Лучшие практики Elasticsearch: сравнение стоимости хранилища между разными версиями

Elasticsearch — одно из наиболее широко используемых технических решений в сценариях анализа журналов — часто сравнивают с конкурентами. Особенно по мере увеличения объема данных журналов основные показатели, которые широко сравниваются в сценариях журналов, включают пропускную способность записи данных, стоимость хранения, скорость запросов и возможности анализа. Будучи продуктом, который постоянно обновляется и совершенствуется, Elasticsearch продолжает внедрять различные новые функции в сценарии анализа журналов, чтобы удовлетворить растущие потребности клиентов в сценариях журналов.
Однако конкуренты часто ошибочно используют более ранние версии Elasticsearch для сравнительного анализа, а затем сравнивают показатели и приходят к выводу, что они лучше, чем Elasticsearch. Такое сравнение очень несправедливо и в большинстве случаев вводит в заблуждение. Помните, что версия 6.x устарела, а версия 7.10 выпущена уже давно. Среди 15 версий между 8.8 и 7.10 Elasticsearch выпустил множество функций оптимизации производительности. Поэтому, чтобы помочь пользователям лучше понять функции последней версии Elasticsearch, я буду следовать этой статье в серии статей «Сравнить старые». и новые версии Elasticsearch в различных измерениях, которые помогут нашим пользователям делать более точные оценки и предоставлять точные данные при выборе технологий.
Предварительные условия тестирования
В этой статье мы сравним Elasticsearch по хранению данных журналов и данных метрик.,существовать Версия6、Версия7и Версия8разница между。Уведомление,Вот сравнение,Никакая оптимизация не будет выполняться в Конфигурации.,То есть,Без включения каких-либо опций настройки сцены,Просто сравнение номеров,Потребление хранилища по умолчанию для того же набора данных. И в следующей серии статей,Давайте посмотрим на сценарий,Провести оптимизацию сцены.
Выбор источника данных и версии
Чтобы максимально реалистично представить ситуацию в реальной среде, мы будем использовать Apache SkyWalking showcase Сгенерированные данные журнала и метрик служат нашим источником данных. В выборе Elasticsearch версий мы выбираем наиболее широко используемую версию, не затрагивая все подверсии. Для версии 6.x мы выберем 6.8 в качестве бета-версии, для версии 7.x мы выберем 7.10. В основном это связано с тем, что в версии 7.10 Elastic внес изменение в лицензию, благодаря которому его поддерживают многие поставщики облачных услуг. Elasticsearch версия водораздела. В то же время мы заметили Opensearch Также является ответвлением этой версии. Что касается версии 8.x, мы будем использовать последнюю версию 8.8.1, предоставленную Tencent Cloud.
Конфигурация
В ходе тестирования мы сосредоточимся на SkyWalking Исходная конфигурация была протестирована без какой-либо оптимизации на уровне индекса. Целью этого является убедиться в том, что если мы не овладеем профессиональным Elasticsearch Можно ли достичь ожидаемых результатов, просто обновив Elasticsearch, без знаний по настройке? Этот метод может дать четкие и интуитивно понятные результаты, а также помочь нам понять, как Elasticsearch работает без оптимизации на уровне индекса.
Прежде чем начать тестирование, мы гарантируем, что разные версии кластера используют одну и ту же структуру данных для хранения данных. Это означает, что мы скопируем отображение индекса в три кластера и будем использовать одни и те же данные, то есть запишем одни и те же данные индекса в три кластера.
Здесь мы сначала SkyWalking Запись данных в Elasticsearch 8.8.1 Кластер,Затем выполните зеркалирование данных,Скопируйте данные в кластеры 6.8 и 7.10. так,Структура, количество и содержание данных одинаковы. в то же время,Мы настроим те же параметры сжатия (значения по умолчанию) и выполним объединение сегментов по индексу.
Сравнение данных журналов
Ниже приведена схема данных журнала SkyWalking:
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"oap_log_analyzer": {
"type": "standard"
}
}
}
},
"mappings": {
"_source": {
"excludes": [
"tags"
]
},
"properties": {
"content": {
"type": "text",
"copy_to": [
"content_match"
]
},
"content_match": {
"type": "text",
"analyzer": "oap_log_analyzer"
},
"content_type": {
"type": "integer",
"index": false
},
"endpoint_id": {
"type": "keyword"
},
"service_id": {
"type": "keyword"
},
"service_instance_id": {
"type": "keyword"
},
"span_id": {
"type": "integer"
},
"tags": {
"type": "keyword"
},
"tags_raw_data": {
"type": "binary"
},
"time_bucket": {
"type": "long"
},
"timestamp": {
"type": "long"
},
"trace_id": {
"type": "keyword"
},
"trace_segment_id": {
"type": "keyword"
},
"unique_id": {
"type": "keyword"
}
}
}
}- Этот индекс имеет 5 осколков и 0 реплик.,Использует собственный анализатор
oap_log_analyzer。 - Этот индекс имеет 15 полей,Условно можно разделить на следующие категории:
- Тип текста (текст): эти поля используются для хранения строк, которые необходимо сегментировать.,например
content。Эти поля можно использовать для полнотекстового поиска.、Нечеткое сопоставление и другие операции. - Тип ключевого слова (ключевое слово): эти поля используются для хранения строк, не требующих сегментации слов.,например
endpoint_id、service_idждать。Эти поля можно использовать для точного сопоставления.、сортировать、Агрегация и другие операции. - Числовые типы (целые, длинные и т. д.). Эти поля используются для хранения целых или длинных целых чисел.,например
content_type、span_idждать。Эти поля можно использовать для выполнения числовых сравнений.、запрос диапазона、Агрегация и другие операции. - Двоичный тип (двоичный): эти поля используются для хранения двоичных данных.,например
tags_raw_data。Эти поля не будут индексироваться или искаться.,Может использоваться только для хранения или поиска. - копировать тип (copy_to): эти поля используются для хранения копий значений других полей.,например
content_match。Эти поля можно использовать для выполнения запросов с несколькими полями.。 - Тип анализатора (анализатор): в этих полях указывается, какой анализатор использовать для обработки текста.,например
content_match。В этих полях могут использоваться разные правила сегментации слов, чтобы влиять на результаты поиска.。
- Тип текста (текст): эти поля используются для хранения строк, которые необходимо сегментировать.,например
Пример:
{
"_index": "sw_log-20231023",
"_id": "fe620a61abca48b394358015a04a55b8",
"_score": 1,
"_source": {
"trace_id": "9ad5dfed-1def-4ed3-b233-5dce5afa66c8",
"unique_id": "fe620a61abca48b394358015a04a55b8",
"span_id": 0,
"endpoint_id": "c29uZ3M=.1_VW5kZXJ0b3dEaXNwYXRjaA==",
"service_instance_id": "c29uZ3M=.1_Mzg0ZWZlYWE2NzFjNGFhYjg2ZGFmZjA3OWE4YjljYzZAMTcyLjIyLjAuNg==",
"content": """2023-10-23 23:59:49.247 [TID:9ad5dfed-1def-4ed3-b233-5dce5afa66c8] [XNIO-1 task-2] INFO o.a.s.s.s.s.c.SongController -Listing top songs
""",
"trace_segment_id": "7e097591b9b74531a14df130f17087a8.54.16981055892474632",
"content_type": 1,
"tags_raw_data": "Cg0KBWxldmVsEgRJTkZPClAKBmxvZ2dlchJGb3JnLmFwYWNoZS5za3l3YWxraW5nLnNob3djYXNlLnNlcnZpY2VzLnNvbmcuY29udHJvbGxlci5Tb25nQ29udHJvbGxlcgoXCgZ0aHJlYWQSDVhOSU8tMSB0YXNrLTI=",
"service_id": "c29uZ3M=.1",
"time_bucket": 20231023235949,
"timestamp": 1698105589247
}
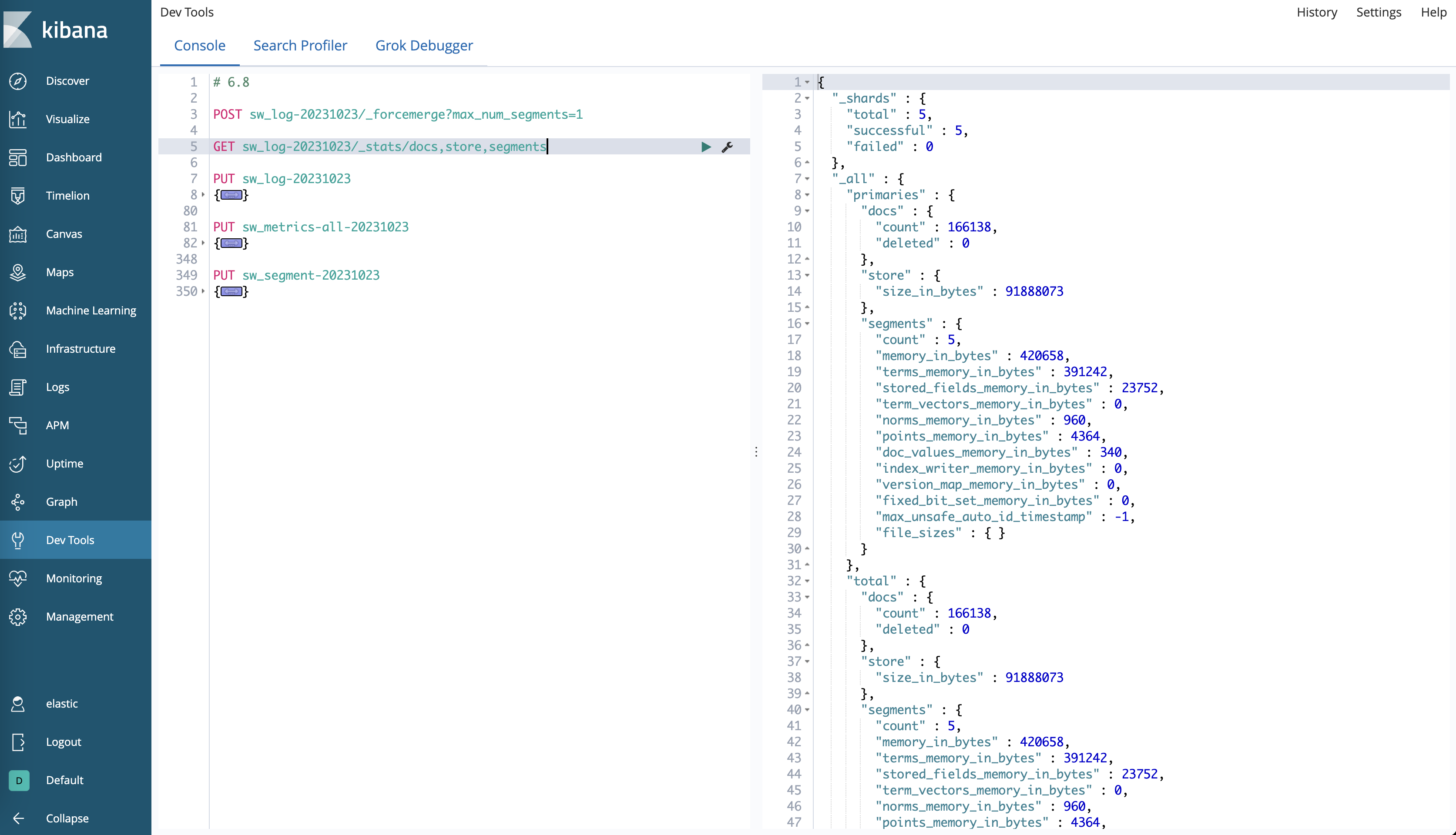
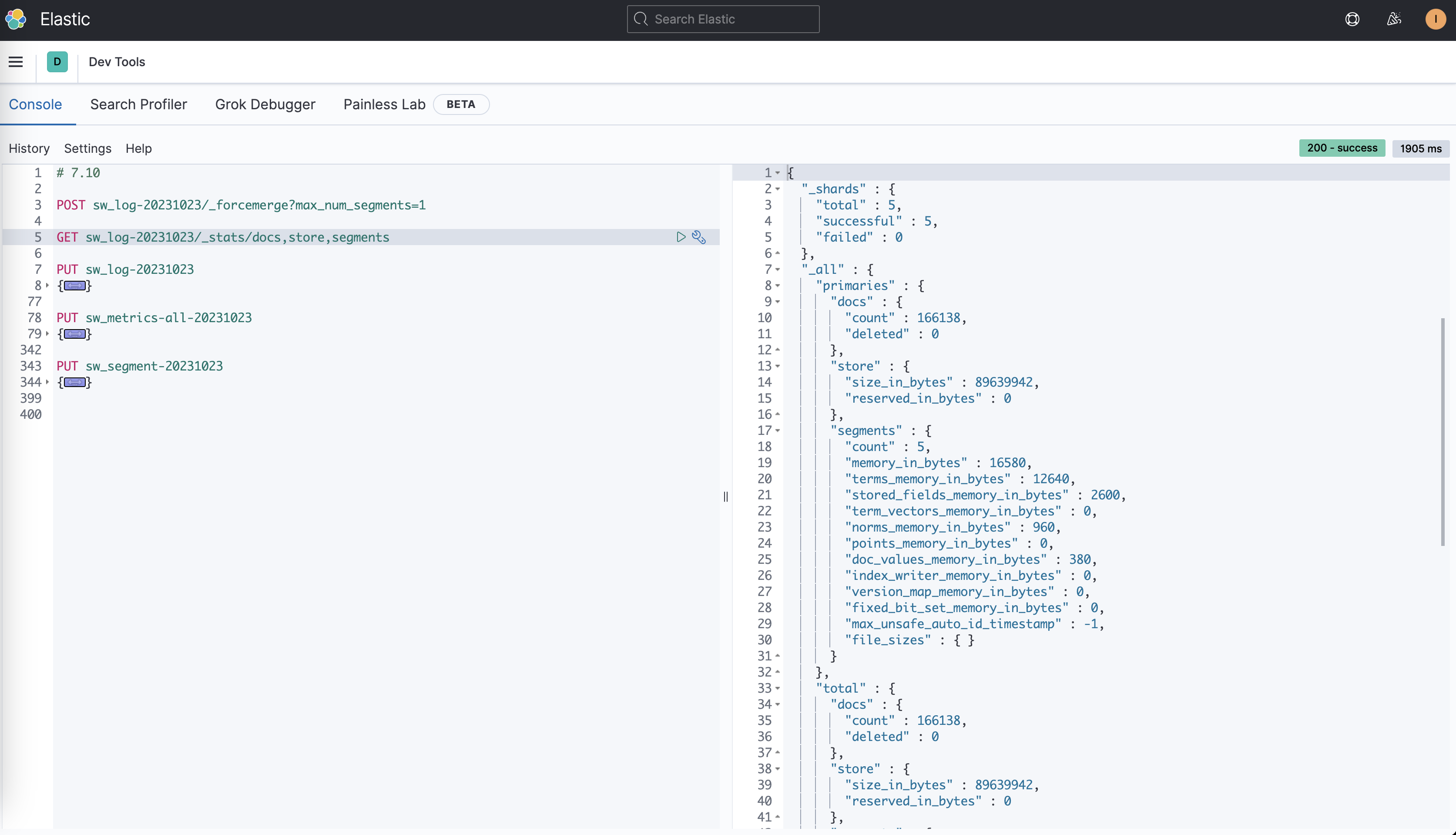
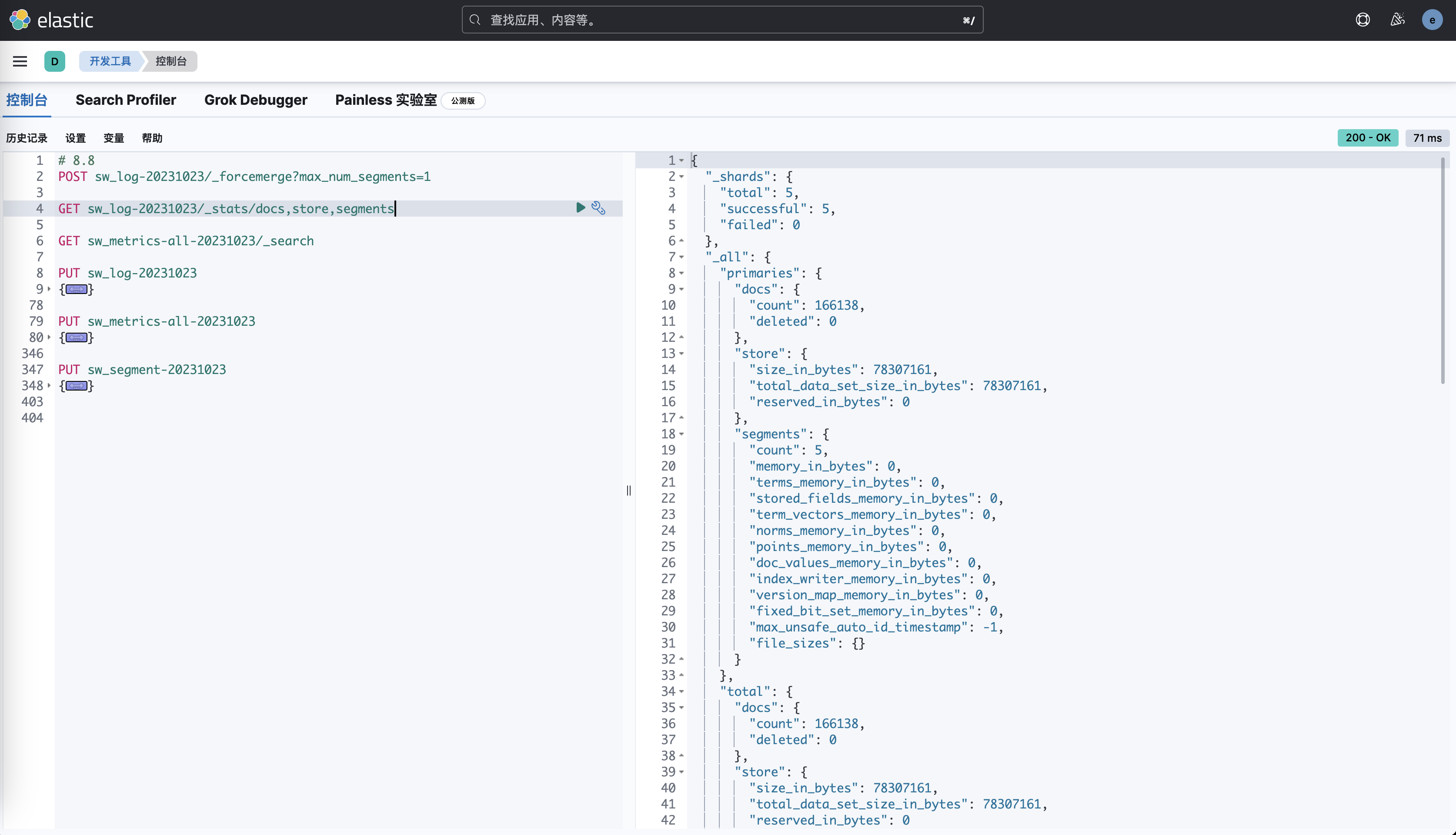
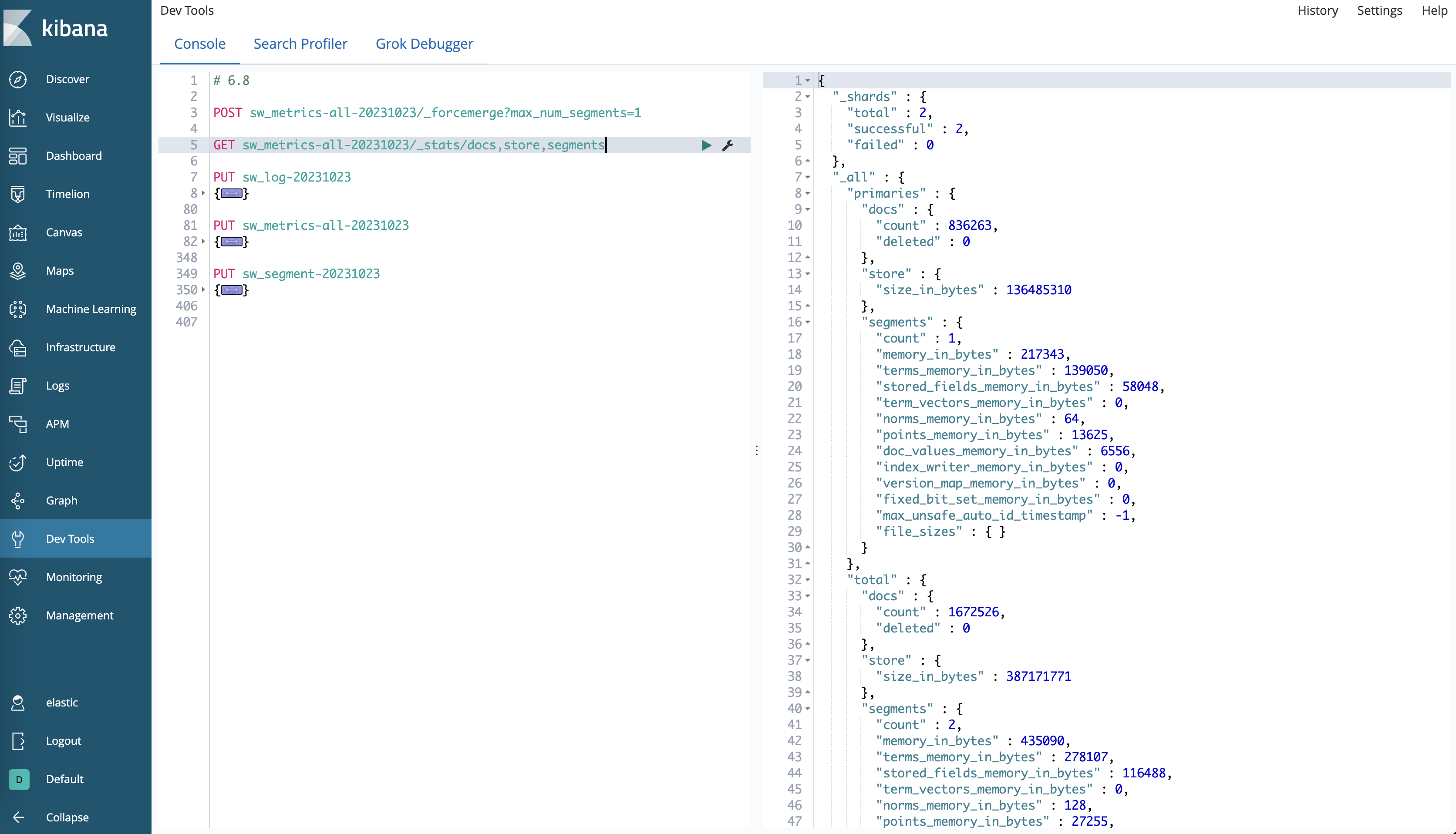
}Мы были в 6,8.,7.10,Запишите те же данные на кластер 8.8.,проходить_stats/store,segmentsинтерфейс,Получаем разницу индексной статистики трех Версий:
Версия | Количество документов | Размер хранилища | количество сегментов | Использование памяти |
|---|---|---|---|---|
6.8 | 166138 | 91888073 байт | 5 | 420658 байт |
7.10 | 166138 | 89639942 байт | 5 | 16580 байт |
8.8 | 166138 | 78307161 байт | 5 | 0 байт |
Как видно из таблицы, вот некоторые основные отличия:
- Размер хранилища уменьшается при обновлении версии.,Это потому, чтоElasticsearchструктура индексаи Алгоритм сжатия оптимизирован.。
- Относительно 6.8Версия,Процент оптимизации хранилища в версии 8.8 составляет ≈14,78%.
- Относительно 7.10Версия,Процент оптимизации хранилища в версии 8.8 составляет ≈12,64%.
- Использование памяти значительно уменьшено с 6,8 до 7,10.,Затем он становится 0, когда достигает 8,8.,Это связано с тем, что Elasticsearch улучшил управление памятью.,То есть выполняется выгрузка кучи,Также изменился способ загрузки
Сравнение данных индикаторов
Ниже приведена схема данных индикатора SkyWalking:
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1,
"analysis": {
"analyzer": {
"oap_analyzer": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"address": {
"type": "keyword"
},
"agent_id": {
"type": "keyword"
},
"component_id": {
"type": "integer",
"index": false
},
"component_ids": {
"type": "keyword",
"index": false
},
"count": {
"type": "long",
"index": false
},
"dataset": {
"type": "text",
"index": false
},
"datatable_count": {
"type": "text",
"index": false
},
"datatable_summation": {
"type": "text",
"index": false
},
"datatable_value": {
"type": "text",
"index": false
},
"denominator": {
"type": "long"
},
"dest_endpoint": {
"type": "keyword"
},
"dest_process_id": {
"type": "keyword"
},
"dest_service_id": {
"type": "keyword"
},
"dest_service_instance_id": {
"type": "keyword"
},
"detect_type": {
"type": "integer"
},
"double_summation": {
"type": "double",
"index": false
},
"double_value": {
"type": "double"
},
"ebpf_profiling_schedule_id": {
"type": "keyword"
},
"end_time": {
"type": "long"
},
"endpoint": {
"type": "keyword"
},
"endpoint_traffic_name": {
"type": "keyword",
"copy_to": [
"endpoint_traffic_name_match"
]
},
"endpoint_traffic_name_match": {
"type": "text",
"analyzer": "oap_analyzer"
},
"entity_id": {
"type": "keyword"
},
"instance_id": {
"type": "keyword"
},
"instance_traffic_name": {
"type": "keyword",
"index": false
},
"int_value": {
"type": "integer"
},
"label": {
"type": "keyword"
},
"labels_json": {
"type": "keyword",
"index": false
},
"last_ping": {
"type": "long"
},
"last_update_time_bucket": {
"type": "long"
},
"layer": {
"type": "integer"
},
"match": {
"type": "long",
"index": false
},
"message": {
"type": "keyword"
},
"metric_table": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"numerator": {
"type": "long"
},
"parameters": {
"type": "keyword",
"index": false
},
"percentage": {
"type": "integer"
},
"precision": {
"type": "integer",
"index": false
},
"process_id": {
"type": "keyword"
},
"profiling_support_status": {
"type": "integer"
},
"properties": {
"type": "text",
"index": false
},
"remote_service_name": {
"type": "keyword"
},
"represent_service_id": {
"type": "keyword"
},
"represent_service_instance_id": {
"type": "keyword"
},
"s_num": {
"type": "long",
"index": false
},
"service": {
"type": "keyword"
},
"service_group": {
"type": "keyword"
},
"service_id": {
"type": "keyword"
},
"service_instance": {
"type": "keyword"
},
"service_instance_id": {
"type": "keyword"
},
"service_name": {
"type": "keyword"
},
"service_traffic_name": {
"type": "keyword",
"copy_to": [
"service_traffic_name_match"
]
},
"service_traffic_name_match": {
"type": "text",
"analyzer": "oap_analyzer"
},
"short_name": {
"type": "keyword"
},
"source_endpoint": {
"type": "keyword"
},
"source_process_id": {
"type": "keyword"
},
"source_service_id": {
"type": "keyword"
},
"source_service_instance_id": {
"type": "keyword"
},
"span_name": {
"type": "keyword"
},
"start_time": {
"type": "long"
},
"summation": {
"type": "long",
"index": false
},
"t_num": {
"type": "long",
"index": false
},
"tag_key": {
"type": "keyword"
},
"tag_type": {
"type": "keyword"
},
"tag_value": {
"type": "keyword"
},
"task_id": {
"type": "keyword"
},
"time_bucket": {
"type": "long"
},
"total": {
"type": "long",
"index": false
},
"total_num": {
"type": "long",
"index": false
},
"type": {
"type": "keyword"
},
"uuid": {
"type": "keyword"
},
"value": {
"type": "long"
}
}
}
}- Этот индекс имеет одну реплику и один шард.,Использует собственный анализатор
oap_analyzer。 - Этот индекс имеет много полей,Условно можно разделить на следующие категории:
- Тип ключевого слова (ключевое слово): эти поля используются для хранения строк, не требующих сегментации слов.,например
address、agent_id、dest_endpointждать。Эти поля можно использовать для точного сопоставления.、сортировать、Агрегация и другие операции. - Тип текста (текст): эти поля используются для хранения строк, которые необходимо сегментировать.,например
dataset、datatable_count、datatable_summationждать。Эти поля можно использовать для полнотекстового поиска.、Нечеткое сопоставление и другие операции. - Числовой тип (целое、long、doubleждать):Эти поля используются для хранения целых чисел или чисел с плавающей запятой.,например
component_id、count、double_valueждать。Эти поля можно использовать для выполнения числовых сравнений.、запрос диапазона、Агрегация и другие операции. - Двоичный тип (двоичный): эти поля используются для хранения двоичных данных.,например
uuid。Эти поля не будут индексироваться или искаться.,Может использоваться только для хранения или поиска. - копировать тип (copy_to): эти поля используются для хранения копий значений других полей.,например
endpoint_traffic_name_match、service_traffic_name_matchждать。Эти поля можно использовать для выполнения запросов с несколькими полями.。 - Тип анализатора (анализатор): в этих полях указывается, какой анализатор использовать для обработки текста.,например
endpoint_traffic_name_match、service_traffic_name_matchждать。В этих полях могут использоваться разные правила сегментации слов, чтобы влиять на результаты поиска.。
- Тип ключевого слова (ключевое слово): эти поля используются для хранения строк, не требующих сегментации слов.,например
Пример данных:
{
"_index": "sw_metrics-all-20231023",
"_id": "meter_datasource_202310230003_c29uZ3M=.1_Mzg0ZWZlYWE2NzFjNGFhYjg2ZGFmZjA3OWE4YjljYzZAMTcyLjIyLjAuNg==",
"_score": 1,
"_source": {
"metric_table": "meter_datasource",
"datatable_summation": "8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-minimumIdle,30|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-threadsAwaitingConnection,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-connectionTimeout,90000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleConnections,30|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleTimeout,1800000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-validationTimeout,15000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-activeConnections,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-leakDetectionThreshold,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-maximumPoolSize,30|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-totalConnections,30",
"datatable_value": "8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-minimumIdle,10|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-threadsAwaitingConnection,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-connectionTimeout,30000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleConnections,10|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleTimeout,600000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-validationTimeout,5000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-activeConnections,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-leakDetectionThreshold,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-maximumPoolSize,10|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-totalConnections,10",
"service_id": "c29uZ3M=.1",
"datatable_count": "8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-minimumIdle,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-threadsAwaitingConnection,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-connectionTimeout,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleConnections,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleTimeout,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-validationTimeout,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-activeConnections,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-leakDetectionThreshold,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-maximumPoolSize,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-totalConnections,3",
"time_bucket": 202310230003,
"entity_id": "c29uZ3M=.1_Mzg0ZWZlYWE2NzFjNGFhYjg2ZGFmZjA3OWE4YjljYzZAMTcyLjIyLjAuNg=="
}
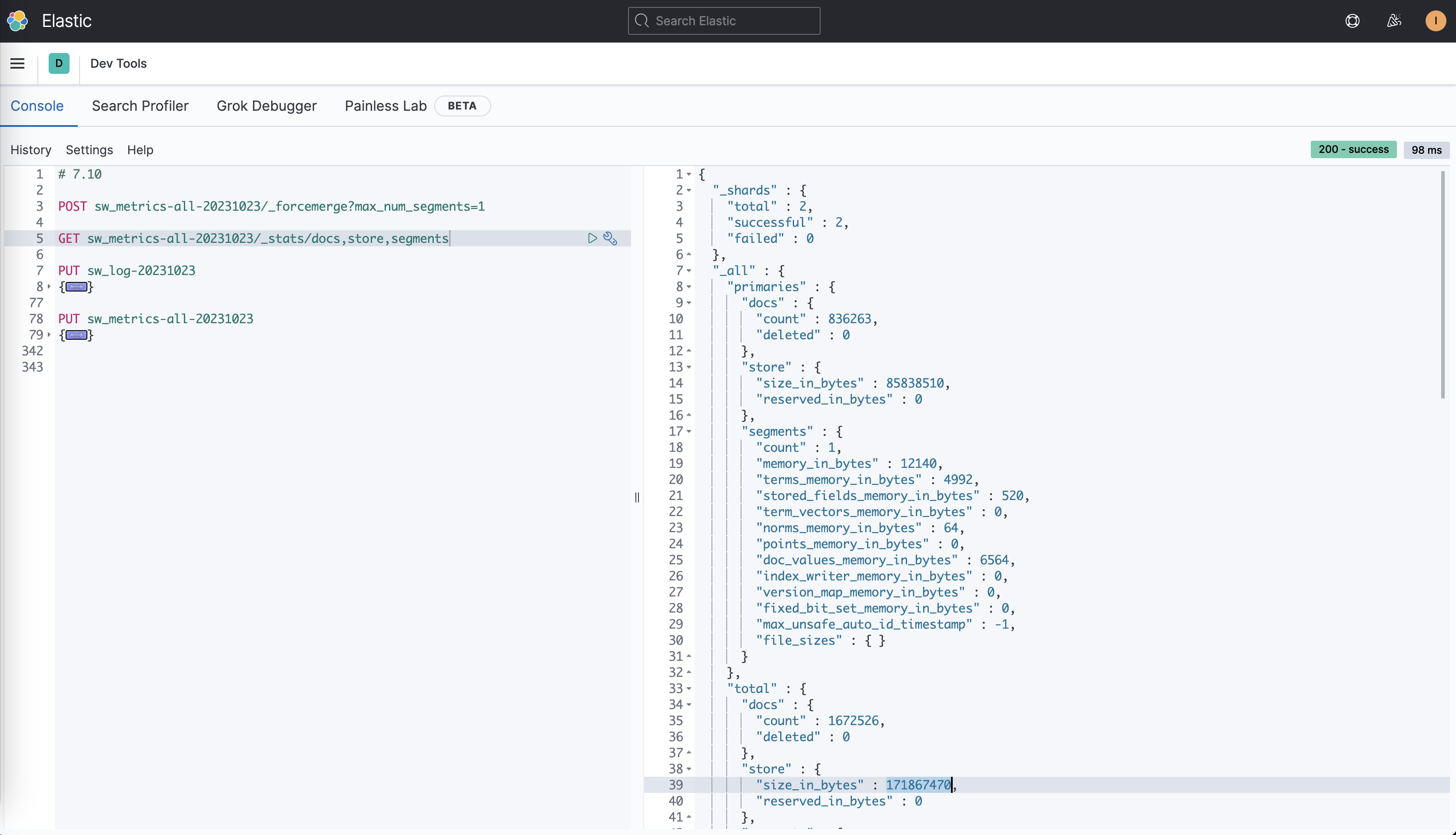
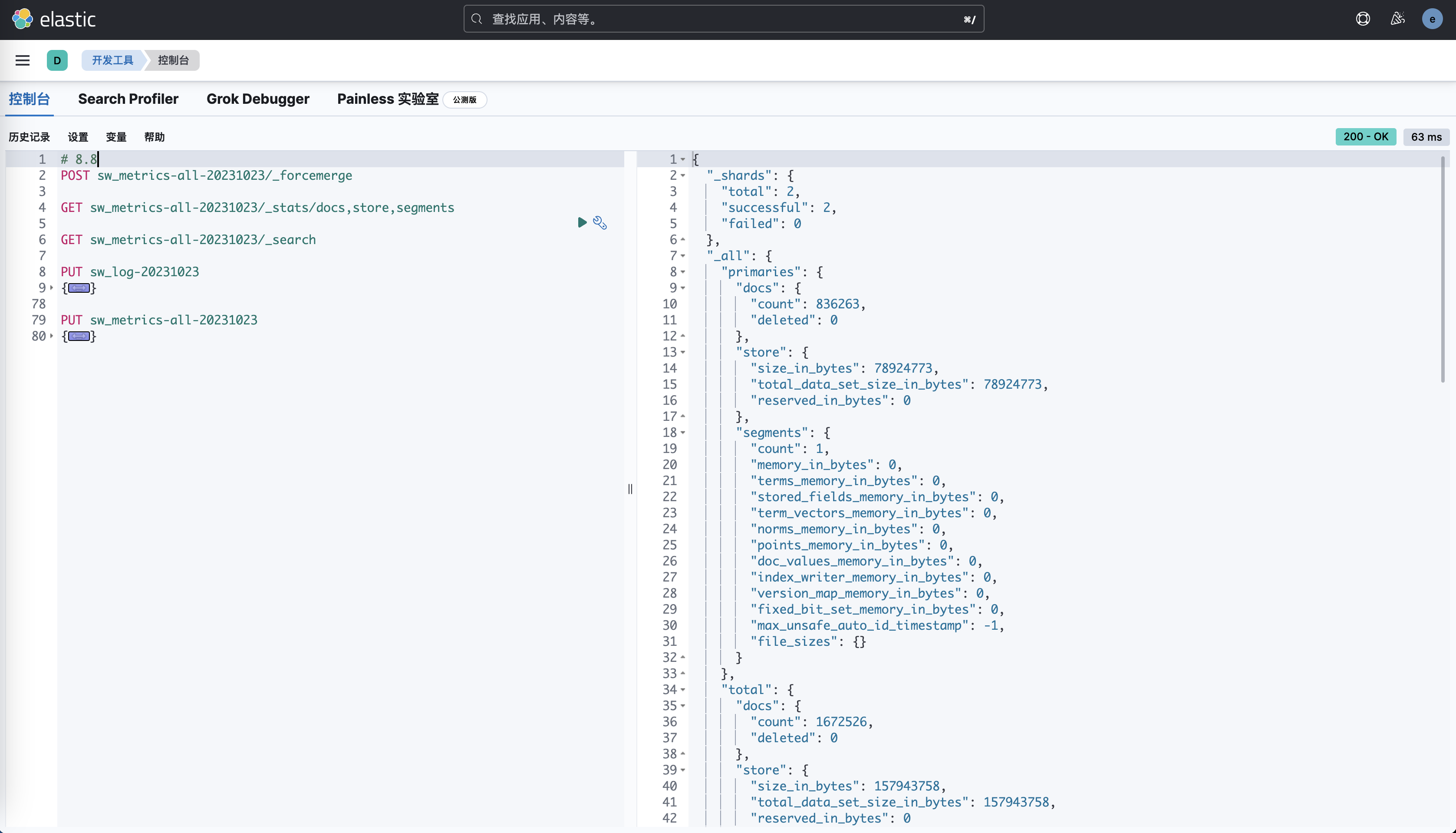
}Мы были в 6,8.,7.10,Запишите те же данные на кластер 8.8.,проходить_stats/store,segmentsинтерфейс,Получаем разницу индексной статистики трех Версий:
Версия | Количество документов | Размер хранилища | количество сегментов | Использование памяти |
|---|---|---|---|---|
6.8 | 1672526 | 273004812 байт | 2 | 43509 байт |
7.10 | 1672526 | 171867470 байт | 2 | 53304 байт |
8.8 | 1672526 | 157943758 байт | 2 | 0 байт |
Как видно из таблицы, вот некоторые основные отличия:
- Размер хранилище уменьшается с обновлением версии, размер 8.8Версия хранилищада157943758 байт,Сравнивать6.8Версияиз Размер хранилищауменьшенный41.2%,Сравнивать7.10Версияиз Размер хранилищауменьшенный8.2%。Это показывает8.8Версиясуществовать Сжатие документови Существует большая разница в оптимизации индекса.изулучшать,Особенно, когда индекс содержит большое количество ключевых слов и числовых полей.
Подвести итог
Elasticsearch Это мощная распределенная система поиска и анализа, которая может помочь пользователям быстро обрабатывать огромные массивы данных журналов и получать ценную информацию. вместе с Elasticsearch Благодаря постоянным обновлениям и оптимизации его производительность в сценариях анализа журналов становится все лучше и лучше, при этом значительно улучшаются объемы памяти, эффективность запросов и функции анализа. В этой статье сравниваются Elasticsearch изтри Версия(6.8、7.10и8.8)существовать По тем же даннымиз Размер индекса,показал имсуществоватьбревно Анализ различий в стоимости хранения в сценариях。
По результатам теста мы видим, что без какой-либо оптимизации:
- бревнов сцене,Относительно 6.8Версия,Процент оптимизации хранения 8.8Версии составляет примерно 14,78%. Относительно 7.10Версия,Процент оптимизации хранилища 8.8Версии составляет примерно 12,64%.от6.8Версияприезжать7.10Версия,Использование Память значительно уменьшена,иприезжать Понятно8.8Версия Тогда это0。Это связано с тем, что Elasticsearch улучшил управление памятью.,Применяется метод загрузки памяти вне кучи.
- существоватьиндексаспект данных,8.8Версия,на 41,2% меньше 6,8Версия,Это снижение на 8,2% по сравнению с версией 7.10.Это показывает8.8Версиясуществовать Сжатие документови索引优化方面有Понятно显著изулучшать,Особенно, когда индекс содержит большое количество полей ключевых слов и числовых типов.
(Обратите внимание, что приведенные выше результаты относятся только к текущим данным испытаний, а фактические результаты могут различаться в зависимости от среды и характеристик данных)
Мы надеемся, что эта статья поможет пользователям лучше понять последние Версия Elasticsearch преимущества и потенциал, а также принимать более обоснованные решения при выборе технологий. Если у вас есть какие-либо вопросы или предложения по содержанию этой статьи, оставьте сообщение в области комментариев, и мы ответим вам как можно скорее. В то же время, пожалуйста, продолжайте обращать внимание на наши статьи по этой серии тем.
Спасибо, что читаете и поддерживаете!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
