Как создаются метки портретов пользователей?
В этом разделе будут представлены методы производства различных портретных этикеток на основе реальных случаев. Офлайн-теги будут содержать статистические теги, теги правил и теги импорта соответственно. фамилия и фамилия классов майнинга также даст краткое введение на основе примеров. Часть этого раздела посвящена ядру Hive. Операторы SQL и примеры кода Java.
Вкладка «Статистика»
Статистические теги используют статистику автономных данных для расчета значений тегов, соответствующих конкретным требованиям в течение определенного периода времени. Большинство статистических тегов включают атрибуты времени, такие как количество лайков за прошедший день, среднее время онлайн за последнюю неделю, количество статей, опубликованных за последний месяц и т. д. Однако не все данные статистических тегов могут в конечном итоге быть выражено количественно, например время последнего входа в систему, было ли оно зарегистрировано на прошлой неделе, результатом являются дата и логическое значение соответственно. Статистические метки могут быть созданы с использованием механизма больших данных для выполнения статистических отчетов. Ниже в качестве примеров для иллюстрации метода создания статистических меток используется среднее время онлайн за последнюю неделю и сведения о том, было ли о ком-то сообщено за последнюю неделю.
Метка «Среднее время онлайн за последнюю неделю» используется для расчета среднего времени онлайн пользователей за последнюю неделю. Предполагая, что текущая дата — T, процесс расчета разделен на два этапа: вычислить сумму продолжительности онлайн в диапазоне дат от T-7 до T-1, разделить сумму на временной интервал 7; Предположим, что сведения о времени пользователя в сети хранятся в столбце online_time таблицы Hive userprofile_demo.user_online_data. Тип столбца — bigint, и в нем хранится количество секунд, в течение которых пользователь был в сети в этот день. Таблица данных однозначно идентифицирует пользователя по основному значению. ключ user_id. Инструкция по созданию статистической метки выглядит следующим образом: общее время онлайн для каждого user_id рассчитывается с помощью функции SUM. Диапазон дат в операторе SQL жестко запрограммирован. В реальной работе диапазон дат можно заменить переменными.
SELECTuser_id,sum(online_time) / 7FROMuserprofile_demo.user_online_dataWHEREp_date >= '2022-06-20'AND p_date <= '2022-06-26'GROUP BYuser_idАналогично, для метки «Сообщалось ли об этом на прошлой неделе» предполагается, что данные о поведении пользователей, сообщающих о них, хранятся в таблице сведений о поведении Hive userprofile_demo.user_report_detail_data, в которой в столбце report_user_id записан пользователь, о котором сообщили. Текущая дата — T, и в процессе расчета необходимо подсчитать только общее количество пользователей, о которых было сообщено в диапазоне дат от T-7 до T-1. Если общее число больше 0, это означает, что о пользователе было сообщено в. последнюю неделю. Статистический оператор выглядит следующим образом. Этот оператор включает в себя оператор подзапроса. Необходимо сначала подсчитать и запросить подробное количество сообщений о каждом пользователе, а затем использовать внешний запрос, чтобы определить, сообщалось ли о пользователе в последний раз. неделя в зависимости от количества сообщений. 1 означает 0. означает нет.
SELECTt.reported_user_id,CASE WHEN t.reportedCount > 0 THEN '1' ELSE '0' END AS reported_ornotFROM(SELECTreported_user_id,count(1) AS reportedCountFROMuserprofile_demo.user_report_detail_dataWHEREp_date >= '2022-06-20'AND p_date <= '2022-06-26'GROUP BYreported_user_id) tДва приведенных выше примера создания статистических меток SQL-операторы запрашивают только результаты меток. Чтобы сохранить содержимое метки, вы можете использовать перезапись вставки для записи результатов в таблицу Hive.
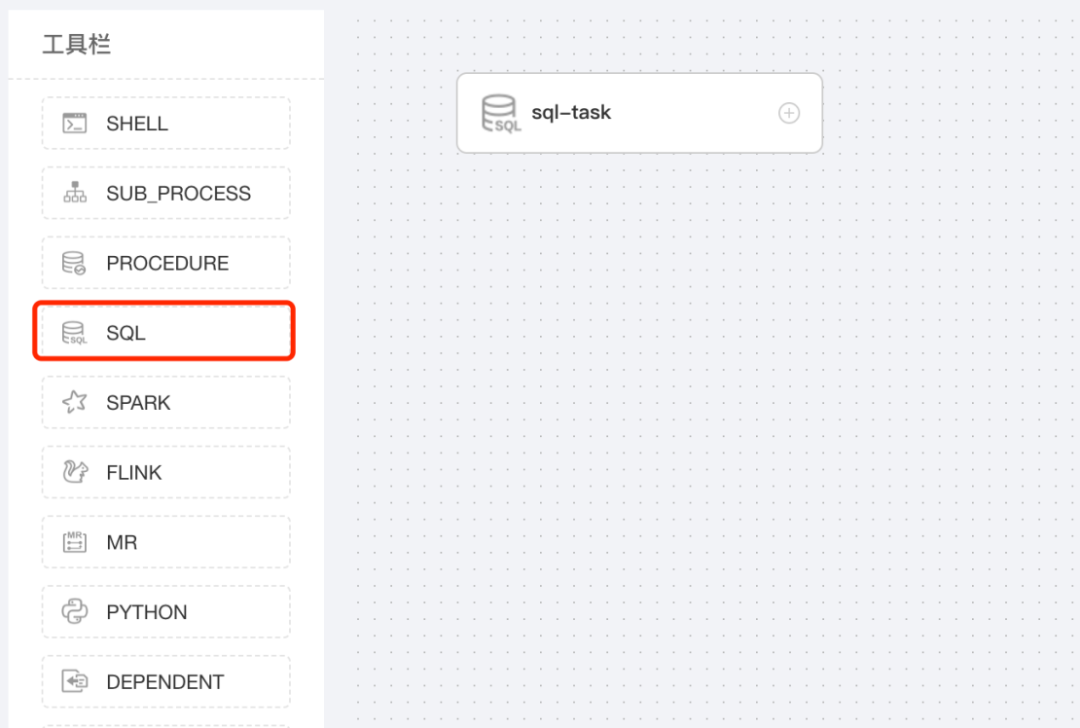
Большинство задач по производству этикеток необходимо выполнять на регулярной основе. В производственной среде приведенные выше инструкции SQL необходимо настроить как запланированные задачи планирования. Существует множество способов настройки задач планирования больших данных. Вы можете использовать инструменты планирования с открытым исходным кодом, такие как Airflow или DolphinScheduler, или написать инженерный код. На примере инструмента планирования DolphinScheduler вы можете визуально настроить рабочий процесс на этом инструменте и настроить рутинные задачи для рабочего процесса. На рис. 3-6 показан процесс настройки задач производства этикеток с помощью DolphinScheduler. Ключевая конфигурация включает оператор SQL для выполнения задачи, а в операторе SQL можно настроить пользовательские переменные для реализации автоматических изменений в цикле статистики данных.
Ярлык правила
Создание правил Ярлыка основано на существующем содержимом тегов.,Необходимо сделать комплексную оценку состояния на основе существующих данных на этикетке.,Наконец сгенерируйте новые данные этикетки,Например, «высокий уровень фанатов-мужчин» зависит от пола и количества тегов фанатов; «телефон Android высокого класса» зависит от операционной системы мобильного телефона и ценника мобильного телефона.
Возьмем в качестве примера метку «Вы большой поклонник мужчин»? Предположим, что метка пола хранится в столбце пола таблицы данных userprofile_demo.user_gender_data, а метка количества поклонников хранится в столбце Fans_count таблицы userprofile_demo. Таблица данных user_fanscount_data Первичным ключом в обеих таблицах является user_id. Определение «высоких фанатов-мужчин» — это пользователи-мужчины с более чем 100 000 поклонников. Сгенерированное предложение этого ярлыка выглядит следующим образом.
-- Записать в таблицу данных метки --INSERT OVERWRITE TABLE userprofile_demo.user_is_highfans_male_label PARTITION (p_date = '2022-06-26')SELECTt.user_id,-- Определите, является ли пользователь пользователем мужского пола с большим количеством поклонников. --CASE WHEN t.gender = 'M' AND t.fans_count > 100000 THEN 1 ELSE 0 END AS is_high_fans_maleFROM(SELECTt1.user_id,t1.gender,t2.fans_countFROM(-- Получите подробные данные о поле и количестве поклонников --SELECTuser_id,genderFROM`userprofile_demo.user_gender_data`WHEREp_date = '2022-06-26') t1INNER JOIN (SELECTuser_id,fans_countFROM`userprofile_demo.user_fanscount_data`WHEREp_date = '2022-06-26') t2 ON (t1.user_id = t2.user_id)) tПриведенный выше оператор состоит из трех частей. Сначала подробные данные о поле и количестве поклонников всех пользователей запрашиваются посредством операции соединения между таблицами данных тегов пола и количества поклонников, затем находятся пользователи мужского пола с наибольшим количеством поклонников. в соответствии с правилами, и, наконец, статистические результаты записываются в таблицу целевых данных. Подобно статистическим тегам, теги правил также могут использовать существующие инструменты планирования или инженерные коды для достижения запланированного вывода меток.
Импортировать теги
Теги импорта используют загруженные пользователем данные для создания новых тегов. Пользователи могут импортировать данные двумя основными способами: загрузка файлов и импорт из других источников данных (таких как MySQL, Hive). Например, действительные пользователи в анкете опроса A могут быть загружены на портретную платформу, а после выпуска игры B аналитик данных обнаружил группу потенциальных высококачественных пользователей, а новую метку «Опрос ориентирован на пользователей»; последующие группы ключевых операций, этих пользователей можно импортировать в портретную платформу и создать новый ярлык «Пользователи потенциального продвижения B-игры».
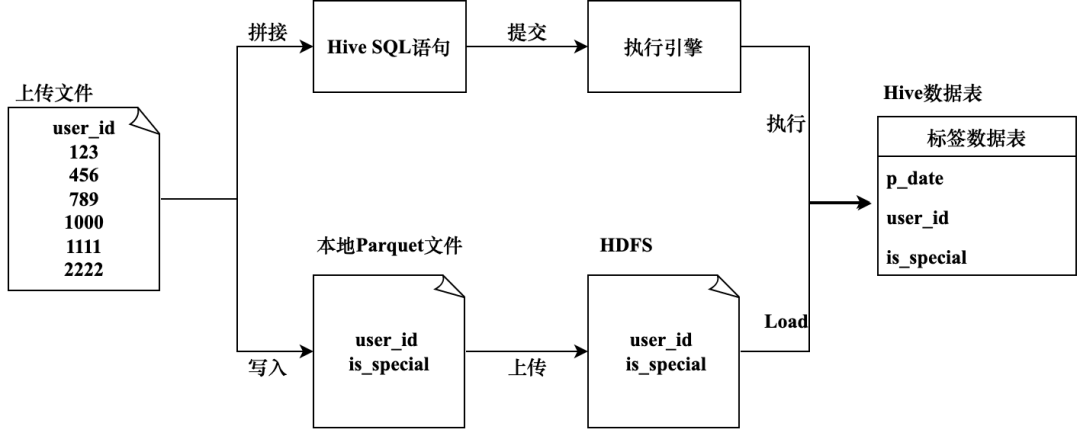
Для создания этикетки путем загрузки файла пользователь должен предоставить файл, содержащий UserId, и загрузить его в функциональный модуль управления этикетками. Чтобы сохранить метод хранения и формат различных тегов одинаковыми, теги, созданные посредством загрузки файлов, в конечном итоге должны быть сохранены в таблице Hive. Чтобы синхронизировать данные в файле с таблицей Hive, в этом разделе будут представлены два решения по реализации.
Вариант 1. Запись данных с помощью операторов SQL.
Запишите в таблицу Hive с помощью оператора вставки. Если объем данных в загруженном файле небольшой, вы можете записать данные из файла в указанную таблицу Hive, объединив операторы вставки. При создании метки «Исследование пользователей» загруженный файл содержит некоторые идентификаторы пользователей. Вы можете установить для этих пользователей значение метки «Исследование пользователей» равным 1, где 1 означает «да», а 0 — «нет». окончательная метка. Данные должны храниться в таблице Hive userprofile_demo.a_activity_special_user_data. Основными атрибутами этой таблицы являются столбцы ключа раздела p_date, user_id и is_special label. Ее основной оператор SQL выглядит следующим образом.
INSERT INTOuserprofile_demo.a_activity_special_user_data PARTITION (p_date = '2022-06-26')VALUES(123, 1),(234, 1),....(1000, 1);Это решение должно просмотреть данные файла, загруженные пользователем, и проанализировать в нем UserId, а затем использовать инженерный код для автоматического создания приведенного выше оператора SQL. Отправив оператор SQL в механизм больших данных, он наконец реализует функцию. создание тегов из загруженного пользователем файла. Этот метод выполнения возможен для файлов с небольшим размером данных, но когда размер данных файла велик, метод объединения операторов SQL больше не применим. Во-первых, оператор SQL слишком длинный и его легко вывести из строя. Эффективность выполнения SQL-операторов ниже, время ожидания увеличивается при большом объеме данных.
Решение 2. Запишите данные через файлы HDFS.
Быстрая запись в таблицу Hive путем прямой записи файлов HDFS. Этот план реализации в основном разделен на два этапа.
- Разберите файл, загруженный пользователем, прочитайте его содержимое и запишите его в файл формата Parquet на текущем компьютере.
- Загрузите указанный выше файл Parquet в HDFS и загрузите его для создания таблицы Hive.
Эта реализация имеет высокую эффективность выполнения, но предполагает прямое манипулирование файлами HDFS. Если код ненормальный, он может испортить онлайн-данные. Метод прямой записи файлов HDFS в основном основан на реализации проекта, и его основной код выглядит следующим образом.
public void writeDatToParquetFile(List<Long> userIds) throws Exception {// Построение таблицы данных SchemaStringBuilder stringBuilder = new StringBuilder();String ls = System.getProperty("line.separator");stringBuilder.append("message m {").append(ls).append(" optional int64 user_id;").append(ls).append(" optional int64 is_special;").append(ls).append("}");String rawSchema = stringBuilder.toString();// Запись данных локально в файл Parquet String parquetPath = "Путь к файлу паркета";Путь path = new Path(parquetPath);MessageType schema = MessageTypeParser.parseMessageType(rawSchema);GroupFactory factory = new SimpleGroupFactory(schema);Configuration conf = new Configuration();GroupWriteSupport.setSchema(schema, conf);ParquetWriter<Group> writer = CsvParquetWriter.builder(path).withWriteMode(Mode.OVERWRITE).withConf(conf).withCompressionCodec(CompressionCodecName.SNAPPY).build();try {Iterator<Long> iterator = userIds.iterator();while (iterator.hasNext()) {Long userId = iterator.next();Group group = factory.newGroup().append("user_id", userId).append("is_special", 1);writer.write(group);}} finally {writer.close();}// Загрузить локальные файлы в строку HDFS destPath = «Адрес файла HDFS»;UserGroupInformation ugi = UserGroupInformation.createRemoteUser("Имя пользователя");ugi.doAs(new PrivilegedExceptionAction<Void>() {public Void run() throws Exception {FileSystem fs = HdfsFileService.getWriteHdfs();fs.copyFromLocalFile(true, true, new Path(parquetPath), new Path(destPath));return null;}});// Load Файл HDFS в таблицу Hive String loadHdfsFileToTable = "LOAD DATA INPATH " + destPath + " INTO TABLE userprofile_demo.a_activity_special_user_data PARTITION (p_date='2022-06-26')";// Выполните приведенный выше оператор через JDBC hiveJdbcTemplate.update(loadHdfsFileToTable);}Подводя итог, на рис. 3-7 показаны два метода реализации генерации меток импортированных классов.
Живые теги
Живые представлены в главах, посвященных классификации тегов и хранению тегов. теги,Живые теги могут обеспечить передачу данных на этикетках в режиме реального времени.,Возможность вернуть последнее значение тега. Например, метка «Количество дней обмена в режиме реального времени».,Он записывает совокупное количество общих ресурсов, которыми поделился пользователь, с раннего утра этого дня до текущего момента; метка «Отчитывался ли пользователь в тот день» указывает, был ли пользователь зарегистрирован в этот день.,Когда происходит событие отчета,Значение тега пользователя может быть обновлено в реальном времени до «отчета».
Живые Источниками данных тегов обычно являются потоки данных в реальном времени, а данные в потоках данных в реальном времени обычно поступают из журналов отчетов на стороне клиента или бизнес-журналов на стороне сервера. Данные в реальном времени могут передаваться с помощью очередей сообщений, а нисходящие данные создаются путем использования данных в очереди. теги. К наиболее популярным в отрасли очередям сообщений относятся Kafka, RocketMQ, RabbitMQ и ActiveMQ. Их преимущества, недостатки и применимые сценарии различны. Среди них Kafka больше подходит для крупномасштабной передачи данных. data работает хорошо с точки зрения пропускной способности и производительности. Технологии, используемые для потребления данных в реальном времени, включают Storm и Spark. Потоковая передача, Flink и т. д. В последние годы Flink широко используется в отрасли, главным образом потому, что он поддерживает простую модель программирования и хорошо работает с точки зрения высокой пропускной способности, низкой задержки и высокой производительности.
Ниже в качестве примера используется «совместное использование количества дней в реальном времени», чтобы представить использование Flink для использования потока данных Kafka в реальном времени для создания Живых. теги процесс. Предположим, что данные о поведении пользователей при совместном использовании записываются в user_share_action_detail Kafka. В теме его данные организованы в формате JSON, а его основные атрибуты включают в себя: время совместного использования, идентификатор пользователя и идентификатор видео. Примеры данных приведены ниже.
{
"userId": 100, // Идентификатор пользователя
"photoId": 200, // Идентификатор общего видео
"shareTime": 1656406377465 // Поделиться меткой времени в миллисекундах
}
Использование Kafka в реальном времени через Flink Данные темы и Живые данные теги обновляются в Redis, и его основной процесс показан на рис. 3-8.
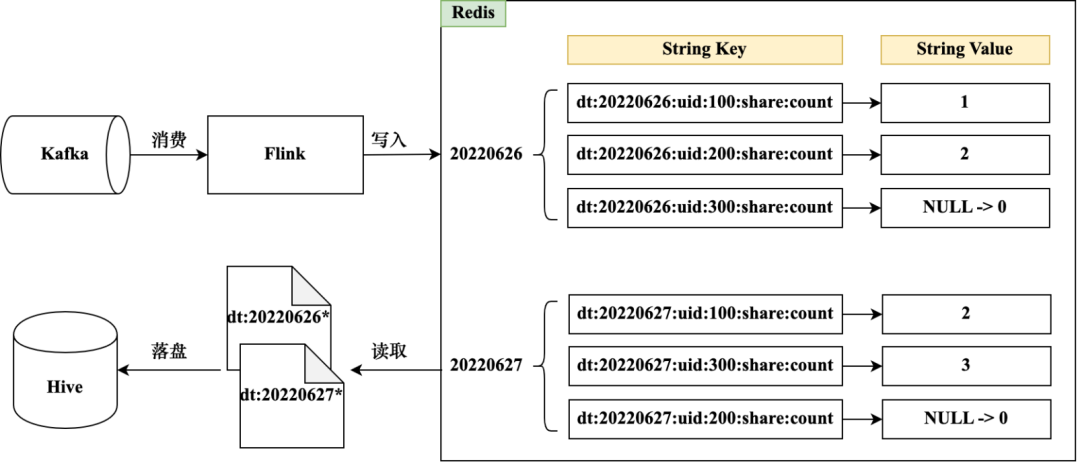
Метка «Количество дня в режиме реального времени» связана с датой, и необходимо различать данные метки в разные даты. Вы можете использовать общую метку времени для расчета текущей даты и создания различных префиксов Redis Key на основе разных дат, например dt:20220626 и dt:20220627. Помимо даты, ключ Redis также содержит информацию об идентификаторе объекта, что позволяет быстро определить количество общих ресурсов для указанного UserId на определенную дату, например dt:20220626:uid:100:share:count. Значение тега количества акций можно сохранить через структуру данных Redis String. Когда количество общих ресурсов указанного UserId увеличивается в определенную дату, значение тега можно изменить с помощью функции incr Redis.
Redis также можно настроить в соответствии с потребностями бизнеса. Срок действия ключа для предотвращения непроизводительной траты ресурсов хранения. Живые данные теги можно регулярно синхронизировать из Redis с таблицей Hive. Поскольку все ключи имеют префиксы даты, файлы данных с указанными префиксами даты можно регулярно получать из Redis. После анализа файлов данных их можно записать в таблицу Hive (для записи). методы, см. Загрузить файл Импортировать теги). После размещения стола Улей его можно использовать как Живые. Резервное копирование данных теги также облегчает последующий возврат данных и запрос исторических данных.
Помимо построения Живые используются данные в реальном времени. Помимо тегов, его также можно записать в таблицу подробных данных о поведении для подробного анализа данных (описанную в последующих главах этой книги). Если взять в качестве примера поведение пользователей при совместном использовании, подробные данные, содержащиеся в сообщении Kafka, могут быть записаны в более крупный формат после анализа Flink. В механизме хранения данных для реализации функции OLAP их можно записать в таблицу ClickHouse, для резервного копирования данных и поддержки автономного статистического анализа их также можно записать в таблицу Hive; ClickHouse предоставляет интерфейс записи данных, который можно вызывать напрямую, когда FLink использует данные в реальном времени для записи данных. Данные Hive можно записать с помощью Hive; JDBC выполняет операторы записи или записывает непосредственно в файлы HDFS и загружает их в таблицы Hive. Процесс записи подробных данных в реальном времени показан на рисунке 3-9.

Теги классов майнинга
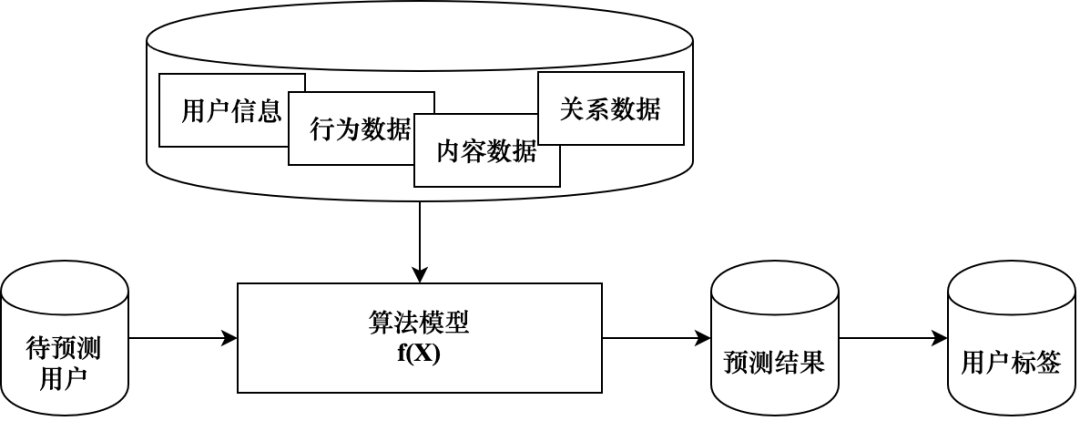
Теги классов Майнинга относится к тегам, добытым с помощью алгоритмов машинного обучения. В отличие от статистики и тегов правил, Теги классов майнинга невозможно рассчитать напрямую с помощью простых статистических утверждений.,Для прогнозирования результатов меток необходимо использовать модели алгоритмов. Например, теги интересов и хобби пользователя.,Необходимо выяснить интересы, хобби и вероятностные значения пользователя на основе прошлого исторического поведения пользователя; теги статуса брака и деторождения пользователя не могут быть получены напрямую из существующей статистики данных;,Необходимо использовать историческое поведение пользователя для майнинга.,Предскажите, женат ли пользователь и имеет ли он детей.
На рисунке 3-10 показаны Теги. классов Производственная логика майнинга, модель алгоритма, опирается на различные данные о функциях для обучения модели. Учитывая группу пользователей, которые необходимо спрогнозировать, можно рассчитать результаты прогнозирования меток, и на основе результатов прогнозирования можно инкапсулировать выходные данные Теги. классов майнинга。большинство Теги классов майнинга Производство в конечном итоге является проблемой классификации.,Алгоритм можно использовать для поиска значения метки с наибольшей вероятностью.,Размер вероятности представляет собой размер склонности пользователя.,Например, вероятность того, что пользователь состоит в браке, равна 0,8, что означает, что пользователь имеет высокую вероятность состоять в браке.,Этот пользователь может быть отнесен к группе женатых пользователей.
Теги классов Процесс производства майнинга включает в себя ряд звеньев машинного обучения. Производственный процесс длительный и требует больших инвестиций в рабочую силу и ресурсы. классов майнинга не занимает высокой доли во всей системе этикеток. Но Теги классов Майнинга может извлекать потенциальную информацию о тегах пользователей из исторических данных, а также расширять границы тегов в процессе сотрудничества с бизнесом, Теги; классов майнинга позволяет уточнить цели оптимизации и гибко адаптироваться к потребностям бизнеса для достижения лучших бизнес-результатов. Общий процесс машинного обучения показан на рисунке 3-11, который примерно разделен на несколько звеньев: сбор и анализ данных, разработка функций, обучение и оценка модели, а также запуск модели. Тег «Женат или нет», основанный на этом процессе.
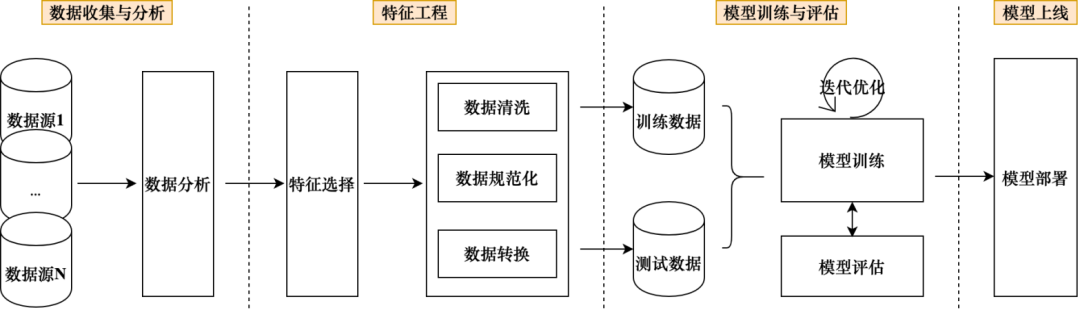
Сбор и анализ данных:для“женат ли”Этикетка,Бизнес-требование — найти состоящих в браке пользователей.,Значения тега — да и нет,Это показывает, что процесс интеллектуального анализа меток представляет собой проблему двоичной классификации. Может предсказать вероятность того, что пользователь женат,Брак и детородный статус разделены по величине вероятности. После выяснения потребностей вы можете сначала собрать образцы данных.,То есть находят группу реальных женатых пользователей для последующего обучения и тестирования модели. После получения образца данных,Начните сортировать данные объектов, которые могут быть использованы при последующем обучении модели.,Состоите вы в браке или нет, это может быть отражено в различных поведенческих данных пользователей.,Например, если история просмотров пользователя содержит много контента о браке,,Вероятность состоять в браке выше, если предпочтения пользователя включают материнский и детский контент;,Вероятность состоять в браке выше; время активности пользователя отражает распределение времени, в течение которого пользователь может выходить в Интернет.,Состоящие в браке пользователи могут иметь определенные характеристики распределения времени; если пользователь среднего возраста или старше, вероятность состоять в браке выше. Чем больше данных вы сможете найти на этапе сбора данных, тем лучше,Выполните анализ собранных данных.,Например, найдите максимальное и минимальное значения данных,Медиана дисперсии и т. д. для данных строкового типа;,Проанализируйте пропорции разных ценностей. Для данных низкого качества,Его следует отфильтровать непосредственно на этом этапе.
Особенности проектирования:для Собранные данные,Когда и качество, и количество соответствуют требованиям,Доступные данные объектов можно фильтровать.,Качество функций в конечном итоге оказывает большое влияние на результаты прогнозирования модели. Выбранные данные объекта должны пройти обработку объекта.,Например, очистка данных, нормализация данных и преобразование данных. Очистка данных используется для удаления грязных и ненормальных данных.,Нормализация данных — это унификация типов данных и форматов данных.,Преобразование данных включает в себя такие процессы, как кодирование и векторизация данных. После того, как данные объекта подвергаются вышеуказанным операциям,,Их можно разделить на данные обучения и тестовые данные и, наконец, применить к обучению модели.
Обучение и оценка модели:Модели алгоритмов используют обучающие данные для обучения модели.,Оцените производительность модели с помощью тестовых данных. Когда результаты прогноза не соответствуют ожиданиям,Оптимизируйте модель, постоянно корректируя параметры модели, пока результаты прогнозирования не будут соответствовать ожиданиям. В центре внимания этого этапа — выбор модели алгоритма.,Вам необходимо выбрать наиболее подходящую модель для решения текущей задачи из таких моделей, как деревья решений, SVM, случайные леса, логистическая регрессия и нейронные сети.,Вы также можете протестировать различные модели алгоритмов и, наконец, провести перекрестную проверку, чтобы выбрать ту, которая дает наилучшие результаты. Существует множество способов оценки моделей.,Например, матрица путаницы, коэффициент Джини, кривая ROC и т. д.,Для оценки эффективности модели необходимо использовать соответствующие методы. В этом разделе для того, чтобы спрогнозировать вероятность того, "состоят ли вы в браке",ПринятоLogisticвозвращаться Модель。
Модель онлайн:когда Модель После того, как результаты прогноза оправдают ожидания,Модели можно развертывать онлайн. После экспорта модель алгоритма в основном содержит файлы четырех типов: файлы модели, файлы кодирования тегов, файлы метаданных и файлы переменных. После того как файл модели «Женат или нет» развернут в сети, его можно использовать для прогнозирования значения вероятности «Женат или нет» пользователя.,Когда значение вероятности превышает указанный порог, оно может быть определено как состоящее в браке, и наконец генерируются данные метки. Когда последующие модели модернизируются и обновляются,Файлы онлайн-моделей необходимо заменить.
Теги классов Алгоритмы и платформы машинного обучения, на которые опирается майнинга, в настоящее время относительно зрелы. Общие платформы машинного обучения в настоящее время включают Spark. MLlib & Spark ML, Scikit-learn и т. д., платформа предоставляет традиционные методы машинного обучения, включая классификацию, регрессию, кластеризацию, обнаружение аномалий и подготовку данных. Глубокое обучение — важная часть машинного обучения, Теги классов Майнинга также может использовать технологию глубокого обучения. Распространенные среды глубокого обучения теперь включают TensorFlow, PyTorch и PaddlePaddle. Пример в этом разделе: Метка «женат ли» представляет собой проблему классификации и должна предсказать вероятность того, что пользователь состоит в браке. В основном используется Spark. Для майнинга используется библиотека ML. Процесс майнинга и основной код следующие.
SparkConf conf = new SparkConf().setAppName("ifMarryOrNotDemo");JavaSparkContext jsc = new JavaSparkContext(conf);SQLContext jsql = new SQLContext(jsc);// Подготовьте данные для обученияList<LabeledPoint> localTraining = Lists.newArrayList(new LabeledPoint(1.0, Vectors.dense(0.0, 1.1, 0.1)),new LabeledPoint(0.0, Vectors.dense(2.0, 1.0, -1.0)),new LabeledPoint(0.0, Vectors.dense(2.0, 1.3, 1.0)),new LabeledPoint(1.0, Vectors.dense(0.0, 1.2, -0.5)));Dataset<Row> training = jsql.applySchema(jsc.parallelize(localTraining), LabeledPoint.class);// Создать экземпляр модели логистической регрессии lr = new LogisticRegression();// Установить параметры модели lr.setMaxIter(10).setRegParam(0.01);// Модель обучения Модель логистической регрессии model1 = lr.fit(training);// Подготовьте тестовые данныеList<LabeledPoint> localTest = Lists.newArrayList(new LabeledPoint(1.0, Vectors.dense(-1.0, 1.5, 1.3)),new LabeledPoint(0.0, Vectors.dense(3.0, 2.0, -0.1)),new LabeledPoint(1.0, Vectors.dense(0.0, 2.2, -1.5)));Dataset<Row> test = jsql.applySchema(jsc.parallelize(localTest), LabeledPoint.class);// тест Модельи запросить результатыmodel1.transform(test).registerTempTable("results");Dataset<Row> results = jsql.sql("SELECT features, label, probability, prediction FROM results");Эта статья взята из книги «Портреты пользователей: построение платформ и бизнес-практика». При перепечатке указывайте источник.




Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
