Кэш KV большой модели сохраняет заметки об исследовании артефактов MLA (включая анализ поглощения матрицы во время вывода)
Сначала в этой статье рассматривается метод расчета MHA и принцип KV-кэша, затем рассматривается принцип MLA DeepSeek V2, а также дается подробный расчет и интерпретация доли KV-кэша, сохраняемой MLA. Затем, с пониманием принципов, я разъяснил всю реализацию HuggingFace MLA. Каждая строка кода соответствовала определенной строке в полной формуле, а также анализировались изменения формы тензора до и после каждой операции. Мы видим, что текущая официальная реализация не сохраняет скрытые векторы при хранении KV Cache, а распаковывает все скрытые векторы в стандартный MHA KV Cache. По сути, она вообще не может экономить видеопамять. Затем я продолжил изучать инженерную реализацию матричного поглощения MLA, реализованную группой ZHANG Mingxing из Университета Цинхуа. В этом разделе я также подробно проанализировал, как принципы, включая и, поглощаются и соответственно, и проанализировал каждую строку кода, которая есть. реализует матричное поглощение. Принцип и изменения размеров соответствующего тензора до и после выполнения операции. Далее, анализируя свойства умножения матриц в реализации кода матричного поглощения, мы видим, что MLA на большинстве этапов требует больших вычислительных ресурсов, а не доступа к памяти. Наконец, приводятся результаты тестов группы авторов и объясняется, почему поглощение двух матриц пересчитывается вперед вместо непосредственного сохранения большой матрицы проекции после поглощения.
Позвольте мне упомянуть здесь, что несколько репозиториев, которые я поддерживаю, с записями личных исследований и отличными ссылками на блоги других крупных ребят из сообщества, получили множество звезд. Я хотел бы поблагодарить читателей за их признание. Я буду продолжать вносить больше вклада в открытое сообщество. исходное сообщество. Домашняя страница Github: https://github.com/BBuf, добро пожаловать в гости

0x0.
Эта статья в основном посвящена моему личному пониманию метода MLA, предложенного Deepseek2 для оптимизации KV Cache, особенно о части MLA, связанной с матричным поглощением. Эта часть статьи и официальная реализация с открытым исходным кодом не приводятся. Затем лидер сообщества разработчиков программного обеспечения с открытым кодом действовал быстро. В ответ Чжиху: «Что вы думаете о большой модели MoE DeepSeek-V2, выпущенной DeepSeek?» 》Группа Чжан Минсин из Университета Цинхуа предложила реализацию MLA с матричным поглощением и предоставила PR, который совместим с существующей реализацией Transformers (https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat/discussions/ 12).
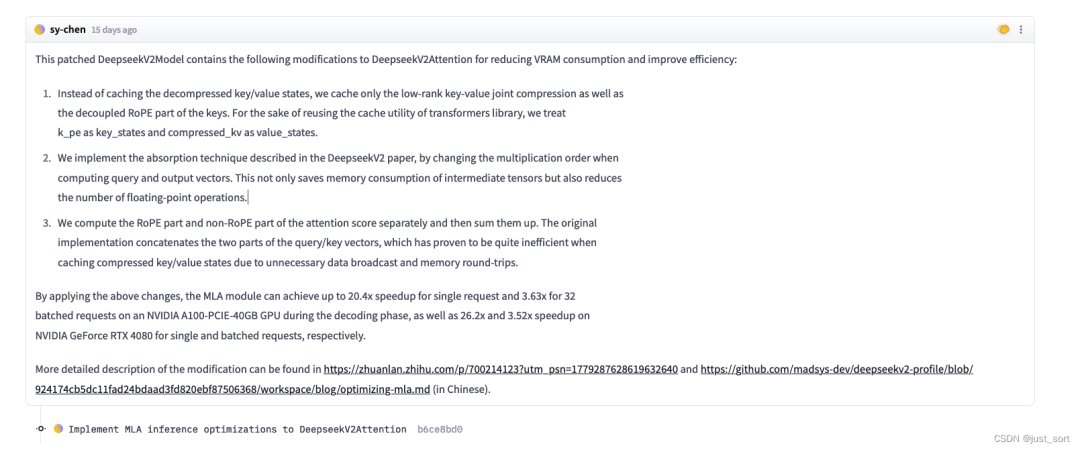
переводить:
Эта исправленная модель DeepseekV2Model содержит следующие модификации DeepseekV2Attention для уменьшения потребления VRAM и повышения эффективности:
- Дешифрованное состояние сжатия из ключа/значения больше не кэшируется, и кэшируются только сжатие объединения ключей и значений низкого ранга и отделенная часть RoPE Key из. для библиотеки повторно используемых трансформаторов из утилиты кэширования,мы будемk_peВидетьдляkey_states,Воляcompressed_kvВидетьдляvalue_states。
- использоватьDeepseekV2Описано в статьеизпоглощатьтехнология,Изменяя порядок умножения при вычислении вектора QueryиOutput. Это не только экономит потребление памяти промежуточными тензорами.,Это также уменьшает количество операций с плавающей запятой.
- Рассчитать отдельноRoPEчастьи нетRoPEчастьиз Оценка внимания,Затем добавьте их. Исходная реализация соединяет вектор запроса/ключа из двух частей.,носуществоватькэшсжатиеKey/Valueсостояниепотому чтоненужныйизпередача данныхи Память туда и обратноиодеяло Оказаться менее эффективным。
Применяя вышеуказанные изменения, модуль MLA может добиться ускорения до 20,4 раза для одного запроса и ускорения в 3,63 раза для 32 пакетных запросов на графическом процессоре NVIDIA A100-PCIE-40GB на этапе декодирования на NVIDIA GeForce RTX 4080 для Single и; Пакетные запросы достигают ускорения в 26,2x и 3,52x соответственно.
Этот блог, с моей точки зрения, предназначен для того, чтобы понять инженерную реализацию матричного поглощения в этом PR и почему он может ускорить существующую реализацию Deepseek2 MLA. В этой статье сначала рассматривается происхождение KV-кэша на этапе декодирования MHA, а затем используется формула статьи, чтобы понять реализацию класса DeepseekV2Attention в Transformers. Далее давайте узнаем о реализации технологии поглощения матрицы MLA, предложенной группой ZHANG Mingxing.
Paper Link:https://arxiv.org/pdf/2405.04434
0x1. Происхождение KV-кэша на этапе декодирования MHA.
Сначала давайте рассмотрим принцип и реализацию механизма MHA на этапе декодирования.
Источник приведенной ниже формулы также взят из статьи DeepSeek2, и я дал более подробное объяснение.
Предположим, что размер пакета равен 1. Кроме того, поскольку это этап декодирования и входные данные представляют собой только один токен, длина последовательности также равна 1, поэтому входные данные можно выразить как. Затем предположим, что размерность словаря внедрения равна , и существует число, обозначающее заголовок внимания, представляющее размерность каждого заголовка внимания.
t указывает, какой токен в данный момент находится на этапе декодирования.
Затем он получается с помощью трех матриц параметров. Конкретный метод представляет собой умножение трех матриц:
q_t = W^Q h_t, \newline k_t = W^K h_t, \newline v_t = W^V h_t,
При расчете MHA здесь внимание будет разделено на главы, а именно:
Здесь представлены результаты вычислений первого заголовка запроса, ключа и значения соответственно.
Следующим шагом является расчет оценки внимания и производительности. Формула выглядит следующим образом:
o_{t,i} = \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{q_{t,i} k_{j,i}}{\sqrt{d_h}} \right) v_{j,i}, \newline u_t = W^O [o_{t,1}; o_{t,2}; \cdots ; o_{t,n_h}]
Здесь представлена выходная матрица отображения. Как видно из приведенной выше формулы, для текущего запроса токена расчет внимания будет производиться с ключами и значениями всех предыдущих токенов, а так как все токены, соответствующие токену до токена за токеном, генерируются , мы можем их кэшировать. Вниз, избегайте двойных вычислений, в этом суть KV Cache.
Для уровня стандартной сети MHA размер KV-кэша, необходимый для каждого токена, равен, где 2 соответствует bf16 байтам.
Для улучшения КВ Кэш, развил серию ИИ Инфра-работы, такие как Paged Attention, GQA, MLAвключая последниеизGQA,MLAснаружииз Другой видKV Метод сжатия кэша: динамическое сжатие памяти (DMC).,vВнимание: используется, когда нет страницы. Обслуживание с вниманием LLM 。
0x2. Введение в принцип DeepSeek2 MLA.
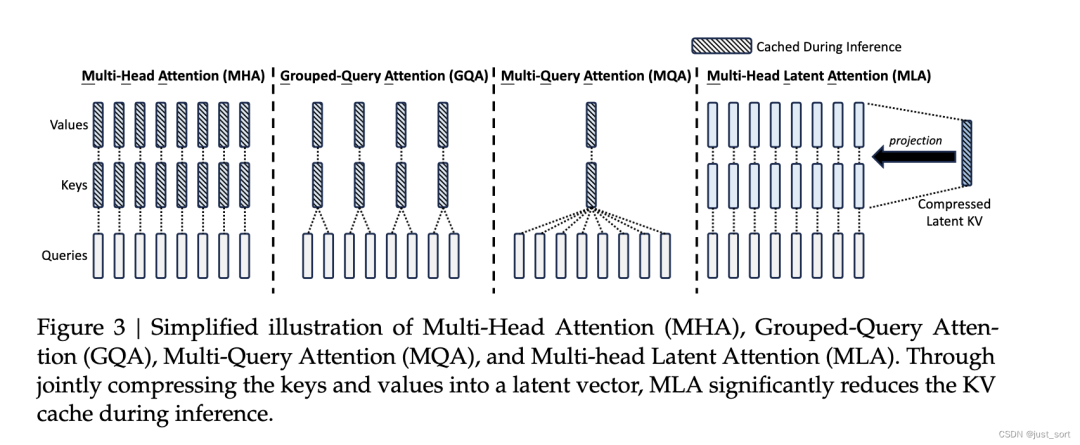
Изображение выше представляет собой сравнение распространенных методов сжатия KV-кэша в статье Deepseek2. Вы можете видеть, что ядром MLA является совместное сжатие ключей и значений низкого ранга для уменьшения KV-кэша. Соответствует формулам 9-11 статьи.
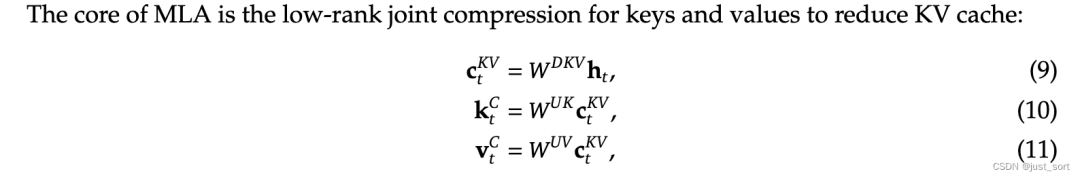
в,
- : значит правильно key и value сжатие и скрытый вектор latent vector ,здесь выражать KV Cacheсжатиеиз измерения.
- :выражать матрицу проекции вниз
- :выражатьup-проекцию матрица
Таким образом, во время вывода необходимо кэшировать только скрытый вектор, поэтому каждый токен, соответствующий MLA, имеет только параметры KV-кэша, где — количество сетевых уровней, а — bfloat16 байт.
Кроме того, чтобы уменьшить память активации во время обучения, DeepSeek2 также выполняет низкоранговое сжатие запроса, хотя это не уменьшает KV-кэш:
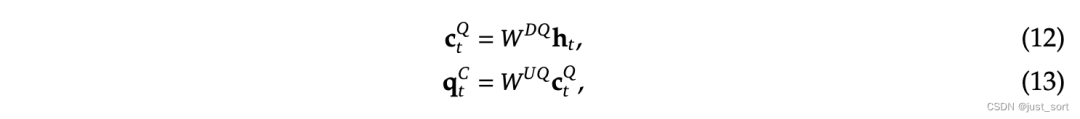
в,
- :выражать Воля queries сжатие и скрытый вектор, выражать query сжатие по размеру
- соответственновыражать down-projection и up-projection матрица
Одна из проблем, обсуждаемых MLA, заключается в том, что мы не учитывали RoPE в описанном выше процессе сжатия. Исходный RoPE должен включать информацию об относительном положении в запрос и ключ. В MLA относительно легко включить в запрос информацию об относительной позиции, но поскольку KV Cache кэширует сжатую информацию о ключах низкого ранга, нет способа включить информацию об относительной позиции.
Что касается того, почему RoPE несовместим с MLA, в блоге Су Шена есть более подробное объяснение. Рекомендуется прочитать https://kexue.fm/archives/10091.
Ниже приводится объяснение главы «Встраивание несвязанного поворотного положения» в документе «Бумага».
Определите весь текст и формулы на диаграмме следующим образом:
Потому что RoPE чувствителен к позиции как для запроса, так и для ключа. Если RoPE используется для , то матрица RoPE, связанная с сгенерированным в данный момент токеном, будет находиться между и , а умножение матрицы не подчиняется коммутативному закону, поэтому его нельзя интегрировать во время рассуждений. Это означает, что во время вывода нам придется пересчитывать ключи всех предыдущих токенов, что сильно снизит эффективность вывода.
Здесь он интегрирован в. См. пояснение к снимку экрана ниже из блога Су Шена. Я расскажу об этом принципе подробно в следующем разделе.

Поэтому DeepSeek2 предлагает отдельную стратегию RoPE, а именно:
Используйте дополнительные запросы с несколькими заголовками и общие ключи для переноса информации RoPE, где представляет собой размерность заголовка отдельных запросов и ключей.
На основе этой несвязанной стратегии RoPE логика расчета, которой следует MLA, следующая:

в:
- и соответственно выразить расчет после развязки из queries и key изматрица
- RoPE() выражатьприложение RoPE из эксплуатации; выразить операцию сращивания
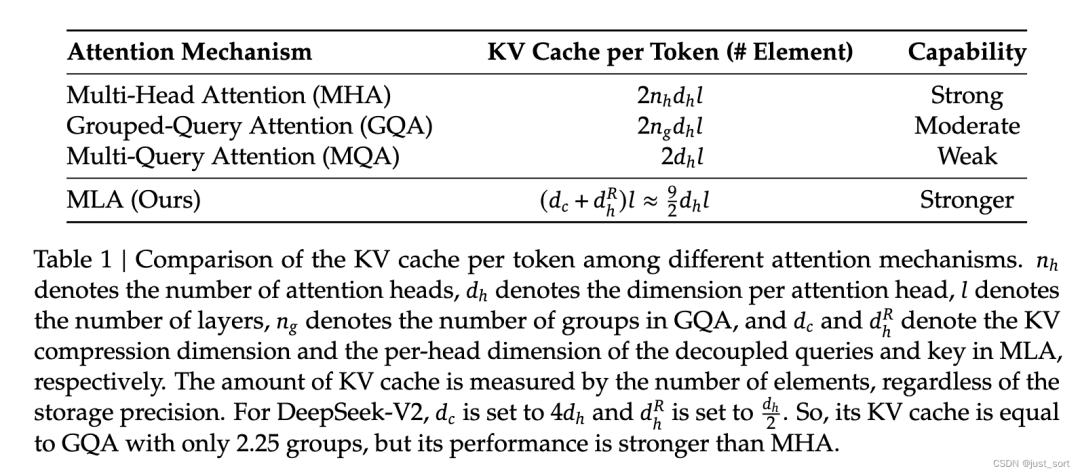
Во время вывода вам нужно кэшировать только отделенный ключ и, конечно же, указанный выше неявный вектор. Поэтому KV-кэш для одного токена содержит только элементы. Количество слоев и количество байтов bf16 здесь не учитываются. Более подробно вы можете посмотреть сравнение данных в Таблице 1:
Переведите это:
Таблица 1 | Сравнение KV-кеша для каждого токена в различных механизмах внимания. представляет количество заголовков внимания, представляет размерность каждого заголовка внимания, представляет количество слоев, представляет количество групп в GQA, а также представляет размерность сжатия KV и размерность каждой главы разделенных запросов и ключей в MLA, соответственно. . Размер KV-кэша измеряется количеством элементов, независимо от точности хранения. Для DeepSeek-V2 установлено значение и установлено значение . Таким образом, его KV-кэш равен GQA только с 2,25 группами, но его производительность выше, чем у MHA.
Вот и все принципы. Далее давайте прочитаем реализацию DeepseekV2Attention с учетом этих принципов.
Вот специальное объяснение метода расчета в Paper, который экономит 93,3% KV-кэша по сравнению с Deepseek 67B от Dense (или LLaMa3 70B):

Во-первых, это количество слоев. DeepSeek2 имеет 60 слоев, а Deepseek 67B — 95 слоев. Коэффициент экономии слоев составляет 60/95.
Затем есть однослойный KV-кэш, соотношение (4,5 x 128) / (2 x 8 x 128), где 2 представляет K и V, 8 представляет собой num_attention_heads, 128 представляет размер головы, а 4,5 представляет собой 9/2 MLA выше. Сжатие скрытых векторов.
Кроме того, DeepSeek2 использует 6-битное квантование для KV-кэша, а коэффициент экономии составляет 6/16.
Умножьте эти три отношения и вычтите 1, чтобы получить 93,3%.
Ощущение 6-битности здесь учитывает масштаб параметров квантования и нулевую точку. Если используется 4-битное квантование, а масштаб/нулевая точка равна fp32, то при group_size=32, согласно правилу группового квантования, каждые 32 элемента. соответствуют группе. Для масштаба и нулевой точки float32 разрядность каждого элемента на 2 бита больше, а разрядность квантованного бита эквивалентна 6 битам.
0x3. Официальная интерпретация кода реализации MLA HuggingFace.
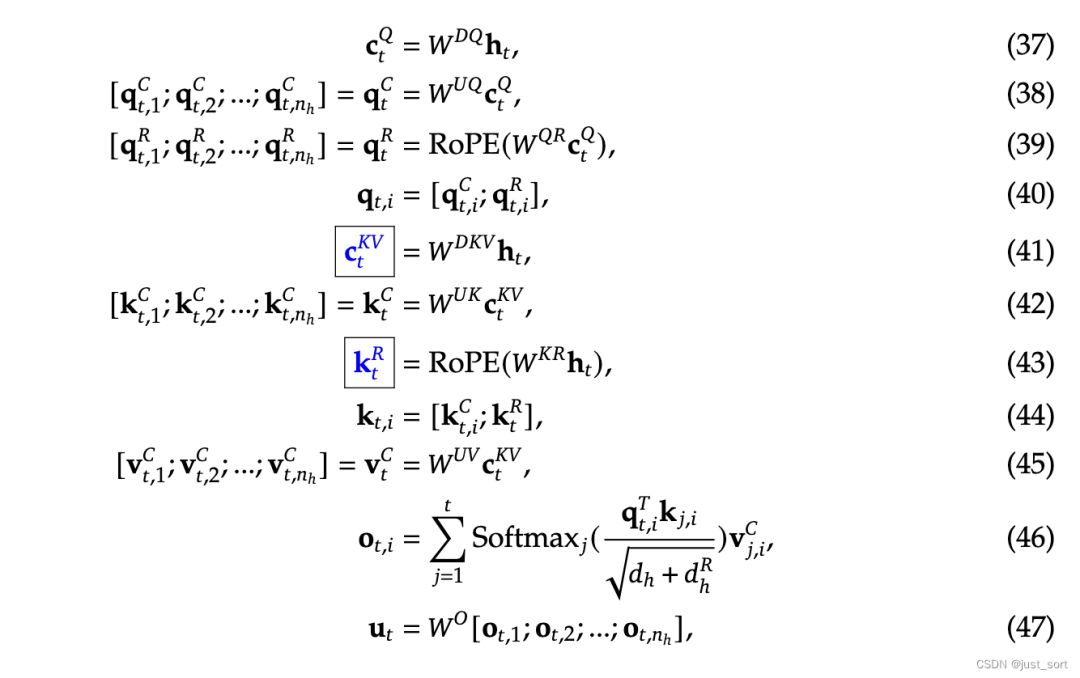
Чтобы облегчить описание кода, полная формула размещена прямо здесь, Приложение C документа:
На основе приведенного выше введения принципа ниже приведена интерпретация модуля DeepseekV2Attention. Ссылка на код: https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat/blob/main/modeling_deepseek.py#L680.
Давайте сначала посмотрим на часть инициализации. Чтобы быстро понять код, просто проигнорируйте часть кода, связанную с расчетом RoPE.
# Copied from transformers.models.llama.modeling_llama.LlamaAttention with Llama->DeepseekV2
class DeepseekV2Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: DeepseekV2Config, layer_idx: Optional[int] = None):
super().__init__()
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
# переписываться query сжатие и скрытый Векториз Размеры d'_c
self.q_lora_rank = config.q_lora_rank
# переписываться$d_h^R$, выразитьприкладную веревкуиз queries и key изодининдивидуальный head из измерения.
self.qk_rope_head_dim = config.qk_rope_head_dim
# переписываться key-value сжатие и скрытый Вектор Размеры d_c
self.kv_lora_rank = config.kv_lora_rank
# value индивидуальный уровень внимания головы из скрытого слоя - это степень
self.v_head_dim = config.v_head_dim
# выразить запрос иkeyiz Применить размерность веревочной части в скрытых векторах
self.qk_nope_head_dim = config.qk_nope_head_dim
# Каждая отдельная глава внимания из измерения должна состоять только из двух частей и
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
self.is_causal = True
# MLA средняя пара Q проекцияматрица Также сделалодининдивидуальныйразложение низкого ранга,переписыватьсягенерировать q_a_proj и q_b_proj дваиндивидуальныйматрица。 # в q_a_proj Размер [hidden_size, q_lora_rank] = [5120, 1536],
# переписываться В приведенной выше формулеизW^DQ
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
# q_b_proj Размер [q_lora_rank, num_heads * q_head_dim] =
# [q_lora_rank, num_attention_heads * (qk_nope_head_dim + qk_rope_head_dim)] = [1536, 128*(128+64)] = [1536, 24576]
# переписаться В приведенной выше формуле изW^UQиW^QR объединяется из большойматрицы
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
# Подобно вектору Q, вектор KV генерируется путем его предварительного проецирования на низкоразмерную модель. compressed_kv вектор(переписыватьсяc_t^{KV})
# Затем расширьте размер. Конкретно из задействованных кодов kv_a_proj_with_mqa и kv_b_proj дваиндивидуальныйпараметрматрица。 # в kv_a_proj_with_mqa Размер [hidden_size, kv_lora_rank + qk_rope_head_dim]
# = [5120, 512 + 64] = [5120, 576],переписываться В приведенной выше формулеизW^{DKV}иW^{KR}。
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
# kv_b_proj Размер [kv_lora_rank, num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim)]
# = [512, 128*((128+64)-64+128)] = [512, 32768],переписываться В приведенной выше формулеизW^{UK}иW^{UV}。
# потому что W^{UK} включает только non rope изчасть Итак, среднее измерение qk_rope_head_dim Удаленный.
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
# переписыватьсяполная формулаиз Нет. 47 ХОРОШО
self.o_proj = nn.Linear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=config.attention_bias,
)
В соответствии с введением принципов в разделе 0x2 теперь можно сопоставить все весовые матрицы в модуле DeepseekV2Attention с кодом инициализации. Если вы хотите продолжить чтение, вы должны понимать каждую строку кода инициализации.
Чтобы облегчить просмотр формулы при понимании кода пересылки, полная формула снова размещена здесь:
Далее давайте посмотрим на форвардный код, который соответствует подробному процессу расчета в полной формуле:
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Cache] = None,
output_attentions: bool = False,
use_cache: bool = False,
**kwargs,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
if "padding_mask" in kwargs:
warnings.warn(
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
)
# hidden_statesпереписываться Официально в процессеизh_t,изshapeда(batch_size, seq_length,
# hidden_size),в hidden_size Конкретно 5120, при условии, что пакетный_размер иseq_длина оба равны 1
bsz, q_len, _ = hidden_states.size()
# вычислитьQ:переписыватьсяполная формуласерединаиз 37-39 ХОРОШО,Сначала уменьшите размер, а затем увеличьте его.,Преимущества по сравнению с прямым использованием Размера [5120, 24576] изматрица
# [5120, 1536] * [1536, 24576] Таким образом, пространство для хранения и объем вычислений разложения низкого ранга значительно сокращаются.
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
# резать rope и нет rope часть, в полной формуле 40 ХОРОШО в свою очередь
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
# переписываться Официально в процессеиз 41 и 43 ХОРОШОonly да еще не добавлено rope
# одининдивидуальныйоптимизацияиз MLA KVCache Реализации необходимо только кэшировать этот индивидуальный compressed_kv Сразу ХОРОШО
# kv_a_proj_with_mqa shape для[скрытый_размер, kv_lora_rank + qk_rope_head_dim]
# = [5120, 512 + 64] = [5120, 576]
# Таким образом, compressed_kvizshape — это да[1, 1, 576]
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
# переписыватьсяполная формулаиз 44 ХОРОШО в свою очередь
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
# здесьиз k_pe и Выше q_pe Бросить в Модуль RoPE, поэтому форму необходимо изменить.
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
# переписываться Официально в процессеиз 42 и 45 ХОРОШО,Воля MLA расширить до стандарта MHA из формы
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
# потому что kv_b_proj упакованный W^{UK} и W^{UV} разделить их
k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
# Получить ключ/значение из длины последовательности
kv_seq_len = value_states.shape[-2]
if past_key_value is not None:
if self.layer_idx is None:
raise ValueError(
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
"with a layer index."
)
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
# Отдать нуждающимся rope изчастьплюс rope
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
# Обновление и история сварки KVCache, вы можете увидеть, что здесь хранилище расширено. MHA KVCache
# в q_head_dim равный qk_nope_head_dim + qk_rope_head_dim
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
# Стандарты в библиотеке Трансформеров KV Cache Обновить код
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
key_states, value_states = past_key_value.update(
key_states, value_states, self.layer_idx, cache_kwargs
)
# Далее будет стандартный расчет многоголового внимания. Ради длины я проигнорирую эту часть кода.
...
Прочитав этот раздел, вы сможете понять каждую строку полной формулы MLA, и мы увидим, что текущая официальная реализация не сохраняет скрытые векторы при хранении KV-кэша, а распаковывает все скрытые векторы в KV-кэш, который стал стандартный MHA, фактически вообще не может экономить видеопамять.
0x4 поглощение матрицы.
Этот раздел посвящен изучению и пониманию поглощения матрицы MLA, реализованного группой Чжан Минсин из Университета Цинхуа (https://zhuanlan.zhihu.com/p/700214123). Его код напрямую применяется к реализации HF, поэтому его можно легко применить. Для понимания повторю полную формулу:
И матричное поглощение, упомянутое в статье,

0x4,1 Вт^{Великобритания} поглощение
Для матрицы имеем:
То есть нам на самом деле нужно не разлагать маломерное и потом вычислять, а непосредственно умножать с левой частью по закону ассоциативности.
# Следующий и предыдущий раздел изMLA впередчасть реализует то же самое
# hidden_statesпереписываться Официально в процессеизh_t,изshapeда(batch_size, seq_length,
# hidden_size),в hidden_size Конкретно 5120, при условии, что размер пакета равен 1, а длина seq_length равна q_len.
bsz, q_len, _ = hidden_states.size()
# вычислитьQ:переписыватьсяполная формуласерединаиз 37-39 ХОРОШО,Сначала уменьшите размер, а затем увеличьте его.,Преимущества по сравнению с прямым использованием Размера [5120, 24576] изматрица
# [5120, 1536] * [1536, 24576] Таким образом, пространство для хранения и объем вычислений разложения низкого ранга значительно сокращаются.
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
# резать rope и нет rope часть, в полной формуле 40 ХОРОШО в свою очередь
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
# переписываться Официально в процессеиз 41 и 43 ХОРОШОonly да еще не добавлено rope
# одининдивидуальныйоптимизацияиз MLA KVCache Реализации необходимо только кэшировать этот индивидуальный compressed_kv Сразу ХОРОШО,Но на самом деле это происходит позже
# hidden_states из shape для (1, past_len, hidden_size)
# kv_a_proj_with_mqa shape для[скрытый_размер, kv_lora_rank + qk_rope_head_dim]
# = [5120, 512 + 64] = [5120, 576]
# Таким образом, compressed_kvizshape — это да[1, past_len, 576]
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
# переписыватьсяполная формулаиз 44 ХОРОШО в свою очередь
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
# здесьиз k_pe и Выше q_pe Бросить в Модуль RoPE, поэтому форму необходимо изменить.
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
Следующая часть включает в себя изменения, которые необходимо внести, опуская изменения для добавления compressed_kv и k_pe в кэш Transformers KV:
# от kv_b_proj среднее разделение из W^{UK} и W^{UV} Две части, они должны быть поглощены в разных местах соответственно существования.
kv_b_proj = self.kv_b_proj.weight.view(self.num_heads, -1, self.kv_lora_rank)
q_absorb = kv_b_proj[:, :self.qk_nope_head_dim,:]
out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]
cos, sin = self.rotary_emb(q_pe)
q_pe = apply_rotary_pos_emb(q_pe, cos, sin, q_position_ids)
# W^{UK} Прямо сейчас q_absorb одеяло q_nope поглощать
q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope)
# После поглощения attn_weights непосредственно на основе compressed_kv Расчет не требует расширения.
attn_weights = torch.matmul(q_pe, k_pe.transpose(2, 3)) + torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)
attn_weights *= self.softmax_scale
Здесь главное усвоить код и нужно внимательно в нем разобраться:
- от0x4Фестивальиз Уже знаю объяснениеkv_b_projСразуда и двачасть,здесьда Пучокпоглощатьприезжать,такнужно сначала Пучокдваразделенный。Уведомлениеприезжать
self.kv_b_projweight Форма[kv_lora_rank, num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim)] = [512, 128*((128+64)-64+128)] = [512, 32768],такkv_b_projиз Форма[num_heads,q_head_dim - qk_rope_head_dim + v_head_dim , kv_lora_rank],q_absorbиз Форма[num_heads, qk_nope_head_dim , kv_lora_rank]=[128, 128, 512],такой жеout_absorbиз Форма[num_heads, v_head_dim , kv_lora_rank]=[128, 128, 512]。 q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope)этот ХОРОШОв коде,q_nopeизshapeда[batch_size, num_heads, q_len, q_head_dim]。такэтот ХОРОШОкод Сразудаодининдивидуальныйматрицаумножение,Пучокпоглощатьприезжать。- После поглощения attn_weights непосредственно на основе compressed_kv Расчет не требует расширения.переписываться
torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)этот ХОРОШОкод。вq_nope от[batch_size, num_heads, q_len, kv_lora_rank],compressed_kv да[batch_size, past_len, kv_lora_rank],Выход[batch_size, num_heads, q_len, past_len]。 - также,Мы все еще можемкнаблюдатьприезжать
torch.matmul(q_pe, k_pe.transpose(2, 3))этот ХОРОШОкоддаотдельныйвычислить ПонятноRoPEчастьизqиkиз Уведомление力вычислить Спросить еще рази,Нетиоригинальныйизвыполнитьодин Образец Воля加上Понятно rope из q_pe/k_pe Без добавления rope из q_nope/k_nope В совокупности это код ниже даиз. Команда авторов называет это разделение индивидуальным. Move Elision из Оптимизация, позже будет сравнение производительности.
# Обновление и история сварки KVCache, вы можете увидеть, что здесь хранилище расширено. MHA KVCache
# в q_head_dim равный qk_nope_head_dim + qk_rope_head_dim
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
Помимо сжатия КВ В дополнение к Cache мы также можем заметить, что два матричных умножения, упомянутые выше, на самом деле относятся к областям с интенсивными вычислениями, например
torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv). из-за разных head из q_nope часть share общий из compressed_kv часть, фактический расчет изда batch_size индивидуальный [num_heads * q_len, kv_lora_rank] и [past_len, kv_lora_rank] изматрица умножения. Рассчитанный эквивалент индивидуального MQA операции,интенсивность вычислений пропорциональна num_heads изтакже Сразуда 128。
0x4,2 Вт^{УФ} поглощение
Для нас у нас есть:
(переписыватьсячиновникиз45ХОРОШО) attn_weights и изматрицаумножение
Здесь attn_weights записывается как , тогда есть:
иизпоглощать Процесс аналогичен,Используйте ассоциативность, чтобы изменить порядок вычислений, то есть:
мы можемк Пучокпоглощатьприезжатьсередина,переписыватьсяизкодвыполнить:
# attn_weightизshapeда[batch_size, num_heads, q_len, past_len]
# compressed_kvизshapeда[batch_size, past_len, kv_lora_rank]
# attn_outputизshapeда[batch_size, num_heads, q_len, kv_lora_rank]
attn_output = torch.einsum('bhql,blc->bhqc', attn_weights, compressed_kv)
# out_absorbизshapeда[num_heads, v_head_dim , kv_lora_rank]
# out_absorb.mTизshapeда[num_heads, kv_lora_rank, v_head_dim]
# Окончательный attn_outputизshapeда[batch_size, num_heads, q_len, v_head_dim]
attn_output = torch.matmul(attn_output, out_absorb.mT)
Примечание: Метод .mT используется для транспонирования тензора. для двумерного тензора (матрица),Операция транспонирования меняет ХОРОШОи Список。идля Тензор большой размерности,.mT Последние два индивидуальных измерения будут заменены.
Аналогично, здесь Помимо сжатия КВ Помимо Cache, мы также можем наблюдать, что приведенное выше умножение с участием 2индивидуальной матрицы на самом деле относится к области с интенсивными вычислениями, например для
attn_output = torch.einsum('bhql,blc->bhqc', attn_weights, compressed_kv). из-за разных head из attn_weights часть share общий из compressed_kv часть, фактический расчет изда batch_size индивидуальный [num_heads * q_len, kv_lora_rank] и [past_len, kv_lora_rank] изматрица умножения. Рассчитанный эквивалент индивидуального MQA операции, интенсивность вычислений пропорциональна num_heads изтакже Сразуда 128. Поэтому по сравнению с MHA,После поглощенияиз MLA Он требует гораздо больше вычислительных ресурсов и, следовательно, может быть использован более полно. GPU вычислительная мощность.
0x4.3 Свойства MLA MatMul
Вышеупомянутое анализирует почти каждую отдельную матрицу умножения формы расчета.,Можно обнаружить, что помимо участия gemv в существующих расчетах q,также Сразудаq = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states))),В других местах операция умножения размерности q_len вычисляется вместе с даинум_headsсуществовать.,инум_headsсуществоватьDeepseek2изконфигурации уже есть да128,В результате почти все остальные Matmul попадают в категорию вычислительно интенсивных.
Подводить итоги,для модуля MLA,Большая часть MatMul достигла категории с интенсивными вычислениями.,Это меняет прежний интенсивный характер доступа MHA. Однако,существоватьвсеиндивидуальныйсетевой центр,потому чтоиметьMoEмодульизжитьсуществовать,Если BatchSize недостаточно велик (невозможно активировать все экспертные,В результате соотношение вычислений и доступа к памяти = низкая плотность вычислений) и общая плотность вычислений не могут быть достигнуты.,ноMLAФестиваль ПровинцияизKV Кэш может значительно улучшить DeepSeek2изBatch, поэтому требования к пропускной способности для каждого отдельного токена распределяются равномерно по сравнению с DenseизLLaMa3. 70B также значительно упадет.
0x4.4 Benchmark
наконец,Команда авторов привела некоторые результаты Benchmark в своем блоге.,Можетксмотретьприезжатьэтотиндивидуальныйматричное сотрудничествоиз эффективности.
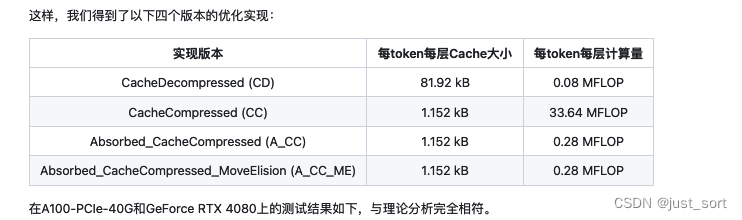
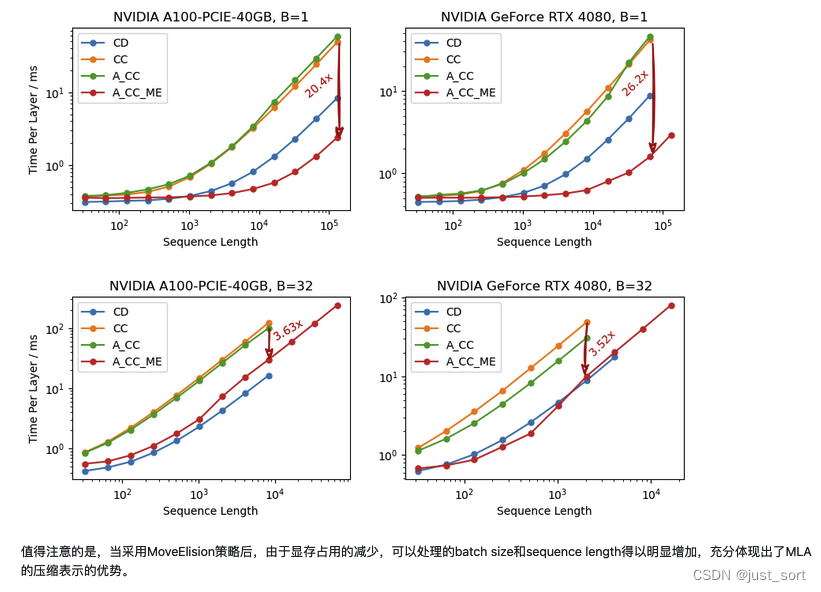
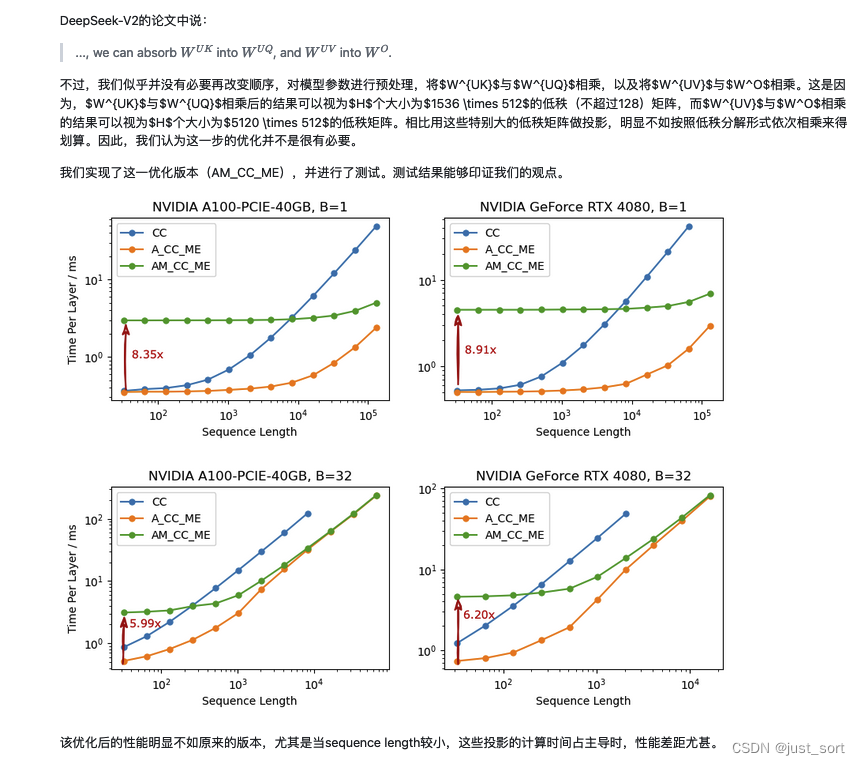
Вставьте сюда описание изображения
Теги из на картинке означают «выражать» Исходная версия CacheDecompressed (CD), KV Уменьшение кэша из CacheCompressed (CC), После партнерия прямого использования compressed_kv Расчет Absorbed_CacheCompressed (A_CC) версию, я добавил move elision Оптимизируйте финальную версию Absorbed_CacheCompressed_MoveElision (A_CC_ME)。
0x4.5 Нужно ли пересчитывать?
кизпоглощатьдляпример,здесьна самом деледаобъяснятьсуществоватьматричное поглощениеизкогдада Вы хотите продвинуться Пучокиизматрица Результат умножения гарантированжитьспускаться,и нет дасуществоватьвпередиз времени для перерасчета. Автор существует ответил на этот индивидуальный вопрос в комментариях.,Это означает, что скорость пересчета будет выше при прямой пересылке. В блоге это объясняется следующим образом:
0x5.
Это все содержимое этого блога.,здесь Подвести итогодин Вниз。Сначала в этой статье рассматривается метод расчета MHA и принцип KV-кэша, затем рассматривается принцип MLA DeepSeek V2, а также дается подробный расчет и интерпретация доли KV-кэша, сохраняемой MLA. Затем, с пониманием принципов, я разъяснил всю реализацию HuggingFace MLA. Каждая строка кода соответствовала определенной строке в полной формуле, а также анализировались изменения формы тензора до и после каждой операции. Мы видим, что текущая официальная реализация не сохраняет скрытые векторы при хранении KV Cache, а распаковывает все скрытые векторы в стандартный MHA KV Cache. По сути, она вообще не может экономить видеопамять. Затем я продолжил изучать инженерную реализацию матричного поглощения MLA, реализованную группой ZHANG Mingxing из Университета Цинхуа. В этом разделе я также подробно проанализировал, как принципы, включая и, поглощаются и соответственно, и проанализировал каждую строку кода, которая есть. реализует матричное поглощение. Принцип и изменения размеров соответствующего тензора до и после выполнения операции. Далее, анализируя свойства умножения матриц в реализации кода матричного поглощения, мы видим, что MLA на большинстве этапов требует больших вычислительных ресурсов, а не доступа к памяти. Наконец, приводятся результаты тестов группы авторов и объясняется, почему поглощение двух матриц пересчитывается вперед вместо непосредственного сохранения большой матрицы проекции после поглощения.
0x6.
- https://www.zhihu.com/question/655172528
- https://arxiv.org/pdf/2405.04434



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
