Как выбрать стратегию соединения в SparkSQL
1. Предисловие
Операция соединения является важной операцией в области анализа больших данных. В этой статье будут представлены пять основных стратегий соединения, поддерживаемых SparkSQL, и сценарии их применения на принципиальном уровне.
SparkSQL имеет пять встроенных стратегий подключения, как показано ниже.
1、Broadcast Hash Join(BHJ)
2、Shuffle Hash Join
3、Shuffle Sort Merge Join(SMJ)
4、Cartesian Product Join
5、Broadcast Nested Loop Join(BNLJ)
2. Факторы, влияющие на выбор стратегии
(1) Является ли это равноценным соединением
Equijoin — это условие соединения, при котором только equals Сравнение, неэквисоединение содержит, кроме equals Любое сравнение, кроме >,<,>=,<=。длянеэквивалентныйсоединять,SparkSQL Поддерживает только Broadcast Nested Loop Join и Cartesian Product Присоединиться. Другие стратегии соединения поддерживают равные соединения.
(2) Пользовательское приглашение на подключение (подсказка)
Spark 3.0 поддерживает следующие подсказки (в файлеhints.scala):
BROADCAST, SHUFFLE_MERGE, SHUFFLE_HASH, SHUFFLE_REPLICATE_NL
(3) Размер подключенного набора данных
Наиболее важным фактором при выборе стратегии подключения является размер набора данных. Основная стратегия — избегать. shuffle и Операции сортировки очень дороги и сильно влияют на производительность запросов.
3. Блок-схема
Нарисована блок-схема, описывающая, как Spark SQL выбирает стратегию подключения:
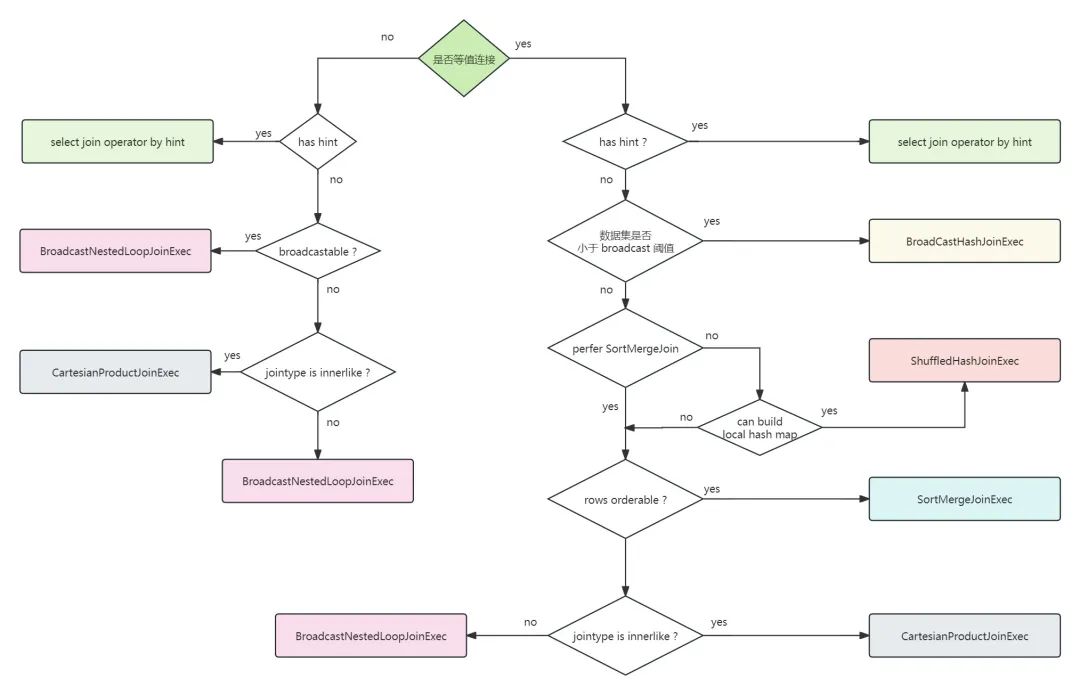
4. Процесс выбора стратегии
Сначала определите, является ли это соединение равным значением, и оно войдет в другой основной процесс.
1. Эквивалентное соединение
(1) Подсказка о подключении, указанная разработчиком, имеет наивысший приоритет.
Для подсказки BROADCAST выберите стратегию Broadcast Hash Join. Если подсказка BROADCAST указана на обеих сторонах объединения, выберите сторону с меньшим набором данных.
Для подсказки SHUFFLE_HASH выберите стратегию Shuffle Hash Join. Если подсказка SHUFFLE_HASH указана на обеих сторонах объединения, выберите сторону с меньшим набором данных.
Для приглашения SHUFFLE_MERGE, если ключ объединения является сортируемым, выберите стратегию случайной сортировки слиянием;
Для приглашения SHUFFLE_REPLICATE_NL, если тип соединения является внутренним, выберите стратегию объединения декартовых продуктов.
(2) Затем определите размер набора данных.
Когда хотя бы одна сторона в подключенном наборе данных достаточно мала для сбора driver конец, а затем транслировать каждому executor Когда, Трансляция Hash Join является предпочтительной стратегией. Пороговый размер набора данных, который может транслироваться, по умолчанию равен 10 м, могу пройти spark.sql.autoBroadcastJoinThreshold Параметры для настройки в зависимости от driver и executor доступная память в конце.
Когда выполняется оператор BroadcastExchange, он сначала собирает набор данных для драйвера, а затем передает его всем узлам-исполнителям. Обратите внимание, что количество строк в наборе данных не может превышать MAX_BROADCAST_TABLE_ROWS (340 миллионов строк), иначе он не будет транслироваться.
На стороне исполнителя набор широковещательных данных используется в качестве подключенной таблицы buildTable, а набор данных, который изначально существовал в исполнителе, то есть подключенная большая таблица, используется в качестве подключенной таблицы StreamTable. В процессе подключения используется таблица StreamTable. пройденные и совпадающие строки находятся в buildTable.
(3) Если выбранная стратегия BroadcastHash не удовлетворяет, определите, следует ли установить стратегию Shuffle Sort Merge Join в качестве предпочтительной, управляемой параметром spark.sql.join.preferSortMergeJoin, который по умолчанию имеет значение true.
Если этот параметр задан явно false, затем определите, следует ли использовать Shuffle Hash Join Условия реализации стратегии: хотя бы один связанный набор данных должен быть достаточно небольшим, чтобы построить hash таблицу (чтобы меньшие наборы данных можно было загрузить в память проживания). Его размер должен быть меньше порога трансляции и shuffle произведение номеров разделов
private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
}
Кроме того, больший набор данных должен быть как минимум в 3 раза больше меньшего набора данных, и на этом этапе выгоды будут больше.
private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
}
Когда выполняется Shuffle Hash Join, два набора данных будут перетасованы, так что строки с одинаковым ключом соединения в обоих наборах данных будут помещены в один и тот же исполнитель. Меньший набор данных используется как buildTable, а больший набор данных используется как StreamTable.
(4) Если вышеуказанные условия не выполняются, начните определять, следует ли использовать соединение слиянием с произвольной сортировкой. Чтобы использовать алгоритм соединения на основе сортировки, ключ соединения должен быть сортируемым.
Shuffle Sort Merge Join Никакие наборы данных не нужно загружать в память, поэтому размер объединяемого набора данных не ограничен. Алгоритмы соединения на основе сортировки не основаны на hash Соединять быстрее, но обычно он работает лучше, чем алгоритм соединения с вложенным циклом, поэтому, основываясь на двойных соображениях производительности и гибкости, Sort Merge Join Это компромисс.
Shuffle Sort Merge Join также необходимо перетасовать связанные наборы данных, чтобы строки с одинаковым ключом соединения в обоих наборах данных были помещены в один и тот же исполнитель. Кроме того, данные каждого раздела необходимо отсортировать в порядке возрастания ключа соединения. .
Любой из двух объединенных наборов данных можно использовать как buildTable илиstreamTable. Когда набор данных представлен в виде таблицыstreamTable, он последовательно повторяется строка за строкой. Для каждой строкиstreamTable buildTable также ищется построчно по порядку. Поскольку все они отсортированы, когда процесс подключения переходит кstreamTable следующей строки, buildTable не обязательно начинать с первой строки, а нужно только запустить. из предыдущего. Просто продолжайте поиск совпадающих строк.
(5) Если условия стратегии соединения слиянием в случайном порядке и сортировкой не выполняются, а тип соединения — InnerLinke, будет использоваться стратегия декартова соединения продуктов, и условия соединения обычно не могут быть определены. Декартово произведение будет очень медленным и склонным к ошибкам, поэтому используйте его с осторожностью;
(6) Если ни одно из вышеперечисленных условий не выполнено, он выберет BroadcastNestedLoopJoin , в это время streamTable и buildTable Сделать вложенный цикл
private def innerJoin(relation: Broadcast[Array[InternalRow]]): RDD[InternalRow] = {
streamed.execute().mapPartitionsInternal { streamedIter =>
val buildRows = relation.value
val joinedRow = new JoinedRow
streamedIter.flatMap { streamedRow =>
val joinedRows = buildRows.iterator.map(r => joinedRow(streamedRow, r))
if (condition.isDefined) {
joinedRows.filter(boundCondition)
} else {
joinedRows
}
}
}
Эффективность этой стратегии также будет очень низкой.
2. Неэквивалентное соединение
Только две стратегии поддерживают неэквисоединения: декартова Product JoinиBroadcast Nested Loop Join。
Если в запросе на подключение указан запрос на подключение, выберите соответствующую политику подключения на основе запроса на подключение. В противном случае, если одна или обе стороны набора данных достаточно малы для трансляции, выберите стратегию Broadcast Nested Loop Join и транслируйте меньший набор данных. Если для широковещательной передачи недостаточно маленького набора данных, проверьте, является ли JointType InnerLike. Если да, выберите стратегию объединения декартовых продуктов, в противном случае выберите стратегию широковещательного соединения вложенного цикла в качестве окончательного решения.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
