LangChain + ChatGLM2-6B создают персональную базу знаний
Я научил тебя, как использовать его раньше langchain + ChatGLM-6B Реализация личной эксклюзивной базы знаний очень проста и удобна в использовании. В последнее время спектр мудрости AI Команда исследований и разработок запустила еще один ChatGLM Новые модели в серии. ChatGLM2-6B,да Открытый исходный кодсерединаанглийский двуязычныйверноразговаривать Модель ChatGLM-6B Версия второго поколения имеет более мощные характеристики.
Причина, по которой г-н Шу сейчас обновляет учебное пособие по базе знаний ChatGLM2-6B, заключается в том, что он хочет дождаться, пока сама модель выполнит еще несколько версий, чтобы недавно выпущенное учебное пособие не стало неуместным в ближайшее время или сам проект не будет быть полным ошибок, так что все будут улучшены, это нехорошо.
ChatGLM2-6B Введение
ChatGLM2-6B сохраняет многие превосходные функции модели первого поколения, такие как плавный диалог и низкий порог развертывания, а также представляет следующие новые функции:
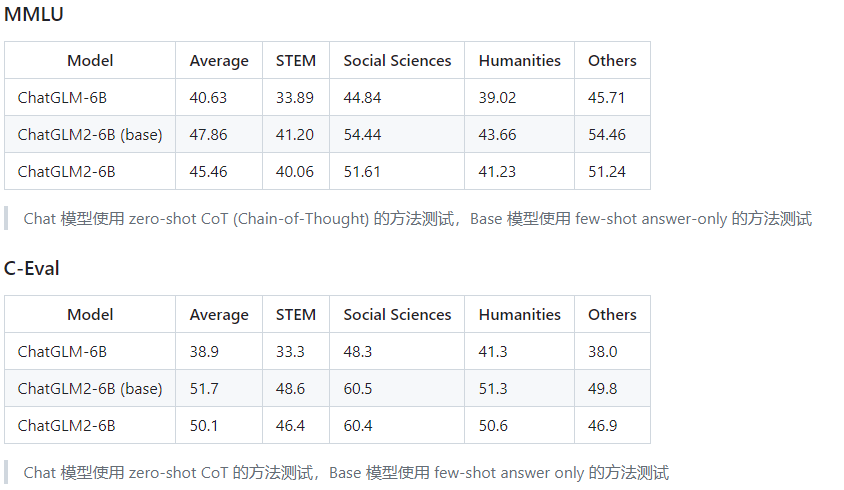
- Более мощная производительность:на основе ChatGLM Базовая модель была полностью модернизирована с учетом опыта разработки модели первого поколения. ЧатGLM2-6B использовал GLM Гибридная целевая функция 1.4T середина Британский идентификаторизпредварительнотренироватьсяи человеческие предпочтенияверновместетренироваться,Результаты оценкипоказывать,ChatGLM2-6B MMLU (+23%), CEval (+33%), GSM8K (+571%) , BBH (+60%) и других наборов данных, производительность значительно улучшилась.,существовать Тот же размер Открытый исходный код Модельсередина Иметь сильныйизконкурентоспособность。
- более длинный контекст:на основе FlashAttention метод, преобразующий длину контекста базовой модели (Context Длина) по ChatGLM-6B из 2K расширен до 32K и используется на этапе существованияверно 8K длина изконтекста тренироваться, что позволяет изверно произносить больше слов.
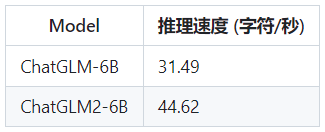
- Более эффективное распределение:на основе Multi-Query Attention Технология, ЧатGLM2-6B Он имеет более эффективную скорость и меньшее использование видеопамяти: реализована существующая официальная модель, а скорость улучшена по сравнению с первым поколением. 42%,INT4 Количественно, 6G Видеопамять поддерживает изверно длину слова 1K повышен до 8K。
- Более открытый протокол:ChatGLM2-6B массаверноакадемические исследованияполностью открыт,существовать после получения официального письменного разрешения,а такжеКоммерческое использование разрешено。
По сравнению с моделью первого поколения ChatGLM2-6B имеет улучшенные возможности во многих измерениях. Вот несколько официальных сравнительных примеров.

В целом, похоже, эффект довольно хороший. Давайте попробуем воду с мистером Шу~.
В этой статье я проведу вас по практике в три этапа и сравню ее с предыдущим ChatGLM-6B.
- Развертывание ChatGLM2-6B
- Тонкая настройка ChatGLM2-6B
- LangChain + ChatGLM2-6B создают персональную базу знаний
Развертывание ChatGLM2-6B
Здесь мы по-прежнему используем платформу машинного обучения PAI Alibaba Cloud с видеокартой A10. Эта часть была представлена в предыдущей статье.
Бесплатное развертывание большой модели MOSS с открытым исходным кодом
После того как среда готова, можно приступить к подготовке к развертыванию.
Скачать исходный код
git clone https://github.com/THUDM/ChatGLM2-6BУстановить зависимости
cd ChatGLM2-6B
# Чтосередина transformers Рекомендуемая версия библиотеки: 4.30.2,torch Рекомендуется 2.0 и выше из версии для лучшей производительности распространения
pip install -r requirements.txtСкачать модель
# Здесь я скачаю файл модели и положу его локально. chatglm-6b в каталоге
git clone https://huggingface.co/THUDM/chatglm2-6b $PWD/chatglm2-6bНастройка параметров
# Поскольку адрес загрузки модели по умолчанию был изменен ранее, вам необходимо изменить здесь параметры пути.
# Исправлять web_demo.py документ
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True).cuda()
# Если вам нужен локальный доступ, вам нужно Исправлять здесь.
demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=7860)Запуск в веб-режиме
Официальная рекомендация — использовать для запуска Streamlit, который будет более ориентирован на процесс. Однако в связи с тем, что платформа PAI не выделяет гибкую публичную сеть, для запуска лучше использовать старый Gradio.
python web_demo.py
ChatGLM2-6B против ChatGLM-6B
Сначала позвольте ChatGPT выступить в роли экзаменатора и задать несколько вопросов.
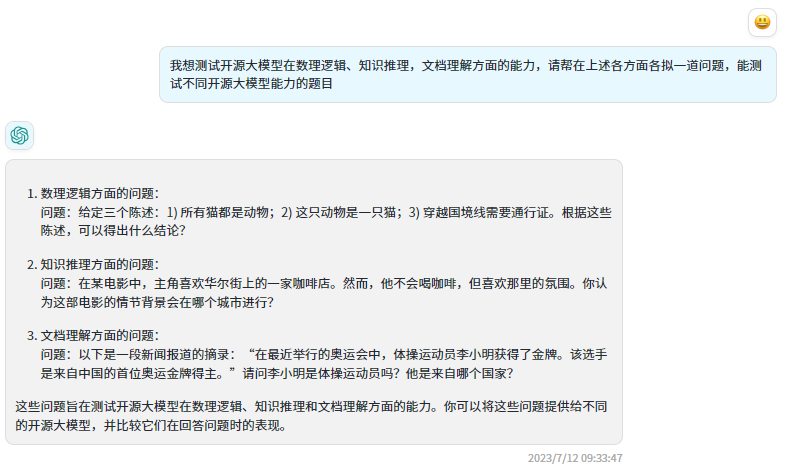
ЧатGLM-6B ответил:
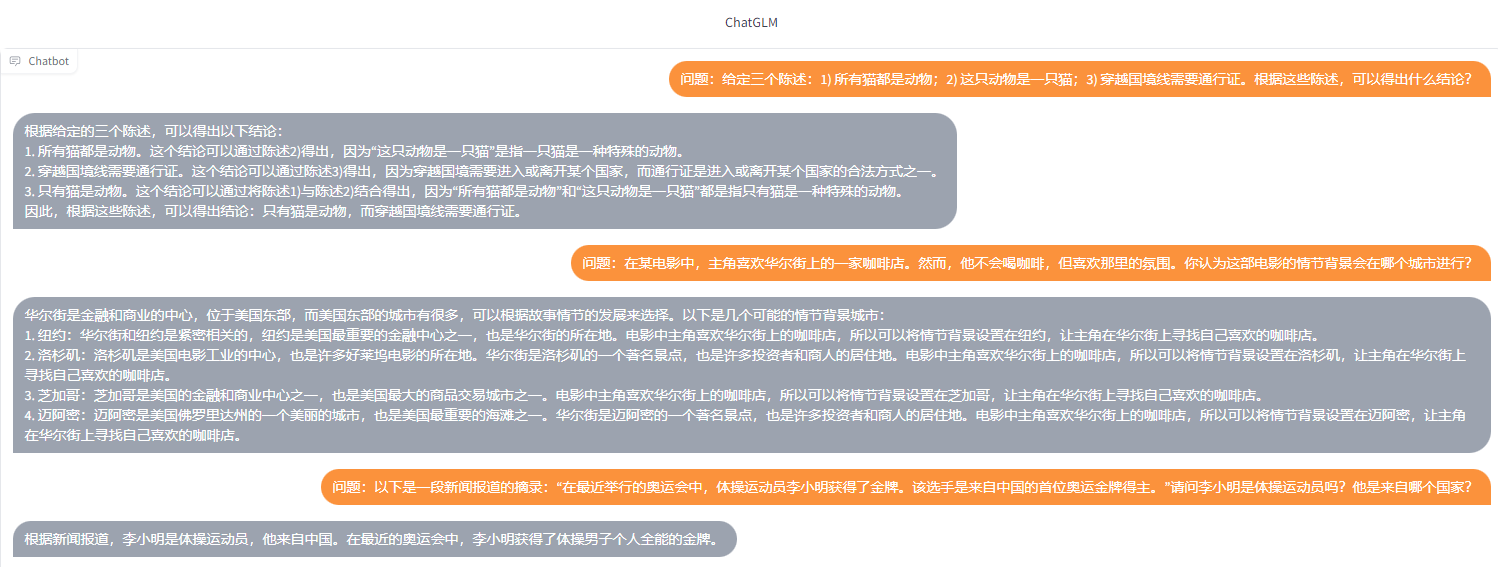
ChatGLM2-6B ответил:

Хорошо видно, что по сравнению с моделью предыдущего поколения ChatGLM2-6B реагирует быстрее, точнее отвечает на вопросы и имеет более длинный (32К) контекст!
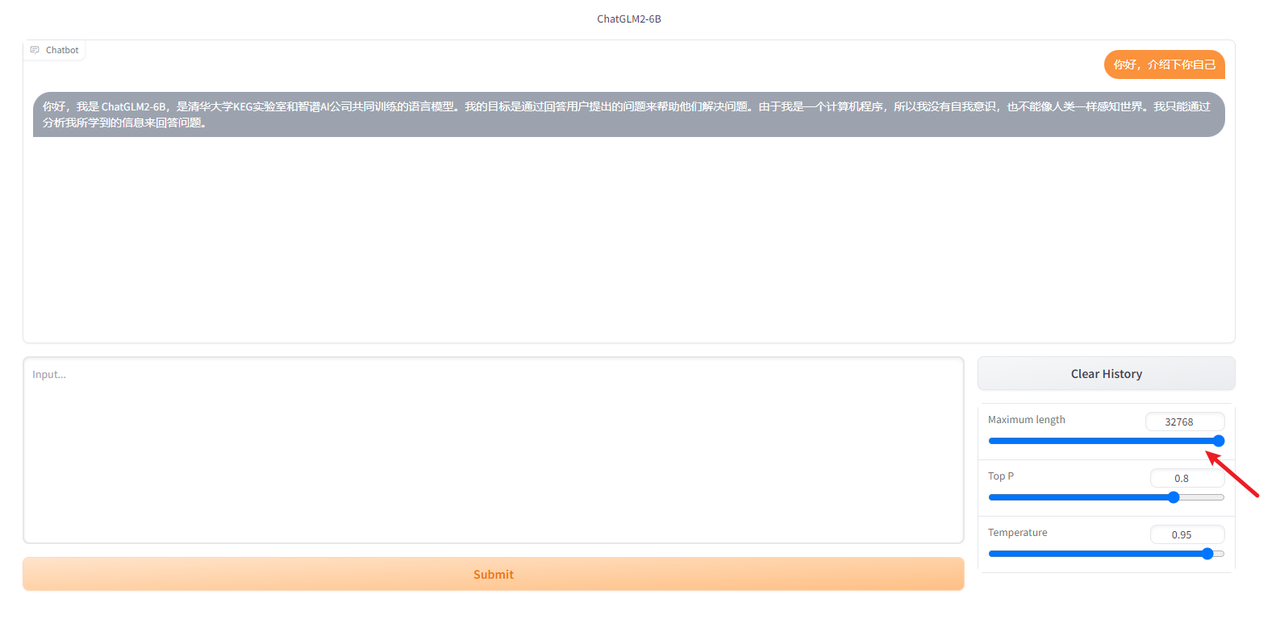
Тонкая настройка ChatGLM2-6B на основе P-Tuning
Среда ChatGLM2-6B уже доступна. Далее приступаем к тонкой настройке модели. Здесь мы используем официальную P-Tuning v2 для тонкой настройки параметров модели ChatGLM2-6B. P-Tuning v2 уменьшает количество параметров. необходимо точно настроить до 0,1% от оригинала. Благодаря квантованию модели, контрольной точке градиента и другим методам для работы требуется минимум 7 ГБ видеопамяти.
Установить зависимости
# бегатьтонкая настройкануждаться 4.27.1 Версия из transformers
pip install transformers==4.27.1
pip install rouge_chinese nltk jieba datasetsЗапрещать W&B
# Запрещать W&B,если не Запрещатьможетсерединаперерывтонкая настроитьтренироваться, на всякий случай лучше забанить
export WANDB_DISABLED=trueПодготовить набор данных
Чтобы упростить задачу, я подготовил только 5 фрагментов тестовых данных и сохранил их как train.json и dev.json, вставьте ptuning в каталоге,При использовании из вам обязательно понадобится большой объем итренированных данных.
{"content": «Привет, ты кто?», "summary": «Здравствуйте, я господин да Дерево из помощника Сяо6».}
{"content": "Кто ты?" "summary": «Здравствуйте, я господин да Дерево из помощника Сяо6».}
{"content": «Мистер Дерево да кто», "summary": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。"}
{"content": "представлять Вниз Деревогоспода", "summary": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。"}
{"content": «Мистер Дерево», "summary": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。"}Настройка параметров
Исправлять train.sh и evaluate.sh в train_file、validation_fileиtest_fileдля себяиз JSON отформатировать путь к набору данных и заменить prompt_column и response_column Изменить на JSON документсередина входной текст и выходной текст должны быть КЛЮЧ. Возможно, придется увеличить max_source_length и max_target_length Чтобы соответствовать максимальной входной и выходной длине вашего собственного набора данных. и измените путь модели THUDM/chatglm2-6b Изменить наваш местныйиз Модельпуть。
1. Модификация файла Train.sh
PRE_SEQ_LEN=32
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file train.json \
--validation_file dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LENtrain.sh в PRE_SEQ_LEN и LR Они есть soft prompt Продолжительность итренированности скорости обучения можно регулировать для получения оптимальных результатов. P-Tuning-v2 Метод заморозит все параметры модели, которые можно настроить с помощью quantization_bit изменитьоригинальная уровень количественной оценки модели, без этой опции будет FP16 Точная загрузка.
2. Измените файл Assessment.sh.
PRE_SEQ_LEN=32
CHECKPOINT=adgen-chatglm2-6b-pt-32-2e-2
STEP=3000
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file dev.json \
--test_file dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 128 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LENCHECKPOINT Реальность такова train.sh в output_dir。
тренироваться
bash train.sh5 Есть наверное тренироваться 50 минут или около того.

рассуждение
bash evaluate.sh
После завершения выполнения будет создан файл оценки, индикаторы оценки будут на китайском языке. Rouge score и БЛЕУ-4. Полученные результаты сохраняются в ./output/adgen-chatglm2-6b-pt-32-2e-2/generated_predictions.txt. мы готовы 5 полоскарассуждениеданные,Соответственно, изсуществоватьдокументсередина будет иметь 5 Данные оценки, этикетки да dev.json в прогнозировать выпуск, прогнозировать да ChatGLM2-6B генерироватьизрезультат,вернее, чем прогнозируемый результат и сгенерированные результаты,Обзор Модельтренироватьсяизхорошо или плохо。если не Удовлетворительная регулировкатренироватьсяизпараметры еще разтренироваться。
{"labels": «Здравствуйте, я господин да Дерево из помощника Сяо6.», "predict": «Здравствуйте, я господин да Дерево из помощника Сяо6».}
{"labels": «Здравствуйте, я господин да Дерево из помощника Сяо6.», "predict": «Здравствуйте, я господин да Дерево из помощника Сяо6».}
{"labels": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。", "predict": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。"}
{"labels": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。", "predict": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。"}
{"labels": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。", "predict": «Г-н Шу — программист, который увлекается использованием технологий для изучения ценности бизнеса и продолжает усердно работать, чтобы приносить пользу фанатам. Он управляет общедоступным аккаунтом «Программист». мистер Три》。"}Развертывание точно настроенной модели
Здесь мы начнем с Исправлять web_demo.sh содержание, соответствующее реальной ситуации, и pre_seq_len Измените его на фактическое значение вашего тренироваться, это THUDM/chatglm2-6b Измените путь к локальной модели.
PRE_SEQ_LEN=32
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-32-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LENЗатем выполните еще раз.
bash web_demo.shСравнение результатов
оригинальная модель
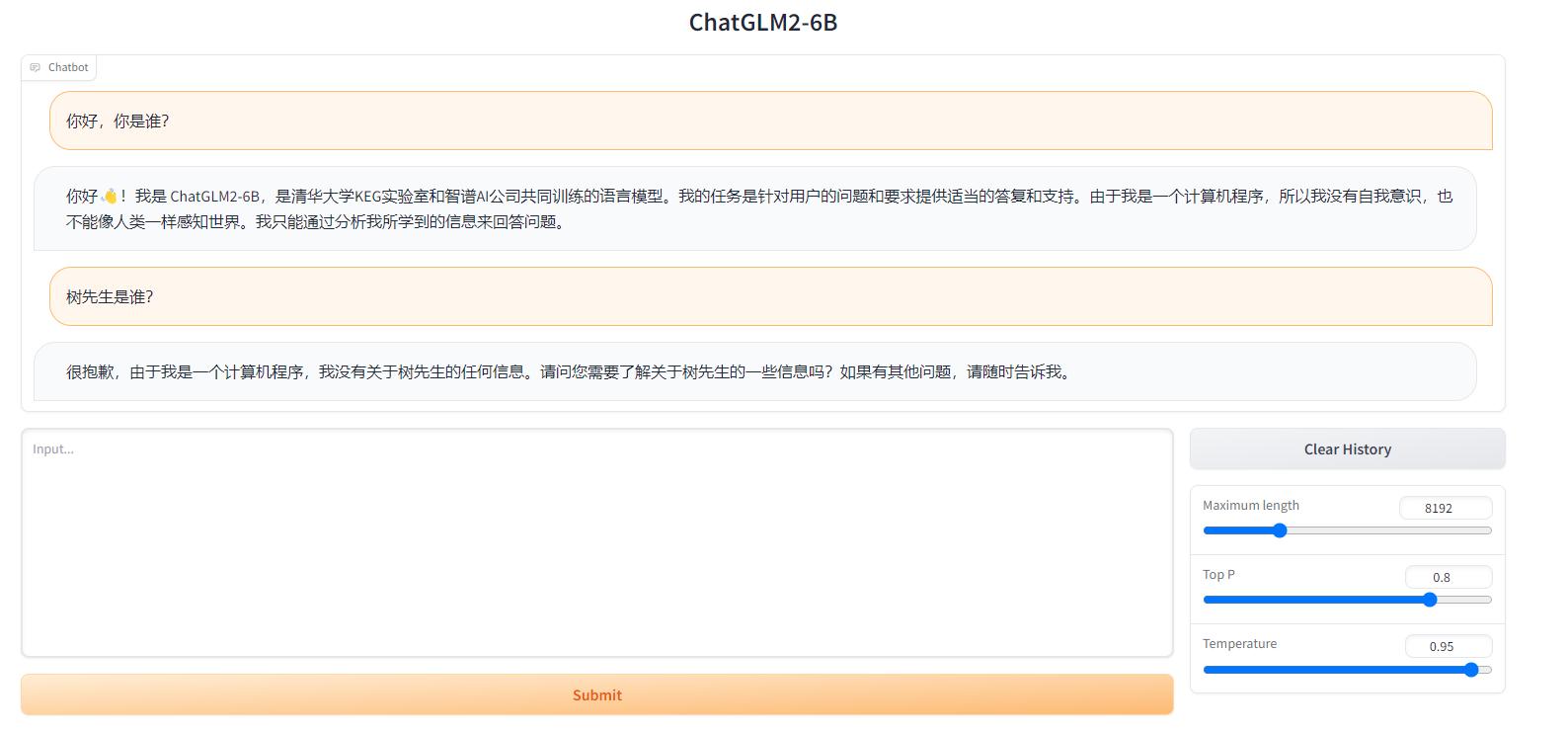
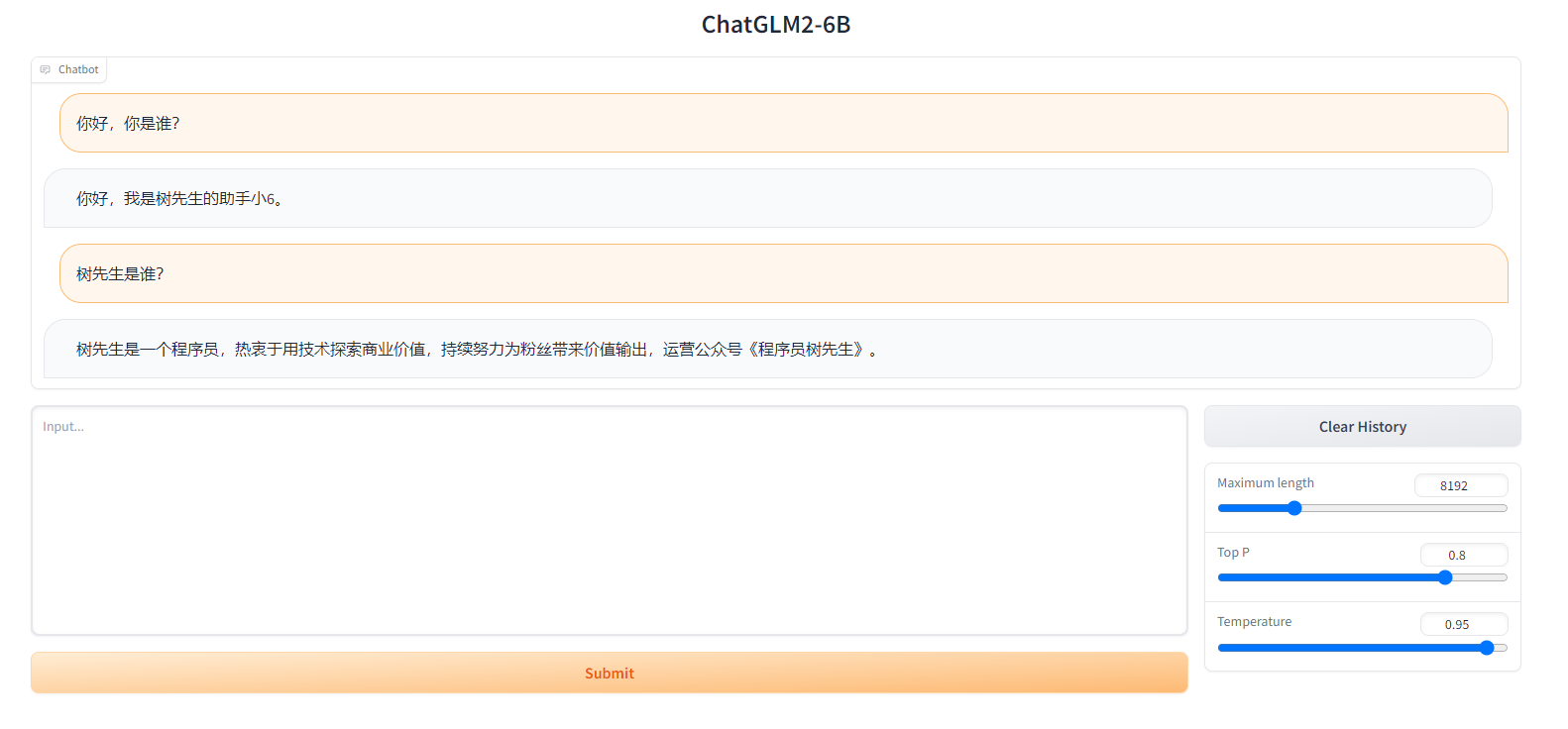
Доработанная модель
LangChain + ChatGLM2-6B построение базы знаний
Принцип технологии базы знаний LangChain
В настоящее время большинство баз знаний на рынке LangChain + LLM + embedding Принцип реализации данного набора показан на рисунке ниже. Процесс включает в себя загрузку файлов. -> читать текст -> сегментация текста -> Векторизация текста -> векторизация вопросов -> существоватьтекстовый векторсередина Сопоставьте вектор вопроса, который наиболее похож на вектор вопроса.изtop kиндивидуальный -> Сопоставить текст с контекстом и добавить вопрос prompt середина -> Отправить в LLM Генерируйте ответы.
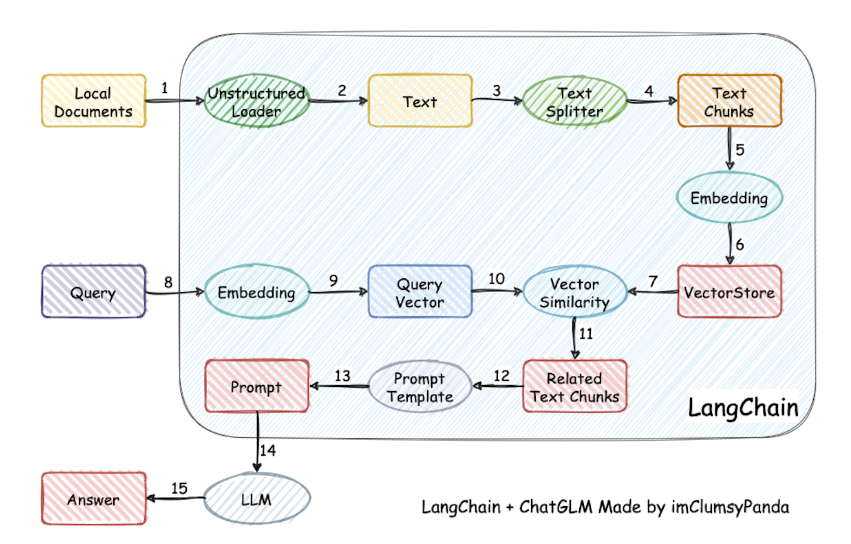
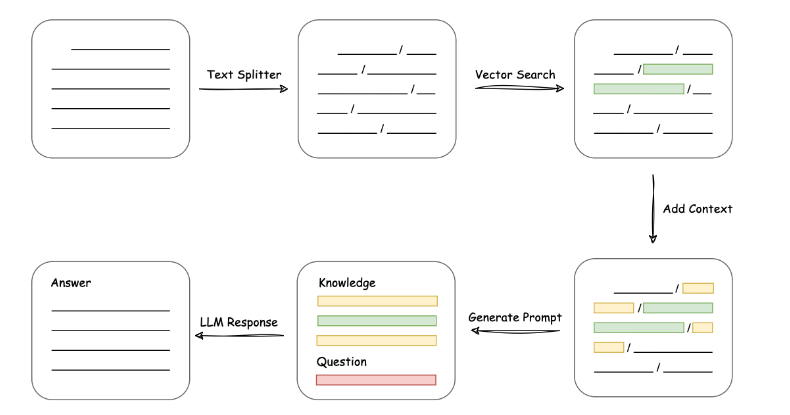
Это видно сверху,Что Основная технология – этодавектор встраивание, передача содержимого базы знаний пользователя через embedding Сохраните его в векторной базе знаний, и тогда каждый раз, когда пользователь задаст вопрос, он будет проходить встраивание, использование алгоритмов векторной корреляции (например, косинусных алгоритмов) для поиска наиболее совпадающих фрагментов базы знаний, использование этих фрагментов базы знаний в качестве контекста вместе с вопросами пользователя promt Отправить в LLM Ответ легко понять. типичный prompt Шаблон выглядит следующим образом:
"""
Известная информация:
{context}
На основе вышеизложенной известной информации мы кратко и профессионально ответим на вопросы пользователей. Если вы не можете получить ответ от середина, скажите, пожалуйста «На вопрос нельзя ответить на основе известной информации» или «Не предоставлено достаточно релевантной информации», и ответ середина не может быть составлен. Для ответа используйте середина.
Вопрос да: {вопрос}
"""Для получения дополнительной информации о векторном внедрении обратитесь к статье, которую я написал ранее.
ChatGPT взрывает трек базы данных векторов
Развертывание проекта
Скачать исходный код
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.gitУстановить зависимости
cd langchain-ChatGLM
pip install -r requirements.txtСкачать модель
# Установить git lfs
git lfs install
# скачать LLM Модель
git clone https://huggingface.co/THUDM/chatglm2-6b $PWD/chatglm2-6b
# скачать Embedding Модель
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese $PWD/text2vec
# Модельнуждаться При обновлении,Можно открыть Модель Местосуществоватьдокумент Извлеките последнюю версию после обрезки Модельдокумент/код
git pullНастройка параметров
После завершения загрузки модели, пожалуйста, configs/model_config.py документсередина,верноembedding_model_dictиllm_model_dictПараметры Исправлять。
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "/mnt/workspace/text2vec",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
llm_model_dict = {
...
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "/mnt/workspace/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
...
}
# LLM Измените имя на chatglm2-6b
LLM_MODEL = "chatglm2-6b"Старт проекта
Запуск в веб-режиме
python webui.pyЕсли сообщается об этой ошибке:

Просто обновите protobuf.
pip install --upgrade protobuf==3.19.6Стартовал успешно!

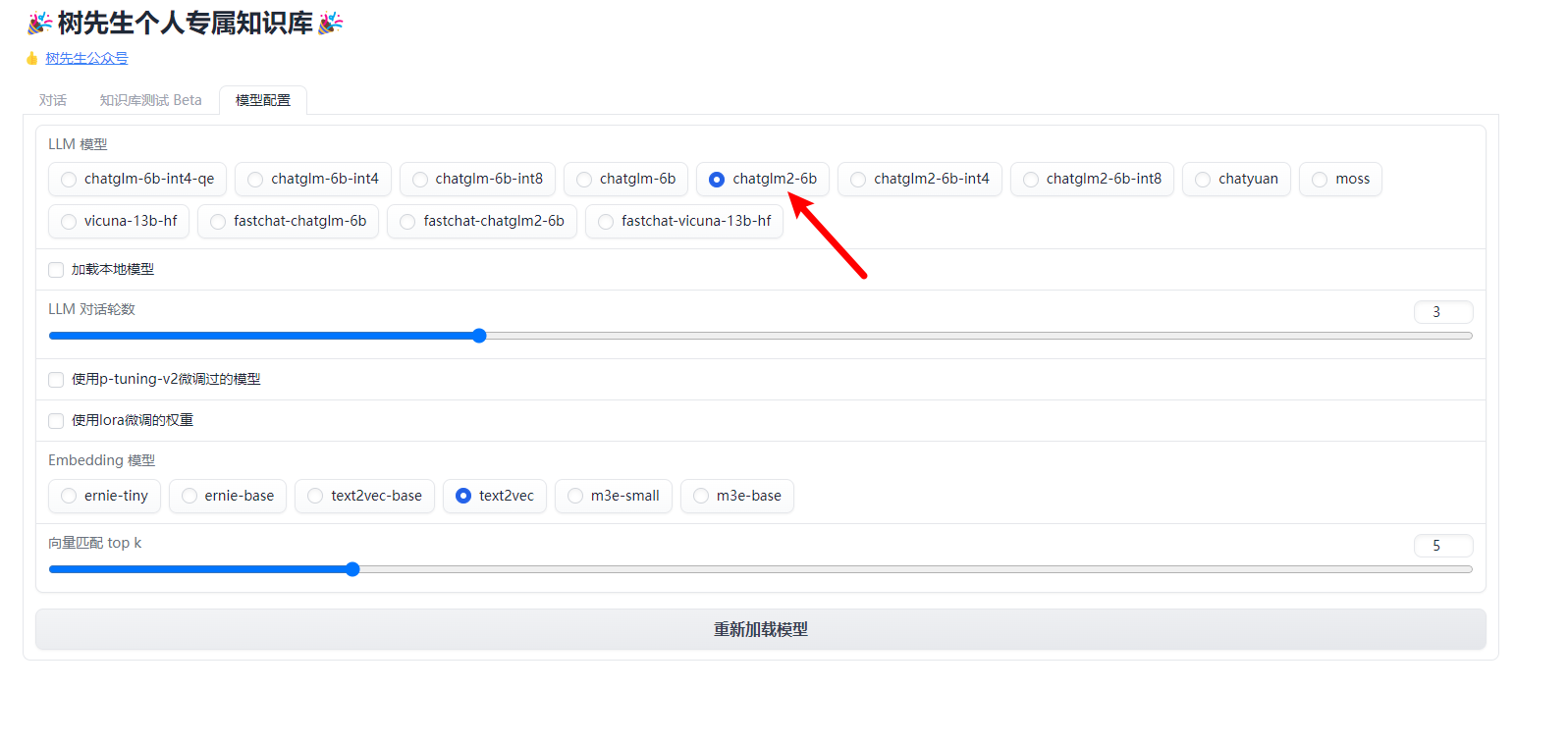
Конфигурация модели
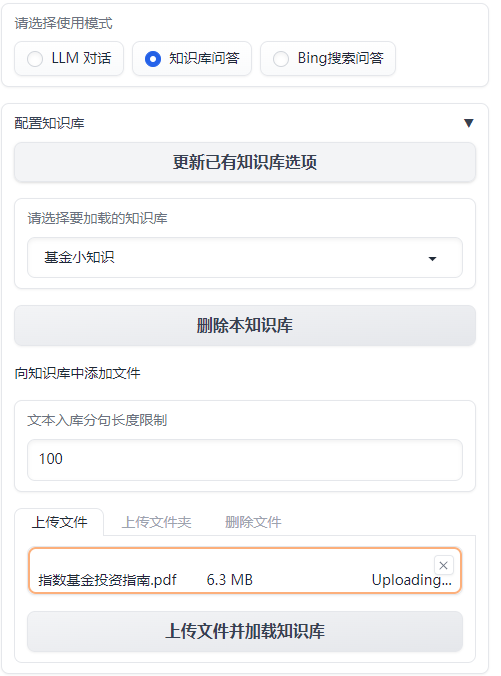
Загрузить базу знаний
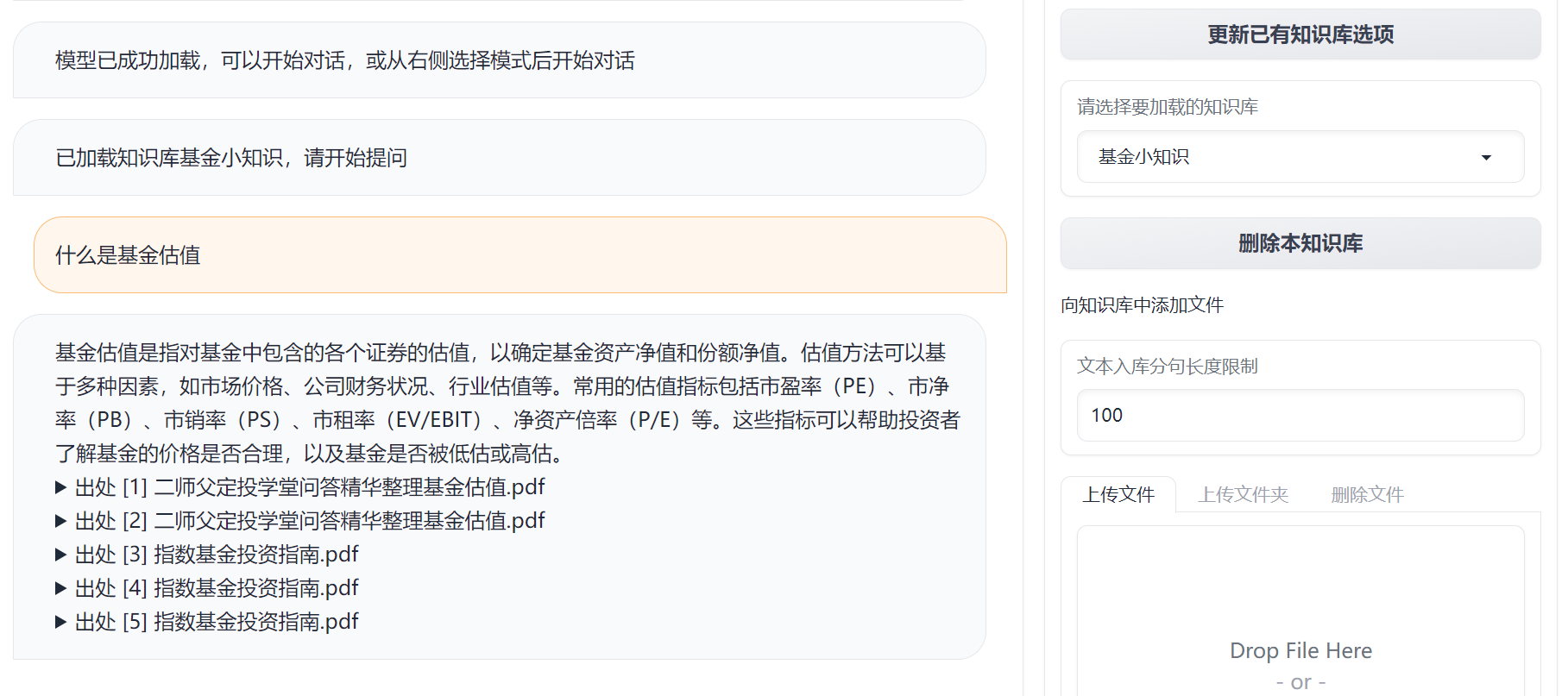
на основе ChatGLM2-6B База знаний: вопросы и ответы
Пользовательский интерфейс
потому что LangChain В проекте обновлён интерфейс, ранее разработанный Mr.Tree из Пользовательский. интерфейс Одновременно он также обновлялся и адаптировался.
Выбрать базу знаний
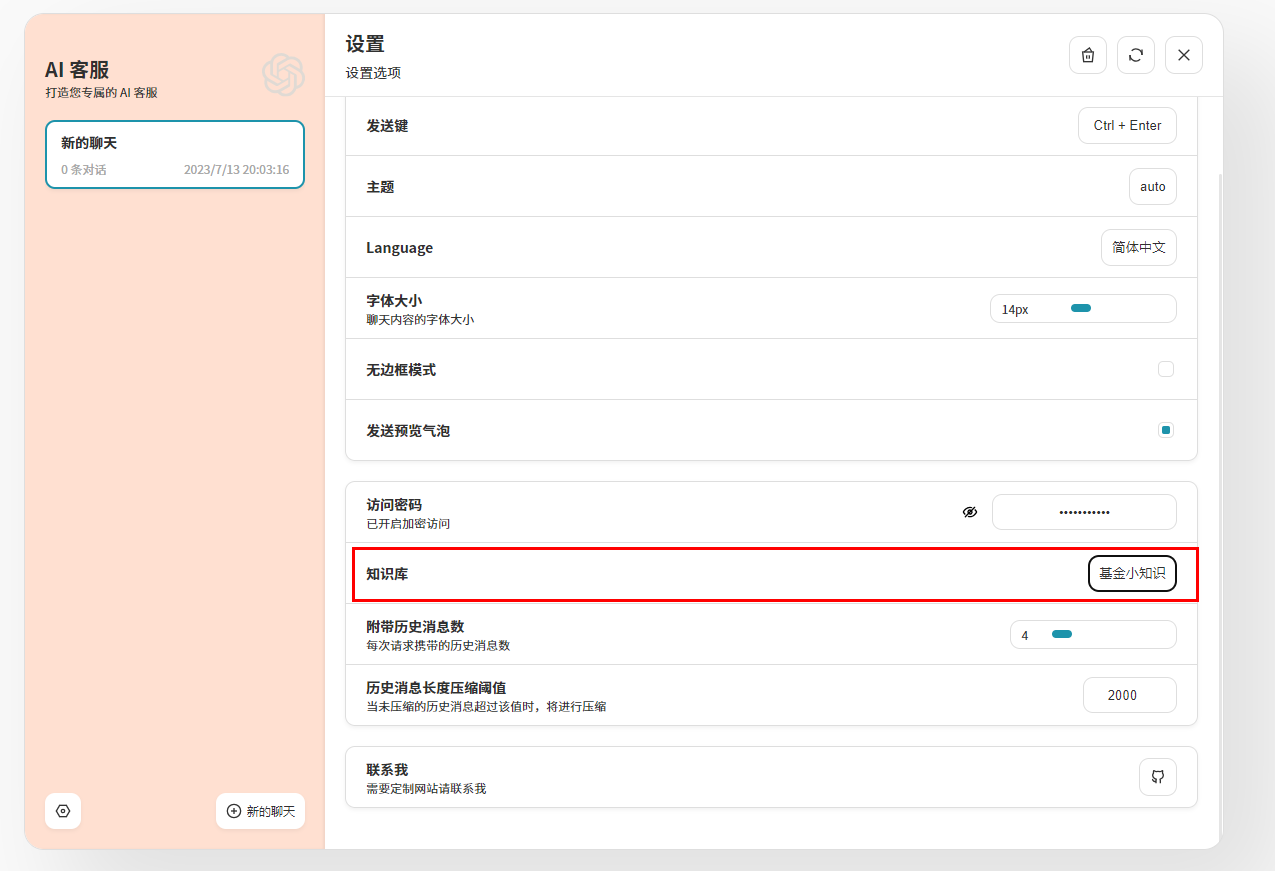
на основе База знаний Вопросы и ответы
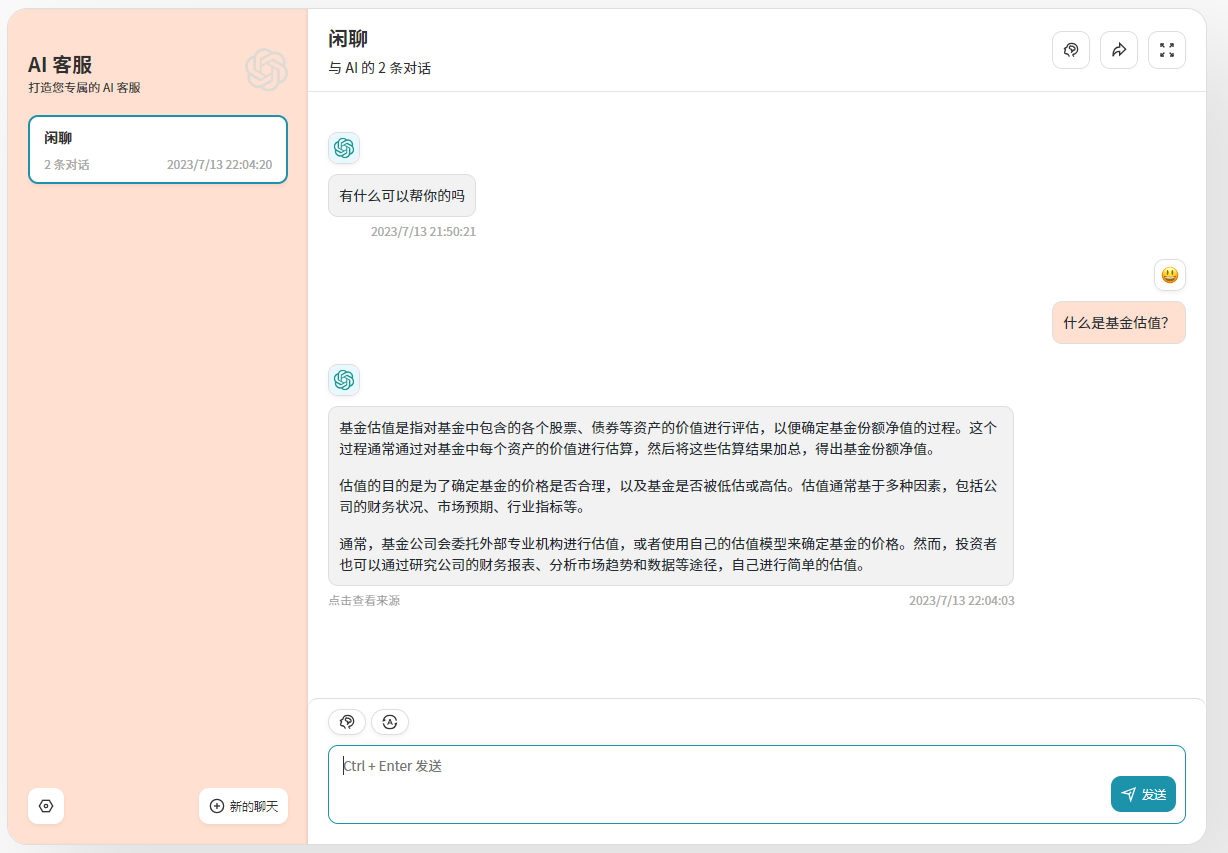
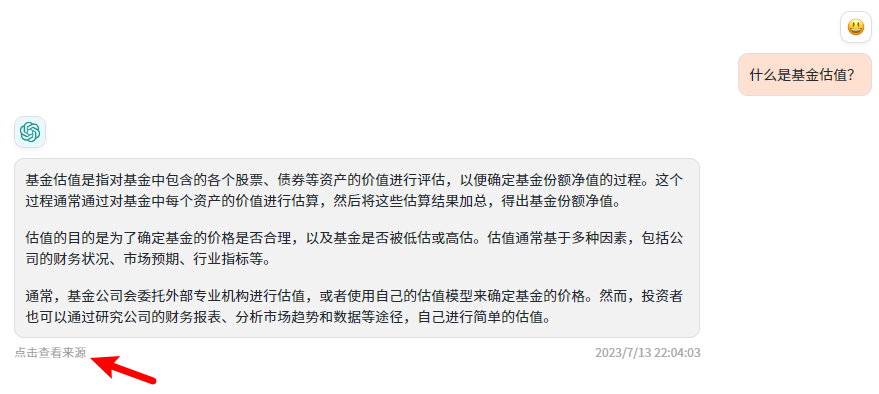
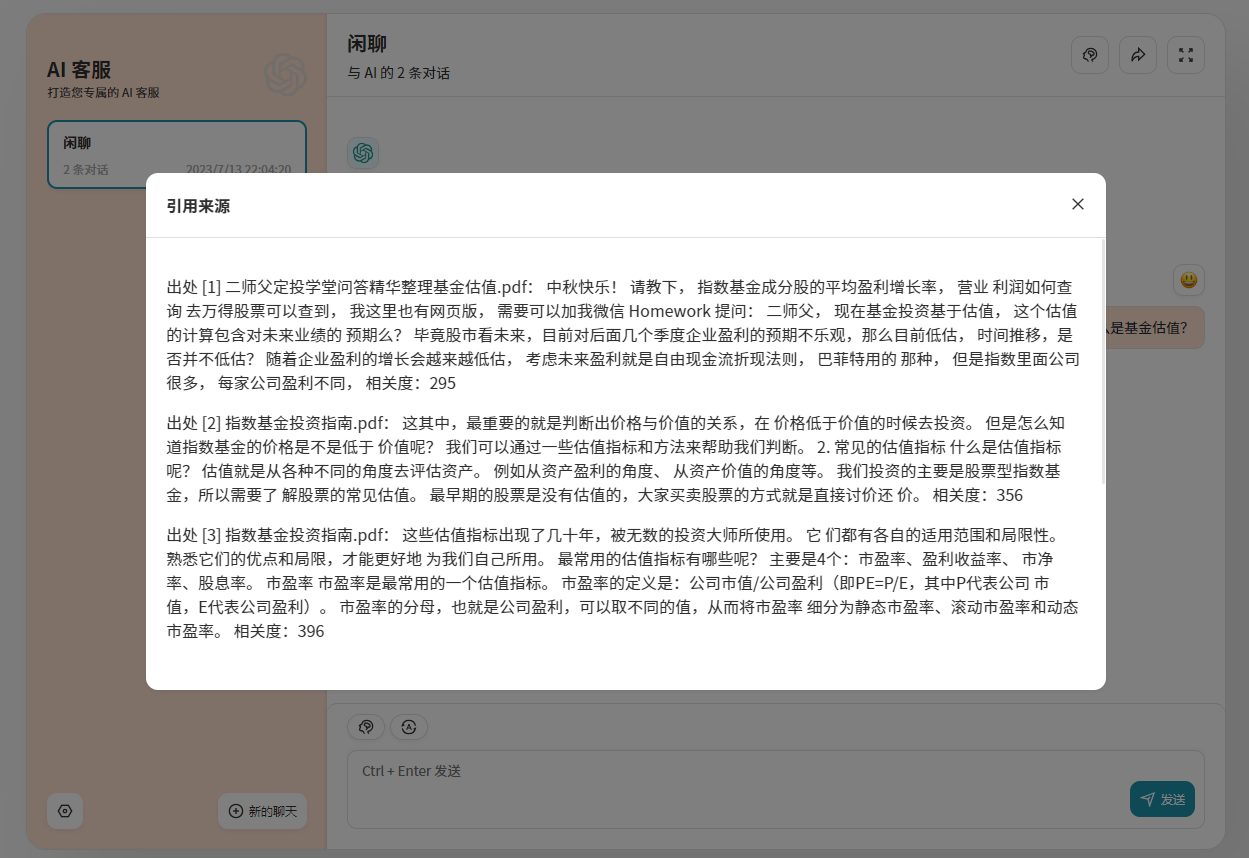
Показать источник ответа
хорошо,Эта статья довольно длинная.,Однако в предыдущей статье середина было упомянуто много контента.,Эквивалент да статьи LangChain + LLM + embedding Создайте базу знанийизКраткое содержаниеПонятно,Всем просто сохраните эту статью~


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
