[Машинное обучение] Подробное объяснение трансферного обучения!
1. Чтодатрансферное обучение
Трансферное обучение (Перенос Learning)это своего родаметоды машинного обучения,Просто подумайте об этом как Задача A Разработанная модель служит исходной точкой и повторно используется для решения задачи. B в процессе разработки модели. Трансферное обучение — это улучшение обучения новым задачам путем переноса знаний из уже изученных связанных задач. Хотя большинство алгоритмов машинного обучения предназначены для решения одной задачи, разработка алгоритмов, способствующих трансферному обучению, является постоянной проблемой машинного обучения. сообщество. Переносное обучение свойственно людям, и мы могли бы обнаружить, например, что обучение распознаванию яблок может помочь распознавать груши, или что обучение игре на клавиатуре может помочь научиться играть на фортепиано.
Чтобы найти сходство целевой проблемы, задача трансферного обучения состоит в том, чтобы начать со сходства и применить модель, изученную в старой области, к новой области.
2. Зачем необходимо трансферное обучение?
- Противоречие между большими данными и меньшим количеством аннотаций:Хотя существует большое количестводанные,Но они часто не маркируются,Невозможно тренироватьсямашинное обучение Модель. Ручная калибровка занимает слишком много времени.
- Противоречие между большими данными и слабыми вычислениями:Обычные люди не могут владеть огромнымиданные Количество и вычислительные ресурсы。поэтомунужно прибегнуть к Модельмиграция。
- Противоречие между универсальными моделями и персонализированными потребностями:даже в том же самом Задачаначальство,Модели также часто сложно удовлетворить индивидуальные потребности каждого.,Например, определенные настройки конфиденциальности. Это требует адаптации Модели между разными людьми.
- Требования для конкретных применений (например, холодный запуск)。
3. Каковы основные проблемы трансферного обучения?
Есть три основных основных вопроса:
- How to transfer: Как сделать трансферное обучение? (Метод миграции дизайна)
- What to transfer: Учитывая целевой домен, как найти соответствующий исходный домен и затем перенести его? (Выбор исходного поля)
- When to transfer: Когда миграция возможна, а когда нет? (Избегайте негативной миграции)
4. Каковы общие концепции трансферного обучения?
- основное определение
- Домен: состоит из функций данных и распределения функций, что является основной частью обучения.
- Исходный домен:область существующих знаний
- Целевой домен:домен для изучения
- Задача:Состоит из целевой функции и результатов обучения,это результат обучения
- Домен: состоит из функций данных и распределения функций, что является основной частью обучения.
- Классификация по пространству признаков
- изоморфизмтрансферное обучение(Homogeneous TL): исходная областьицелевой Пространство признаков домена такое же, как и у Передачи. не удалась, повторная загрузка отменена. Dₛ = Dₜ
- гетерогенныйтрансферное обучение(Heterogeneous TL):исходная областьицелевой Пространство признаков домена другое, Передача не удалась, повторная загрузка отменена. Dₛ != Dₜ
- Классификация по сценарию миграции
- индуктивныйтрансферное обучение(Inductive TL):исходная областьицелевой Задача обучения другая
- Тип прямого нажатиятрансферное обучение(Transductive TL):исходная областьицелевой домен другой, задача обучения та же
- без присмотратрансферное обучение(Unsupervised TL):исходная областьицелевой домен Ни у кого из них нет тегов
- Классификация по методу миграции
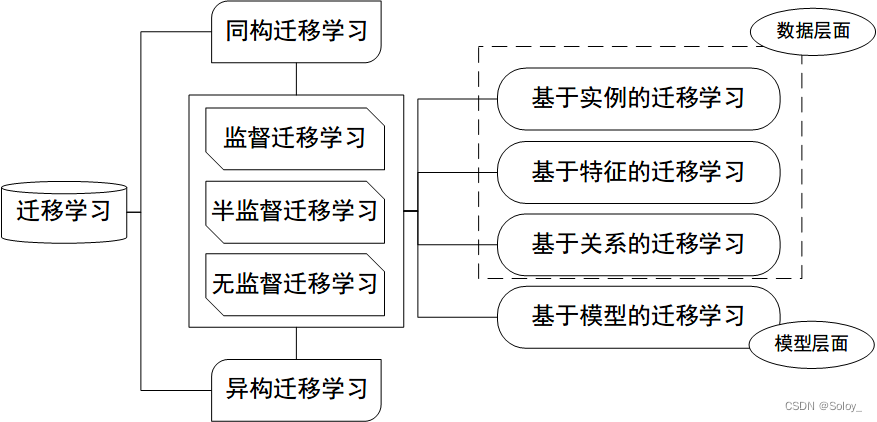
- TL на основе экземпляра:Повторное использование через весаисходная областьицелевой образец домена для миграции Трансферное на основе выборки обучениеметод (Instance based Transfer Learning) В соответствии с определенными правилами определения веса повторно используйте образцы данных для выполнения передачи. обучение. Следующий рисунок наглядно представляет идею исходного метода миграции, основанного на выборке. В области есть разные виды животных, такие как собаки, птицы, кошки и т. д., целевой. В домене есть только одна категория: собаки. При миграции, чтобы максимизировать и отключить Как и в случае с доменом, мы можем искусственно увеличивать исходную Масса выборки, принадлежащая к категории собак в области.
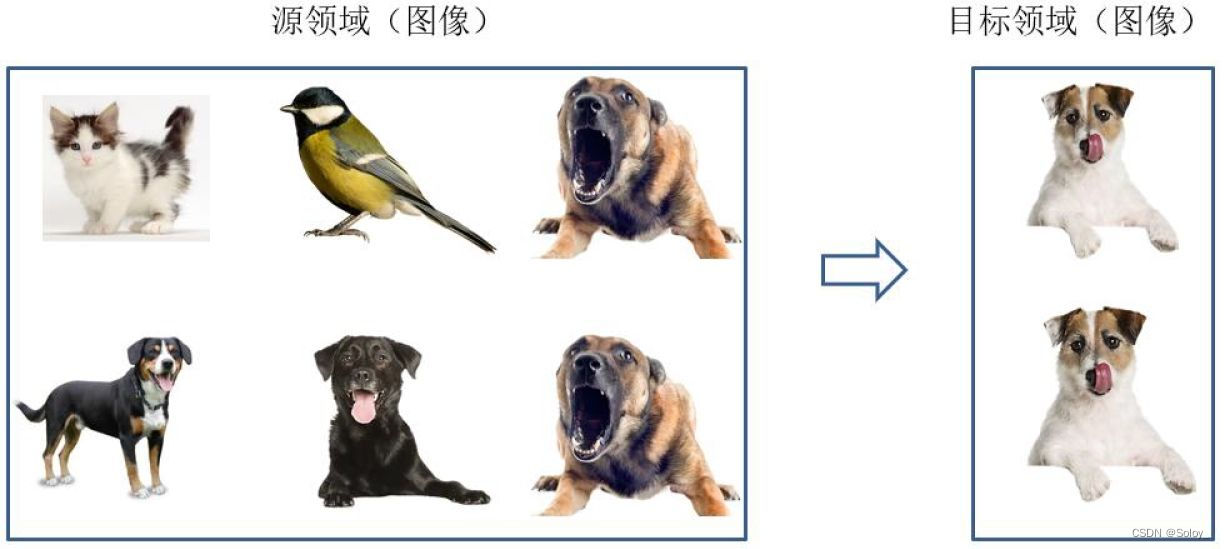
- Миграция на основе функций (TL на основе функций):Воляисходная областьицелевой Особенности домена трансформируются в одно и то же пространство Миграция на основе функцийметод (Feature based Transfer Learning) Это относится к передаче признаков друг другу посредством преобразования признаков с целью уменьшения исходной областьицелевой разрыв между доменом или исходная; областьицелевой Характеристики данных домена преобразуются в единое пространство признаков, а затем традиционные методы машинного обучение осуществляет классификацию и идентификацию. По изоморфизму и неоднородности признаков его можно разделить на изоморфизм и неоднородность трансферное. обучение. На рисунке ниже наглядно представлены два типа функций, основанных на взимаетсятрансферное обучениеметод。
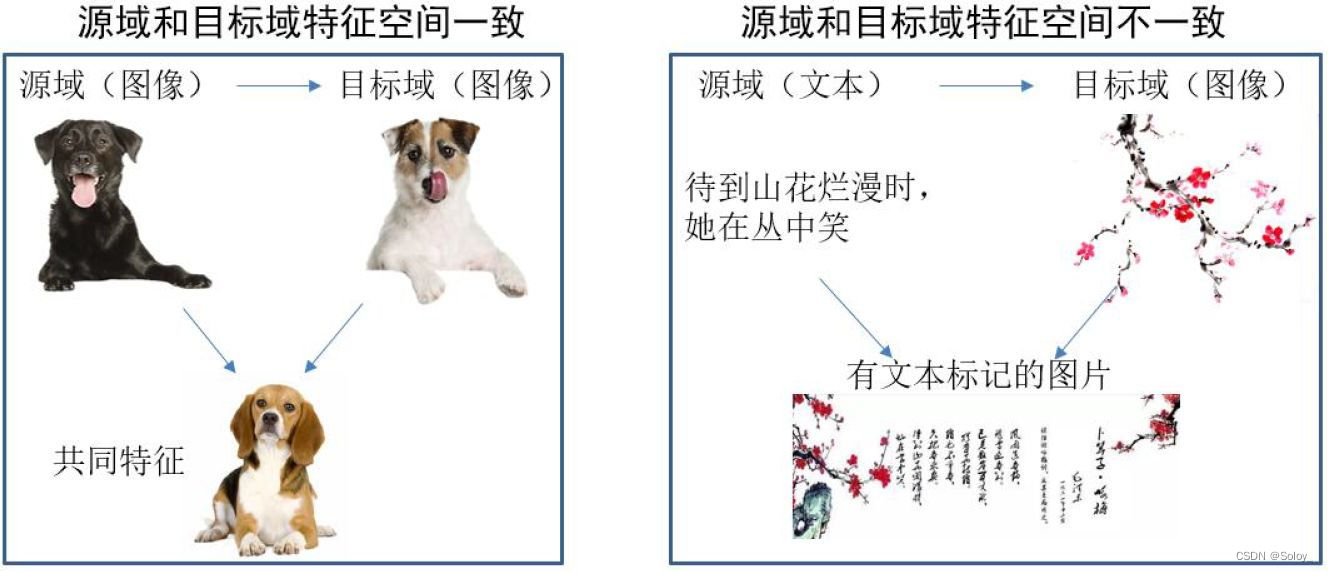
- Миграция на основе модели (TL на основе параметров):использоватьисходная областьицелевой Совместное использование параметров для домена Модель Метод миграции на основе модели (Parameter/Model based Transfer Learning) значит из исходной областьицелевой Найдите информацию о параметрах, общих для них, в домене, чтобы реализовать метод миграции. Допущения, необходимые для этого метода миграции: исходная областьвданныеицелевой данные в домене могут использовать некоторые параметры модели. Изображение ниже наглядно представляет трансферное решение на основе модели. Основная идея метода обучения.
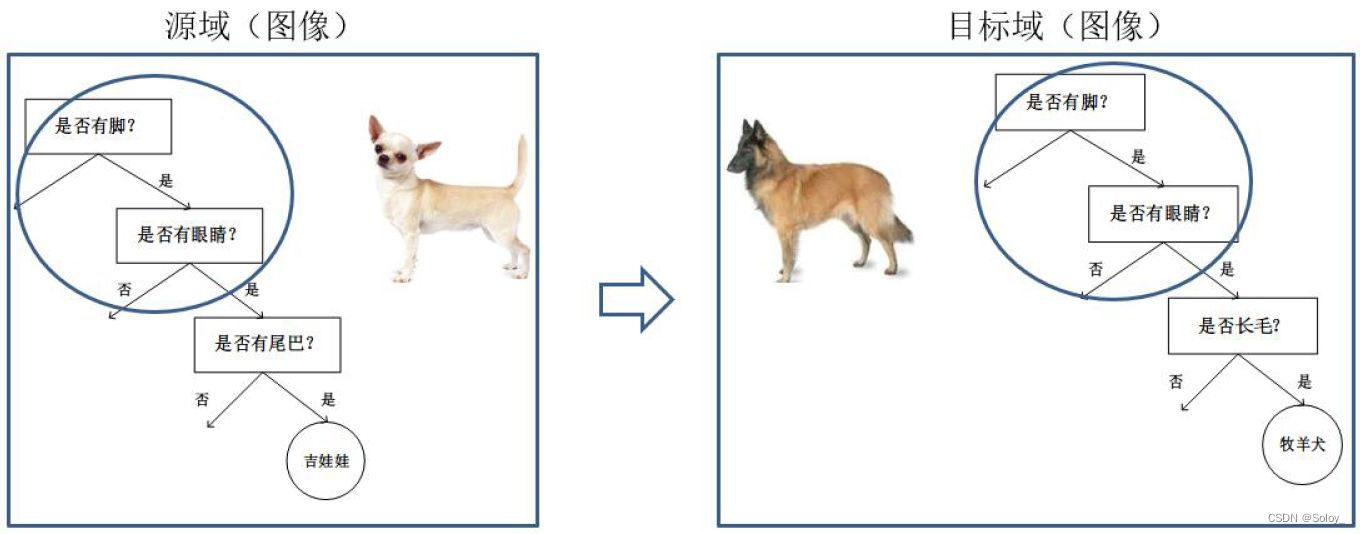
Передача не удалась, повторная загрузка отменена.
- Миграция на основе отношений (TL на основе отношений):использоватьисходная Перенос логических сетевых связей в регионе Трансфер на основе отношений обучениеметод (Relation Based Transfer Learning) Он имеет совершенно иную идею, чем три вышеупомянутых метода. Этот метод более сосредоточен наисходная областьицелевой Связь между образцами домена. На рисунке ниже графически представлено Аналогичные отношения между полями.

Передача не удалась, повторная загрузка отменена.
5. В чем разница между трансферным обучением и традиционным машинным обучением?
трансферное обучение | традиционное машинное обучение | |
|---|---|---|
Распределение данных | Данные обучения и тестирования не обязательно должны быть одинаково распределены. | Данные обучения и тестирования распределяются поровну. |
метка данных | Недостаточно аннотаций данных. | Достаточно аннотации данных |
Моделирование | Можно повторно использовать предыдущие модели | Каждая Задача соответственно Моделирование |
6. Каковы основные критерии и критерии измерения трансферного обучения?
Общую идею трансферного обучения можно резюмировать так::Разработайте алгоритмы для максимизациииспользовать Отмеченоизполеиз Знание,Содействовать приобретению знаний и обучению в целевой области.
трансферное обучение Ядро:找到源полеи目标поле之间изсходство,и разумно использовать его. Это сходство очень распространено. например,Строение тела у разных людей одинаковое, манера езды на велосипеде и мотоцикле схожа, схожи методы игры в бадминтон и теннис. Это сходство также можно понимать как инвариант. Оставаться неизменными в ответ на постоянно меняющиеся изменения.,Только так мы сможем быть непобедимыми.
**При таком сходстве следующим шагом будет Как измерить и использовать это сходство. **Цели измерительной работы преследуют две цели: во-первых, хорошо измерить сходство между двумя областями, не только сообщая нам качественно, схожи ли они, но и количественно определяя степень сходства. Во-вторых, использовать измерение в качестве критерия и увеличить сходство между двумя областями с помощью методов обучения, которые мы хотим использовать, чтобы завершить трансферное обучение。
Резюме в одном предложении: Сходство — это основа, а критерии измерения — важные средства.
7. В чем разница между трансферным обучением и другими концепциями?
- трансферное обучениеимногозадачное обучениесвязь:
- многозадачное обучение:Несколько связанных Задача Учитесь вместе;
- трансферное обучение:Акцент на повторное использование информации,Миграция с одного домена на другой.
- трансферное обучениеиадаптация домена:адаптация домена:Сделать распределение двух функций несовместимымdomainпоследовательный。
- трансферное обучениеиковариационный сдвиг:ковариационный сдвиг:данные Условное распределение вероятностей。
8. При каких обстоятельствах можно использовать трансферное обучение?
трансферное обучениесамые полезные ситуациида,Если попытаться оптимизировать производительность ЗадачаB,Обычно эти «Проблемы» встречаются относительно редко. Например, в радиологии вы знаете, что для создания хорошо работающей радиологической диагностической системы сложно собрать множество рентгенографических сканирований, поэтому в этом случае вы можете поискать родственную, но другую задачу, такую как распознавание изображений, в которой вы можете быть использованы. 1 Он был обучен на миллионах изображений и изучил на них множество низкоуровневых функций, так что это может помочь сети лучше справляться с такими задачами, как радиология, даже если в задаче не так много данных.
Если разница между двумя полями особенно велика,трансферное обучение нельзя использовать напрямую,Потому что в данном случае это не очень хорошо работает. в этом случае,Рекомендую вышеуказанные методы,Шаг за шагом мигрируйте между двумя доменами с низким сходством (пересекая реку, наступая на камни).
9. Что такое тонкая настройка?
сетевойfinetuneМожет бытьда Самый простойиз Глубокая сетевая миграцияметод。Finetune,Также называется тонкой настройкой, тонкой настройкой., Это важная концепция глубокого обучения. Если коротко, тонкая настройка — это использовать обученную другими сеть и настроить ее под свою задачу. Из этого значения нам нетрудно понять, что Finetune – это трансферное часть обучения.
Зачем нужна уже обученная сеть?
В практических приложениях мы обычно не обучаем нейронную сеть с нуля для новой задачи. Очевидно, что такая операция занимает очень много времени. В частности, наши обучающие данные не могут быть такими большими, как ImageNet, чтобы обучать глубокую нейронную сеть с достаточно сильной способностью к обобщению. Даже при таком большом объеме обучающих данных затраты будут невыносимыми, если мы начнем обучение с нуля.
Зачем нужна тонкая настройка?
Потому что модели, обученные другими, могут не полностью подойти для наших собственных задач. Возможно, данные обучения других людей и наши данные не подчиняются одному и тому же распределению; возможно, сети других людей могут делать больше, чем наши задачи; возможно, сети других людей более сложны, а наши задачи проще;
10. Что такое глубокая сетевая адаптация?
глубокая паутина finetune Это может помочь нам сэкономить время обучения и повысить точность обучения. но finetune Имеет свои присущие недостатки: не справляется с обучением и тестированием. данные разные ситуации. Это явление часто встречается в практических приложениях. потому что finetune Основное предположение также заключается в том, что данные обучения и данные тестирования подчиняются одному и тому же Распределению. данных。Этотрансферное Это также неверно и в обучении. Поэтому нам нужно идти дальше и разрабатывать более эффективные методы для глубоких сетей, чтобы лучше выполнять трансферные операции. обучение Задача。
Возьмите Распределение, которое мы представили ранее. Взяв за основу метод адаптации данных, многие методы глубокого обучения разработали уровень адаптации (уровень адаптации) для завершения результата. областьицелевой Адаптация доменных. Адаптация дает возможность исходная областьицелевой домениз Распределение данные находятся ближе, что позволяет сети работать лучше.
11. Применение GAN в трансферном обучении
Генеративно-состязательные сети (GAN) вдохновлены идеей игр двух игроков в теории самоигр. Он состоит из двух частей:
- Одна часть — это генеративная сеть, которая отвечает за создание максимально поддельных образцов. Эта часть называется генератором;
- Другая часть — дискриминационная сеть. Эта часть отвечает за определение того, является ли выборка реальной или сгенерированной генератором. Эта часть называется дискриминатором. Взаимная игра между генератором и дискриминатором завершает состязательное обучение.
GAN Цель ясна: создать обучающие выборки. Похоже это связано с трансферным Большая цель обучения немного другая. Однако, поскольку в трансферном При обучении, естественно, есть исходное поле и целевое поле. Поэтому мы можем избежать процесса генерации выборок и напрямую преобразовать данные в одно из полей. (обычно целевой домен) Относитесь к нему как к сгенерированному образцу. В это время функция генератора меняется. Он больше не генерирует новые выборки, а выполняет функцию извлечения признаков: постоянно изучает характеристики данных домена, чтобы дискриминатор не мог различать два домена. Таким образом, исходный генератор также можно назвать экстрактором признаков. (Feature Extractor)。
12. Реализация кода
Загрузка данных
Inception-v3Модель:Нажмите, чтобы скачать
flower_photosданныенабор:Нажмите, чтобы скачать
Разархивируйте и поместите его в каталог изображений. Путь указан в программе ниже.
import glob
import os.path
import random
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile# Количество узлов на узком уровне Inception-v3Модель
BOTTLENECK_TENSOR_SIZE = 2048
# Имя тензора, представляющего результат слоя узкого места в Inception-v3Model.
# В Inception-v3Model, предложенном Google, имя этого тензора — «pool_3/_reshape:0».
# При обучении Модели вы можете получить имя тензора через tensor.name.
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
# Имя, соответствующее входному тензору изображения.
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
# Загружен каталог файлов модели Inception-v3, обученный Google.
MODEL_DIR = './images/model/'
# Имя файла загруженной модели Inception-v3Model, обученной Google.
MODEL_FILE = 'tensorflow_inception_graph.pb'
# Поскольку данные обучения будут использоваться несколько раз, вектор признаков, рассчитанный с помощью модели Inception-v3 исходного изображения, можно сохранить в файле, чтобы избежать повторных вычислений.
# Следующие переменные определяют адреса хранения этих файлов.
CACHE_DIR = './images/tmp/bottleneck/'
# Папка данных изображений.
# Каждая подпапка в этой папке представляет собой категорию, которую необходимо выделить, и в каждой подпапке хранятся изображения соответствующей категории.
INPUT_DATA = './images/flower_photos/'
# Процент проверенных данных
VALIDATION_PERCENTAGE = 10
# % проверенных данных
TEST_PERCENTAGE = 10
# Определить настройки нейронной сети
LEARNING_RATE = 0.01
STEPS = 4000
BATCH = 100# Эта функция считывает все списки изображений из папки данных и разделяет их по данным обучения, проверки и тестирования.
# Параметрыtest_percentage и validation_percentage определяют размер набора данных тестирования и набора данных проверки.
def create_image_lists(testing_percentage, validation_percentage):
# Все полученные изображения сохраняются в словаре результатов.
# Ключом этого словаря является имя категории, а значением также является словарь, в котором хранятся все названия картинок.
result = {}
# Получить все подкаталоги в текущем каталоге
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# Первый полученный каталог является текущим и его не нужно учитывать.
is_root_dir = True
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
# Получите все допустимые файлы изображений в текущем каталоге.
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
file_list = []
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.'+extension)
file_list.extend(glob.glob(file_glob))
if not file_list:
continue
# Получите имя категории по имени каталога.
label_name = dir_name.lower()
# Инициализируйте набор обучающих данных, набор тестовых данных и набор данных проверки текущей категории.
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name)
# Случайным образом разделите данные на набор обучающих данных, набор тестовых данных и набор данных проверки.
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (testing_percentage + validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
# Поместите данные текущей категории в словарь результатов.
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images
}
# Вернуться ко всем упорядоченным элементам
return result# Эта функция получает адрес изображения по имени категории, набору, к которому оно принадлежит, и номеру изображения.
# Параметр image_lists предоставляет всю информацию об изображении.
# Параметр image_dir указывает корневой каталог. Корневой каталог, в котором хранится изображение, отличается от корневого каталога, в котором хранится вектор признаков изображения.
# Параметр label_name задает название категории.
# Параметр index задает номер изображения, которое необходимо получить.
# Параметр категории указывает, входят ли получаемые изображения в набор обучающих данных, набор тестовых данных или набор данных проверки.
def get_image_path(image_lists, image_dir, label_name, index, category):
# Получите информацию обо всех изображениях в данной категории.
label_lists = image_lists[label_name]
# Получите всю информацию об изображениях в коллекции в соответствии с названием коллекции, к которой она принадлежит.
category_list = label_lists[category]
mod_index = index % len(category_list)
# Получите имя файла изображения.
base_name = category_list[mod_index]
sub_dir = label_lists['dir']
# Конечный адрес — это адрес корневого каталога данных. + папка категории + название картины
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path# Эта функция получает адрес файла вектора объектов после обработки модели Inception-v3 через имя категории, набор данных, к которому он принадлежит, и номер изображения.
def get_bottlenect_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + '.txt';# Эта функция использует загруженную и обученную модель Inception-v3Model для обработки изображения и получения вектора признаков изображения.
def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
# Этот процесс фактически использует текущее изображение в качестве входных данных для расчета значения тензора узкого места. Значение этого тензора узкого места является новым вектором признаков этого изображения.
bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
# Результат, обработанный сверточной нейронной сетью, представляет собой четырехмерный массив, и этот результат необходимо сжать в вектор признаков (одномерный массив).
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values# Эта функция получает вектор признаков изображения, обработанного Inception-v3Model.
# Эта функция сначала попытается найти вычисленный и сохраненный собственный вектор. Если его невозможно найти, она сначала вычислит собственный вектор, а затем сохранит его в файл.
def get_or_create_bottleneck(sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):
# Получите путь к файлу вектора объектов, соответствующему изображению.
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR, sub_dir)
if not os.path.exists(sub_dir_path):
os.makedirs(sub_dir_path)
bottleneck_path = get_bottlenect_path(image_lists, label_name, index, category)
# Если этот файл вектора объектов не существует, вектор объектов рассчитывается с помощью Inception-v3Model, и рассчитанные результаты сохраняются в файле.
if not os.path.exists(bottleneck_path):
# Получить исходный путь к изображению
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
# Получите содержимое изображения.
image_data = gfile.FastGFile(image_path, 'rb').read()
# print(len(image_data))
# Поскольку размер входного изображения непостоянен, полученный здесь размер image_data также несовместим (проверен), но вектор признаков 2048 может быть сгенерирован с помощью загруженной inception-v3Model. Конкретный принцип неизвестен.
# Вычисление векторов признаков с помощью Inception-v3Model
bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor, bottleneck_tensor)
# Сохраните рассчитанный вектор признаков в файл.
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
# Получите соответствующий вектор признаков изображения непосредственно из файла.
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
# Вернуть полученный вектор признаков
return bottleneck_values# Эта функция случайным образом получает пакет изображений в качестве обучающих изображений.
def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many, category,
jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
# Случайным образом добавьте категорию и номер изображения к текущим данным обучения.
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(65536)
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index, category,
jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths# Эта функция получает данные всех тестов. В заключительном тесте необходимо рассчитать показатель точности для всех тестов.
def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
label_name_list = list(image_lists.keys())
# Перечислите все категории и протестируйте изображения в каждой категории.
for label_index, label_name in enumerate(label_name_list):
category = 'testing'
for index, unused_base_name in enumerate(image_lists[label_name][category]):
# Рассчитайте вектор признаков, соответствующий изображению, через Inception-v3Model и добавьте его в окончательный список данных.
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, index, category,
jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype = np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truthsdef main(_):
# Прочитайте все изображения.
image_lists = create_image_lists(TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
n_classes = len(image_lists.keys())
# Прочтите уже обученную Inception-v3Модель.
# Обученная модель Google сохраняется в GraphDef. Protocol В буфере хранится метод расчета каждого значения узла и значение переменной.
# Вопрос персистентности TensorFlow подробно описан в главе 5.
with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# Загрузите прочитанную модель Inception-v3 и верните тензор, соответствующий входным данным, и тензор, соответствующий результату слоя узкого места расчета.
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def, return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME])
# Определите новый вход нейронной сети. Этот вход является значением узла, когда новое изображение достигает уровня узкого места посредством прямого распространения Inception-v3Model.
# Этот процесс можно понимать так же, как извлечение признаков.
bottleneck_input = tf.placeholder(tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder')
# Определить новый стандартный ввод ответа
ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')
# Определите полностью связный слой, чтобы решить новую задачу классификации изображений.
# Поскольку обученная модель Inception-v3 абстрагировала исходное изображение в вектор признаков, который легче классифицировать, нет необходимости обучать такую сложную нейронную сеть для выполнения этой новой задачи классификации.
with tf.name_scope('final_training_ops'):
weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.001))
biases = tf.Variable(tf.zeros([n_classes]))
logits = tf.matmul(bottleneck_input, weights) + biases
final_tensor = tf.nn.softmax(logits)
# Определите функцию потери перекрестной энтропии
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
train_step = tf.compat.v1.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
# Точность расчета
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
tf.global_variables_initializer().run()
# тренировочный процесс
for i in range(STEPS):
# Получайте один пакет обучения каждый раз, когда данные
train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'training', jpeg_data_tensor, bottleneck_tensor)
sess.run(train_step, feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})
# Проверьте точность на проверочном наборе.
if i%100 == 0 or i+1 == STEPS:
validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'validation', jpeg_data_tensor, bottleneck_tensor)
validation_accuracy = sess.run(evaluation_step, feed_dict={
bottleneck_input:validation_bottlenecks, ground_truth_input: validation_ground_truth})
print('Step %d: Validation accuracy on random sampled %d examples = %.1f%%'
% (i, BATCH, validation_accuracy*100))
# Проверьте точность окончательных тестовых данных.
test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess, image_lists, n_classes,
jpeg_data_tensor, bottleneck_tensor)
test_accuracy = sess.run(evaluation_step, feed_dict={bottleneck_input: test_bottlenecks,
ground_truth_input: test_ground_truth})
print('Final test accuracy = %.1f%%' % (test_accuracy * 100))Начни бежать
tf.app.run()


Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
