Лучшие практики проектирования моделей данных HBase
В эпоху больших данных,Все больше предприятий сталкиваются с проблемой обработки и хранения больших объемов данных. HBase,В качестве распределенной базы данных NoSQL на базе Hadoop.,Благодаря своей способности обрабатывать огромные объемы данных и иметь высокую пропускную способность и низкую задержку.,Широко используется в различных сценариях,Такие как анализ данных в реальном времени, онлайн-сервисы, Интернет вещей и т. д. Однако,Как разработать эффективную модель данных, отвечающую потребностям бизнеса,Это по-прежнему основная проблема, с которой сталкиваются многие разработчики. В этой статье мы проанализируем на примерах,лучшая практика, подробно изучающая проектирование модели данных HBase,И в сочетании с примерами кода,Помогите читателям применить эти методы и принципы в реальных проектах.
Принципы проектирования модели данных HBase
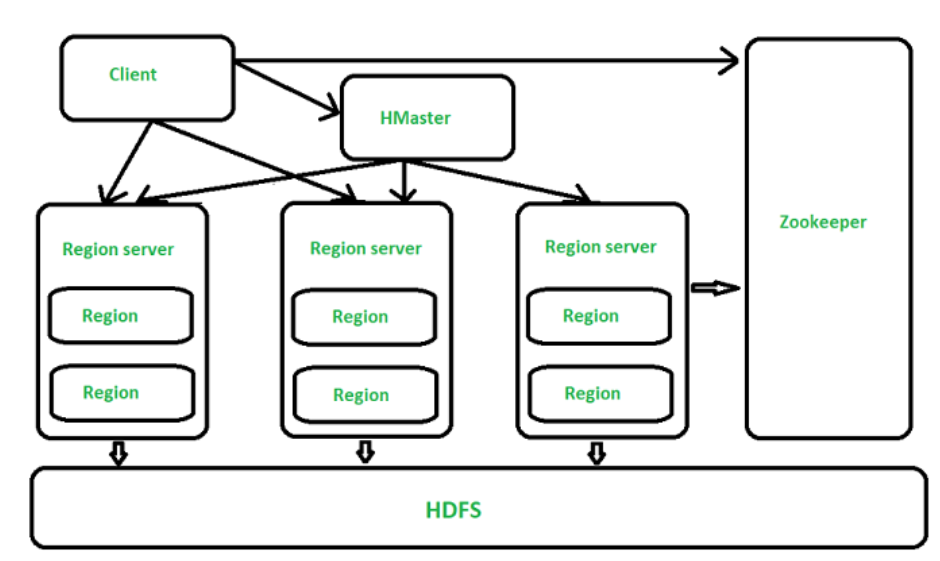
При разработке модели данных HBase необходимо учитывать следующие основные принципы:
принципы проектирования | иллюстрировать |
|---|---|
широкий дизайн стола | Таблицы HBase разрежены, широки и могут иметь несколько семейств столбцов. При разработке модели данных количество таблиц следует максимально сократить, а семейства столбцов и столбцы следует увеличить, чтобы повысить эффективность запросов. |
Дизайн клавиш строки | RowKey — это основа проектирования модели данных HBase. В большинстве сценариев запросов ключи строк используются для поиска данных, поэтому конструкция ключей строк напрямую влияет на производительность запроса. Ключи строк должны быть разработаны так, чтобы избежать проблем с «горячими точками» и поддерживать сканирование на основе префиксов. |
дизайн семейства колонн | Семейство столбцов в HBase — это базовая единица хранения. Столбцы в семействе столбцов должны относиться к одному и тому же типу данных, чтобы избежать ненужного дискового ввода-вывода при чтении. |
Временная метка и управление версиями | HBase поддерживает многоверсионное хранилище данных, что полезно для обработки данных временных рядов или ведения исторических записей. При разработке моделей следует правильно использовать временные метки и контроль версий. |
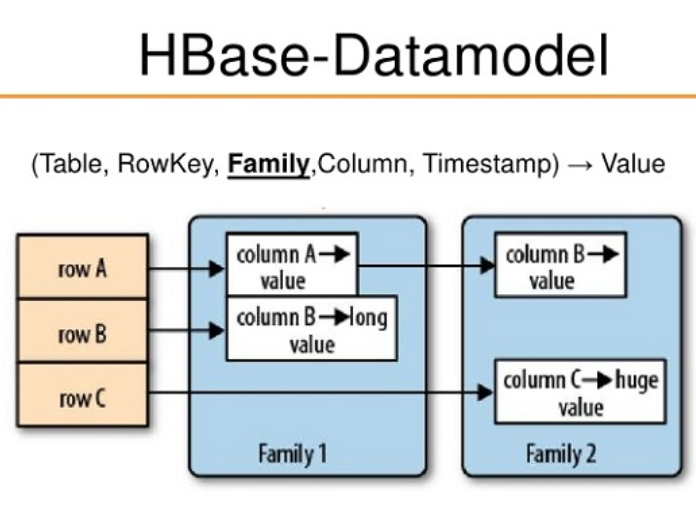
Практический пример: Разработка модели данных для приложений социальных сетей
Предположим, мы разрабатываем приложение для социальной сети, которому необходимо хранить такие данные, как информация о пользователе, его дружеские отношения, сообщения пользователя и его комментарии. На основе этого сценария мы спроектируем модель данных HBase и развернем ее в реальных проектах.
дизайн стола
В приложениях социальных сетей мы можем спроектировать следующие таблицы:
имя таблицы | подробныйиллюстрировать |
|---|---|
users | Сохраняйте основную информацию о пользователе, такую как имя пользователя, адрес электронной почты, время регистрации и т. д. |
friends | Сохраняйте дружеские отношения между пользователями. |
posts | Хранит информацию о публикациях, размещенную пользователями. |
comments | Сохраняет информацию о комментариях под публикацией. |
1 Таблица информации о пользователях (пользователи)
Дизайн таблицы пользовательской информации очень важен.,Потому что он хранит самую основную информацию в социальных сетях。Доступ к ключам строк таблицы можно получить с помощью пользователяID(user_id),Это позволяет быстро находить информацию о пользователе с помощью клавиш строк.。в таблицекланыможно разделить на две категории:personal(персональная информация)иmeta(информация метаданных)。кланыpersonalможет включатьимя пользователя、Электронная почта и т. д.,иmetaМожет включать время регистрации пользователя.、Время последнего входа в систему и т. д.
кланы | Список | подробныйиллюстрировать |
|---|---|---|
personal | username | имя пользователя |
personal | Электронная почта пользователя | |
meta | registration_time | Время регистрации пользователя |
meta | last_login_time | Время последнего входа пользователя |
2 Таблица отношений друзей (друзья)
Таблица отношений друзей используется для хранения отношений между пользователями. В HBase,Размер каждой строки данных влияет на эффективность чтения и записи.,Поэтому объем данных в каждой строке должен быть максимально уменьшен.。мы можемuser_idкак ключ строки,Сохранить дружеские отношения как кланы. Дружба двусторонняя,Однако одностороннее хранилище можно использовать и в реальном хранилище.,То есть записываются дружеские отношения только одной стороны.
кланы | Список | подробныйиллюстрировать |
|---|---|---|
friends | friend_user_id | Идентификатор пользователя друга |
3 Таблица информации о постах (посты)
В таблице информации о сообщениях хранятся сообщения, опубликованные пользователями.。Ключи строк можно использоватьuser_id + post_idкомбинация,Это позволяет быстро найти все публикации, опубликованные пользователем.。кланыможет включатьcontent(Опубликовать контент)иmeta(Метаданные)。contentкланыхранилище Текстовое содержание поста,metaкланыхранилище Время публикации поста、Количество лайков и т. д.
кланы | Список | подробныйиллюстрировать |
|---|---|---|
content | text | Текстовое содержание поста |
meta | post_time | Время публикации поста |
meta | likes | Количество лайков к посту |
4 Информационная форма комментариев (комментарии)
Форма для комментариевхранилище Комментарии под каждым постом。Ключи строк можно использоватьpost_id + comment_idкомбинация,Это позволяет осуществлять эффективный поиски Управление информацией комментариев。кланыможет включатьcontent(Содержание комментария)иmeta(Метаданные)。contentкланыхранилище Текстовое содержание комментария,metaкланыхранилище Когда комментарий был опубликован、Количество лайков и т. д.
кланы | Список | подробныйиллюстрировать |
|---|---|---|
content | text | Текстовое содержание комментария |
meta | comment_time | Время публикации комментария |
meta | likes | Количество лайков на комментарии |
《Дизайн клавиш строкии Стратегия раздела》
В HBase дизайн ключей строк имеет решающее значение, поскольку он напрямую влияет на производительность чтения и записи данных. При проектировании ключей строк следует учитывать следующие моменты:
принципы проектирования | иллюстрировать |
|---|---|
Избегайте острых проблем | Ключи строк следует распределять максимально равномерно, чтобы избежать концентрации большого количества запросов на определенных ключах строк, что приводит к дисбалансу нагрузки на Сервере региона. |
Поддержка сканирования префиксов | Дизайн клавиш линия должна быть максимально поддержана сканирования префиксов,Для повышения эффективности запросов. Например,в таблице пользователей,Можно использовать |
Стратегия раздела | Когда объем данных большой,Рассмотрите возможность разделения ключей строк,для улучшения возможностей параллельной обработки. Например,может быть |
«Дизайн конструкции колонны и оптимизация локальности данных»
В HBase,кланы — это базовая единица физической памяти.,Данные в одних и тех же кланах хранятся вместе. поэтому,При разработке кланов следует попытаться поместить в одни и те же кланы весьма релевантные данные.,для повышения эффективности чтения. в то же время,Избегайте размещения несвязанных данных в одном клане.,Чтобы уменьшить чтение нерелевантных данных.
Например,в таблице пользователей,мы можемпользователяперсональная информация(нравитьсяимя пользователя、электронную почту) и информацию метаданных (например, время регистрации、время последнего входа) хранятся отдельно в разных кланах.
«Управление данными временных рядов и версиями»
HBase поддерживает многоверсионное хранение данных, что особенно полезно при работе с данными временных рядов. Благодаря управлению версиями можно легко выполнить историческое обратное отслеживание и управление несколькими версиями данных.
В приложениях социальных сетей важными сценариями являются управление версиями журналов операций пользователей, публикаций и комментариев. Например, в таблице комментариев мы можем хранить несколько версий количества лайков и времени комментариев для каждого комментария, чтобы анализировать эволюцию комментариев.
Развертывание кода и практика
1 Создание и настройка таблицы HBase
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.TableName;
public class HBaseTableCreation {
public static void main(String[] args) {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Создать таблицу информации о пользователе
TableName tableName = TableName.valueOf("users");
ColumnFamilyDescriptor personalFamily = ColumnFamilyDescriptorBuilder.newBuilder("personal".getBytes()).build();
ColumnFamilyDescriptor metaFamily = ColumnFamilyDescriptorBuilder.newBuilder("meta".getBytes()).build();
TableDescriptor tableDescriptor = TableDescriptorBuilder.newBuilder(tableName)
.setColumnFamily(personalFamily)
.setColumnFamily(metaFamily)
.build();
admin.createTable(tableDescriptor);
// Создайте таблицу отношений друзей
tableName = TableName.valueOf("friends");
ColumnFamilyDescriptor friendsFamily = ColumnFamilyDescriptorBuilder.newBuilder("friends".getBytes()).build();
tableDescriptor = TableDescriptorBuilder.newBuilder(tableName)
.setColumnFamily(friendsFamily)
.build();
admin.createTable(tableDescriptor);
// Создать таблицу информации о публикации
tableName = TableName.valueOf("posts");
ColumnFamilyDescriptor contentFamily = ColumnFamilyDescriptorBuilder.newBuilder("content".getBytes()).build();
metaFamily = ColumnFamilyDescriptorBuilder.newBuilder("meta".getBytes()).build
();
tableDescriptor = TableDescriptorBuilder.newBuilder(tableName)
.setColumnFamily(contentFamily)
.setColumnFamily(metaFamily)
.build();
admin.createTable(tableDescriptor);
// Создайте таблицу с информацией о комментариях
tableName = TableName.valueOf("comments");
contentFamily = ColumnFamilyDescriptorBuilder.newBuilder("content".getBytes()).build();
metaFamily = ColumnFamilyDescriptorBuilder.newBuilder("meta".getBytes()).build();
tableDescriptor = TableDescriptorBuilder.newBuilder(tableName)
.setColumnFamily(contentFamily)
.setColumnFamily(metaFamily)
.build();
admin.createTable(tableDescriptor);
} catch (Exception e) {
e.printStackTrace();
}
}
}2 Вставка и запрос данных
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
public class HBaseDataInsertion {
public static void main(String[] args) {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config)) {
// Вставьте данные пользователя
Table table = connection.getTable(TableName.valueOf("users"));
Put put = new Put(Bytes.toBytes("user1"));
put.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("username"), Bytes.toBytes("john_doe"));
put.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("email"), Bytes.toBytes("john_doe@example.com"));
put.addColumn(Bytes.toBytes("meta"), Bytes.toBytes("registration_time"), Bytes.toBytes("2024-08-27"));
table.put(put);
// Запрос пользовательских данных
Get get = new Get(Bytes.toBytes("user1"));
Result result = table.get(get);
String username = Bytes.toString(result.getValue(Bytes.toBytes("personal"), Bytes.toBytes("username")));
System.out.println("Username: " + username);
} catch (Exception e) {
e.printStackTrace();
}
}
}лучшие практики
В реальных проектах, по мере увеличения объема данных и изменения бизнес-требований, дизайн модели данных HBase также необходимо постоянно корректировать и оптимизировать.
принципы проектирования | иллюстрировать |
|---|---|
Динамическое управление кланом | С разработкой приложений,Возможно, потребуется добавить новые кланы для хранения новых типов данных. на ранних стадиях проектирования,Должно быть место для расширения,для последующих динамических корректировок. |
Дизайн клавиш строк Оптимизация | Если объем данных очень велик, вы можете рассмотреть возможность использования ключей строк раздела (например, хеш-префикса + фактического ключа строки) для дальнейшего улучшения возможностей параллельной обработки системы. |
Управление жизненным циклом данных | Для данных, чувствительных ко времени, вы можете установить TTL (время жизни), чтобы автоматически удалять просроченные данные и снижать нагрузку на хранилище. |
Сочетание кэширования и индексации | Сочетание вторичного индекса и механизма кэширования HBase может эффективно повысить производительность запросов, особенно в сложных сценариях запросов. |
Мониторинг и настройка | Регулярно отслеживайте производительность HBase и вносите коррективы в зависимости от фактического использования, например корректировку размера региона, оптимизацию метода сжатия HFile и т. д., чтобы обеспечить стабильность и эффективность системы. |
HBase — это мощная и гибкая распределенная база данных NoSQL, конструкция ее модели данных напрямую связана с производительностью и масштабируемостью системы.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
