Как точно оценить потребление памяти при выводе и тонкой настройке llm
Command-R+, Mixtral-8x22b и Llama 3 70b были выпущены в последние недели, и эти модели огромны. Все они имеют более 70 миллиардов параметров:
Command-R+: параметры 104B
Mixtral-8x22b: Модель Mixed Expert (MoE) с параметрами 141B.
Лама 370б: параметры 70,6Б
Можете ли вы точно настроить и запустить эти модели на компьютере?
В этой статье я объясню, как рассчитать минимальный объем памяти, необходимый этим моделям для вывода и точной настройки. Этот метод применим к любому фильму и точно рассчитывает общее потребление памяти.

Память, необходимая для вывода
Все три модели выпускаются с 16-битными весами: float16 для Command-R+ и bfloat16 для Mixtral и Llama 370b. Это означает, что один параметр занимает 16 бит или 2 байта памяти.
Один миллиард параметров будет занимать 2 миллиарда байт, или 1 миллиард байт равен 1 ГБ, поэтому 1 миллиард параметров занимает 2 ГБ памяти. Для параметров 100B требуется 200 ГБ памяти. Это приблизительное значение, поскольку 1 КБ равен не 1000 байтам, а 1024 байтам. С помощью этого простого метода мы можем примерно оценить использование памяти, а подробный процесс вычислений мы рассмотрим позже.
Чтобы узнать, сколько параметров имеет модель, не скачивая ее, можно просмотреть карточку модели:

Если вы делаете быстрый вывод на графическом процессоре, вам необходимо полностью загрузить модель в оперативную память графического процессора.
Для Command-R+: 193,72 ГБ ОЗУ графического процессора
Для Mixtral-8x22B: 262,63 ГБ оперативной памяти графического процессора
Для Llama 370b: 131,5 ГБ оперативной памяти графического процессора.
Или, скажем, вам понадобится 2 графических процессора по 80 ГБ, например два h100.
Активированное потребление памяти
После загрузки модели,Нам нужно больше Память в хранилище Модель активации,то есть тензор, созданный во время вывода. Эти тензоры передаются из одного слоя в другой. Их размер в Память оценить непросто. Чтобы оценить это активированное потребление памяти, я использовал «Уменьшение Activation Recomputation in Large Transformer Модели» предлагаемый метод.
Для оценки потребления памяти нам необходимо знать следующее:
s: максимальная длина последовательности (количество токенов на входе)
б: размер партии
h: Скрытое измерение Модели
а: Обратите внимание на количество головокСтандартный слой-трансформер состоит из блоков самообслуживания и блоков MLP, каждый блок соединен двумя слоями-нормами. Потребление памяти каждого компонента оценивается следующим образом.
1. Блок внимания
Блок внимания состоит из механизма самовнимания, линейной проекции и дропаута. Требования к памяти включают в себя:
Линейная проекция сохраняет входные активации размером 2sbh, а выпадение Нужно занять маску СБХ.
Линейная проекция и активация входа самовнимания требуют по 2sbh каждая.
Матрицы запроса (Q) и ключа (K) требуют 4sbh.
Softmax и его отсев требуют 2as²b и as²b соответственно.
Значения, примененные к хранилище(V), в сумме составляют 2as²b. + 2sbh。Обратите внимание, что общий объем памяти, необходимый для блоков, составляет 11sbh + 5as²b.
sbh здесь равно s*b*h, который мы будем сокращать ниже.
2. Блок МЛП
Блок MLP состоит из двух линейных слоев и дропаута:
Хранилище линейного уровня стоит 2sbh и 8sbh входных данных, нелинейность GeLU также требует 8sbh. Нам не нужно хранить активации GeLU для вывода, но я все равно считаю их на случай, если какая-то структура вывода сохранит эти активации. Размер маски, хранимый в Dropout, равен sbh.
Таким образом, для блока MLP требуется 19 квадратных метров пространства.
3、layer-norms
Каждому LN требуется 2sbh для хранения входных данных, что составляет 4sbh для двух слоев.
4. Для всего слоя
Общая потребность в памяти составляет 11sbh + 5as²b (от блока внимания) + 19sbh (от блока MLP) + 4sbh (от LN).
Потребление памяти на активацию уровня = 34 sbh + 5as²b
Если мы используем 16-битный тип данных, то нам нужно умножить это число на 2, потому что для каждого параметра активации потребуется 2 байта.
5. Итого
Это уравнение примерно соответствует фактическому потреблению памяти. Большинство фреймворков вывода оптимизированы путем удаления тензоров, как только они перестают быть полезными, поэтому обычно это число будет меньше этого числа. Но во время вывода также создаются различные буферы, потребляющие память. Но в результате экспериментов я обнаружил, что рассчитанное нами значение в основном похоже на структуру Трансформеров Hugging Face. Для других более оптимизированных платформ, таких как vLLM и TGI, потребление памяти будет уменьшено.
Если вы используете передовые технологии, такие как FlashAttention, Alibi или RoPE, потребление памяти при обработке длинных последовательностей также будет значительно снижено.
6. Оценка потребления памяти Command-R+, Mixtral-8x22B и Llama 370b для вывода
В стандартном сценарии, когда параметры модели и активации являются 16-битными, нам также необходимо установить гиперпараметры декодирования.
S = 512 (длина последовательности), B = 8 (размер пакета)
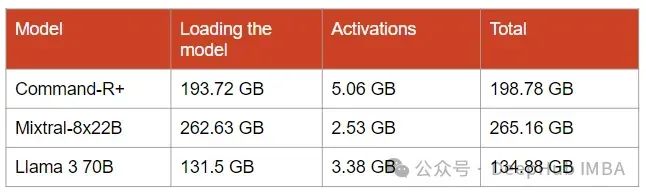
Размер активации ничтожен по сравнению с размером модели в памяти. Но их размер быстро увеличивается с увеличением размера партии и длины последовательности.
Уменьшите потребление памяти для вывода
Большая часть потребления памяти для вывода связана с параметрами модели. Последние алгоритмы квантования могут значительно снизить потребление памяти. Они сжимают модель, уменьшая разрядность большинства параметров, пытаясь сохранить при этом точность модели.
8-битное квантование практически без потерь, тогда как 4-битное квантование лишь незначительно снижает производительность. 4-битное квантование делит потребление памяти модели на 4, поскольку большинство параметров имеют размер 4 бита, что составляет 0,5 байта вместо 2 байтов. Я рекомендую использовать AWQ для 4-битного квантования, он прост в запуске и позволяет быстро создавать модели.
Для очень больших моделей с более чем 100B параметров квантование с более низкой точностью, например 2,5 или 3 бита, все равно может дать точные результаты. Например, AQLM показывает хорошую производительность при 2-битном квантовании Mixtral-8x7B. Но проблема с AQLM в том, что стоимость количественных моделей очень высока. Для очень больших моделей это может занять несколько недель.
Другой вариант — переместить модель на другое запоминающее устройство, например, в ОЗУ ЦП. Но его недостаток в том, что он слишком медленный, особенно при пакетном декодировании. Платформы, оптимизированные для вывода ЦП, помогают поддерживать вывод достаточно быстрым. Например, Neural Speed — одна из самых быстрых платформ для вывода данных о процессоре с использованием квантованных моделей.
Если вы используете ЦП, вам все равно понадобится много оперативной памяти ЦП для загрузки модели и сохранения активаций, а метод расчета тот же.
Память, необходимая для точной настройки
Для точной настройки llm оценка потребления памяти немного сложнее. Помимо хранения весов модели и активаций, для всех слоев нам также необходимо хранить состояние оптимизатора.
Потребление памяти состояния оптимизатора
Оптимизатор AdamW — самая популярная тонкая настройка llm, он создает и сохраняет по 2 новых параметра для каждого параметра модели. Если у нас модель 100B, оптимизатор создаст 200B новых параметров. Для большей стабильности обучения параметры оптимизатора имеют формат float32, что означает, что каждый параметр занимает 4 байта памяти.
Это основная причина, по которой точная настройка потребляет больше памяти, чем вывод.
Например, для Mixtral-8x22B оптимизатор создает 2*141B = 282B параметров float32. Памяти он потребляет 1053,53 ГБ, плюс надо добавить память, занимаемую самой моделью, которая составляет 262,63 ГБ. Таким образом, всего требуется 1315,63 ГБ памяти графического процессора. Это около 17 А100 по 80 ГБ!
И этого недостаточно для тонкой настройки модели. Нам также нужна память для хранения активаций.
Память, необходимая для вычисления градиентов
В отличие от вывода, где нам нужно сохранить только активации одного слоя перед переходом к следующему слою, точная настройка требует сохранения всех активаций, созданных во время прямого прохода. Это необходимо для расчета градиента, который затем используется для обратного распространения ошибки и обновления весов модели.
Чтобы оценить Память, необходимая для вычисления градиентов,Мы можем использовать ту же формулу, что и для вывода.,Затем результат умножается на количество слоев.
Если L — количество слоев, то память, потребляемая для расчета градиента, равна
L(34sbh + 5as²b)Оценка потребления памяти Llama 3 70b, Mixtral-8x22B и тонкая настройка Command R+
Нам нужно оценить размер модели и добавить размер активации всех слоев и размер состояния оптимизатора.
Для тонкой настройки я установил следующие гиперпараметры:
S = 512 (длина последовательности)
B = 8 (размер партии)
Что касается состояний оптимизатора, я предполагаю, что это float32.
так что возьми

Это наихудший случай потребления памяти, то есть никакие оптимизации для снижения потребления памяти не используются. К счастью, существует множество оптимизаций, которые мы можем применить для снижения требований к памяти.
Уменьшите потребление памяти при точной настройке
Поскольку состояния оптимизатора потребляют много памяти, было проведено множество исследований, чтобы уменьшить их объем памяти, например:
LoRA: заморозьте всю модель и добавьте обучаемый адаптер с миллионами параметров. Используя LoRA, мы сохраняем только состояние оптимизатора параметров адаптера.
QLoRA: LoRA, но модель квантуется с точностью до 4 бит или меньше.
AdaFactor и AdamW-8bit: более эффективный оптимизатор памяти, обеспечивающий производительность, близкую к AdamW. Но AdaFactor может работать нестабильно во время обучения.
GaLore: проецирует градиенты в подпространство низкого ранга, что может уменьшить размер состояния оптимизатора на 80%.
Другая значительная часть памяти потребляется активацией. Чтобы уменьшить его, обычно используется контрольная точка градиента. Когда ему необходимо рассчитать градиенты, он пересчитывает некоторые активации. Это снижает потребление памяти, но также замедляет точную настройку.
Наконец, существуют такие платформы, как Unsloth, которые значительно оптимизированы для тонкой настройки с использованием LoRA и QLoRA.
Подвести итог
В этой статье мы покажем, как оценить трансформатор. Потребление памяти модели. Этот метод не работает с моделями других архитектур, кроме трансформаторов. Например, стоимость активации памяти Mamba и RWKV значительно ниже, поскольку они не используют механизм внимания.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
