Комплексный источник данных случая (2) в реальном времени на основе Flume+Kafka+Hbase+Flink+FineBI
04: Источник данных
Цель:Понимание формата источников данных и создание данных моделирования
путь
- step1:Формат данных
- step2:Генерация данных
осуществлять
Формат данных
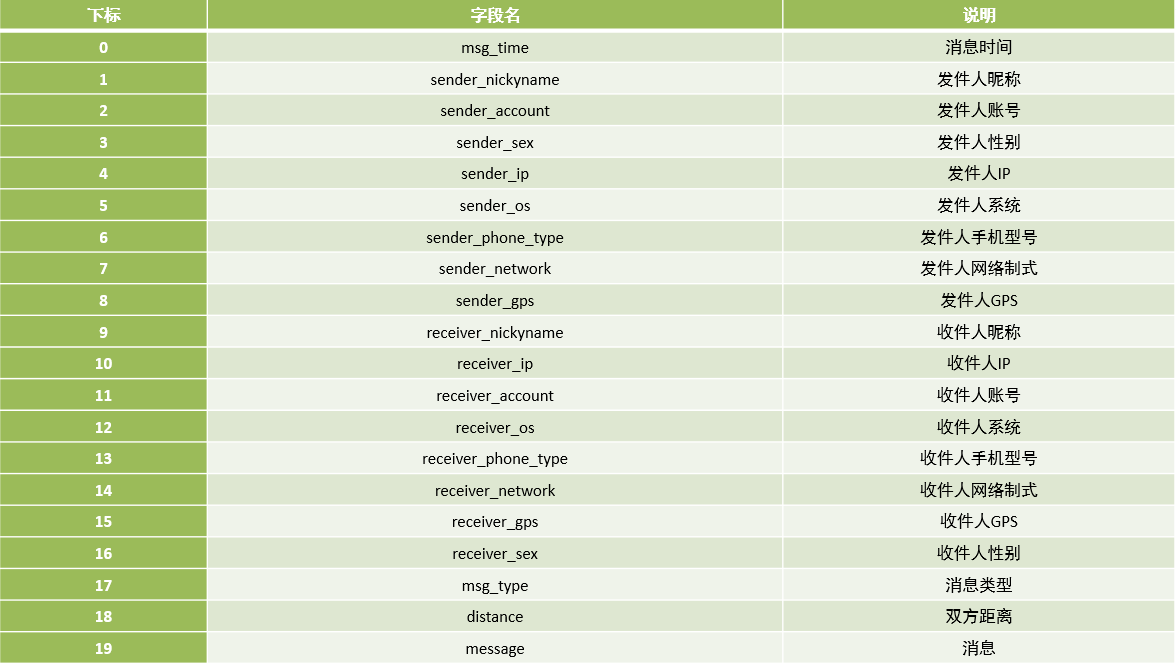
время сообщения | Ник отправителя | Счет отправителя | Пол отправителя | IP-адрес отправителя | система отправителя | Модель мобильного телефона отправителя | Формат сети отправителя | Отправитель GPS | Ник получателя | IP-адрес получателя | Счет получателя | Система получателя | Модель мобильного телефона получателя | Формат сети получателя | GPS получателя | Пол получателя | Тип сообщения | Расстояние между двумя сторонами | информация |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
msg_time | sender_nickyname | sender_account | sender_sex | sender_ip | sender_os | sender_phone_type | sender_network | sender_gps | receiver_nickyname | receiver_ip | receiver_account | receiver_os | receiver_phone_type | receiver_network | receiver_gps | receiver_sex | msg_type | distance | message |
2020/05/08 15:11:33 | Гу Бойи | 14747877194 | мужской | 48.147.134.255 | Android 8.0 | Сяоми Редми К30 | 4G | 94.704577,36.247553 | Лейю | 97.61.25.52 | 17832829395 | IOS 10.0 | Apple iPhone 10 | 4G | 84.034145,41.423804 | женский | TEXT | 77.82KM | Блуждание по краям света,Пастух переплывает реку. Поклоняюсь перед троном Будды,Я просто хочу провести сто лет вместе. |
Генерация данных
Создать исходный каталог файлов
mkdir /export/data/momo_initЗагрузите программу данных моделирования
cd /export/data/momo_init
rz
Создать каталог данных моделирования
mkdir /export/data/momo_dataЗапустите программу для генерации данных
грамматика
java -jar /export/data/momo_init/MoMo_DataGen.jar оригинальныйданныепуть моделированиеданныепуть Случайно генерировать интервал данных, мс времяТест: генерировать фрагмент данных каждые 500 мс.
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
500Результат: создается файл данных моделирования MOMO_DATA.dat, а разделитель полей в каждой части данных равен \001.
краткое содержание
- Понимание формата источников данных и создание данных моделирования
05: Техническая архитектура и выбор технологий
- Цель:Освоить техническую архитектуру и выбор технологий для случаев реального времени
- путь
- step1:нуждатьсяанализировать
- step2:Выбор технологии
- step3:Техническая архитектура
- осуществлять
- нуждатьсяанализировать
- Автономные вычисления с хранилищем
- Предоставить оффлайн Т + 1статистикаанализировать
- Обеспечить мгновенный запрос Оффлайнданных
- вычисления в режиме реального времени
- Предоставить в реальном временистатистикаанализировать
- Автономные вычисления с хранилищем
- Выбор технологии
- Оффлайн
- данныеколлекция:Flume
- Автономное хранилище: Hbase
- Оффлайнанализировать:Hive:Сложные расчеты
- Мгновенный запрос: Phoenix: эффективные запросы
- в реальном времени
- данныеколлекция:Flume
- в реальном временихранилище:Kafka
- в реальном временивычислить:Flink
- в реальном время Приложение: MySQL + FineBI или Redis + JavaВеб Визуализация
- Оффлайн
- Техническая архитектура
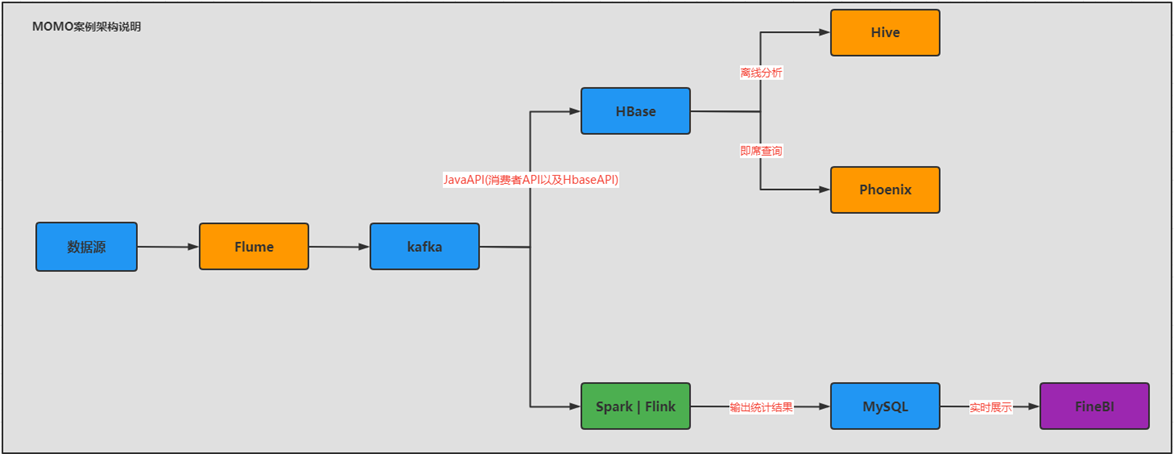
- Почему бы не передать данные Flume напрямую в Hbase, а равномерно передать их в Kafka, а затем передать из Kafka в Hbase?
- Избегайте высокой нагрузки на компьютер, вызванной высокой степенью одновременной записи, обеспечьте развязку архитектуры и добейтесь асинхронной эффективности.
- Обеспечьте согласованность данных
- нуждатьсяанализировать
- краткое содержание
- Освоить техническую архитектуру и выбор технологий для случаев реального времени
06: Проверка и установка лотка
Цель:Обзор базового использования и реализации установки Flume. лотка тест
путь
- Шаг 1: Проверка лотка
- step2:Установка лотка
- step3:тест Флюма
осуществлять
Обзор флюма
- Функция: в реальном время выполнять мониторинг и сбор потока данных в файле или сетевом порту
- Сцена: Сбор файлов в первое время
- развивать
- Шаг 1: Сначала создайте файл конфигурации: свойства [K=V]
- шаг 2: Запустите этот файл
- композиция
- Агент: Агент — это программа Flume.
- Источник: отвечает за мониторинг источника данных.,Превратите динамические данные источника данных в данные каждого события.,Поместите Eventданные потоки в Channel
- Канал: отвечает за временное хранение информации, отправленной источником для приемника для получения информации.
- Приемник: отвечает за получение данных из канала и запись их в Цель.
- Событие: представляет объект данных.
- глава: Коллекция карт [КВ]
- body:byte[]
Установка лотка
Загрузить установочный пакет
cd /export/software/
rz
Разархивируйте и установите
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /export/server/
cd /export/server
mv apache-flume-1.9.0-bin flume-1.9.0-binИзменить конфигурацию
#Интегрируйте HDFS и скопируйте файлы конфигурации HDFS
cd /export/server/flume-1.9.0-bin
cp /export/server/hadoop/etc/hadoop/core-site.xml ./conf/
#Изменить переменные среды Flume
cd /export/server/flume-1.9.0-bin/conf/
mv flume-env.sh.template flume-env.sh
vim flume-env.sh #Изменить строку 22
export JAVA_HOME=/export/server/jdk1.8.0_65
#Изменить строку 34
export HADOOP_HOME=/export/server/hadoop-3.3.0Удалите собственный пакет гуавы Flume и замените его пакетом Hadoop.
cd /export/server/flume-1.9.0-bin
rm -rf lib/guava-11.0.2.jar
cp /export/server/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar lib/Создать каталог
cd /export/server/flume-1.9.0-bin
#Каталог хранения файлов конфигурации программы
mkdir usercase
#Taildir Каталог хранения данных в юанях
mkdir positionтест Флюма
Требования: собирать данные чата и писать в HDFS.
анализировать
- Источник: Taildir: динамический мониторинг нескольких файлов. реальном времениданныеколлекция
- Канал: mem: кэшировать данные в памяти.
- Sink:hdfs
развивать
vim /export/server/flume-1.9.0-bin/usercase/momo_mem_hdfs.properties# define a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define s1
a1.sources.s1.type = TAILDIR
#Указываем файл записи метаданных
a1.sources.s1.positionFile = /export/server/flume-1.9.0-bin/position/taildir_momo_hdfs.json
#Преобразуйте все источники данных, которые необходимо отслеживать, в группу
a1.sources.s1.filegroups = f1
#Укажите, кто такой f1: контролировать все файлы в каталоге
a1.sources.s1.filegroups.f1 = /export/data/momo_data/.*
#Укажите, что заголовок данных, собранных f1, содержит пару KV
a1.sources.s1.headers.f1.type = momo
a1.sources.s1.fileHeader = true
#define c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#define k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/momo/test/daystr=%Y-%m-%d
a1.sinks.k1.hdfs.fileType = DataStream
#Укажите создание файлов по времени, обычно закрытых
a1.sinks.k1.hdfs.rollInterval = 0
#Укажите размер файла для создания файла, обычно 120 ~ Количество байтов, соответствующее 125M
a1.sinks.k1.hdfs.rollSize = 102400
#Указываем количество событий для создания файла, обычно закрытого
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = momo
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#bound
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1Запустить HDFS
start-dfs.shЗапустить Флюм
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_hdfs.properties -Dflume.root.logger=INFO,consoleЗапуск смоделированных данных
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
100Посмотреть результаты
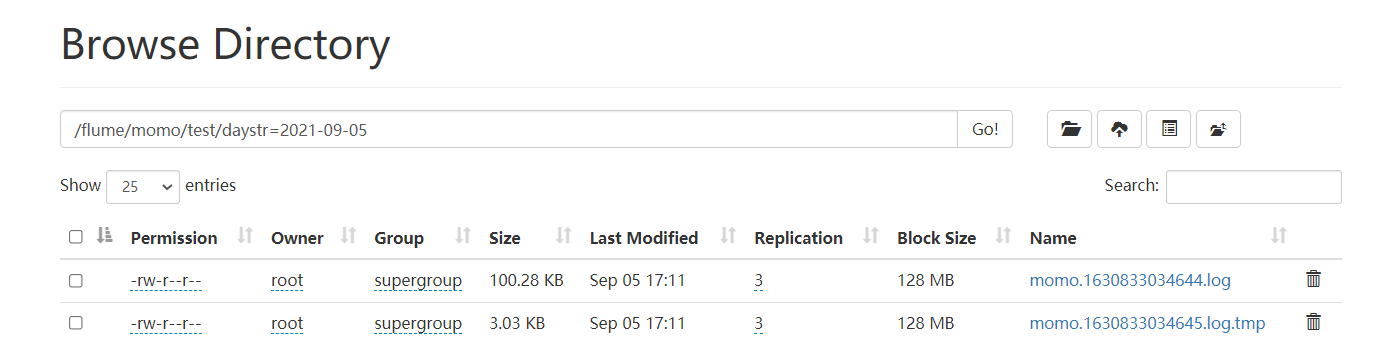
краткое содержание
- Обзор базового использования и реализации установки Flume. лотка тест
07: Разработка программы сбора Flume
Цель:Пример реализации программы сбора Flume
путь
- step1:нуждатьсяанализировать
- step2:программаразвивать
- step3:Тестовая реализация
осуществлять
нуждатьсяанализировать
Требования: собирать данные чата и записывать их в Kafka в режиме реального времени.
Source:taildir
Channel:mem
Sink:Kafka sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappyпрограммаразвивать
vim /export/server/flume-1.9.0-bin/usercase/momo_mem_kafka.properties# define a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define s1
a1.sources.s1.type = TAILDIR
#Указываем файл записи метаданных
a1.sources.s1.positionFile = /export/server/flume-1.9.0-bin/position/taildir_momo_kafka.json
#Преобразуйте все источники данных, которые необходимо отслеживать, в группу
a1.sources.s1.filegroups = f1
#Укажите, кто такой f1: контролировать все файлы в каталоге
a1.sources.s1.filegroups.f1 = /export/data/momo_data/.*
#Укажите, что заголовок данных, собранных f1, содержит пару KV
a1.sources.s1.headers.f1.type = momo
a1.sources.s1.fileHeader = true
#define c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#define k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = MOMO_MSG
a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 100
#bound
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1Тестовая реализация
Запустить Кафку
start-zk-all.sh
start-kafka.sh Создать тему
kafka-topics.sh --create --topic MOMO_MSG --partitions 3 --replication-factor 2 --bootstrap-server node1:9092,node2:9092,node3:9092перечислять
kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092Начать потребитель
kafka-console-consumer.sh --topic MOMO_MSG --bootstrap-server node1:9092,node2:9092,node3:9092Запустите программу Flume
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_kafka.properties -Dflume.root.logger=INFO,consoleЗапустить данные моделирования
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
50Наблюдения
краткое содержание
- Пример реализации программы сбора Flume



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
