Комплексный анализ записи данных Elasticsearch, процесса их извлечения и основных принципов.
✍🏻Предисловие✍🏻
В современную эпоху, основанную на данных, возможность быстро и точно хранить и извлекать информацию является ключом к успеху в бизнесе. Elasticsearch, как распределенная система поиска и анализа RESTful, стала предпочтительным выбором многих предприятий и разработчиков благодаря своим мощным функциям индексации, поиска и агрегирования. Процесс чтения и записи, лежащий в его основе, сочетает в себе эффективные структуры данных и передовые принципы распределенной системы, гарантируя надежное хранение и быстрое извлечение данных.
1️⃣✍🏻 введение в архитектуру
Во-первых, с архитектурной точки зрения Elasticsearch — это распределенная система поиска и анализа, способная хранить, искать и анализировать большие объемы данных. Для достижения этих функций Elasticsearch использует механизмы сегментирования и репликации, чтобы данные можно было распределять по нескольким узлам, а также обеспечить отказоустойчивость и масштабируемость. Кратко представим архитектуру Elasticsearch:
1. Распределенная архитектура
- Узлы и кластеры:Elasticsearchпо нескольким узлам(Node)композиция,Эти узлы могут образовывать кластер. Каждый узел может обрабатывать запросы на чтение и запись.,Данные распределяются и реплицируются между узлами кластера.,для достижения высокой доступности и масштабируемости.
- Шардинг и реплики:Для поддержки масштабныхданные,Elasticsearch делит индекс на несколько сегментов (Shard),Каждый осколок может храниться и обрабатываться независимо. также,Каждый шард может иметь несколько реплик (Реплика).,Используется для обеспечения избыточности данных, восстановления после сбоев и балансировки нагрузки чтения.
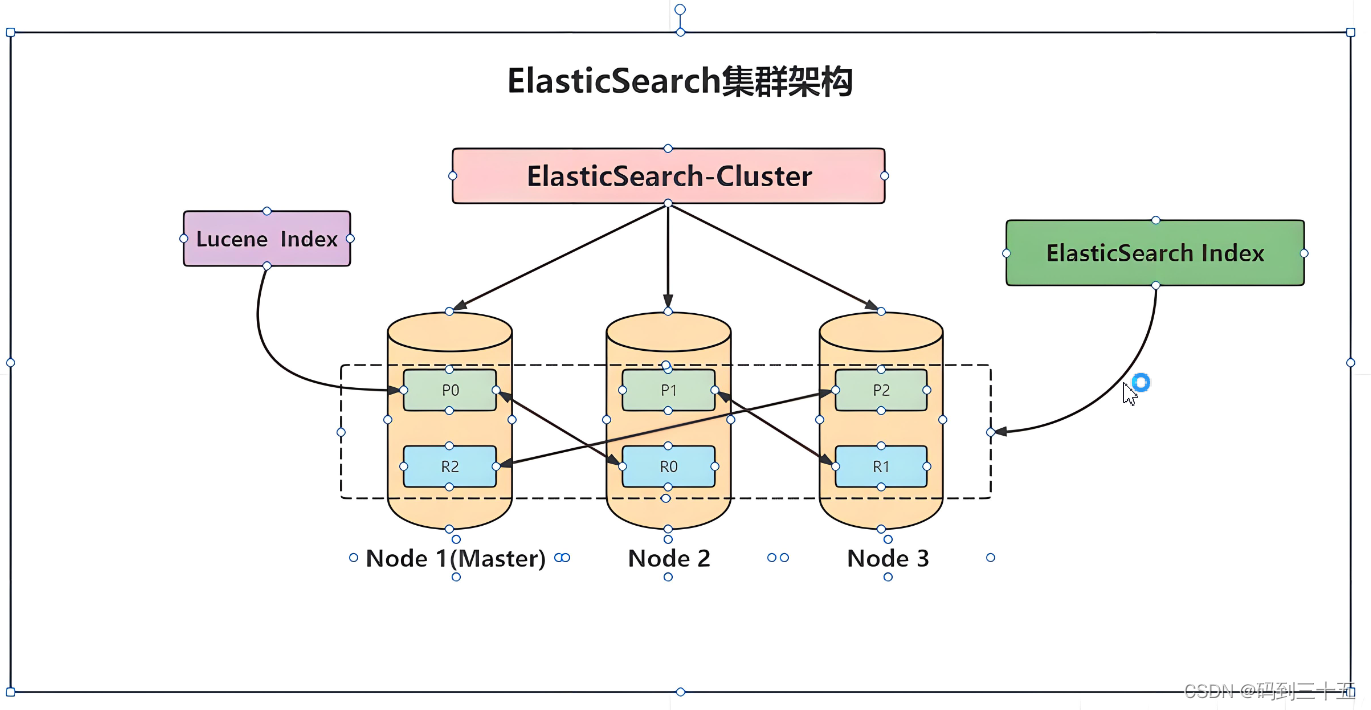
2. Индексирование и поиск
- инвертированный индекс:ElasticsearchиспользоватьLuceneкак лежащее в основепоиск Библиотека。LuceneСтроитьинвертированный индекс(Inverted Index)ускоритьсяпоискпроцесс。инвертированный Индекс сопоставляет слова в документе со списком документов, содержащих эти слова, обеспечивая быстрый поиск и извлечение.
- Выполнение запроса:Когда клиент отправляетпоискпо запросу,Запросы сначала поступают на координирующий узел. Координирующий узел анализирует операторы запроса,Определите, к каким шардам необходимо получить доступ,И перенаправить запрос на соответствующий узел данных. узел данных выполняет запрос локально,и возвращает результаты на координирующий узел. Координирующий узел агрегирует результаты от различных узлов данных.,И выполнять сортировку, пейджинг и т.д.,Наконец, результаты возвращаются клиенту.
3. Запись и сохранение данных
- Процесс записи:когда документ написанElasticsearchчас,Сначала они помещаются в буфер в памяти.,И одновременно записываются в журнал транзакций (Translog), чтобы обеспечить долговечность данных. С течением времени или достижением определенных условий,,Данные в буфере будут обновлены (обновлены) в индекс Lucene.,Сформируйте новый сегмент (Segment). Эти сегменты неизменяемы,Однажды написанное, оно не может быть изменено. финальный,Сохранение изменений в памяти и транслог на диск посредством операций очистки.
- объединение сегментов:Чтобы оптимизировать хранение ипоискпроизводительность,Luceneбудет проводиться регулярнообъединение сегментов(Segment Операция слияния. В процессе слияния возникло множество мелких объединений. сегментов на более крупные сегменты и удаляйте повторяющиеся и удаленные документы, чтобы освободить место для хранения.
4. Кэширование и оптимизация производительности
- Кэш запросов:ElasticsearchНекоторые результаты запросов кэшируются, чтобы ускорить ответ на повторяющиеся запросы.。также,кроме Сегментированный кеш Такие механизмы, как запросы, используются для сокращения ненужных вычислений и операций ввода-вывода.
- Стратегия оптимизации:чтобы улучшитьпроизводительность,Elasticsearch также предлагает различные стратегии оптимизации.,Например, использование соответствующих анализаторов (Анализатор) и операторов запросов, разумная настройка параметров индекса, использование операций агрегации и фильтрации и т. д. Эти оптимизации могут снизить сложность запросов и вычислительные затраты.,Улучшите скорость запросов и время ответа.
Таким образом, архитектура Elasticsearch сочетает в себе технологию распределенной обработки, индексирования и поиска, механизмы записи и сохранения данных, стратегии кэширования и оптимизации производительности для достижения эффективных и надежных функций хранения и поиска данных.
2️⃣✍🏻es процесс и принцип записи данных
При записи данных Elasticsearch следует следующим принципам и шагам:
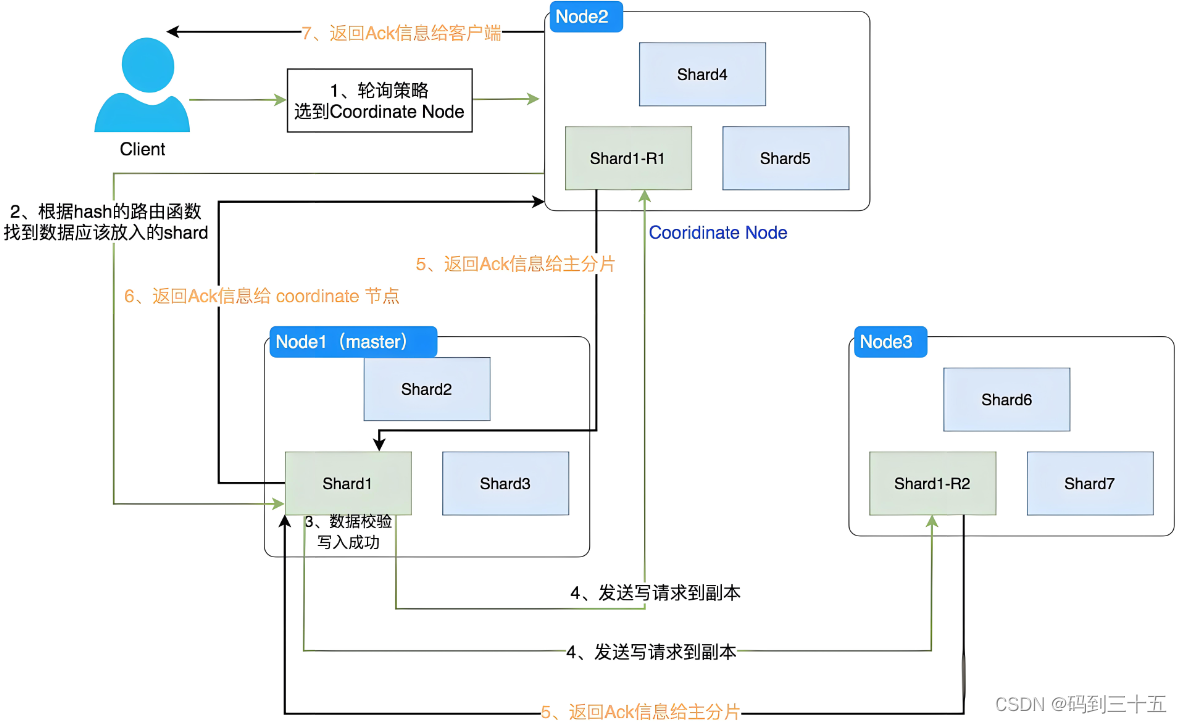
1. Узел запроса и координации клиента
- Клиент отправляет запрос на запись в кластер Elasticsearch, и этот запрос можно отправить на любой узел кластера.
- Узел, получивший запрос, будет выступать в роли координирующего узла. Координационный узел отвечает за обработку запросов клиентов.,и направляет запрос на правильный узел данных.
2. Маршрутизация и первичная обработка шардов
- Координирующий узел определит, в какой основной сегмент должен быть записан документ, на основе настроек _id и индекса документа (например, количества сегментов). Это достигается с помощью хэш-функции и операции по модулю.,Убедитесь, что документы с одинаковым _id всегда направляются в один и тот же основной сегмент.
- После определения целевого первичного сегмента координационный узел перенаправляет запрос на узел данных, где расположен основной сегмент.
- После того, как основной шард на узле данных получит запрос,Документ сначала будет записан в структуру индекса Lucene в памяти. Этот процесс включает в себя преобразование документа в форму инвертированного индекса.,для последующего анализа и анализа.
3. Синхронизация данных и сегментирование реплик.
- Как только документ будет записан в основной шард,Основной шард начнет синхронизировать данные с соответствующим шардом-репликой. Это необходимо для обеспечения избыточности и доступности данных.
- Реплика шарда — это полная копия основного шарда.,Они могут обрабатывать запросы поиска и предоставлять возможности восстановления данных. Когда основной осколок недоступен,Реплики осколков могут быть повышены до новых первичных осколков.
- синхронизация данных выполняется асинхронно,Это означает, что запрос на запись может быть возвращен клиенту после обработки основного сегмента.,Нет необходимости ждать, пока все шарды реплики будут синхронизированы.
4. Напишите подтверждение и ответ.
- Когда основной шард и достаточное количество шардов-реплик (либо все, либо большинство, в зависимости от конфигурации) успешно записали документ, координирующий узел получает подтверждение этих шардов.
- После получения достаточных подтверждений координирующий узел отправляет клиенту ответ об успешном завершении, указывающий, что документ был успешно записан.
5. Основной механизм письма
В Elasticsearch базовый механизм записи является ключевой частью обеспечения надежности, долговечности данных и возможности эффективного поиска:
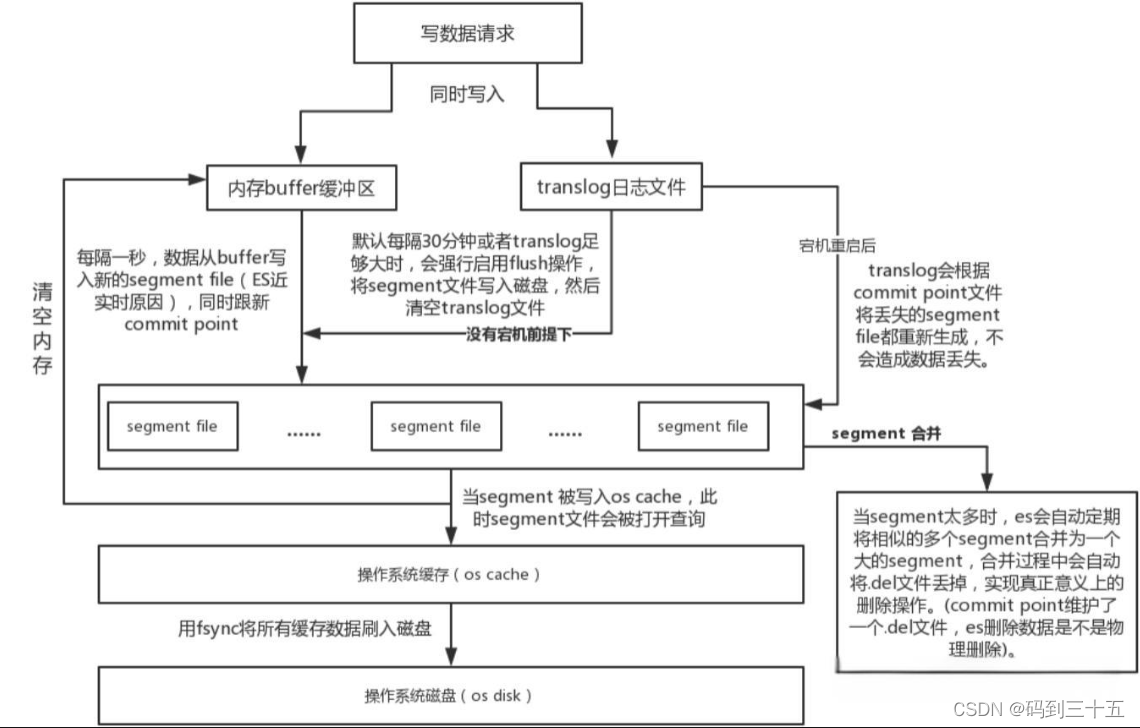
5.1. Буфер и транслог.
- Когда документы записываются в Elasticsearch, они сначала помещаются в буфер в памяти. Этот буфер является временным и используется для быстрого получения и обработки запросов на запись.
- в то же время,Для обеспечения долговечности и надежности данных,Каждая операция записи также записывается в журнал транзакций (Translog). Translog — это файл журнала, записанный в виде добавления.,Он записывает все изменения индекса. Этот механизм аналогичен журналу упреждающей записи (WAL) или журналу повторного выполнения (журналу повторного выполнения) в библиотеке данных.,Используется для восстановления данных после сбоя системы.
5.2. Операция обновления.
- через некоторое время,данные в буфере будут накапливаться до определенной суммы,В настоящее время эти данные необходимо обновить в индексе Lucene. Операция обновления создает новый сегмент Lucene (сегмент).,И запишите данные из буфера в этот сегмент.
- Сегменты Lucene неизменяемы.,После написания его нельзя изменить.,Это гарантирует согласованность данных и эффективность поиска. В индекс будут добавлены новые сегменты,Сделайте вновь записанные данные доступными для поиска.
- Операции обновления являются циклическими.,Частоту обновлений можно контролировать посредством конфигурации. Частые обновления улучшат производительность данных в реальном времени.,Но это также увеличит нагрузку на ввод-вывод и загрузку ЦП, а меньшее количество обновлений приведет к сокращению операций ввода-вывода;,Но это может снизить производительность данных в реальном времени.
5.3. Операция промывки.
- Отличие от обновления,Операция очистки сохранит изменения в памяти и транслог на диск. Это означает, что данные фактически записываются в физическое хранилище.,Вместо того, чтобы просто сохраняться в кеше файловой системы операционной системы.
- Операция промывки вызовет функцию fsync операционной системы, чтобы гарантировать запись данных на диск.,Соответствующие кэши и файлы (например, Translog) будут очищены. Это освобождает место в памяти.,И подготовиться к последующим операциям записи.
- Частота операции промывки обычно намного ниже, чем операция обновления.,Потому что это связано с операциями дискового ввода-вывода.,Относительно медленно. но,В Elasticsearch,Операция промывки управляется автоматически,Он будет динамически корректироваться в зависимости от таких факторов, как размер, скорость записи и возможности дискового ввода-вывода.
Благодаря этому базовому механизму записи Elasticsearch может предоставлять эффективные функции поиска и анализа, обеспечивая при этом надежность данных. Буферы, журналы транзакций, операции обновления и очистки работают вместе, чтобы гарантировать, что данные записываются в индекс правильно и быстро и могут быть запрошены пользователями.
Основываясь на вышеуказанных принципах и шагах, Elasticsearch может обеспечить эффективные, надежные и масштабируемые функции записи данных.
3️⃣✍🏻процесс чтения данных
Ниже объясняется процесс чтения данных Elasticsearch, включая ключевые этапы и задействованные компоненты.
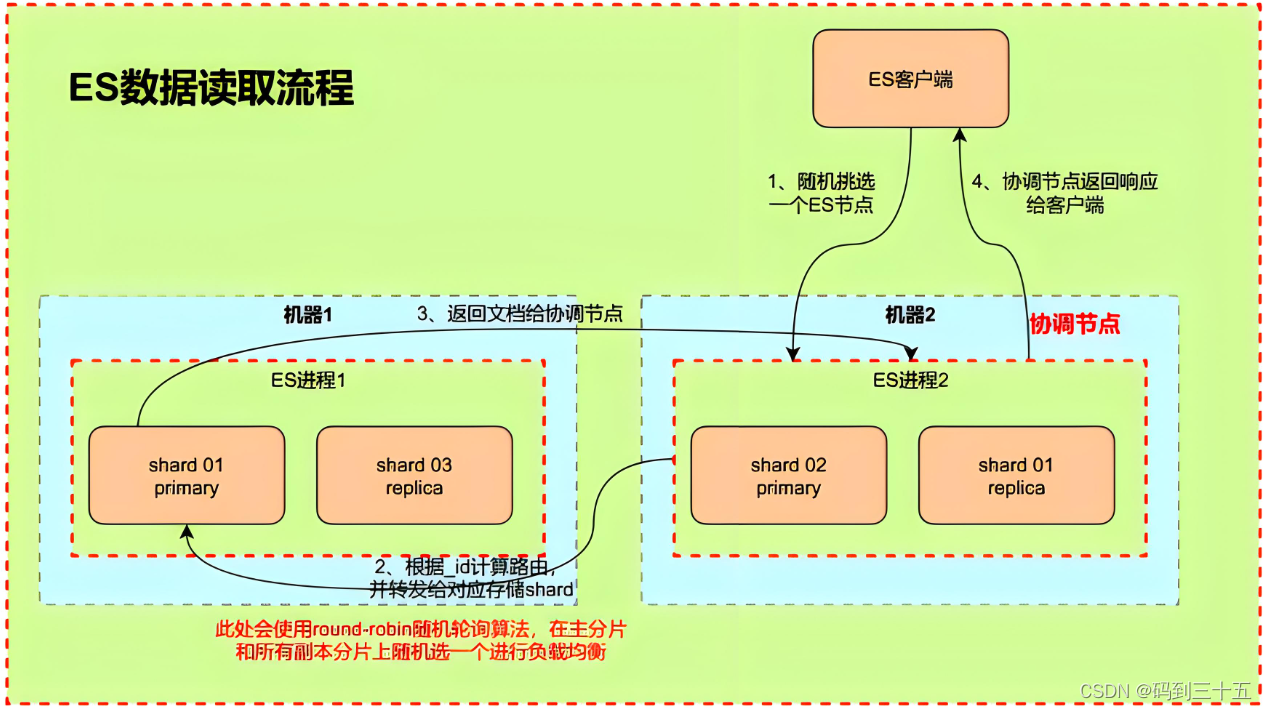
1. Клиент отправляет запрос
- Когда пользователь хочет получить данные из Elasticsearch,Они отправят запрос на поиск через клиентский API Elasticsearch. Этот запрос содержит подробную информацию о запросе,Если ты хочешьпоискизиндекс、Тип запроса (например, запрос на совпадение、запрос диапазона и т. д.)、Условия фильтрации и т. д.
2. Запрос доходит до координационного узла
- Запрос сначала достигает узла в кластере Elasticsearch, который называется координирующим узлом. Узел). Координационный узел отвечает за получение клиентских запросов, обработку логики маршрутизации запросов и связь с узлом данных (Data). Node) для связи и получения актуальных данных.
3. Разберите запрос и определите целевой шард.
- После получения координирующим узлом запроса,Проанализируем оператор запроса,И определите, какие сегменты необходимо запросить, на основе информации о сопоставлении и настройках. Каждый индекс в Elasticsearch разделен на несколько сегментов.,Эти сегменты можно распределить по нескольким узлам кластера для улучшения масштабируемости и производительности.
4. Перенаправить запрос на узел данных.
- Координационный узел пересылает запрос запроса узлу данных, содержащему целевой сегмент, на основе информации о местоположении сегмента. Каждый узел данных хранит часть данных индекса и отвечает за обработку запросов, связанных с этими данными.
5. Выполните запрос на узле данных.
- После того, как узел данных получит запрос запроса,Библиотека Lucene будет использоваться для выполнения фактических операций поиска. Lucene — это высокопроизводительная полнофункциональная библиотека механизма текстового поиска.,Он обеспечивает мощные функции индексирования и поиска. Узел данных будет извлекать соответствующие документы в индексе Lucene на основе условий запроса.,и сгенерировать набор результатов.
6. Объедините и отсортируйте результаты.
- Узел данных возвращает результаты запроса координирующему узлу. Если запрос включает в себя несколько сегментов,Координирующему узлу необходимо агрегировать результаты из разных шардов.,При необходимости выполняйте сортировку, разбиение по страницам и другую обработку результатов. Этот процесс может потребовать определенных вычислительных ресурсов.,Особенно, когда набор результатов велик.
7. Верните результаты клиенту
- Как только результаты будут готовы,Координирующий узел инкапсулирует их в единый формат ответа.,и возвращаемся к клиенту。В ответе содержится запросизрезультат、Количество совпадающих документов、Агрегированная информация, такая как данные (при наличии). Клиент может проанализировать этот ответ, чтобы получить необходимые данные.
Стратегии кэширования и оптимизации
- Кэш запросов:ElasticsearchНекоторые результаты запроса будут кэшироваться,Чтобы быстро ответить на один и тот же запрос запроса. Это может сократить количество повторных посещений Luceneindex.,Улучшите производительность запросов. Однако,Из-за ограниченного пространства кэша,Кэшируются только некоторые результаты запроса.
- Сегментированный кеш запросов:данныена узлеиз Сегментированный кеш запросов Запросы могут хранитьсяизрезультат。когда жеиз Запрос приходит сновачас,Результаты могут быть получены непосредственно из кеша,Нет необходимости снова посещать индекс Lucene. Это помогает снизить зависимость от дискового ввода-вывода.,Улучшите скорость запросов.
- Оптимизация операторов запроса:чтобы улучшить查询производительность,Пользователи должны писать эффективные операторы запросов. Избегайте использования дорогостоящих операций запроса (таких как запросы с подстановочными знаками, запросы регулярных выражений и т. д.).,Правильное использование фильтров и операций агрегирования,Оптимизация структуры индексов может помочь улучшить скорость запросов.
Основываясь на этих подробных шагах и стратегиях оптимизации, Elasticsearch может эффективно обрабатывать запросы на чтение данных и предоставлять пользователям быстрые и точные результаты.
4️⃣✍🏻Резюме
Процесс чтения и записи Elasticsearch — это тщательно спроектированный распределенный процесс обработки. При записи данных он обеспечивает надежность и долговечность данных с помощью таких механизмов, как буферы, журналы транзакций, операции обновления и очистки.
В то же время, с помощью мощных возможностей индексирования Lucene, документы можно быстро преобразовать в форму, доступную для поиска. При чтении данных Elasticsearch использует узел координации для маршрутизации запроса к нужному узлу данных, использует Lucene для эффективного поиска, агрегирует и сортирует результаты и, наконец, возвращает их клиенту. Этот процесс сочетает в себе такие технологии, как кэширование, оптимизированные операторы запросов и распределенную обработку, чтобы обеспечить высокую производительность и низкую задержку для запросов. Благодаря этим разработкам Elasticsearch предоставляет предприятиям и разработчикам мощные и гибкие решения для хранения и поиска данных.
Навыки обновляются благодаря обмену ими, и каждый раз, когда я получаю новые знания, мое сердце переполняется радостью. Искренне приглашаем вас подписаться на публичный аккаунт 『
код тридцать пять』 , для получения дополнительной технической информации.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
