создайте эксклюзивный инструмент управления паролями за 10 минут — Vaultwarden
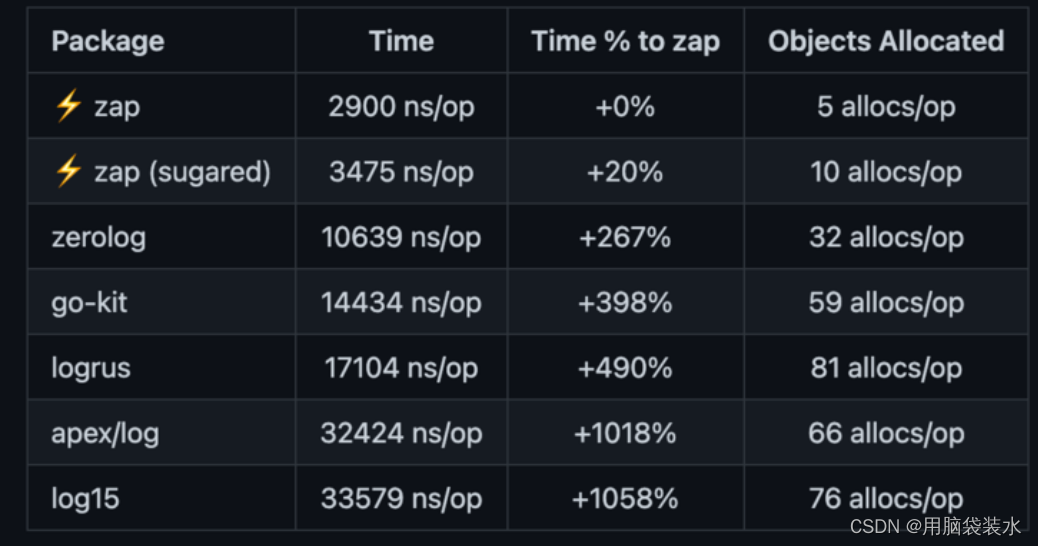
Высокопроизводительная библиотека бревен Golang zap + компонент для резки бревен лесоруба подробное объяснение

Концепция и использование Springboot ConstraintValidator

Новые функции Go 1.23: точная настройка основных библиотек, таких как срезы и синхронизация, значительно улучшающая процесс разработки.

[Весна] Введение и базовое использование AOP в Spring, SpringBoot использует AOP.

Чтобы начать работу с рабочим процессом Flowable, этой статьи достаточно.

Байтовое интервью: как решить проблему с задержкой сообщений MQ?
ASP.NET Core использует функциональные переключатели для управления реализацией доступа по маршрутизации.
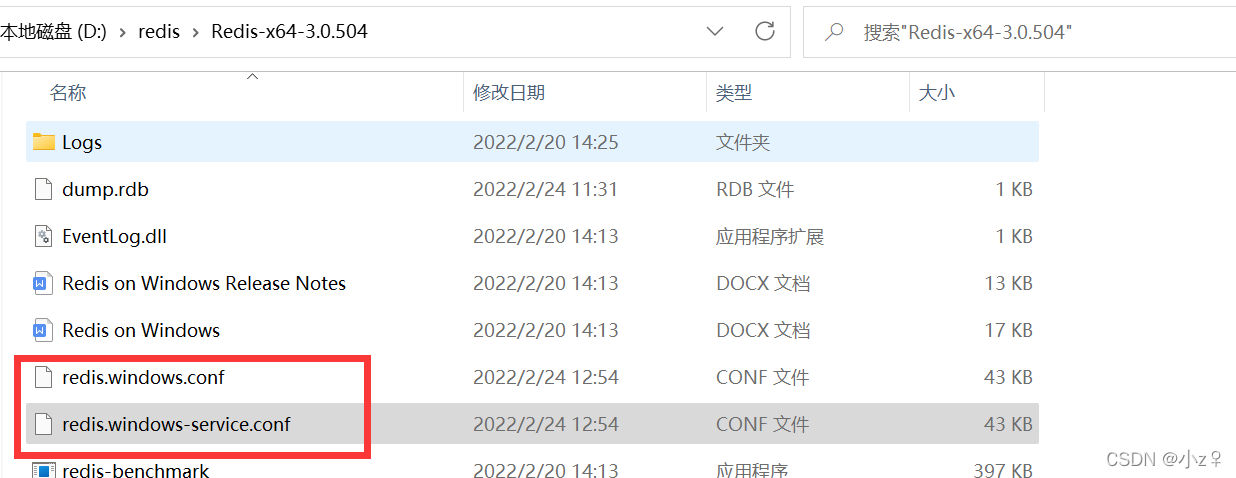
[Проблема] Решение Невозможно подключиться к Redis; вложенное исключение — io.lettuce.core.RedisConnectionException.
От теории к практике: проектирование чистой архитектуры в проектах Go
Решение проблемы искажения китайских символов при чтении файлов Net Core.
Реализация легких независимых конвейеров с использованием Brighter

Как удалить и вернуть указанную пару ключ-значение из ассоциативного массива в PHP
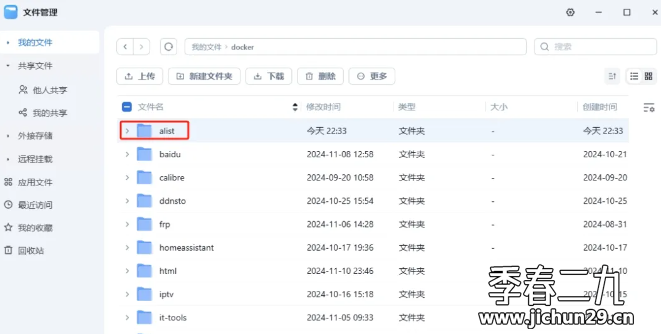
Feiniu fnos использует Docker для развертывания учебного пособия по AList
Принципы и практика использования многопоточности в различных версиях .NET.
Как использовать PaddleOCRSharp в рамках .NET

CRUD используется уже два или три года. Как читать исходный код Spring?

Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️
