Крупномасштабные гетерогенные кластеры, гибридные параллельные распределенные системы, объясняющие проблему несбалансированной вычислительной мощности HETHUB
Видеоурок здесь:
1. Причины возникновения крупномасштабных гетерогенных кластеров:
Ограниченное количество однотипных графических процессоров затрудняет построение крупномасштабного кластера:Обучение крупномасштабных моделей зависит от огромных вычислительных ресурсов.。Например,тренироватьсяGPT-4Модель(1.8Триллионы параметров)нуждаться25000индивидуальныйA100 графический процессор. Создание крупномасштабных кластеров с использованием графического ускорителя — непростая задача. Создание крупномасштабных кластеров с использованием нескольких типов графических ускорителей — эффективный способ решить проблему нехватки однородных графических ускорителей.
Однако,Существующие крупномасштабные модели распределенных систем обучения поддерживают только однородные ускорители графических процессоров и не поддерживают гетерогенные ускорители графических процессоров.。
Поэтому появилась HETHUB — гибридная система параллельного распределенного обучения крупномасштабных моделей.,Система поддерживает гетерогенные кластеры.,включатьAMD、Nvidia Графические процессоры и другие типы графических ускорителей. Он представляет собой распределенный унифицированный коммуникатор, обеспечивающий связь между гетерогенными ускорителями графического процессора, распределенный предсказатель производительности и автоматический параллельный планировщик для эффективной разработки и обучения моделей с использованием гетерогенных ускорителей графического процессора. По сравнению с системами распределенного обучения с однородными ускорителями графического процессора, наша система может поддерживать шесть комбинаций гетерогенных ускорителей графического процессора. Мы обучаем модель Llama-140B на гетерогенном кластере с 768 GPU-ускорителями (128 AMD и 640 GPU-ускорителями). Экспериментальные результаты показывают, что лучшая производительность нашей системы в гетерогенных кластерах достигает 97,49% от теоретического верхнего предела производительности.
2. Проблемы гетерогенных крупномасштабных кластеров
1) Проблемы общения。разные типыGPUАкселераторы не могут напрямую общаться друг с другом,Потому что разные типы ускорителей ЦП имеют разные библиотеки связи.,Такие как Нвидиа Графический процессор использует NCCl, а ускоритель графического процессора C использует HCCL.
2) Проблемы распределенного обучения из-за несбалансированной вычислительной мощности.。для больших масштабов в гетерогенных кластерах Модель Спроектируйте и внедрите оптимальные распределенныетренироваться Стратегия – это очень сложно。разные типыGPUускорительразличия в вычислениях и хранении, а также крупномасштабные Модель Характеристики сильной связи вычислений и коммуникации приводят к увеличению количества распределенных стратегий по мере увеличения гетерогенности.GPUускоритель、Количество слоев или операторов модели растет экспоненциально.
3) Проблема точности。разные типыGPUускоритель Разница в точности верхнего оператора составит Модель Точность трудно достичь точности однородной кластеризации.。
Поэтому HETHUB, гибридная система параллельного распределенного обучения крупномасштабных моделей, проделала следующую работу.
1. Гетерогенное общение:Мы построилииндивидуальныйраспределенный унифицированный коммуникатор для поддержки различныхGPUускорительобщение между。Коммуникаторвключатьдваиндивидуальный Коммуникационная библиотека,Один из них представляет собой коммуникатор Ethernet или IPoIB на базе ЦП, другой — коммуникатор на базе графического процессора с IB или RoCE;,Он определяет унифицированный интерфейс связи для поддержки нескольких типов графических ускорителей.
2. Распределенный предиктор производительности,Помочь оценить стратегии распределенного обучения моделей в гетерогенных кластерах. Выполняем автоматический анализ на небольшом кластере,и построить модели оценки эффективности. Затем,Эту модель оценки производительности можно использовать для прогнозирования производительности.,направлять Крупномасштабный Принятие решений по стратегиям распределенного обучения на кластере.
3. Автоматический параллельный планировщик,Он может автоматически искать оптимальные стратегии распределенного параллелизма для заданной модели и топологии гетерогенного кластера. Это может повысить эффективность разработки и расчета модели.
Гетерогенное общениеПожалуйста, обратитесь к предыдущим блогам и видео.
Сегодня мы сосредоточимся на,Проблемы распределенного обучения из-за несбалансированной вычислительной мощности。
три、Несбалансированная вычислительная мощностьНеравномерная стратегия разделения
Основные идеи гетерогенной вычислительной мощности, несбалансированной вычислительной мощности и разделения моделей.
3.1 Неравномерная стратегия разделения, основанная на параллелизме конвейеров
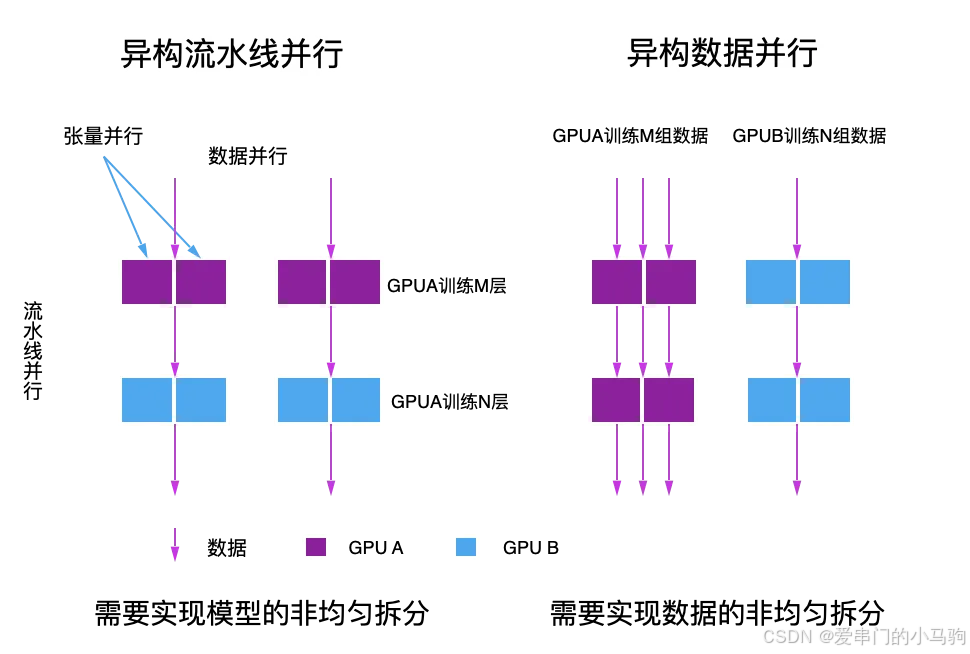
При обучении больших языковых моделей можно использовать гетерогенное обучающее решение, основанное на конвейерном параллелизме, для эффективного решения проблемы несбалансированной вычислительной мощности за счет неравномерного разделения слоя преобразователя. В соответствии с фактической вычислительной мощностью каждого чипа, чип с более высокой вычислительной мощностью может обрабатывать больше слоев, а чип с более низкой вычислительной мощностью может обрабатывать меньше слоев. С точки зрения структуры модели объем вычислений для каждого слоя одинаков. , поэтому в соответствии с коэффициентом вычислительной мощности можно достичь наилучших результатов в качестве коэффициента разделения слоев. Например, предположив, что вычислительная мощность чипа A в 4 раза превышает мощность чипа B, вы можете позволить чипу A рассчитывать 4-слойные трансформаторные модули, а чипу B — 1-слойные трансформаторные модули для достижения оптимального распределения ресурсов In. Теория, высочайшая производительность.
3.2 Гетерогенное обучение на основе параллелизма данных
Гетерогенное обучение, основанное на параллелизме данных, также позволяет справиться с различиями в вычислительной мощности, регулируя размер пакетной обработки данных на разных чипах. Например, в ситуации, когда вычислительная мощность чипа A в 4 раза превышает вычислительную мощность чипа B, чипу A можно разрешить вычислять 4 пакета на каждой итерации, тогда как чип B может рассчитывать только 1 пакет, тем самым балансируя рабочую нагрузку каждого чипа. и достижение теоретической оптимальной производительности.
Добавьте комментарий к изображению, не более 140 слов (по желанию)
3.3 Конвейерный параллелизм для гетерогенных узлов
Учитывая, что производительность связи между гетерогенными ускорителями GPU ниже, чем между однородными ускорителями GPU, мы
1. Используйте параллелизм данных на однородных узлах
2. Тензорный параллелизм внутри узлов.
3、через Конвейерный параллелизм для гетерогенных узлов。
4. Автоматический процесс разделения гетерогенных моделей вычислительной мощности.
Согласно основной идее разделения модели, создается поисковое пространство для получения окончательного метода разделения модели.
Добавьте комментарий к изображению, не более 140 слов (по желанию)
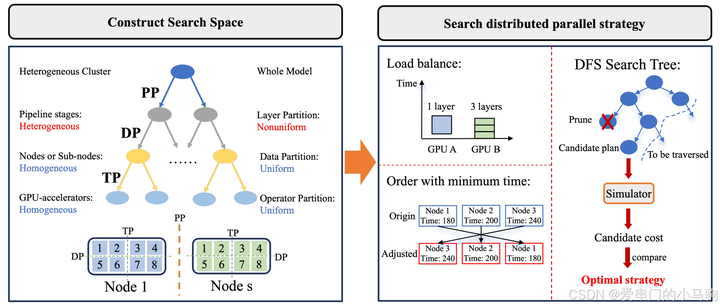
4.1 Создайте пространство поиска
Трехуровневое дерево поиска строится для представления пространства поиска стратегии распределенного обучения модели. Корневой узел представляет всю модель, а другие узлы представляют разделенные подмодели. Кроме того, конечные узлы представляют собой окончательную модель, выполненную в одном ускорителе графического процессора.
Уровень 1. Разделите модель на основе общего количества слоев преобразователя, используя стратегию параллельного разделения неоднородного конвейера. Цель разделения — обеспечить балансировку вычислительной нагрузки разных типов графических ускорителей.
Второй уровень: разделение подмоделей на однородные узлы с использованием единой стратегии параллелизма данных.
Третий уровень: разделить модель, используя единую стратегию тензорных параллельных вычислений.
После трехуровневой сегментации полную модель можно сопоставить с гетерогенными кластерами для обучения.
4.2. Поиск стратегий распределенного обучения.
Чтобы в полной мере использовать ресурсы гетерогенных ускорителей графического процессора, мы даем два правила, нацеленные на балансировку нагрузки и минимальное время сквозного обучения, для управления распределенным параллельным поиском по политикам в построенном дереве поиска.
1) Балансировка нагрузки. В соответствии с вычислительными ресурсами гетерогенных ускорителей графического процессора и вычислительными требованиями уровня модели мы разделяем уровень модели неравномерно, чтобы максимально сбалансировать вычислительные задачи между различными ускорителями графического процессора. То есть ускорители графического процессора с высокими вычислительными ресурсами выполняют больше слоев.
2) Кратчайшие сроки сквозного обучения. Мы планируем этапы параллелизма конвейера для разных типов графических ускорителей на основе времени выполнения этапов на разных типах графических ускорителей и времени связи между этапами, чтобы оптимизировать время сквозного обучения.
Ссылки:



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
