Краткое описание и настройка механизма управления памятью Flink JobManager
обзор
Мы знаем, что JobManager старой версии Flink как менеджер отвечает только за задачи инициализации и координации. Нехватка памяти очень мала, а OOM и другие проблемы возникают редко.
Однако с Flink CDC [1] Широкое использование и внедрение технологии сбора данных в реальном времени. Flink новая версия Source интерфейс(FLIP-27: Refactor Source Interface [2]) Connector Все чаще JobManager Его обязанности становятся все тяжелее и тяжелее: он также берет на себя ответственность за регулярное динамическое распознавание и координацию сегментирования данных (SplitEnumerator Подробности о конструкции см. [3] статья). Особенно когда объем данных велик и асимметрия данных серьезная, очень легко получить сбой из-за нехватки памяти, что приведет к JobManager Авария и выезд, последствия очень серьезные.
в предыдущей статье Flink TaskManager Введение в механизм управления памятью и краткий обзор настройки [4] , мы систематически объяснили Flink новая Модель памяти версии, основанная на мотивах дизайна и подробно описанная TaskManager Технические принципы и опыт онлайн-конфигурации каждой области и подобласти памяти. Эта статья посвящена объяснению JobManager Совместное использование структуры памяти и связанного с ней опыта помогает заданиям выполняться быстрее и стабильнее.
Обзор раздела памяти JobManager
Аналогично мы начинаем со схемы разделов памяти JobManager [5] на официальном сайте Flink.

Видно, что по сравнению с разделом памяти TaskManager раздел памяти JobManager довольно прост: только общая память процесса JVM, общая память Flink, память кучи, память вне кучи, метапространство JVM. , и накладные расходы во время выполнения JVM больше не различаются. Нет областей инфраструктуры и пользовательских областей, а также других областей, таких как управляемая память и сетевой кэш.
Но это не означает, что память JobManager лучше управляется; напротив, это означает, что сообщество Flink по-прежнему контролирует память JobManager очень грубо, поэтому, когда возникают проблемы, они более скрыты и их труднее устранить. найти, поэтому этому следует уделить особое внимание.
Подробное объяснение каждой области памяти JobManager.
Аналогичным образом мы анализируем использование каждой из вышеперечисленных областей памяти по отдельности, а также опыт онлайн-конфигурации и настройки.
Общая память процесса JVM (Total Process Memory)
Эта территория представляет собой всю JVM Использование памяти процессом включает в себя все области памяти, представленные ниже. Обычно он используется для установки квот ресурсов для контейнерных сред (YARN, Kubernetes). Например, мы установили Flink параметр jobmanager.memory.process.size для 4G, то если JVM Случайно использовано больше физической памяти (RSS, RES). и т. д.), вам придется прекратить работу (SIGKILL, эквивалент kill -9)изрезультат。
потому что JobManager Отвечает за координацию всей операции, а также за работу с ZooKeeper ждать HA Если служебная связь прерывается напрямую из-за чрезмерного использования ресурсов, последствия будут более серьезными, чем TaskManager Более серьезно: например, последний снимок еще не подтвержден, а недавно начавшийся JobManager Невозможно найти доступную информацию о снимках, что может привести к потере данных или двойному учету.
Поэтому в Существуют жесткие проверки квот ресурсов. из В контейнерной среде,Пожалуйста, работайте после полного испытания под давлением.,Правильно настройте параметр,Оставьте как можно больший запас прочности.
Общая память Flink (Total Flink Memory)
Flink Общая память относится к JobManager Область памяти, которую можно воспринимать и которой можно управлять, то есть вышеупомянутая JVM Общая память процесса вычесть еще раз Flink неконтролируемый Метапространство и Накладные расходы (накладные расходы времени выполнения) две области.
мы можем использовать jobmanager.memory.flink.size параметр для управления Flink Порог общего объема памяти для неконтейнерных сред (например, Standalone режим ожидания), вы можете установить этот параметр, чтобы разрешить Flink Рассчитайте размер каждой подобласти памяти самостоятельно.
В реальных бизнес-сценариях мы рекомендуем, чтобы общий объем Flink-памяти JobManager был не менее 1,5 ГБ, чтобы обеспечить стабильность работы.
Куча памяти JVM
для JobManager С точки зрения кучи памяти (JVM проходить -Xmx и -Xms Параметр управления (область памяти, доступная для сборки мусора из области памяти) имеет следующие цели:
- Flink Сам фреймворк из накладных расходов, таких как RPC Общение, Интернет UI Кэширование, высокая доступность, связанная с ожиданием потоков
- Различные типы новой версии Connector из SplitEnumerator, используемые для динамического восприятия и разделения источников данных при шардинге.
- Режим развертывания ожидания сеанса или приложения,Когда пользователь отправляет задание,Выполнить код пользовательской программы,Также может быть выделение памяти
- Пользовательский код функции обратного вызова контрольной точки (CheckpointListener),Используется для уведомления о событиях завершения и сбоя моментального снимка.,или Выполнить пользовательскую логику
Размер кучи памяти в параметре конфигурации: jobmanager.memory.heap.size。нужно особое вниманиеизда,Если параметр настроен,Пожалуйста, не настраивайте вышеупомянутоеиз JVM Общая память процесса или Flink общая память параметр, чтобы избежать неправильной конфигурации.
в производственной среде,Мы часто сталкиваемся с клиентами, которым необходимо предоставить MySQL CDC Connector для доступа к очень большим таблицам (миллиарды данных), в то время как Flink CDC Размер чанка по умолчанию 8096. так SplitEnumerator Могут быть сгенерированы сотни тысяч осколков, в результате чего JobManager Память исчерпана.
В этом случае самый простой способ — увеличить CREATE TABLE заявление WITH параметрсередина scan.incremental.snapshot.chunk.size значение, например, увеличить 100000, так По мере того, как каждый шард становится больше, общее количество шардов будет значительно уменьшаться. Также будет снижено давление кучи памяти. Однако когда осколки становятся больше, диспетчер задач Давление обработки соответственно увеличится, поэтому TaskManager станет более вероятным ОММ, нажми на тыкву, чтобы поднять совок.
Tencent Cloud Stream Computing Oceanus разработала функцию, позволяющую значительно сократить использование динамической памяти JobManager при очень большом объеме данных. По сравнению с версией с открытым исходным кодом она может снизить использование динамической памяти примерно на 70%. В следующих статьях мы объясним принципы оптимизации, и каждый может попробовать ее.
Кроме Connector верно JobManager Вызывает давление кучи памяти снаружи, когда пользователь отправляет данные Flink задание, если создаются дополнительные долгосрочные потоки (например, Curator Координировать объем обработки данных нескольких заданий), что также может привести к Classloader Связанный объект памяти не может быть переработан, что в конечном итоге приводит к утечке памяти.
Память вне кучи JVM
JobManager из Объем внешней памяти обычно невелик, обычно делится на JVM Управление прямой памятью и проведением UNSAFE.allocateMemory Выделенный блок собственной памяти.
За пределами жесткая память из параметра конфигурации jobmanager.memory.off-heap.size,по умолчаниюда 128M, но это всего лишь джентльменское соглашение. Оно используется для вычета суммы при расчете размера кучи памяти и не ограничивает чрезмерное использование. Но если дополнительная настройка jobmanager.memory.enable-jvm-direct-memory-limit для true,но Flink встречапроходить -XX:MaxDirectMemorySize строго ограничить Direct Использование памяти области. Если им действительно злоупотребляют, его немедленно выбрасывают. OutOfMemoryError: Direct buffer memory аномальный.
Flink С точки зрения аспектов, пользователи памяти вне кучи в основном включают Flink Akka Связь с инфраструктурой и код, когда пользователи отправляют задания (обычно редко), или Checkpoint Пользовательский код в функциях обратного вызова (тоже обычно редко).
В нормальных условиях проблем с памятью вне кучи возникает очень мало. Но если он часто появляется в куче OOM Если вы все еще не можете найти причину, вы можете попробовать включить вышеуказанное limit Ограничения (ограничения все еще существуют, см. [6], чтобы определить, связано ли это с Direct Бесконечный рост области приводит к сжатию пространства кучи.
Метапространство JVM
JVM Metaspace В основном сохраняет загрузку класса и метода из метаданных, Flink Конфигурацияпараметрдля jobmanager.memory.jvm-metaspace.size,Размер по умолчанию — 256 МБ.
Обычно нет необходимости настраивать его, если пользователь не фиксирует Flink В ходе работы использовалось много динамической генерации и загрузки классов. «волшебство», вызывающее JVM Сообщить OutOfMemoryError: Metaspace.
Накладные расходы во время выполнения JVM (JVM Overhead)
Кроме Описание выше из Heap、За пределами кучи、вне метапространства,JVM При самом запуске также будут возникать некоторые накладные расходы на память, которая используется для хранения времени ожидания кэша кода. Флинк fromКонфигурацияпараметрдля jobmanager.memory.jvm-overhead.fraction,по умолчаниюдля 0.1 Прямо сейчас 10% из JVM Общая память процесса;На него также распространяется минимальный порог(параметрдля jobmanager.memory.jvm-overhead.min,по умолчанию 192M) и максимальный порог (параметр для jobmanager.memory.jvm-overhead.max,по умолчанию 1G) из предела.
Если отправлено Flink При работе есть материалы JNI вызов C/C++ Связанные библиотеки классов, то эта часть пространства памяти также может быть использована. Обнаружение утечек памяти в этой области более сложное и может потребовать, например, jemalloc [7] и jeprof [8] ждать вспомогательного, я не буду здесь вдаваться в подробности. Заинтересованные читатели могут прочитать то, что я писал ранее. Flink Часто задаваемые вопросы [9] статья.
Справочное чтение
[1] https://ververica.github.io/flink-cdc-connectors/
[2] https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface
[3] https://cloud.tencent.com/developer/article/1930211
[4] https://cloud.tencent.com/developer/article/2024181
[5] https://nightlies.apache.org/flink/flink-docs-master/zh/docs/deployment/memory/mem_setup_jobmanager/
[6] https://heapdump.cn/article/142660
[7] https://github.com/jemalloc/jemalloc
[8] http://manpages.ubuntu.com/manpages/impish/man1/jeprof.1.html
[9] https://cloud.tencent.com/developer/article/1754719


Высокоуровневые операции Mongo, если данные не существуют, вставка и обновление, если они существуют (pymongo)
Проектирование и внедрение системы управления электронной коммерцией на базе Vue и SpringBoot.

Статья длиной в 9000 слов знакомит вас с процессом запуска SpringBoot — самым подробным процессом запуска SpringBoot в истории — с изображениями и текстом.

Как настроить размер экрана в PR. Учебное пособие по настройке размера видео в PR [подробное объяснение]
Элегантный и мощный: упростите операции ElasticSearch с помощью easy-es

Проект аутентификации по микросервисному токену: концепция и практика

【Java】Решено: org.springframework.http.converter.HttpMessageNotWritableException.
Изучите Kimi Smart Assistant: как использовать сверхдлинный текст, чтобы открыть новую сферу эффективной обработки информации
Начало работы с Docker: использование томов данных и монтирования файлов для хранения и совместного использования данных

Использование Python для реализации автоматической публикации статей в публичном аккаунте WeChat
Разберитесь в механизме и принципах взаимодействия потребителя и брокера Kafka в одной статье.
Spring Boot — использование Resilience4j-Circuitbreaker для реализации режима автоматического выключателя_предотвращения каскадных сбоев

13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
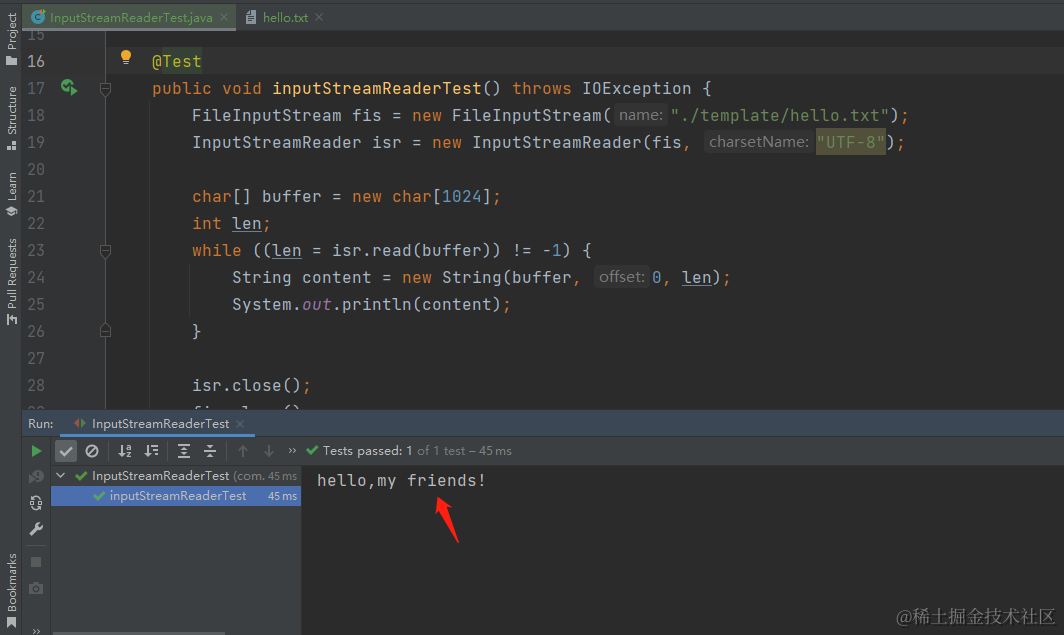
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
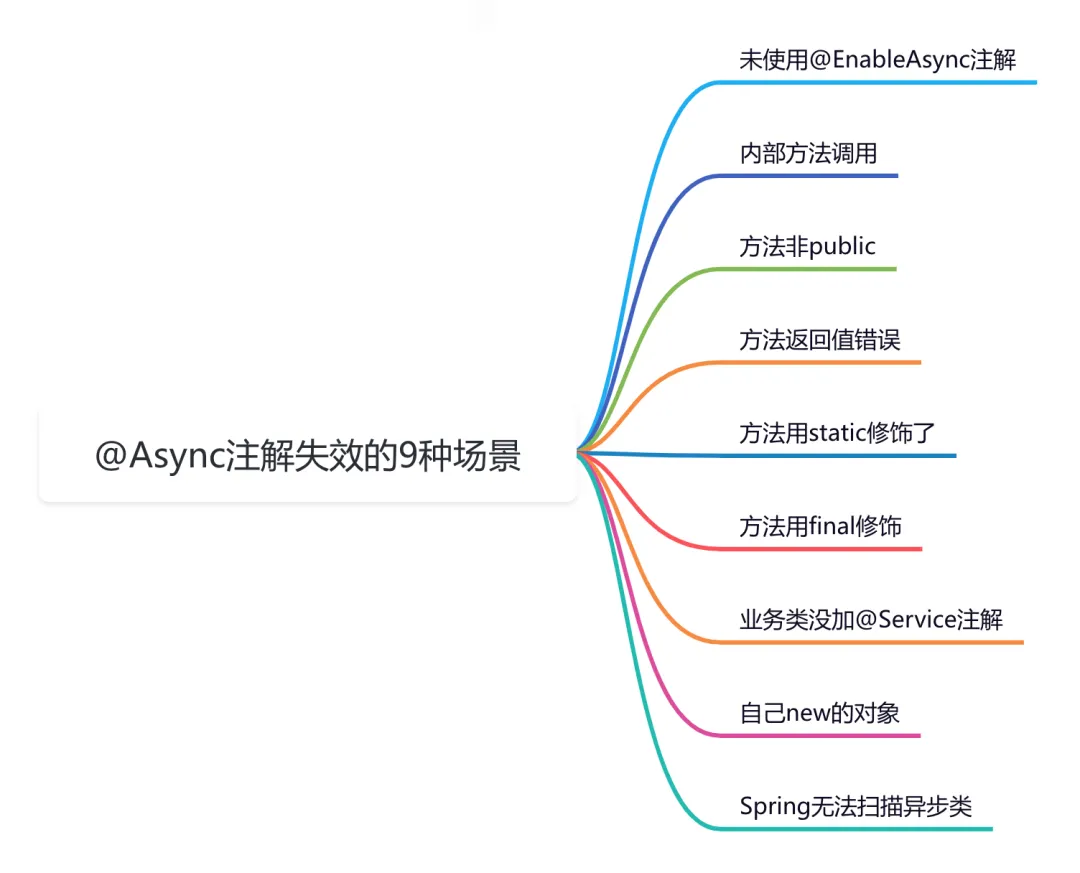
9 сценариев асинхронного сбоя @Async
