Легкое улучшение Yolov8: Ghostnet, G_ghost, семейная битва Ghostnetv2 (2): Huawei Ghostnetv2, новая SOTA в производительности малой модели на стороне устройства
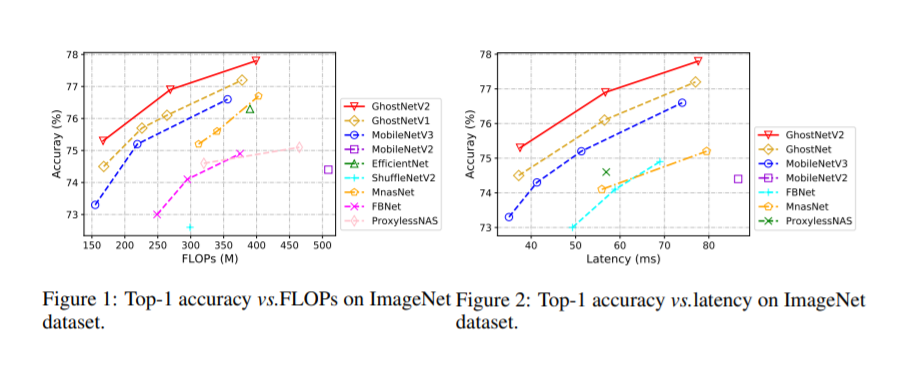
1. Сравнение производительности Ghostnet, G_ghost и Ghostnetv2.
Введенный в yolov8, Bottleneck объединен с c2f, заменяя все c2f в магистральной сети.
layers | parameters | GFLOPs | kb | |
|---|---|---|---|---|
YOLOv8s | 168 | 11125971 | 28.4 | 21991 |
YOLOv8_C2f_GhostBottleneckV2s | 279 | 2553539 | 6.8 | 5250 |
YOLOv8_C2f_GhostBottlenecks | 267 | 2553539 | 6.8 | 5248 |
YOLOv8_C2f_g_ghostBottlenecks | 195 | 2581091 | 6.9 | 5283 |
2. Введение в сеть-призрак

бумага:https://arxiv.org/pdf/2211.12905.pdf
Хотя модуль Ghost может значительно снизить вычислительные затраты, его возможности представления функций также ослаблены, поскольку «операция свертки может моделировать только локальную информацию внутри окна». В GhostNet пространственная информация половины объектов захватывается с помощью дешевых операций (глубинная свертка 3×3), а остальные объекты получаются только с помощью поточечной свертки 1×1, без какой-либо информации, связанной с другими пикселями. общаться. Способность захвата пространственной информации слаба, что может препятствовать дальнейшему улучшению производительности. Работа GhostNetV2, представленная в этой статье, представляет собой расширенную версию GhostNet, принятую в качестве Spotlight в NeurIPS 2022.
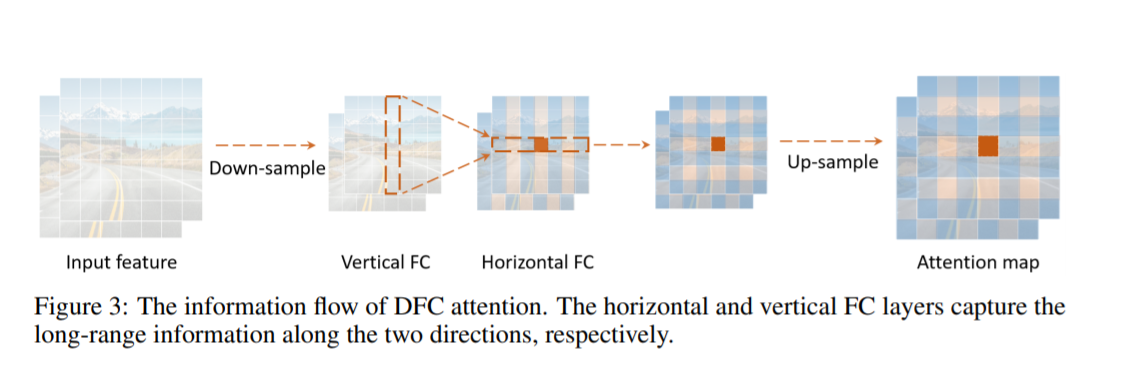
DFC Attention: Модуль внимания на основе разделенного полносвязного слоя
Модуль внимания, подходящий для небольших торцевых моделей, должен отвечать трем условиям:
- Сильная способность моделировать пространственную информацию на больших расстояниях. По сравнению с CNN важной причиной высокой производительности Transformer является то, что он может моделировать глобальную пространственную информацию, поэтому новый модуль внимания также должен иметь возможность захватывать пространственную информацию на больших расстояниях.
- Развертывание эффективно. Модуль внимания должен быть дружественным к аппаратному обеспечению и эффективным в вычислительном отношении, чтобы не замедлять вывод, и, в частности, не должен содержать недружественных к аппаратному обеспечению операций.
- Идея проста. Чтобы обеспечить обобщающую способность модуля внимания, конструкция этого модуля должна быть максимально простой.
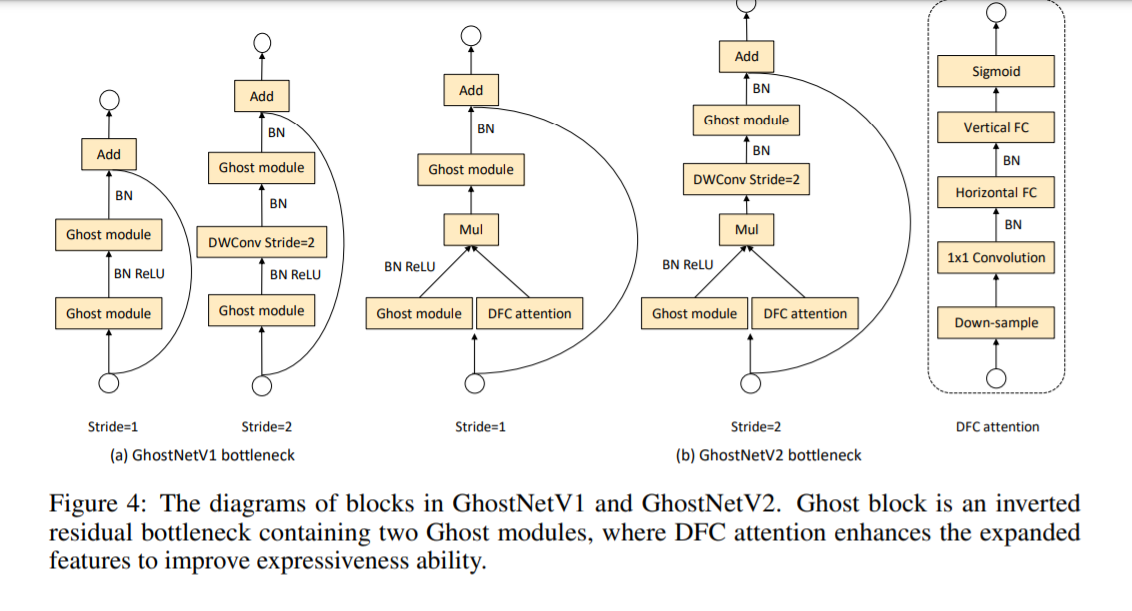
На рисунке 4 ниже схематически показано узкое место GhostV2. Ветка внимания DFC расположена параллельно первому модулю Ghost для расширения расширенных функций. Расширенные функции затем вводятся во второй модуль Ghost для создания выходных функций. Он фиксирует зависимость между пикселями на больших расстояниях в разных пространственных положениях и повышает выразительность модели.
3.Yolov8 представляет Ghostnetv2
3.1 Добавьте ultralytics/nn/backbone/ghostnetv2.py
основной код
class GhostModuleV2(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True, mode=None, args=None):
super(GhostModuleV2, self).__init__()
self.mode = mode
self.gate_fn = nn.Sigmoid()
if self.mode in ['original']:
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
elif self.mode in ['attn']:
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.short_conv = nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(oup),
nn.Conv2d(oup, oup, kernel_size=(1, 5), stride=1, padding=(0, 2), groups=oup, bias=False),
nn.BatchNorm2d(oup),
nn.Conv2d(oup, oup, kernel_size=(5, 1), stride=1, padding=(2, 0), groups=oup, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.mode in ['original']:
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, :self.oup, :, :]
elif self.mode in ['attn']:
res = self.short_conv(F.avg_pool2d(x, kernel_size=2, stride=2))
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, :self.oup, :, :] * F.interpolate(self.gate_fn(res), size=(out.shape[-2], out.shape[-1]),
mode='nearest')Подробности см.:
https://cv2023.blog.csdn.net/article/details/131300994



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
