Как выполнить инкрементную синхронизацию данных на основе DataX?
Оглавление
1. Принцип синхронизации данных DataX2. Полностью синхронизированная реализация3. Мысли об инкрементной синхронизации4. План реализации добавочной синхронизации5. О высокой доступности DataXссылка
1. Принцип синхронизации данных DataX
DataX — это версия с открытым исходным кодом интеграции данных Alibaba Cloud DataWorks, инструмента/платформы для автономной синхронизации данных, широко используемой в Alibaba Group. DataX реализует эффективную синхронизацию данных между различными разнородными источниками данных, включая MySQL, Oracle, OceanBase, SqlServer, Postgre, HDFS, Hive, ADS, HBase, TableStore (OTS), MaxCompute (ODPS), Hologres, DRDS, databend и т. д. Функция.
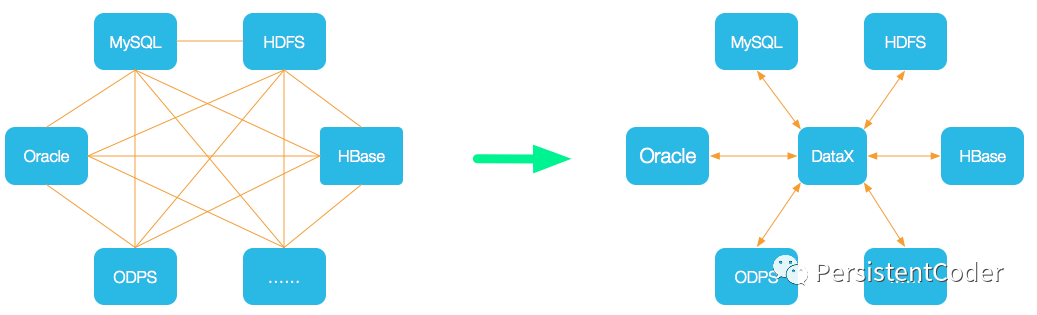
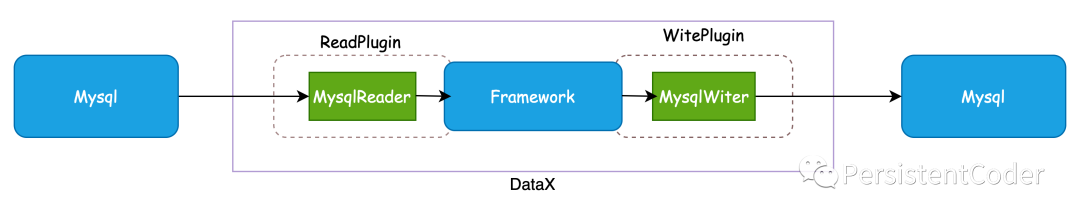
Сам DataX, как платформа автономной синхронизации данных, построен с использованием архитектуры плагинов Framework +. Абстрактное чтение и запись источников данных в подключаемые модули Reader/Writer и включение их во всю структуру синхронизации.
- Reader: Reader — это модуль сбора данных.,данные, ответственные за сбор источников данных,Отправьте данные в Framework.
- Writer: Writer — это модуль записи данных.,Отвечает за постоянный запрос информации из Framework.,И запишите данные в место назначения.
- Фреймворк: Фреймворк используется для соединения читателя и писателя.,В качестве канала передачи данных для обоих,и обрабатывать буферизацию,контроль потока,одновременно,преобразование данных и другие основные технические вопросы.
Версия DataX 3.0 с открытым исходным кодом поддерживает многопоточный режим на одном компьютере для выполнения синхронного выполнения задания. На следующем рисунке представлена временная диаграмма жизненного цикла задания DataX. На ней кратко объясняется взаимосвязь между каждым модулем DataX в общей конструкции архитектуры. .
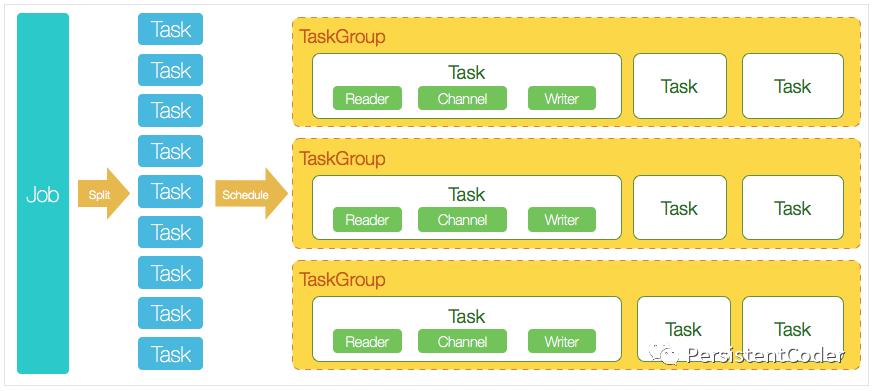
Введение основного модуля:
- DataX выполняет задание для одного синхронного данных.,Мы называем это Иов,После того, как DataX получит задание,Будет запущен процесс для завершения всего синхронного процесса задания. Модуль DataX Job — это центральный узел управления для одного задания.,предполагалосьданныеубирать、Сегментация подзадач (преобразование одного расчета задания в несколько подзадач)、Управление TaskGroup и другие функции.
- После запуска DataXJob,Будет основано на различных стратегиях сегментации источников.,Разделите работу на несколько небольших задач (подзадач),Для облегчения выполнения одновременно. Задача — это наименьшая единица задания DataX.,Каждая Задача будет отвечать за часть синхронной работы данных.
- После разделения нескольких задач DataX JobпозвонюSchedulerмодуль,Согласно настроенному количеству одновременноданных,Объедините разделенные задачи,Собирается в TaskGroup (группу задач). Каждая группа задач отвечает за выполнение всех назначенных задач в определенное время.,По умолчанию количество одновременно для одной группы задач — 5.
- Каждая задача запускается TaskGroup,После запуска задачи,Всегда будет начинатьсяReader—>Channel—>Writerнить для выполнения задачисинхронный Работа。
- После запуска задания DataX задание отслеживает и ожидает завершения нескольких задач модуля TaskGroup, а также ожидает завершения всех задач TaskGroup перед успешным завершением задания. В противном случае процесс завершается ненормально, и значение завершения процесса не равно 0.
Процесс планирования DataX:
Например, пользователь отправил задание DataX и настроил 20 параллелизмов для синхронизации данных MySQL из 100 таблиц с ODPS. Идея принятия решений по планированию DataX заключается в следующем:
- DataXJob разделен на 100 задач на основе подбаз данных и таблиц.
- По данным 20 одновременно, для расчета DataX необходимо выделить в общей сложности 4 группы задач.
- 4 группы задач делят 100 разделенных задач поровну.,Каждая группа задач отвечает за выполнение в общей сложности 25 задач, 5 из которых выполняются одновременно.
2. Полностью синхронизированная реализация
1. Окружающая среда
Datax использует среды Python, Java и Maven. Рекомендуется установить python2.7, jdk1.8 и maven3.6. Процесс установки не будет подробно описан.
2. Установите данные
mkdir -p /opt/tools/datax
cd /opt/tools/datax
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar zxf datax.tar.gz -C /usr/local/
rm -rf /usr/local/datax/plugin/*/._*3. Написать скрипты синхронизации
Просмотр шаблонов синхронизации:
python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriterФормат выходного шаблона:
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}Измените его в соответствии с форматом шаблона, замените источник данных и целевые таблицы, а также секреты учетной записи и создайте сценарий *.json в каталоге /usr/local/datax/script:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "source_user",
"password": "pwd",
"column": ["*"],
"splitPk": "ID",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://sourceHost:port/database"
],
"table": ["source_table"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://targetHost:port/database",
"table": ["target_table"]
}
],
"password": "pwd",
"preSql": [
"truncate target_table"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "target_user",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5",
"byte" : 5242880
}
}
}
}Следует отметить следующее:
- Машина datax имеет доступ к машине-источнику данных и порту.,Используемая учетная запись имеет разрешения на чтение библиотеки данных и таблиц.
- Машина Datax имеет доступ к целевой машине и порту.,Используемая учетная запись имеет разрешения на запись в библиотеку данных и таблицы.
4. Выполните синхронизацию
Выполняем скрипт синхронизации:
python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.jsonНо есть проблема. Команда синхронная. Окно должно быть активным во время процесса выполнения, и клиент не может быть отключен, иначе задача будет прекращена. Поскольку журнал выполнения является консольным выводом, журнал выполнения невозможно просмотреть. после завершения выполнения, поэтому нам необходимо изменить команду на выполнение без приостановки и вывести журнал выполнения в указанный каталог. Замените его следующей командой:
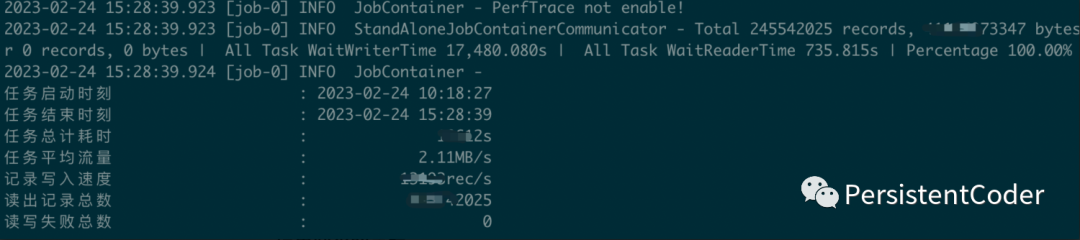
nohup python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json >> /var/log/datax/xxx.log 2>&1 &Таким образом, нет необходимости постоянно блокировать окно, и ssh-клиент не будет отключен по сетевым причинам, что приведет к завершению задачи. Если вы видите в журнале следующее содержимое, это означает, что задача синхронизации успешно выполнена:
3. Мысли об инкрементной синхронизации
Конечно, нам не нужно выполнять полную синхронизацию каждый раз, когда мы синхронизируем данные. Итак, если некоторые таблицы уже были синхронизированы один раз, как выполнить инкрементальную синхронизацию?
Прежде всего, Datax — это синхронизация одной таблицы, поэтому, если нам нужно выполнить инкрементальную синхронизацию, нам нужно знать, какова «сумма» приращения и каковы правила измерения.
- Приращение относится к расстоянию с последнего времени (полная сумма или приращение).,Увеличено количество строк данных.,Это также космический диапазон, который на этот раз нуждается в синхронности.
- правила измерения,Разумеется, в качестве правил измерения мы выберем столбцы с растущей тенденцией.,Например, id автоматически увеличивает первичный ключ.,время создания данных.
Поскольку тенденция роста таблицы неопределенна, начальное и конечное значения id для инкрементальной синхронизации определить невозможно, а тенденцию роста id нельзя использовать в качестве правила измерения. Однако время — это инкрементный показатель, на который мы можем рассчитывать. и определить, например, синхронизацию T+1. То есть синхронизировать данные предыдущего дня 24 часа, синхронизировать раз в 5 минут и т. д. Мы можем определить моменты начала и окончания с помощью простых вычислений.
Конечно, инкрементальная синхронизация не означает синхронизацию в режиме реального времени или почти в реальном времени. Она больше используется в сценариях резервного копирования данных и автономных вычислений. Datax сам по себе не очень хорош для выполнения этих задач. требований реального времени, вы можете использовать другие методы, такие как инструменты синтаксического анализа binlog и т. д. Следовательно, инкрементную синхронизацию, о которой мы здесь говорим, также можно понимать как сценарии данных, в которых данные не будут меняться, или как данные с относительно коротким жизненным циклом.
В качестве обратного примера, для данных о возврате электронной коммерции временной цикл бизнес-сценария относительно длинный, поэтому от создания заказа на возврат до возврата товаров на склад может пройти несколько дней, а также может потребоваться десять с половиной месяцев или даже больше, чтобы пересечь границу в течение длительного времени, тогда в определенной степени или в определенном диапазоне данных использовать Da нецелесообразно. Tax выполняет инкрементную синхронизацию, поскольку данные, синхронизированные в T+1 или T+n, все равно могут измениться. Если обработка не будет выполнена, возникнут проблемы со строгостью и точностью синхронизированных данных. Если будет выполнена компенсационная обработка, процесс синхронизации завершится. изменить заново. Это чрезвычайно сложно, поэтому лучше рассмотреть другие, более качественные и подходящие решения.
Таким образом, использование Datax для выполнения инкрементной синхронизации данных в автономном режиме больше подходит для сценариев, в которых жизненный цикл данных относительно короткий, таких как пополнение счета, снятие средств, игровые заказы и т. д., а также для сценариев, в которых точность периферийных данных невысока.
4. План реализации добавочной синхронизации
Причина, по которой ее называют инкрементной синхронизацией, заключается в том, что это либо запуск в реальном времени, либо запуск с фиксированной частотой, а Datax больше подходит для запуска с фиксированной частотой. Фиксированная частота не может избежать планирования. Datax — это автономный инструмент синхронизации, поэтому мы можем рассмотреть возможность регулярного запуска на основе crontab планирования, поставляемого с системой Linux, или с использованием платформы планирования с открытым исходным кодом.
1.crontab+shell
Используйте встроенную функцию планирования системы Linux crontab. Например, синхронизируйте один раз в день. Сценарий оболочки вычисляет время, а затем прозрачно передает его в условиеwhere файла конфигурации json Datax с помощью команды. можно рассчитать следующим образом:
where create_time >= UNIX_TIMESTAMP(date_sub(curdate(),interval 1 day))
and create_time < UNIX_TIMESTAMP(curdate());Читающую часть сценария синхронизации можно изменить следующим образом:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "source_user",
"password": "pwd",
"column": ["*"],
"splitPk": "ID",
"where": "create_time >= UNIX_TIMESTAMP(date_sub(curdate(),interval 1 day))
and create_time < UNIX_TIMESTAMP(curdate())";
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://sourceHost:port/database"
],
"table": ["source_table"]
}
]
}
},
"writer": ...
}
],
"setting": {
"speed": {
"channel": "5",
"byte" : 5242880
}
}
}
}Затем напишите расписание crontab:
crontab -e
0 0 1 * * ? * nohup python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json >> /var/log/datax/xxx.log 2>&1 &Выполняйте задачу каждый день в час ночи, чтобы синхронизировать данные предыдущего дня и тем самым добиться дополнительной синхронизации. Еще следует отметить, что условия инкрементной синхронизации требуют индекса, в противном случае можно легко загрузить процессор экземпляра базы данных.
2. Распределенное планирование + оболочка
Аналогичным образом мы можем использовать относительно зрелое в отрасли решение по планированию для запуска команд синхронизации для добавочной синхронизации. Например, xxl-job поддерживает задачи планирования оболочки.
Перейдите к машине Datax, чтобы написать сценарий оболочки:
#!/bin/bash
nohup python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json >> /var/log/datax/xxx.log 2>&1 &Создайте задачу оболочки:
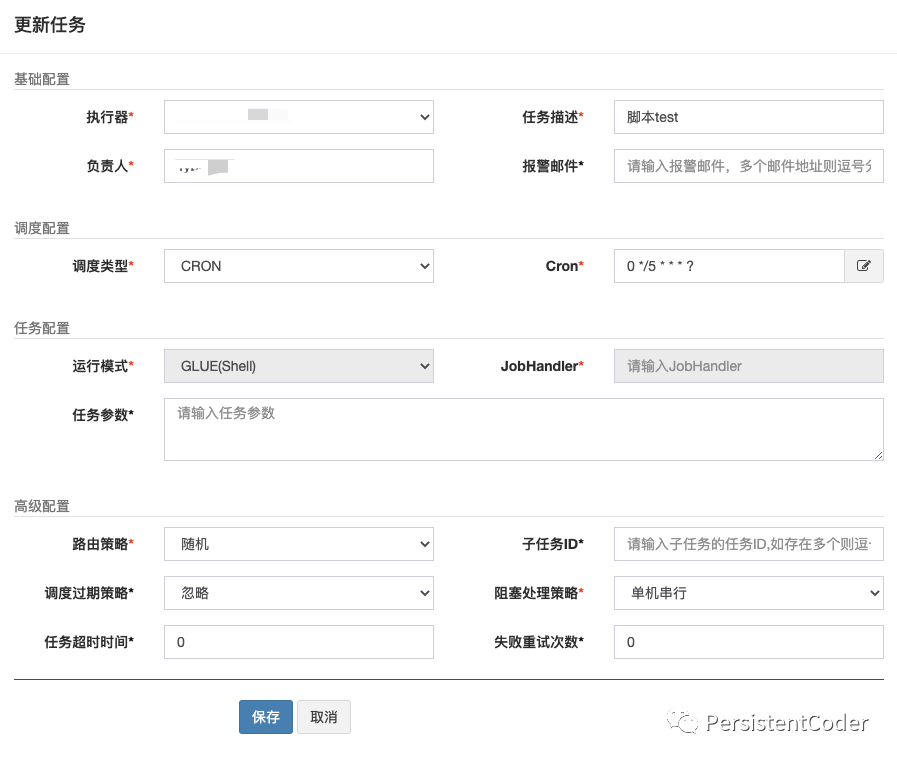
Напишите сценарий оболочки исполнителя:

Исходный код задачи-скрипта размещается в диспетчерском центре, а логика сценария запускается в исполнителе. Когда запускается задача сценария, исполнитель загружает исходный код сценария для создания файла сценария на компьютере исполнителя, а затем вызывает сценарий через код Java и записывает журнал вывода сценария в файл журнала задачи в режиме реального времени; что его можно просмотреть в режиме реального времени в диспетчерском центре. Следить за выполнением скрипта.
Следует отметить, что,Даже если вы просто хотите запланировать оболочку,Исполнитель по-прежнему необходим (конкретную причину можно найти в принципе выполнения задачи оболочки linkxxl-job),Вы можете написать простой исполнитель с помощью ссылкиxxl-job-executor-sample-springboot.
Но этот метод немного невзрачный. Нужно ли мне развертывать набор Java-сервисов, чтобы выполнить скрипт? В основном используется частота планирования xxl-задания, а затем, когда достигается узел времени выполнения, сценарий оболочки может выполняться удаленно, и можно решить беспарольный вход в систему и разрешения на выполнение между компьютерами в интрасети.
5. О высокой доступности DataX
Datax сам по себе является автономным инструментом синхронизации и, естественно, автономен. Так как же обеспечить высокую доступность, например, микросервисов или распределенного планирования?
Конечно, мы можем рассмотреть реализацию планирования xxl-задания. Когда кластер исполнителей будет развернут, все узлы будут зарегистрированы для администратора. Затем при запуске задачи исполнитель будет выбран в соответствии с политикой для выполнения. сообщается об ошибке или выполнение завершается неудачно, таким же образом можно выполнить такое же выполнение команд синхронизации Datax. Вы можете себе представить, что мы регистрируем все машины, на которых развернут инструмент синхронизации DataX, в xxl-задании. платформу планирования, настройте стратегию планирования и отправьте команды удаленного сценария оболочки для выполнения синхронизации при запуске задачи. Если выполнение не удалось, попробуйте другое.
К счастью, кто-то уже это сделал. Веб-инструмент DataX был написан на основе DataX. Его интеграция и вторичная разработка xxl-job реализуют инкрементальную синхронизацию данных на основе времени и автоматического увеличения первичных ключей. «Исполнитель» задачи поддерживает развертывание кластера, выбор стратегии многоузловой маршрутизации исполнителя, контроль тайм-аута, повторную попытку сбоя, сигнализацию сбоя, зависимость задачи, процессор исполнителя, память, мониторинг нагрузки и т. д.
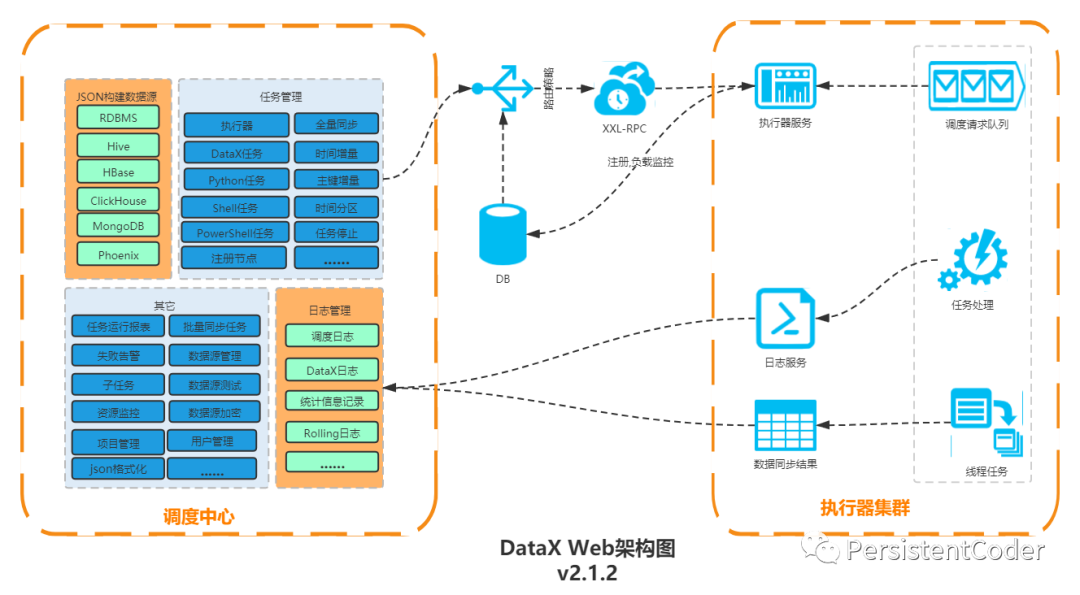
Подробности можно найти в документе по ссылке:
https://github.com/WeiYe-Jing/datax-web
ссылка
https://github.com/alibaba/DataX/blob/master/introduction.md
https://blog.csdn.net/zhuyu19911016520/article/details/124143716
https://github.com/WeiYe-Jing/datax-web


сравнение строк PHP
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
Go: Лесоруб-лесоруб на колесах Введение

Основы серверной разработки: технология кэширования, которую должен освоить каждый программист

Java Advanced Collections TreeSet: что это такое и зачем его использовать?
Оказывается, у команды go build столько знаний

Node.js
Анализ исходного кода, связанный с запланированными задачами версии ruoyi-vue (7), то есть анализ модуля ruoyi-quartz.

Вход в систему с помощью скан-кода WeChat (1) — объяснение процесса входа в систему со скан-кодом, получение авторизованного QR-кода для входа.

HikariPool-1 — обнаружено отсутствие потока или скачок тактовой частоты, а также конфигурация источника данных Hikari.
Сравнение высокопроизводительной библиотеки JSON Go

Простое руководство по извлечению аудио с помощью FFmpeg

Подсчитайте количество строк кода в проекте

Spring Boot элегантно реализует многопользовательскую архитектуру: концепции и практика

Как интегрировать функцию оповещения корпоративного WeChat в систему планирования xxl-job

SpringBoot интегрирует отправку сообщений через веб-сокет в режиме реального времени

Краткий анализ основных библиотек журналов в Go: узнайте, как интегрировать функции вращения и резки бревен на уровне проектирования.
Реализация API-шлюза с нуля-Golang

[Разговорный сайт] Как Springboot получает значения свойств из файлов конфигурации yml или свойств

Spring Boot — синхронные события приложения против асинхронных событий публикации и подписки. Практический бой

Spring Boot использует Swagger3 для создания документов интерфейса API.

[1269] Использование Gunicorn для развертывания проектов flask.

Краткое изложение 10 способов регистрации bean-компонентов в SpringBoot

Flask Learning-9. 2 способа включения режима отладки (debug mode).
Руководство по настройке самостоятельного сервера для Eudemons Parlu

40 вопросов для собеседований по SpringBoot, которые необходимо задавать на собеседованиях! При необходимости ответьте на вопросы для собеседования SpringBoot [предлагаемый сборник] [легко понять]
Через два года JVM может быть заменен GraalVM.
