Кейс Elasticsearch RAG: настройка релевантности для гибридного поиска

В нашей предыдущей статье《Случай Elasticsearch: код Baixing реализует RAG справочной документации Tencent ES》В этой статье мы познакомим вас, как быстро выполнить поиск с помощью комплексного поискового решения.выполнить RAG , чье внимание сосредоточено на эффективности —— Полный и удобный пакет решений,Это делает весь процесс создания и запуска RAG более эффективным, прилагая вдвое меньше усилий. И эта статья,МыСосредоточьтесь на результатах поиска, на том, как адаптироваться к различным ситуациям (разные привычки пользователей в поиске и возможные дефектные данные) и добиться оптимальных результатов.。
как было сказано ранее,Нелегко по-настоящему понять, что такое RAG.,выполнитьRAGЭто еще сложнее。Текущая ситуация такова, что большую часть времени пользователи простовыполнитьRAGПонимается как добавлениевекторная база данных。ноRAGэто сложное понятие,Это не просто векторная база данных,Внедрение RAG требует глубокого понимания бизнес-сценариев.,И требует большой обработки данных и оптимизации алгоритмов.,Понимание и обратная связь поведения пользователей также являются важным ключом к достижению конечного эффекта.。Итак, нам нужно скорее гибридное поисковое решение, а не просто векторный поиск.。
Преимущества и ограничения векторного поиска
Мы знаем, что векторный поиск — это метод поиска, основанный на модели векторного пространства, который может преобразовывать текст в математические векторы, а затем достигать сопоставления и поиска текста путем расчета сходства между векторами. Принцип и процесс векторного поиска примерно следующие:
- Во-первых, текст должен быть предварительно обработан, например, извлечение магистрали, фрагмент, карта и т. д., чтобы преобразовать текст в размер, подходящий для обработки модели встраивания слов, и установить связь между фрагментами и исходным документом.
- Затем текст необходимо векторизовать, то есть фрагментированный текст представляется в виде многомерного числового вектора. Этого можно добиться с помощью некоторых моделей встраивания слов, таких как Word2Vec, GloVe, BERT и т. д.
- Наконец, оператор запроса должен быть векторизован, то есть оператор запроса представлен в виде многомерного числового вектора. Этого можно достичь с помощью той же модели внедрения документа, что и сам документ, или с помощью некоторых специальных моделей внедрения запроса, таких как: Q-BERT, Q-трансформатор и т. д.
- После получения векторного представления документа и оператора запроса сопоставление и поиск текста могут быть достигнуты путем расчета сходства между ними. Этого можно достичь с помощью некоторых мер сходства, таких как косинусное сходство, евклидово расстояние, манхэттенское расстояние и т. д. Обратите внимание, что расчеты сходства могут выполняться с несколькими векторными полями, а результаты в конечном итоге объединяются, а документ может иметь несколько фрагментов. Для сравнения общего балла документа необходимо взвешивать оценки векторного сходства фрагментов.
Векторный поиск имеет следующие преимущества:
- Он может обрабатывать сложные и неоднозначные выражения на естественном языке, такие как синонимы, синонимы, языковые варианты и т. д.
- Он может фиксировать семантические отношения между текстами, такие как гипонимия, причинность, сходство и т. д.
- Он может поддерживать многоязычный и межъязыковый поиск, то есть запрашивать документы на одном языке на другом языке.
- Он может поддерживать мультимодальный и кросс-модальный поиск, то есть использовать текст для запроса документов нетекстового типа, таких как изображения или видео.
Векторный поиск также имеет следующие ограничения:
- Способность векторного поиска понимать естественный язык основана на моделях глубокого обучения.,Вместо индексации векторов и вычислений сходства векторов:
- Для обучения и развертывания моделей глубокого обучения требуется большое количество вычислительных ресурсов и места для хранения данных.
- Для обучения моделей глубокого обучения требуется большой объем аннотированных данных. Если данные низкого качества или не охватывают все возможные сценарии, модель может не обобщаться на новые данные.
- Модели глубокого обучения необходимо регулярно обновлять, чтобы адаптироваться к изменениям в данных и поведении пользователей. Если модель устарела или неточна, это может повлиять на качество результатов поиска и удовлетворенность пользователей.
- Необходимо учитывать размерность и плотность векторов, чтобы выбрать подходящие методы индексации и запроса. Если размерность вектора слишком велика или слишком мала или векторное распределение неравномерно, это может повлиять на эффективность и точность поиска.
- Внедрение и обслуживание векторного поиска требует значительных вычислительных ресурсов и опыта. Для некоторых сценариев применения с ограниченными ресурсами этот вариант может оказаться неприемлемым.
- В сценарии поиска короткого текста векторный поиск может столкнуться с проблемой семантического понимания. Хотя векторный поиск может выполнять семантический анализ запросов, при использовании коротких текстов представление и понимание семантики может быть недостаточно точным, что приводит к плохо релевантным результатам.
- Векторный поиск представляет данные в виде векторных представлений слов, что создает естественные препятствия для людей с точки зрения прозрачности и интерпретируемости поиска. Люди не могут легко понять, почему два векторных представления похожи, а также сложно понять, как изменить функции, чтобы их можно было изменить. Улучшить релевантность;
- Модификация модели внедрения、Тюнинг、переподготовкаДля большинства команд разработчиков порог слишком высок, а рентабельность инвестиций полна неопределенности.。
Одно предложение итог,Просто векторный поиск выглядит хорошо,Но это слишком сложно реализовать,И векторный поиск должен обеспечивать точный поиск.,Также есть требования к пользователям。
Случаи, когда векторный поиск не дает результатов
Как мы упоминали в предыдущей статье Приложение RAG справочной документации Tencent ES в качестве примера. Давайте посмотрим на контрэффекты, которые мы получим в некоторых сценариях, если будем использовать только векторный поиск:
Когда мы знаем, что Tencent Cloud предлагает уникальные экономичные модели,Модель звездного моря,мы хотим знатьTencent Cloud ESВы когда-нибудь использовали эту модель?。но Когда пользователь не хочет вводить длинную строку предложений,Если мы будем искать только «Звездное море», мы увидим, что векторный поиск не может найти правильные результаты:
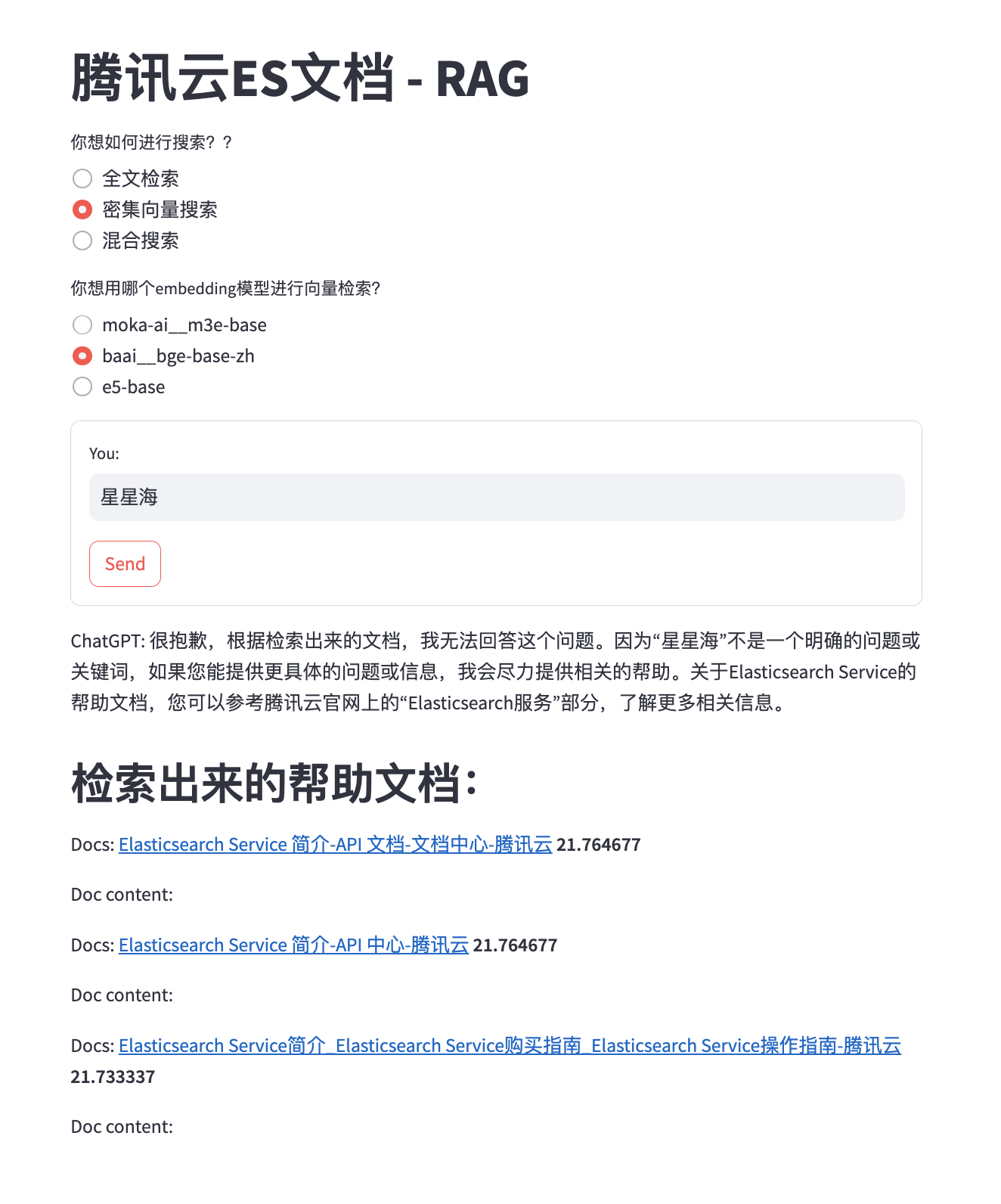
Это связано с тем, что векторный поиск основан на вычислении сходства векторов слов, а векторы слов обучаются с помощью большого количества текстовых данных и часто содержат некоторую семантическую и контекстную информацию. Если оператор запроса слишком короткий, например, содержит только идентификатор, хеш-код или название продукта, то их векторы слов могут не отражать их истинное значение, и они не могут эффективно сопоставляться с другими связанными документами. Это приведет к неточным результатам векторного поиска или даже к совершенно нерелевантному контенту.
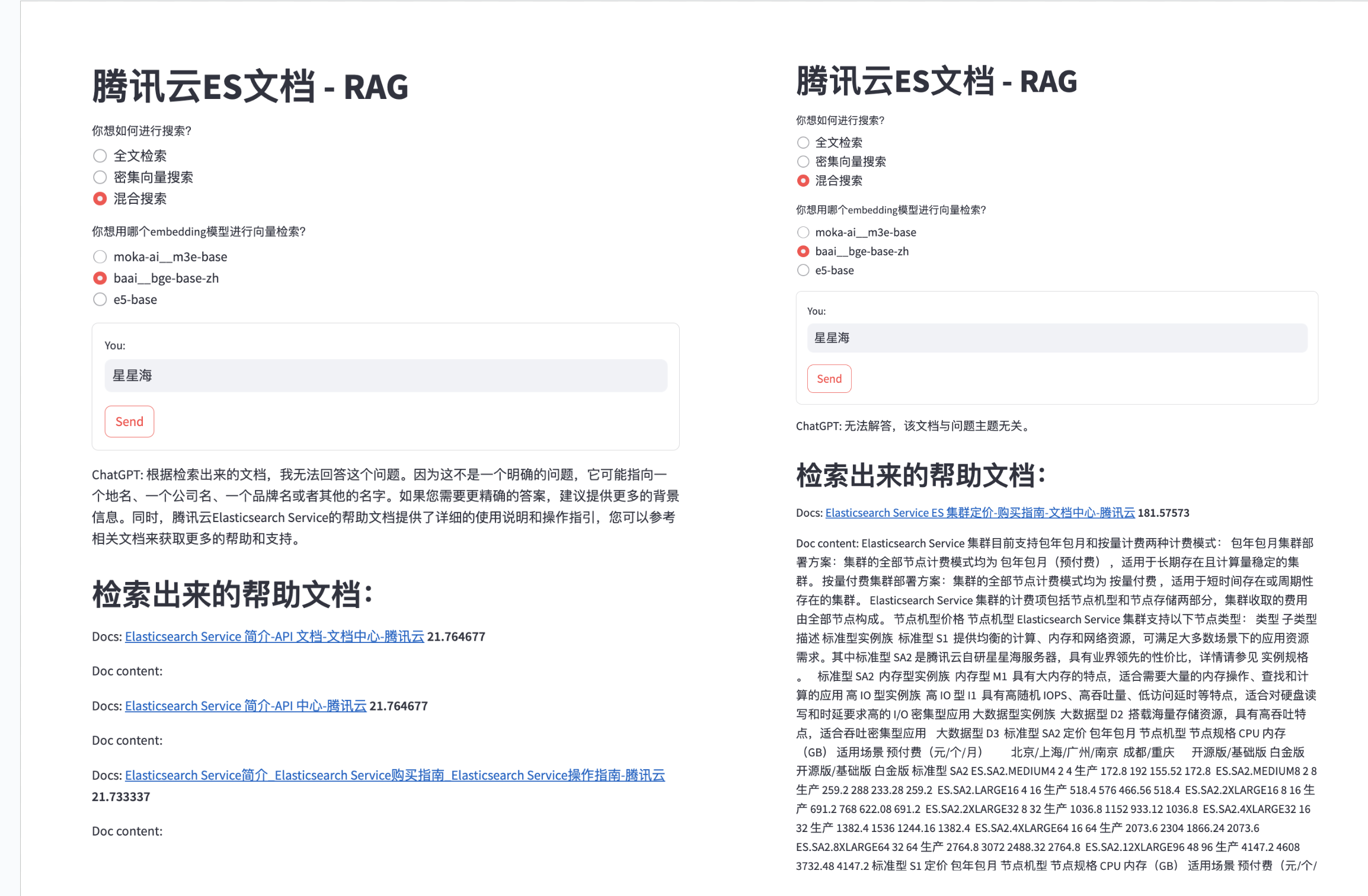
Аналогичным образом, если мы запросим такие ключевые слова, как «8XLARGE64» и «99,9%», векторный поиск выдаст некоторый нерелевантный контент, что сделает стоящую за ним большую модель бесполезной и может даже ввести в заблуждение, и в этом отношении полнотекстовый поиск. легко справится с задачей:

Чтобы решить эту проблему, мы можем использовать некоторые методы, такие как:
- Увеличение длины оператора запроса, например добавление некоторых описательных слов после идентификатора, хэш-кода или названия продукта или использование некоторых общих вопросов в качестве операторов запроса, может увеличить семантическую информацию оператора запроса и улучшить эффект векторного поиска.
- Используйте специальные символы или теги, например двойные кавычки до и после идентификатора, хеш-кода или названия продукта, или используйте определенные имена полей, чтобы сообщить системе векторного поиска, что эти слова должны сопоставляться точно, а не на основе сходства.
- В сочетании с поиском по ключевым словам, например, в результатах векторного поиска, метод поиска по ключевым словам используется для сопоставления и фильтрации текста операторов запроса и документов. Это может исключить некоторый нерелевантный контент и повысить точность поиска.
Эти методы могут в определенной степени улучшить проблему векторного поиска при обработке коротких операторов запроса, но у них также есть некоторые недостатки, такие как:
- Увеличение длины оператора запроса может увеличить затраты пользователя на ввод данных, и пользователь может не знать, как расширить оператор запроса, или расширенный оператор запроса может не соответствовать истинным намерениям пользователя.
- Использование специальных символов или знаков может увеличить затраты пользователей на обучение, и пользователи могут быть незнакомы с использованием этих символов или знаков или забывать их использовать, что приводит к плохим результатам поиска.
- Объединение поиска по ключевым словам может снизить эффективность поиска, а также имеет некоторые ограничения. Например, он не может обрабатывать ситуации, когда семантика аналогична, но текст отличается, или он не может обрабатывать размытость, опечатки и т. д.
поэтому,нам нужен лучший способ,Решить проблему векторного поиска при обработке коротких операторов запроса.,Здесь на помощь приходит гибридный поиск. Гибридный поиск может сочетать в себе преимущества векторного поиска и поиска по ключевым словам.,Добейтесь более быстрых, точных и разнообразных результатов поиска. в следующей части,Мы подробно представим Принципы и преимущества гибридного поиска。
Принципы и преимущества гибридного поиска
Гибридный поиск — это метод поиска, сочетающий в себе векторный поиск и поиск по ключевым словам.,Он может воспользоваться преимуществами эффективности векторного поиска и гибкости поиска по ключевым словам.,выполнить Быстрее、Более точный、Более разнообразные результаты поиска. Принципы и преимущества гибридного поиск следующий:
- Принцип гибридного поиска заключается в том, чтобы сначала использовать двусторонний вызов для получения запроса пользователя. Векторизация и расчет сходства выполняются для операторов запроса и документов соответственно, а также полнотекстовый поиск на основе сегментации слов. Два запроса выполняются параллельно, а возвращенные результаты объединяются и сортируются в соответствии с определенной логикой (например, средневзвешенным значением, объединенной сортировкой и т. д.), и, наконец, получается окончательный набор результатов поиска.
- Преимущества гибридного поиска:,Он может преодолеть ограничения векторного поиска и поиска по ключевым словам.,выполнить Улучшения в следующих аспектах:
- Более точный Результаты поиска для。Гибридный поиск может использовать поиск по ключевым словам и векторный поиск для одновременного запроса данных.,Повысьте точность и надежность поиска。
- Более разнообразные результаты поиска. Гибридный поиск может использовать преимущества разнообразия векторного поиска.,Возвращает различные результаты поиска,Вместо того, чтобы просто возвращать лучший результат соответствия,Это может предоставить больше выбора и информации.,Удовлетворение различных потребностей и предпочтений пользователей в запросах。
- Более сложные требования к запросам。Гибридный поиск может использовать логические операции, сортировку, фильтрацию и другие функции поиска ключевых слов для достижения более сложных запросов.,Например, запросы, содержащие несколько условий, несколько полей, несколько правил сортировки и т. д.,Это улучшает функциональность и гибкость поиска.
- Более интерпретируемые результаты поиска. Гибридный поиск может использовать сопоставление и выделение текста для поиска по ключевым словам.,Добейтесь более интерпретируемых результатов поиска,Например, он отображает степень соответствия, позицию совпадения, соответствие содержимого и т. д. между оператором запроса и документом.,Это может улучшить понимание и удовлетворенность пользователей результатами поиска.
Факторы, которые следует учитывать при реализации гибридного поиска
Чтобы хорошо выполнить работу в гибридном поиске, при оценке проекта необходимо обратить внимание на следующие аспекты:
- Больше системных ресурсов и затрат на проектирование. Гибридный поиск требует использования методов векторного поиска и поиска по ключевым словам, что увеличивает потребление ресурсов и сложность системы, а также стоимость и сложность проектирования и обслуживания системы.
- Некоторые несоответствия и конфликты между векторным поиском и поиском по ключевым словам. Гибридный поиск требует объединения и сортировки результатов векторного поиска и поиска по ключевым словам, что может вызвать некоторые несоответствия и конфликты. Например, результаты, возвращаемые двумя методами поиска, различаются или степень сходства или совпадения двух методов поиска различна. . или правила сортировки двух методов поиска различаются, что может повлиять на качество и достоверность результатов поиска.
- Эффективная фильтрация может сделать поиск более эффективным.
Динамические и гибкие возможности поиска по запросу
Использование Elasticsearch предоставит нашим пользователям большую гибкость. Благодаря единому интерфейсу полнотекстовый поиск, векторный поиск и гибридный поиск можно использовать по требованию в любое время для достижения «оплаты по мере использования». В бессерверной модели динамически предоставляемые вычислительные ресурсы сочетаются с динамическими комбинациями интерфейсов. будет более гибким, контролируя наши расходы.
Например, посредством определения следующей функции мы можем определить, как выполнять поиск на основе динамических условий в любое время, не внося изменений в код:
# Search ElasticSearch index and return body and URL of the result
def search(es, embedding_model, query_text, search_mode):
source_fields = ["body_content", "url", "title"]
query = None
knn = []
highlight = None
rank = None
if search_mode in ["Полнотекстовый поиск", "Гибридный поиск"]:
query = {
"multi_match": {
"query": query_text,
"fields": ["body_content^2","title","headings"],
"boost": 1,
"type": "most_fields",
"analyzer": "ik_max_word"
}
}
if search_mode in ["Плотный векторный поиск", «Смешанный поиск»]:
knn = [{
"field": "ml.inference.headings_embeddings.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": embedding_model,
"model_text": query_text
}
},
"k": 5,
"num_candidates": 10,
"boost": 24
}, {
"field": "ml.inference.body_content_embeddings.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": embedding_model,
"model_text": query_text
}
},
"k": 5,
"num_candidates": 10,
"boost": 24
},
]
if search_mode == «Полнотекстовый поиск»:
highlight= {
"pre_tags": ["`"],
"post_tags": ["`"],
"fields": {
"body_content": {}
}
}
if search_mode == «Смешанный поиск»:
rank = {
"rrf":{
"window_size": 5,
"rank_constant": 2
}
}
resp = es.search(
index="search-tencent-es-doc",
fields=source_fields,
query=query,
knn=knn,
highlight = highlight,
rank = rank,
size=3,
source=False)
return resp
Эффективно комбинируйте и сортируйте результаты многосторонних отзывов.
Когда результаты векторного поиска и поиска по ключевым словам противоречивы и противоречивы,,Elasticsearch также предоставляет множество методов, упрощающих отладку результатов. в настоящий момент,elasticsearchОбеспечивает, например.:Линейная взвешенная сумма и объединенный ранжирование на основе обратного результата.(RRF)два пути。этотдва пути Все можно легко изменить в функции,Как в примере кода, приведенном выше:
- линейно-взвешенная сумма:query:
"boost":1; knn:"boost": 24
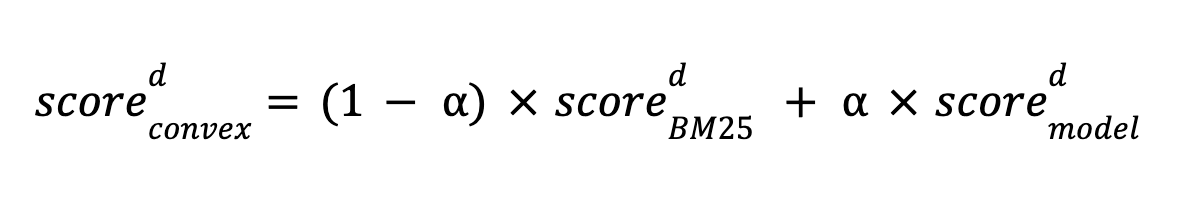
- RRF:
rank ={"rrf":{"window_size":5,"rank_constant":2}}
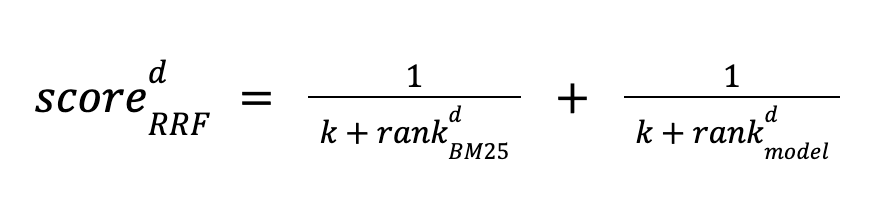
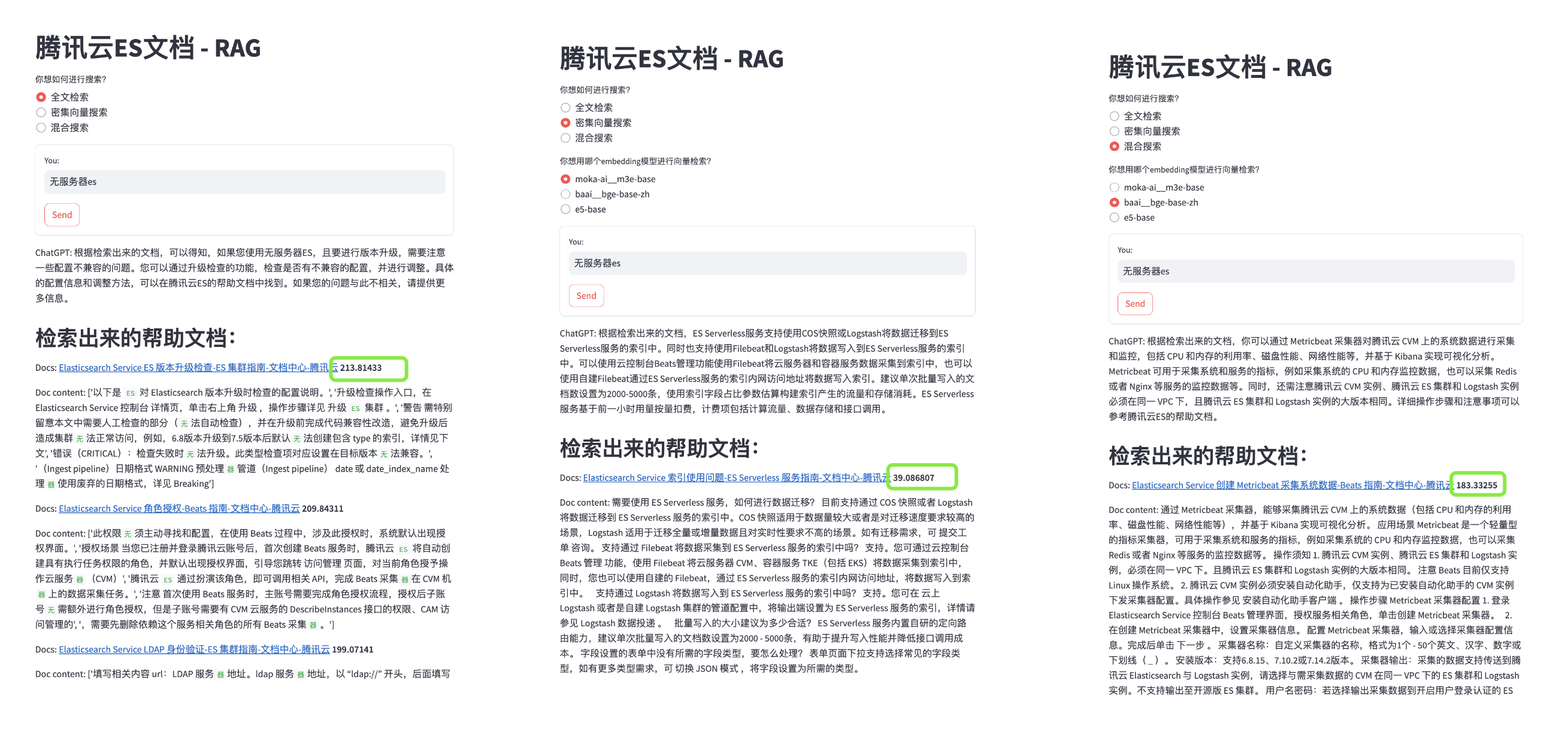
Когда мы обнаруживаем, что результаты полнотекстового поиска более важны во время использования,Мы можем настроить параметры соответствующим образом,Ниже приводитсяquery:"boost":1
иquery:"boost":24Разница:
Конечно, корректировка посредством взвешенной оценки не является панацеей. Часто из-за разных методов оценки релевантности разные методы поиска дают очень разные оценки релевантности. Единому весу трудно справиться с различными сценариями, потому что вес полнотекстового поиска увеличивается, что делает для нас это невозможным. ответить на вопросы, связанные с семантическим поиском. Вопрос:
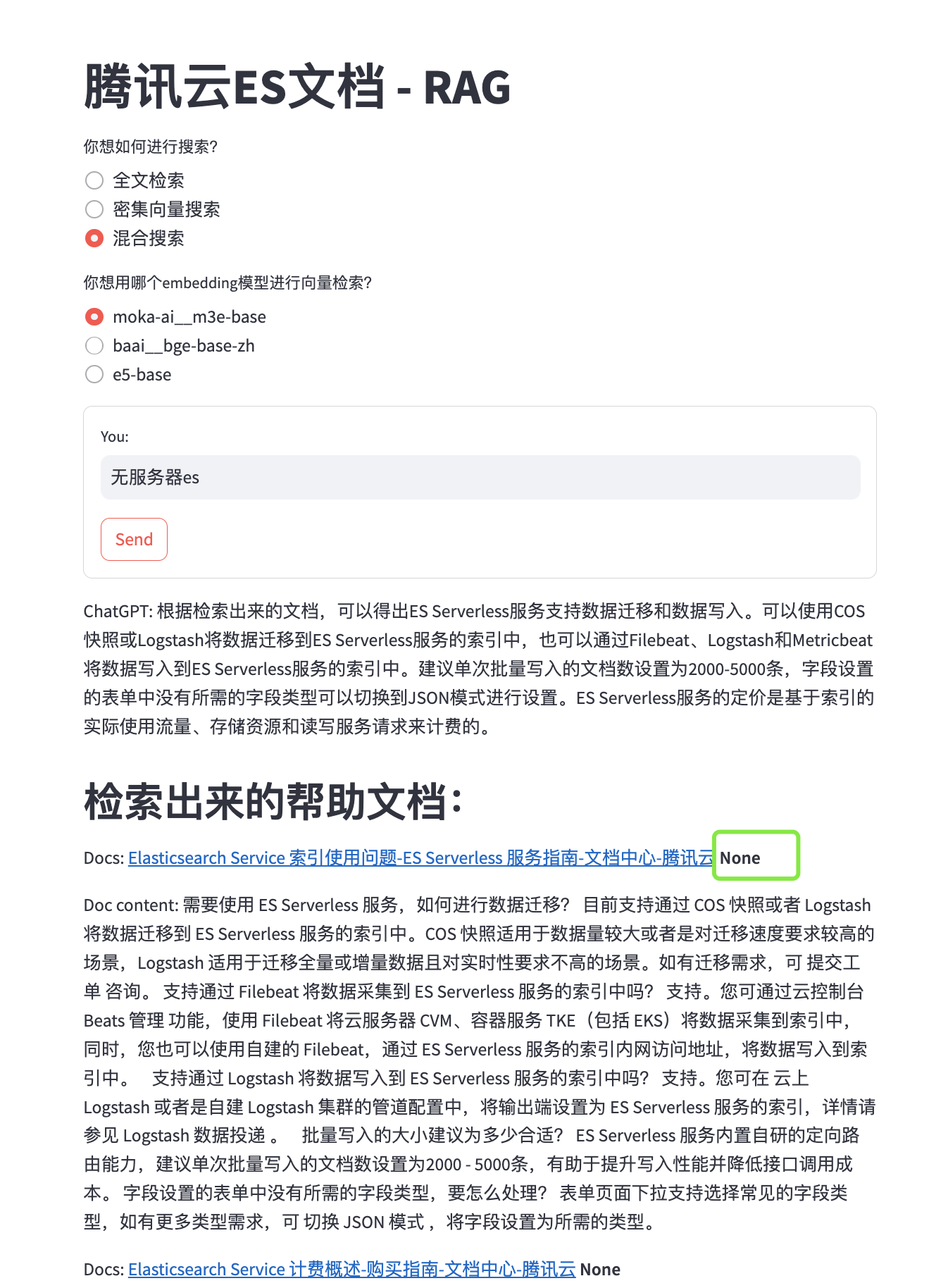
Поэтому мы также предоставляем возможность эффективно объединять и ранжировать результаты без необходимости оценивать их по релевантности. —— RRF。
После использования RRF результаты больше не содержат оценок релевантности, а объединяются на основе ранжирования документов при многостороннем отзыве:
Фильтровать условия поиска
Помимо сортировки, фильтрация также является очень важной возможностью в гибридном поиске или векторном поиске. Исключение некоторых документов, которые не соответствуют условиям, может не только сделать наши запросы более эффективными, но и сделать конечные результаты более точными. и Elasticsearch По сравнению с другими базами данных,Легче добиться этого,Конкретные причины см.《Векторный поиск в Elasticsearch: обоснование конструкции》одно предложение。
Например, определив фильтр непустой строки (здесь следует отметить, что Elasticsearch Функция корпоративного поиска создает различные типы полей, необходимые для настройки каждого важного поля при создании индекса, что позволяет нам фильтровать его, например, здесь body_content.enum,Он автоматически создается приложением. keyword тип):
body_content_filter = {
"bool": {
"must": [],
"filter": [],
"should": [],
"must_not": [
{
"bool": {
"minimum_should_match": 1,
"should": [
{
"match_phrase": {
"body_content.enum": ""
}
}
]
}
}
]
}
}Мы можем искать в векторе необычные документы, которые могут совпадать(Такие как здесьbody_contentДокументы, представляющие собой пустые строки)отфильтровать:
if search_mode in ["Плотный векторный поиск", «Смешанный поиск»]:
knn = [{
"field": "ml.inference.headings_embeddings.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": embedding_model,
"model_text": query_text
}
},
"k": 5,
"num_candidates": 10,
"boost": 24,
"filter": body_content_filter
}, {
"field": "ml.inference.body_content_embeddings.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": embedding_model,
"model_text": query_text
}
},
"k": 5,
"num_candidates": 10,
"boost": 24,
"filter": body_content_filter
},
]
Подвести итог
Создать приложение RAG относительно легко, если у вас есть законченное решение. Однако актуальность отладки и поиска требует большего опыта и возможностей в области поиска. К счастью, Elasticsearch по-прежнему находится на переднем крае в этом отношении, предоставляя наиболее полные и богатые возможности настройки запросов и сортировки, а также широко доступную поддержку сообщества, даже генерацию больших моделей на общедоступных данных. Сосредоточившись на изучении возможностей Elasticsearch, мы можем легко получить помощь по различным каналам для настройки запросов. Это имеет решающее значение для выбора технологии и успеха или провала конечного проекта.
Иногда правильный выбор перевешивает усилия.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
