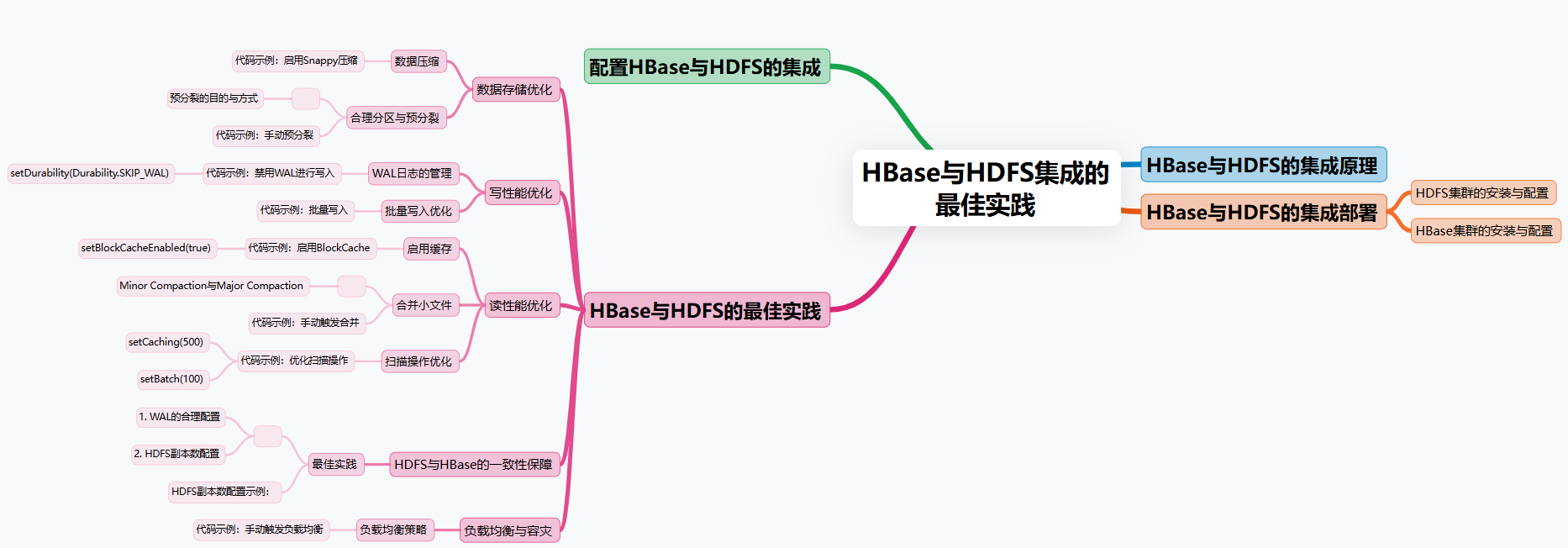
Лучшие практики интеграции HBase с HDFS
С наступлением эры больших данных распределенные системы хранения и вычисления стали основными решениями для обработки данных. HBase и HDFS являются представителями распределенных баз данных NoSQL и распределенных файловых систем соответственно. Они оба произошли от экосистемы Hadoop и часто используются в сочетании. HBase использует HDFS в качестве базовой системы хранения и использует характеристики распределенного хранилища HDFS для обеспечения эффективного произвольного чтения и записи, а также возможностей управления большими объемами данных.
Принцип интеграции HBase и HDFS
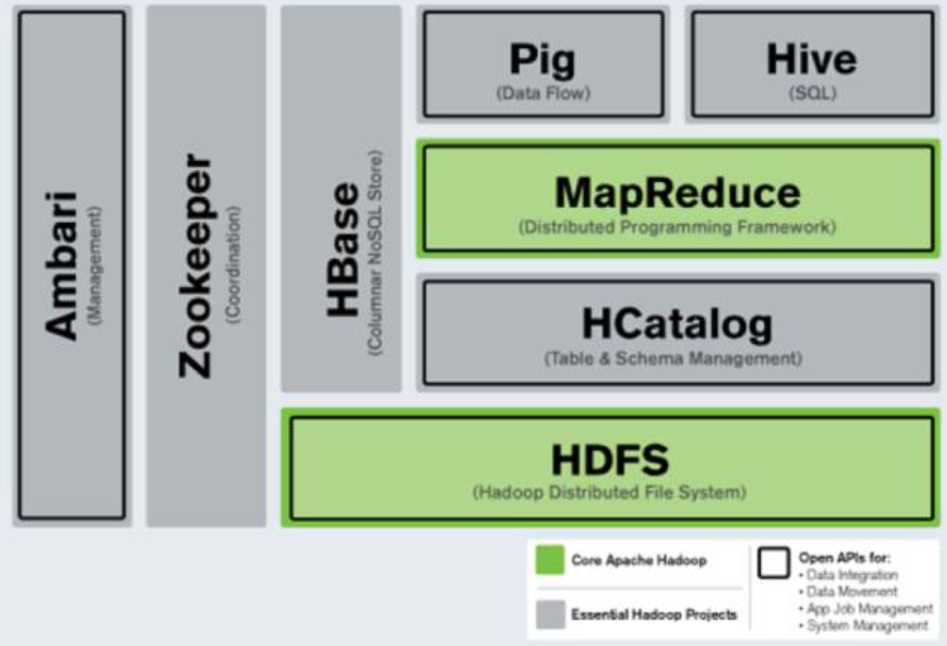
HBase использует HDFS в качестве основного механизма хранения. HBase фрагментирует данные на несколько регионов и сохраняет эти регионы в HDFS. HDFS отвечает за распространение этих файлов региона по нескольким узлам и обеспечивает отказоустойчивость и гарантии высокой доступности. HBase тесно интегрирован с HDFS посредством следующих механизмов:
хранение данных | описывать |
|---|---|
хранение данныхсуществоватьHFileсередина | Данные в HBase хранятся в HDFS в формате HFile. Каждый HFile содержит упорядоченные блоки данных и управляется сервером региона. |
Файлы WAL хранятся в HDFS. | Операции записи HBase сначала записываются в журналы WAL, и эти журналы сохраняются в HDFS, чтобы обеспечить возможности восстановления данных. |
Характеристики HDFS | описывать |
|---|---|
Обеспечить высокую надежность и избыточность данных | HDFS использует избыточность данных (механизм копирования), чтобы гарантировать, что данные не будут потеряны при сбое узла. HBase использует эту функцию для достижения высокой доступности. |
Интегрированное развертывание HBase и HDFS
Установка и настройка HDFS-кластера
Прежде чем приступить к настройке HBase, нам необходимо настроить кластер HDFS. HDFS — один из основных компонентов Hadoop. Мы можем создать HDFS с помощью Hadoop.
Установите Hadoop и настройте HDFS:
# СкачатьHadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
tar -xzf hadoop-3.3.0.tar.gz
cd hadoop-3.3.0
# Отредактируйте файл core-site.xml, чтобы настроить файловую систему HDFS по умолчанию.
nano etc/hadoop/core-site.xml
# Добавьте следующую конфигурацию
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
# Отредактируйте файл hdfs-site.xml и настройте количество копий данных и путь хранения.
nano etc/hadoop/hdfs-site.xml
# Добавьте следующую конфигурацию
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
# Формат HDFS Namenode
bin/hdfs namenode -format
# Запустить HDFS
sbin/start-dfs.shНа данный момент мы успешно развернули кластер HDFS.
Установка и настройка кластера HBase
Настройте HBase и интегрируйтесь с HDFS.
# Скачать HBase
wget https://downloads.apache.org/hbase/2.4.8/hbase-2.4.8-bin.tar.gz
tar -xzf hbase-2.4.8-bin.tar.gz
cd hbase-2.4.8
# Настройка интеграции HBase с HDFS
nano conf/hbase-site.xml
# Добавьте следующую конфигурацию,Убедитесь, что HBase использует HDFS в качестве базового хранилища.
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
</configuration>
# Запустить HBase
bin/start-hbase.shНа этом этапе кластер HBase интегрирован с HDFS и успешно запущен. HBase будет использовать HDFS для хранения своих данных.
Лучшие практики для HBase и HDFS
В крупномасштабных распределенных системах интеграция HBase и HDFS может обеспечить надежную гарантию эффективного хранения и чтения данных. Однако ключом к оптимизации производительности и масштабируемости HBase стало то, как заставить их комбинацию полностью раскрыть свои преимущества посредством настройки и оптимизации. В этом разделе мы рассмотрим несколько ключевых стратегий оптимизации при интеграции HBase и HDFS и подробно продемонстрируем, как применять эти стратегии на примерах кода.
Оптимизация хранения данных
Каждая запись в HBase хранится в виде пар ключ-значение, а данные находятся в семействе столбцов (Column Family) далее делится на несколько столбцов и, наконец, записывается в HDFS в виде файла (HFile). В сценариях крупномасштабной обработки данных организация данных и методы сжатия будут напрямую влиять на эффективность хранения и производительность чтения HBase. Поэтому Оптимизация хранения Данные в основном включают в себя следующие аспекты:
Сжатие данных
Сжатие данных — эффективное средство сокращения использования дискового пространства и повышения эффективности ввода-вывода. В HBase,Семейства столбцов могут включать сжатие для уменьшения размера HFile.,Тем самым уменьшая объем данных на HDFS. HBase поддерживает несколько алгоритмов сжатия.,нравитьсяSnappy、LZO、Gzipждать,другойсжатиеалгоритмсуществоватьсжатие Каждый из них имеет свои особенности с точки зрения скорости и скорости декомпрессии.。
- Snappy:быстрыйсжатие Скорость декомпрессии,Подходит для сценариев с высокой производительностью в реальном времени.,носжатиеставка относительно низкая。
- Gzip:вышесжатие Ставка,Но скорость декомпрессии относительно медленная.,подходит для историихранение данные и другие сцены, не требующие высокой производительности в реальном времени.
Включив соответствующие алгоритмы сжатия, можно не только сократить накладные расходы на хранение HDFS, но и уменьшить объем данных, передаваемых по сети, тем самым повышая эффективность чтения данных.
Пример кода: включить сжатие Snappy
Вот пример кода, как включить сжатие Snappy для таблицы HBase:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.compress.Compression.Algorithm;
public class HBaseCompressionExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Определить имя таблицы
TableName tableName = TableName.valueOf("user_data");
// Таблица определений описывающего персонажа
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// Определите семейство столбцов описывать символ и включите сжатие Snappy.
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
columnDescriptor.setCompressionType(Algorithm.SNAPPY);
tableDescriptor.addFamily(columnDescriptor);
// Если таблица не существует, создайте таблицу
if (!admin.tableExists(tableName)) {
admin.createTable(tableDescriptor);
System.out.println("Table created with Snappy compression.");
} else {
System.out.println("Table already exists.");
}
}
}
}setCompressionType(Algorithm.SNAPPY)Метод включения сжатия Snappy.- Таким образом, HBase будет использовать алгоритм сжатия Snappy в HDFS для сжатия данных, хранящихся в HFile, тем самым снижая нагрузку на хранилище.
Разумное разделение и предварительное разделение
В HBase хранится таблица данные В нескольких регионах регион является базовой единицей горизонтального секционирования HBase. Поскольку данные продолжают расти, регионы будут автоматически разделяться на более мелкие регионы, чтобы сбалансировать каждый регион. Нагрузка на сервер. Однако процесс автоматического разделения может вызвать определенные потери производительности, особенно когда поступает большой объем данных и системе необходимо часто выполнять разделение регионов.
Чтобы решить эту проблему, мы можем предварительно разбить таблицу вручную. Предварительное разделение позволяет заранее разделить регионы в соответствии с диапазоном данных RowKey, тем самым избегая частого автоматического разделения в пиковый период записи данных и улучшая производительность записи всей системы.
Пример кода: предварительное разделение вручную
Следующий код показывает, как создать таблицу с предварительным разделением в HBase:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBasePreSplitExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Определить имя таблицы
TableName tableName = TableName.valueOf("user_data");
// Таблица определений описывающего персонажа
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// Определить семейство столбцов описать символ
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
tableDescriptor.addFamily(columnDescriptor);
// Определите предварительно разделенные диапазоны значений ключей
byte[][] splitKeys = new byte[][] {
Bytes.toBytes("1000"),
Bytes.toBytes("2000"),
Bytes.toBytes("3000")
};
// Если таблица не существует, создайте таблица и предварительное разделение
if (!admin.tableExists(tableName)) {
admin.createTable(tableDescriptor, splitKeys);
System.out.println("Table created with pre-split regions.");
} else {
System.out.println("Table already exists.");
}
}
}
}createTable(tableDescriptor, splitKeys)Метод создания таблицы с предварительным разделением。splitKeysОпределяет предварительно разделенный диапазон RowKey.- Благодаря предварительному разделению данные будут распределяться по разным регионам в соответствии с диапазоном RowKey, что предотвращает концентрацию нагрузки при записи на одном регионе.
Напишите оптимизацию производительности
Производительность операций записи HBase тесно связана с частотой взаимодействия и механизмом управления данными HDFS. В HBase каждая операция записи (Put, Delete и т. д.) сначала записывается в WAL (Write-Ahead Log) записывает журнал операций каждой записи, чтобы облегчить восстановление в случае сбоя системы. Следовательно, оптимизация управления WAL и стратегий записи существенно повлияет на производительность записи HBase.
Управление журналами WAL
WAL HBase записывает журнал каждой операции записи, гарантируя, что в случае сбоя системы данные можно будет восстановить через WAL. Однако в некоторых сценариях приложений, не требующих высокой согласованности данных, вы можете временно отключить журналы WAL, чтобы повысить производительность записи.
Отключение WAL подходит для некоторых сценариев временной загрузки данных или некоторых неосновных бизнес-сценариев, которые могут допустить потерю данных. Следует отметить, что отключение WAL приведет к снижению долговечности данных. При сбое системы данные, не записанные на диск, могут быть потеряны.
Пример кода: отключение WAL для записи
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseDisableWALExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("user_data"))) {
// Создать объект размещения
Put put = new Put(Bytes.toBytes("user1234"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("John Doe"));
// Отключить ведение журнала WAL
put.setDurability(Durability.SKIP_WAL);
// выполнить операцию записи
table.put(put);
System.out.println("Data written without WAL.");
}
}
}setDurability(Durability.SKIP_WAL)Метод используется для отключения журналов WAL, тем самым уменьшая накладные расходы ввода-вывода при записи и повышая скорость записи.- Отключение WAL подходит для сценариев, не требующих высокой надежности данных, и может значительно повысить производительность пакетной записи.
Оптимизация пакетной записи
В сценариях крупномасштабной записи данных запись отдельных записей одна за другой приведет к огромным задержкам в сети и частому дисковому вводу-выводу, что повлияет на эффективность записи. Таким образом, HBase предоставляет механизм пакетной записи, который позволяет объединить несколько операций Put в один запрос и отправить их на региональный сервер в пакетном режиме. Это не только снижает частоту сетевых запросов, но и уменьшает количество операций записи WAL.
Пример кода: пакетная запись
Следующий код показывает, как использовать пакетную запись для повышения производительности записи:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.ArrayList;
import java.util.List;
public class HBaseBatchWriteExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("user_data"))) {
// Создать пакетное размещение объектов
List<Put> putList =
new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
Put put = new Put(Bytes.toBytes("user" + i));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("User " + i));
putList.add(put);
}
// Выполнить пакетную запись
table.put(putList);
System.out.println("Batch write completed.");
}
}
}- Помещая несколько объектов Put в список и отправляя их на региональный сервер в пакетном режиме, количество сетевых запросов и количество записей в журнал WAL сокращается, тем самым значительно повышая производительность записи.
Читать оптимизацию производительности
существоватьбольшойхранение В системе данных также важна оптимизация производительности операций чтения. Глубокая интеграция HBase и HDFS позволяет распределять и хранить данные в нескольких регионах. На сервере в полной мере используйте возможности распределенной файловой системы HDFS. Однако производительность чтения зависит не только от HDFS, но и от того, как данные организованы в HBase и механизма кэширования.
Включить кеширование
HBase предоставляет несколько механизмов кэширования.,Используется для ускорения чтения данных. Например,HBaseизBlockCacheПоследнее прочитанноеизHFileБлокировать кеш в памятисередина,Это ускоряет последующее чтение тех же данных. в то же время,Можно играть на семейном уровне Включить кеширование, чтобы данные автоматически загружались в кэш при чтении.
Пример кода: включить BlockCache
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBaseCacheExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Определить имя таблицы
TableName tableName = TableName.valueOf("user_data");
// Таблица определений описывающего персонажа
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// Определить семейство столбцов описать символи Включить блоккэш
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
columnDescriptor.setBlockCacheEnabled(true); // Включить блоккэш
tableDescriptor.addFamily(columnDescriptor);
// Если таблица не существует, создайте таблицу
if (!admin.tableExists(tableName)) {
admin.createTable(tableDescriptor);
System.out.println("Table created with BlockCache enabled.");
} else {
System.out.println("Table already exists.");
}
}
}
}setBlockCacheEnabled(true)Этот метод используется для включения кэширования на уровне семейства столбцов для повышения производительности чтения.- Когда BlockCache включен, недавно использованные блоки HFile будут кэшироваться в памяти, а последующие запросы на чтение можно будет считывать непосредственно из кэша, чтобы избежать ненужного дискового ввода-вывода, что повышает скорость чтения.
Объединение небольших файлов
В процессе интеграции HBase с HDFS,Большое количество небольших файлов (маленьких HFiles) может вызвать проблемы с производительностью в HDFS.,Особенно при чтении,Слишком много маленьких файлов может вызвать множество случайных операций ввода-вывода.,Уменьшите общую производительность чтения системы. Чтобы решить эту проблему,может пройтиHBaseизУплотнениеПриходить Объединение небольших файлов,Уменьшить фрагментацию файлов,Улучшите непрерывность чтения данных.
HBase поддерживает два типа слияний:
- Minor Compaction:Объединение небольших файлов,Объединение соседних небольших файлов HFile в файлы большего размера.,Однако более старые версии данных не будут удалены.
- Major Compaction:Объединение небольших файлови为一个更большойиздокумент,А избыточные данные старой версии будут удалены.
Пример кода: запуск слияния вручную
Вот пример кода, как вручную запустить операцию слияния:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBaseCompactionExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Определить имя таблицы
TableName tableName = TableName.valueOf("user_data");
// Запустить Major вручную Compaction
admin.majorCompact(tableName);
System.out.println("Major compaction triggered.");
}
}
}admin.majorCompact(tableName)Метод, используемый для запуска Major Сжатие, объединение небольших файлов в файлы большего размера и очистка старых версий данных для повышения производительности чтения.- Операция слияния будет занимать определенный объем системных ресурсов. Рекомендуется выполнять ее при низкой загрузке системы, чтобы не влиять на обычные операции чтения и записи.
Оптимизация операции сканирования
HBaseсерединаизScanОперация используется для чтения серии записей в пакетном режиме.,При чтении большого количества данных,Эффективность операций сканирования имеет решающее значение. Операция сканирования по умолчанию считывает данные один за другим.,А также путем правильной настройки кэша сканирования и размера пакета.,Может значительно улучшить пропускную способность чтения.
- Cache Size:Укажите каждое чтениеизколичество строк,Увеличение количества строк кэша может уменьшить количество строк кэша, связанных с регионом.
- Batch Size:Укажите каждое семейство колонн из каждогосерединачитатьиз Количество столбцов。
Пример кода: оптимизация операций сканирования
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseScanOptimizationExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("user_data"))) {
// Создать объект сканирования
Scan scan = new Scan();
scan.setCaching(500); // Установите размер кэша на 500 строк.
scan.setBatch(100); // Установите размер пакета на 100 столбцов.
// выполнить сканирование
try (ResultScanner scanner = table.getScanner(scan)) {
for (Result result : scanner) {
// Обработка результатов сканирования
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
System.out.println("Row: " + rowKey + ", Name: " + name);
}
}
}
}
}setCaching(500)Этот метод используется для установки количества читаемых каждый раз строк кэша равным 500, чтобы снизить частоту взаимодействия с сервером.setBatch(100)Этот метод используется для установки количества столбцов для пакетной обработки равным 100, чтобы избежать чтения данных по столбцам и повысить производительность чтения.
Гарантия согласованности между HDFS и HBase
Интеграция HBase и HDFS должна учитывать проблемы согласованности данных. HBase по умолчанию обеспечивает постоянство и согласованность данных с помощью механизма WAL (журнал упреждающей записи). Записанные данные сначала будут записаны в WAL, а затем в память HBase. Даже в случае сбоя системы несохраненные данные можно восстановить через WAL.
В дополнение к механизму WAL,Сама HDFS также имеет механизм множественного копирования.,Надежность хранения данных можно дополнительно повысить за счет настройки количества реплик HDFS. Обычно,Количество реплик для HDFS установлено равным 3.,Чтобы гарантировать, что данные имеют копии хранилища на нескольких узлах.,Даже если узел выйдет из строя,Никакие данные также не будут потеряны.
лучшие практики:
- Правильная настройка WAL:существовать Сценарий основных данныхсередина,WAL всегда должен быть включен для обеспечения строгой согласованности данных. Для временных данных или сценариев с низкими требованиями к согласованности,Вы можете пропустить записи WAL в соответствии с потребностями бизнеса.,для улучшения производительности.
- Расположение вторичного номера HDFS:По данным бизнесаиз Требования к надежности,Правильно настройте количество реплик HDFS. Обычно установка 3 является более сбалансированным выбором.,Это обеспечивает надежность данных,Он не будет чрезмерно потреблять ресурсы хранения.
Пример расположения вторичного номера HDFS:
Вы можете передать файл конфигурации HDFS hdfs-site.xml Установите следующие параметры:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>dfs.replicationУстановите значение 3, что означает, что каждые данные будут сохраняться в 3 копиях в HDFS для обеспечения надежности данных.
Балансировка нагрузки и аварийное восстановление
Чтобы улучшить масштабируемость и возможности аварийного восстановления кластера HBase, глубокая интеграция HDFS и HBase обеспечивает хранение данных. нагрузки и аварийное стратегия восстановления. HBase использует регион Данные сервера распределяются по нескольким узлам данных HDFS для достижения балансировки нагрузки. При выходе узла из строя HBase автоматически восстанавливает данные на других доступных узлах, чтобы обеспечить доступность данных.
Стратегия балансировки нагрузки
HBase поддерживает функцию автоматической балансировки нагрузки путем динамического распределения регионов между различными серверами регионов, чтобы обеспечить балансировку нагрузки на каждый сервер. Балансировку нагрузки можно включить вручную или автоматически.
Пример кода: запуск балансировки нагрузки вручную
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBaseLoadBalanceExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// Вручную активировать балансировку нагрузки
admin.balance();
System.out.println("Load balancing triggered.");
}
}
}admin.balance()Этот метод используется для ручного запуска операции балансировки нагрузки. HBase попытается перераспределить регион, чтобы обеспечить равномерное распределение нагрузки на кластер.
Тесная интеграция HBase с HDFS делает их широко используемыми. Данные и обработка имеют сильные преимущества. Путем правильного проектирования таблиц, сжатия, пакетной записи и чтения. оптимизацию производительности Стратегия,HBase может в полной мере реализовать преимущества распределенного хранилища HDFS.,Обеспечивает эффективную производительность чтения и записи в сценариях с большими объемами данных.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
