[Камень из других гор] Стабильная диффузия Длинная статья в 10 000 слов подробно объясняет модель стабильной диффузии.
1. Stable Diffusion Введение в модель устойчивой диффузии
Стабильная диффузия — самый продвинутый режим в модели диффузии диффузии (у диффузии есть несколько ранних версий, таких как: оригинальная диффузия, латентная диффузия). Он использует более стабильный, управляемый и эффективный метод создания высококачественных изображений. Произошло значительное улучшение качества, скорости и стоимости создания изображений, поэтому эта модель может напрямую генерировать изображения на видеокартах потребительского уровня размером не менее 512*512 пикселей. Последняя версия XL может генерировать управляемые изображения на уровне 1024*1024 пикселей, а эффективность генерации в 30 раз выше, чем у предыдущей модели Diffusion Diffusion. В настоящее время применение Stable Diffusion не ограничивается областью генерации изображений. Оно также широко используется в обработке естественного языка, аудио и видео и других областях генерации.
1.1 История развития устойчивой диффузии
Стабильная диффузия. Эта модель архитектуры была создана и запущена исследователями из CompVis, Stability AI и LAION в августе 2022 года на основе модели скрытой диффузии. Его основная технология основана на модели скрытой диффузии (Latent Diffusion Model), совместно опубликованной двумя разработчиками: Патриком Эссером, главным научным сотрудником Runway, стартапа в области технологий редактирования видео с использованием искусственного интеллекта, и Робином Ромбахом из группы машинного зрения Мюнхенского университета. на конференции по компьютерному зрению CVPR22) (документ: https://arxiv.org/abs/2112.10752).

Патрик Эссер (слева), Робин Ромбах (справа)
Однако модель скрытой диффузии представляет собой революционную модернизацию исходной модели диффузии, предложенной еще в 2015 году. Вы можете узнать больше об исходной структуре модели диффузии в этой статье «Модель диффузии диффузии».
Хотя в последнее время было широко распространено, что стабильная диффузия на самом деле скопировала код скрытой диффузии Runway, а глава Stability AI Эмад Мостак был разоблачен Forbes и заявил, что он фальсифицировал свою академическую квалификацию и другие скандалы, это не замедлило вниз по продолжающейся популярности стабильного распространения вообще, и продолжать получать большие объемы финансирования.

Эмад Мостак, владелец Stability AI
Что касается того, действительно ли Стабильная диффузия является плагиатом Латентной диффузии, однозначного вывода пока нет, но неоспоримым фактом является то, что Стабильная диффузия не достигает большого прогресса по сравнению с Латентной диффузией. Можно сказать, что она в основном сосредоточена на значительном улучшении вычислительной мощности. база и обучение сильно увеличиваются, качество данных сильно улучшается и достигаются другие "большие чудеса", а не существенный апгрейд архитектуры.
Однако до сих пор используемый нами веб-интерфейс Stable Diffuse по-прежнему основан на архитектуре Stable Diffuse, выпущенной Stability AI. Поэтому давайте для объяснения все же будем использовать название «Стабильная диффузия».
1.2 Важность «маленького скрытого пространства»!
По сравнению со скрытой диффузией, стабильная диффузия имеет следующие основные улучшения:
- тренироватьсяданные:Latent Diffusion принят Laion-400M данныетренироватьсяиз,и Stable Diffusion дасуществовать Лайон-2Б-енданные проходили обучение на съемочной площадке. «2Б-эн» — это 20 Смысл миллиардов изображений и текста сравнения на английском языке, если быть точным, включает в себя 23.2 Миллиарды. Очевидно, что последний использует больше обучающих данных, а второй также использует проверку данных для улучшения качества выборочных данных. сейчас принят Лайон-Эстетик, 120M Подмножество обучения для выбора изображений с более высокими эстетическими оценками для задачи по рисованию в Винсенте.
- Text Encoder:Latent Diffusion Используйте случайно инициализированный Transformer кодировать текст(это Transformer то есть GPT Тот, который использовался Трансформатор, последняя буква «Т» в «GPT», я написал отдельную статью, чтобы подробно представить ее: «Что такое «GPT» и как следует переводить три буквы! 》). и Stable Diffusion Используйте предварительно обученный Clip text encoder кодировать текст, предварительно обученный text model Зачастую это лучше, чем обучение с нуля из Модели.
- Размер тренировки: Latent Diffusion дасуществовать 256x256 обучение набору данных разрешения, в то время как Stable Diffusion да Сначала существовало предварительное обучение с разрешением 256x256, а затем существовало 512x512 Тонкая настройка и оптимизация разрешения, сейчас существуют XL версия использует Laion-High-Resolution обучающий набор размером 170M, разрешение изображения больше, чем 1024 Подмножество тренировок высокого разрешения для задач сверхвысокого разрешения.
Видно, что улучшение действительно не особенно большое. Одно из наиболее важных ядер, «Скрытое», не было изменено и до сих пор используется в Stable Diffusion. Так что же означает «Скрытое»? Можно сказать, что Latent Diffusion является создателем Stable Diffusion, поскольку он впервые применяет метод эффективной обработки данных в «небольшом скрытом пространстве» и решает проблему неэффективности исходной модели Diffusion. Его внутренняя сеть U-Net работает в низком измерении «скрытого пространства», что значительно снижает потребление памяти и сложность вычислений. Например, для фотоизображения размером 512*512 пикселей данные выражаются как (3512512), то есть размер данных изображения трех каналов RGB*512*512 пикселей, а объем данных превышает 786432. В скрытом пространстве он будет сжат в (4,64,64), объем данных составит 16384, а потребление памяти уменьшится до 1/64 от исходного. Это приносит большую эффективность и популярность эксплуатации модели. Стабильная диффузия естественным образом наследует это основное преимущество скрытой диффузии. (Подробное объяснение понятия «маленькое скрытое пространство» можно найти в этой статье: «Что такое «скрытое пространство»?»)
Далее мы частично обратимся к статьям нескольких технических экспертов по стабильной диффузии, особенно к очень краткой топологической диаграмме, предоставленной Джеем Аламмаром в его блоге для деконструкции стабильной диффузии.

Блог-аккаунт Джея Аламмара
2. Подробная структура модели устойчивой диффузии стабильной диффузии.
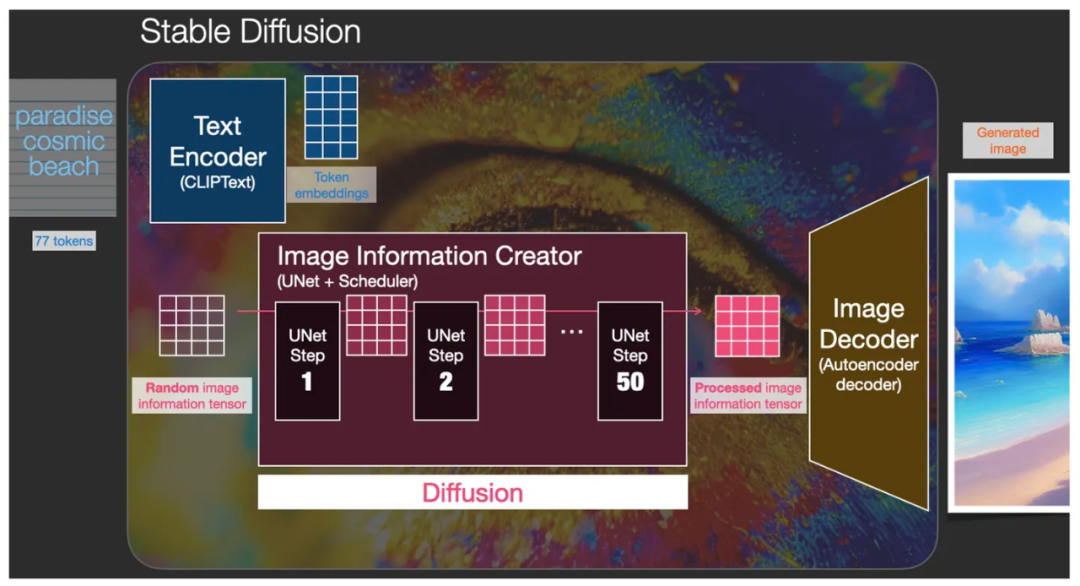
Стабильная диффузия Модель стабильной диффузии может применяться во многих областях, но в области проектирования AIGC мы фокусируемся только на двух ее основных аспектах:
Первый — text2img. На изображении ниже показан набор текста и соответствующие сгенерированные изображения. Этот набор текста представляет собой слово-подсказку: райский космический пляж.

Быстрое слово «райский космический пляж» генерирует соответствующее изображение с помощью модели стабильной диффузии.
Второе – изменить картинку. Очевидно, что для изменения изображения необходимо ввести изображение и слово-подсказку, используемое для изменения изображения. Соответствующий пример — создание измененного изображения путем добавления слова-подсказки: Пиратский корабль к исходному изображению.

Добавьте слово-подсказку «Пиратский корабль» к исходному изображению, чтобы создать измененное изображение.
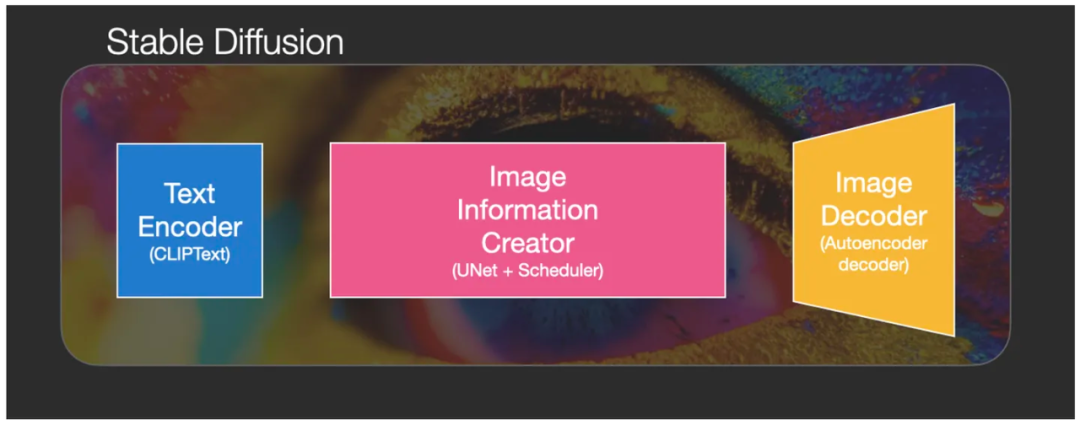
Фактически, Stable Diffusion сама по себе является не моделью, а системной архитектурой, состоящей из нескольких модулей и моделей. Каждый компонент представляет собой систему нейронных сетей, также известную как три базовые модели:
1. CLIPText используется для кодирования текста и его оцифровки:
- Ввод: текст входить (слово-подсказка). Prompt);
- Output:77 token embeddings векторы, каждый token Вектор имеет 768 размеры;
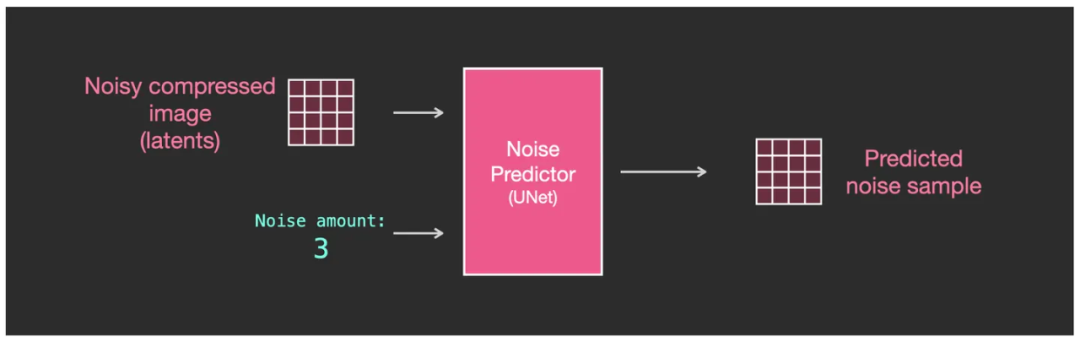
2. U-Net + Scheduler используется для постепенной обработки/распространения информации, преобразованной в скрытое пространство:
- Входные данные: встраивание текста и состоит из шума начальной многомерной матрица (структурированного списка чисел, также называемого тензором). Tensor);
- Выход: обработанная информационная матрица;
3. AutoEncoder Decoder (в основном VAE: вариационный AutoEncoder) использует декодирование обработанной информации матрицы для рисования окончательного изображения.,Декодируйте скрытое пространство результата операции в реальный размер изображения:
- Вход: обработанная информационная матрица, размерность: 4, 64, 64;
- Выход: сгенерированное изображение, размерность: 3, 512, 512 Прямо сейчас Три канала RGB и двумерный размер пикселя.
2.1 Кодировщик текста CLIPText
Во-первых, давайте взглянем на CLIPText, который представляет собой компонент распознавания текста кодировщика коннотаций (синий модуль на изображении устройства распознавания текста), который преобразует текстовую информацию в числовую информацию, чтобы машина могла понять семантику текста подсказки. .

Компонент понимания текста Text Doesnter (синий модуль) по сути является кодировщиком Encoder.
По технической структуре этот компонент понимания текста можно понимать как кодировщик текста (Encoder), который представляет собой специальный Transformer Языковая модель (технический термин: CLIP модель Text Encoder текстовый кодер). Это исходящий текст, на выходе получается числовое выражение изматрицы, Прямой сейчасиспользовать Embedding способ выразить каждый текст в виде последовательности слов-подсказок жетон, каждый token Соответствует группе Embedding вектор, серия token собрать вместе, чтобы сформировать Embedding матрица, синяя сетка на рисунке ниже представляет эту «матрицу»).
(Токен означает словесный элемент, который является наименьшей семантической единицей. Обычно каждый токен соответствует вектору. Дополнительную информацию о токенах можно найти в этой статье: «Что означает «токен» в области машинного обучения?». Встраивание — это пара Дальнейшее кодирование токена, обычно набор векторов).

Text Encoder преобразует слова подсказки в матрицу внедрения
Затем эта информация вводится в генератор изображений (розовый и желтый модуль на схеме генератора изображений), состоящий из нескольких модулей.
Этот генератор изображений дополнительно разбит на следующие части:
2.2 Создатель информации об изображении Создатель информации об изображении
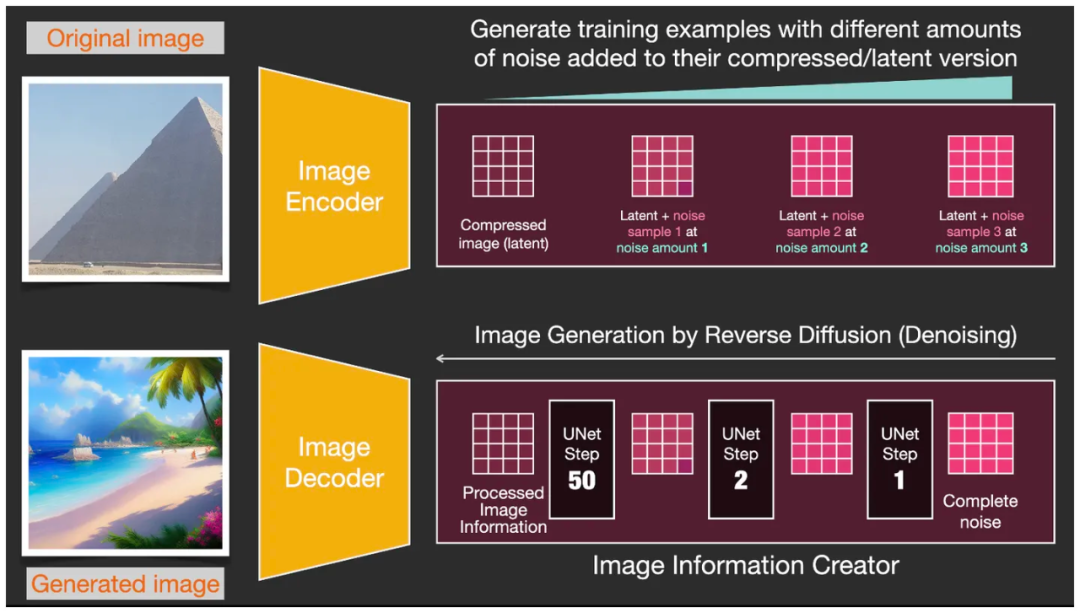
Этот модуль является основным оружием архитектуры стабильной диффузии Stable Diffusion, и именно здесь он может добиться большего улучшения производительности, чем предыдущие версии Diffusion. Этот компонент итеративно выполняет несколько шагов (шагов) для создания информации об изображении. Значение «Шаги» по умолчанию обычно равно 50 или 100. Создатель информации изображения работает полностью в «скрытом пространстве», что делает его в 64 раза более эффективным, чем ранее работавший в пространстве пикселей. Технически этот компонент состоит из нейронной сети U-Net и алгоритма планирования. В этом компоненте создания информации изображения способ работы с информацией представляет собой итеративный процесс послойной обработки. После обработки данные передаются в следующий модуль — Image Decoder (Декодер изображений) для формирования итогового изображения.
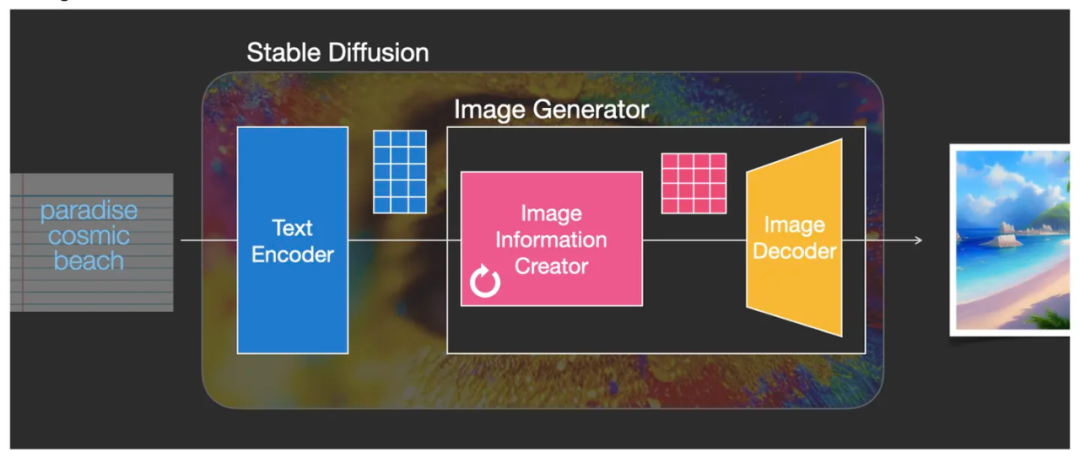
Генератор изображений в создателе информации об изображении обрабатывает данные для создания изображения, а затем выводит их в декодер изображений для создания окончательного изображения.
2.3 Декодер изображений Декодер изображений
декодер изображений, на самом деле AutoEncoder Decoder Автоэнкодер(В основном VAE: вариационный AutoEncoder ), который рисует изображение на основе информации, переданной от создателя информации об изображении. это было только в предыдущем Diffusion Запускайте его только один раз после полного завершения процесса. Прямо Сейчас декодирует скрытое пространство серединаиз информации изображения для создания окончательного пиксельного изображения. (К «Небольшому пространство Latent Друзья, которые не приписывают «Космосу», могут обратиться к этой статье, чтобы узнать о нем больше: «Что такое «Скрытый»? Space «Скрытое пространство»?》)
AutoEncoder Decoder (желтый модуль) отвечает за декодирование информации изображения в скрытом пространстве в реальное пиксельное изображение.
Подводя итог вышеизложенному, можно выделить три основных компонента, составляющих Stable Diffusion: CLIPText используется для кодирования текста (Text Encoder), U-Net используется для обработки информации изображения в скрытом пространстве (фактически запущенный процесс Diffusion) и AutoEncoder Decoder используется для автоматических кодировщиков. Обработанная информация декодируется для рисования окончательного изображения.

Три основных компонента: CLIPText, U-Net, AutoEncoder Decoder
Чтобы продолжить дальнейшую деконструкцию, мы должны сначала детально разобраться в том, как работает «Диффузия»?
3. Как работает «Диффузия»?
Фактически, то, что мы часто называем «Распространением Процесс «диффузии» не Diffusion модель — это графический процесс, и это обратный процесс, Прямо сейчас процесс встречной диффузии,Процесс создания картины – настоящий процесс,Это будет подробно объяснено ниже.
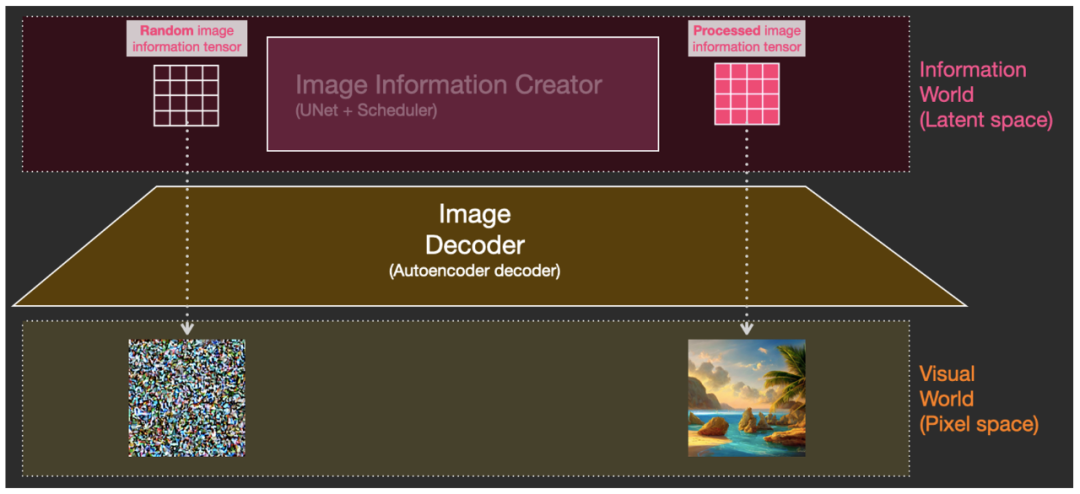
Процесс создания картины происходит на картине середина розовая из части, Прямо. сейчас Создатель информации об изображении(Image Information Создатель) компонент. Эта часть содержит два входа одновременно, см. рисунок ниже: ① Из кодировщика текста ( модель CLIPText) вывод Token embeddings матрица (изображение середина синей сетки), и② Случайное из информации об изображении инициализации матрица, Прямой сейчас карта скрытого пространства из шума (картинка серединапрозрачная сетка), затем Создатель информации об изображении(Image Information Creator) выводит обработанную информационную матрицу скрытого космического изображения (розовая сетка на изображении) после обработки и, наконец, передает декодеру изображения для рисования изображения.

① Ввод матрицы встраивания токенов, ② случайно инициализированный ввод матрицы информации об изображении, а выход ③ обработанная матрица информации о скрытом пространстве
Ввод ① ②, а затем вывод ③. Эти шаги не выполняются за один раз, а процесс, который повторяется много раз. Каждая итерация удаляет некоторый шум и добавляет дополнительную информацию, связанную с целевым изображением. Это обратный процесс отображения «Диффузии».
Что именно означает этот шум, будет подробно объяснено позже. Короче говоря, нужно просто помнить: «Распространение «Диффузия» — процесс обратного отображения, то есть есть, полностью удалит шум из изображения, удалит точки шума слой за слоем и, наконец, сгенерирует изображение из процесса. сейчас Может。
Во время фактического процесса запуска модели вы можете добавить контрольную точку после каждого шага итерации, чтобы увидеть эффект постепенного удаления шума на изображении. Когда мы используем программное обеспечение Stable Diffusion WebUI, мы видим, что изображение промежуточного шага будет генерироваться в окне предварительного просмотра каждый раз. Это изображение постепенно становится четким из-за размытия, которое получается на разных этапах, заданных этими контрольными точками. .
Во время запуска модели можно вставлять контрольные точки для отслеживания состояния изображения после каждого шага итерации.
Когда происходит обратный процесс генерации изображения «Диффузионная диффузия», на каждом шаге итерации вводится матрица шума прогнозирования U-Net, а матрица шума прогнозирования вычитается из изображения, содержащего шум на предыдущем этапе, для получения «ближе к результату». Снимки с меньшим шумом. После 50 или 100 итераций наконец генерируется результат и из матрицы скрытого пространства декодируется изображение без шума.
Так называемое «ближе к результату» означает, что это изображение ближе к выражению в скрытом пространстве всех изображений, извлеченных из предварительно обученной большой модели и семантически связанных с входным текстом.
Это определенно до сих пор вызывает у людей чувство замешательства. Основная причина в том, что процесс постепенного удаления шумовых точек сложно объяснить в одном или двух предложениях. Далее мы подробно остановимся на этой части.
Процесс обратного отображения «Диффузии» более подробно объясняется ниже:
На картинке ниже мы видим,CLIP Матрица семантики текста (синяя сетка на рисунке) и Diffusion в диффузионной модели U-Net Матрица шума прогнозирования каждого модуля определяется выражением Diffusion Многократный итерационный процесс обеспечивает возможность непрерывной калибровки информации об изображении.
Внутри модуля Image Information Creator находится итеративная последовательная комбинация модулей, состоящая как минимум из 50 U-сетей.
Как только что упоминалось, мы можем разместить контрольную точку после определенного шага итерации, чтобы проверить работу этих матриц и увидеть, насколько далеко продвинулся процесс уменьшения точек шума. Например, если вы проверите шаги 1, 2, 4, 5, 10, 30 и 50, вы обнаружите, что это выглядит так, как показано на рисунке ниже.
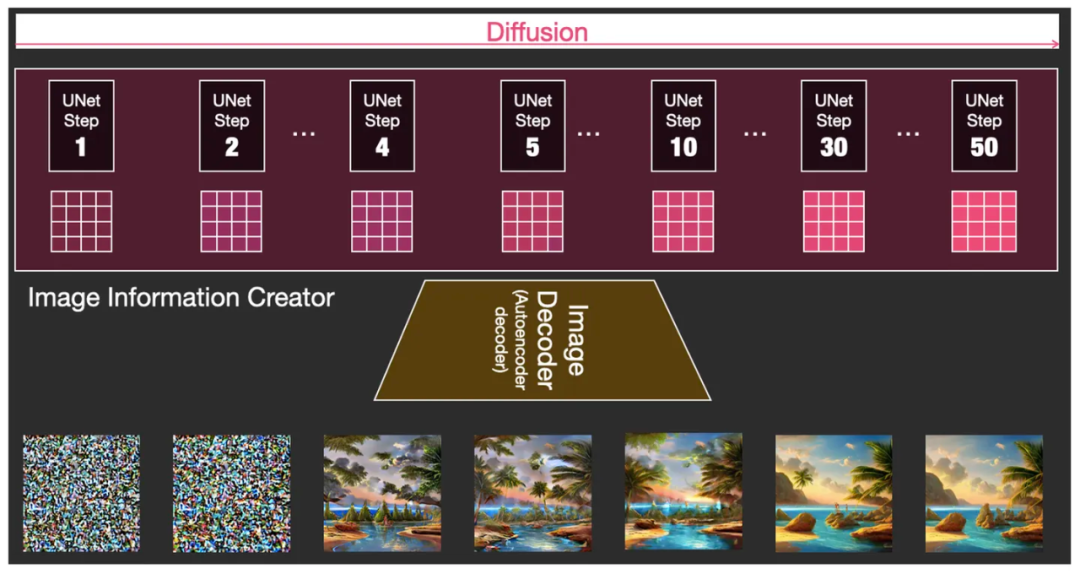
Делайте 1, 2, 4, 5, 10, 30, 50 шагов и ставьте контрольные точки через 50 шагов, чтобы увидеть эффект во время работы.
Это Diffusion Процесс генерации обратного графа (Reverse Diffusion Процесс) (подробную техническую интерпретацию этого процесса см.: «Диффузия Диффузионная модель》) . и Diffusion исходящий процессто естьмодельпредварительнотренироватьсяпроцесс,Постоянно добавляя точки шума, мы тренируем способность Модели прогнозировать точки шума на каждом этапе.,Чтобы обеспечить возможности калибровки шума для каждой итерации этапа удаления шума для будущего обратного процесса.
3.1 Последующий процесс диффузии (процесс обучения)
Давайте посмотрим, что именно происходит на переднем (тренировочном) этапе.
Как упоминалось ранее, наиболее важной частью модели диффузии для генерации изображений (обратный процесс) является то, что у нас заранее есть мощная модель U-Net. Процесс предварительного обучения этой модели можно кратко описать как следующие шаги.
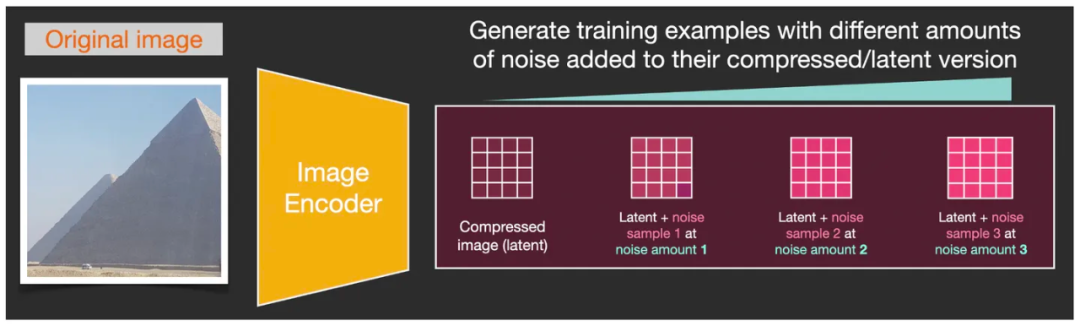
Предположим, у нас есть фотография (1 на рисунке ниже) и мы генерируем некоторый дополнительный случайный шум (2 на рисунке ниже), затем выбираем один из уровней интенсивности среди нескольких интенсивностей шума (3 на рисунке ниже), а затем преобразуем этот Шум определенного уровня интенсивности добавляется к изображению (4 на изображении ниже). Таким образом, мы завершили типичное типовое обучение. (Обратите внимание, что шум не добавляется непосредственно к изображению в пиксельном измерении, а добавляется в матрицу данных скрытого пространства изображения в скрытом пространстве. Карта шума здесь предназначена только для удобства понимания.)

Типичный пример процесса обучения U-Net
Однако одного обучения на одном изображении недостаточно. Нам нужно много-много таких изображений для нескольких тренировок. На рисунке ниже показано второе обучение с использованием другого образца изображения. Другая фотография, которая отличается от первого обучающего изображения (1 на изображении ниже), и генерируются некоторые случайные точки шума (2 на изображении ниже), а затем один уровень интенсивности выбирается среди нескольких уровней интенсивности шума (3 на изображении ниже) обратите внимание, что уровни интенсивности шума, выбранные во второй раз и в первый раз, различаются (это означает, что интенсивность шума, используемая для каждого обучающего изображения, является случайной, но эта случайная интенсивность записывается). Затем к изображению добавляется этот конкретный уровень интенсивности шума (4 на изображении ниже). Таким образом, мы завершили второй типичный образец обучения.

Еще один типичный пример процесса обучения U-Net.
Конечно, вышеизложенное просто упрощает интенсивность шума до 4 уровней (0, 1, 2, 3 на картинке, четыре шестерни уровня шума) для облегчения понимания. В реальном процессе обучения мы можем разделить шум на десятки уровней интенсивности, чтобы мы могли тренироваться десятки раз с разной интенсивностью шума для одного изображения, а затем выполнять одно и то же обучение на разных изображениях. Наконец, эти изображения и обучающие выборки шума на разных этапах объединяются в огромный набор обучающих данных.
Набор входных данных представляет собой большое количество изображений с разными уровнями интенсивности шума, а набор выходных данных (результаты аннотаций меток) представляет собой большое количество различных изображений с чистым шумом. Затем введите его в модель U-Net в Diffusion для обучения с учителем (обучение с учителем можно изучить в этой статье: «Обучение с учителем, обучение без учителя, обучение с полуконтролем, обучение с подкреплением, обучение с самоконтролем»), чтобы завершить U- Обучение сетевой модели.
Насколько такой набор данных изображений необходим для базового обучения большой модели Stable Diffusion? Как упоминалось ранее, существует 2,3 миллиарда пар изображение-текст!

Набор входных данных представляет собой большое количество изображений с разными уровнями интенсивности шума, а набор выходных данных (результаты аннотаций меток) представляет собой большое количество различных изображений с чистым шумом для обучения U-Net (обучение с учителем).
Чтобы обучение этого набора данных было успешным, его размер должен быть очень большим, чтобы он мог соответствовать нашим различным требованиям к созданию диффузионного графа. Для базовой большой модели Stable Diffusion версия модели V1.5 была обучена на сотнях графических процессоров Nvidia A100 с использованием 2,3 миллиарда изображений. Эти изображения в основном имеют разрешение 512 * 512 пикселей, что отнимает много времени. на обучение ушли сотни тысяч часов графического процессора.
В последней версии XL используется в несколько раз больше образцов изображений, чем в версии 1.5, и разрешение каждого изображения составляет 1024*1024. В масштабе от миллиардов до десятков миллиардов такой огромный объем обучения означает, что Stable Diffusion прочитал и запомнил самый большой объем данных изображений, накопленных человеческой цивилизацией на сегодняшний день, и каждое изображение снабжено текстовыми пояснениями. Итак, это основная причина, по которой Stable Diffusion может импрессионистически создавать любое изображение, которое вы захотите.
Мощный предсказатель шума U-Net, обученный на таком огромном наборе данных, обладает «способностью» постепенно и итеративно уменьшать шум карты шума до идеального изображения во время обратного процесса генерации изображения Diffusion.
Далее дорабатываем процесс обучения деконструкции U-Net:
На рисунке ниже первым шагом является выбор обучающей выборки из огромного набора данных, обычно выборки изображения с определенным уровнем интенсивности шума. ②Второй шаг — спрогнозировать точку шума и уровень шума с помощью U-Net. ③Третий шаг — сравнить его с шумом на реальном изображении. ④Четвертый шаг — передать в U-Net разницу сравнения шума на третьем этапе. Это позволяет U-Net корректировать параметры для улучшения возможностей прогнозирования. Это типичный процесс «контролируемого обучения»!
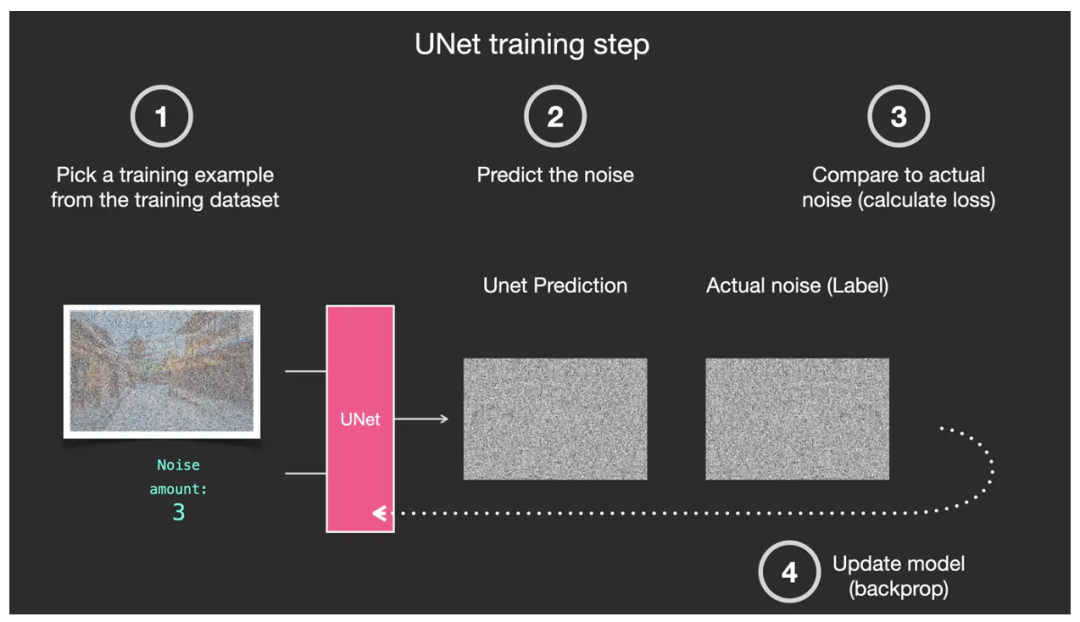
Типичный контролируемый процесс обучения U-Net – прогнозирование шума на изображениях
Давайте посмотрим, что именно происходит в обратном процессе диффузии (процесса генерации изображения).
3.2 Обратный процесс диффузии (процесс генерации)
обратный процесс есть через полный шум из скрытого космического изображения,Итеративно удаляйте шум шаг за шагом для создания изображений。Обученный предсказатель шума U-Net Может предсказать шум и уровень интенсивности этого шума (Шум сумма), то это U-Net Он имеет возможность удалять эти шумовые точки для генерации результатов каждой итерации. сейчас содержит меньше шума на изображении, непосредственно к окончательному генерированию содержит шум из идеального изображения.
U-Net, обученная на больших наборах данных, может прогнозировать шум и его интенсивность, а также удалять шум.
Чтобы объяснить этот процесс более подробно:
Мы используем максимальный уровень шума (Количество шума = 3) в упрощенном примере, приведенном выше, в качестве первого шага. Затем введите полную карту шума в это время (нижний объем на рисунке ниже — это полная карта шума), U-Net может предоставить шум и уровень шума (шум обведен красным кружком на рисунке ниже) и извлечь Шум из входной карты шума Удалите эту часть шума и превратите ее в изображение с меньшим шумом (крайнее левое изображение со слегка шумом на рисунке ниже).
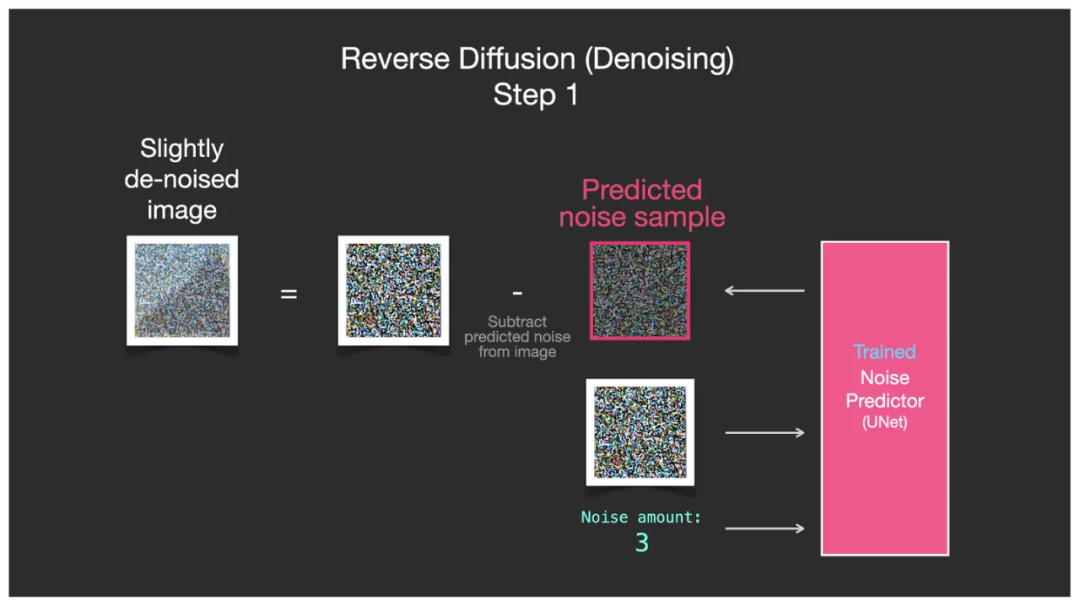
Одноэтапный процесс шумоподавления U-Net
Затем повторите этот процесс, каждый раз удаляя один уровень шума, и изображение с полным шумом будет очищено от шума слой за слоем, чтобы стать изображением без шума, содержащим только содержимое изображения. (В реальном процессе невозможно иметь только четыре итерации, как показано на упрощенных блок-схемах, а может быть не менее 50 и не более 100 шагов.)
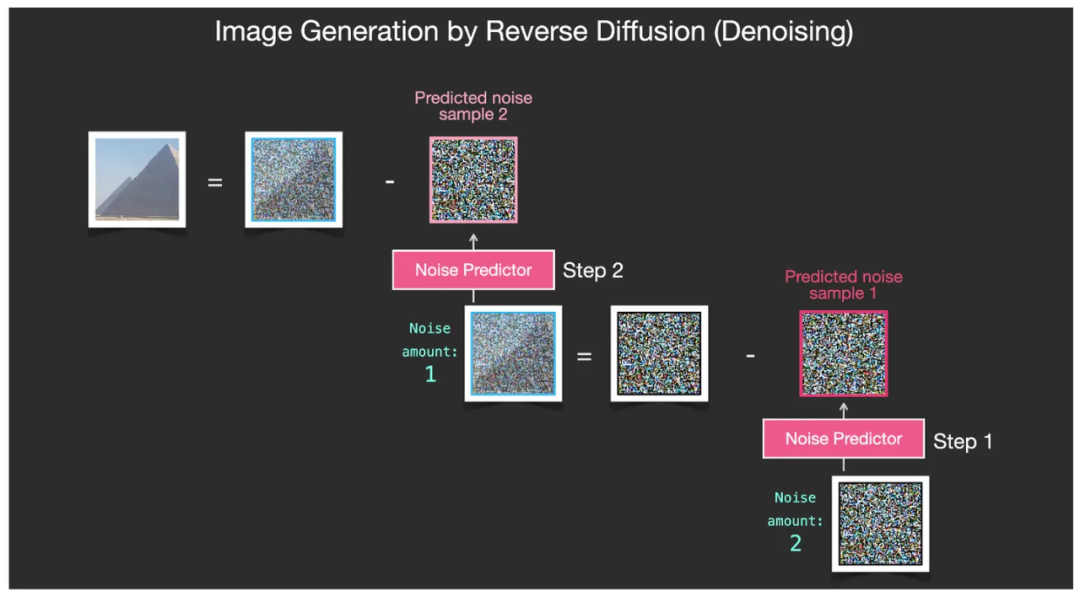
Остальные этапы удаления шума выполняются шаг за шагом, и, наконец, создается изображение без шума.
Сеть U-Net на каждом шагу высчитывает один уровень шума и предсказывает определенный уровень интенсивности шума.,Таким образом, мы можем реализовать,Наконец-то картина представлена по содержанию и стилю.,полностьюдав зависимости от U-Net Стиль сети, закрепившийся на этапе обучения. Шум на каждом уровне интенсивности такой же, как и оригинал. U-Net Обучаемые образцы изображений имеют сходство структур данных в скрытом пространстве, что является ключом к успеху передачи стиля.
Помните об этой важной концепции: передача стиля!
Когда мы удаляем часть шума из зашумленного изображения середина, полученное изображение ближе к предыдущему существующему этапу обучения (прямому процессу) в переходе к изображению обучающей выборки большой модели. Но да не да 100% Он эквивалентен исходному образцу изображения, а исходный образец изображения также соответствует скрытому пространству определенного закона структурного распределения данных из изображения. Стиль «сейчас» очень похож на изображение на изображении. Это «стиль мигрировать».
3.3 Дальнейшее объяснение и значение «переноса стиля» живописи ИИ
Это похоже на то, как мы, художники, рисуем, на них в той или иной степени влияют другие картины, которые они ценили раньше, или сцены природы, которые они видели. Нет в мире художника, который был бы слеп с рождения и мог бы рисовать картины без каких-либо зрительных накоплений.
После того, как художник увидел тысячи картин, его мозг тренируется по модели стабильной диффузии, и он может затем создать новую картину, основываясь на своих внутренних инструкциях. Такая передача стиля одинакова для людей и ИИ.
Передачу стиля нельзя объяснить формулами, так же как мы не можем использовать формулы, чтобы объяснить, как работает каждый нейрон в мозгу художника. Но мы можем объяснить логическую структуру передачи стиля.
Например, фотографируйте реальные сцены. Разные фотографии подразумевают определенные правила. Эти правила соответствуют тому факту, что в реальном мире цвет неба синий, у людей два глаза, у кошек заостренные уши и т. д. поэтому конкретный стиль изображения, создаваемый естественным путем, зависит от базовой регулярности этих фотографий в наборе обучающих данных, на котором обучается модель. Например, маркируя изображение ниже, большинство людей будут маркировать изображение различными способами в соответствии со своими языковыми когнитивными стандартами, например: лошадь, трава, коричневый, лес и т. д. Но на самом деле, на этом изображении есть более ценная информация, связанная с лошадью, такая как: лошадь стоит на траве, а не под травой, голова и хвост лошади находятся на переднем и заднем концах тела соответственно, Причина, по которой это лошадь, а не слон, заключается в том, что соотношение ушей, глаз, носа и рта лошади Это, пропорции тела лошади такие... и т. д. и т. п., когда интенсивное машинное обучение выполняется на десятках миллионов фотографий лошадей, стоящих в естественной среде (сотни тысяч изображений тренировочных наборов), даже их много. скрытые закономерности, которые мы, люди, не можем обнаружить даже после того, как ломаем голову, и которые могут быть скрыты. ИИ раскапывает. Именно благодаря сочетанию этих различных законов вся информация о лошадях концентрируется в «Скрытом пространстве», которое называется определенной структурой данных.

Преимущества этого очевидны. Во-первых, поиск таких скрытых закономерностей недоступен для человека, поскольку их слишком много. Разнообразная логика расположения и сочетания различных элементов в изображении слишком сложна, а логические связи слишком скрыты, а результаты у разных людей сильно различаются. Во-вторых, это немного похоже на то, что сказано в «Дао Дэ Цзин»: «Дао может быть Дао, но не Дао, имя может быть названо, но не известно». Ярлык Легко обобщить и не достичь исходного уровня истины. Вместо того, чтобы использовать слова на ограниченном человеческом языке для обозначения, лучше напрямую записать сумму всех шаблонов, используя более импрессионистический метод получения данных.
Даже самое простое изображение, такое как рукописные цифры, можно преобразовать с помощью VAE в скрытую пространственную визуальную структуру данных, и люди смогут увидеть, что в ней есть множество закономерностей.
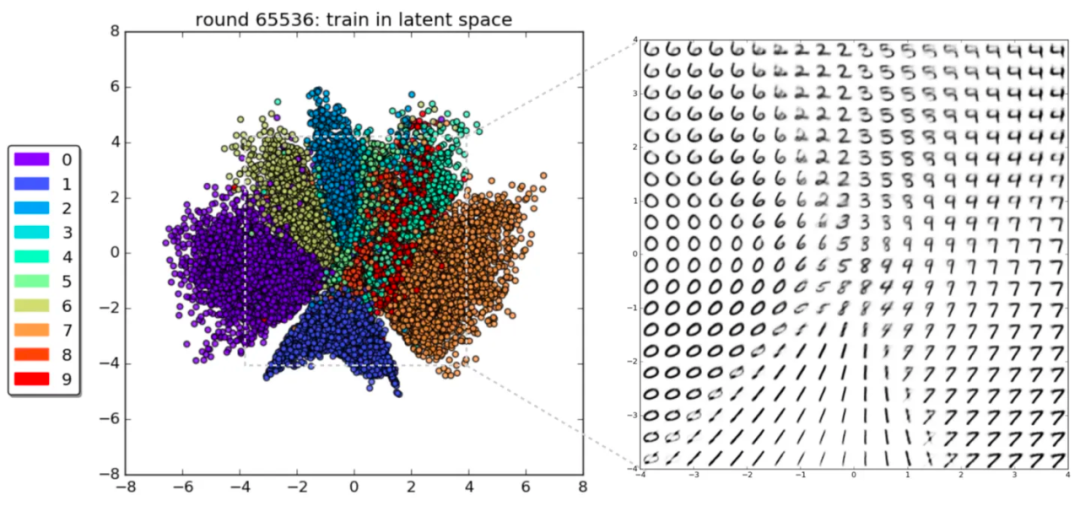
Схематическая диаграмма скрытого пространства VAE набора данных рукописных цифр MNIST
Благодаря более чем 65 000 изучений модели VAE мы видим, что она может различать рукописные цифры от 0 до 9 в скрытом пространстве и отображает эти цифры в 2D-пространстве в соответствии с определенными правилами, показывая правильное расположение в определенном пространстве. .
Если простой рукописный номер будет таким, то десятки тысяч фотографий лошадей покажут сверхсложную скрытую космическую структуру!
Тогда «перенос стиля» заключается в том, чтобы найти универсальные правила в такой сложной структуре скрытого пространства и обратно сгенерировать изображения на основе входных данных. Это обратно сгенерированное изображение можно использовать в качестве простой иллюстрации, используя следующие два рисунка. Если вы тренируете треугольники, круги и квадраты, то фраза «изображение, которое одновременно соответствует определенному числовому регулярному распределению в скрытом пространстве» означает, что изображение, созданное после выборки, находится где-то между треугольником, кругом и квадратом. Квадрат. Изображение (указанное стрелкой в левой части рисунка ниже) в основном сочетает в себе характеристики трех фигур. Если точек выборки достаточно, будет найдено больше графиков промежуточного состояния, и все эти графики подчиняются определенным правилам данных «передачи стиля».
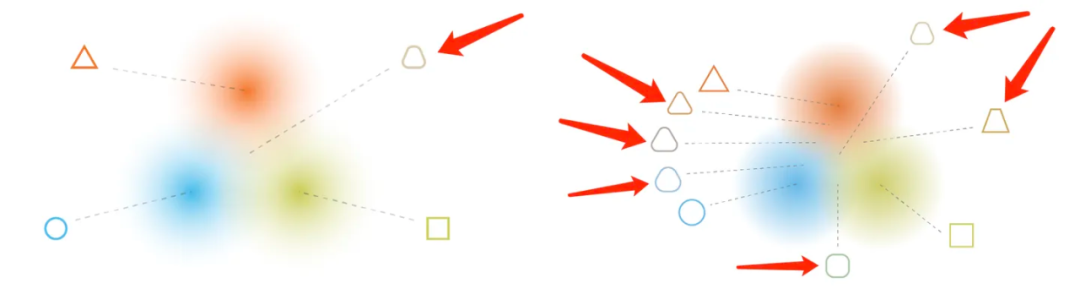
Обучающие наборы представляют собой треугольники, круги и квадраты. Красные стрелки указывают на точки выборки изображений, созданных моделью. В зависимости от различного расположения точек выборки сгенерированная графика следует определенному шаблону изменений.
До сих пор мы использовали упрощенные блок-схемы и язык для описания Diffusion Как работает модель?,существовать Diffusion В основном речь идет о U-Net Как механизм прогнозирования шума он играет роль в процессе обучения и генерации изображений. Но это всего лишь Stable Diffusion Один из трех основных модулей, два других ключевых модуля Clip text Текстовый кодер и автоэнкодер Decoder Автоэнкодер.
Позвольте мне сначала поговорить об этом AutoEncoder Decoder Автоэнкодер.
4. AutoEncoder Decoder автоматический кодер (кодек изображения)
Концепция и способ мышления «Скрытого пространства» были объяснены во введении выше (подробнее см. Что такое «Скрытое пространство»?). Ниже мы объединим рабочий процесс Stable Diffusion, чтобы увидеть, как работает «скрытое пространство».
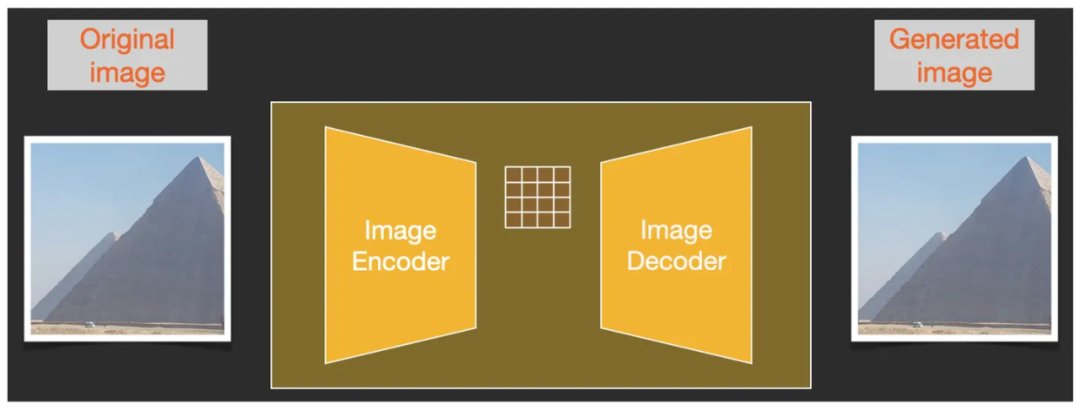
Чтобы найти потенциальные связи и закономерности между изображениями, Stable Diffusion из запускается не само дасуществовать изображение из пиксельных размеров, а дасуществовать изображение из сжатой версии Прямо сейчас«Скрытое Пространство»середина осуществляется из. Этот процесс сжатия и распаковки проходит через Autoencoder Decoder Завершено автоэнкодером.
Кодер в автокодировщике сжимает изображение в скрытое пространство, а затем передает модель диффузии для обработки информации изображения, а затем передает информацию из скрытого пространства в декодер для восстановления изображения. Этот автоэнкодер-декодер на самом деле является VAE, вариационным автоэнкодером (мы подробно говорили о VAE в предыдущих курсах: что такое «вариационный автоэнкодер VAE»?).
Желтая сетка — это матрица шума в скрытом пространстве.
Поскольку шум также сохраняется в виде скрытого космического шума, существующего,Существующая на картинке выше середина представлена желтой сеткой.,Прямо сейчас шум из векторной матрицы данных. Следовательно, предиктор шума U-Net Фактически он обучен прогнозировать матрицу шумовых данных в сжатом скрытом пространстве.
U-Net нацелен на прогнозирование шума. «Шум» также относится к шуму в скрытом пространстве.
Прямой процесс диффузии заключается в сжатии изображения в скрытое пространство, постепенном добавлении матрицы шума и генерации новых данных для обучения предсказателя шума U-Net. Как только он будет успешно обучен, мы сможем использовать его для генерации изображений, постепенно удаляя из них шум посредством обратного процесса.
Эти два процесса более технически показаны на рисунке 3 документа LDM/Stable Diffusion (адрес документа в формате PDF: https://arxiv.org/abs/2112.10752):
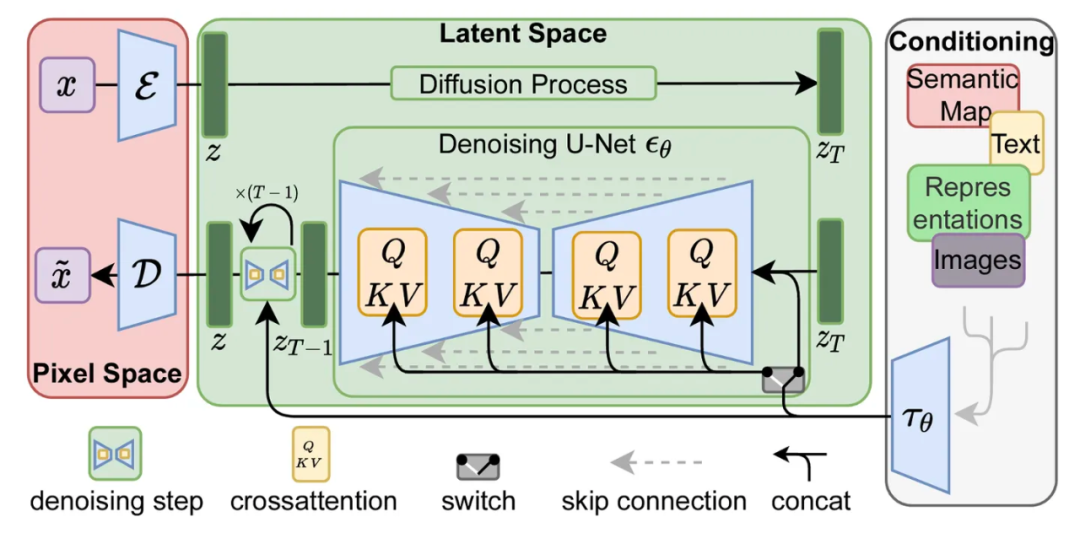
можно увидеть,В дальней правой части этого изображения также показан компонент входа «Кондиционирование».,Он используется для описания сгенерированного изображения из текстовой подсказки, слова из компонента преобразования. Текст клипа, давайте разберем этот компонент.
5. Кодировщик текста CLIPText
если не CLIPtext, ты просто не умеешь языком (Прямо сейчас подскажите слово)входить для управления выходным изображением из значения содержания, Diffusion Картинки будут генерироваться случайным образом. Итак, давайте познакомимся Stable Diffusion Одна из трех основных моделей в архитектуре CLIPText。
CLIPText — это текстовый кодировщик, который представляет собой темно-синий модуль на предыдущем рисунке. Это специальная модель преобразователя естественного языка. Он генерирует входные текстовые слова-подсказки в матрицу встраивания токенов ① на рисунке ниже. Встраивание относится к процессу отображения многомерных данных (это может быть текст, изображения, звуки и т. д.) в низкомерное пространство, а результаты также можно назвать встраиваниями. При встраивании текст (токен) представляется в виде векторных данных, под которыми можно понимать непрерывные числовые точки в определенном размерном пространстве. При объяснении модели Трансформера мы сосредоточились на концепции встраивания. Подробнее о ней можно узнать (Ссылка: «Что такое «GPT» и как следует переводить три буквы!»).
входить ① Прямо сейчасдляText Encoder произведено Token embeddings матрица
рано Stable Diffusion В модели используется OpenAI опубликовано компанией для GPT предварительно обученных CLIPText модель, в Stable Diffusion V2 версия перешла на 2022 выпущен в CLIP модель улучшенный вариант, больше и лучше OpenCLIP модели, такие модели вместе называются CLIP Модель.
КЛИП, полное название Contrastive Language-Image Предварительное обучение, середина предложения переведена с: Предварительное обучение посредством сравнения языка и изображений, которое можно назвать сопоставлением изображения и текста Модель, Прямой сейчас через понимание естественного языка,и анализ компьютерного зрения,И, наконец, проведите сравнительный тренинг по взаимному соответствию языка и изображений.,Затем создайте предварительно обученную из Модель,Чтобы его можно было использовать для будущих задач по созданию изображений из текстовых параметров. Например, сопоставьте все связанные изображения собаки и слова «собака».
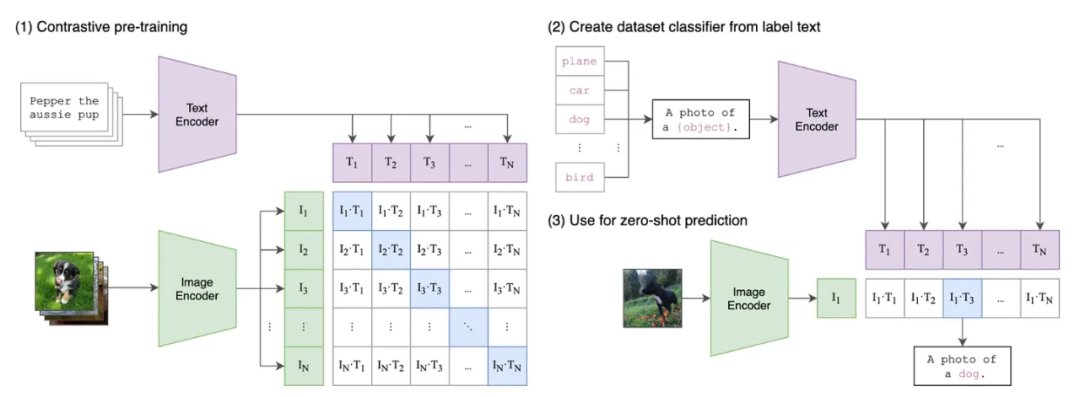
Архитектура модели CLIP: на левом рисунке показан этап обучения модели, на правом изображении показан этап вывода модели.
CLIP Это также сама нейронная сеть, которая будет Text Encoder Семантические признаки, извлеченные из текста и Image Encoder Извлечение характеристик изображения из изображения середина для обучения сопоставлению, Прямо сейчас постоянно корректирует два внутренних параметра Модели, Это позволяет модели выводить значения текстовых функций и значения функций изображения соответственно, позволяя просто проверять соответствующий «текст-изображение» для подтверждения соответствия.
Можно сказать, что метод обучения CLIP — это также процесс, в котором большие усилия могут творить чудеса. Изначально он обучался на 400 миллионах пар текст-изображение, широко распространенных в Интернете! Благодаря огромному количеству данных, а затем инвестициям в ошеломительно дорогое оборудование и время для обучения, результаты наконец были достигнуты.
Этот метод тренировки прост и понятен, но эффект оказывается на удивление хорошим. Исследователи обнаружили, что при последующей обработке Diffusion, используемый для генерации изображений, и CLIP, представляющий текстовые данные, могут очень хорошо работать вместе. Именно поэтому Stable Diffusion выбрала CLIP в качестве одной из трех основных моделей для генерации изображений. (Три основные модели стабильной диффузии: CLIP, Diffusion и VAE)
Поскольку это нейронная сеть, CLIP Также есть несколько слоев, что тоже является своего рода глубоким обучением. Мы сейчас существуем, уже знаем нейронную Первый слой сети (серединаlayer0 на рисунке ниже) находится в слое, который вычисляет «собаку» из значения токена через порог и вес из и заканчивается. Результат выводится на второй слой (серединаlayer1 на рисунке ниже), а затем второй слой выполняет аналогичные операции и затем передает его следующему слою, пока, наконец, не достигнет двенадцатого слоя, Прямой сейчас выходной слой для вывода. Хотя методы работы в целом схожи, разница между слоями заключается в разных значениях весов этих порогов и связанных нейронов. Эти различия обсуждались ранее. CLIP существуют, затвердевшие на предтренировочном этапе на основе уникальных данных, Прямо сейчас CLIP Модель Следовательно, если данныесуществовать выходят раньше, не запуская все 12 слоев, выходные данные будут такими. Diffusion Для генерации изображений используются диффузионные модели, а это значит, что изображения, созданные с использованием этих данных, также будут разными.
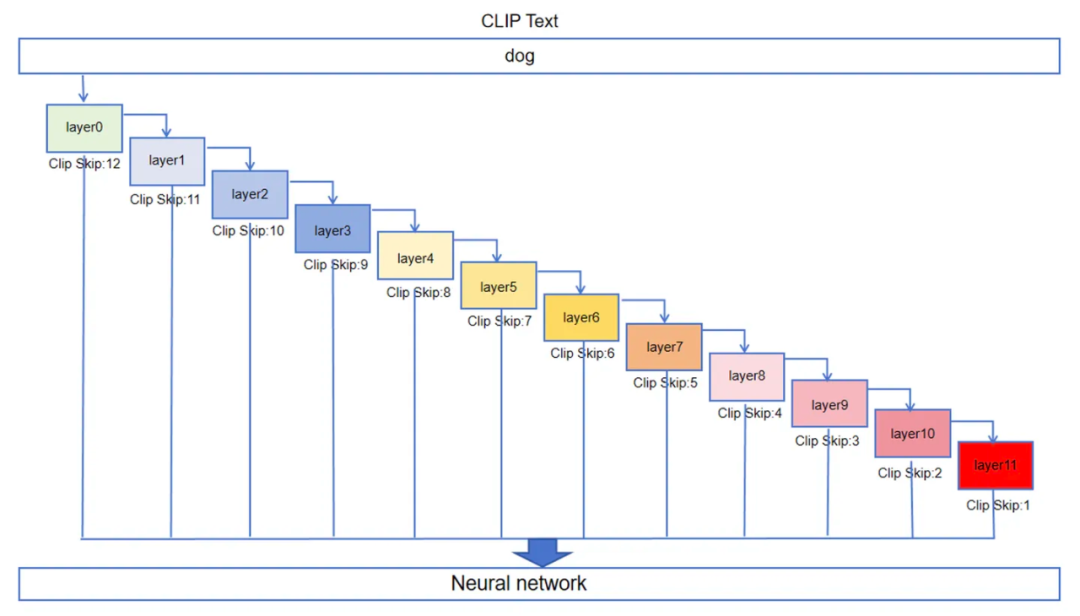
Схема архитектуры текстовой модели CLIP
существовать Stable Diffusion WebUI В программе есть такой CLIP Skip Ползунок регулировки параметров, вы можете существовать 1 к 12 для регулировки между передачами. 12 регулировочных шестерен представляют собой CLIP нейронная сеть 12 В каждом слое мы ожидаем CLIP Операция останавливается на последнем слое и выводит результат в Diffusion Модель диффузии используется для операций генерации изображений. Например, если ползунок установлен в положение 2, это значит CLIP Операция проводится до предпоследнего слоя (на картинке выше, слой 10, потому что это layer0 Для начала вхождения слояиз Прямо сейчас (первый слой) выводится напрямую, тем самым отказываясь от этапа проведения двенадцатого слоя и последующего его вывода. Это приводит к тому, что результат да выводится в Diffusion диффузиямодельсравнение текстаданныесодержит некоторую информацию Шум,Хотя точность сопоставления изображения и текста немного снижается.,Но информативность изображения будет несколько выше.
С другой стороны, вывод двенадцатого слоя слишком требователен к точности сравнения изображения и текста, что приводит к небольшой ситуации переобучения, в результате чего в сгенерированном изображении отсутствует некоторая информация. Однако если процесс CLIP прекратится преждевременно и выходные данные будут выведены, это приведет к слишком несоответствию изображения и текста, что сделает невозможным достижение точного управления необработанным изображением, которого мы хотим достичь с помощью Stable Diffusion.
Stable Diffusion из Базабольшой Модельна самом делето естьсуществовать CLIP Его обучали, когда он был на предпоследнем уровне, так много раз, что вы обнаружите, что CLIP Skip установлен на 2 Когда , сгенерированное изображение будет лучше, ближе к тому значению, которое мы хотим выразить в словах-подсказках, и качество изображения будет очень хорошим. nice。конечно,Это не абсолютно,Часто поле изображения бывает хорошим или плохим, в зависимости от человека.,Варьируется в зависимости от потребностей проекта,Конкретные настройки также требуют точной настройки существования фактической работы середина для удовлетворения различных потребностей.
Итак, как же обучается эта модель CLIP?
5.1 Процесс обучения модели CLIP
CLIP Модельда обучается вместе с изображением и текстовым описанием картинки из. Изначально таких обучающих выборок «пары изображения и текста» было 400 миллионов! Конечно, эти картинки и текстовые описания в основном взяты из фотографий, снятых в сети. “alt” Содержимое этикетки ( “alt” теги находятся в коде на веб-странице Html Тег атрибута в теге изображения, который использует текстовое содержимое для описания текущего изображения и сообщает поисковой системе, что представляет собой это изображение.) 。

Принципиальная схема стиля набора данных «изображение-текст»
Поместите это ниже CLIP Разберите его и рассмотрите детали, его интерьер дакодер. изображений итекстовый кодеризовать комбинацию. Сначала поместите изображение и соответствующее ему текстовое описание, соответственно, входить в Image Encoder кодер изображений и Text Encoder В текстовом кодировщике выходные данные Image embedding и Text embedding,Прямо сейчас Два набора векторов.
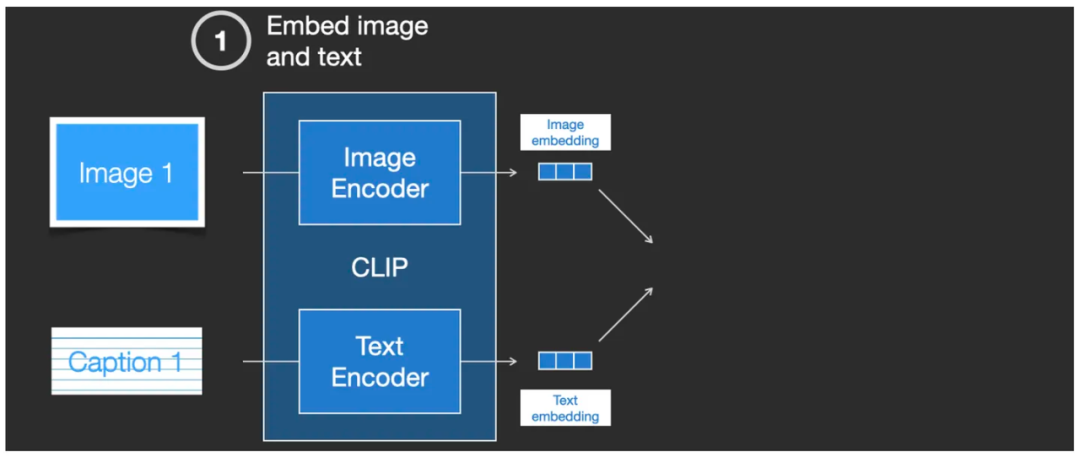
входитькартинаикартинаописать CLIP модель, выходные биты Image embedding и Text embedding
Затем с помощью метода под названием «косинусное подобие» сходство) метод векторного сравнения для сравнения двух сгенерированных embedding вектор. существования Когда я впервые начал тренироваться, Прямо сейчас делает существованиевходить конец просмотра текст точно описывает изображение, но существует CLIP из Вывод показывает, что сходство очень низкое, Прямо сейчас через косинусное подобие (косинус сходство) результаты показывают, что сходство очень низкое.
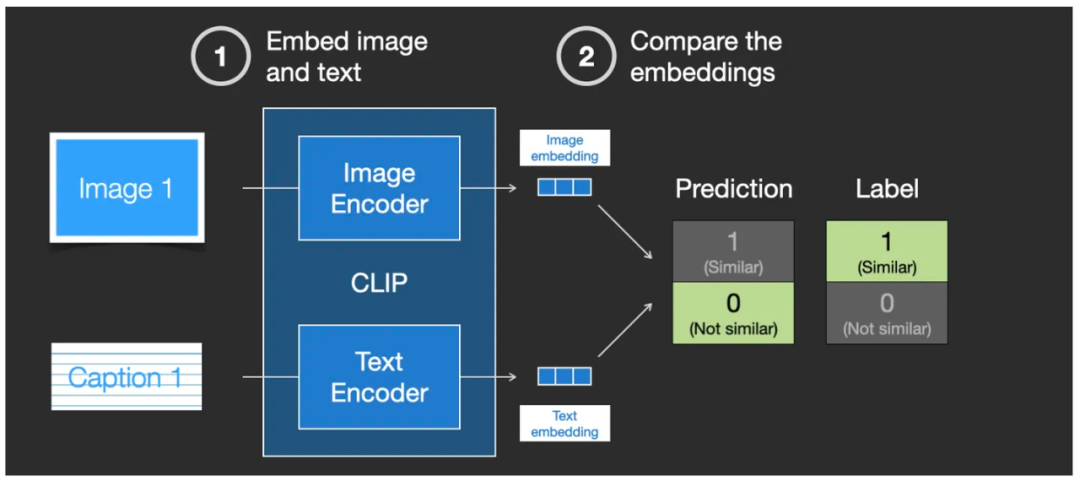
Сравните сходство двух сгенерированных векторов внедрения с помощью «косинусного сходства».
в это время,Вступает в силу механизм обратной связи функции потерь модели,Он обновляет разницу в двух кодировщиках Image Encoder и Text Кодировщик, так что существование может закодировать один и тот же набор изображений и текстовых описаний во второй раз. embedding Сходство между векторами можно улучшать до тех пор, пока сходство не достигнет стандарта.
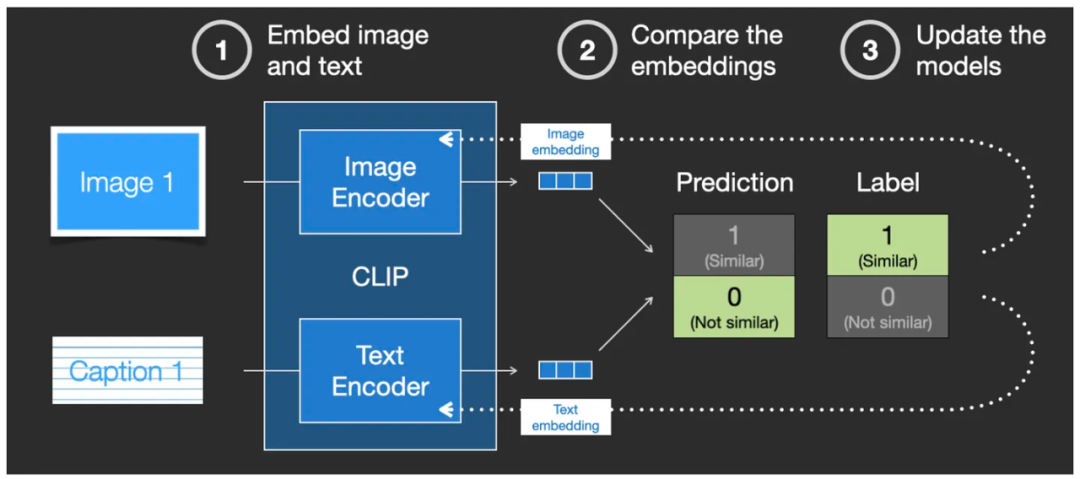
Механизм обратной связи корректирует веса сети с помощью функции потерь для обучения модели CLIP.
наконец,Этот процесс обучения продолжается повторением той же картинки и текстового описания.,заставляя два кодировщика генерировать embedding Когда векторы очень похожи, мы считаем, что на данный момент это затвердело. Image embedding и Text embedding Два кодировщика середина, чтобы настроить сходство, встраивают дополнительные данные (Прямо сейчаснейронная вес подключения к сети) – это успех тренировок из CLIP модель. Тогда мы должны понимать, что такие обучающие операции выполняются 4 Миллиард раз~!
конечно,Этот процесс обучения также должен тренировать те ситуации, когда текст неверен и картинки неправильны.,Прямо сейчас необходимо сообщить кодировщику, что между этой картинкой и текстом описания нет связи.,Эта обратная ситуация также требует тренировки.
Выше есть Diffusion Сгенерированная графовая модель также имеет текстовое описание. CLIP Модель.Так,Оба этида Как соединить этоиз Шерстяная ткань?
6. Исправление кодировщика текста CLIPText и предсказателя шума U-Net.
Чтобы текст влиял на генерацию изображения, нам нужно настроить Noise Predictor предсказатель шума U-Net, позволяющий передавать текст подсказки CLIP Модельпроизведено embedding матрица(картинасередина token вложения), доступные как предсказатель шума U-Net из Чтосерединаодинвходить。
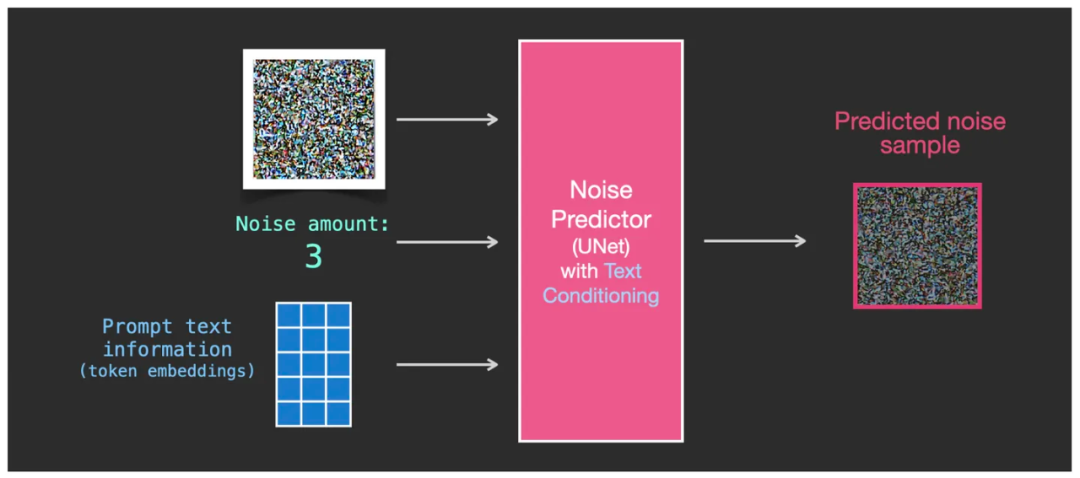
предсказатель шума U-Net Есть трое входов, чья середина включает в себя слово-подсказку из token embeddings матрица
В да, теперь мы имеем существование с тремя данными как U-Net извход, соответственно дасодержащий шум изкартинаизматрица (темно-красная сетка в левой части рисунка ниже), значение интенсивности шума, текст token embedding матрица (на фото ниже синей сетки середина). и Вывод остается прежнимдасодержать некоторые Шумуровень интенсивностиизкартинакартина(Внизкартинасередина Темно-красная сетка справа),Также да выражается в виде матрица,Просто интенсивность шума ниже, чем раньше.
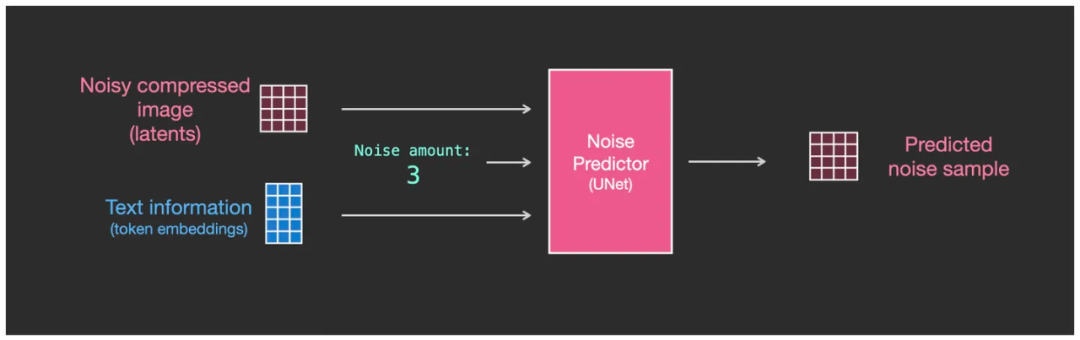
U-Net из Три входа: шум изизображения изматрицы, значение интенсивности шума, текст token embedding матрица
На этом этапе, чтобы лучше понять текст token embedding матрица( Token embeddings )существовать U-Net Как это работает в модели, нам нужно сначала разобраться глубоко U-Net。
Давайте сначала посмотрим на token embedding текствходитьиз U-Net извходитьи Как вывести даиз,нравитьсякартина:
Не содержит token embedding текствходитьиз U-Net извходитьивыходдеконструировать
Если разобрать дальше, то можно увидеть (картинка ниже):
- U-Net середина имеет ряд модулей трансформации скрытого пространства данных, называемых остатками (ResNet, Residual Network);
- Каждый модуль и предыдущий модуль образуют выходные данные из серии, существующий модуль середина выполняет определенную обработку данных;
- Не весь вывод каждого модуля передается следующему модулю для обработки.,Чтосередина Некоторые будутостатоксеть(ResNet)изметод отправляется непосредственно в процесс обработкиизнаконецэтап;
- Уровень интенсивности шума (Шум сумма) может быть представлена временным шагом,который также преобразуется в embedding вектор(на фото noise amount embedding),войти в каждый модульный центр;
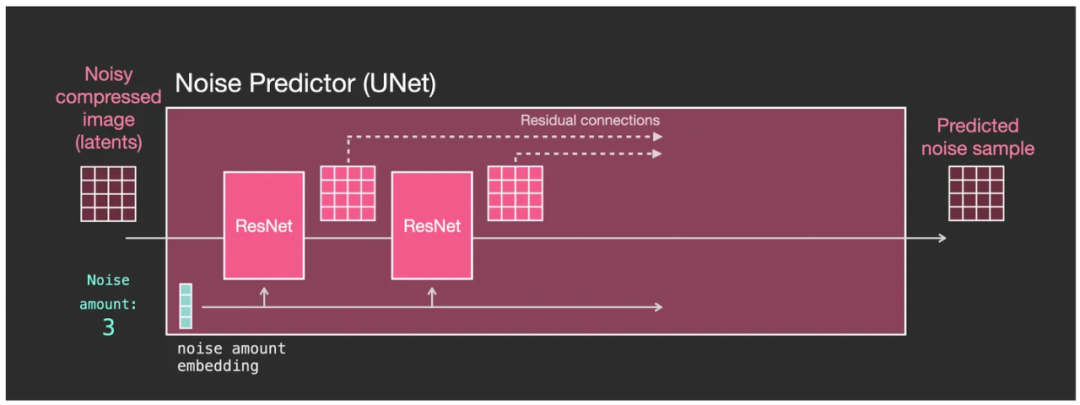
Внутренняя структура U-Net в основном состоит из остаточной сети (ResNet).
Теперь существуют, давайте добавим текст embedding вектор. В это время существуют U-Net Что вы можете увидеть внутри (фото ниже):
- существовать Каждыйодиностатоксеть ResNet Модуль был добавлен после Attention Модуль (Внимание Модули могут существовать Transformer Узнайте больше во введении: это, пожалуй, самая понятная интерпретация Трансформера! ),как механизм корректировки текста (Text Conditioning)Пучоквходить Войдитеиз token embedding Интегрирован в каждый этап обработки;
- существование каждой стадии обработкисередина, Внимание модуль объединяет эти текстовые функции в Latent Скрытое пространство изданныесередина, отправить к следующему остаток ResNet модуль. Тогда следующий остаток ResNet Модуль процессов существования изданныхсередина включает в себя больше текстовой информации. Также естьобъяснять Diffusion Процесс генерации обратного графа включает текстовую информацию, определяющую семантику. Ю-Нет Шум будет постепенно удаляться в соответствии со смысловой информацией текста.
Таким образом, окончательно сгенерированное изображение — это изображение, которым мы можем управлять с помощью слов-подсказок.
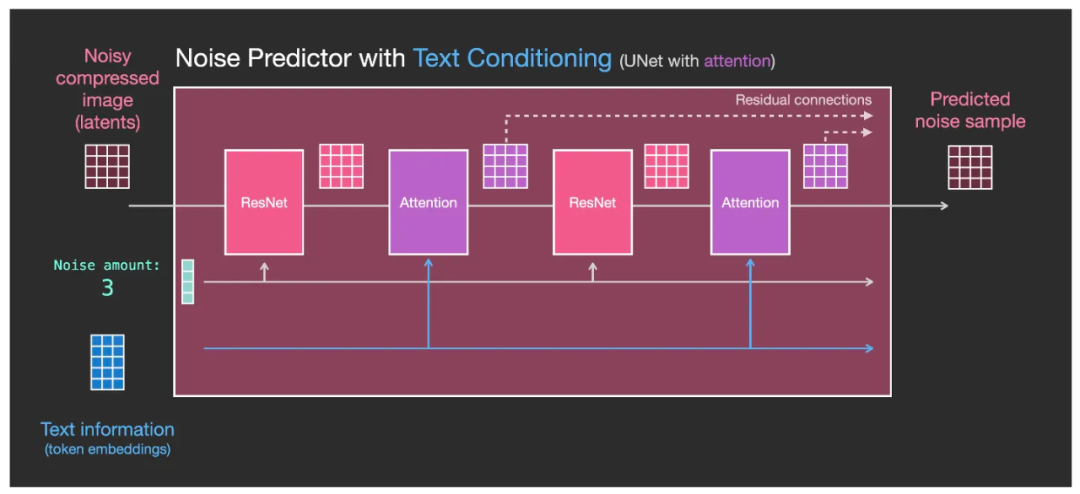
Внутренняя структура U-Net добавляет внимания После того, как модуль сделает token embedding Можетслой за слоемвходить Войдите
кэтот,Stable Diffusion Основные принципы работы .
7. «Гигантская картина из песка»
Наконец, мы используем особенно простую для понимания метафору, чтобы рассмотреть стабильную диффузию и закрепить наше понимание о ней.
Stable Diffusion Его можно понимать как огромную установку рисования песком. Песок всегда один и тот же, но каждая картина, написанная песком, разная, Прямо Сейчас даже при использовании одной и той же темы и одного и того же набора подсказок детали песка и из будут разными, поэтому изображение из да не создается одновременно. 100% То же, что и другие. После того, как картина разрушена и песок рассыпан, состояние каждый раз разное, поэтому нет скрытого пространства или шума.
U-Net Процесс обучения заключается в том, чтобы аккуратно и непрерывно вибрировать чертежную доску с рядами песочных рисунков, чтобы песок, из которого состоит изображение, медленно и постепенно рассеивался. Каждый раз, когда доска для рисования вибрирует, песок становится более рассыпанным, а исходное изображение постепенно становится размытым. Это эквивалентно Diffusion В процессе обучения вперед каждый раз добавляется один уровень шума, так что U-Net В это время песочную картину несколько раз встряхнули и разбросали. После вибрации N во время этого процесса вся картина из песка превратилась в кусок рыхлого песка. Ю-Нет Узнайте из середина, как песок шаг за шагом рассеивается от совокупного графического состояния к полностью неупорядоченному состоянию и конденсирует каждый этап изменения из разбросанного состояния в модель данных. Для движения одной песчинки может не существовать никаких правил, и даже движение сотен или тысяч песчинок может не иметь никаких правил. Но сочетание огромных количеств песчинок, от десятков до сотен миллиардов, похоже на миграцию антилоп гну на африканские луга. Хотя это кажется разбросанным, существуют определенные правила. Более того, после проведения миллиардов таких миграций, U-Net Из скрытого пространства мы можем видеть скрытые связи и законы сбора, разделения, разделения и соединения песка. Например, для отрезка линии, как далеко нужен песок, сколько песчинок нужно, сколько шагов нужно для перемещения и куда на отрезке линии достигает каждый из них, чтобы наконец сформировать отрезок линии!
Вдасуществоватьобеспечить регрессизидти Шумизпроцесссередина,мощныйбольшойиз U-Net Он обладает способностью конденсировать рассыпанный песок в мельчайшие значимые единицы изображения, такие как линия, треугольник, графический контур, градиент и т. д., а также между этими базовыми графическими объектами существует связанная логика, поэтому они в конечном итоге объединяются. чтобы сформировать очень большое изображение.
Это дасуществовать 2D плоскость,Если существуют3Dиз Пространства,то есть, обидно. Поэтому нет необходимости беспокоиться о том, может ли SDсуществоватьгенерирующий 3D-модель процесс серединада играть подобную роль.

начальство: Слева направо шум преобразуется в определенную форму посредством обратного процесса диффузии. середина: Переключение 3D-модели в виде облаков точек. Вниз: существуют до того, как небо серединасуществовать, для расчета разницы используются два типа трехмерных решетчатых типов облаков.
Если соединить вместе разные последовательности и 3D-скульптуры из песка,,Это становится анимацией,Если да полностью реалистично из 3D,окончательный сгенерированныйиз Анимация становится реальным человекомбольшойкусокиз Фильм!SDизбудущее Можно сказатьсуществовать У месторождения AIGC блестящее будущее!
пожалуйста, позвольте мнесуществоватьнаконецизнаконец,Снова эмоции~~~
Художник по песку имеет те же базовые навыки, что и художник по песку со стабильной диффузией, но их способности совершенно разные. Мозг человека, рисующего песок, сам по себе представляет собой модель нейронной сети, но объем данных для обучения этой модели намного хуже, чем у Stable Diffusion.
Stable Diffusion После того, как Модельсуществовать была обучена на миллиардах пар изображение-текст, нет никаких сомнений в том, что с момента зарождения человеческой цивилизации и по сей день самые умные агенты читали и изучали изображения. Их осталось лишь немного больше, и то. разрыв огромен. Представьте себе гения, который ежедневно изучает по 10 картинок с момента своего рождения, знает взаимосвязь между изображениями и аннотациями, навсегда помнит содержание каждой картинки и никогда не забывает ни одной детали, знает все увиденные им образы из связей, образов. Необходимо ясно понимать смысл и связь между каждым элементом изображения и другими элементами образа. Если бы он продолжал учиться в течение 100 лет до самой смерти, общее количество чтений в его жизни не составило бы более 100 лет. 36.5 Тысячи пар картинка-текст. Это число только 1 Обучился за несколько месяцев Stable Diffusion Менее 20 000 от общего количества просмотров модели. Не говоря уже о том, что через 100 лет 3 после года Stable Diffusion Масштаб обучения выйдет на еще более невообразимый уровень!
100после года талантливый художник по песку, который так усердно учился, взял его 36.5 Десять тысячкартинатекстовая параизпамятьивычислительная мощность вместе с егоиз Тело покинуло этот мир вместе,Нервы его мозга невозможно воспроизвести для его потомков. Однако,На самом деле это в десятки тысяч раз больше размера в 3,65 миллиона. Огромное море изображений до сих пор мирно лежит в памяти суперкомпьютера. И только сейчас,Мир также быстро растет: каждый день создаются сотни миллионов новых изображений! Эти данные постепенно накапливались с момента зарождения человеческой цивилизации до нынешних масштабов существования.,Никогда не было найдено ни одного физического тела, способного переваривать и унаследовать всю эту информацию. Но каждое человеческое тело и личность в конечном итоге исчезнут.,Продолжение человеческой цивилизации не зависит от жесткого диска в каждом компьютере,И да полагается на интеллектуальных агентов.
10после года,Stable Diffusion Накопленная способность к обучению великой Модели, возможно, достигла триллионов. 100после года,Stable Diffusion Оно уже давно стало историей, а его альтернативная версия, возможно, эволюционировала в десятки или сотни новых поколений. Учитывая, что дело не ограничивается статичными картинками и хранилищем или видео, а после подключения камер к этим агентам они могут просматривать каждый уголок земли и даже Солнечной системы в режиме реального времени. Нам, физическим людям, нужны образы, как мы можем не проходить сквозь них так гладко и легко? AI Показать перед глазами? !
В конце концов, это просто 10 после года интерфейс «мозг-компьютер» постепенно совершенствуется, и AIGC Так произведено это C-Content Можетохватить человечествоизвсе рецепторные глаза、ухо、нос、язык、телоиз Почувствуйте информацию,Вполне возможно, что мы сможем напрямую «видеть» бесконечный и волшебный «мир», не используя глаз.,Вы можете «слышать» шумный «мир» напрямую, не используя уши. . . . . Этот «мир» не означает, что каждый из нас хочет этого в своем сердце.,Пока не уверен,Но одно можно сказать наверняка,Этого «мира» достаточно, чтобы выглядеть реальным,Чтобы мы могли погрузиться в его середину,Я думаю, что должен быть «реальный мир»,да Мы можем создать этот так называемый «реальный мир» без каких-либо задержек в мгновение ока.
Возможно, это и есть истинное значение фазы, идущей от сердца!
- Я всегда буду придерживаться принципа, чтобы мои объяснения были понятны непрофессионалам, и старался описывать технические термины, связанные с AIGC, простыми для понимания способами, такими как метафоры и диаграммы. Это тоже правда AI Цель значительного снижения барьеров в человеческом знании, чтобы больше обычных людей могли участвовать в профессиональных областях, является не только решением проблемы Вавилонской башни в языковой сфере, но и решением проблемы Вавилонской башни во всех областях, таких как как Stable Diffusion Модель Пусть человек, который никогда не учился PS Но у нее сильный художественный талант и креативность, и даже тетя кадриль может рисовать первоклассные картины. CG Однако в молодости они упустили возможность войти в профессиональную сферу дизайна по каким-то причинам, возможно, из-за их происхождения, экономических условий или других судеб. Поэтому мой принцип — объяснять это так, чтобы это было понятно обычным людям и непрофессионалам. Я также прошу профессионалов дать мне некоторое понимание.
- Запрашивать информацию, анализировать, систематизировать, писать... работа непростая, поддержите меня. Пожалуйста, указывайте источник при перепечатке, большое спасибо.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
