Кубок Европы программистов: использование больших данных для прогнозирования количества побед более увлекательно, чем игра в футбол
Кубок Европы, который в самом разгаре, вышел в стадию плей-офф, и исход каждой игры затрагивает сердца тысяч болельщиков. Погода, место проведения, звезды, тактика, травмы, судьи — каждый фактор может повлиять на исход игры. Говорят, что в футбольных матчах исход никогда не знаешь до последнего момента. Любители ставок на футбол не только ценят волнующее душу и волнующее очарование футбола, но и участвуют в психологической и стратегической игре с букмекерскими компаниями (фактически, чтобы зарабатывать деньги на ставках). Автор этой статьи начинает с уровня данных и прогнозирует результаты победы, ничьи и поражения в футбольном матче, анализируя характеристики данных, относящиеся к футбольному матчу, и комбинируя их с методами модели машинного обучения. Особое напоминание: эта статья не представляет собой каких-либо рекомендаций по инвестициям или ставкам. Азартные игры сопряжены с риском, поэтому будьте осторожны, делая ставки!
Великий Фортебо Придит однажды сказал: «В игре нет договорных матчей, и все игры — фейки». Асимметрия информации является основной причиной разрыва между богатыми и бедными. Можно ли в эпоху больших данных уменьшить информационную асимметрию с помощью данных для успешного прогнозирования футбольных матчей? Эта статья начинается с уровня данных, анализируя характеристики данных, связанные с футбольными матчами, и объединяя их с методами модели машинного обучения для прогнозирования результатов выигрыша, ничьей и проигрыша футбольных матчей. Далее направляйте ставки на футбол на одну игру на основе результатов прогнозирования, чтобы добиться эффективной прибыли и даже стабильных прибыльных методов ставок.
- Откройте для себя особенности данных футбольных игр.
- Построить прогноз Модель.
- Прогнозируйте вероятность исхода матча (победа, ничья, поражение).
- Анализируйте стратегии ставок на футбол.
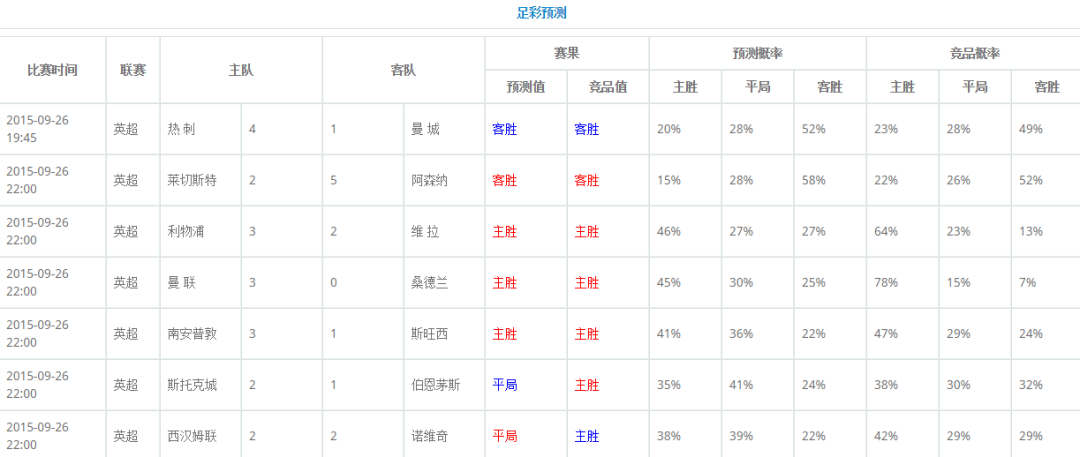
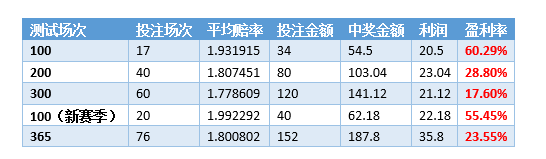
Используя предложенную в этой статье стратегию ставок, мы делаем ставку на 20 из 100 игр сезона Премьер-лиги 2015 года. Если все ставки являются одинарными (2 юаня за ставку), вы можете получить прибыль в размере 22,18 юаня, сделав ставку на 20 игр, с нормой прибыли 55%! Ниже в качестве примера будут взяты данные пяти крупнейших европейских лиг за 2015 год, чтобы подробно представить, как построить практичную и эффективную систему прогнозирования футбольных лотерей с помощью данных и простых методов машинного обучения.
01. Прогнозы футбольных лотерей
«Мы можем рассматривать нынешнее состояние Вселенной как ее прошлые следствия и будущие причины. Если разумный человек может знать силы всех естественных движений и положения всех естественно созданных объектов в определенный момент, если он также может анализировать эти данные ,Движение самых больших объектов во Вселенной к мельчайшим частицам заключено в простой формуле. Для этого мудрого человека нет ничего двусмысленного, и будущее представляется ему лишь прошлым». — Французский математик Пьер Симон Лаплас.
1.1 Характеристики данных
Так как же нам быть предупрежденными и заранее узнать результаты футбольных матчей? Существует ли разумный и эффективный метод прогнозирования футбольных матчей, позволяющий добиться более стабильной прибыли при ставках на футбольные лотереи?
Демон Лапласа, предложенный Лапласом, является типичным представителем механического детерминизма. Он считал, что пока у вас есть распределение всех сил и состояний объектов во Вселенной, вы можете предсказать все в будущем с помощью мощного ИИ. такой вывод Отрицается котом Шрёдингера. Хотя демон Лапласа имеет свои ограничения, он все же в принципе применим в макродинамике. Как и в реальной истории, рассказанной в фильме «Money Ball» с Брэдом Питтом в главной роли, баскетбольный клуб использовал анализ данных, чтобы найти подходящих игроков, и в конце концов сформировал команду с низкой общей зарплатой, которая может конкурировать с богатыми «Янкиз» за чемпионство. На исход футбольного матча влияют тысячи факторов. Независимо от того, являетесь ли вы обычным болельщиком или профессиональным футбольным критиком, вы можете выделить ряд влияющих факторов, таких как рейтинг команд, исторические рекорды, данные нападения и защиты, последние данные. результативность, преимущество домашнего поля, красные карточки арбитров и т. д.
В отрасли существует множество методов прогнозирования футбольных матчей. Вот краткое описание нескольких распространенных методов:
- На основе метода прогнозирования количества целей. Метод, основанный на прогнозируемом количестве голов [1], преобразует прогнозирование результатов игры в использование Модели распределения Пуассона для оценки наступательных и защитных возможностей обеих сторон, а затем прогнозирует окончательный результат игры через количество голов. забил.
- На основе вероятностной регрессионной модели. В статье [2] предлагается использовать несколько различных объясняющих переменных для формирования модели вероятностной регрессии.,В основном учитывайте уровень команды, недавнее выступление、важность игры、Расстояние между хозяевами и гостями и т. д.
- Делаем прогнозы с использованием байесовских сетей. В основном использование субъективных и объективных данных, связанных с игрой, для обучения и моделирования байесовской сети.,Затем предскажите исход игры.
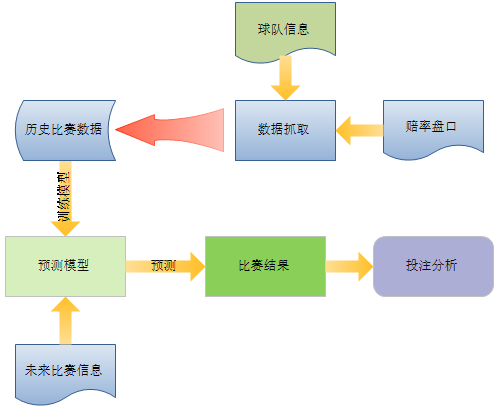
Что касается многих статей по футбольным прогнозам, данные, используемые для прогнозирования игр, в основном делятся на два аспекта: один — это фундаментальная информация о команде, а другой — публичные коэффициенты. Реализация прогнозирования футбольной лотереи здесь в основном учитывает эти два аспекта данных.
1.1.1 Основная информация о команде
Основная информация о команде состоит из пяти аспектов: сила команды, предматчевый статус, история матчей, влияние на поле, а также наступательные и защитные возможности обеих команд. Мы количественно оцениваем способности хозяев и гостей в этих пяти аспектах как 17-мерные непрерывные характеристики.
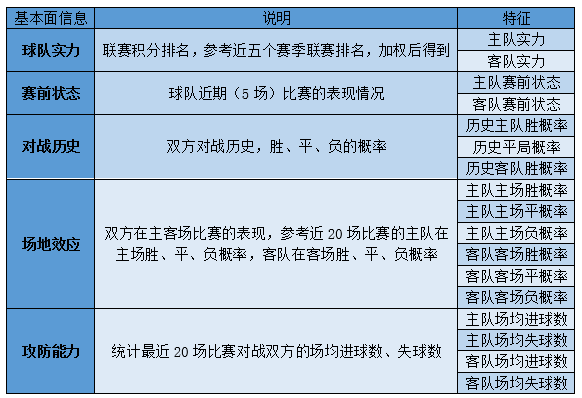
1.1.2 Шансы
Основы команды легко понять, но какая конкретная связь между шансами и исходом футбольного матча? Основным условием шансов является вероятность, но это не просто вероятность. Проще говоря, после серии научного анализа и оценок определенной игры игровая компания приходит к трем исходам: победа, ничья и проигрыш. тот, у кого меньше шансов на выигрыш, будет иметь более низкие шансы. Шансы относительно высоки. Уровень вероятности не соответствует конечному результату, но как только поведение рынка сформируется, букмекеры конвертируют вероятность в коэффициенты на продажу. Чтобы соответствовать рыночным ожиданиям и отражать ценность существования, данные общедоступных коэффициентов должны быть более или менее связаны с фактической вероятностью игры, тем самым удовлетворяя психологию публичных ставок, а окончательные коэффициенты включают рыночную ожидаемую стоимость букмекерской конторы. сочетание игровой информации и вероятностей исхода.
- Коэффициенты отражают силу двух команд.
- Коэффициенты основаны на базовой вероятности исхода матча.
- Коэффициенты учитывают рыночные ожидания букмекерской конторы.
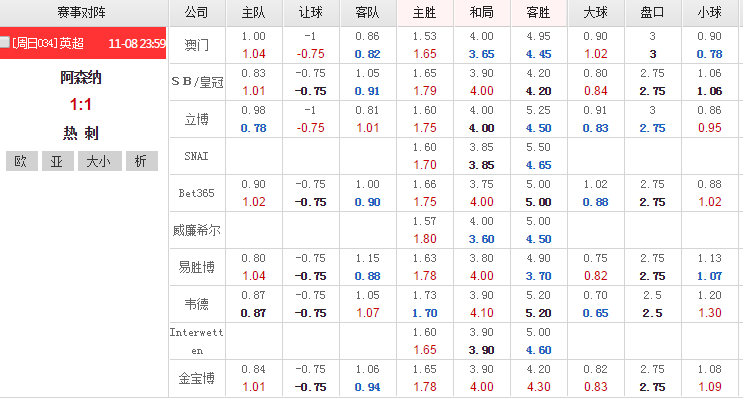
Можно видеть, что коэффициенты, раскрываемые самой букмекерской компанией, содержат информацию, связанную с игрой, но смешаны с рыночными ожиданиями букмекеров и тенденциями ставок игроков и связаны со многими коммерческими интересами. Коэффициенты могут меняться с момента их первоначального выставления до начала игры. Когда букмекеры получат дополнительную информацию, они внесут определенные корректировки в зависимости от динамики команды и тенденций ставок. Опытные игроки часто принимают решения о своих ставках, наблюдая за первоначальными коэффициентами и изменениями коэффициентов разных букмекерских контор. Шансы в разных играх разные, и шансы варьируются от начальной до окончательной выплаты, и мы надеемся использовать методы машинного обучения, чтобы позволить модели понимать значение от имени людей, а затем прогнозировать результаты футбольных матчей. .
1.2 Подготовка данных
Здесь в качестве примера мы возьмем прогнозы пяти основных европейских лиг. Ниже мы проводим анализ данных и подготовку к пяти основным европейским лигам.
Методы прогнозирования для кубковых соревнований, таких как Кубок Европы, Кубок Америки, Чемпионат мира и т. д., аналогичны, но проблемы с данными немного отличаются. Эта проблема будет кратко обсуждаться в последней части этого раздела.
Требуемые данные в основном включают в себя:
- Основная информация об игре: лига, команда хозяев, команда гостей, счет.
- Информация о коэффициентах: европейские коэффициенты (победа, ничья, проигрыш), предоставленные различными букмекерами на игру.
Благодаря сканированию мы получили информацию о пяти основных европейских лигах с 2010 по 2015 год, а также информацию о коэффициентах, опубликованную 17 ведущими букмекерскими компаниями. Конкретные данные по каждой лиге следующие:
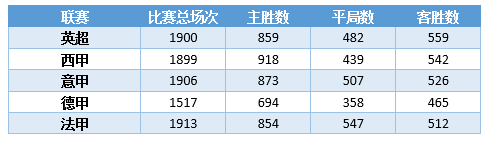
Фундаментальные информационные характеристики команды можно получить с помощью статистики исторических рейтингов очков в лиге и информации об участии команды, в общей сложности с 17-мерными характеристиками команды. Что касается коэффициентов, поскольку не существует единого стандарта времени для окончательных коэффициентов, предоставляемых каждой игровой компанией перед началом игры, в текущей версии используются только начальные коэффициенты на выигрыш, ничью и проигрыш, опубликованные 17 крупными игровыми компаниями. Компания имеет в общей сложности 51-мерную характеристику шансов.
1.3 Модель прогнозирования
1.3.1 Нелинейная модель
Существующие игровые данные накапливаются с 27 июля 2010 года и содержат данные за пять полных сезонов, а также за сезон 2015 года. На примере Премьер-лиги мы случайным образом выбрали 55 игр из каждого из предыдущих пяти сезонов и 90 игр из последнего сезона, в результате чего в общей сложности получилось 365 игр, чтобы сформировать тестовый набор, а оставшиеся данные были использованы в качестве обучающего набора. . В игровых данных есть несколько расстроенных игр. Мы посчитали такие данные странными выборками и исключили их в процессе обучения, в результате чего получился обучающий набор из 1339 игр.
В рамках линейной модели LR точность прогноза тестового набора Премьер-лиги составила 38,18%, а в модели SVM точность увеличилась до 51,23%. Матрица путаницы прогноза модели SVM результатов прогнозирования выигрыша, ничьи и проигрыша в игре выглядит следующим образом:
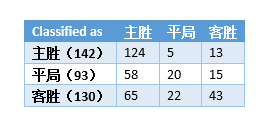
Согласно результатам прогнозирования Премьер-лиги, точность прогнозирования модели SVM на 13,05% выше, чем у модели LR. Мы предполагаем, что нелинейная модель имеет лучшую производительность при прогнозировании результатов футбольных матчей. Мы использовали одни и те же обучающие и тестовые наборы и опробовали несколько разных нелинейных моделей.

По результатам экспериментов мы обнаружили, что, за исключением французской Лиги 1, другие лиги имеют лучшие результаты в нелинейных моделях, особенно в модели Random Forest (RandomForest), с точностью прогнозирования более 53%. Но почему точность прогнозов французской Лиги 1 ниже, чем у других лиг?
С точки зрения болельщиков, французская Лига 1 менее конкурентоспособна, чем другие четыре основные лиги. Среди ее игроков большая доля иностранных игроков из стран третьего мира, представленных Африкой. Игровая тактика и дисциплина слабые, и в играх часто полагаются. на звёздах индивидуальная результативность игрока. Теория Шеннона доказывает, что энтропия эквивалентна степени неопределенности информационного содержания. То есть, чем больше информационная энтропия объекта и чем выше степень хаоса, тем больше неопределенность его информации. В футбольных матчах, чем ближе по силе обе стороны, тем выше вероятность исхода матча и тем сложнее точно предсказать исход матча.
Истинную силу команды в каждой игре сложно измерить искусственно. Здесь мы просто используем рейтинг команды в лиге как меру силы команды. В лиге степень хаоса во всей лиге измеряется по колебанию очков в рейтинге команды. Метод расчета следующий:
- В соответствии с рейтингом очков в лиге команда, занявшая первое место, получает 20 очков, команда, занявшая второе место, получает 19 очков и так далее, команда, занявшая 20-е место, получает 1 очко, а команда, вылетевшая в низшую лигу, получает 0 очков;
- Рассчитайте разницу в рейтинге каждой команды за последние 10 сезонов лиги;
- Показатель хаоса в лиге рассчитывается как среднее значение разницы в рейтинге каждой команды.
Рейтинг хаоса в лиге

Из результатов, рассчитанных вышеуказанным методом, мы видим, что показатель хаоса в Лиге 1 намного выше, чем в других четырех высших лигах, что соответствует перцептивному пониманию болельщиков. Это приводит к использованию одних и тех же данных. информация для анализа Лиги 1. Точность прогноза намного ниже, чем у других четырех высших лиг.
На данный момент мы достигли точности прогнозирования 53,42% для Премьер-лиги с использованием модели случайного леса. Есть ли способ дальнейшего повышения точности помимо дальнейшего изучения дополнительных функций? Давайте сначала посмотрим на влияние существующих функций на целевое значение в модели случайного леса.
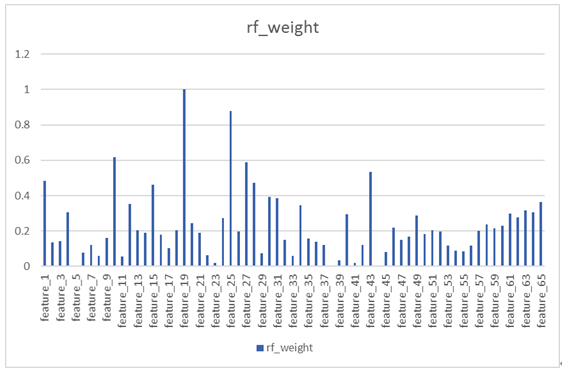
Среди них последние 17-мерные характеристики являются фундаментальными характеристиками команды, а остальные — характеристиками шансов. В соответствии с моделью случайного леса фундаментальные характеристики команды обычно имеют небольшой вес и оказывают ограниченное влияние на целевые результаты. Характеристики с большим эффектом в основном существуют в векторе признаков шансов.
1.3.2 Модель DNN
Характеристики являются исходным материалом систем машинного обучения и оказывают наибольшее влияние на конечный эффект модели. Даже простые модели могут достичь более высокой точности, если необработанные данные могут быть лучше представлены подходящими функциями. Однако разработка функций — это утомительная и трудоемкая задача, требующая большого опыта и знаний. В отношении футбольных матчей обычные болельщики и профессиональные футбольные аналитики могут наблюдать совершенно разные моменты. Ручной выбор и обработка признаков во многом зависят от профессионального опыта или даже удачи и отнимают много времени. Эту проблему может решить глубокое обучение, которое стало очень популярным в последние годы. Другое название глубокого обучения — обучение функций без учителя, которое представляет собой метод обучения функциям без учителя. Самое мощное в этом то, что в нейронной сети, содержащей множество скрытых слоев, выходные данные одного из слоев можно использовать как другую форму выражения входных данных, которая может «выражать» и «понимать» более точно». Характеристики вещей, тем самым эффективно повышая точность прогнозов.
Традиционная нейронная сеть использует обратное распространение во время процесса обучения, то есть на основе ошибки между текущим выходным сигналом и меткой используется метод градиентного спуска для корректировки параметров предыдущих слоев до тех пор, пока модель не сойдётся. Однако в реальных проектах имеются очевидные недостатки:
- Легко сходиться к локальному минимуму и попасть в локальный оптимум.
- Когда тренировки недостаточны, легко перетренироваться.
- Требуются данные обучения в виде помеченных данных.
- Скорость обучения низкая, а требования к производительности вычислений высоки.
Для решения проблем, существующих в процессе обучения многослойных нейронных сетей, Хинтон предложил другой метод обучения — послойное обучение без учителя и жадное послойное обучение. Метод обучения в основном делится на два основных этапа:
- Нейроны обучаются слой за слоем, чтобы минимизировать разницу в информации, содержащейся на входе и выходе каждого уровня сети. Этот этап представляет собой процесс обучения без присмотра.
- По помеченным данным обучения,Ошибка используется для точной настройки параметров каждого слоя сети сверху вниз.

Используя множественные нелинейные преобразования глубоких нейронных сетей, мы можем получить еще одно, более эффективное представление особенностей входных данных, достигая эффективного изучения характеристик данных футбольной лотереи. Таким образом, мы можем использовать выходные данные скрытого слоя сети глубокого обучения в качестве новой входной функции и комбинировать их с другим обучением нелинейной статистической модели для получения окончательного выходного результата.
На примере Премьер-лиги метод ансамбля в сочетании с глубокими нейронными сетями значительно повысил точность прогнозирования результатов матчей.

1.4 Прогнозы на кубок и прогнозы результатов
1.4.1 Прогнозы на кубок
Приведенные выше данные включают анализ и прогнозирование пяти основных европейских лиг в качестве примера, но методы прогнозирования для кубковых матчей или других соревнований аналогичны. Однако кубок предсказать сложнее, чем чемпионат, главным образом по следующим двум причинам:
- Игр стало меньше. В Премьер-лиге участвуют 20 команд, а в обычном сезоне проводится 380 игр. Общее количество игр в кубке гораздо меньше этого числа. После расширения в 2016 году в Кубке Европы приняли участие 24 команды, а в чемпионате мира приняли участие 32 команды и всего 64 игры; Таким образом, общее количество игр, связанных с кубком, намного меньше, чем в лиге.
- качество данных более нестабильно. Поскольку кубок обычно проводится раз в четыре года,Большие изменения в участвующих командах,Сила команды сильно меняется. Это приводит к относительно небольшому количеству исторических матчей между противоборствующими командами.,В то же время руководство историческими боевыми данными стало слабее. как на чемпионате мира,Единственные команды, которые могут составить конкуренцию сборной Китая, — это Бразилия, Коста-Рика и Турция.,данных очень мало. В итоге,Прогнозы на кубок сложнее, чем на игры чемпионата. В сочетании с приведенным выше анализом французской Лиги 1,Кубок эквивалентен «лиге» с более высокой степенью хаоса.,Прогнозируемые результаты более случайны.
1.4.2 Прогноз очков
Метод прогнозирования результата аналогичен методу прогнозирования результата игры. Получение восходящих данных и абстракция признаков могут быть использованы повторно. Основная цель — преобразовать цель прогнозирования в прогноз результата игры, как показано на следующем рисунке. :
В реальной реализации прогнозирования оценок мы можем рассматривать его как проблему регрессии или проблему классификации. Здесь в качестве примера мы приведем два относительно простых и практичных метода.
1. Метод распределения Пуассона.
Распределение Пуассона было предложено французским математиком Симоной Дени Пуассон в 1838 году. Оно описывает распределение вероятностей количества случайных событий, происходящих в единицу времени. Здесь мы можем предположить, что количество голов, забитых обеими сторонами игры, соответствует распределению Пуассона (это очень сильное и простое предположение), смоделировать только лямбда-параметр и получить максимальную вероятность забитого гола в финальной игре. .
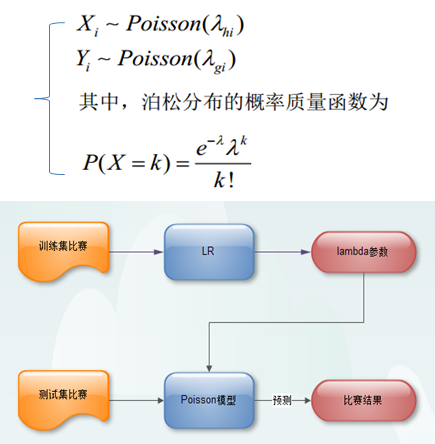
2. Несколько методов классификации
Метод мультиклассификации рассматривает прогнозирование оценок как проблему мультиклассификации. С помощью статистики данных мы обнаружили, что количество голов в одной игре в большинстве игр меньше или равно 4. Например, в 97% игр Кубка европейских чемпионов забивается менее 5 голов. Таким образом, мы можем рассматривать прогнозирование баллов как задачу классификации 25 (5*5) категорий, используя функцию Softmax для моделирования каждого возможного балла.
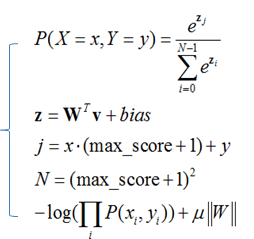
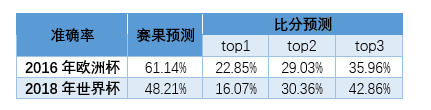
PS: В следующей таблице показаны прогнозы результатов и прогноз очков чемпионата Европы 2016 года и чемпионата мира 2018 года (вы можете видеть, что точность прогноза сильно колеблется).
02. Анализ стратегии ставок
В настоящей футбольной лотерее существует множество видов игр. Например, спортивная лотерея включает в себя игру «выигрыш-ничья-проигрыш», игру на счет, игру с общим количеством голов, игру «выигрыш-ничья-проигрыш», комбинированную игру и т. д. Основываясь на ранее полученной системе прогнозирования футбольных лотерей, может ли она дать некоторые рекомендации для наших ставок на футбол? Ну, речь идет о том, сможете ли вы заработать деньги.

2.1 Как заработать деньги
Существует так много типов футбольных лотерейных билетов, что людям не терпится их приобрести. Здесь мы анализируем только самый простой метод одноигровой лотереи в футбольной лотерее. Формула расчета фиксированного бонуса по одиночной ставке для одной игры: коэффициент одиночной игры в выбранной игре × 2 юаня × кратное.
Предположим, что Да Чжуан делает ставки на n+m игр, правильно угадывает n игр и шансы на n угаданных игр равны соответственно, тогда общая прибыль, которую Да Чжуан может использовать для покупки пакетов для Сяо Мэй, рассчитывается следующим образом:
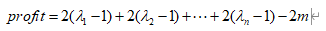
Пусть общая прибыль profit>0,Давайте сделаем простой вывод приведенной выше формулы:
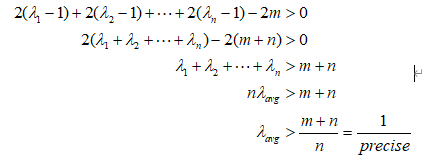
Он показывает, что если вы хотите, чтобы конечная общая прибыль была больше нуля, обратная величина точности прогнозирования игры со ставками должна быть меньше, чем средние шансы угадать игру, то есть следующая формула должна быть удовлетворен:

Для нашей текущей наиболее эффективной модели (NN+SVM) в тренировочном наборе Премьер-лиги (1339 игр) и тестовом наборе (365 игр) результаты прогнозирования следующие:

Результат по-прежнему не соответствует требованиям формулы (1), а это означает, что когда мы делаем ставки, полностью основываясь на результатах прогнозирования модели, мы обязательно потеряем деньги в долгосрочной перспективе.
2.2 Анализ интервала вероятности прогнозирования модели
Результаты игры, предсказанные моделью, дают соответствующие вероятности. Независимо от того, существуют ли они в определенном интервале, значение вероятности прогнозируемых результатов удовлетворяет формуле (1). Таким образом, вам нужно только скорректировать стратегию ставок на основе прогнозируемых вероятностей.
В дополнение к исходному тестовому набору (365 игр) в качестве тестовых наборов для тестирования были случайным образом сгенерированы 100, 200, 300 и 100 игр Премьер-лиги в новом сезоне 2015 года. Результаты показаны ниже:
1/точность является обратной величиной точности прогнозирования игры.
Bet_odds_avg — это средний коэффициент, соответствующий правильно предсказанным играм.
Odds_avg — средний коэффициент, соответствующий результатам матча в каждом интервале.
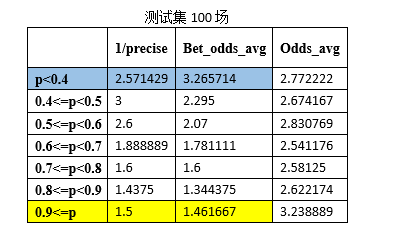
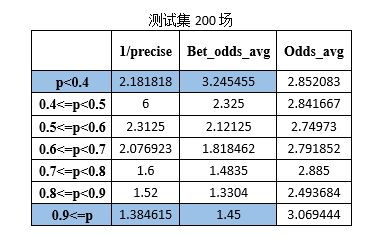
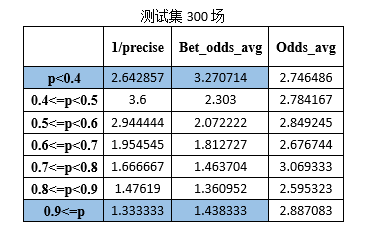
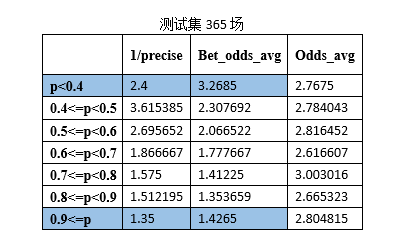
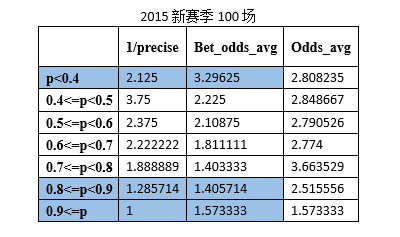
Результаты, полученные при обучении, вы можете увидеть на текущей обучающей выборке (1339 игр, ни одной расстроенной игры). SVM Модель прогнозирования матчей Премьер-лиги в Prob. p<0.4иp>=0.9 Интервал удовлетворяет формуле (1), то есть, когда прогнозируемая вероятность системы прогнозирования футбольной лотереи находится в пределах такого интервала, ставки могут быть прибыльными. Выполняйте смоделированные ставки на основе этой стратегии ставок и делайте только одну ставку, если она соответствует требованиям вероятности. Могут быть получены следующие данные:
В более широком смысле, применима ли эта стратегия ставок к другим четырем высшим лигам? Аналогичным образом мы случайным образом сгенерировали 100, 200 и 300 тренировочных наборов для тестирования Ла Лиги, Серии А, Бундеслиги и Лиги 1 соответственно.
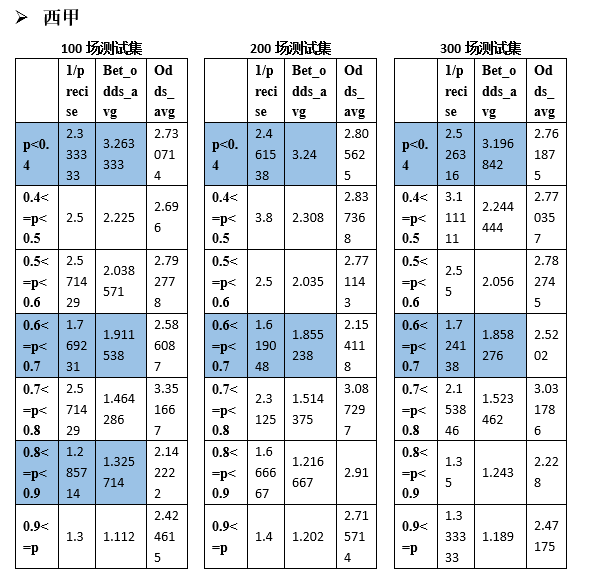
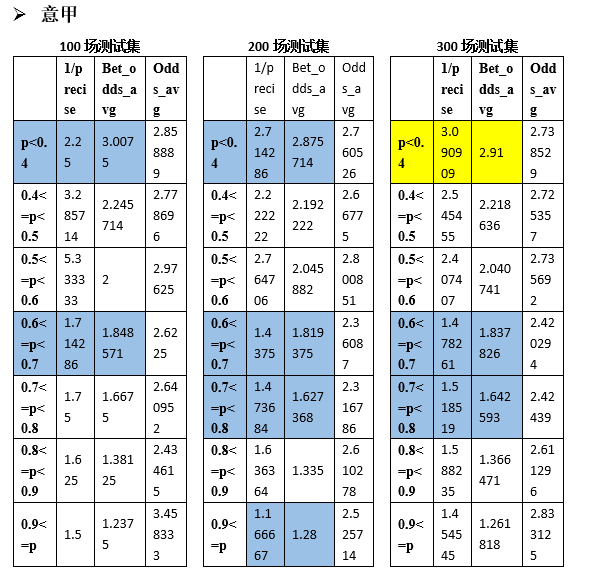
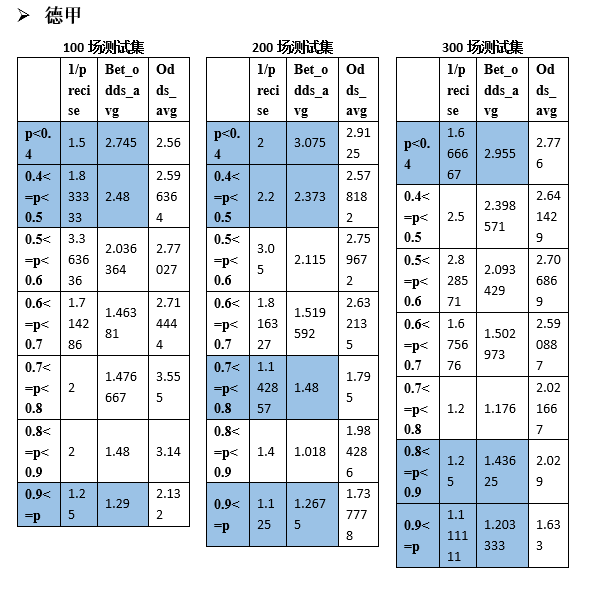
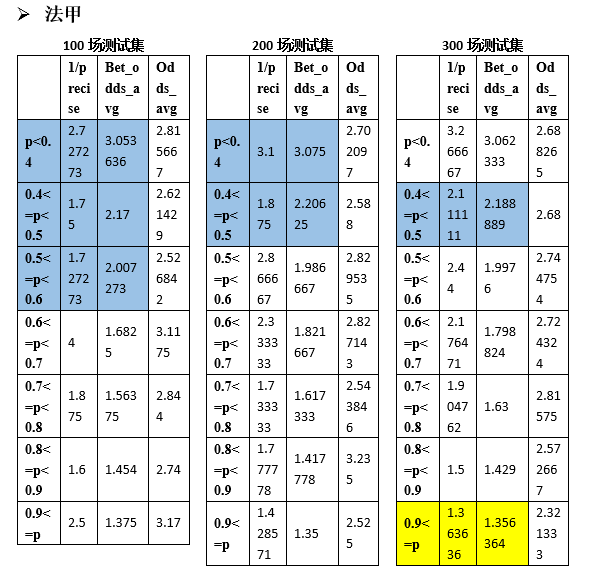
Видно, что и другие лиги имеют аналогичные интервалы вероятности, удовлетворяющие формуле прибыли (1). Статистика следующая:
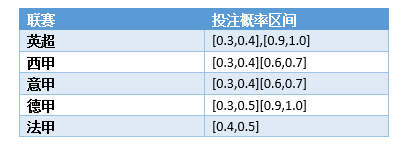
2.3 Проблемы
- Текущие правила интервала ставок на прибыль применялись только к серии из примерно 300 игр в каждой лиге.,Можно ли быть более универсальным?,Также необходимо иметь больше данных о совпадениях для тестирования и проверки.
- Существующие стратегии ставок ограничены диапазоном вероятности прогноза, а соотношение ставок на игры к общему количеству игр недостаточно велико. Например, Премьер-лига составляет 20%, а коэффициент ставок на французскую Лигу 1 — всего 7% из-за низкой точности. .
- Поскольку коэффициенты ставок на события будут колебаться, уровень прибыльности будет сильно различаться в зависимости от различных тренировочных наборов, что затрудняет обеспечение высокого и стабильного уровня прибыльности.
03、One more thing
Видя это, амбициозный и жаждущий знаний одноклассник (ду) студент (гоу) уже горит желанием попытаться продемонстрировать свои таланты на этом Кубке Европы. Все больше студентов, которые еще способны учиться, начинают делать выводы из одного примера и готовятся посвятить себя более масштабным сценариям применения, таким как прогнозирование акций. Прогнозирование акций, или профессионально известное как финансовая количественная оценка, использует большие данные и профессиональные математические модели, чтобы заменить субъективное человеческое суждение при выборе акций и сроках, чтобы получить стабильную и устойчивую избыточную прибыль. Подобно прогнозам футбольных лотерей, финансовая количественная оценка также требует сбора данных, анализа признаков и модулей модели прогнозирования. Но также необходимы более сложные системы выбора акций и торговые системы. На рисунке ниже представлена схематическая диаграмма простой финансовой количественной торговой системы.
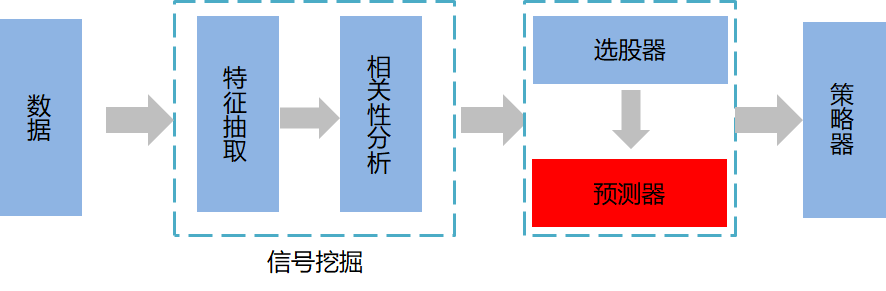
Благодаря бурному развитию технологий искусственного интеллекта за последние 20 лет активно продвигалась автоматизация, основанное на данных и интеллектуальное развитие количественной торговли. Однако, поскольку количественная торговля является проблемой, затрагивающей множество областей, большой объем математических знаний, финансовых знаний и системной инженерии, она более сложна в практическом применении по сравнению с теоретическими предположениями и содержит больше иррациональных факторов и непрозрачной информации. и другие актуальные практические вопросы. Полное описание или даже краткое введение в количественный трейдинг достойно отдельной статьи. Вот лишь введение и простое расширение метода в предыдущем прогнозе футбольной лотереи. Далее в основном рассказывается о том, как объединить приложение с прогнозированием запасов с двух аспектов: анализ сигналов и модуль прогнозирования.

3.1 Добыча сигналов
По сравнению с данными футбольных прогнозов, существует множество сигналов, связанных с акциями, которые значительно расширились с точки зрения количества и характеристик. От самых основных цен открытия и закрытия до технических индикаторов акций, таких как MACD, KDJ и т. д., до абстракции фундаментальной информации об акциях. Существует множество измерений сигналов и характеристик. Ключ заключается в следующем: во-первых, как извлечь больше сигналов с помощью корреляции акций, во-вторых, количественную оценку корреляции и анализ признаков;
1. Извлечение эффективных релевантных сигналов
В дополнение к общедоступной биржевой информации качество прогнозируемого эффекта во многом будет определяться тем, как извлекать более эффективные релевантные сигналы. Такие как события, горячие точки в социальных сетях и т. д. Это требует построения полноценной и систематической системы сбора данных, сигналов для расширения базы источников информации.
- Огромный индекс тепла Шумиха в СМИ. Популярность в поиске. Социальная популярность.
- непредвиденныйданныеактуальность Пиво против подгузников. Фондовый рынок против индекса страха в социальных сетях. Эпидемия гриппа и популярные поисковые запросы.
2. Количественная оценка корреляции признаков
Имея большое количество сигналов данных, необходимо создать систему оценки корреляции признаков, исключить грубость и выбрать суть, максимально уменьшить помехи, выбрать объясняющие переменные с сильной прогностической способностью и улучшить качество источники информации.
Обычно используются следующие методы:
1. Метод анализа коэффициента корреляции:
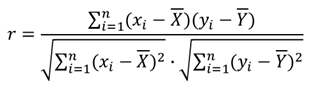
2. Метод анализа информации КЛ:

3. Проверка гипотез: P-значение.
4. Извлекайте информацию для встраивания с помощью сетей глубокого обучения.
3.2 Модель прогнозирования
Типы количественных инвестиций включают количественный выбор акций, количественный выбор времени, статистический арбитраж и т. д. Здесь мы рассматриваем только прогнозирование роста и падения акций в качестве примера для рассмотрения модели прогнозирования. Чтобы предсказать взлет и падение, помимо возможности использовать те же традиционные модели машинного обучения, что и в приведенных выше прогнозах футбольной лотереи, характеристики биржевых данных очень подходят для использования моделей глубокого обучения и сложных моделей, связанных с временными рядами, таких как DNN, LSTM и популярная сейчас модель-трансформер.
- Информация о запасах — это достаточно «большие данные»
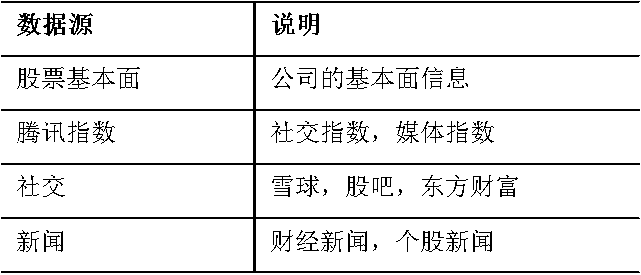
- Информация о запасах имеет естественные «последовательные» характеристики.

Из приведенного ниже эксперимента по сравнению доходности тестового набора мы видим, что модель глубокой нейронной сети в сочетании с LSTM имеет более высокую точность прогнозирования, а также значительно улучшаются избыточная доходность Alpha и коэффициент доходности от торговли.
Простая модель против модели LSTM
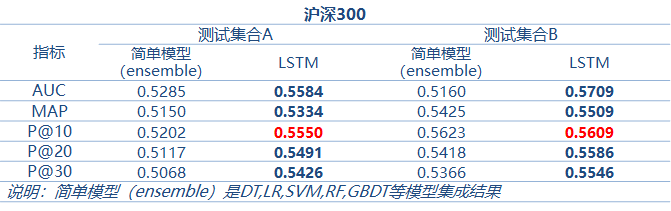
Точность прогнозов выросла в среднем на 3%
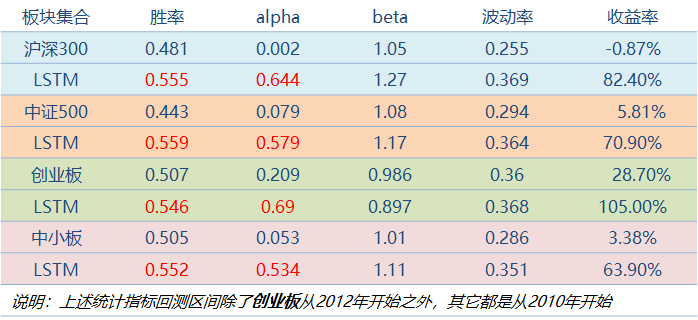
В разных секторах наблюдается стабильная избыточная альфа
04. Заключение
Лю написал в постскриптуме «Задачи трех тел»: «Наблюдая за футболом в последнем ряду стадиона, сложные технические движения самих игроков были скрыты расстоянием. То, что появляется на площадке, — это всего лишь футбольный мяч, состоящий из из двадцати трех очков и одного специального очка. Постоянно меняющаяся матрица состава существует только в видах спорта с мячом. Футбольная игра представляет собой такую четкую математическую структуру, которая также может быть одной из прелестей этого вида спорта: «В течение 90 минут зеленое поле, полное чудесного напряжения, является самым захватывающим очарованием футбола, и мы постоянно исследуем неизведанное и долгое. для него предсказание будущего — это инстинктивное стремление человека. Метод модели прогнозирования футбольной лотереи, представленный в этой статье, основан на шансах и фундаментальных характеристиках команды и реализовал прогнозирование результатов пяти основных европейских лиг. Точность прогнозирования Премьер-лиги достигла 54,55%. На основе модели прогнозирования футбольной лотереи, предложенной в этой статье, можно реализовать эффективное угадывание выигрыша-ничьи-проигрыша в одной игре и прогнозирование счета на основе прогнозируемого значения вероятности.
Однако текущая версия системы прогнозирования все еще имеет множество недостатков:
- образцы данных все еще требуют дальнейшего накопления,Дальнейшее расширение выборки данных конкурса,Добавлена Суперлига Китая и кубковые соревнования, такие как Лига чемпионов и Лига чемпионов AFC;
- Особенность майнинга. для DNN Модель,Текущие размеры объекта все еще слишком малы.,Эффективных функций не так много. Дальнейшее изучение эффективных функций — одна из следующих важных задач. Например, коэффициенты меняют значение,Боевой порядок, уровень усталости игрока, важность игры,Последние новости команды и многое другое,Далее изучайте и анализируйте факторы, влияющие на игру.
- Текущая стратегия ставок с использованием вероятностей прогнозирования футбольных лотерей по-прежнему относительно проста, и ее стабильность и применимость все еще нуждаются в тестировании и корректировке на большем количестве наборов данных.
- Добавьте прогнозы на другие результаты игры, например, количество забитых голов, вероятность неудач в сильных и слабых командах и т.д.
Метод, описанный в этой статье, не является идеальным «демоном Лапласа». В сочетании с новыми и более полными данными и новейшими методами искусственного интеллекта для больших моделей каждый может использовать свое воображение и знания предметной области для создания более полной системы прогнозирования футбола. Наслаждаясь страстным противостоянием на зеленом поле, ощутите бесконечное очарование данных и машинного обучения.
Ссылки
[1] Dixon, M., & Pope, P. (2004). The value of statistical forecasts in the UK associationfootball betting market. International Journal of Forecasting, 20, 697-711
[2] Goddard J, Asimakopoulos I. Forecasting football results and the efficiency of fixed‐odds betting[J]. Journal of Forecasting, 2004, 23(1): 51-66.
[3] Constantinou A C, Fenton N E, Neil M. pi-football: A Bayesian network model for forecasting Association Football match outcomes[J]. Knowledge-Based Systems, 2012, 36: 322-339.
[4] Mittal A, Goel A. Stock prediction using twitter sentiment analysis[J]. Standford University, CS229 (2011 http://cs229. stanford. edu/proj2011/GoelMittal-StockMarketPredictionUsingTwitterSentimentAnalysis. pdf), 2012, 15: 2352.
[5] Ding X, Zhang Y, Liu T, et al. Deep learning for event-driven stock prediction[C]//Twenty-fourth international joint conference on artificial intelligence. 2015.
Примечание. Эта статья представляет собой технический обмен, пожалуйста, участвуйте с развлекательным настроем, с удовольствием покупайте лотерейные билеты и делайте ставки рационально.
-End-
Автор оригинала|Цю Фухао



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
