Llama2 делает вывод, что RTX3090 превосходит 4090 и имеет превосходную пропускную способность по задержке, но сильно отстает от A800.
Отчет о сердце машины
Монтажер: Ду Вэй, Сяочжоу
Это одна из немногих статей, в которой проводится углубленное сравнение предварительного обучения, тонкой настройки и вывода больших моделей с использованием потребительских графических процессоров (RTX 3090, 4090) и серверных видеокарт (A800).
Большие языковые модели (LLM) добились огромного прогресса как в академических кругах, так и в промышленности. Но обучение и внедрение LLM очень дорогое и требует много вычислительных ресурсов и памяти, поэтому исследователи разработали множество фреймворков и методов с открытым исходным кодом для ускорения предварительного обучения, тонкой настройки и вывода LLM. Однако производительность различных аппаратных и программных стеков во время выполнения может значительно различаться, что затрудняет выбор лучшей конфигурации.
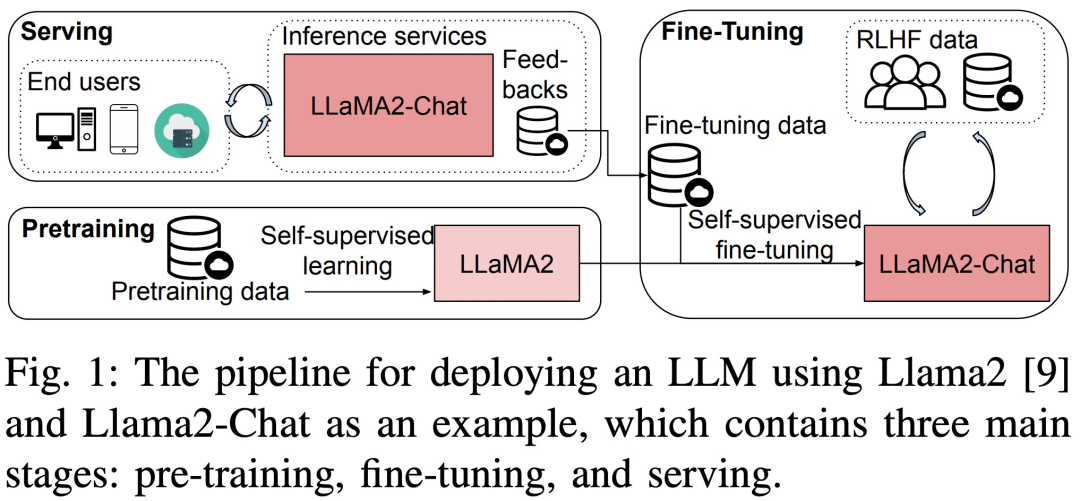
Недавно в новой статье под названием «Анализ производительности обучения, точной настройки и вывода больших языковых моделей во время выполнения» представлен подробный анализ производительности обучения, точной настройки и вывода LLM во время выполнения с макро- и микро-перспектив.

Адрес статьи: https://arxiv.org/pdf/2311.03687.pdf.
В частности, в этом исследовании сначала проводятся сквозные тесты производительности на трех 8-GPU для LLM разных размеров (параметры 7B, 13B и 70B) для предварительного обучения, тонкой настройки и обслуживания с индивидуальной оптимизацией или без нее. платформа, включая ZeRO, количественный анализ, пересчет и FlashAttention. Затем в исследовании представлен подробный анализ времени выполнения подмодулей, включая операторы вычислений и связи в LLM.
Введение метода
Тесты в исследовании основаны на нисходящем подходе и охватывают сквозную производительность шага, производительность времени на уровне модуля и производительность времени оператора Llama2 на трех аппаратных платформах с 8 графическими процессорами, как показано на рисунке 3.
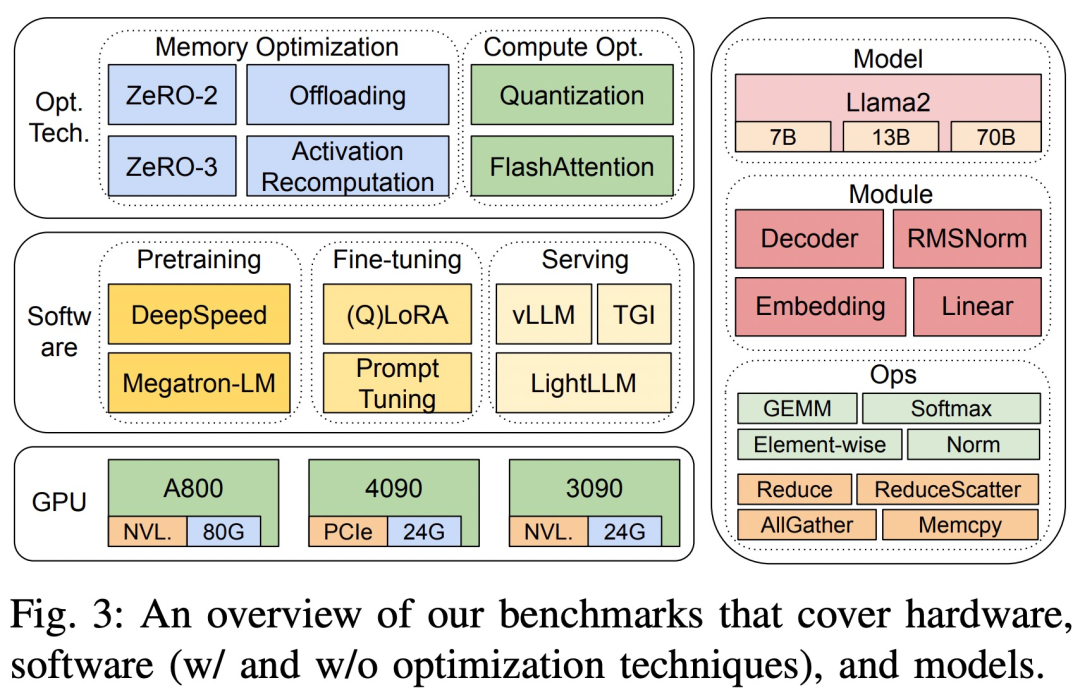
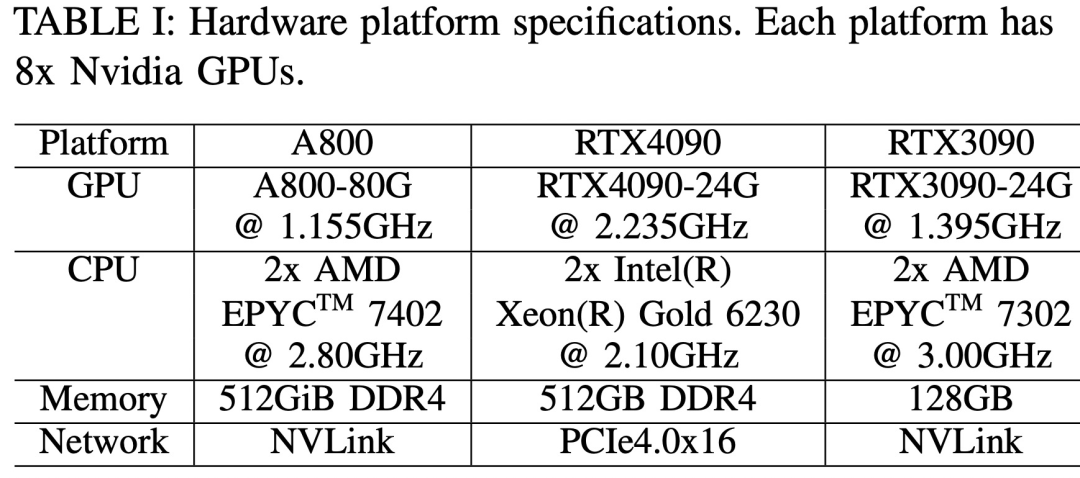
Три аппаратные платформы: RTX4090, RTX3090 и A800. Конкретные характеристики показаны в таблице 1 ниже.
Что касается программного обеспечения, в исследовании сравнивалось время сквозного этапа DeepSpeed и Megatron-LM с точки зрения предварительного обучения и точной настройки. Для оценки методов оптимизации в исследовании использовалась DeepSpeed для включения следующих оптимизаций одна за другой: ZeRO-2, ZeRO-3, разгрузка, повторный расчет активации, квантование и FlashAttention для измерения улучшения производительности и сокращения времени и потребления памяти.
Что касается услуг LLM, существует три высокооптимизированные системы: vLLM, LightLLM и TGI, и в этом исследовании сравнивается их производительность (задержка и пропускная способность) на трех тестовых платформах.
Чтобы гарантировать точность и воспроизводимость результатов, в этом исследовании была рассчитана средняя длина инструкций, входных и выходных данных обычно используемого набора данных LLM «альпака», то есть 350 токенов на выборку, и случайно сгенерированных строк для достижения длины последовательности. из 350.
В службе вывода, чтобы всесторонне использовать вычислительные ресурсы и оценить надежность и эффективность инфраструктуры, все запросы планируются в пакетном режиме. Набор экспериментальных данных состоит из 1000 синтетических предложений, каждое предложение содержит 512 входных токенов. В этом исследовании всегда поддерживается параметр «максимальная длина сгенерированного токена» во всех экспериментах на одной и той же платформе графического процессора, чтобы обеспечить согласованность и сопоставимость результатов.
Сквозная производительность
Это исследование посредством предварительного обучения, тонкой настройки и вывода различных размеров. Llama2 Модель (7Б, 13Б и 70Б) Время шага, пропускная способность и Память потребления и другие показатели для измерения Сквозной на существующей индивидуальной тестовой платформе. производительность. При этом были оценены три широко используемые системы сервисов вывода: TGI, vLLM. и LightLLM,и сосредоточиться насосредоточиться — Включены такие индикаторы, как задержка, пропускная способность и потребление.
Производительность на уровне модуля
LLM Обычно состоит из ряда модулей (или слоев), которые могут иметь уникальные вычислительные и коммуникационные характеристики. Например, составляют Llama2 Ключевые модули модели: Embedding、LlamaDecoderLayer、Linear、SiLUActivation и LlamaRMSNorm。
Результаты предварительной тренировки
существуют предтренировочные экспериментальные занятия,Исследователь сначала проанализировал производительность перед обучением (время итерации или пропускная способность, потребление Память) моделей разных размеров (7Б, 13Б и 70B) на трех тестовых платформах.,Затем было проведено микро-бенчмаркинговое тестирование на уровне модуля и эксплуатации.
Сквозная производительность
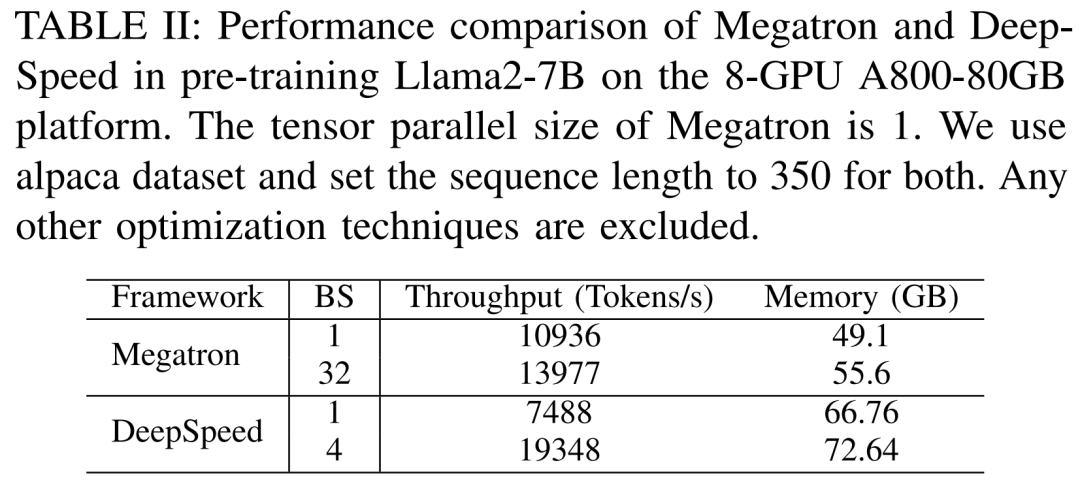
Исследователи впервые провели эксперименты, чтобы сравнить Megatron-LM и DeepSpeed производительность, как в A800- 80GB Предварительное обучение на сервере Llama2-7B без использования каких-либо методов оптимизации памяти (таких как ZeRO)。
Длина последовательности, которую они использовали, была 350 и за Megatron-LM и DeepSpeed Предоставляются два набора размеров партии, начиная с 1 до максимального размера партии. Результаты следующие: II показано в пропускной способности обучения (токены / секунды) и потребительский уровень GPU память (единица ГБ) в качестве эталона.
Результаты показывают, что Megatron-LM немного быстрее DeepSpeed, когда оба размера пакета равны 1. Тем не менее, DeepSpeed является самым быстрым по скорости обучения, когда размер пакета достигает максимального значения. Когда размеры пакетов одинаковы, DeepSpeed потребляет больше памяти графического процессора, чем тензорный параллельный Megatron-LM. Даже при небольших размерах пакетов обе системы потребляли значительные объемы памяти графического процессора, вызывая переполнение памяти на серверах графического процессора RTX4090 или RTX3090.
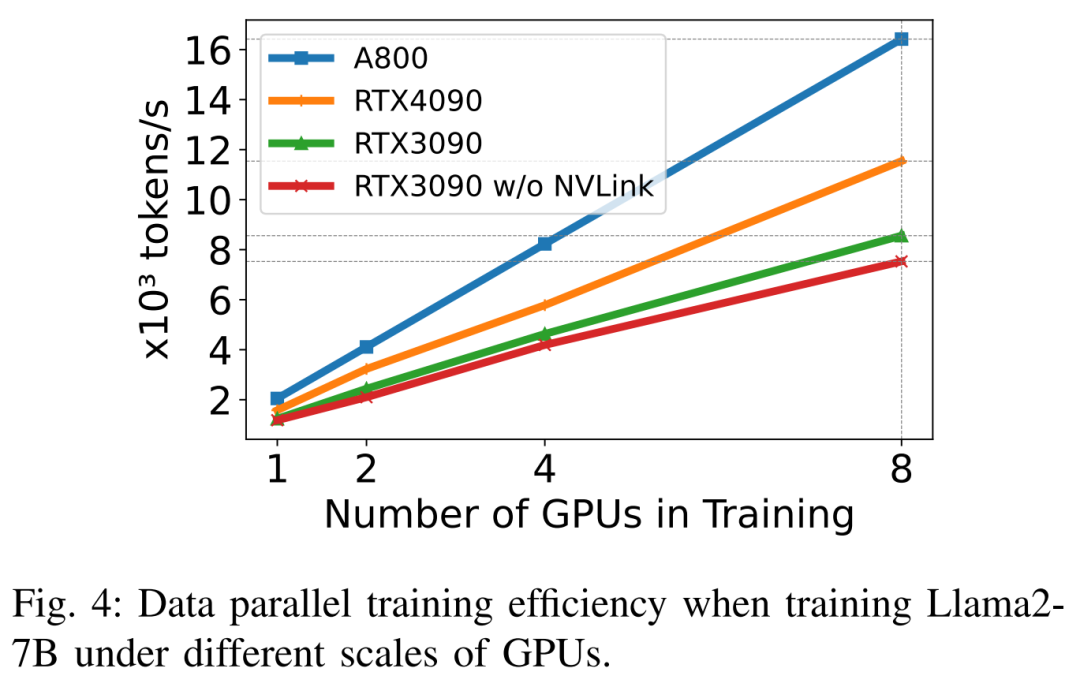
на тренировке Llama2-7B (длина последовательности 350, размер партии 2), исследователь использовал количественные DeepSpeed Изучить эффективность расширения на разных аппаратных платформах. Результат такой, как показано ниже 4 На фото А800 Почти линейное масштабирование, RTX4090 и RTX3090 Эффективность расширения немного ниже, соответственно 90.8% и 85,9%. существовать RTX3090 Платформа, НВЛинк Подключение чем без NVLink Эффективность расширения была улучшена. 10%。
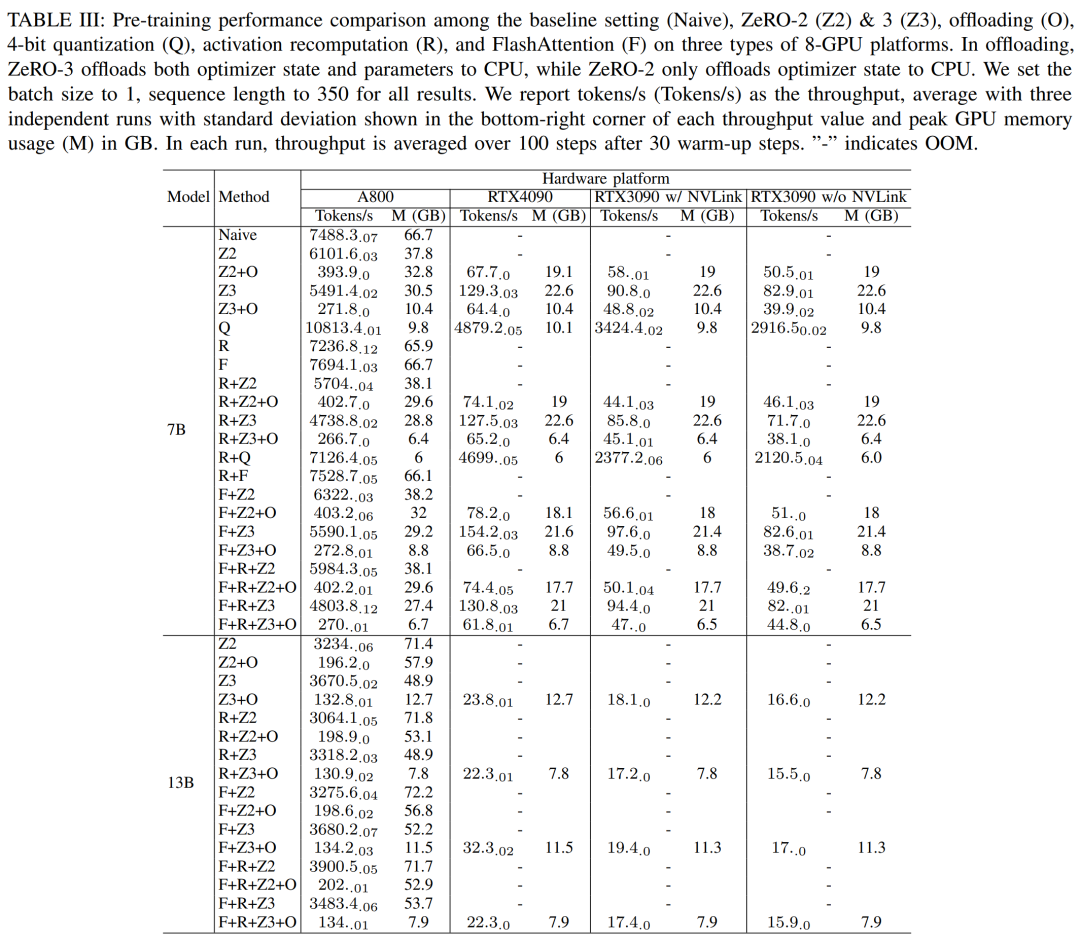
Исследователи используют DeepSpeed Оценить производительность обучения при использовании различных вычислительно эффективных методов Памяти. Для справедливости все оценки имеют длину последовательности 350, размер партии 1. Вес загруженной модели по умолчанию: bf16。
Для тех, у кого есть функция удаления ZeRO-2 и Зе РО-3, это будут оптимизация и оптимизация соответственно + Выгрузите модель в CPU БАРАН. Для квантования они использовали 4bits конфигурация. Также сообщается NVLink Когда недействителен RTX3090 производительность (т.е. все данные проходят через PCIe автобусная трансмиссия). Результаты следующие: III показано.
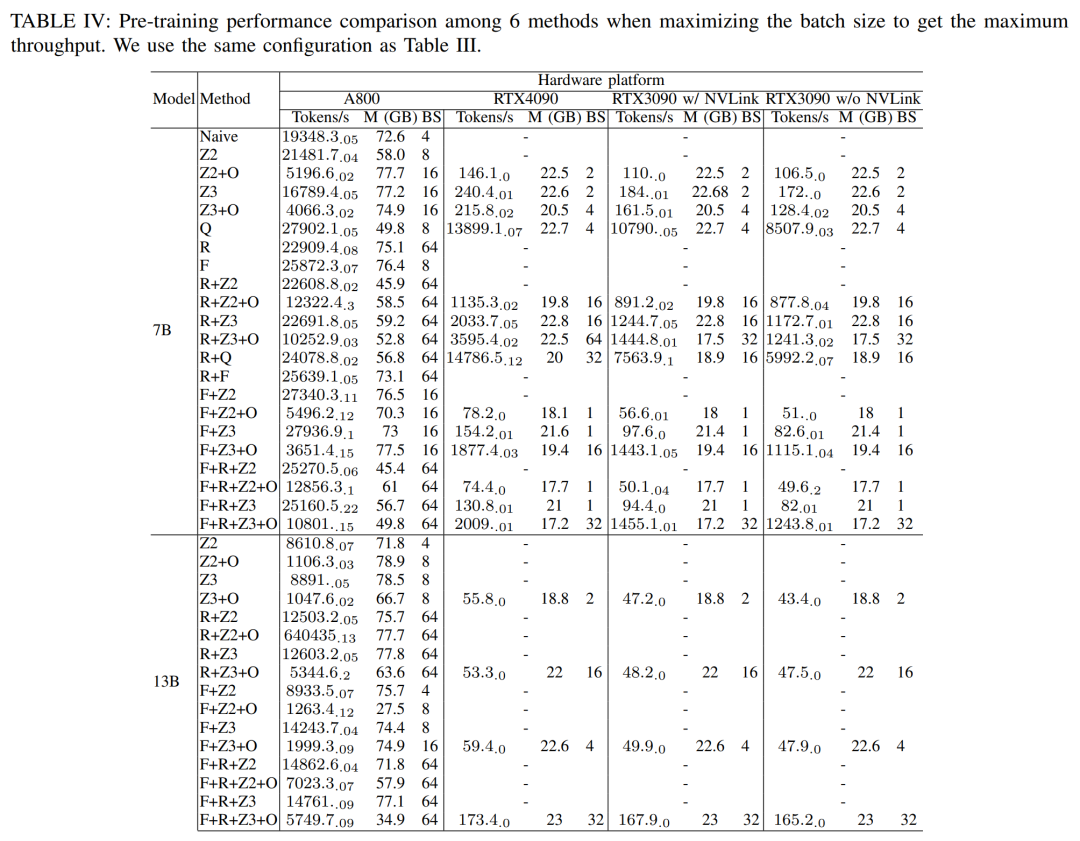
Исследователи далее использовали различные GPU Вычислительная мощность сервера. Результаты следующие: IV Как показано, показано, что увеличение размера пакета может легко улучшить процесс обучения. Таким образом, с высокой пропускной способностью и большой памятью GPU Серверы лучше потребительского уровня GPU Сервер больше подходит для полнопараметрического обучения смешанной точности.
Анализ уровня модуля
таблица ниже V Продемонстрированная одноэтапная предварительная подготовка Llama2-7B Общие и вычислительные затраты времени на прямую и обратную иоптимизацию Модели. Для обратной фазы, поскольку общее время включает в себя неперекрывающееся время, время вычислительного ядра намного меньше, чем для прямой фазы иоптимизации. Если неперекрывающееся время удалить из обратной фазы, это значение станет 94.8。

Перерасчет и влияние FlashAttention
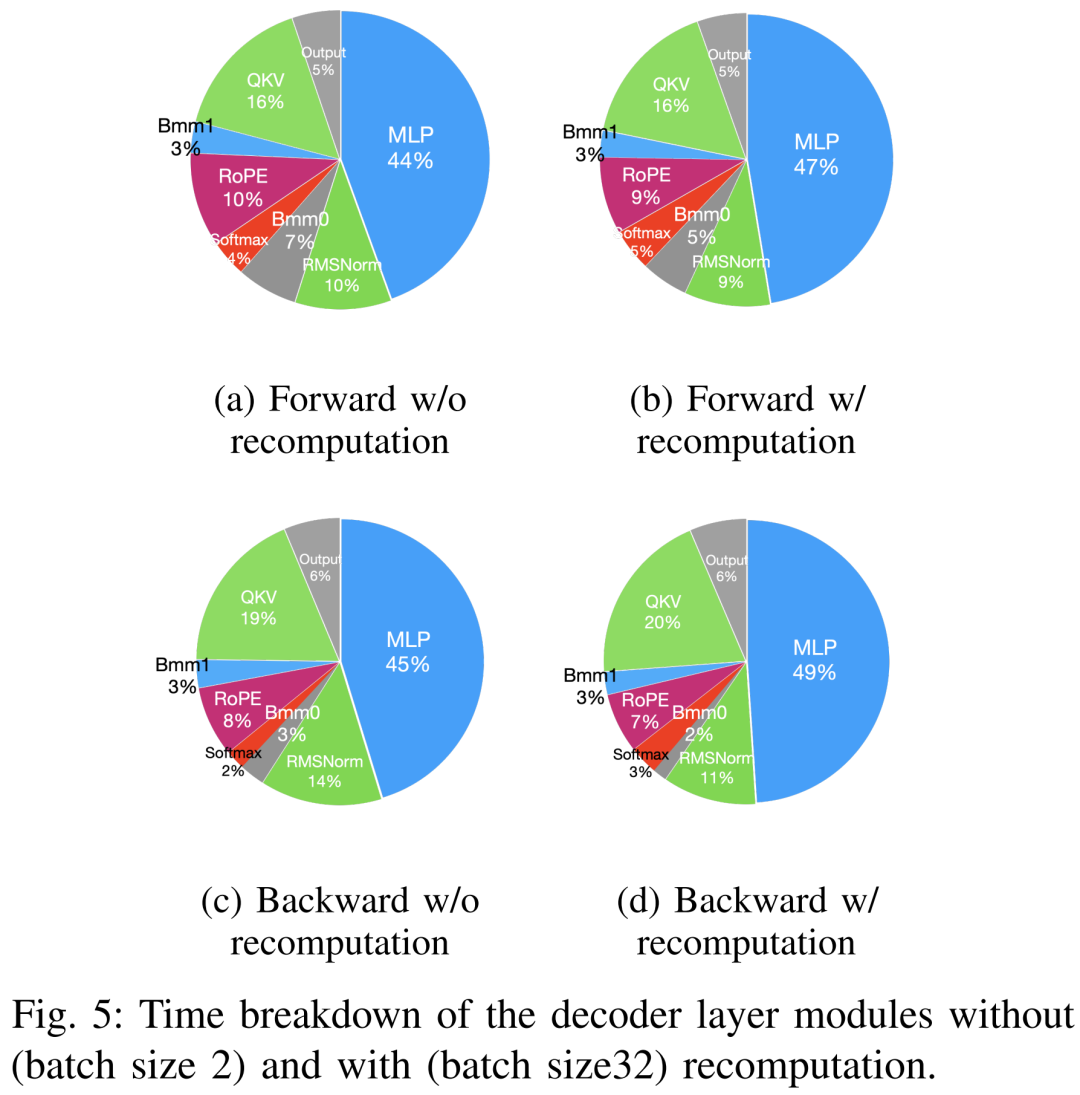
Технологии ускорения предварительного обучения можно условно разделить на две категории: экономия памяти и увеличение размера пакета, а также ускорение вычислительных ядер. Как показано ниже 5 Как показано, графический процессор существуют этапы прямого и обратного устройства иоптимизации. 5-10% времени, проведенного без дела.
Исследователи полагали, что такое время простоя было связано с меньшими размерами партий, поэтому они протестировали все методы с максимально возможным размером партии. Наконец, пересчет используется для увеличения размера пакета, а FlashAttention используется для ускорения расчета анализа керна.
нравитьсятаблица ниже VII Как показано, по мере увеличения размера пакета время прямой и обратной фаз значительно увеличивается, а графический процессор Простоя практически нет.

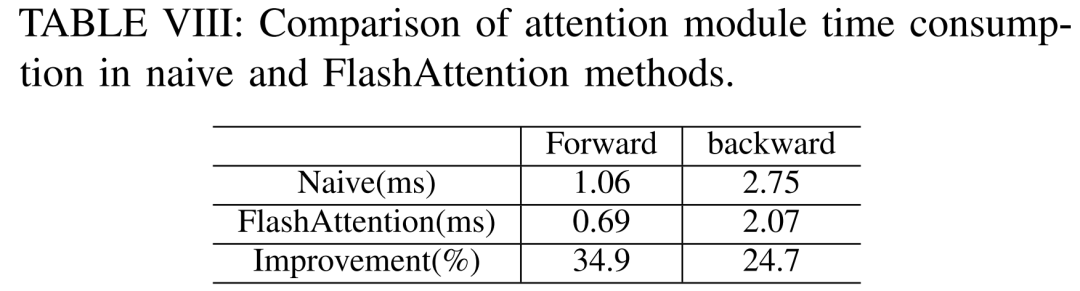
таблица ниже VIII Покажите это FlashAttention Модули прямого и обратного внимания можно ускорять соответственно. 34.9% и 24.7%。
Точная настройка результатов
В ходе сеанса тонкой настройки исследователи в основном обсуждали метод эффективной точной настройки параметров (PEFT) и продемонстрировали LoRA и QLoRA существуют различные размеры модели и тонкая под аппаратными настройками настройкапроизводительность. Используемая длина последовательности равна 350, размер партии 1. По умолчанию веса модели загружаются в bf16。
результатнравитьсятаблица ниже IX показано, используйте LoRA и QLoRA тонкая настройка Llama2-13B тенденции производительности по сравнению с Llama2-7B Будьте последовательны. и lama2-7B Взаимно Сравнивать,тонкая настройка Llama2-13B Пропускная способность упала примерно на 30%。
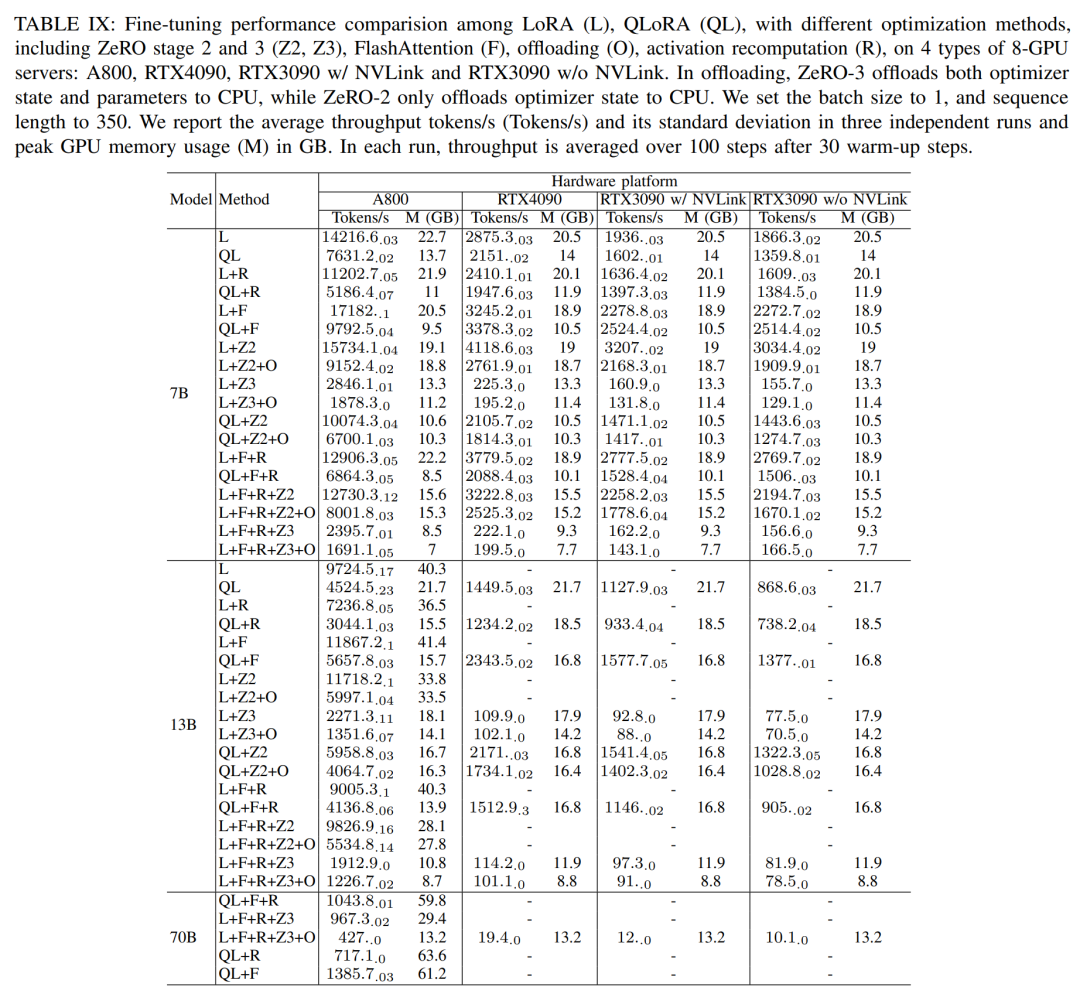
Однако, когда все методы оптимизации объединены, даже RTX4090 и RTX3090 Также тонкая настройка Лама2-70Б, реализована 200 tokens / Общая пропускная способность в секундах.
Результаты вывода
Сквозная производительность
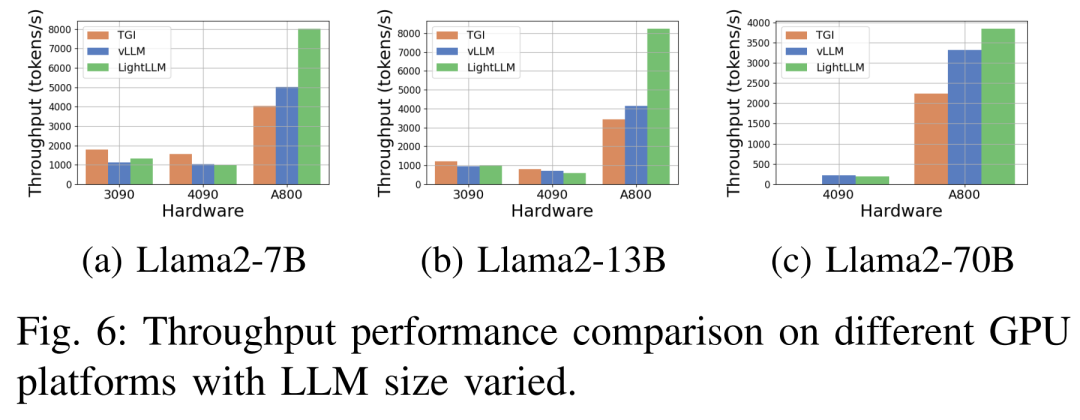
Изображение ниже 6 показывает всесторонний анализ пропускной способности на различных аппаратных платформах и рамку вывода, в которой отсутствует Llama2-70B соответствующие данные вывода. в TGI Фреймворк демонстрирует отличную пропускную способность, особенно RTX3090 и RTX4090 и т. д. есть 24GB память графический процессор. также LightLLM существовать A800 GPU Производительность на платформе значительно лучше, чем TGI и vLLM, пропускная способность увеличивается почти вдвое.
Эти экспериментальные результаты показывают, что TGI рассуждениерамкасуществовать 24GB Память GPU платформа с превосходной производительностью и LightLLM рассуждениерамкасуществовать A800 80GB GPU Демонстрирует самую высокую пропускную способность на платформе. Это открытие показывает LightLLM специально для A800/A100 Серия высокой производительности GPU Оптимизирован.
Характеристики задержки на разных аппаратных платформах и схемах рассуждений следующие: показаны 7, 8, 9, 10.
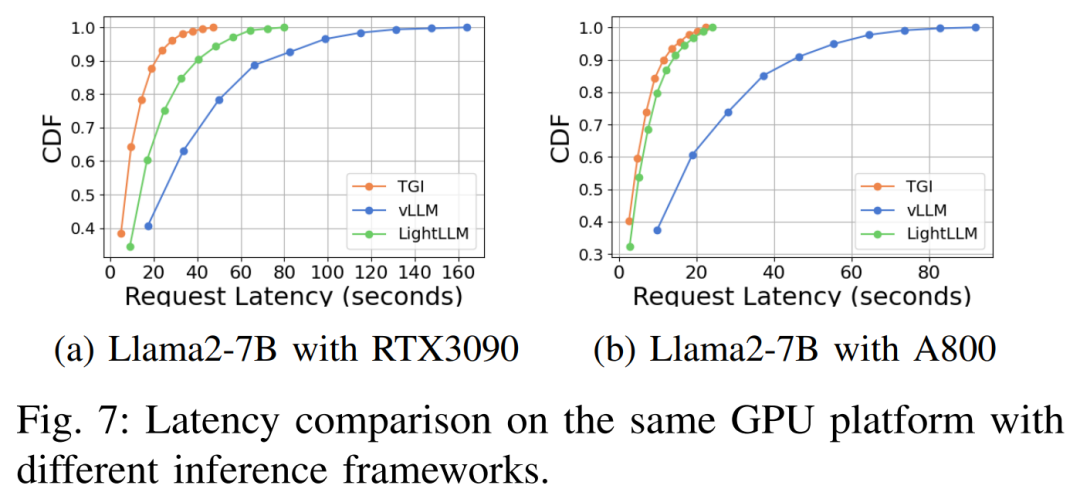
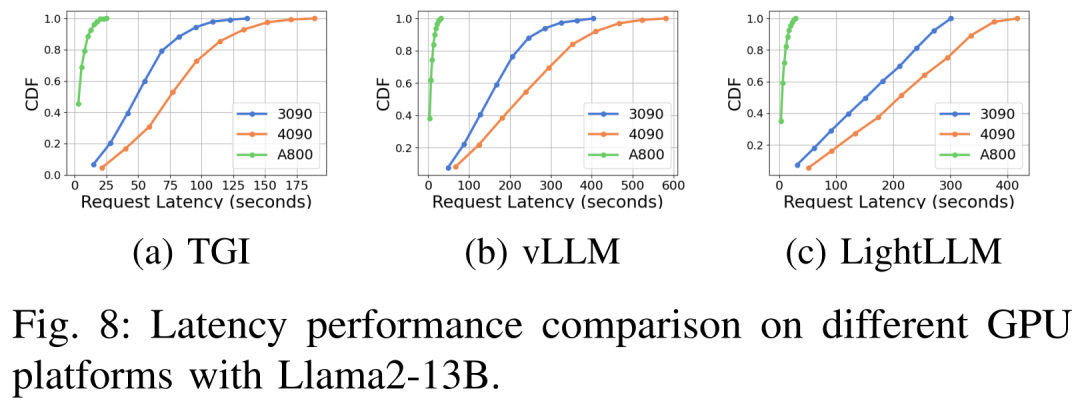
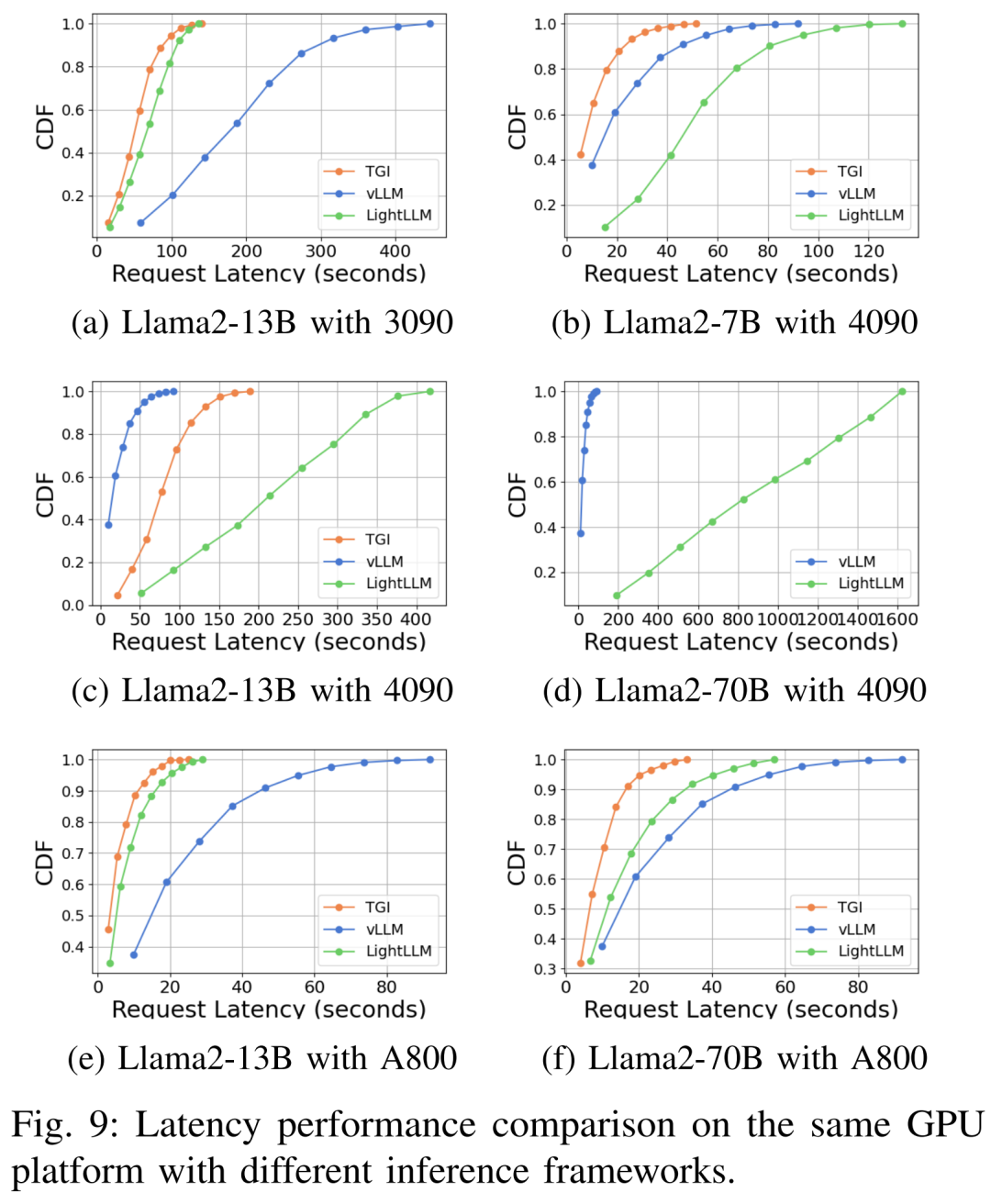
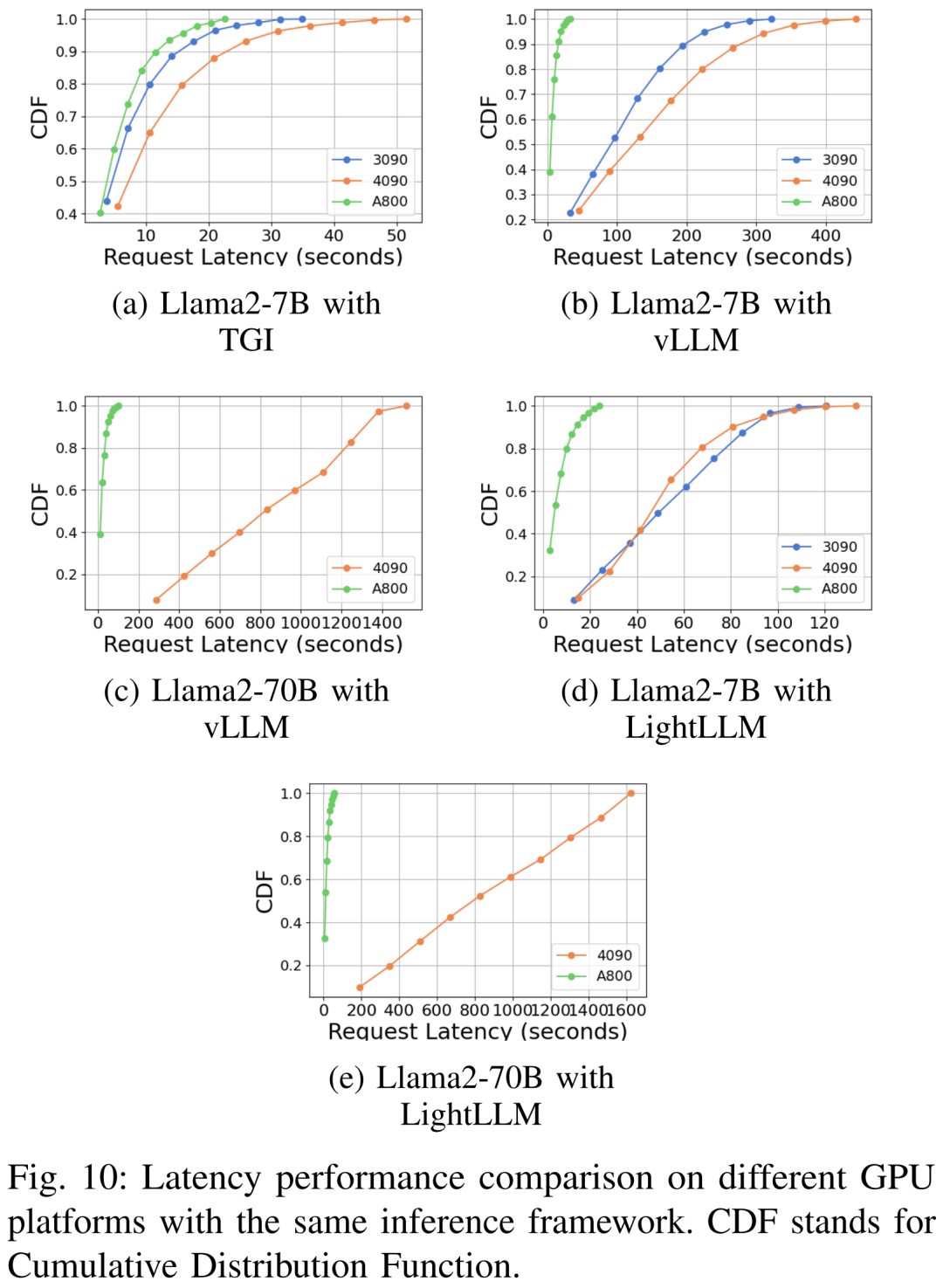
Подводя итог фото А800 Платформа существует, пропускная способность и задержка значительно лучше, чем у RTX4090 и RTX3090 Две платформы потребительского уровня. А среди двух платформ потребительского уровня RTX3090 Сравнивать RTX4090 Небольшое преимущество. При работе на платформе потребительского уровня TGI, vLLM и LightLLM Три индивидуальных вывода не показали существенной разницы с точки зрения пропускной способности. Напротив, ТГИ существование всегда лучше двух других индивидуумов с точки зрения латентности. существовать A800 GPU На платформе LightLLM существующие работают лучше всего с точки зрения пропускной способности, и его задержка также очень близка TGI рамка.
Дополнительные экспериментальные результаты можно найти в оригинальной статье.
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
