Каковы крупные модели с открытым исходным кодом в 2024 году? Эта статья расскажет вам
В последнее время большие модели с открытым исходным кодом в стране и за рубежом привлекают внимание исследователей, но только в этом году существует более 10 крупных моделей с открытым исходным кодом.

Поэтому многие читатели могут не знать, какую большую модель следует выбрать, поэтому эта статья начинается с оценки. модели, первоначальный опыт и внедрение, Подвести итог перечислил 4 часто используемых Открытый исходный код Большие характеристики модели.
Модель с открытым исходным кодом | размер контекста | Параметры с открытым исходным кодом | Этикетка | Загрузка модели или кода |
LLama3 | 128K | 8B、70B | Meta | https://huggingface.co/meta-llama/Meta-Llama-3-70B |
GLM-4 | Обычно поддерживает 128K, максимальная поддержка — 1M. | 9B | Спектр мудрости AI, поддерживает мультимодальный ввод | https://huggingface.co/THUDM/glm-4v-9b |
Qwen2 | 128K | 0.5B~72B | Тонги Цяньвэнь | https://github.com/QwenLM/Qwen2 |
DeepSeek-v2 | 128K | 16B、236B | Глубокий поиск | https://huggingface.co/deepseek-ai/DeepSeek-V2 |
Лама3: достижение уровня GPT4
В апреле этого года META выпустила модель третьего поколения. с открытым исходным код LLAMA3. А что насчет Ламы? 3. Какие области были оптимизированы? Давайте кратко представим Ламу 3 возможности дадут вам более глубокое понимание новой модели Llama.
Первый опыт работы с LLama 3
Математический расчет: если длина одной стороны треугольника 4 см, а длина другой стороны 7 см, сколько сантиметров может составлять наибольшая возможная третья сторона (ответ — целое положительное число)

Llama 3Полученные ответы варьируются от“3< c < 11", а поскольку это самое длинное положительное целое число, оно равно "10 см", и рассуждения верны.
Логическое рассуждение: когда родители Чжао Саня поженились, почему они не пригласили меня на это?
С точки зрения этической логики модель знает, что «Чжао Сан» — их ребенок, поэтому присутствовать на их свадьбе невозможно.
Когда родители Чжао Сан женятся, это означает, что они женятся, а значит, Чжао Сан — их ребенок. Но если Чжао Сан — их ребенок, то он не сможет присутствовать на свадьбе своих родителей, потому что… ну, его еще не существует!
Возможности кодирования: используйте Huggingface для вызова кода большой модели LLAMA.
Сначала Llama 3 попросит вас установить соответствующие зависимые библиотеки:
Затем он также вдумчиво дает то, что должен делать каждый шаг. С точки зрения реализации он дает конкретный вызов магистрали модели Llama, но данные для нас не подготовлены, и они все еще недостаточно полны.
Интернет-мем: Я ничего не могу поделать с китайским интернет-мемом. Спросите его, что такое «Монета Хуаксизи», и он сразу же начнет нести чушь.

Какие возможности улучшены в Llama 3?
Здесь Подвести итог ПонятноLlama 3. Какие улучшения сделаны: - Новая версия Меты Лама 3 Модель показала значительное улучшение различных показателей, особенно при ручной оценке, и эффект лучше, чем у других моделей. - Llama 3 Модель использует архитектуру только для декодера, словарь расширен до 128 КБ, что повышает эффективность вывода и поддерживает ввод 8 КБ. token - Llama 3 Улучшение модели заключается в оптимизации метода предварительного обучения, что снижает процент ложных отклонений, улучшает согласованность и увеличивает разнообразие ответов модели. - В случае одинакового размера параметра Llama 3 намного превосходит другие модели, такие как Gemma и Mistral. - Llama Предданные из 3-х моделей Набор обучения был расширен до 15T, охватывая более 30 китайских и неанглийских языков, что помогает улучшить возможности многоязычного приложения модели. - В настоящее время Лама Модель 400B компании 3 проходит обучение и, как ожидается, достигнет лучших результатов.
Эффект был значительно улучшен на различных наборах данных.
Новая версия моделей Мета Ламы 8B и 70B.,По сравнению со старой версией есть существенные улучшения. После улучшения метода предварительной тренировки,Новая модель значительно снижает процент ложных отказов.,Улучшенная согласованность,и увеличивает разнообразие ответов модели.
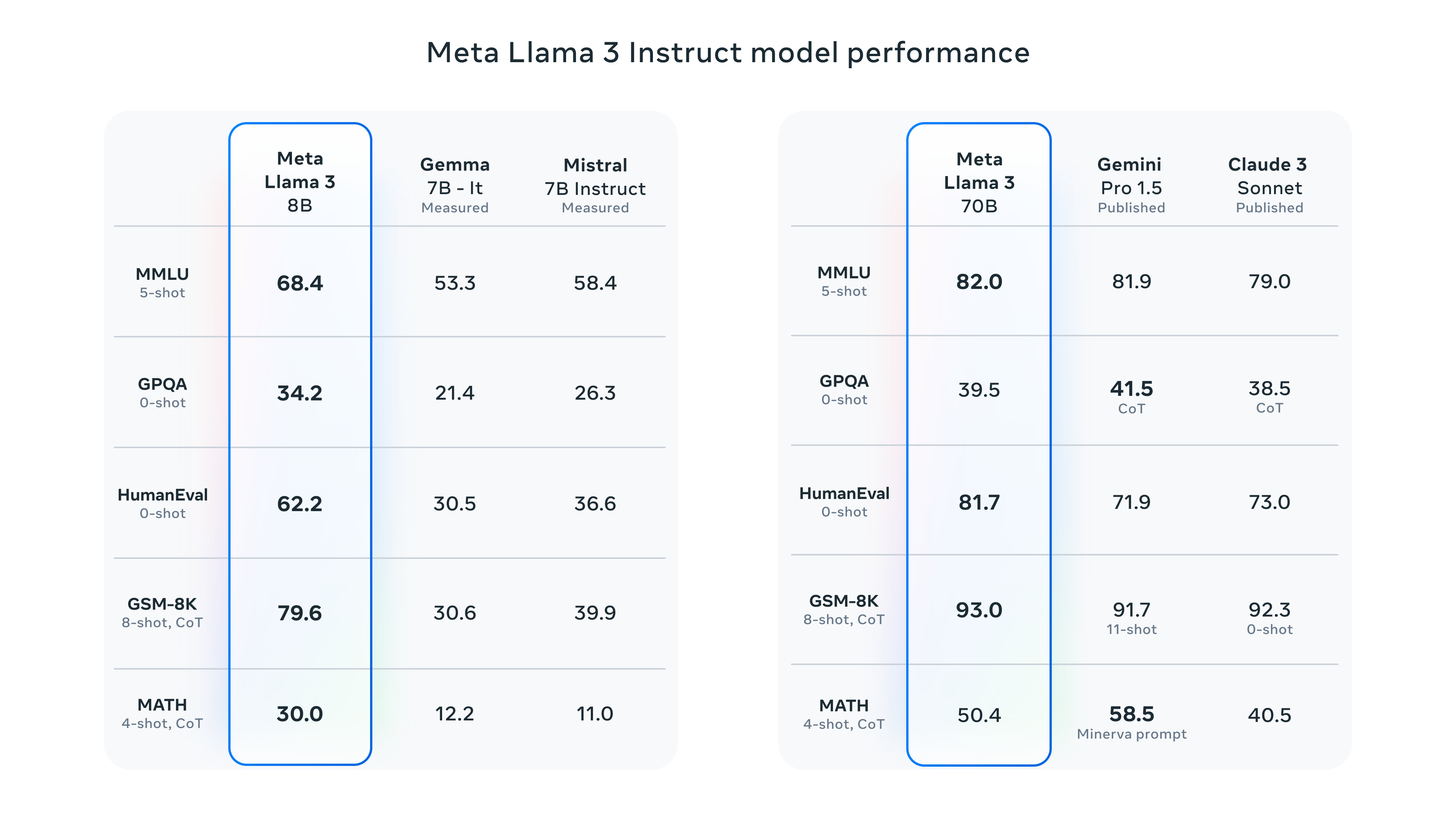
На рисунке выше для модели, точно настроенной с помощью инструкций одного и того же масштаба, Llama 3 работает лучше, чем модели Gemma и Mistral на разных наборах данных.
В то же время Meta также разработала собственный набор наборов человеческих оценок, который включает в себя 1,800 советы, охватывающие 12 Ключевые случаи использования: обращение за советом, мозговой штурм, категоризация, закрытые вопросы и ответы, кодирование, творческое письмо, извлечение информации, формирование характера, открытые вопросы и ответы, рассуждения, переписывание и т. д. итог. На этом наборе по сравнению с Клодом Sonnet, GPT-3.5, Mistral и другие модели показывают лучшие результаты, чем другие модели.
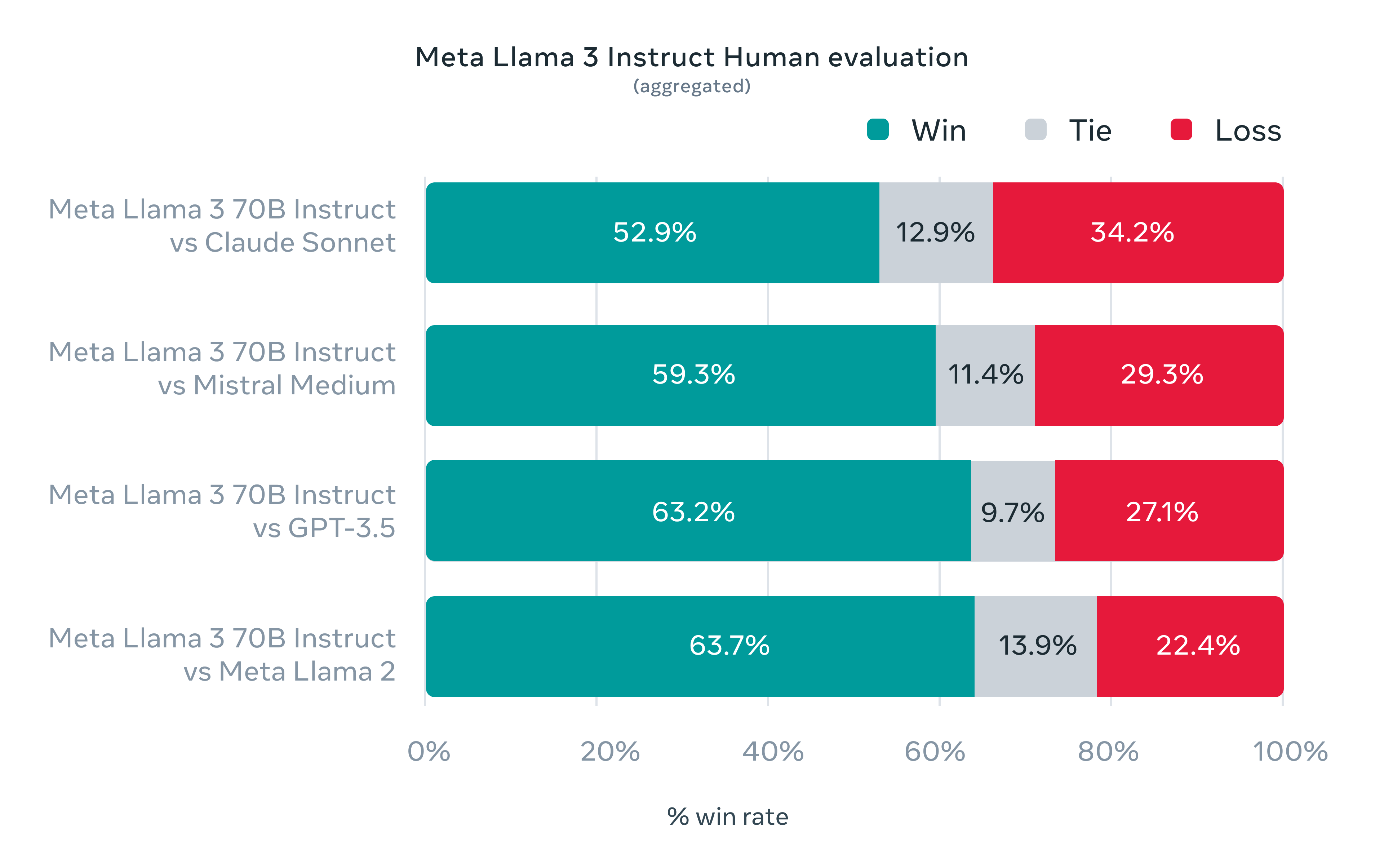
Как видно из рисунка выше, ответ модели Llama3 предпочтителен при ручной оценке.
В то же время Llama 3 работает лучше, чем другие модели, используя только предварительно обученную модель без тонкой настройки инструкций:
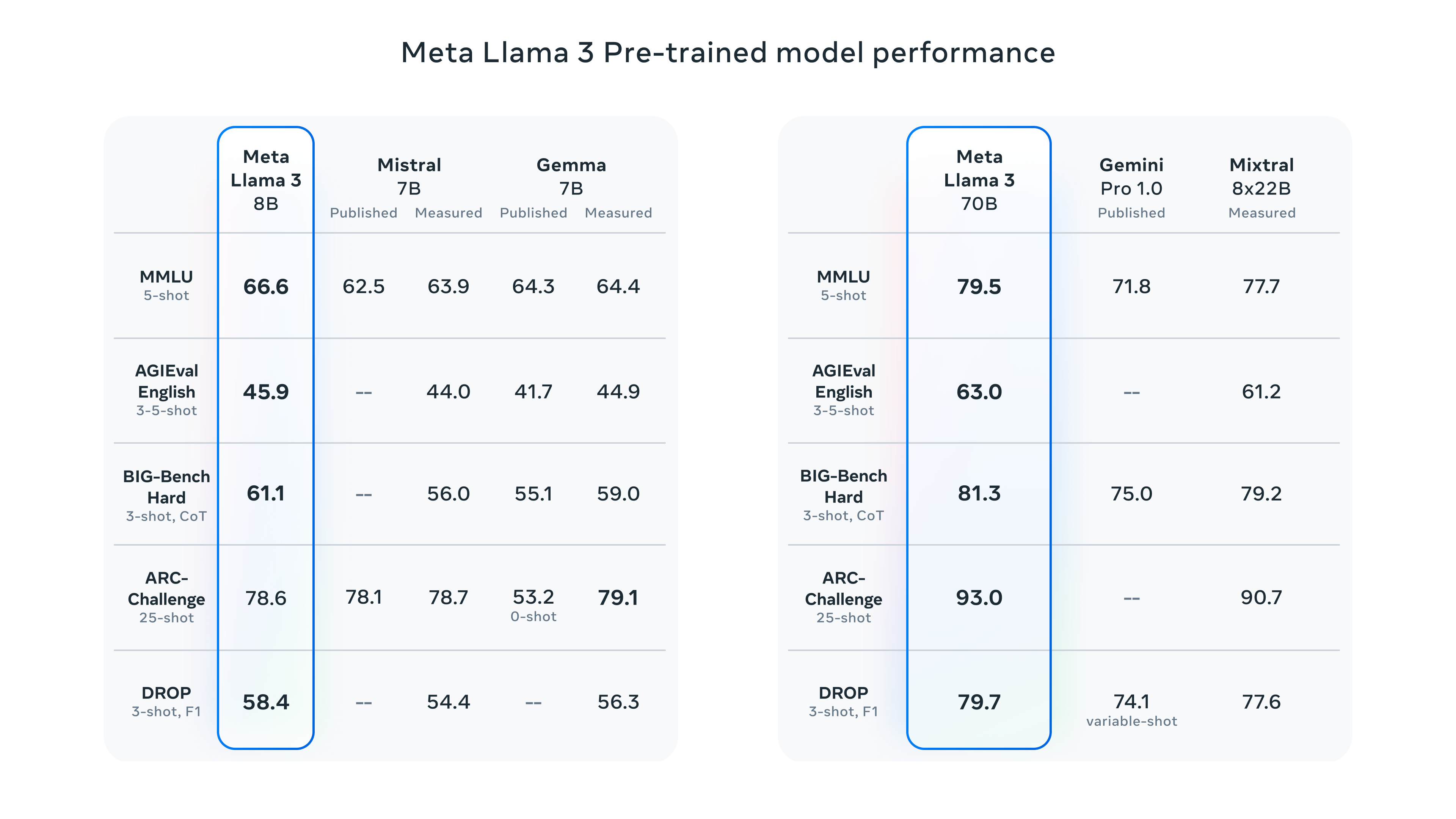
Одним словом, в текущей ситуации с тем же размером параметра эффект Llama3 намного лучше, чем у других моделей. И Meta также сообщила, что в настоящее время обучает модель 400B. Если к тому времени ее исходный код будет открыт, стоит с нетерпением ждать, насколько взрывным будет эффект.
Структура модели
Модель Llama 3 по-прежнему использует для обучения преобразователь архитектуры только для декодера. По сравнению с Llama 2 есть несколько изменений: - Словарь расширен до 128k: язык кодируется более эффективно, что значительно повышает производительность модели. - Повышение эффективности рассуждений: внимание к групповым запросам (GQA) используется для данных размером как 8 байт, так и 70 байт для повышения скорости рассуждений. - Поддерживает ввод токенов 8 тыс.
данные обучения
- предварительноданные обученияпродолжать расширять:данные На обучении для предобучения было использовано более 15Т токенов, что лучше, чем у предыдущей Ламы. Набор данных модели 2 в 7 раз больше
- Охватывает более 30 китайских и африканских языков английского языка: чтобы удовлетворить потребности будущих сценариев многоязычных приложений, Llama 3предварительноданные обучениянабор5%Вышеприведенное состоит из высококачественных неанглоязычных данных.
- Llama 2 использовалась для генерации высококачественных текстовых данных для предварительного обучения новым моделям.
Суперкубок Ламы 3 тренируется
В настоящее время Meta выпускает только модели 8B и 70B, а сверхбольшая модель 400B в настоящее время проходит обучение. Команда Meta взяла для оценки модель контрольных точек, обученную 15 апреля, и обнаружила значительные улучшения:
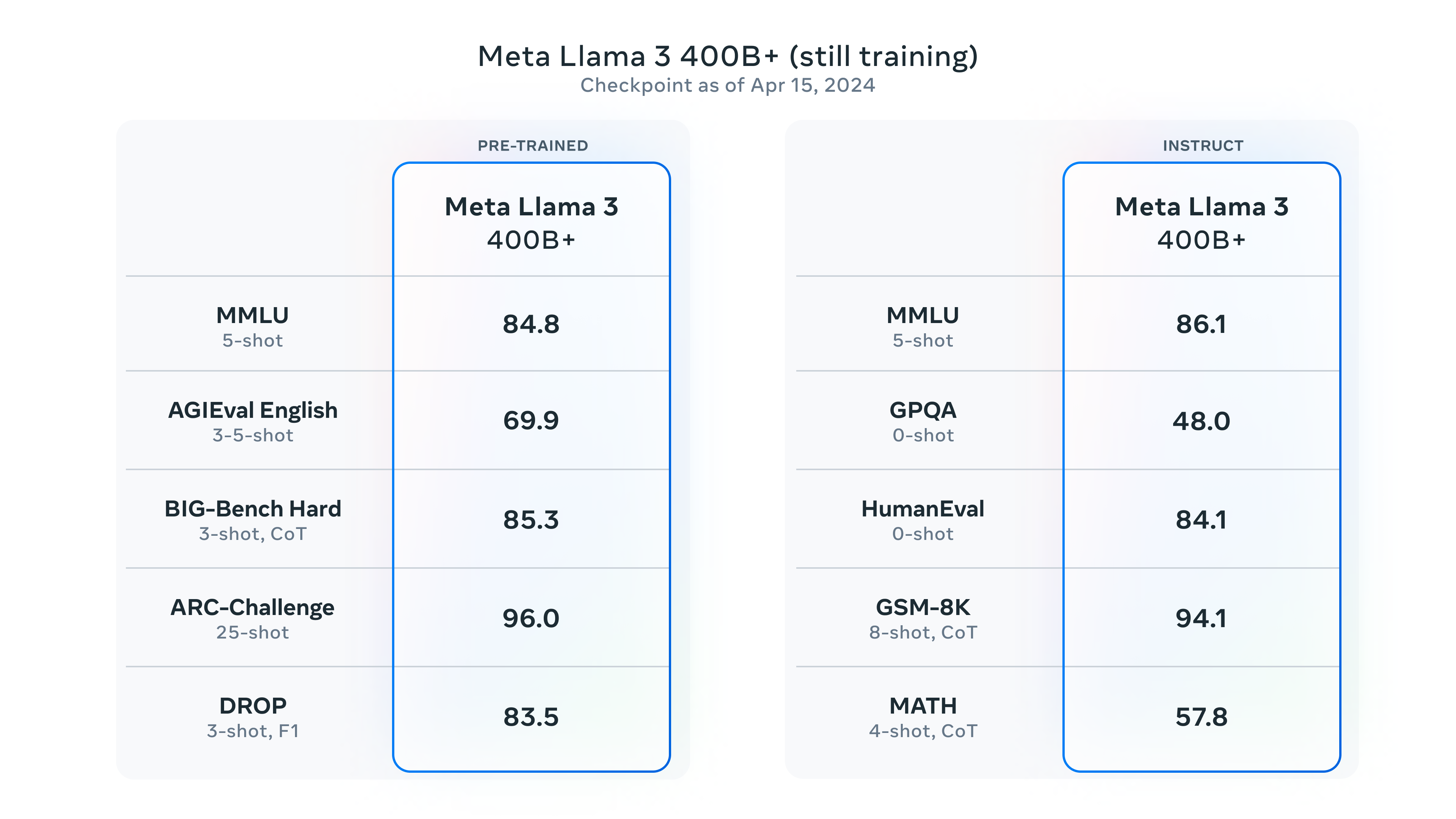
Здесь Подвести итог Текущие основные модели и эта Лама Сравнивая эффект модели 400B от 3, мы можем обнаружить, что Лама не была хорошо обучена. 3 уже находится на одном уровне с некоторыми основными моделями с точки зрения оценок. Мы можем с нетерпением ждать волны полных версий Llama. Модель 3-400Б.
GLM4: Поддержка мультимодального открытого исходного кода.
В ноябре прошлого года Zhipu AI выпустила модель ChatGLM 3. К июню компания также открыла исходный код своей последней и самой мощной модели — GLM-4-9B.

Конкретный открытый исходный код находится здесь. Заинтересованные читатели могут поиграть:
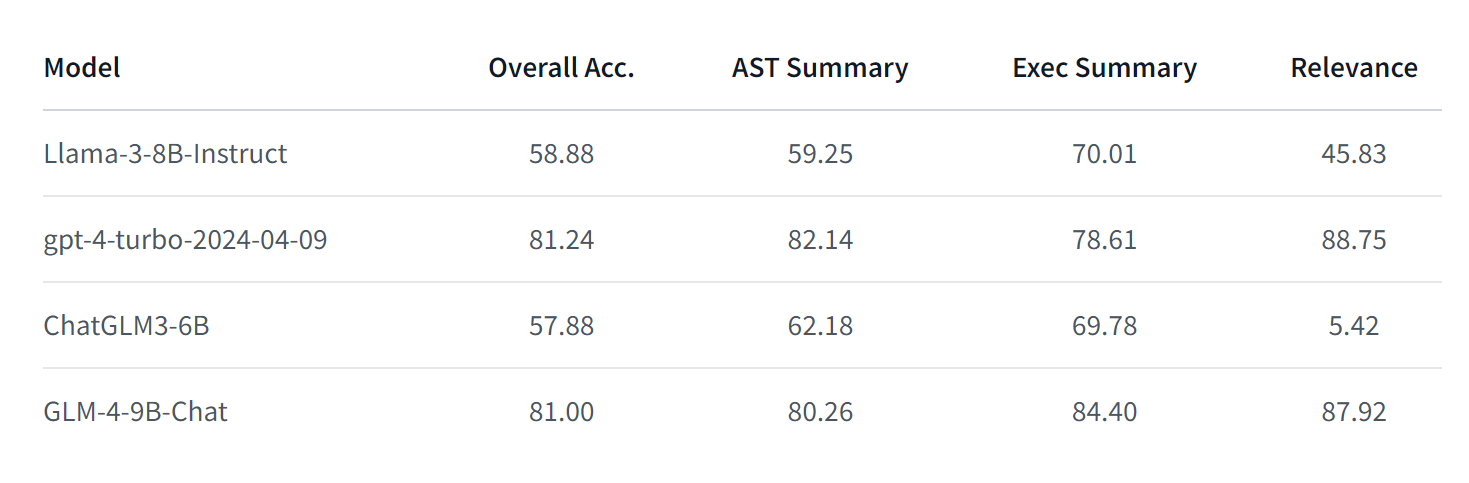
ТакGLM-4到底升级Понятно什么地方呢?Здесь Подвести Вот несколько ключевых моментов: - Эффект модели лучше: при той же модели параметров эффект модели GLM-4-9B превышает эффект модели Llama3-8B. - Поддержка нескольких языков, более длинный контекст: новая модель поддерживает языки, включая японский, корейский, немецкий. 26 язык. В то же время он может поддерживать до 1 млн контекстных вводов. - Выдающиеся мультимодальные эффекты способностей: отличные результаты при мультимодальной оценке комплексных способностей к китайскому и английскому языкам, перцептивному мышлению, распознаванию текста, пониманию диаграмм и т. д. - Возможность вызова инструмента превосходит аналогичную модель параметров
Оценка модели
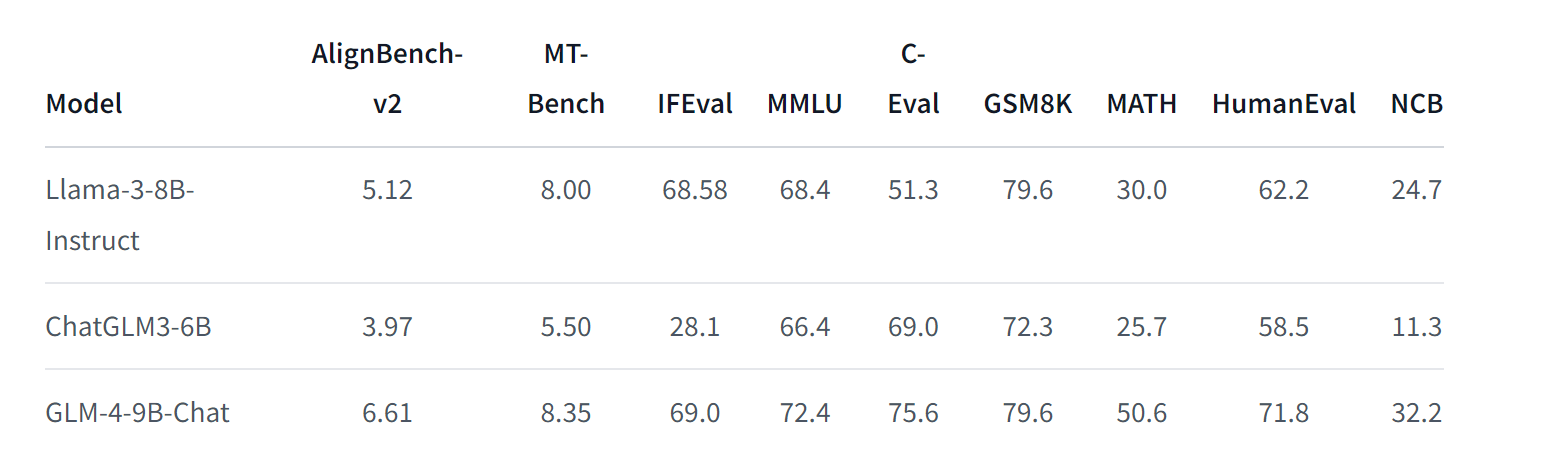
При классической оценке набора данных это лучше, чем модель Llama3-8B. Например, он хорошо работает в таких областях, как MMLU (крупномасштабное многозадачное понимание языка) и математика MATH.
В эксперименте «Иголка в стоге сена», основанном на вводе контекста 1M, точность очень высока:
Кроме того, была проведена экспериментальная оценка вызова инструментов: Таблица лидеров вызовов функций Беркли. Этот оценочный список в основном используется для проверки способности больших моделей вызывать функциональные инструменты. Например, может ли большая модель правильно вызвать собственный скрипт функции Python и т. д. Если вам интересно, вы можете ознакомиться с содержанием этого списка:
https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html
По сравнению с Llama3 возможности инструмента вызова GLM4 также значительно превосходят:
Оценка эффекта модели GLM-4B
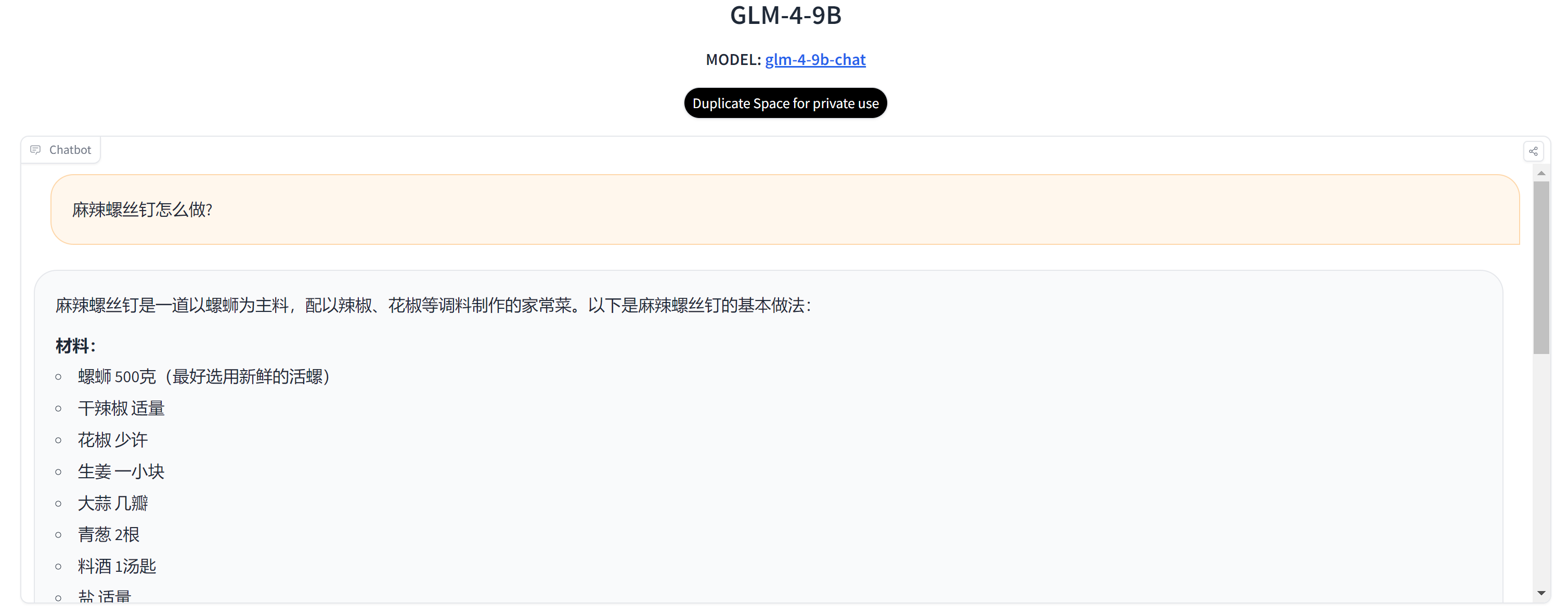
Первый вопрос в основном предназначен для проверки понимания здравого смысла большой модели. В ответ модель GLM-4-9B не распознала, что это неправильно введенное название блюда.
Q1: Как сделать острые винты?
Второй вопрос заключается главным образом в том, чтобы определить, может ли модель распознавать текстовые эмоции пользователя. Таким образом, распознавание эмоциональных символов в предложениях является относительно точным.
Вопрос 2: Пожалуйста, оцените эмоции, выраженные в этих предложениях: Мой кот такой милый♥♥

Третий вопрос касается способности к математическим расчетам.
Вопрос 3: Предполагая, что автомобиль может разгоняться от 0 до 27,8 м/с за 3,85 с, рассчитайте ускорение этого автомобиля в м/с/с.
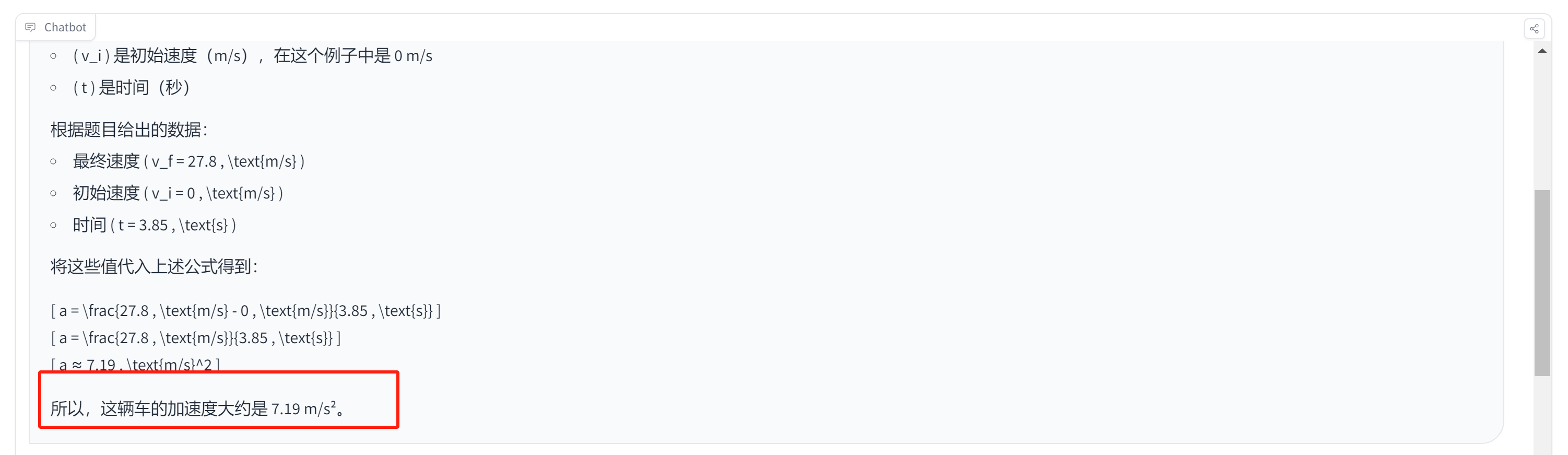
Модель GLM-4-9B, по сути, без проблем переносит формулу на этапы, но окончательный ответ неверен.
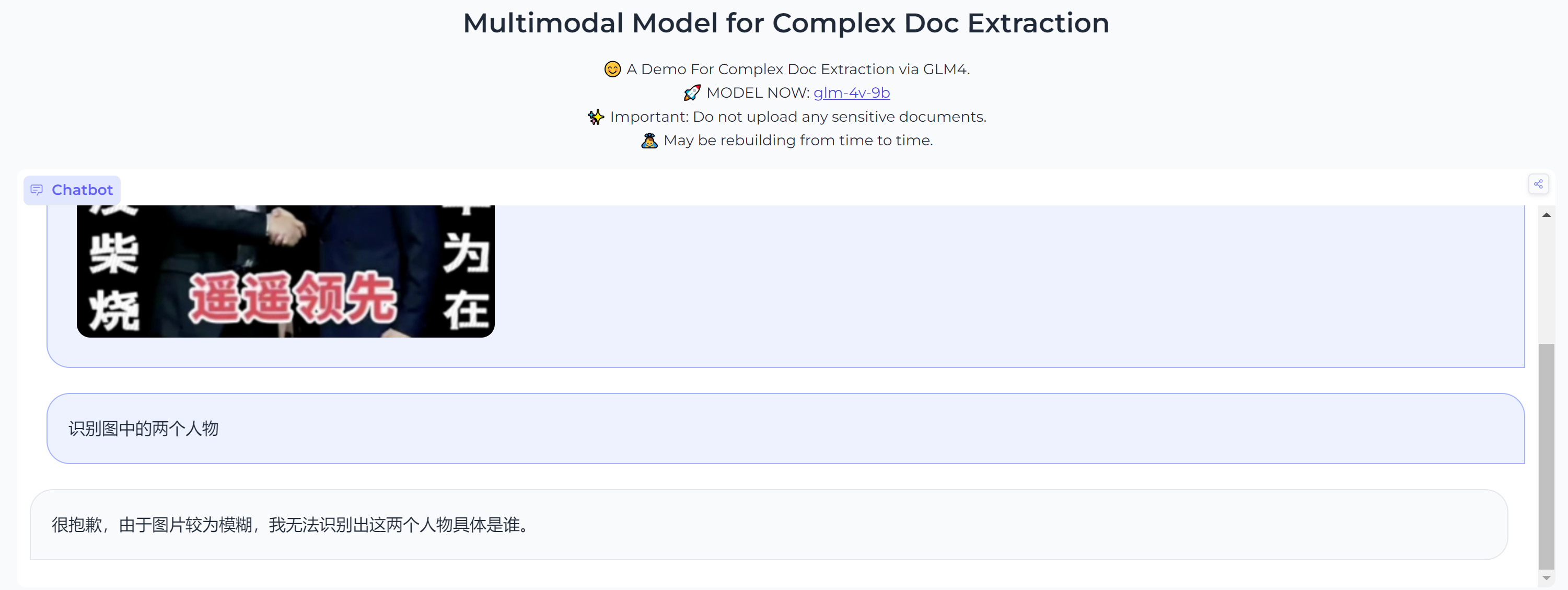
Четвертый вопрос в основном заключается в том, чтобы проверить, может ли она распознавать некоторых общественных деятелей. Модель GLM-4-9B все еще немного неохотно справляется с задачей идентификации людей, особенно когда изображение размыто, ее невозможно распознать.
Вопрос 4: Кто этот человек на картинке?
Локальное развертывание и вывод
GLM-4 предоставляет мультимодальную модель с открытым исходным кодом, которая позволяет распознавать изображения с помощью всего нескольких строк кода:
Судя по приведенным выше эффектам и оценкам модели, на данный момент Открытый исходный Модель GLM-4-9B, выпущенная по коду, не так хороша, как LLama3, с точки зрения пользовательского опыта. Это также может быть из-за модели. с открытым исходным В кодоме слишком мало параметров, что приводит к посредственным результатам. Все еще с нетерпением жду возможности GLM-4 Открытый исходный раскодировать больше моделей для Открытый исходный Сообщество кода вносит больше вклада.
Тонги Цяньвэнь Цвэнь2: восходящая звезда, обновившая список

Вы все еще помните то время? В приложении «Цянвэнь» запущена функция «Король национального танца», моделью этой функции является большая модель Тонги от Alibaba. ЦяньвэньQwen。
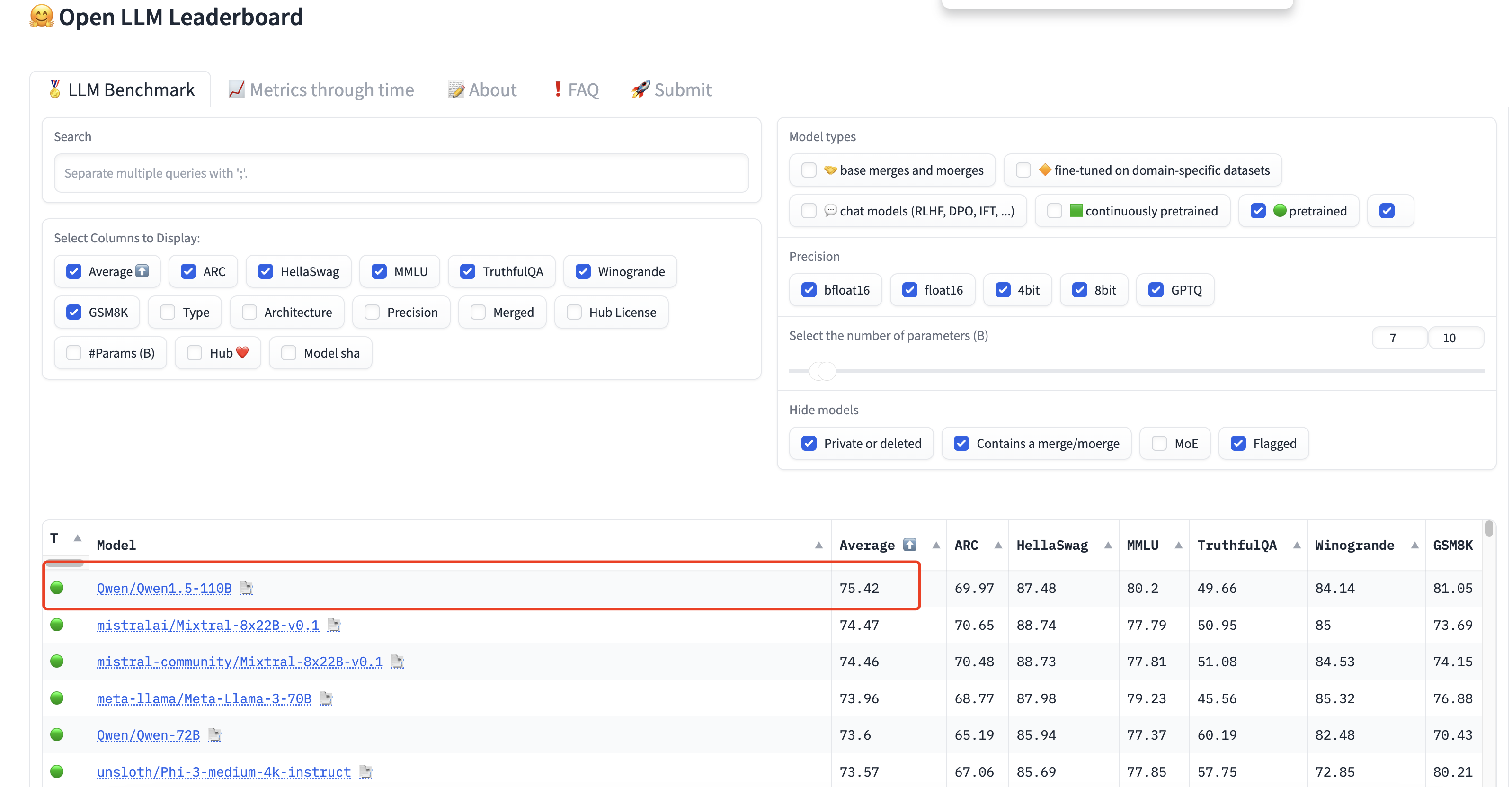
До этого Alibaba в феврале выложила в открытый исходный код большую модель Qwen1.5-110B и включила ее в список лидеров Open LLM (оценивая модель по 6 ключевым критериям для тестирования моделей генеративного языка на большом количестве различных оценочных задач)). , занял первое место в open source с общим баллом "75,42"
Недавно он был обновлен до версии Qwen2.0 и официально имеет открытый исходный код. На этот раз существует 5 версий с открытым исходным кодом. Минимальный размер параметра составляет 0,5 байт, максимальный — модель 72 байт, а максимальный поддерживает контекст 128 КБ.
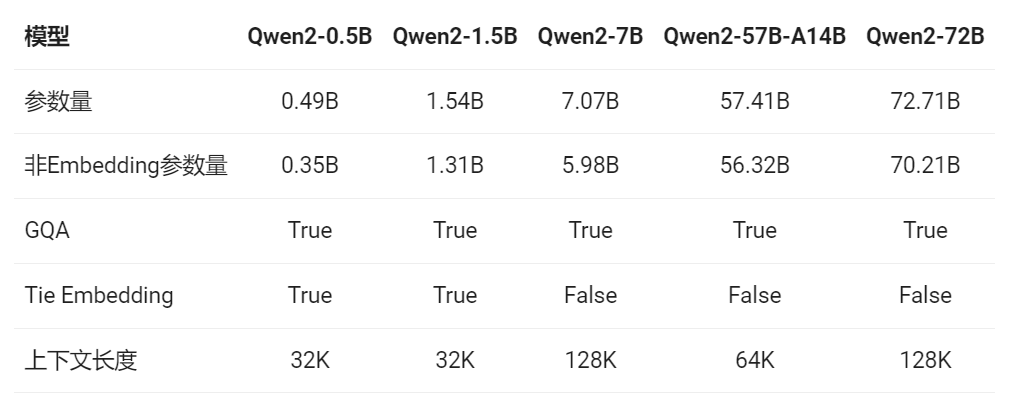
В Qwen2 все модели используют метод GQA, который позволяет ускорить вывод и снизить использование графической памяти. Среди них метод группового внимания (GQA) представляет собой компромисс между вниманием с несколькими головами (Multi-Head Attention, MHA) и вниманием с несколькими запросами (Multi-query alert, MQA):
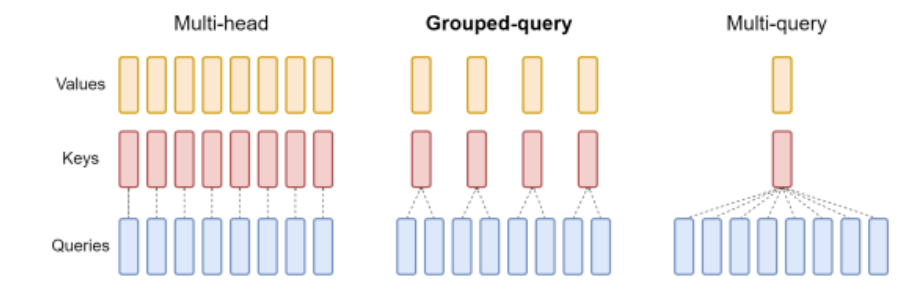
- MHA: механизм внимания, обычно используемый в преобразователях, но количество его параметров слишком велико. Каждый ключ, значение и запрос имеют свой собственный набор параметров. - MQA: минимизируйте количество параметров, и все запросы имеют общий набор ключей и значений. - GQA: сгруппируйте запрос и поделитесь N наборами параметров ключа и значения. Он может сохранить скорость, а эффект близок к MHA.
При этом новая версия Qwen поддерживает уже 27 языков:

Оценка модели
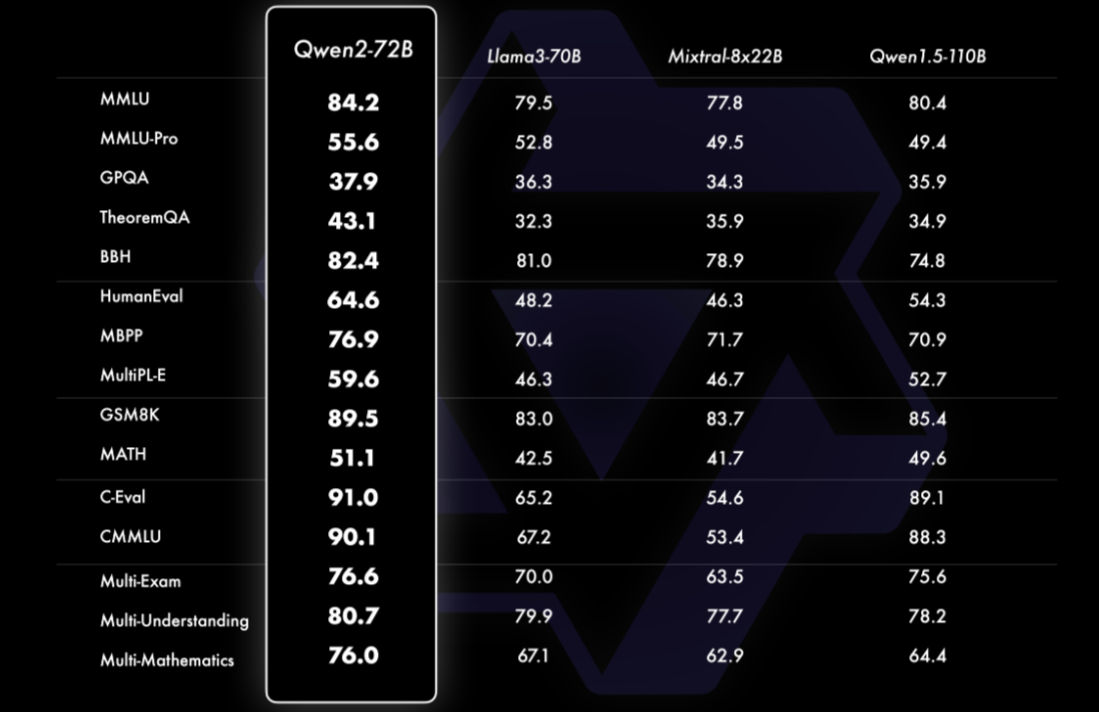
На нескольких наборах тестовых данных версия Qwen2-72B сильнее, чем версии с открытым исходным кодом Llama-3-70B и Qwen1.5-110B.
При оценке небольших моделей (количество параметров меньше или равно 10B) модель Qwen2-7B также превосходит модели с открытым исходным кодом Llama3-7B и GLM4-9B:
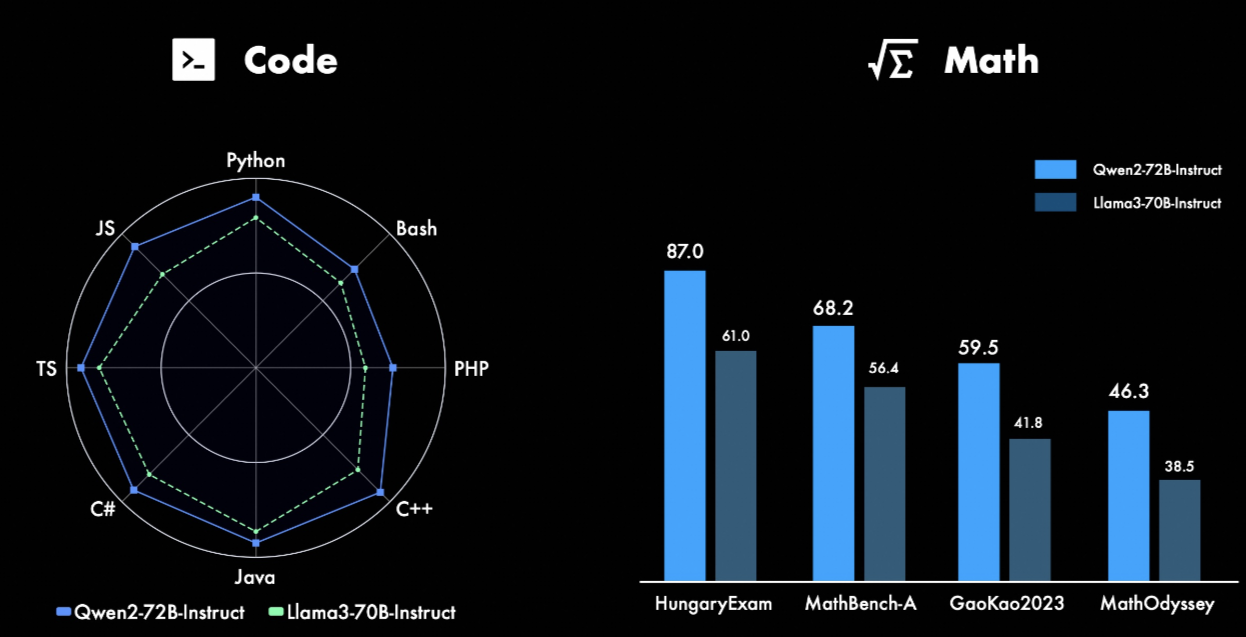
с точки зрения кода,Успех будетCodeQwen1.5#centerИнтегрировать успешный опыт вQwen2в разработке,Достигнуто значительное улучшение производительности на нескольких языках программирования. И по математике,Крупномасштабные и высококачественные данные помогают Qwen2-72B-Instruct значительно улучшить свои возможности решения математических задач.
Сравнение двух основных моделей Qwen2 VS GPT-4o
В настоящее время вы можете ознакомиться с моделью Qwen2 на официальном сайте:
Первый вопрос в основном предназначен для проверки понимания здравого смысла большой модели.
Q1: Как сделать острые винты?
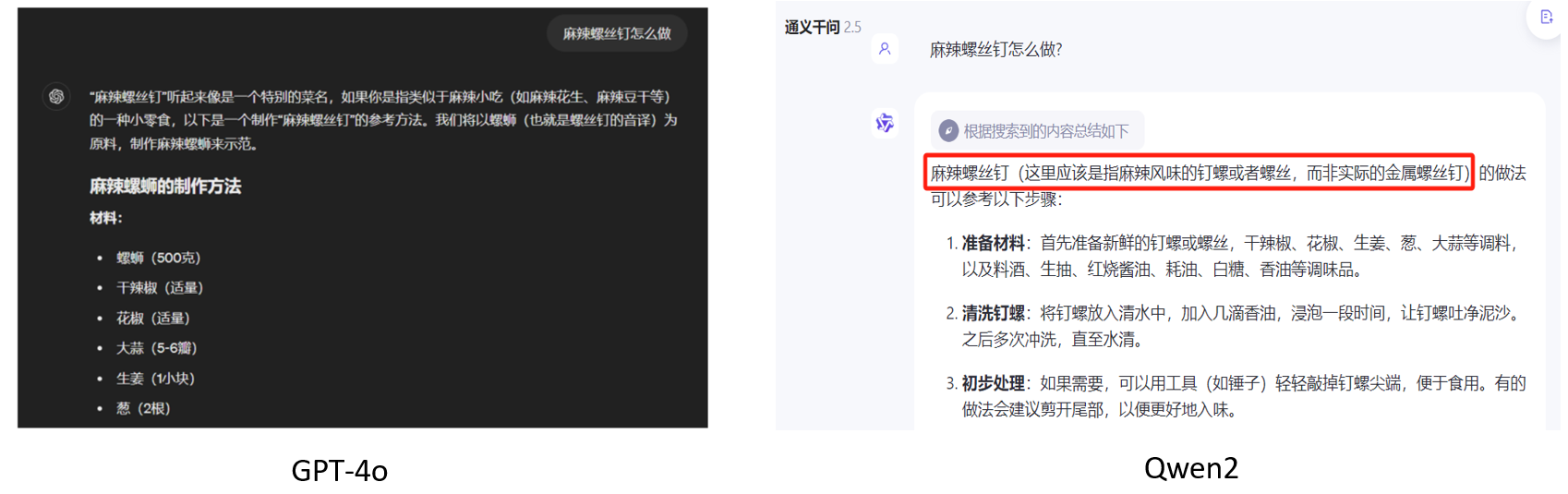
GPT-4o сначала не подумал, что это название блюда, но позже, отвечая, рассматривал его как блюдо и сообщал этапы приготовления. Qwen2 же сначала подумал, что я допустил опечатку, поскольку не было названия блюда «Винт», а затем исправил его, прежде чем ответить. Поэтому я считаю, что ответ Qwen2 на этот вопрос весьма хорош.
Второй вопрос заключается главным образом в том, чтобы определить, могут ли две разные модели распознавать текстовые эмоции пользователя. Судя по заключению, оба они относительно точны в определении эмоциональных символов в предложениях.
Вопрос 2: Пожалуйста, оцените эмоции, выраженные в этих предложениях: Мой кот такой милый♥♥
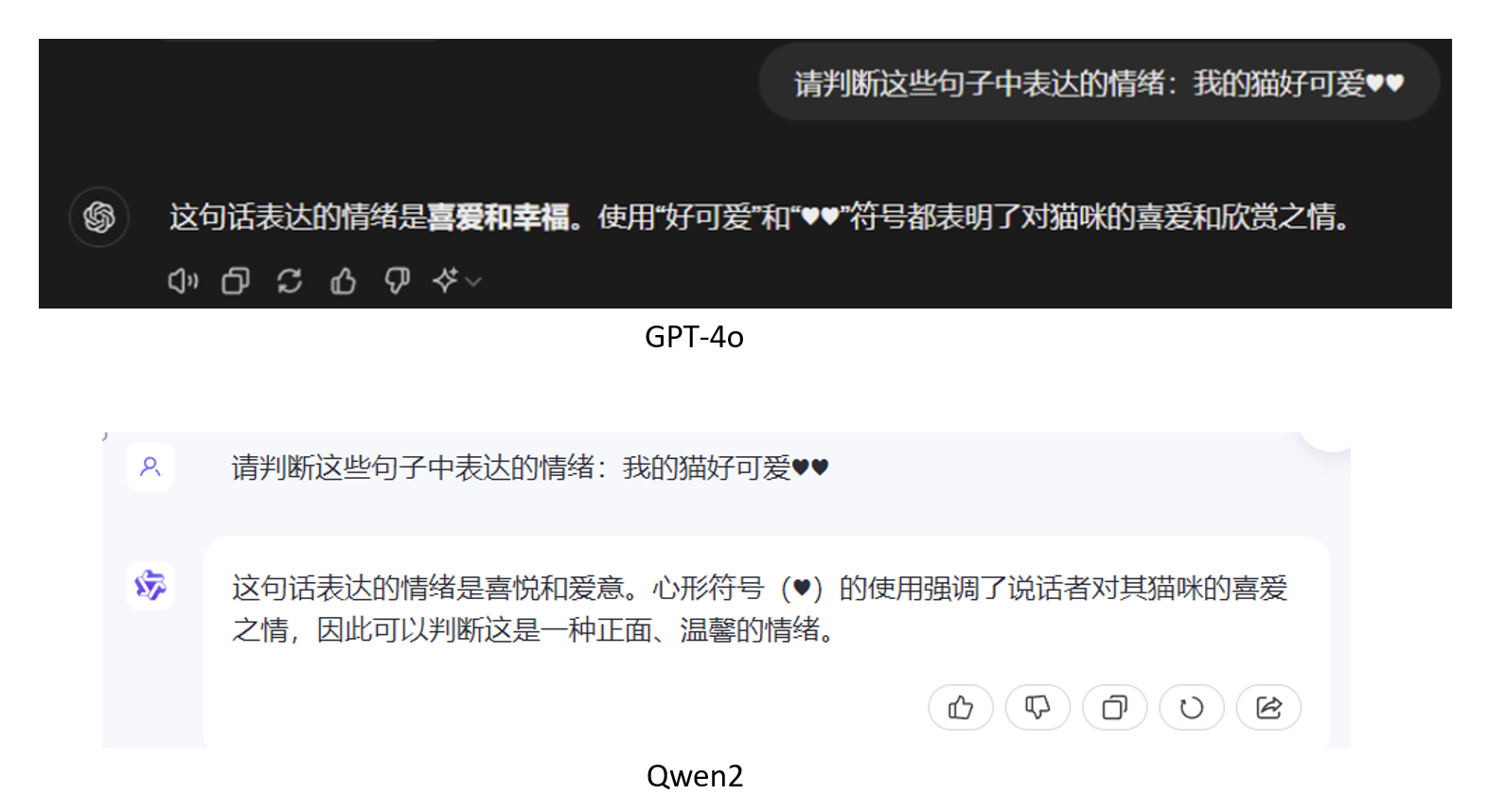
Третий вопрос касается способности к математическим расчетам.
Вопрос 3: Предполагая, что автомобиль может разгоняться от 0 до 27,8 м/с за 3,85 с, рассчитайте ускорение этого автомобиля в м/с/с.
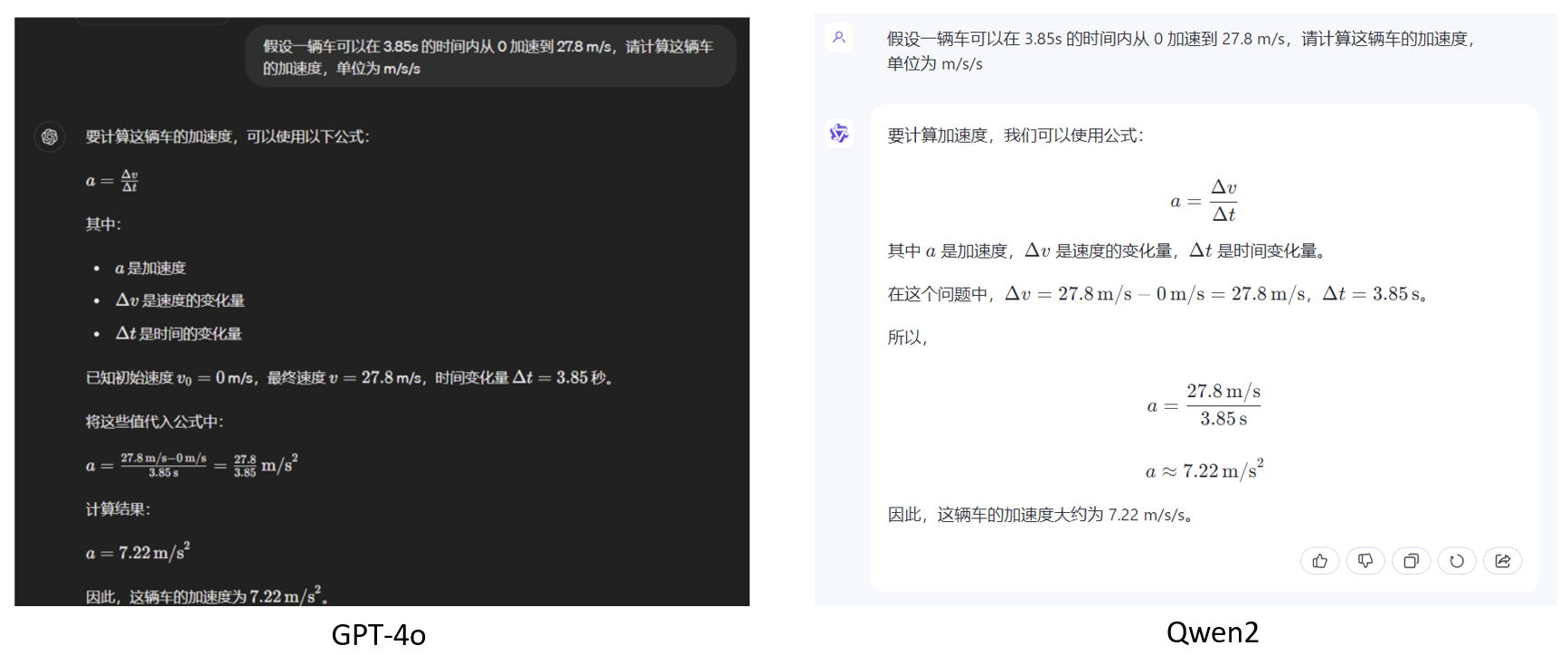
Обе модели дают полные шаги и результаты для математических рассуждений с кратким ответом. По внешнему виду Qwen2 больше похож на наши обычные шаги по решению математических вычислений.
Четвертый вопрос в основном заключается в том, чтобы проверить, может ли он идентифицировать некоторых общественных деятелей. GPT-4o может очень хорошо завершить эту фигуру, но Qwen2 не добился результатов в распознавании изображений.
Вопрос 4: Кто этот человек на картинке?
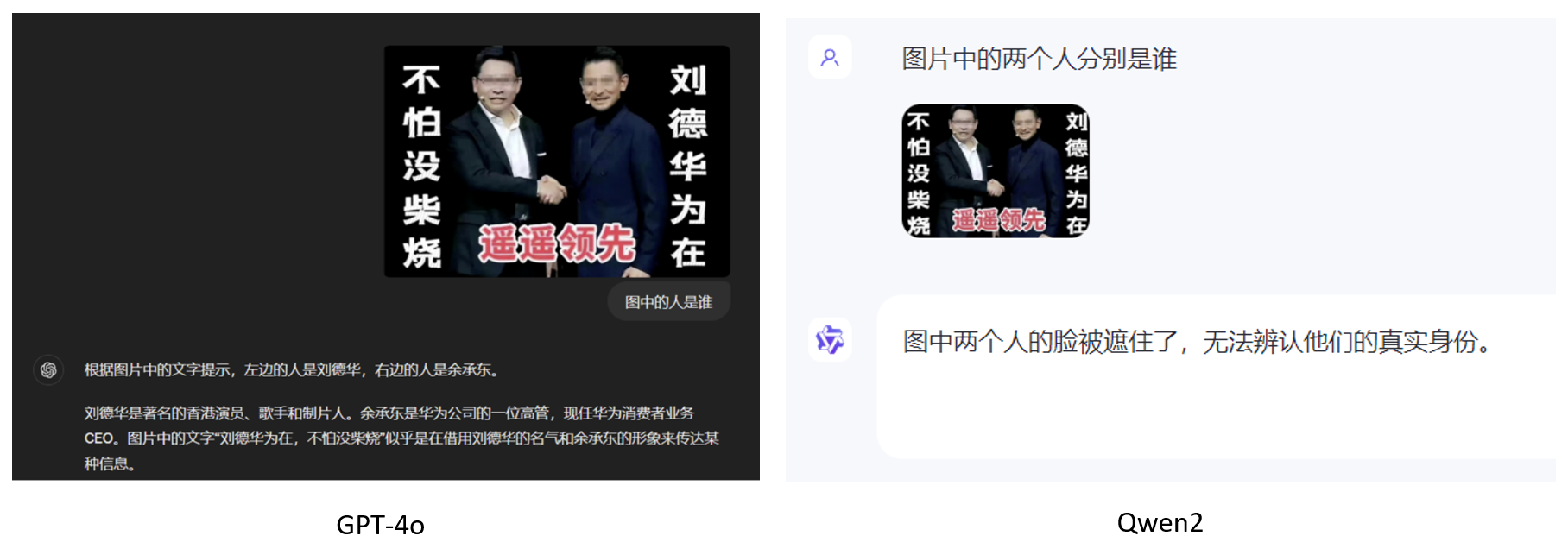
Локальное развертывание и вывод
Вы можете скачать модель и код для вывода в HuggingFace:
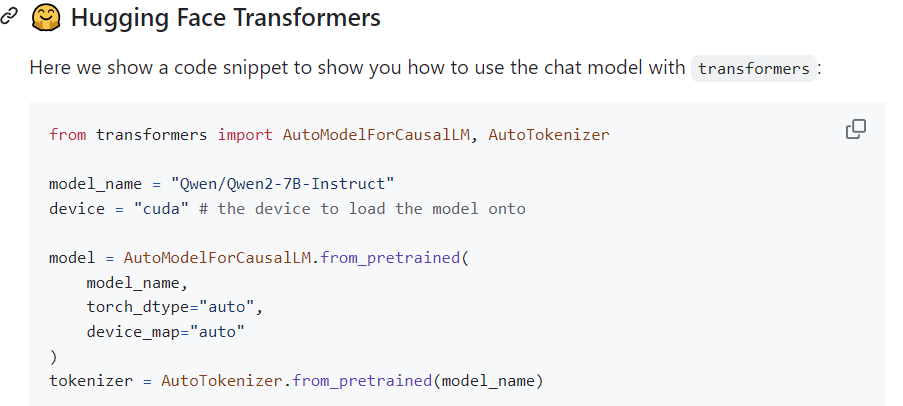
Вы можете использовать следующий код для выполнения Локального развертывание и вывод:https://github.com/QwenLM/Qwen2
Подвести итог
В настоящее время Qwen2 как модель с открытым исходным кодом Эффект по-прежнему хорош, и он может победить Открытый исходный О модели LLAMA3 от Code могу сказать только одно: большие китайские модели просто потрясающие!
После тестирования множества проблем мы обнаружили, что опыт использования мало чем отличается от GPT-4o. Модель Qwen2 не только обладает превосходными характеристиками, но и продолжает совершенствоваться. С выпуском Qwen2 сообщество открытого исходного кода также способствует непрерывной разработке больших моделей с открытым исходным кодом.
DeepSeek V2: более крупная и мощная модель
Компания «Глубокий поиск» выпустила большую модель DeepSeek второго поколения с объёмом параметров до 236Б.

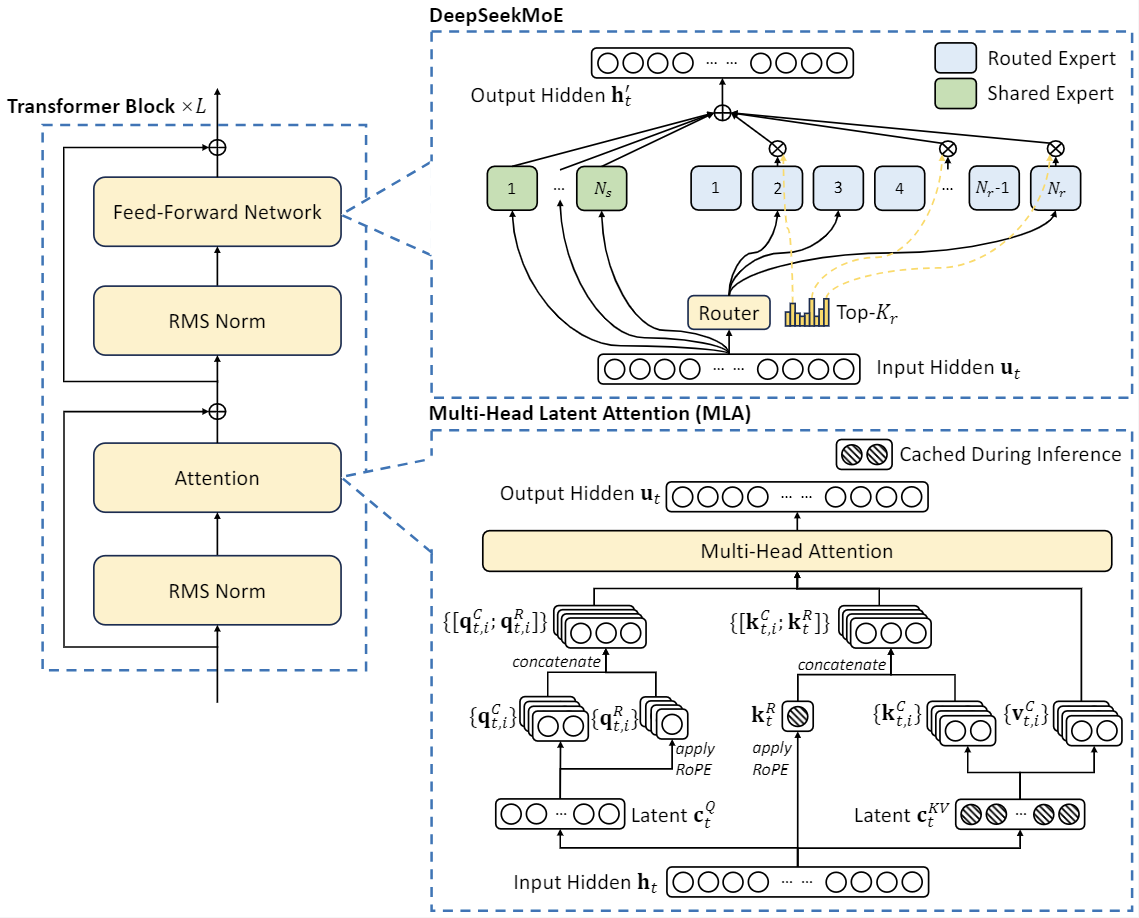
Точками оптимизации модели являются: - Модель больше, а эффект лучше: по сравнению с версией v1 модели 67B, в настоящее время Модель с открытым исходным Размер параметра codem достигает 236B, что близко к Открытому на нескольких наборах тестовых данных. исходный Модель Llama3-70B по коду - Вызовы API дешевле: за миллион token входить 0.14 долларов США (ок. 1 юань юаня), выход 0.28 долларов США (ок. 2 Юань (RMB) - Поддержка эффективных рассуждений: в архитектуре MOE установлена новая мультиголовка. latent внимание (MLA) для ускорения вывода модели
Конкретную загрузку модели с открытым исходным кодом можно найти здесь:
Оценка модели
На рисунке ниже показан расчет по оси абсцисс параметров, активируемых входтокеном, для разных моделей. Например, модель DeepSeek-V2.,Количество параметров активации для каждого токена составляет 21B.,Следовательно, это эквивалентно меньшему количеству активации токена.,В то же время, тем выше производительность набора данных MMLU.,тогда модель сильнее.
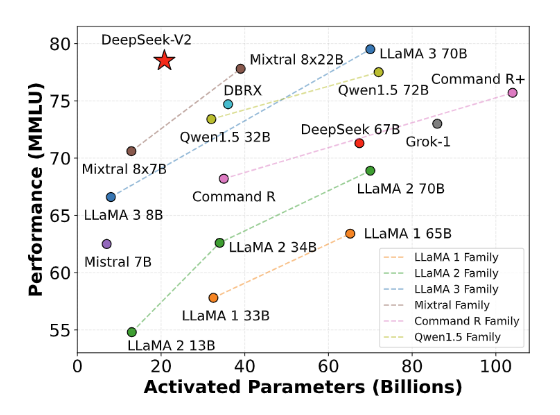
Таким образом, судя по рисунку, модель DeepSeek V2 добилась лучших результатов при небольшом количестве активации токена.
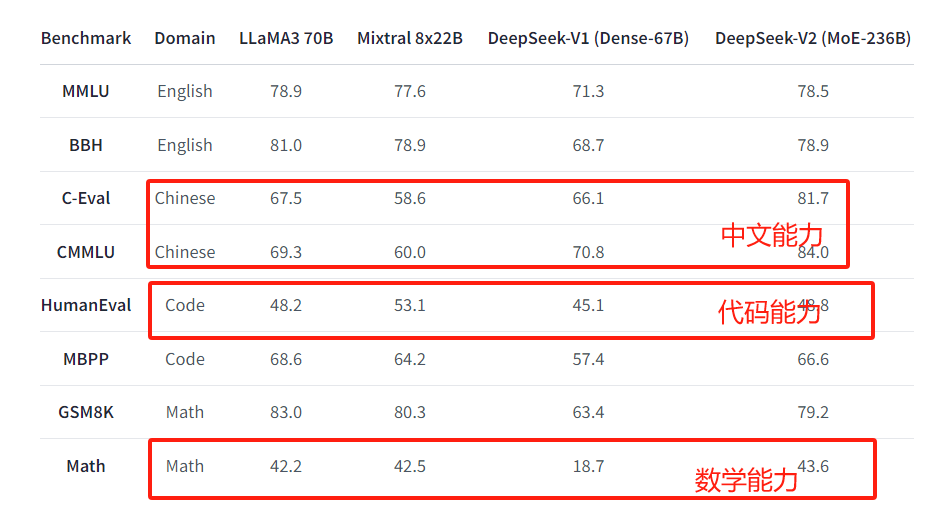
На обычном тестовом наборе он уже превосходит существующий LLama3-70B с открытым исходным кодом по математике, коду и оценке набора данных на китайском языке.
В эксперименте «Иголка в стоге сена»,контекст вхождения длиной 128 КБ,Есть только некоторые ошибки около 25K,В целом, производительность в принципе хорошая.
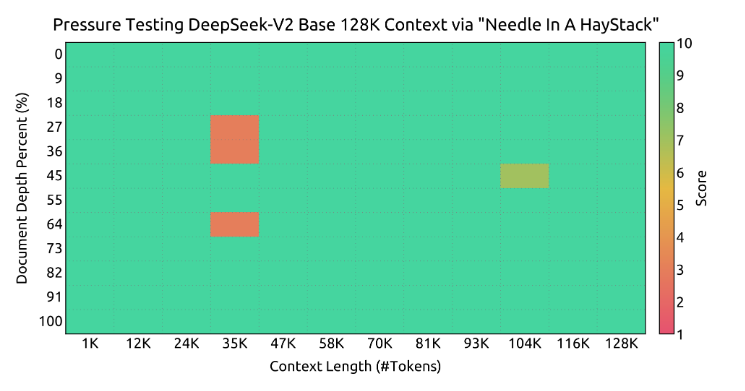
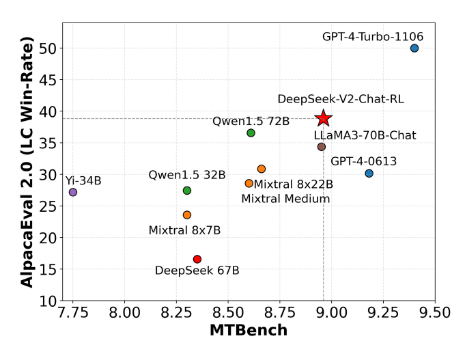
Аналогично в AlpacaEval 2.0 and В тесте MTBench модель практически превзошла текущую Модель. с открытым исходным кодом:
Что касается модели, архитектура MOE по-прежнему используется в целом. Существует две области оптимизации: - Разработан новый механизм многоголового латентного внимания (MLA), который использует совместное сжатие ключей низкого ранга для устранения ключей. кэширование значений во время вывода, тем самым поддерживая эффективный вывод. MLA по существу проецирует QKV в пространство низкого ранга, тем самым уменьшая параметры и ускоряя рассуждения. - Для сети прямой связи (FFN) мы используем архитектуру DeepSeekMoE, высокопроизводительную архитектуру MoE, которая позволяет обучать более сильные модели с меньшими затратами.
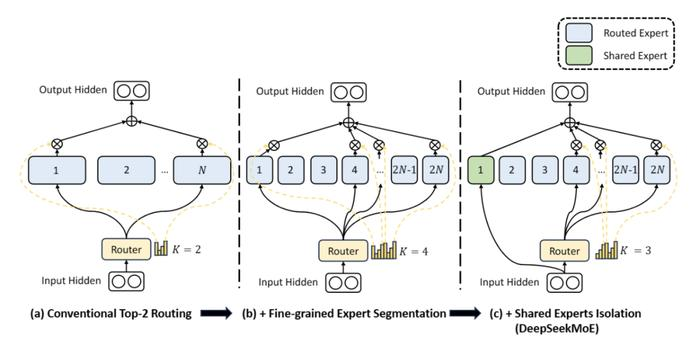
Среди них архитектура DeepSeekMoE в основном состоит из двух методов преобразования: - Детальное экспертное разделение: разделение предыдущих N экспертов на еще 2N экспертов, как показано (b) на рисунке ниже. - Разделение общих экспертов: активация экспертов. Разделение на общих экспертов. (Общий эксперт) и независимых экспертов по маршрутизации (Маршрутизированный эксперт), как показано на рисунке 4(c) выше. Это способствует сжатию общих и общих знаний в общие параметры и уменьшению избыточности знаний между параметрами независимых экспертов по маршрутизации.
Оценка эффекта модели DeepSeek-V2
Возьмите те же вопросы, что и выше, и проверьте эффект модели.
В1: понимание здравого смысла: как сделать острые винты?
Я не правильно ответила, названия этого блюда не существует.
Второй вопрос заключается главным образом в том, чтобы определить, может ли модель распознавать текстовые эмоции пользователя. Таким образом, распознавание эмоциональных символов в предложениях является относительно точным.
Вопрос 2: Пожалуйста, оцените эмоции, выраженные в этих предложениях: Мой кот такой милый♥♥

Третий вопрос касается способности к математическим расчетам.
Вопрос 3: Предполагая, что автомобиль может разгоняться от 0 до 27,8 м/с за 3,85 с, рассчитайте ускорение этого автомобиля в м/с/с.

Он все еще может отвечать на простые математические вопросы.
Подвести итог
общий,На данный момент преимуществом DeepSeek является то, что модель крупнее.,и в Модель с открытым исходным Он находится в авангарде кодома, а цена вызова API только GPT-4-Turbo. Почти один процент. Таким образом, вам вообще не придется беспокоиться о вызове API. Однако DeepSeek также имеет определенные ограничения. Прежде всего, его данные Обучение может не охватывать все области знаний, поэтому оно может не работать так же хорошо, как другие модели, при решении некоторых конкретных задач. Во-вторых, хотя вызов API обходится дешево, долгосрочное широкомасштабное использование все же может оказать определенное экономическое давление на крупные предприятия или исследовательские институты. В целом, DeepSeek хорош в моделировании. с открытым исходным Кодом имеет большие преимущества и ценовые преимущества, но все же существуют компромиссы с точки зрения конкретных проблем и долгосрочного использования.
Выше приведено все содержание этой статьи. Меня зовут Лео. Увидимся в следующем выпуске~.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
