Краткое обсуждение создания платформы для устранения неполадок при обучении больших моделей.
Общий обзор
Chat-GPT от OpenAI раскрыл нам потенциал общего искусственного интеллекта, а выпуск GPT4-Turbo еще больше расширил наше представление об общем искусственном интеллекте. В Китае возникли различные крупномасштабные модели. В то же время одна за другой возникают различные инженерные проблемы, вызванные обучением больших моделей. Обучение большой модели обычно включает в себя большое количество параметров, огромные вычислительные требования и сложные сетевые структуры, что делает весь процесс обучения чрезвычайно сложным. В этом случае ошибки, которые могут возникнуть в процессе обучения, могут быть связаны с различными аспектами, такими как аппаратное обеспечение, программное обеспечение, сеть, приложения и т. д., что чрезвычайно затрудняет обнаружение и устранение неисправностей. Любой сбой в процессе обучения может привести к прерыванию обучения, в результате чего будут потеряны все расчеты от последней контрольной точки до момента прерывания. Перезапуск обучающей задачи также занимает определенное количество времени, а дорогие вычислительные ресурсы делают каждую секунду особенно важной. Ведь «время — деньги». В этой статье основное внимание будет уделено поиску ошибок при обучении больших моделей, а также попыткам предложить некоторые идеи и методы решения, надеясь принести читателям некоторую помощь и вдохновение.
Введение в распределенное обучение
Прежде чем представить метод обучения крупномасштабной модели, нам сначала необходимо понять основной процесс обучения модели. Обучение модели обычно включает в себя следующие ключевые этапы:
- Подготовка данных: предварительно обработайте исходные данные и введите их в обучающую модель.
- Построение модели: постройте соответствующую структуру модели на основе реальных проблем.
- Инициализация параметров: присвойте начальные значения нейронам или весам модели.
- Расчет градиента. Рассчитайте ошибку между выходными данными модели и фактическим целевым значением с помощью алгоритма обратного распространения ошибки и рассчитайте градиент.
- Обновление параметров: в соответствии с рассчитанным градиентом параметры модели корректируются для уменьшения ошибки.
- Итеративная оптимизация: повторяйте вышеуказанные шаги до тех пор, пока не будет достигнуто заданное количество итераций или пока не будут выполнены другие условия остановки.
Поскольку количество параметров модели и объем вычислений очень велики, традиционные методы обучения на одной машине обычно требуют много времени для завершения обучения. Чтобы решить эту проблему, исследователи предложили метод распределенного обучения для обучения крупномасштабных моделей. Эти методы позволяют распределять задачи обучения на несколько вычислительных узлов одновременно, тем самым значительно сокращая время обучения.
Ниже мы кратко представим несколько распространенных методов распределенного обучения:
- Параллелизм данных: разделите обучающие данные на несколько частей и запустите одну и ту же модель на каждом вычислительном узле, но с использованием разных копий данных. Этот метод позволяет эффективно использовать вычислительные ресурсы нескольких вычислительных узлов и ускорить процесс обучения.
- Параллелизм модели: разбейте модель на несколько модулей и запустите один из модулей на каждом вычислительном узле. Этот метод может еще больше сократить временную сложность обучения модели и повысить эффективность обучения.
- Конвейерный параллелизм: разделите процесс обучения модели на несколько этапов, каждый этап отвечает за вычислительный узел, а выходные данные предыдущего этапа используются в качестве входных данных следующего этапа. Этот параллельный подход позволяет более эффективно использовать вычислительные ресурсы и увеличить скорость обучения.
- Гибридный параллелизм: сочетает в себе параллелизм данных, параллелизм моделей и конвейерный параллелизм для распределения задач обучения по нескольким вычислительным узлам. Эта гибридная стратегия параллельного обучения позволяет в полной мере использовать различные вычислительные ресурсы и повысить эффективность обучения.
Весь процесс обучения требует использования различных технологий, таких как графический процессор (GPU), сеть удаленного прямого доступа к памяти (RDMA), технология виртуальной частной облачной сети (VPC), технология виртуализации и хранилище. Эти технологии играют важную роль в тренировочном процессе, такие как:
- Графический процессор (GPU): GPU обычно имеет большое количество вычислительных ядер и широкие возможности параллельных вычислений, что может ускорить обучение модели.
- Сеть удаленного прямого доступа к памяти (RDMA). Сеть RDMA обеспечивает удаленный доступ к памяти, обеспечивая эффективную передачу данных и операции с очередями без блокировок. Это особенно важно при обучении крупномасштабных моделей, чтобы избежать узких мест в процессе передачи данных.
- Технология виртуальной частной облачной сети (VPC). Технология VPC может обеспечить виртуальную изолированную сетевую среду для задач обучения, обеспечивая безопасность данных во время процесса обучения и одновременно повышая эффективность обучения.
- Технология виртуализации. Технология виртуализации может абстрагировать и изолировать вычислительные ресурсы, чтобы разные приложения могли работать на одном физическом устройстве. Это особенно важно при обучении крупномасштабных моделей, чтобы избежать проблем с конкуренцией за ресурсы.
- Хранение: технологии хранения могут обеспечить эффективное хранение данных и возможности доступа к ним для процесса обучения, например, распределенные файловые системы, базы данных и т. д.
Подводя итог, можно сказать, что обучение крупномасштабной модели — это сложный процесс, включающий множество технологий. Использование соответствующих методов и приемов обучения может эффективно повысить эффективность обучения и сократить время обучения.
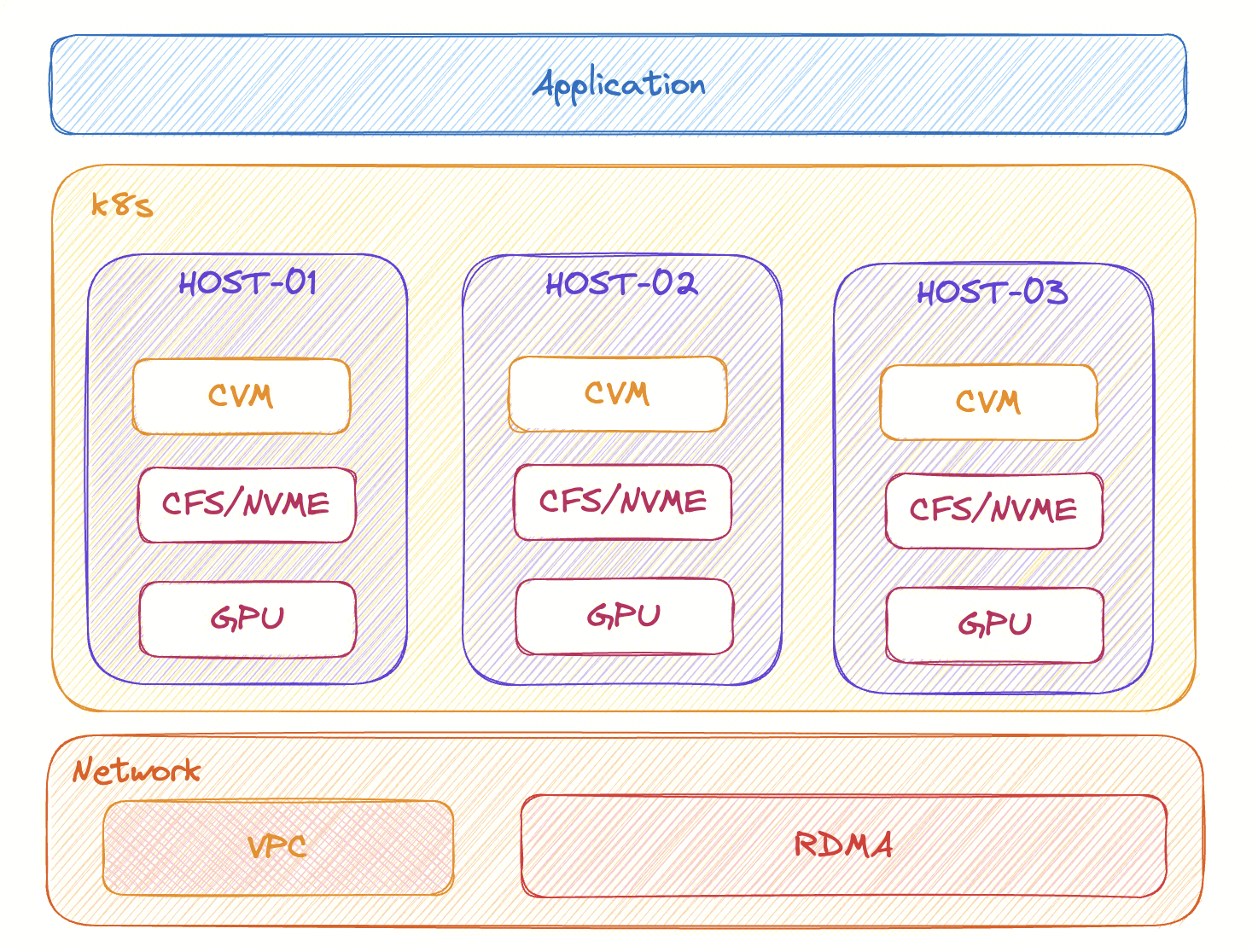
Как показано на рисунке, приложения обычно развертываются на нескольких компьютерах, а развертывание приложений и управление ими осуществляется через сеть VPC. На этапе запуска обучения сеть VPC обычно используется для установления TCP-соединения (например, инициализации NCCL) для обмена базовыми данными. После начала обучения данные обучения обычно сохраняются в CFS, чтобы обеспечить возможность совместного использования несколькими компьютерами. После получения данных графический процессор отвечает за выполнение конкретных вычислительных задач. В процессе обучения синхронизация параметров будет передаваться посредством коллективной связи с использованием сети RDMA. Неисправности могут возникнуть на любом узле на любом этапе. Устранение неполадок и обнаружение точки неисправности требует определенного понимания всего процесса обучения и связанных с ним стеков технологий. Как быстро обнаружить ее, является огромной проблемой.
Общая классификация неисправностей
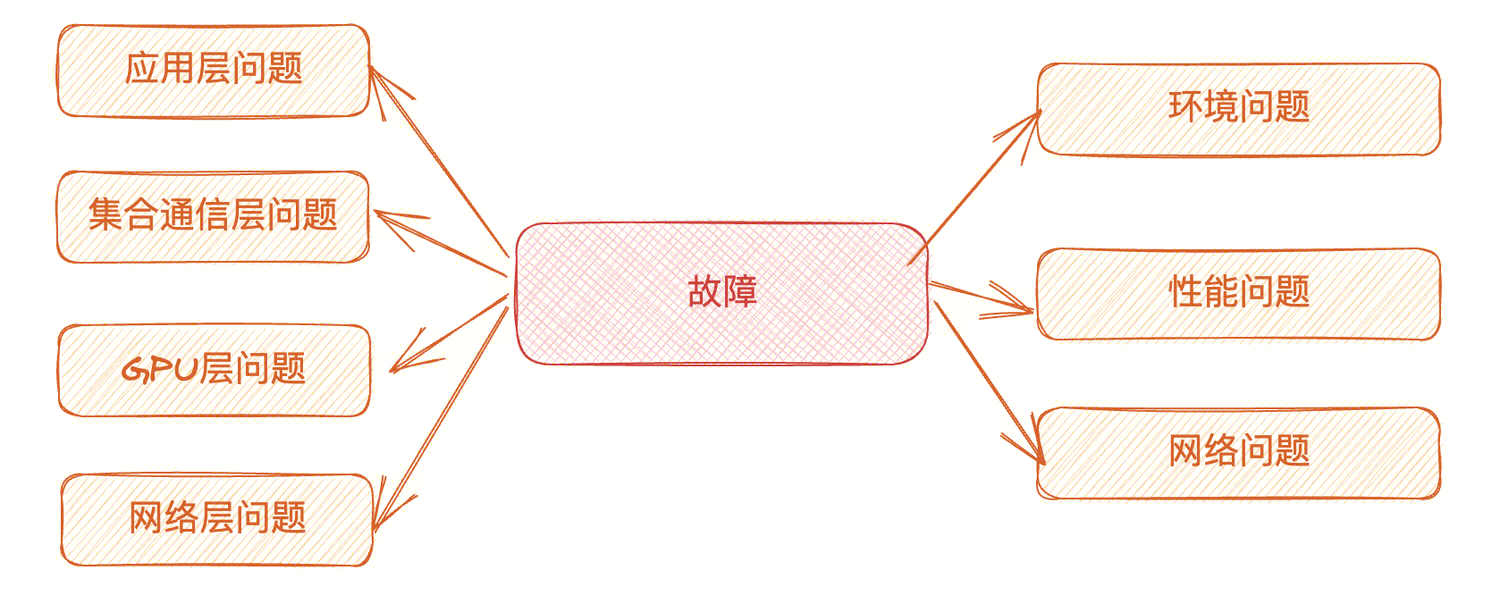
«Первое условие победы над врагом — понять врага». Мы разделяем неисправности на следующие категории в зависимости от их местоположения: ошибки уровня приложений, ошибки уровня коллективной связи, ошибки уровня графического процессора и ошибки сетевого уровня. В зависимости от явления сбоя мы также можем грубо разделить его на проблемы окружающей среды, проблемы с производительностью и проблемы с сетью.
- Проблемы окружающей среды: обычно связаны с несовместимыми конфигурациями, несовместимыми версиями программного обеспечения и зависимостями, а также проблемами с драйверами.
- Проблемы с производительностью. Проблемы с производительностью обычно сложны и могут включать сбой одного компьютера или карты, что приводит к снижению скорости кластера. Это также может быть вызвано неоптимальной топологией связи, низкой эффективностью связи или ограничением частоты из-за перегрева графического процессора.
- Проблемы с сетью. Проблемы с сетью уровня VPC обычно очевидны. Они обычно проявляются в невозможности доступа или установки TCP-соединения, а также в потере или повторной передаче TCP-пакетов. Проблемы сети RDMA необходимо наблюдать и анализировать вместе с индикаторами мониторинга, связанными с RDMA, такими как трафик, PFC, ECN и т. д.
Как анализировать и обрабатывать ошибки
Согласно классификации, приведенной в предыдущей главе, мы разделяем проблемы в зависимости от места неисправности на: включая проблемы уровня приложения, проблемы уровня коллективной связи, проблемы уровня графического процессора и проблемы сетевого уровня.
- Проблемы на уровне приложения: Обычно PyTorch, DeepSpeed и Megatron сообщают об ошибках, которые могут быть вызваны ошибками в некоторых приложениях.
- Проблемы уровня связи коллекции: обычно уровень NCCL создает некоторые журналы исключений, или время связи нестабильно или внезапно увеличивается во время процесса обучения. Это может быть связано с аномалиями коллективной связи или проблемами со связью.
- Проблемы на уровне графического процессора. Некоторые проблемы на уровне графического процессора обычно приводят к сбою приложения, и в системных журналах могут быть очевидные исключения XID и т. д.
- Проблемы сетевого уровня. Некоторые проблемы с сетью VPC могут привести к сбою запуска обучения, а проблемы сетевого уровня RDMA могут привести к прерыванию обучения. Обычно проявляется как тайм-аут TCP прикладного уровня.
При возникновении проблем на всех уровнях мы можем начать с явления, попытаться воспроизвести проблему, использовать определенные инструменты для сбора дополнительной информации, провести подробный анализ и, наконец, определить первопричину и решить проблему. В ходе этого процесса мы будем передавать инструменту опыт анализа и позиционирования, постоянно улучшать инструмент и повышать эффективность общего устранения неполадок.
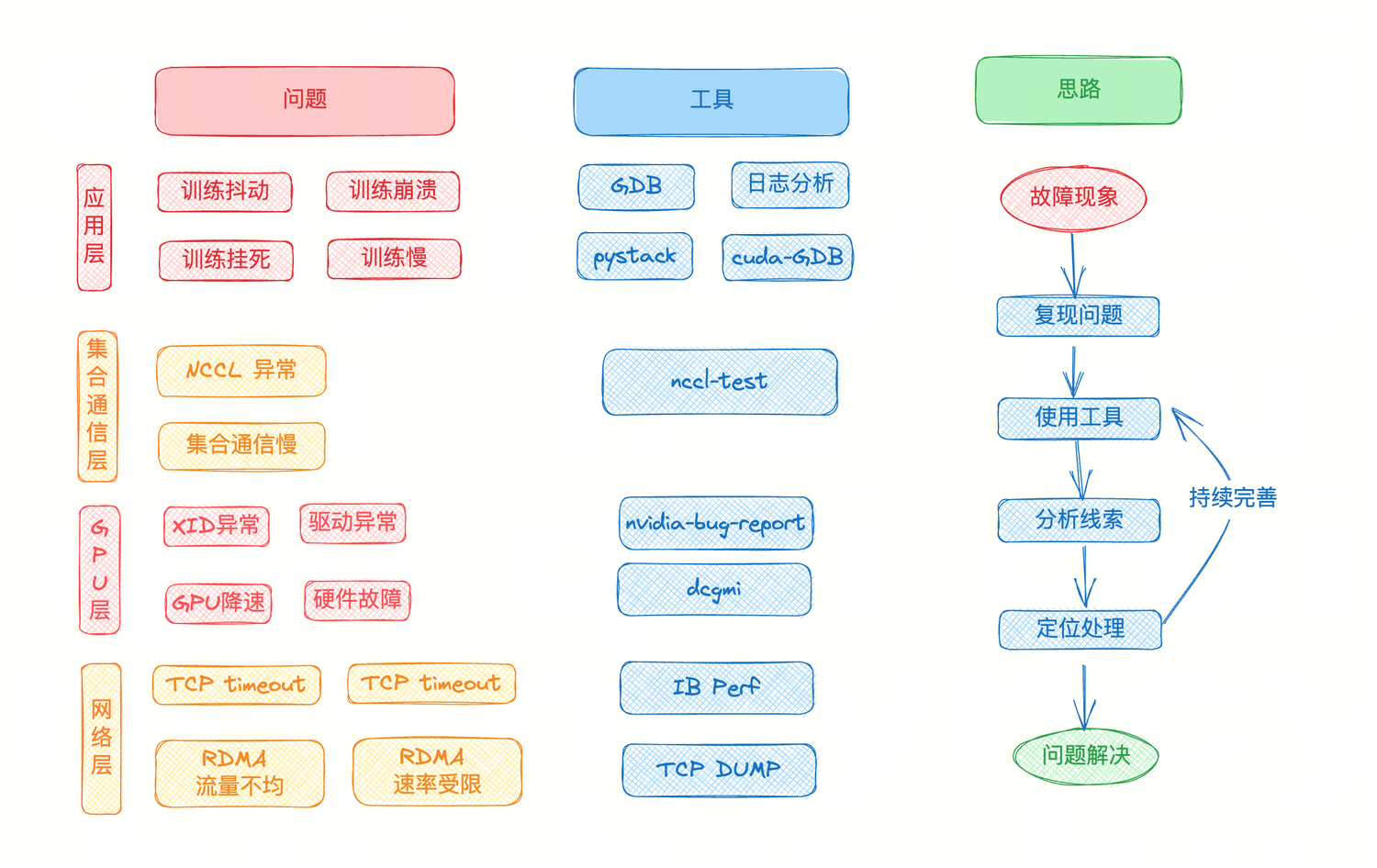
На каждом уровне проблемы в настоящее время существуют определенные инструменты, помогающие проанализировать и справиться с проблемой.
- На уровне приложения вы можете анализировать журналы приложений, использовать GDB или cuda-gdb для отладки приложений и просматривать информацию стека вызовов с помощью pystack.
- На уровне связи с коллекцией вы можете использовать инструмент nccl-test для выполнения различных тестов, таких как allreduce_pref, all2all_perf, чтобы проверить, является ли связь с коллекцией нормальной.
- На уровне графического процессора вы можете использовать команду nvidia-smi -q для просмотра состояния графического процессора, а также использовать dcgmi для диагностики графического процессора и сбора соответствующих индикаторных данных.
- На сетевом уровне мы можем использовать инструмент tcp dump для захвата пакетов для анализа и инструмент IB perf для проверки нормальности rdma.
В случае реальных неисправностей мы можем гибко выбирать и использовать вышеуказанные инструменты для анализа и обнаружения проблемы в соответствии с реальной ситуацией.
Идеи по созданию платформы устранения неполадок
Когда размер кластера невелик, описанные выше идеи определения проблем и обработки могут сыграть определенную роль. Однако по мере увеличения количества параметров модели и увеличения сложности обучения требуемый размер кластера становится все больше и больше. Поэтому нам необходимо постоянно разрабатывать и оптимизировать наш опыт обработки проблем. В то же время мы должны анализировать и обрабатывать ошибки на более высоком уровне. На основе этого мы можем спланировать весь процесс обработки ошибок.
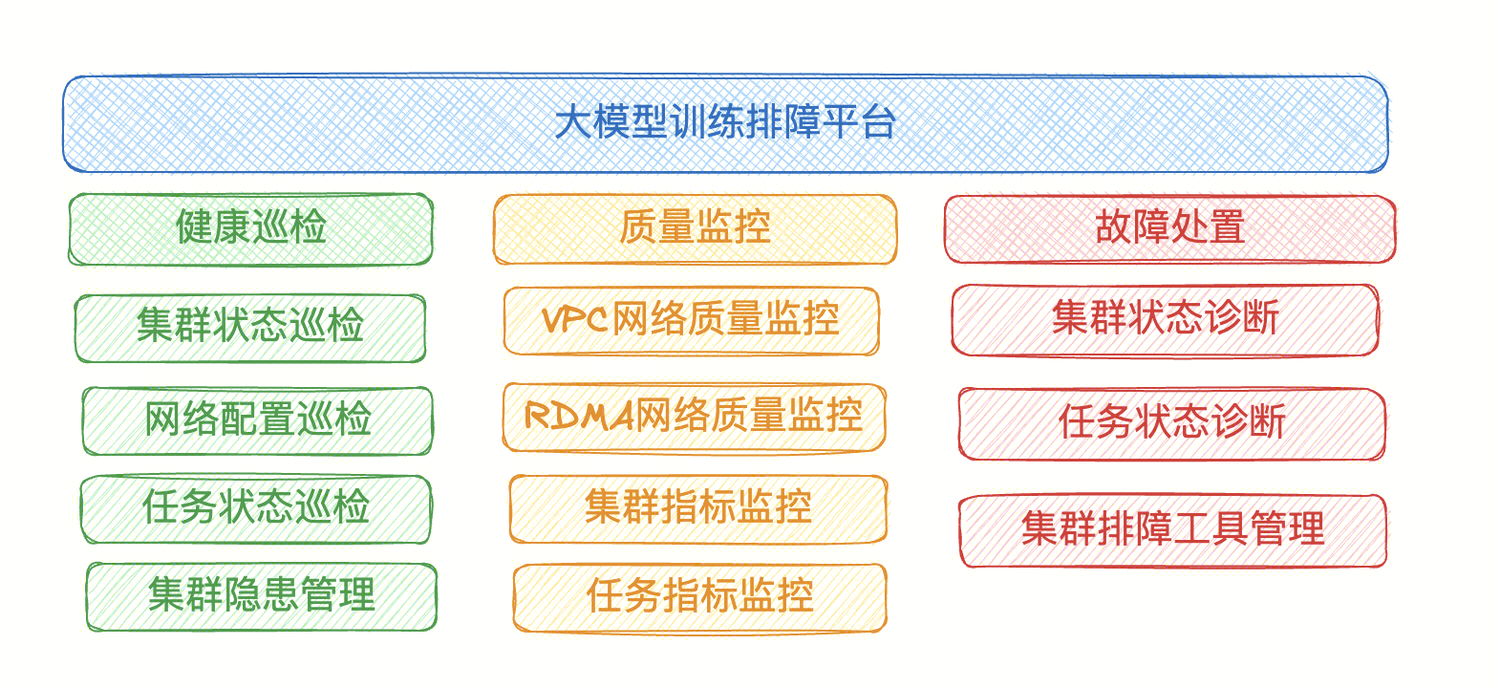
Исходя из вышеизложенных традиционных идей по устранению неполадок, мы можем расширить их. Простая идея состоит в том, чтобы разделить платформу на три модуля в соответствии с этапами предотвращения ошибок → мониторинга ошибок → обработки ошибок:
- Модуль проверки работоспособности: стремится предотвращать потенциальные риски, проводить регулярные проверки кластеров, сетей и задач обучения, а также систематически управлять и контролировать потенциальные проблемы, чтобы предотвратить их перерастание в сбои.
- Модуль мониторинга качества: отслеживает показатели кластера и задач, упреждающе выдает оповещения в нештатных ситуациях и обеспечивает визуальное отображение основных показателей.
- Модуль устранения неполадок: отвечает за диагностику и устранение неисправностей, интеграцию инструментов устранения неполадок и своевременное возобновление обучения выполнению задач.
В крупномасштабных кластерах анализ и обработка отказов требуют больших объемов данных. Например, кластер kilocard, содержащий 156 машин, имеет в общей сложности 1248 рангов. Необходимо проанализировать данные каждого ранга, если обрабатываются данные сетевого уровня, если устройство подключено к 16 портам, ему потребуется обработать 2596. данные порта.
Обычно для сценариев задач по устранению неполадок мы можем просто назначить задачу конкретным узлам, выполнить определенную логику обнаружения или диагностики (последовательная или параллельная может быть организована в зависимости от фактической ситуации), а затем собрать и проанализировать результаты.
В процессе анализа обычно требуются следующие три типа анализа:
- Разница анализировать: Найдите аномальные точки,Например, использование графического процессора определенной карты низкое.,Трафик на определенном порту низкий. Этот анализ отражает сбой одной карты и сбой одного сетевого порта.,Это может привести к замедлению скорости обучения кластера.
- Анализировать согласованность: анализировать согласованность определенных элементов конфигурации.,Например, порядок портов связи на определенной машине непостоянен.,Несовместимый тип ЦП и т. д. находятся в одном кластере,Лучше всего поддерживать единообразие среды и оборудования, используемых для обучения.,Когда модели ЦП несовместимы,Это также может вызвать проблемы со связью на уровне NCCL.
- Точность анализировать: для определенных конкретных тестовых заданий.,Например, исключение XID,Замедление работы графического процессора и т. д.,Необходимо четко сравнить, соответствуют ли обнаруженные значения ожиданиям. Элементы обнаружения, которые не соответствуют ожиданиям, являются аномалиями.,Требуется руководить лечением.
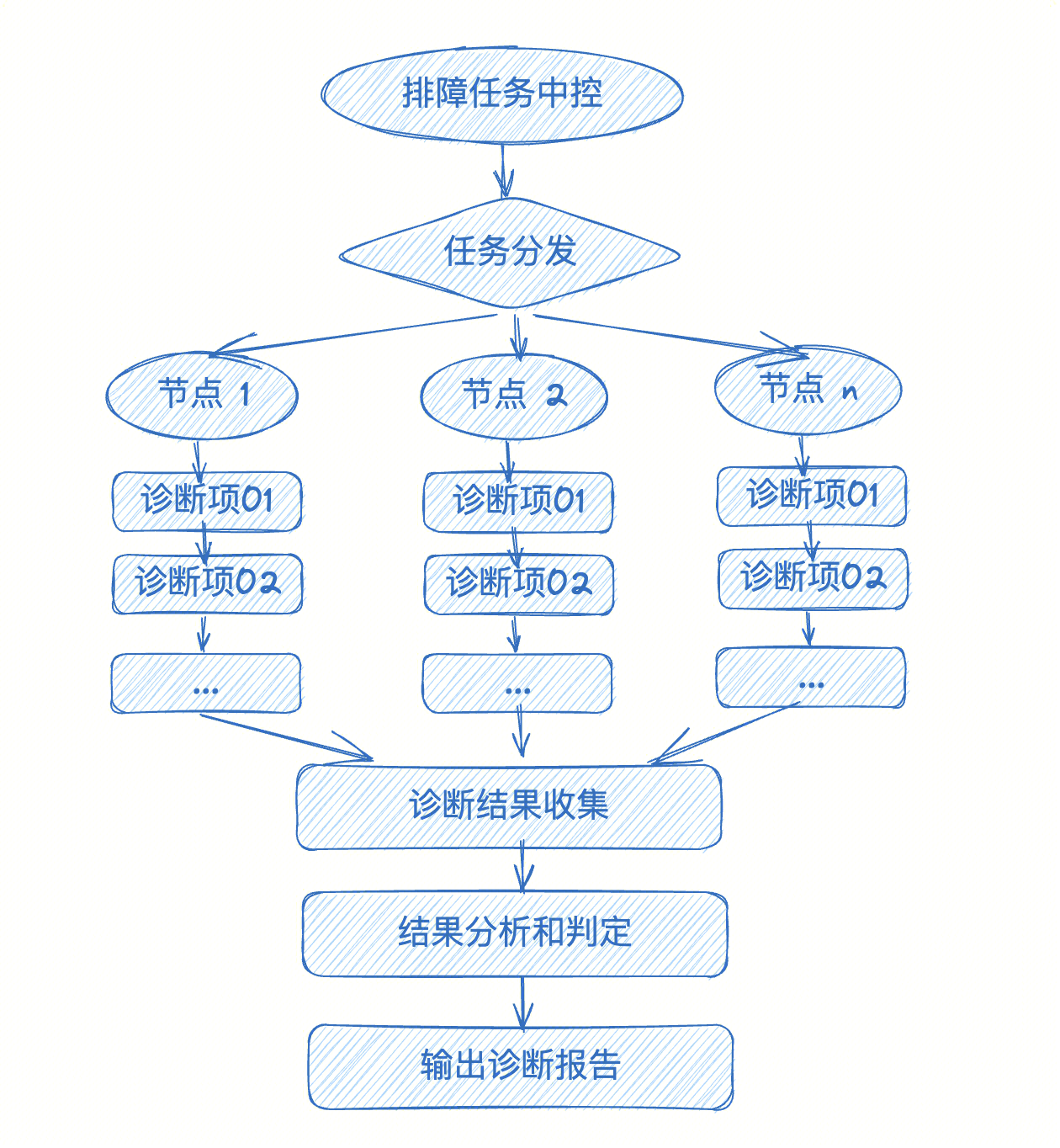
Распределение дел
Явление неисправности: в ходе определенного обучения для обучения определенной задаче было использовано 48 машин. После того, как задача продолжалась в течение месяца, возникла проблема с зависанием на уровне приложения. Энергопотребление всех графических процессоров. было сокращено примерно на 1 миллион, но коэффициент использования графического процессора был низким и составлял 100%. После перезапуска задачи обучение можно возобновить, но через некоторое время зависание снова появится.
Процесс устранения неполадок:
- Машины, участвующие в обучающем кластере, были настроены и проверены по индексу, явных отклонений обнаружено не было. На аппаратном уровне журналов ошибок также нет.
- После анализа показателей сетевого уровня кластера потери пакетов не обнаружено, а на сетевом уровне RMDA не обнаружено пакетов PFC или других аномалий. Используйте NCCL-TEST, чтобы выполнить тест allreduce_perf и не обнаружить никаких отклонений.
- Среда применения была протестирована, и не было никаких различий в среде обучения и конфигурации 48 машин.
- Начните анализировать уровень приложения. Чтобы облегчить отладку, добавьте следующие переменные среды:
# Включите трудоемкую статистику коллективного общения факела
export TORCH_CPP_LOG_LEVEL=INFO
export TORCH_DISTRIBUTED_DEBUG=DETAIL
# Включите мониторинг коллективной связи pytorch. При возникновении исключения или истечении времени ожидания он больше не будет зависать и распечатывать стек вызовов.
export NCCL_ASYNC_ERROR_HANDLING=1 5. После повторения проблемы используйте cuda-gdb всем rank Проведите отладочный анализ и обнаружите, что все процессы зависли. ncclKernel_AllGather_Ring_LL_Sum_int8_t()середина,ОК и NCCL Связанный.
6. Добавьте `экспорт NCCL_ASYNC_ERROR_HANDLING=1 ` После этого журнал уровня приложения показывает, что все потоки застряли. WorkNCCL(SeqNum-5586566, OpType=_ALLGATHER_BASE, В этой операции подтвердите Держитесь уровня коллективного общения.
7. Очевидно, нет. После вопроса NCCL.,Запустить верный код, связанный с NCCL, и руководить анализом,发现类似вопрос:https://github.com/NVIDIA/nccl/pull/898。 анализировать: a. 集合通信середина,Связь между любыми двумя узлами,Каждый раз, когда вы сообщаете собеседнику, какие данные необходимо прочитать,,буду использоватьприезжатьсчетчик ссылок(comm->fifohead),+1 после каждого общения.
b. Максимальное значение Int, int 4 байта от -2147483648 до 2147483647. После того, как int превысит максимальное значение, оно будет отменено и начнется снова с минимального значения. uint64, 8 байт 0~18446744073709551615.
c. когда slots[x].idx > int_max В этом случае он будет расценен как неудачный и связь не может быть завершена.
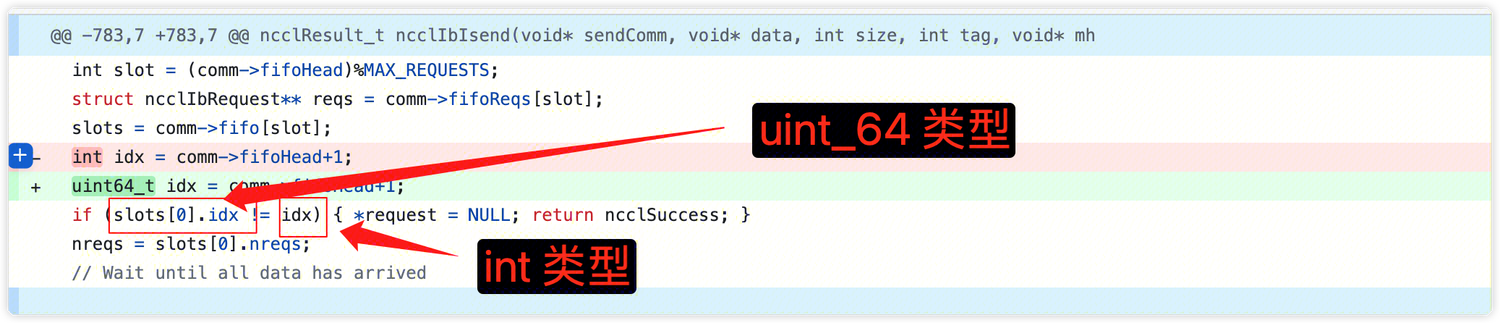
8. Обновите исправленную версию NCCL и проверьте ее, чтобы устранить проблему.
существоватьэтого дела Поиск ошибок и процесса обработки, мы в первую очередь полагаемся на возможности платформы, верно кластерные индикаторы и соответствующие сигналы тревоги руководить Поиск неисправности, чтобы обнаружить наличие существующих аномалий и устранить сбои оборудования и проблемы на стороне сети. В то же время мы используем NCCL-TEST для проверки проблем. с сетью RDMA。существовать В отсутствие подсказок,Начнем анализ руководить прикладным уровнем. первый,Используйте инструменты устранения неполадок кластера,верно Прикладная среда всего кластера руководила обнаружением,Проверить, нет ли каких-либо несоответствий в среде каждого узла. наконец,Наш верный уровень приложенияруководить анализ,Добавьте несколько переменных среды,Добавьте журнал, когда программа зависает и завершает работу.,и использовать инструменты устранения неполадок кластера,всемrank,использоватьcuda-gdbrukoводить анализ стека вызовов,Чтобы обнаружить, есть ли какие-либо несоответствия в существующем процессе и хранилище потоков. Окончательное подтверждение того, что все процессы зависли. Коллективное общение NCCL существует.,Затем объедините слой NCCL и проведите детальную интерпретацию и анализ кода.,Наконец решите проблему.
Идеи лечения тяжелых и сложных заболеваний
При обучении больших моделей коренные причины ошибок сложны. Некоторые ошибки прикладного уровня и коллективной коммуникации пока не могут быть полностью охвачены и обнаружены с помощью индикаторов. Нам нужно успокоиться и провести углубленный анализ, чтобы шаг за шагом обнаружить истину.
При некоторых тяжелых и сложных заболеваниях вы также можете обратиться к следующим основным идеям борьбы с ними:
- Устранение неполадок журналов аппаратных ошибок, системного системного журнала, проблем с сетью RDMA.
- Добавьте журналы уровня приложения, добавьте переменные среды экспорта NCCL_ASYNC_ERROR_HANDLING=1; экспортируйте NCCL_DEBUG=INFO и некоторую информацию журнала. Для получения дополнительной информации о настройке журнала обратитесь к документам конфигурации, предоставляемым каждой платформой обучения.
- использовать cuda-gdb Инструменты анализируют стеки вызовов cuda-gdb для отладки приложение cuda, да GDBрасширение。Официальное введение:https://docs.nvidia.com/cuda/cuda-gdb/index.html, cuda-gdb Обычно существующий драйвер устанавливается во время установки. Следует отметить, что для существования контейнера необходимо использовать cuda-gdb Когда требуется картографирование libcudadebugger.so файл в контейнер, иначе cuda-gdb может работать неправильно. Метод отображения: k8s Может быть изменен yaml файл, увеличить монтирование параметры. докер может добавить -v параметр. Путь и версия конкретных файлов зависят от фактических. Нижеследующее предназначено только для справки.
# Пожалуйста, обратите внимание на версию файла и его конкретное местоположение ниже, пожалуйста, обратитесь к реальной ситуации. Можетиспользовать ldconfig -p | grep libcudadebugger Определить фактическое местоположение
VolumeMounts:
- mountPath: /lib64/libcudadebugger.so.535.129.03
name: libcudadebugger
volumes:
- name: "libcudadebugger"
hostPath:
- path: /lib64/libcudadebugger.so.535.129.034. Проанализируйте и систематизируйте все данные, чтобы найти подозрительные точки.
5. Провести углубленный анализ кодов, связанных с подозрительными моментами.
Подвести итог
В этой статье кратко представлена классификация проблем, возникающих при обучении крупномасштабных моделей, основные методы устранения неполадок и основные идеи создания платформы инструментов устранения неполадок. С развитием крупномасштабных моделей и увеличением количества параметров необходимые вычислительные ресурсы также будут постепенно увеличиваться. Расширение масштаба кластера и проблемы с стабильностью обучения и эффективностью устранения неполадок кластера также станут более серьезными. Это всего лишь отправная точка, и у меня есть некоторые приблизительные мысли, я надеюсь, что это поможет всем.
ЯсуществоватьучаствоватьНа третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 года будет проводиться конкурс сочинений. Соберите команду, чтобы выиграть приз!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
