Краткое обсуждение технологии предотвращения утечки данных DLP
Предисловие
С быстрым развитием информационных технологий и популярностью Интернета,Данные становятся все более важными в современном обществе. Однако,Утечки данных стали серьёзной проблемой,За последние годы такое происходило несколько разИнцидент с утечкой больших данных:
1. Утечка данных Facebook в 2018 году: выяснилось, что Facebook предоставил пользовательские данные политической консалтинговой фирме Cambridge Analytica. Сообщается, что Cambridge Analytica получила персональные данные более 80 миллионов пользователей Facebook без их согласия для манипулирования избирателями и персонализированной рекламы.
2. 2013-2014 гг., утечки данных Yahoo: Yahoo раскрыла серию утечек данных в 2016 г., затронувших около 3 миллиардов учетных записей пользователей. Эти утечки включают конфиденциальные данные, такие как личная информация пользователей, пароли и контрольные вопросы.
3. Утечка данных Equifax в 2017 году. Американское кредитно-рейтинговое агентство Equifax было взломано, что привело к утечке личной информации примерно 143 миллионов американцев, включая имена, номера социального страхования, номера кредитных карт и другую конфиденциальную информацию.
4. В 2018 году произошел инцидент с утечкой данных Marriott: отели Marriott, принадлежащие Marriott International Hotels Group, были взломаны, и произошла утечка личной информации примерно 520 миллионов гостей, включая имена, адреса, номера телефонов, номера паспортов и т. д.
5. Утечка данных Uber в 2016 году. В 2016 году выяснилось, что Uber был взломан, что привело к утечке личной информации примерно 57 миллионов пользователей и 6 миллионов водителей, включая имена, адреса электронной почты, номера телефонов и т. д.
Поэтому исследование и применение технологий предотвращения утечки данных стали особенно важными.
Для решения проблемы утечки данных,Исследователи и технологические эксперты придумали различные методы предотвращения утечки данных.,На данный момент существуют две основные фракции,одинТехнология шифрования данных,Это также один из самых простых и часто используемых методов. Зашифровав данные,может быть преобразован в зашифрованный текст,Только те, у кого есть правильный ключ, могут расшифровать и получить доступ к данным. другой,технология идентификации данных,Он может ограничивать доступ к данным на основе личности и разрешений пользователя.,а также записывать и контролировать доступ к данным и их использование.,В целях оперативного обнаружения и реагирования на потенциальные риски утечек.
Технология обнаружения контента DLP
1. Обнаружение регулярных выражений
Подробности см.:Основные принципы регулярных выражений - longhuihu - Блог Сад (cnblogs.com)
2. многорежимное обнаружение гиперсканирования
Вышеуказанные два являются базовыми технологиями обнаружения. Основной метод обнаружения в основном использует традиционную технологию обнаружения для поиска и сопоставления контента. Эти два метода могут обнаруживать четкий конфиденциальный информационный контент. Обнаружение атрибутов документа в основном основано на типе документа и его размере. . , определяется имя документа. Определение типа документа основано на формате файла, а не просто на основе определения суффиксного имени. В случае изменения имени суффикса обнаружение типа файла может точно определить. тип обнаруженного файла. Вы можете использовать специальные функции для идентификации документов в файлах специальных типов и форматов.
3. Точное сравнение данных (EDM)
Точное сопоставление данных (EDM) защищает данные клиентов и сотрудников, а также другие структурированные данные, обычно хранящиеся в базах данных. Например, клиент может написать стратегию использования обнаружения EDM для поиска и сопоставления появления любых трех слов: «имя», «идентификационный номер», «номер банковского счета» или «номер телефона» в сообщении. в базе данных клиентов. EDM обеспечивает обнаружение на основе любой комбинации столбцов данных в определенном столбце данных, то есть обнаружение N из M полей в конкретной записи; Он может срабатывать по «группе значений» или указанному набору типов данных;
Поскольку для каждой ячейки данных сохраняется отдельный номер перемешивания, только сопоставленные данные из одного столбца могут активировать стратегию обнаружения, которая ищет различные комбинации данных. Например, если существует политика EDM, запрашивающая комбинацию «имя + идентификационный номер + номер мобильного телефона», то «Чжан Сан» + «13333333333» «110001198107011533» может активировать эту политику, но даже если «Джон Доу» также находится в той же базе данных, и «Джон Доу» + «13333333333» «110001198107011533» не может активировать эту политику.
EDM также поддерживает логику близости для уменьшения возможных ложноположительных ситуаций. Для текста произвольной формы, обрабатываемого во время обнаружения, все данные в одном столбце функций должны иметь настраиваемое количество слов, чтобы считаться совпадением. Например, по умолчанию в тексте обнаруженного тела письма количество слов «Чжан Сан» + «13333333333» и «110001198107011533» должно находиться в пределах выбранного диапазона, прежде чем появится совпадение. Для текста, содержащего табличные данные (например, электронную таблицу Excel), все данные в одном столбце функций должны находиться в одной строке табличного текста, чтобы считаться совпадением, чтобы уменьшить общее количество ложных срабатываний.
4. Сравнение документов по отпечаткам пальцев (IDM)
Сопоставление документов по отпечаткам пальцев (IDM) обеспечивает точное обнаружение неструктурированных данных, хранящихся в виде документов, таких как файлы Microsoft Word и PowerPoint, документы PDF, финансовые документы, документы слияний и поглощений и другую конфиденциальную или конфиденциальную информацию. IDM создает отпечатки пальцев. Функции для обнаружения извлеченных частей оригинала. документы, черновики или различные версии защищенных документов.
IDM сначала необходимо изучить и обучить конфиденциальные документы. При получении документов с конфиденциальным содержанием IDM использует технологию семантического анализа для сегментации слов, затем выполняет семантический анализ и предлагает модели отпечатков пальцев документов с конфиденциальной информацией, которые необходимо изучить и обучить. использует то же самое. Этот метод фиксирует отпечаток тестируемого документа или контента, сравнивает полученный отпечаток пальца с обученным отпечатком пальца и подтверждает, является ли обнаруженный документ конфиденциальным информационным документом на основе заданного сходства. Этот метод позволяет IDM иметь чрезвычайно высокую точность и большую масштабируемость.
5. Сравнение векторной классификации (SVM)
Машины опорных векторов (машины опорных векторов) были предложены Вапником и др. в 1995 году. В дальнейшем, с развитием статистической теории, машины опорных векторов постепенно привлекли внимание исследователей в различных областях и за короткий период времени получили широкое распространение.
Машина опорных векторов основана на теории размерности VC статистической теории обучения и принципе минимизации структурного риска. Она использует информацию, предоставленную ограниченными выборками, для поиска наилучшего компромисса между сложностью и способностью к обучению модели для получения наилучшего обобщения. способность.
Основная идея SVM состоит в том, чтобы нелинейно отобразить обучающие данные в многомерное пространство признаков (гильбертово пространство) и найти в этом многомерном пространстве признаков гиперплоскость, чтобы максимально изолировать границу между положительными и отрицательными примерами. .
Появление SVM эффективно решает традиционные проблемы выбора результатов нейронной сети, локальных минимумов, переобучения и другие проблемы. Он также демонстрирует множество привлекательных свойств в задачах машинного обучения, таких как небольшие выборки, нелинейность и многомерные данные, и широко используется в таких областях, как распознавание образов и интеллектуальный анализ данных.
Алгоритм сравнения SVM подходит для данных, которые имеют тонкие характеристики или которые сложно описать, например финансовые отчеты и исходные коды. В процессе использования документы сначала подразделяются и классифицируются по содержанию. Каждый тип коллекции документов имеет значение принадлежности к этой категории. После сравнения SVM определяется, к какой категории принадлежит обнаруженный документ, а также разрешения и права. политики таких документов получены. В то же время, основываясь на характеристиках SVM, документы на терминале или сервере могут быть классифицированы и обнаружены в соответствии с их классификационным значением.
Разница между IDM и SVM заключается в том, что IDM сравнивает отпечаток обнаруживаемого файла с каждым файлом в обучающей модели, в то время как SVM векторизует обнаруживаемый файл и приписывает его определенному типу обучающего набора.
Форма продукта
Защита от потери данных по электронной почте
Защита от потери данных по электронной почта широко используется на предприятиях и в основном используется при экспорте корпоративной электронной почты для идентификации контента, мониторинга соответствия и аудита исходящих корпоративных электронных писем. Строго говоря, Защита от потери данных по электронной почтетакже принадлежит Сетевое DLP, но как всегда Сетевое Разница в реализации DLP — Защита. от потери данных по электронной почта обычно развертывается на основе метода MTA электронной почты. Сканер DLP может напрямую получать трафик электронной почты с уровня приложения для сканирования. DLPОбычно через три уровняIPСообщения анализируются и восстанавливаются, а трафик приложений сканируется.。Наиболее репрезентативны здесьБезопасность Крокодил DLP:

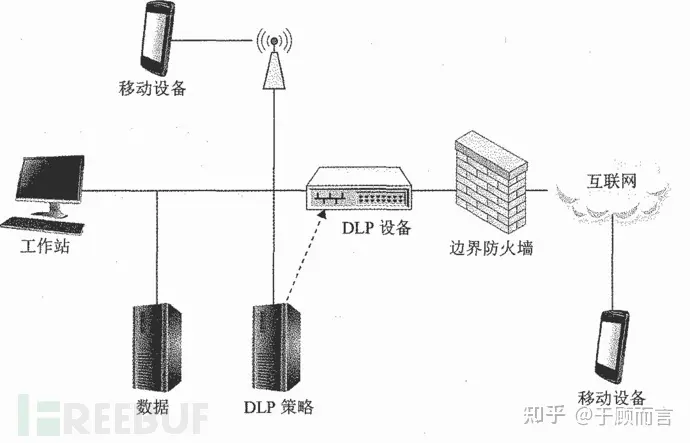
Сетевое DLP
Сетевое DLP (NDLP) в основном развертывается на внешних соединениях предприятия и внутри предприятия. Он выполняет идентификацию контента, мониторинг соответствия и аудит сетевых данных посредством зеркалирования или прозрачной передачи сетевого трафика. DLP зависит от сетевого трафика, и его сложно полностью охватить крупным предприятиям.
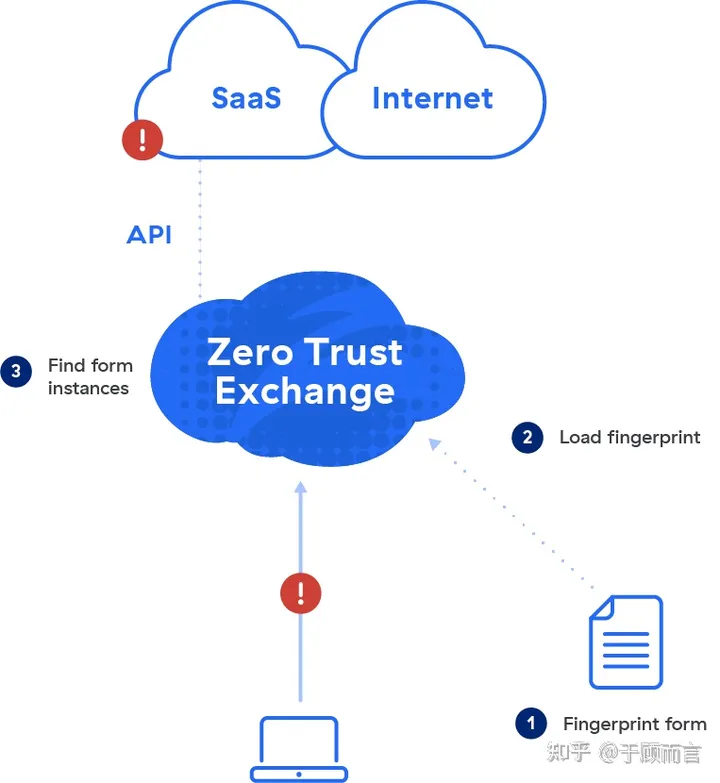
В число ведущих производителей входят zscaler:
zscaler является ведущим игроком в области SASE, а его методом реализации является облачный DLP (Cloud DLP), который является важной частью его функции безопасности данных. Механизм сопоставления DLP поддерживает расширенные функции обнаружения, такие как EDM, IDM и машинное обучение. В то же время он поддерживает сторонние механизмы обнаружения DLP через интерфейс ICAP.
Встроенный словарь очень богат:
Aadhaar Card Number (India)
ABA Bank Routing Numbers
Adult Content
Citizen Service Numbers (Netherlands)
Company Number (Japan)
Credit Cards
Financial Statements
Gambling
Identity Card Number (China)
Identity Card Number (Malaysia)
Identity Card Number (Thailand)
Illegal Drugs
Individual Taxpayer Registry ID (Brazil)
Medical Information
Medicare Numbers (Australia)
MyNumber (Japan)
Names (Canada)
Names (Spain)
Names (US)
National Health Service Number (UK)
National Identification Card Number (Taiwan)
National Identification Number (France)
National Identification Number (Poland)
National Identification Number (Spain)
National Insurance Numbers (UK)
NRIC Numbers (Singapore)
Resident Registration Number (Korea)
Salesforce.com Data
Self-Harm & Cyberbullying
Social Insurance Numbers (Canada)
Social Security Number (Spain)
Social Security Number (Switzerland)
Social Security Numbers (US)
Source Code
Standardized Bank Code (Mexico)
Tax File Numbers (Australia)
Tax Identification Number (Indonesia)
WeaponsТерминал DLP
Терминал DLP,Как следует из названия,Это управление конфиденциальными данными на корпоративных терминалах.
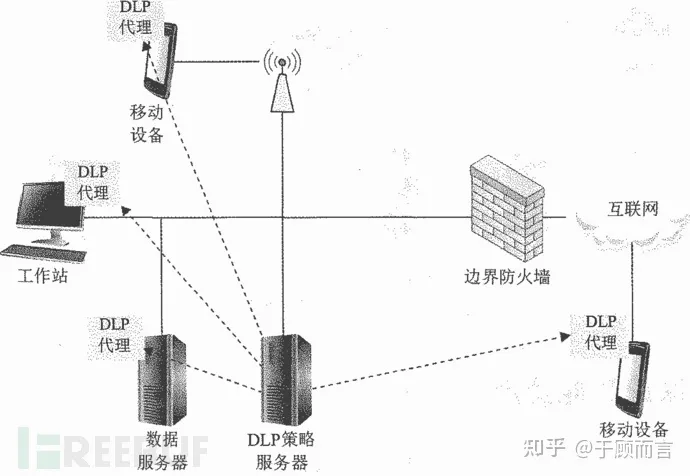
Развернув клиент в терминале,Сначала соберите данные для машинного обучения,В сочетании с требованиями управления отдела управления данными,Сформируйте стратегию иерархической классификации, подходящую для предприятия, а затем используйте клиента;,Сочетайте стратегии иерархической классификации и шифрования документов.,Применяется для ежедневного обращения и хранения данных терминала.。Более репрезентативными являютсяSymantec DLP,Он объединяет несколько технологий в набор собственных решений:
- Обнаружение конечных точек DLP --- Обнаружение конечных точек DLP.
- Предотвращение конечных точек DLP — предотвращение конечных точек DLP.
- Обнаружение сети DLP — обнаружение сети DLP.
- Защита сети DLP --- защита сети DLP.
- Мониторинг сети DLP --- Мониторинг сети DLP
- Запрет сети DLP для электронной почты --- Сеть DLP предотвращает электронную почту
- Предотвращение сети DLP для Интернета --- Предотвращение сети DLP для Интернета
- Чувствительное распознавание изображений DLP --- Чувствительное распознавание изображений DLP
- Информационно-ориентированная аналитика --- Анализ информационного центра

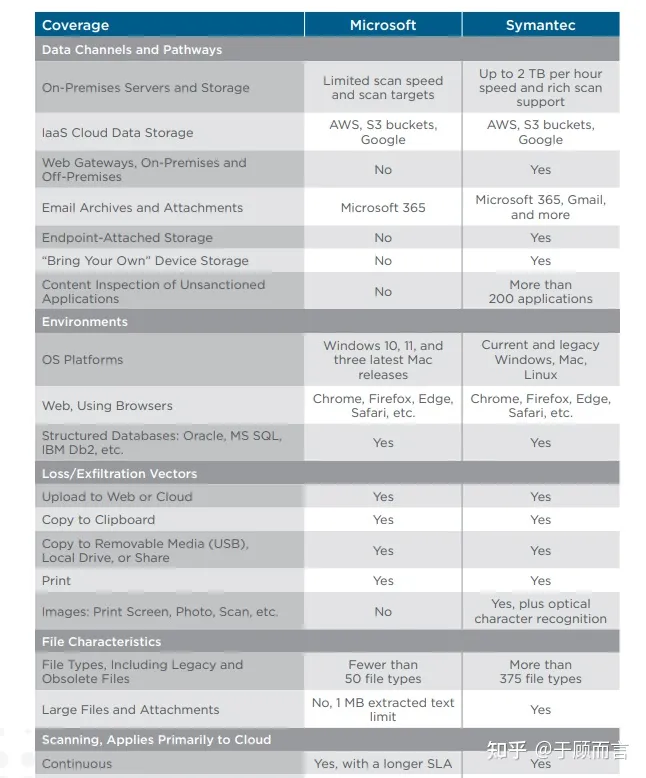
Внедрите демонстрационную версию алгоритма DLP самостоятельно
Восстановить файлы трафика,Через тот же алгоритм генерации отпечатков пальцев,Рассчитать данные отпечатка пальца отсканированного документа,Определите, применяются ли правила защиты, настроенные администратором, посредством точного соответствия и сопоставления по сходству.,Например, электронное письмо, которое произошлои Сходство конфиденциальных документов компаний настолько велико, насколько40%Просто заблокируйте его и подождите.。Заимствовать из открытого исходного кодаGitHub - ssdeep-project/ssdeep: Fuzzy hashing API and fuzzy hashing tool,Общий процесс выглядит следующим образом:
#include <stdio.h>
#include <stdlib.h>
#include <inttypes.h>
#include "fuzzy.h"
#define FILENAME "foo.dat"
#define SIZE 0x50000
void generate_random(unsigned char *buf, uint32_t sz)
{
uint32_t i;
for (i = 0 ; i < sz ; ++i)
buf[i] = (unsigned char)(rand() % 255);
buf[(sz-1)] = 0;
}
int write_data(const unsigned char *buf,
const uint32_t sz,
const char *fn)
{
printf ("Writing to %s\n", fn);
FILE * handle = fopen(fn,"wb");
if (NULL == handle)
return 1;
fwrite(buf,sz,1,handle);
fclose(handle);
return 0;
}
int main(int argc, char **argv)
{
unsigned char * buf;
char * result, * result2;
FILE *handle;
srand(1);
buf = (unsigned char *)malloc(SIZE);
result = (char *)malloc(FUZZY_MAX_RESULT); // Имитировать хеш-значение первого файла
result2 = (char *)malloc(FUZZY_MAX_RESULT); // Имитировать хеш-значение второго файла
if (NULL == result || NULL == buf || NULL == result2)
{
fprintf (stderr,"%s: Out of memory\n", argv[0]);
return EXIT_FAILURE;
}
generate_random(buf,SIZE);
if (write_data(buf,SIZE,FILENAME)) // Случайно сгенерировать первый файл
return EXIT_FAILURE;
printf ("Hashing buffer\n");
int status = fuzzy_hash_buf(buf,SIZE,result);
if (status)
printf ("Error during buf hash\n");
else
printf ("%s\n", result);
handle = fopen(FILENAME,"rb");
if (NULL == handle)
{
perror(FILENAME);
return EXIT_FAILURE;
}
printf ("Hashing file\n");
status = fuzzy_hash_file(handle,result); //хеш-шард
if (status)
printf ("Error during file hash\n");
else
printf ("%s\n", result);
fclose(handle);
printf ("Modifying buffer and comparing to file\n");
int i;
for (i = 0x100 ; i < 0x110 ; ++i)
buf[i] = 37; // Измените 10 мест на основе первого файла, чтобы создать второй файл.
status = fuzzy_hash_buf(buf,SIZE,result2); //хеш-шард
if (status)
printf ("Error during buffer hash\n");
else
printf ("%s\n", result2);
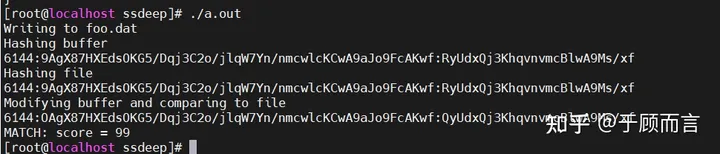
i = fuzzy_compare(result,result2); // Два файла, сравнение сходства
if (-1 == i)
printf ("An error occured during matching\n");
else
{
if (i != 0)
printf ("MATCH: score = %d\n", i);
else
printf ("did not match\n");
}
return EXIT_SUCCESS;
}
Reference
https://www.aqniu.com/industry/84089.html
https://www.freebuf.com/articles/database/229358.html
https://www.zhihu.com/question/35681178
https://baijiahao.baidu.com/s?id=1746641492584625558&wfr=spider&for=pc
https://www.freebuf.com/articles/database/275816.html
https://www.gartner.com/reviews/market/data-loss-prevention
https://www.eaglecloud.com/product/xdlp
https://www.bilibili.com/video/av201303117/
https://docs.broadcom.com/doc/data-loss-prevention-core-solution
https://www.zscaler.com/technology/data-loss-prevention
https://www.zscaler.com/resources/data-sheets/zscaler-cloud-dlp.pdf
GitHub - ssdeep-project/ssdeep: Fuzzy hashing API and fuzzy hashing tool



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
