Как мы можем использовать семантический поиск в сценариях, где применяются большие модели?
через некоторое время,Все больше корпоративных пользователей начинают применять большие языковые модели в бизнесе. Однако,Из-за недостатков больших языковых моделей, таких как устаревание, неточность, галлюцинации, серьезная чушь и обучение на основе данных Интернета,,поэтому,Непосредственное использование контента, созданного с помощью больших языковых моделей, в бизнес-сценариях.,Особенно сценарии, затрагивающие некоторые профессиональные области и частные данные.,не может предоставить точную или ценную информацию. поэтому,Применение больших моделей часто необходимо сочетать с технологией поиска. таким образом,Семантический поиск внезапно стал горячей темой, которая раньше редко обсуждалась.。но,Объединение семантического поиска с большими моделями — это не просто комбинация инструментов.,Ни один“Преобразуйте все данные с помощью моделей машинного обучения -> Семантический поиск снова -> Наконец, результаты поиска можно ввести в большую модель. Поэтому в этой статье будут представлены некоторые мысли по этому поводу, которые, надеюсь, будут полезны всем.
Почему нам следует использовать семантический поиск при работе с большими моделями?
главный,нам нужно подумать,Почему нам следует использовать семантический поиск при работе с большими моделями,Знайте, каково ваше первоначальное намерение, и тогда вы сможете его придерживаться.,а не зависеть от второстепенных вещей,Со временем проект деформировался.
Наше первоначальное намерение состоит в том, чтобы использовать возможности понимания, рассуждения и генерации больших моделей, чтобы помочь нам повысить производительность и удобство работы с пользователем. Однако устаревшие или неточные ответы на выводы в больших моделях, обученных на основе данных Интернета, имеют недостатки. технология, обеспечивающая большие модели точной контекстной информацией (плюс вопросами) в качестве исходного материала для создания.
Поскольку семантический поиск позволяет лучше понимать разговорные вопросы в длинных текстах и находить более релевантный контент в базах данных, он является хорошим дополнением к более крупным моделям.
Основные возможности семантического поиска могут обеспечить точное контекстное окно для больших моделей.
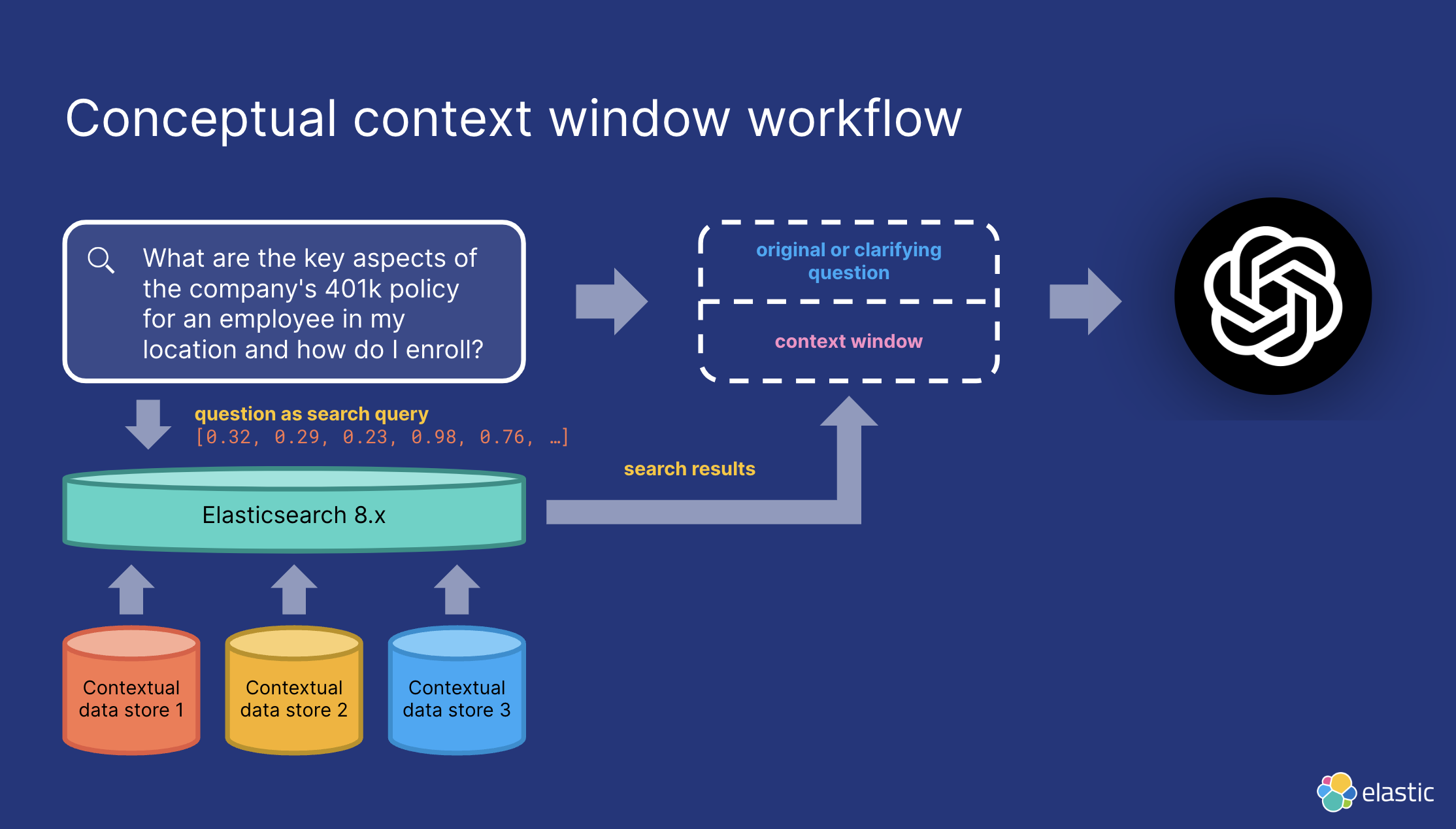
Но еще один момент,Что нам нужно четко знать, так это,Будь то ChatGPT или Bard,Или, может быть, это просто слова Вэнь Синя.,Тонги Цяньвэнь и др.,LLMВвод на самом деле является текстом。Контент, который мы отправляем в большую модель для обобщения, расширения, перевода, переписывания и создания, не является вектором.。
поэтому,Основная цель — точно и эффективно предоставить контекстную информацию для больших языковых моделей.。Семантический поиск является лишь дополнительным техническим средством и представляет собой ветвь многопутевого вызова. Инвертированный поиск, фильтрация категорий данных и сущностей, объединение воспоминаний, переупорядочение и т. д. — все это технические решения, которые необходимо учитывать для этой цели.
Семантический поиск = векторный поиск?
Семантический поиск делится на инвертированный поиск с разреженным представлением.и Два типа поиска по сходству для плотных представлений。То, что мы обычно называем векторным поиском, относится к поиску по сходству, основанному на плотном представлении встраивания (поиск KNN и ANN).。Но на самом деле у нас также есть инвертированный семантический поиск, основанный на разреженном представлении.Эти два метода поиска,Все получают выгоду от крупномасштабных языковых моделей (примечание,LLM относится к языковой модели со многими параметрами.,Это не относится конкретно к моделям со сверхвысокими параметрами, таким как ChatGPT.,на самом деле,Разработку моделей с десятками миллионов признаков-параметров можно назвать большими языковыми моделями),И большой прогресс был достигнут в скорости запоминания и корреляции.,Особенно модель, разработанная на основе трансформатора,напримерBERTждать。
Но когда мы выбираем решение семантического поиска, поиск по сходству (поиск KNN и ANN), основанный на плотном представлении встраивания, не обязательно является оптимальным решением. Например, SPLADE на рисунке ниже представляет собой модель разреженного представления, которая не уступает большинству моделей плотного внедрения. Преимущество этой модели в том, что данные, обрабатываемые моделью, представляют собой не векторный массив, а читаемый человеком. интерпретируемые слова + вес, технология обратного поиска все еще используется. Таким образом, будут преимущества в размере модели, генерируемом индексе и производительности поиска. Кроме того, благодаря своей сильной способности сопоставления терминов, он также может лучше адаптироваться к информационному выражению, отображаемому векторным поиском, когда пользовательский ввод слишком короткий и есть. недостаточно контекста. Недостаток слабых способностей.

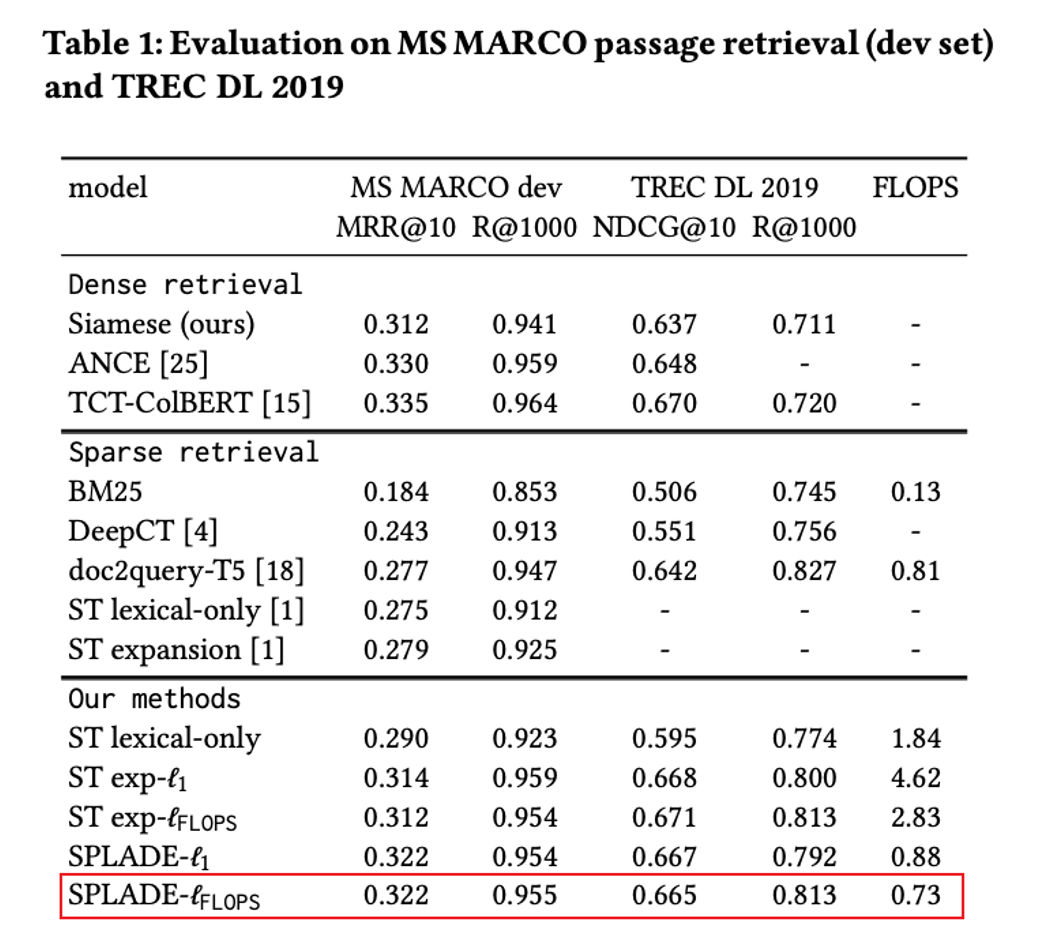
В этом отношении ELSER в Elasticsearch работает хорошо:
Каковы ограничения векторного поиска?
Конечно, векторный поиск по-прежнему обладает более мощными возможностями семантического понимания. Нам нужен векторный поиск. Но в то же время вам также необходимо знать, что эффективно, элегантно и точно создать возможности векторного поиска непросто. Это подлежит:
- Способность векторного поиска понимать естественный язык основана на моделях глубокого обучения, а не на индексировании векторов и расчетах сходства векторов.:
- Для обучения и развертывания моделей глубокого обучения требуется большое количество вычислительных ресурсов и места для хранения данных.
- Для обучения моделей глубокого обучения требуется большой объем аннотированных данных. Если качество данных недостаточно высокое или не охватывает все возможные сценарии, модель может не обобщаться на новые данные.
- Модели глубокого обучения необходимо регулярно обновлять, чтобы адаптироваться к изменениям в данных и поведении пользователей. Если модель устарела или неточна, это может повлиять на качество результатов поиска и удовлетворенность пользователей.
- Необходимо учитывать размерность и плотность векторов, чтобы выбрать подходящие методы индексации и запроса. Если размерность вектора слишком велика или слишком мала или векторное распределение неравномерно, это может повлиять на эффективность и точность поиска.
- Векторный поиск требует больших затрат на реализацию и поддержку.,Требуются значительные вычислительные ресурсы и опыт.。Для некоторых сценариев применения с ограниченными ресурсами,Или когда не хватает профессионального подбора моделей,Это может быть нежизнеспособным вариантом.
- В сценарии поиска короткого текста векторный поиск может столкнуться с проблемой семантического понимания. Хотя векторный поиск может выполнять семантический анализ запросов, при использовании коротких текстов представление и понимание семантики может быть недостаточно точным, что приводит к менее релевантным результатам.
- Векторный поиск представляет данные в виде векторных представлений слов, что создает естественные препятствия для людей с точки зрения прозрачности и интерпретируемости поиска. Люди не могут легко понять, почему два векторных представления похожи, а также сложно понять, как изменить функции, чтобы их можно было изменить. Улучшить релевантность;
- Для большинства команд разработчиков порог изменения, настройки и переобучения моделей внедрения слишком высок, а рентабельность инвестиций полна неопределенности.
Если объяснить в одном предложении, эффект векторного поиска не может быть непосредственно представлен или получен после того, как вы решите использовать векторную библиотеку. Выбор модели, разумная настройка, размеры модели, количественная оценка, обновления модели и т. д. — все это повлияет на эффект.
В частности, большинство векторных библиотек предоставляют только возможности хранения векторов, индексации векторов и сравнения сходства векторов.,Но это решает только инженерную задачу,То есть,Библиотека векторов решает лишь проблему быстрого поиска векторов или нет.,QPS высокий?,Вопрос о том, велика ли пропускная способность или нет,Однако не существует способа решить проблему точности поиска, то есть эффекта, который требует выбора, настройки и непрерывного обучения модели встраивания.Это не в узком смысле“векторный поиск”вопрос,Это проблема НЛП (обработки естественного языка) в широком смысле.
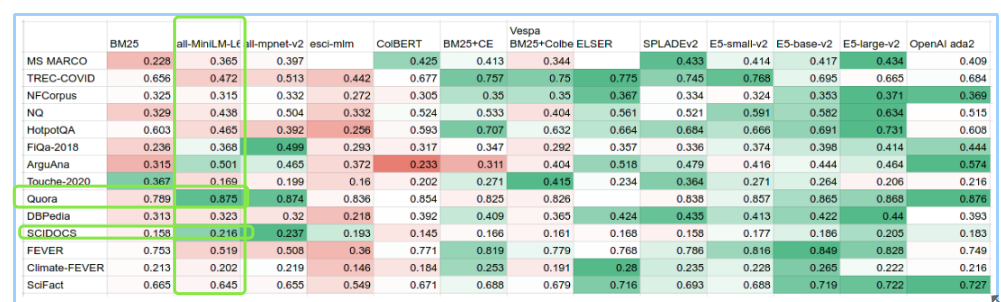
Нужен ли векторный поиск?
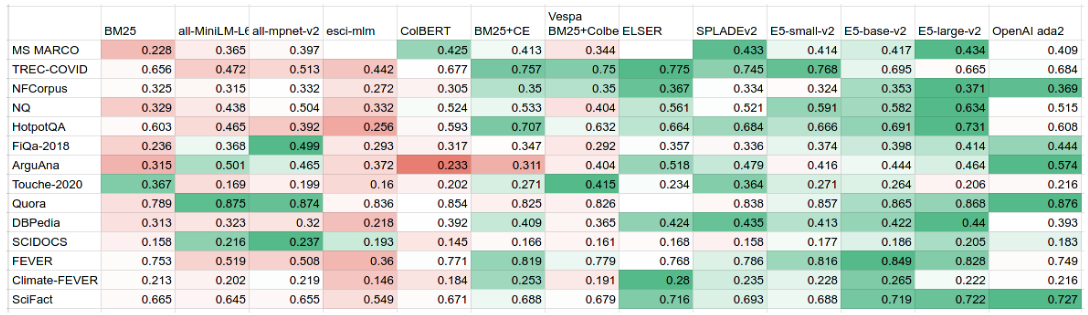
Актуальность векторного поиска во многом зависит от выбранной модели. Из теста ниже мы видим,Есть даже многоembeddingЭффект от модели не так хорош, какBM25+CE。В то же время он не так хорош, как инвертированный поиск с разреженным представлением.。Поэтому не стоит сразу использовать векторный поиск на основе KNN или ANN, поскольку эффект может оказаться не таким хорошим, как вы думаете.而且即便你用正确из方式打开了векторный поиск,Большинство полученных улучшений составляют около 10 % (от 8 x % до 9 x %).,Насколько это полезно для конечного пользователя?,Это необходимо оценить. Эта оценка должна основываться на количестве кликов по результатам поиска.
Каковы ограничения на правильное и разумное использование моделей внедрения?
Чтобы использовать векторный поиск, мы должны сначала решить проблему векторизации документов и запросов. То есть нам нужно знать, как выбирать и использовать модель внедрения.
Применимые поля модели внедрения
Различные модели внедрения по-разному влияют на разные области. Причины следующие:
- Характеристики данных и семантические различия: Тексты в разных полях имеют разные характеристики и семантические различия. Например,Текст в поле новостей может содержать большое количество информации и событий в реальном времени.,Хотя тексты в области медицины могут включать терминологию, специфичную для конкретной предметной области.иконцепция。потому чтоВ наборах данных и корпусах, используемых разными моделями во время обучения, могут быть отклонения.,поэтому Модель, которая хорошо работает в определенной области, может не подходить для обработки текста в других областях.。
- Объем и разнообразие данных. На производительность встроенных моделей часто влияет объем и разнообразие обучающих данных. Если модель обучается на небольшом объеме данных или данные недостаточно разнообразны, ее способность понимать текст в определенной области может быть ограничена. И наоборот, если модель обучена на более крупном наборе данных с широким охватом, она, как правило, будет работать лучше в разных областях.
- Специализация предметной области. Некоторые области имеют конкретную специализацию, где термины, понятия и контекстная информация имеют решающее значение для правильного понимания и внедрения в текст. Некоторые модели могут хорошо работать с текстами общего характера, но им может не хватать соответствующих знаний и опыта при работе с текстами, специфичными для предметной области, что приводит к плохим результатам.
- Архитектура модели и цели обучения. В разных моделях внедрения используются разные архитектуры и цели обучения, что может привести к тому, что они будут работать по-разному при обработке текста в разных доменах. Например, некоторые модели ориентированы на обучение языковых моделей и подходят для генерации непрерывного текста, тогда как другие модели могут больше подходить для таких задач, как классификация и распознавание именованных объектов;
Для конкретных областей для достижения лучших результатов следует рассмотреть следующие подходы:
- Используйте предварительно обученные модели для конкретного домена. В некоторых доменах могут быть предварительно обученные модели для конкретного домена, которые лучше работают при обработке текста в определенном домене. Другими словами, при выборе модели нужно понимать, на каком поле данных в основном обучается модель:
- Точная настройка модели для конкретного домена. Используйте данные, связанные с доменом, для точной настройки предварительно обученной модели и адаптации ее к функциям и семантике конкретного домена.
- Объедините несколько моделей или ансамблевых методов. Объедините результаты нескольких моделей внедрения или примените методы ансамблевого обучения, чтобы получить более полное и точное представление внедрения.
Поэтому, если нет модели, подходящей для ваших данных, лучше сначала использовать BM25, чтобы установить собственный эталон, а затем сравнивать эффекты один за другим.
ограничение длины токена
Transformer Сам по себе авторегрессивен, BERT Создатель,Производительность значительно снижается при использовании документов с числом токенов более 512.。
Большинство моделей на базе Transformer имеют это ограничение. Ниже приведены несколько распространенных моделей внедрения на основе Transformer:
- BERT (представления двунаправленного кодировщика от преобразователей): BERT — это предварительно обученная модель на основе преобразователя, которая изучает универсальные языковые представления из крупномасштабных текстовых данных посредством обучения без учителя. Он хорошо справляется с некоторыми задачами обработки естественного языка и может использоваться для создания встроенных представлений текста.
- GPT (генеративный предварительно обученный трансформатор): GPT представляет собой серию моделей на основе трансформатора, таких как GPT-1, GPT-2 и GPT-3. Эти модели в основном используются для генерации текста, изучения языковых моделей посредством предварительного обучения и могут использоваться для создания непрерывных вложений текста.
- XLNet (Сеть для понимания языка eXtreme): XLNet — это еще одна модель предварительного обучения на основе Transformer, в которой используется новый метод обучения, называемый моделью языка перестановок (языковая модель перестановок), для лучшего выявления зависимостей в предложениях и контексте.
- RoBERTa (надежно оптимизированный подход к предварительному обучению BERT): RoBERTa — это улучшение и оптимизация модели BERT. Он повышает производительность и надежность модели за счет корректировки методов обучения и гиперпараметров. Это также модель на основе Transformer, подходящая для создания встроенных представлений текста.
Помимо вышеперечисленных моделей, существуют и другие модели, основанные на Transformer модель встраивания, например Transformer-XL、Electra、BERT-Base ждать. Эти модели основаны на Transformer архитектура,Поэтому нам нужно не только выбрать подходящую модель встраивания на основе Трансформера, исходя из конкретных задач и потребностей.,И выполнить соответствующую предварительную подготовку или тонкую настройку,получить встроенное в текст представление, подходящее для конкретной задачи,И при создании вложений вам также необходимо учитывать ограничения токенов.。
И для OpenAI,в настоящий момент,его главныйembeddingмодельtext-embedding-ada-002,ограничение длины токенадля:8191。См. документацию。
Что касается других моделей, которые можно скачать с Huggingface, большинство из них есть в модели. Никаких ограничений в карте не указано.,Но изНекоторые модели отмечены ограничениямиПриходите и посмотрите,Обычно оно ограничено значением менее 512:
SentenceTransformer(
(0): Transformer({'max_seq_length': 509, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)(sentence-transformers/facebook-dpr-ctx_encoder-multiset-base)
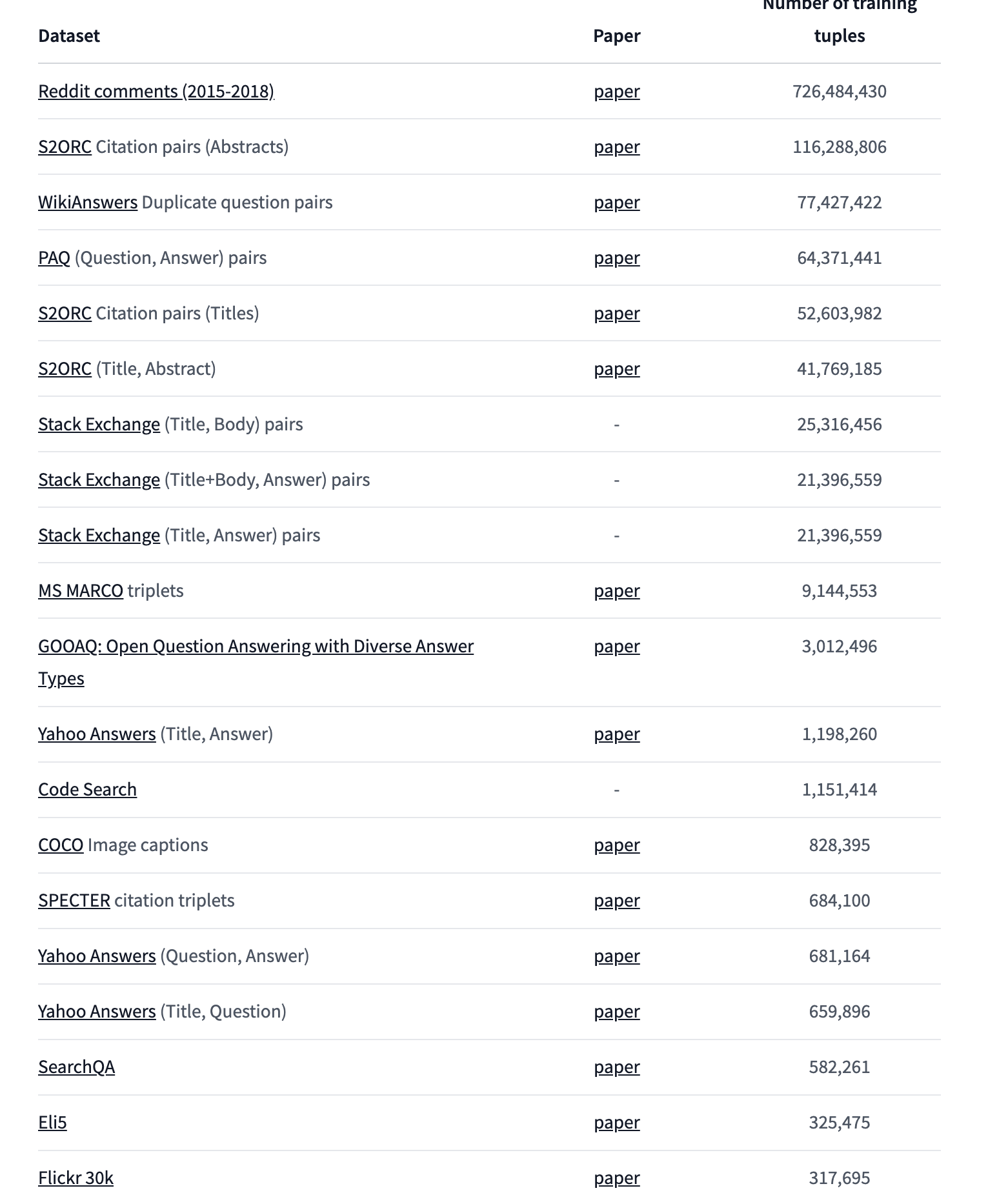
так,Если вы хотите эффективно использовать модель внедрения,Вам необходимо соблюдать размер входного документа. Ввод длинного текста (например, документов,пресс-релизы и др.),Для обработки файлов необходима стратегия фрагментации,например,Можно сделать по рядам、по предложению、Разделить по абзацу или по указанному количеству символов。Общий принцип состоит в том, чтобы попытаться гарантировать, что вырезанный контент содержит полную семантику, не превышая предела.Общие методы обработки включают в себяClipping(метод усечения),Pooling(метод объединения),оконный метод,метод сжатия。Можно ссылаться:Как Берт решает проблему с длинным текстом?или chatgpt-retrieval-plugin/services/chunks.py
поэтому,Может ли модель внедрения достичь желаемой корреляции,Есть много ограничений,напримерBEIRвdataset,ВсеДанные после разумного разделения:
С другой стороны, не все данные следует использовать для внедрения. Обратитесь к набору данных BEIR, указанному выше. В статье некоторые части подходят для точного сопоставления и фильтрации. возьмем бумагу в качестве примера:
==== Front
Clin Cancer Res
Clin Cancer Res
Clinical Cancer Research
1078-0432
1557-3265
American Association for Cancer Research
34740925
CCR-21-2595
10.1158/1078-0432.CCR-21-2595
Version of Record
Clinical Trials: Targeted Therapy
A Novel Third-generation EGFR Tyrosine Kinase Inhibitor Abivertinib for EGFR T790M-mutant Non–Small Cell Lung Cancer: a Multicenter Phase I/II Study
Efficacy and Safety of Abivertinib in Patients with T790M+ NSCLC
https://orcid.org/0000-0002-0478-176X
Zhou Qing 1
https://orcid.org/0000-0001-7078-7767
Wu Lin 2
Hu Pei 3
An Tongtong 4
Zhou Jianying 5
Zhang Li 6
Liu Xiao-Qing 7
Luo Feng 8
Zheng Xin 3
Cheng Ying 9
Yang Nong 10
Li Junling 11
Feng Jifeng 12
https://orcid.org/0000-0002-6251-3771
Han Baohui 13
Song Yong 14
Wang Kai 15
Zhang Li 16
Fang Jian 4
Zhao Hong 17
Shu Yongqian 18
Lin Xiao-Yan 19
Chen Zhihong 1
Gan Bin 1
Xu Wan-Hong 20
Tang Wei 20
Zhang Xiaoying 20
Yang Jin-Ji 1
Xu Xiao 21
https://orcid.org/0000-0002-3611-0258
Wu Yi-Long 1*
1 Department of Pulmonary Oncology, Guangdong Lung Cancer Institute, Guangdong Provincial People's Hospital and Guangdong Academy of Medical Sciences, Guangzhou, China.
2 Department of Medical Oncology, Second Chest Cancer Unit, Hunan Cancer Hospital/The Affiliated Cancer Hospital of Xiangya School of Medicine, Central South University, Changsha, China.
3 Clinical Pharmacology Research Center, Peking Union Medical College Hospital, Chinese Academy of Medical Sciences & Peking Union Medical College, Beijing, China.
4 Department of Thoracic Oncology, Peking University Cancer Hospital & Institute, Beijing, China.
5 Department of Respiratory Medicine, The First Affiliated Hospital, Zhejiang University School of Medicine, Hangzhou, China.
6 Department of Respiratory and Critical Care Medicine, Peking Union Medical College Hospital, Chinese Academy of Medical Sciences & Peking Union Medical College, Beijing, China.
7 Department of Lung Cancer, Fifth Medical Center of PLA General Hospital, Beijing, China.
8 Lung Cancer Center, West China Hospital of Sichuan University, Chengdu, China.
9 Division of Thoracic Oncology, Jilin Provincial Cancer Hospital, Changchun, China.
10 Department of Medical Oncology, Lung Cancer and Gastrointestinal Unit, Hunan Cancer Hospital/The Affiliated Cancer Hospital of Xiangya School of Medicine, Central South University, Changsha, China.
11 Department of Medical Oncology, China National Cancer Center/China Cancer Research Foundation/Cancer Hospital, Chinese Academy of Medical Sciences and Peking Union Medical College, Beijing, China.
12 The Affiliated Cancer Hospital of Nanjing Medical University, Jiangsu Cancer Hospital, Jiangsu Institute of Cancer Research, Nanjing, Jiangsu, China.
13 Department of Pulmonary Medicine, Shanghai Chest Hospital, Shanghai Jiao Tong University, Shanghai 200030, China.
14 Department of Respiratory and Critical Care Medicine, Jinling Hospital, Nanjing University School of Medicine, Nanjing, China.
15 Department of Respiratory Medicine, The Second Affiliated Hospital, Zhejiang University School of Medicine, Hangzhou, China.
16 Department of Medical Oncology, State Key Laboratory of Oncology in South China, Collaborative Innovation Center for Cancer Medicine, Sun Yat-sen University Cancer Center, Guangzhou, China.
17 Oncology Department, Chinese PLA General Hospital, Beijing, China.
18 Department of Oncology, The First Affiliated Hospital with Nanjing Medical University, Nanjing, China.
19 Department of Medical Oncology, Fujian Medical University Union Hospital, Fuzhou, China.
20 ACEA Pharmaceutical Research, Hangzhou, China.
21 ACEA Therapeutics Inc., San Diego, California.
Trial Registration ID: NCT02330367
Prior presentation: Abstracts were accepted in World Conference on Lung Cancer, December 3–8, 2016 and American Society of Clinical Oncology, May 31- June 4, 2019; a poster was presented in American Society of Clinical Oncology, Chicago, 2019.
* Corresponding Author: Yi-Long Wu, Department of Pulmonary Oncology, Guangdong Lung Cancer Institute, Guangdong Provincial People's Hospital and Guangdong Academy of Medical Sciences, No.106 Zhongshan 2nd Road, Guangzhou 510080, China. Phone: 208-387-7855; E-mail: syylwu@live.cn
15 3 2022
14 3 2022
28 6 11271135
16 7 2021
13 9 2021
01 11 2021
©2021 The Authors; Published by the American Association for Cancer Research
2021
American Association for Cancer Research
https://creativecommons.org/licenses/by-nc-nd/4.0/ This open access article is distributed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) license.
Abstract
Purpose:
To establish recommended phase II dose (RP2D) in phase I and evaluate safety and efficacy of abivertinib in patients with EGFR Thr790Met point mutation (T790M)-positive(+) non–small cell lung cancer (NSCLC) with disease progression from prior EGFR inhibitors in phase II.
Patients and Methods:
This multicenter, open-label study included 367 adult Chinese patients. Abivertinib at doses of 50 mg twice a day to 350 mg twice a day was evaluated in phase I in continual 28-day cycles, and the RP2D of 300 mg twice a day was used in phase II in continual 21-day cycles. Primary endpoints include RP2D in phase I and objective response rate (ORR) at RP2D in phase II.
Results:
The RP2D of 300 mg twice a day for abivertinib was established based on pharmacokinetics, efficacy, and safety profiles across doses in phase I. In phase II, 227 patients received RP2D for a median treatment duration of 24.6 weeks (0.43–129). Among 209 response–evaluable patients, confirmed ORR was 52.2% [109/209; 95% confidence interval (CI): 45.2–59.1]. Disease control rate (DCR) was 88.0% (184/209; 95% CI: 82.9–92.1). The median duration of response (DoR) and progression-free survival (PFS) was 8.5 months (95% CI: 6.1–9.2) and 7.5 months (95% CI: 6.0–8.8), respectively. The median overall survival (OS) was 24.9 months [95% CI: 22.4–not reachable (NR)]. All (227/227) patients reported at least 1 adverse event (AE), with 96.9% (220/227) of treatment-related AEs. Treatment-related serious AEs were reported in 13.7% (31/227) of patients. Death was reported in 4.4% (10/227) of patients, and none was deemed as treatment-related.
Conclusions:
Abivertinib of 300 mg twice a day demonstrated favorable clinical efficacy with manageable side effects in patients with EGFR T790M+ NSCLC.
Key Lab System Project of Guangdong Science and Technology Department – Guangdong Provincial Key Lab of Translational Medicine in Lung Cancer 2017B030314120 High-level Hospital Construction Project DFJH201810 National Science and Technology Infrastructure Program National Key Science Projects Program 2018ZX09301–014–002
==== Body
pmcTranslational Relevance
This phase I/II study, investigation of the novel third-generation EGFR tyrosine kinase inhibitor (TKI) abivertinib in 367 Chinese patients with advanced EGFR Thr790Met point mutation (T790M)-positive(+) non–small cell lung cancer (NSCLC), is the first clinical study conducted in the Chinese patients at a large scale to investigate the clinical benefits of abivertinib. Current phase I/II design facilitated immediate recommended phase II dose (RP2D) assessments in an expanded patient population. Abivertinib demonstrated favorable efficacy and tolerable safety profiles in patients.
Introduction
...
Discussion
This phase I/II study, investigation of the novel third-generation EGFR-TKI abivertinib in 367 Chinese patients with advanced NSCLC, is the first clinical study conducted in the Chinese patients at a large scale to investigate the clinical benefits of abivertinib. In phase I, 300 mg twice a day was selected as the RP2D based on favorable efficacy outcomes and a safety profile comparable with that observed at lower doses with greater steady-state PK parameters. The safety and efficacy of the 300 mg twice a day dose and schedule was further demonstrated in phase II with 227 patients. Abivertinib at 300 mg twice a day was generally well tolerated, with the most common AEs being liver transferase elevation, diarrhea, and rash, which are common with approved EGFR-TKIs and other investigational third-generation agents (9, 15–17). At the dose of 300 mg twice a day, abivertinib treatment resulted in ORR (52.2%) and DCR (88.0%) with significant DoR (8.5 months), PFS (7.5 months), and OS (24.9 months) in patients with EGFR T790M mutation. A substantial efficiency gain in abivertinib efficacy and safety evaluations is obtained by using this two-phase study design, of which a modified three-plus-three dose escalation scheme allowed quick cohort expansion and RP2D determination which was not dependent on MTD of the drug, and also this phase I/II design seamlessly facilitated immediate RP2D assessments in an expanded patient population with less toxicity and favorable efficacy.
Abivertinib demonstrated efficacious effects in overcoming T790M-mediated resistance with the ORR of 52.2%, which is comparable with other third-generation EGFR-TKIs as reported ORRs in the range between 42% and 67% from different studies (10, 15–18). Of the patients included in this study, about 30 had brain metastases. The ORRs for patients with brain metastases or without brain metastasis were 50.0% and 52.5%, respectively and among 159 patients with disease progression, 24.5% of patients were progressed in the CNS as their primary site. Given that the sample size of the patients with brain metastases in this study was small, and the cerebrospinal fluid concentration of the drug has not be systematically analyzed, the efficacy of abivertinib in patients with brain metastases is inconclusive and further study will be warranted. In phase II, abivertinib treatment demonstrated promising effects in PFS and OS with a median PFS of 7.5 months and a median OS of 24.9 months (40% maturity). The subsequent treatment after disease progression includes chemotherapy, rechallenging EGFR-TKIs and Chinese traditional medicines, etc.
In this study with Chinese patients, grade ≥ 3 AE AST/ALT increase occurred more frequently while grade ≥ 3 QT interval prolongation was observed at a similar frequency compared with data previously reported for other TKIs (2–4, 9, 19). However, the majority or AST/ALT increase AEs were mild (grade 1 in severity) and 2 AEs led to treatment discontinuation. The risk factors analysis reflected a relative actual situation for Chinese patients who had a more complicated medication history. The skin rash rate (37% for all grades and 2.2% for grade 3/4) was lower than many first- and second-generation TKIs reported (>70% for all grades and >15% for grade 3/4) probably due to spare target against WT EGFR by abivertinib treatment (2–4). ILD, a warning AE for all TKIs, occurred in 4.8% (13/272) at RP2D in this study; 11 cases (4.0%) were SAEs; 10 cases (3.7%) were grade ≥ 3; one case (0.4%) was fatal. Two cases with grade 2/3 ILD among above 13 cases were re-treated with abivertinib at reduced doses when ILD was recovered to grade 1 till disease progression, suggesting ILD is still controllable by abivertinib treatment. Together, abivertinib treatment in this study demonstrated favorable efficacy and safety profiles in patients with NSCLC patients with EGFR—resistant T790M mutation.
Abivertinib is a pyrrolpyrimidine-based, third-generation EGFR-TKI which is structurally distinct from FDA only approved third-generation TKI osimertinib (12). The molecular structure of a drug may determine its target-binding properties, subsequently the clinical outcomes, and ultimately molecular mechanism upon drug resistance. In recent clinical and nonclinical studies, resistance mechanism of abivertinib was reported to be distinct from that reviewed with osimertinb. Off-target resistance mechanisms involving TP53, MET, ERBB2, and RB1, etc. are thought to be the common resistance mechanisms found by abivertinib treatment as reported from current phase I/II study (43.3%, 13/30 cases; ref. 20), first-in-human study (62.5%, 10/16 cases; ref. 13), and nonclinical studies (BCL-2 and c-MET amplification from in vitro and in vivo results, respectively; ref. 21). EGFR tertiary mutations (8.7%, 4/30 from phase I/II and 0/16 from first-in-human resistance patients) including C797S by abivertinib treatment are much less than osimertinib resistance reported (21%–45%; refs. 13, 20). Moreover, EGFR T790M loss with abivertinib resistance (9.3%, 4/27 from phase I/II and 0/16 from first-in-human resistance patients) was less frequent than reported in osimertinib resistance cohorts (42%–68%), indicating that potential combination therapy, such as abivertinib in combination with drugs targeting bypass pathways, might be explored to overcome the resistance to abivertinib (13, 20). An impressive response was reported in several patients receiving sequential treatment firstly with abivertinib and followed by osimertinib, which suggests that rechallenging third-generation EGFR-TKIs with distinct resistance profile might warrant clinical benefits in patients failed with a third-generation EGFR-TKI (22).
In summary, phase I established abivertinib 300 mg twice a day as RP2D, which is consistent with that previously reported in abivertinib first-in-human study. The clinical efficacy of abivertinib coupled with its safety profile in phase II further confirmed positive clinical outcomes in patients with EGFR T790M+ resistant mutation. Whether the clinical benefits to abivertinib can be expanded in patients with EGFR-TKI–naïve advanced NSCLC will be evaluated in a randomized trial in comparison with gefitinib. In addition, further research into mechanism of acquired resistance with abivertinib and other third-generation EGFR-TKIs and strategies of subsequent treatment will help define the use of these agents in this setting.
Supplementary Material
Supplementary Data Click here for additional data file.
Acknowledgments
This research was supported by Key Lab System Project of Guangdong Science and Technology Department – Guangdong Provincial Key Lab of Translational Medicine in Lung Cancer (Grant No. 2017B030314120, to Y.L. Wu); High-level Hospital Construction Project (Grant No. DFJH201810, to Q. Zhou); and National Science and Technology Infrastructure Program (National Key Science Projects Program, Grant No. 2018ZX09301–014–002, to W.H. Xu, W. Tang, X. Zhang, and X. Xiao).
This study was funded by ACEA Pharmaceutical Research, Hangzhou, China. ACEA Pharmaceutical Research led the design and conduct of the study, monitored it, and provided the study drug. ACEA Pharmaceutical Research, with authors, also participated in the collection, management, analysis, and interpretation of the data. We appreciate the patients, their families, and caregivers for their participation in the study. Medical writing support was provided by Yiqun Zhou, PhD, EME Pharma Consultants, funded by ACEA Therapeutics Inc.
The costs of publication of this article were defrayed in part by the payment of page charges. This article must therefore be hereby marked advertisement in accordance with 18 U.S.C. Section 1734 solely to indicate this fact.
Authors' Disclosures
Q. Zhou reports personal fees from AstraZeneca, Boehringer Ingelheim, BMS, Eli Lilly and Company, MSD, Pfizer, Sanofi, and Roche outside the submitted work. Y.L. Wu reports grants, personal fees, and other support from AstraZeneca; grants and personal fees from BMS; personal fees and other support from Boehringer Ingelheim and Merck; personal fees from Eli Lilly and Company, Hengrui, MSD, Pfizer, Roche, and Sanofi; and other support from Takeda outside the submitted work. No disclosures were reported by the other authors.
Authors' Contributions
Q. Zhou: Conceptualization, resources, investigation, writing–original draft, writing–review and editing. L. Wu: Resources, investigation, writing–review and editing. P. Hu: Resources, investigation, writing–review and editing. T. An: Resources, investigation, writing–review and editing. J. Zhou: Resources, investigation, writing–review and editing. L. Zhang: Resources, investigation, writing–review and editing. X.Q. Liu: Resources, investigation, writing–review and editing. F. Luo: Resources, investigation, writing–review and editing. X. Zheng: Resources, investigation, writing–review and editing. Y. Cheng: Resources, investigation, writing–review and editing. N. Yang: Resources, investigation, writing–review and editing. J. Li: Resources, investigation, writing–review and editing. J. Feng: Resources, investigation, writing–review and editing. B. Han: Resources, investigation, writing–review and editing. Y. Song: Resources, investigation, writing–review and editing. K. Wang: Resources, investigation, writing–review and editing. L. Zhang: Resources, investigation, writing–review and editing. J. Fang: Resources, investigation, writing–review and editing. H. Zhao: Resources, investigation, writing–review and editing. Y. Shu: Resources, investigation, writing–review and editing. X.Y. Lin: Resources, investigation, writing–review and editing. Z. Chen: Resources, investigation, writing–review and editing. B. Gan: Resources, investigation, writing–review and editing. W.H. Xu: Resources, investigation, writing–review and editing. W. Tang: Resources, investigation, writing–review and editing. X. Zhang: Resources, investigation, writing–review and editing. J.J. Yang: Resources, investigation, writing–review and editing. X. Xu: Resources, investigation, writing–review and editing. Y.L. Wu: Conceptualization, resources, investigation, writing–original draft, writing–review and editing.
Note: Supplementary data for this article are available at Clinical Cancer Research Online (http://clincancerres.aacrjournals.org/).
==== Refs
References
1. Mok TS , WuYL, ThongprasertS, YangCH, ChuDT, SaijoN, . Gefitinib or carboplatin-paclitaxel in pulmonary adenocarcinoma. N Engl J Med 2009;361 :947–57.19692680
2. Rosell R , CarcerenyE, GervaisR, VergnenegreA, MassutiB, FelipE, . Erlotinib versus standard chemotherapy as first-line treatment for European patients with advanced EGFR mutation-positive non-small-cell lung cancer (EURTAC): a multicentre, open-label, randomised phase 3 trial. Lancet Oncol 2012;13 :239–46.22285168
3. Schuler M , WuYL, HirshV, O'ByrneK, YamamotoN, MokT, . First-line afatinib versus chemotherapy in patients with non-small cell lung cancer and common epidermal growth factor receptor gene mutations and brain metastases. J Thorac Oncol 2015;11 :380–90.
4. Wu YL , ChengY, ZhouX, LeeKH, NakagawaK, NihoS, . Dacomitinib versus gefitinib as first-line treatment for patients with EGFR-mutation-positive non-small-cell lung cancer (ARCHER 1050): a randomised, open-label, phase 3 trial. Lancet Oncol 2017;18 :1454–66.28958502
5. Yu HA , ArcilaME, RekhtmanN, SimaCS, ZakowskiMF, PaoW, . Analysis of tumor specimens at the time of acquired resistance to EGFR-TKI therapy in 155 patients with EGFR-mutant lung cancers. Clin Cancer Res 2013;19 :2240–7.23470965
6. Han B , YangL, WangX, YaoLD. Efficacy of pemetrexed-based regimens in advanced non-small cell lung cancer patients with activating epidermal growth factor receptor mutations after tyrosine kinase inhibitor failure: a systematic review. Onco Targets Ther 2018;11 :2121–9.29695919
7. Reck M , Paz-AresL, BidoliP, CappuzzoF, DakhilS, Moro-SibilotD, . Outcomes in patients with aggressive or refractory disease from REVEL: A randomized phase III study of docetaxel with ramucirumab or placebo for second-line treatment of stage IV non-small-cell lung cancer. Lung Cancer 2017;112 :181–7.29191593
8. Ramalingam SS , VansteenkisteJ, PlanchardD, ChoBC, GrayJE, OheY, . Overall survival with osimertinib in untreated, EGFR-mutated advanced NSCLC. NEJM 2020;382 :41–50.31751012
9. Mok TS , WuYL, AhnMJ, GarassinoMC, KimHR, RamalingamSS, . Osimertinib or platinum-pemetrexed in EGFR T790M-positive lung cancer. N Engl J Med 2017;376 :629–40.27959700
10. Janne PA , YangJC, KimDW, PlanchardD, OheY, RamalingamSS, . AZD9291 in EGFR inhibitor-resistant non-small-cell lung cancer. N Engl J Med 2015;372 :1689–99.25923549
11. Lee CK , NovelloS, RydenA, MannH, MokT. Patient-Reported symptoms and impact of treatment with osimertinib versus chemotherapy in advanced non-small-cell lung cancer: the AURA3 trial. J Clin Oncol 2018;36 :1853–60.29733770
12. Xu X , MaoL, XuW, TangW, ZhangX, XiB, . AC0010, an irreversible EGFR inhibitor selectively targeting mutated EGFR and overcoming T790M-induced resistance in animal models and lung cancer patients. Mol Cancer Ther 2016;15 :2586–97.27573423
13. Ma Y , ZhengX, ZhaoH, FangW, ZhangY, GeJ, . First-in-human Phase I study of AC0010, a mutant-selective EGFR inhibitor in non-small cell lung cancer: Safety, efficacy, and potential mechanism of resistance. J Thorac Oncol 2018;13 :968–77.29626621
14. Biankin AV , PiantadosiS, HollingsworthSJ. Patient-centric trials for therapeutic development in precision oncology. Nature 2015;526 :361–70.26469047
15. Yang JCH , CamidgeDR, YangCT, ZhouJ, GuoR, ChiuCH, . Safety, Efficacy, and pharmacokinetics of almonertinib (HS-10296) in pretreated patients with EGFR-mutated advanced NSCLC: a multicenter, open-label, phase 1 trial. J Thorac Oncol 2020;15 :1907–18.32916310
16. Kim DW , TanDS, AixSP, SequistLV, SmitEF, HidaT, . Preliminary Phase II results of a multicenter, open-label study of nazartinib (EGF816) in adult patients with treatment-naive non-small cell lung cancer (NSCLC). J Clin Oncol 2018;36 :9094.
17. Murakami H , NokiharaH, HayashiH, SetoT, ParkK, AzumaK, . Clinical activity of ASP8273 in Asian patients with non-small cell lung cancer with EGFR activating and T790M mutations. Cancer Sci 2018;109 :2852–62.29972716
18. Sequist LV , SoriaJC, GoldmanJW, WakeleeHA, GadgeelSM, VargaA, . Rociletinib in EGFR-mutated non-small-cell lung cancer. N Engl J Med 2015;372 :1700–9.25923550
19. Yang JC , AhnMJ, KimDW, RamalingamSS, SequistLV, SuWC, . Osimertinib in pretreated T790M-positive advanced non-small-cell lung cancer: AURA study phase II extension component. J Clin Oncol 2017;35 :1288–96.28221867
20. Zhang YC , ChenZH, ZhangXC, XuCR, YanHH, XieZ, . Analysis of resistance mechanisms to abivertinib, a third-generation EGFR tyrosine kinase inhibitor, in patients with EGFR T790M-positive non-small cell lung cancer from a phase I trial. EBioMedicine 2019;43 :180–7.31027916
21. Xu WH , TangW, LiTT, ZhangXY, SunY, . Overcoming resistance to AC0010, a third generation of EGFR inhibitor, by targeting c-Met and Bcl-2. Neoplasia 2019;21 :41–45.30504063
22. Zhang YC , ZhouQ, ChenZH, ChuaiSK, YeJY, WuYL, . The spatiotemporal evoluation of EGFR C797S mutation in EGFR non-small cell lung cancer: opportunity for third-generation EGR inhibitors re-challenge. Sci Bulletin 2019;64 :499–503.Сначала следует использовать подходящую модель НЛП.,Извлечение категорий из статей,автор,Котировки и другая информация,Этот тип информации больше подходит для хранения в поле ключевого слова для полнотекстового поиска и точного соответствия.。Для введения, резюме, результатов, контента, эффектов и т. д. после разделения на фрагменты используется модель внедрения для извлечения информации о функциях.。
Потребление ресурсов и использование модели внедрения
с другой стороны,Чтобы добиться лучших результатов,Встраивание моделей имеет тенденцию увеличивать параметры модели для улучшения понимания контекста. Несколько хороших моделей встраивания,Он может даже поддерживать семантическое понимание на нескольких языках.,Но еще и потому, что параметров больше,Часто он потребляет больше ресурсов。OpenAIизembeddingМодельtext-embedding-ada-002,Размер модели превышает 300 ГБ.
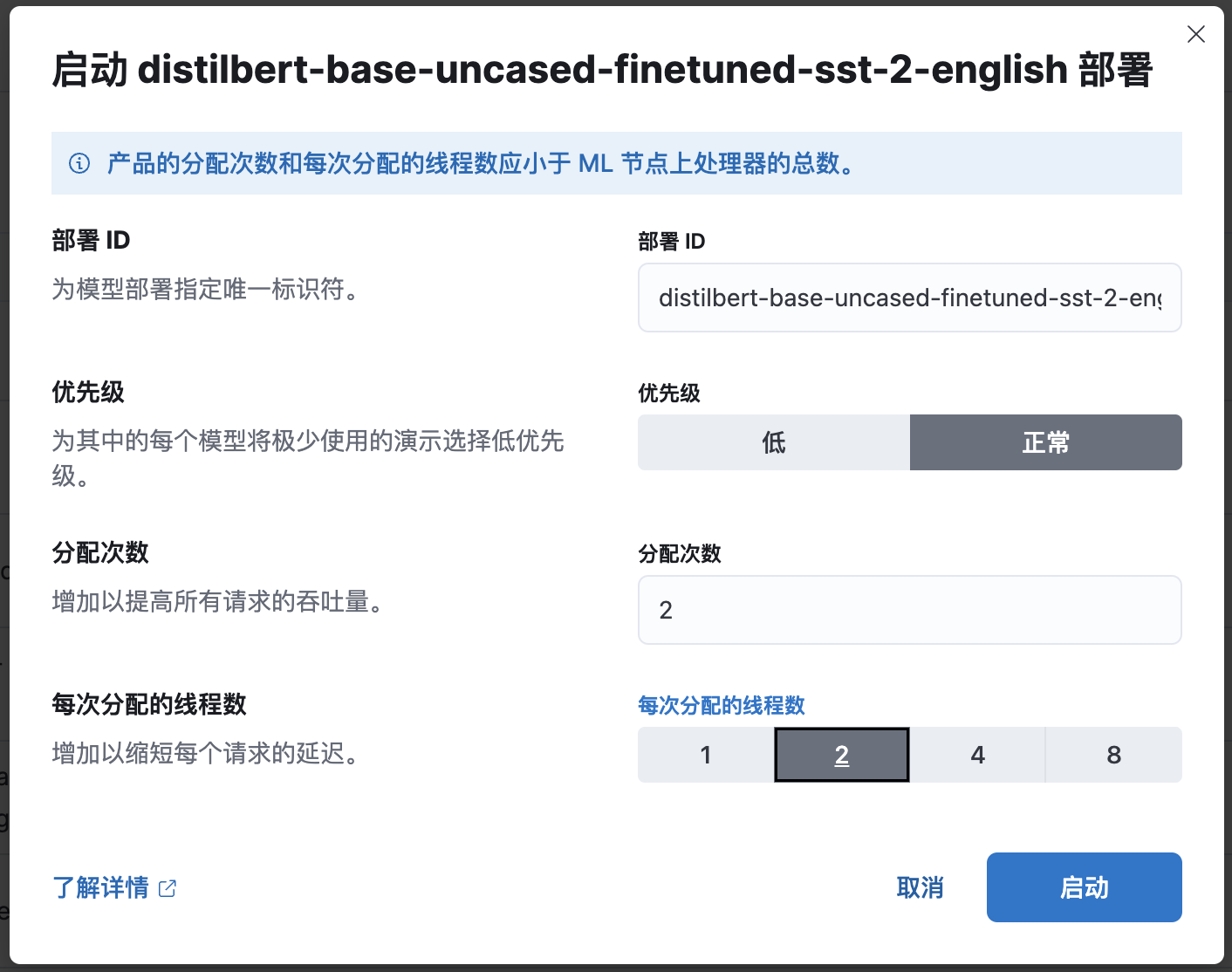
Если вы используете платформу машинного обучения для развертывания, вам необходимо обратить внимание на потребление ресурсов. В Elasticsearch модели распределяются между потоками. Другими словами, модель будет загружена в память и распределена между несколькими выделениями (чем больше выделений, тем выше одновременная пропускная способность), и каждое выделение может улучшить возможности обработки за счет настройки многопотоков (чем больше потоков, тем выше одновременная пропускная способность). ). Чем быстрее скорость рассуждений)
Помните о начале и никогда не забывайте первоначальное намерение: конечная цель — улучшить запоминаемость и релевантность.
Чтобы предоставить более точную контекстную информацию для больших моделей, необходимо объединить лучшие методы в разных сценариях для достижения эффективности и точности.
В практических приложениях нам часто необходимо объединить векторный поиск и другие технологии поиска или даже объединить машинное обучение и технологию рассуждений НЛП, чтобы создать эффективную и гибкую систему поиска. Это позволяет в полной мере использовать преимущества различных технологий, избегая при этом их ограничений. Вот некоторые распространенные методы и предложения:
- Используйте гибридный индекс для хранения документов. Гибридный индекс — это индексная структура, которая содержит как терминальный индекс, так и векторный индекс. Указатель терминов используется для хранения такой информации, как термины, которые встречаются в документе, и их частота. Векторные индексы используются для хранения векторов, полученных путем преобразования документов с помощью моделей глубокого обучения. Таким образом, вы можете использовать индекс термина или векторный индекс в соответствии с различными потребностями при запросе.
- Используйте другие технологии НЛП для извлечения функций глубокого понимания и маркировки информации в данных (например, моделей прогнозирования категорий и моделей распознавания сущностей) для фильтрации и извлечения индексов слов.
- Используйте двухэтапный поиск для выполнения запросов. Двухслойный поиск — это метод запроса, который сначала использует индекс термина для грубого ранжирования (грубое ранжирование), а затем использует векторный индекс для точного ранжирования (тонкое ранжирование). Грубая сортировка используется для быстрой фильтрации пакета документов-кандидатов из большого количества документов. Точная сортировка используется для дальнейшей фильтрации наиболее релевантных документов из документов-кандидатов. Это может улучшить качество запросов, обеспечивая при этом эффективность запросов.
- Используйте многоэтапный поиск (Многоэтапный поиск) для выполнения запроса. Мультиплексирование — это поиск с использованием нескольких индексов разных типов или источников.,и выполнять каждый результат поискаСлияниеилиИзменение рейтингаиз查询
- Необходимо настроить корреляцию, пока,поставлятьПроверка эффекта отзываспособность:
- Скорректированные параметры поиска, поля и индексы
- Переключенная модель внедрения
- Использует новый алгоритм сортировки
И вПоисковая платформа Elasticsearch не только предоставляет различные инструменты для повышения релевантности поиска, но также предоставляет инструменты базового тестирования для проверки эффектов отзыва и релевантности.。Благодаря поддержке сообщества можно использовать разные плагины для оптимизации в разных ситуациях.
Улучшение возможностей поиска не может быть достигнуто в одночасье. Изменения в требованиях и технологических итерациях также означают, что требуется постоянное совершенствование. Выбор надежной, полной и широко проверенной платформы станет для нас хорошим началом для эффективного использования семантического поиска и эффективной интеграции с большими моделями, что поможет нам победить на старте.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
