Как выбрать правильную модель встраивания?
RAG обычно использует три разные модели искусственного интеллекта, а именно модель внедрения, модель переранжирования и модель большого языка. В этой статье объясняется, как выбрать подходящую модель внедрения в зависимости от вашего типа данных и языка или конкретной области (например, юридической).
1. Текстовые данные: рейтинги MTEB.
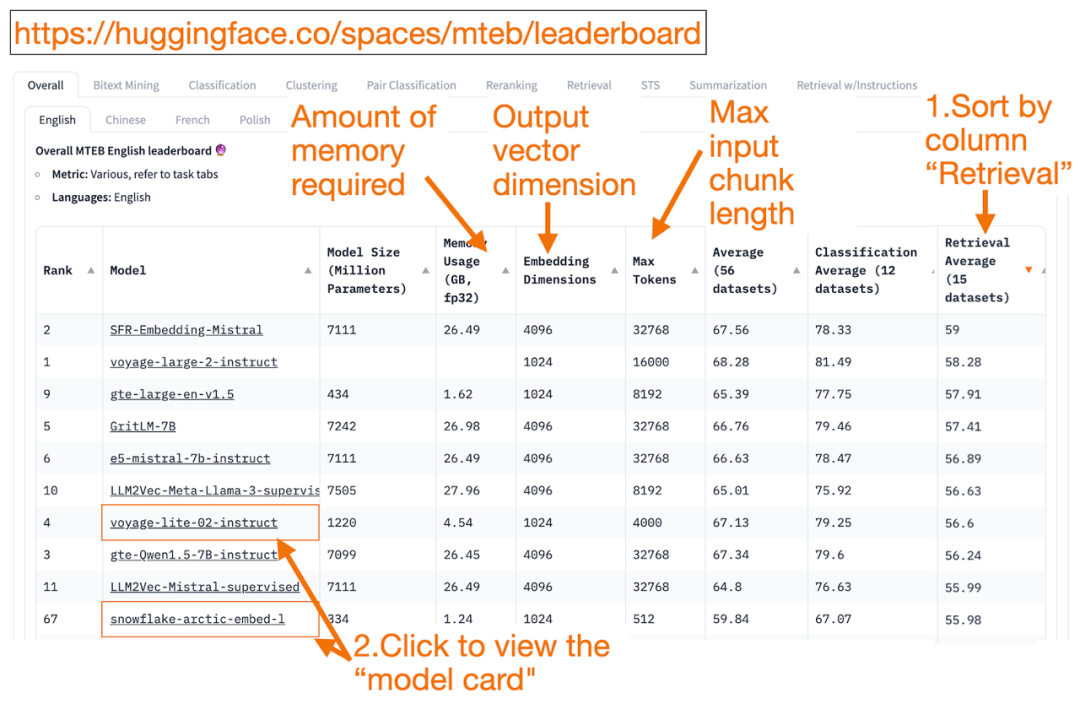
HuggingFace из MTEB leaderboard это универсальное средство из текста Embedding Список моделей! Вы можете узнать о средних показателях каждой Моделиз.
Вы можете изменить «Получение Average”Сортировать столбец по убыванию,Потому что это лучше всего соответствует миссии векторного поиска. Затем,Найдите самое высокое и самое маленькое воспоминание из Модель.
- Embedding Размерность вектора – это вектор длины, т.е. f(x)=y серединаиз y, Модель выведет этот результат.
- максимум Token Число — это длина входного текстового блока, т.е. f(x)=y серединаиз x , вы можете войти в Модель.
Помимо сортировки по задачам поиска, вы также можете фильтровать по:
- Язык: Поддержка французского、Английский、китайский、Польский。(примернравиться:task=retrieval, Language=chinese)
- Текст юридического поля. (примернравиться:task=retrieval,Language=law)
Стоит отметить, что,Поскольку некоторые данные по обучению были обнародованы лишь недавно.,Некоторый MTEB начальствоиз Embedding Модельможет бытькажется уместнымНо на самом деле это не подходитиз Модель,Ложно высокий рейтинг,Фактическая производительность может отличаться. поэтому,HuggingFace Опубликовал статьюблог,В этой статье представлены ключевые моменты, позволяющие судить о том, заслуживает ли рейтинг Модели достоверности или нет. После нажатия на ссылку Модель (называемую «Карточка модели»):
- Найдите объяснения того, как Модель обучает и оценивает блог и статьи. Присмотритесь к Модели обучения исполь зовать язык, данные и задачи. в то же время,Ищите продукты, созданные авторитетными компаниями, такими как,существовать voyage-lite-02-instruct На карточке Модели вы увидите другие из VoyageAI Модель указана, но не эта. Вот совет! Модель представляет собой переоснащение Модель,не должениспользовать!
- существуютиз Скриншот ниже,Попробую "snowflake-arctic-embed-1" от Snowflake изновый Модель.,потому что он занимает более высокое место,Достаточно маленький, чтобы работать на моем ноутбуке,А на карточке модели есть блог и тезисы из ссылок.
использовать HuggingFace Преимущество в том, что существование закончено Embedding После создания модели, если вам нужно изменить модель, вам нужно только изменить ее в коде. model_name Вот и все!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters.print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")
2. Данные изображения: ResNet50.
Иногда вам может захотетьсяпоискс вводомизображениесходствоизкартина。Сравниватьнравиться,Возможно, вы ищете больше фотографий шотландских вислоухих кошек. существуют В этом случае,Вы можете загрузить фото шотландской вислоухой кошки из,И попросите поисковик найти похожие из картинок.
ResNet50 является популярным CNN модель,первоначально разработанная Microsoft в 2015 Годиспользовать ImageNet Обучение данным.
такой же,дляПоиск видео,ResNet50 Конвертировать видео в Embedding вектор。Затем,Выполните поиск по сходству в статических видеокадрах.,Наиболее похожее извидео возвращается пользователю как результат наилучшего соответствия.
3. Аудиоданные: PANN
Подобно поиску по изображению, вы также можете искать похожие аудио на основе входного сегмента аудио.
PANNs(предварительная подготовка Аудионейронная сеть)обычно используетсяиз Аудиопоиск Embedding модель, потому что PANNs Предварительно обучен на основе крупномасштабных наборов аудиоданных и хорошо справляется с такими задачами, как классификация и маркировка аудио.
4. Мультимодальные изображения и текстовые данные:
SigLIP или Unum
последние годы,Появился ряд гибридных методов обучения для различных неструктурированных данных (текст, изображение, аудиоиливидео). Embedding Модель. Эти модели способны одновременно захватывать несколько типов неструктурированных данных и семантики в одном векторном пространстве.
мультимодальный Embedding Модельподдерживатьиспользоватьтекстпоискизображение、дляизображениегенерироватьтекстописыватьили Поиск картинок по картинкам。
OpenAI существовать 2021 Запущен в 2017 году CLIP Это стандарт Embedding Модель, но поскольку она требует от пользователей самостоятельной настройки, ее сложно использовать, поэтому ее трудно использовать. 2024 В 2016 году Google запустил SigLIP(Sigmoidal-CLIP)。Должен Модельсуществоватьиспользовать zero-shot Достигнута хорошая производительность по запросу.
Маленькая Модель LLM в настоящее время становится все более популярной. Потому что эти модели не требуют больших кластеров облачных вычислений.,Может работать на ноутбуке. Маленькая модель занимает меньше памяти,Меньшая задержка,Работает быстрее, чем большой Модель Быстрее。Unum предоставилмультимодальныймаленький Embedding Модель.
5、мультимодальныйтекст、Аудио、видеоданные
мультимодальныйтекст-Аудио RAG Система в основном генерируется типа Магистр права. Такие приложения сначала преобразуют звук в текст, генерируют пары звук-текст, а затем преобразуют текст в текст. Embedding вектор. После этого можете действовать как обычно. RAG для получения текста. существование Последний шаг: текст снова отображается в Аудио.
OpenAI из Whisper Речь можно транскрибировать в текст. Кроме того, OpenAI из Text-to-speech (TTS) Модель также может конвертировать текст в аудио.
мультимодальныйтекст-видеоиз RAG Система использует аналогичный метод сначала сопоставляет видео с текстом, конвертируя в Embedding Vector выполняет поиск текста и возвращает видео в качестве результатов поиска.
OpenAI из Sora Можно конвертировать текст в видео. и Dall-e Аналогичным образом вы предоставляете текстовые подсказки, а LLM Создать видео. Сора Видео также можно создавать из неподвижных изображений или других видео.
Milvus в настоящее время интегрировал мейнстрим модели EmbeddingModel.,Каждый может испытать:https://milvus.io/docs/embeddings.md
ссылка
MTEB leaderboard: https://huggingface.co/spaces/mteb/leaderboard
Лучшие практики MTEB: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Поиск похожих изображений: https://milvus.io/docs/image_similarity_search.md
Поиск видео-изображений: https://milvus.io/docs/video_similarity_search.md
Поиск похожих аудио: https://milvus.io/docs/audio_similarity_search.md
Текстовый поиск по изображениям: https://milvus.io/docs/text_image_search.md
Документ SigLIP (CLIP для потери сигмовидной кишки), 2024 г.: https://arxiv.org/pdf/2401.06167v1
Unum мультимодальный Embedding Модель:
https://github.com/unum-cloud/uform



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
