Как построить платформу, похожую на Shence
Sence Data является профессиональным поставщиком услуг в области анализа больших данных и маркетинговых технологий в Китае и в настоящее время предоставляет услуги обработки данных многим торговцам. Функция портретной платформы является лишь частью всех сервисных модулей Shence. В этом разделе описывается процесс создания аналогичной платформы на основе личного понимания и технической информации, предоставленной Shence.
Знакомство с продуктом Shence
Shence Data Positioning — профессиональный отечественный поставщик услуг в области анализа больших данных и маркетинговых технологий. Компания стремится предоставить следующие возможности, чтобы помочь компаниям реализовать полный процесс оцифровки маркетинга.
Продуктовое решение, предоставляемое в настоящее время Sence Data, представляет собой «два облака и одно». Shence Analysis Cloud может интегрировать несколько источников данных, таких как реклама, поведение пользователей и бизнес-операции, охватывая бизнес-анализ и информацию пользователей во всех сценариях, а также обеспечивать многомерный анализ данных в реальном времени и интеллектуальные решения для принятия решений для различных ролей в предприятие. Shence Marketing Cloud — это платформа цифрового маркетинга, охватывающая все сценарии, включая публичные и частные домены, онлайн и оффлайн. Платформа инфраструктуры данных Shence — это бизнес-ориентированная полнофункциональная платформа инфраструктуры данных, которая может собирать, управлять, хранить, запрашивать и отображать данные в режиме реального времени. Она оснащена механизмом анализа данных для эффективного накопления активов данных и расширения возможностей бизнес-приложений. сценарии и помогают предприятиям создать прочную основу данных для реализации цифровых операций.
Помимо использования комплексных продуктовых решений, Shence также предоставляет услуги, которые можно приобрести и использовать отдельно. В Таблице 9-4 кратко представлены основные сценарии применения каждой услуги.
Таблица 9-4 Продукты, связанные с данными Shence, и применимые сценарии
Название продукта | Основные функциональные точки | Сценарии применения |
|---|---|---|
Божественный анализ стратегии | Отчеты (данные конфигурации для формирования отчетов) Обзор (панель данных) Анализ (события, хранение, уязвимости) Закладки Интеллектуальный анализ раннего предупреждения | На основе данных, собранных со всех каналов, можно реализовать различные функции анализа, построить аналитические отчеты и установить информацию раннего предупреждения. |
Портрет пользователя Shence | Управление тегами пользователей. Группировка пользователей. Портрет группы пользователей. | Настраивайте производственные теги, выбирайте людей на основе тегов и деталей поведения, а также анализируйте портреты толпы. |
Shence Интеллектуальная работа | Канва процесса планирования операций Управление содержанием операций WeChat | Разрабатывать оперативные планы для достижения точных операций |
Shence Интеллектуальная рекомендация | Слот инвентаря (рекомендуемые правила) | Настраивайте рекомендуемые материалы и стратегии и используйте возможности алгоритмов для получения интеллектуальных рекомендаций. |
Тест Шенца AB | эксперимент АБ | Конфигурацияэксперимент АБ, анализ результатов эксперимента |
Анализ рекламы Shence | Анализ каналов Отслеживание каналов | Грамотное размещение рекламы, анализ постинвестиционного эффекта |
Гостевая сцена Шенса | Инструменты анализа и эксплуатации жизненного цикла клиента | Управление жизненным циклом клиента |
Основные технические модули
Основные функции Shence прямо или косвенно полагаются на различные типы данных, собранных со стороны бизнеса.,Разные данные взяты из разных источников,Но необходим единый уровень доступа к данным,Для удовлетворения различных уровней потребностей в доступе к данным,Уровень доступа должен поддерживать горизонтальное расширение; собранные данные необходимо очищать и организовывать в соответствии с бизнес-требованиями, а затем сохранять, чтобы обеспечить эффективные функции анализа;,Данные должны быть записаны в подходящее место для удовлетворения требований к производительности.механизм В запросе; все функции наконец предоставляются пользователям через интерфейсную систему отображения, а действия пользователя на странице преобразуются в команды запроса и анализа с помощью механизма. требовать исполнения. Подводя итог, чтобы реализовать платформу, подобную Shence, с технической точки зрения, она в основном включает в себя пять технических модулей, как показано на рисунке 9-17: Сборка. данных и доступ к ним、ETL-обработка、система хранения、механизм Система запросов и внешнего отображения. В этом разделе будут представлены основные идеи реализации каждого модуля и технологические решения с открытым исходным кодом, которые можно использовать.
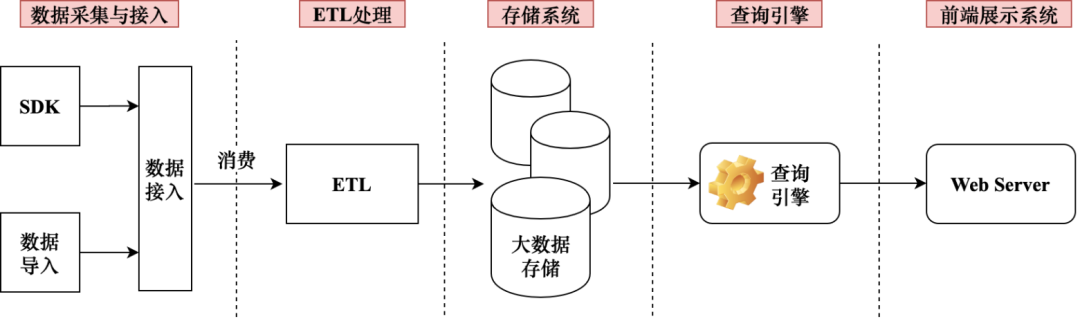
1. Сбор данных и доступ к ним
Сбор данных отвечает за обобщение бизнес-данных из различных каналов, из которых типы каналов можно разделить на клиентские и серверные. Клиенты в основном включают Android, IOS, небольшие программы, HTML5 и т. д. Данные в основном поступают из скрытых точек клиента, а бизнес-данные могут передаваться через SDK скрытых точек. Серверная часть в основном относится к импорту данных на стороне сервера. Импортированные данные в основном включают в себя бизнес-журналы на стороне сервера, а также могут быть существующими бизнес-данными на стороне сервера, например данными, хранящимися в бизнес-базе данных MySQL.
Чтобы унифицировать метод доступа к сбору данных, все данные могут быть записаны с использованием протокола HTTP, чтобы уменьшить потребление пропускной способности сети при передаче данных, загружаемые данные могут быть сжаты. В конечном итоге данные поступают на сервер через балансировщик нагрузки. Балансировка нагрузки может поддерживать горизонтальное расширение для адаптации к различным объемам данных доступа. Собранные данные в конечном итоге перенаправляются на разные внутренние серверы для размещения данных. Сервер может использовать Nginx, который в качестве семиуровневого балансировщика нагрузки подходит для анализа данных протокола HTTP. Данные могут быть напрямую записаны в локальный файл. Во-первых, данные можно быстро записывать и сохранять. С другой стороны, их можно отделить от последующих ссылок ETL, чтобы облегчить обработку данных по требованию на этапе ETL. На рис. 9-25 показан основной процесс модуля сбора данных и доступа.
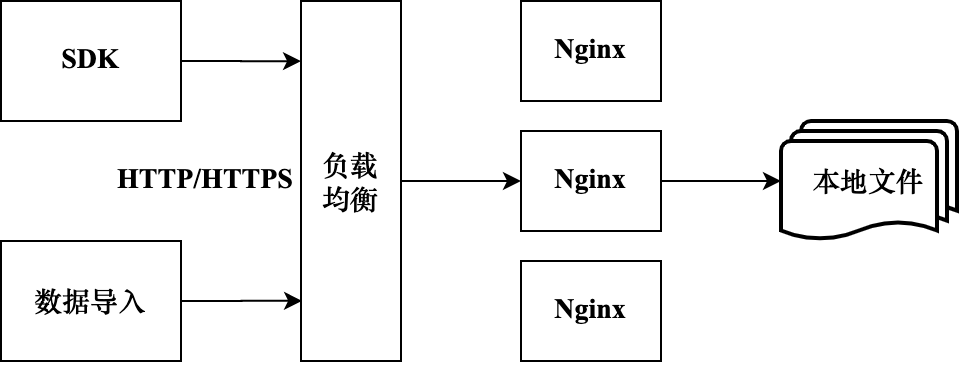
Shence открыла исходный код SDK для сбора клиентских данных, который можно использовать непосредственно в проектах. Существуют также некоторые инструменты с открытым исходным кодом для сбора журналов на стороне сервера, такие как Logstash и FileBeat, оба из которых поддерживают протокол HTTP для передачи данных. Logstash реализован на базе Java и работает на JVM, но потребляет много ресурсов при работе. FileBeat реализован на основе языка Go и занимает меньше ресурсов; Если вам необходимо загрузить существующие данные из бизнес-базы данных в службу сбора данных, вы можете использовать для этого Logstash или Syncer. Балансировка нагрузки развилась относительно зрело. Вы можете рассмотреть возможность использования LVS для четырехуровневой балансировки нагрузки. Вы можете использовать Nginx или HAProxy для семиуровневой балансировки нагрузки. Вы также можете использовать облачные сервисы балансировки нагрузки, такие как Alibaba Cloud SLB, Tencent Cloud CLB. и АВС ЭЛБ.
2. ETL-обработка
После того, как собранные данные записаны в локальный файл через Nginx, данные необходимо проанализировать и обработать. При анализе данных сначала необходимо распаковать данные в исходные бизнес-данные, затем проверить, является ли содержимое данных законным, отбросить ненормальные данные и т. д. Качество данных можно контролировать в процессе анализа данных, а при появлении большого количества аномальных данных можно выдать и своевременно обработать сигнал тревоги. Для поддержки вторичного развития пользователей модуль анализа и обработки данных может предоставлять определяемые пользователем функции подключаемых модулей. Когда у пользователей есть особые потребности в обработке данных, они могут вмешаться с помощью подключаемых модулей. В этой ссылке также может быть реализовано сопоставление идентификаторов. Каждый фрагмент данных, передаваемый пользователем, содержит UserId или DeviceId и т. д. Чтобы добиться уникальности глобального идентификатора, исходный идентификатор можно преобразовать в унифицированный идентификатор, а затем передать последующим. ссылки.
Данные после анализа и обработки данных могут быть записаны в очередь сообщений для использования последующими ссылками. Почему данные не могут быть записаны напрямую? Есть два основных соображения: во-первых, после записи данных в очередь сообщений все соответствующие стороны могут использовать сообщения для удовлетворения различных бизнес-потребностей, во-вторых, достигается разделение бизнеса и снижение пикового трафика данных, а последующие модули записи данных могут масштабироваться самостоятельно; . Способность соответствовать требованиям к производительности записи. На рис. 9-26 показан основной процесс модуля обработки данных ETL.

Чтобы иметь возможность обнаруживать изменения в локальных файлах, его можно реализовать на основе JNotify, а WatchDog реализован на основе языка Java, а WatchDog реализован на основе языка Python. Оба широко используются в отрасли. Очередь сообщений, показанная на рисунке 9-26, представляет собой Kafka, которая больше подходит для крупномасштабной обработки данных. Другие очереди сообщений с открытым исходным кодом включают RabbitMQ, RocketMQ и т. д.
3. Система хранения
Данные после анализа и обработки данных окончательно записываются в систему хранения через модуль записи данных. В некоторых бизнес-сценариях наиболее распространенными методами хранения больших данных являются файлы HDFS или таблицы Hive, чтобы ускорить запросы и анализ; используйте какую-нибудь эффективную реализацию механизма анализа, например ClickHouse, упомянутую в этой книге. Модуль записи данных можно реализовать с помощью Flink. Сначала ему необходимо потреблять данные, обработанные восходящим потоком, а затем использовать интерфейс, предоставляемый Hadoop, для записи данных (ClickHouse также поддерживает запись данных через интерфейс). В настоящее время в отрасли существует множество типов механизмов хранения, и их необходимо выбирать исходя из характеристик данных и потребностей бизнеса. На рис. 9-27 показан основной процесс модуля системы хранения.

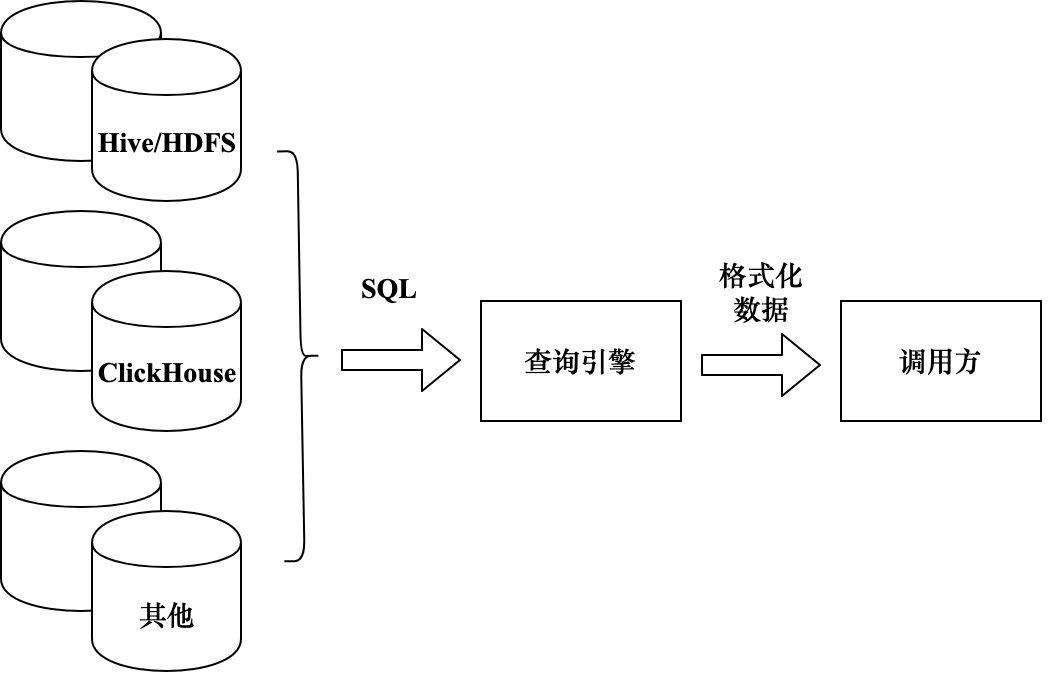
4. Механизм запросов
Как показано на рис. 9-28, все запросы функций в конечном итоге преобразуются в задачи выполнения данных. Задачи выполнения данных выражаются в форме операторов SQL. Наконец, механизм запросов используется для поиска данных, соответствующих условиям, из Hive или. Кликхаус. Чтобы повысить скорость расчета, вы можете сначала использовать ClickHouse для расчета. Если расчет не удается или происходит ненормально, вы можете использовать Hive для полного расчета. Поскольку Hive и ClickHouse имеют разные преимущества и недостатки и поддерживают бизнес-сценарии, механизм запросов должен поддерживать функцию маршрутизации к различным механизмам выполнения в зависимости от типа задачи.
Механизм запросов должен быть очень абстрактным. Функциональные интерфейсы, которые он предоставляет, не имеют ничего общего с конкретным механизмом, а конкретные детали выполнения скрыты извне. Результаты запроса инкапсулируются обработчиком запросов и возвращаются вызывающей стороне. Например, результаты запроса собираются в данные формата диаграммы, а затем возвращаются на интерфейсную страницу для отображения.
5. Внешняя система отображения и другие модули.
Система внешнего отображения — это функциональная система, которую пользователи могут напрямую воспринимать и использовать. Какие функции внешней системы отображения связаны с потребностями бизнеса, и различные функции должны быть тщательно разработаны для повышения удобства пользователя. Существует также множество интерфейсных фреймворков с открытым исходным кодом, таких как React и Vue. В главе 7 этой книги также представлены шаги по созданию интерфейсной среды на основе Vue. Интерфейс должен быть ориентирован на удобство использования функций и полезность результатов. Пользователи могут легко и эффективно использовать функции платформы для удовлетворения своих собственных потребностей. Различные результаты, отображаемые на странице, должны быть четкими и легкими для понимания.
Чтобы обеспечить надежность и стабильность системы, необходимо обеспечить полные возможности мониторинга системы. От доступа к данным до использования различных функций платформы — задействовано множество основных компонентов и функциональных модулей. Когда в определенном звене возникают проблемы, их необходимо своевременно обнаружить и устранить. Если вы предоставляете коммерческие продукты, вам необходимо следить за тем, является ли действующая лицензия законной для обеспечения интересов бизнеса.
Для мониторинга рабочего состояния программного и аппаратного обеспечения в системе необходимо предоставить комплексные и полные инструменты для эксплуатации и обслуживания. Коммерческие продукты также должны поддерживать автоматическое обновление версий, чтобы снизить затраты на ручное вмешательство и повысить эффективность развертывания.
Эта статья взята из книги «Портреты пользователей: построение платформ и бизнес-практика». При перепечатке указывайте источник.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
