Как Elasticsearch 8.X генерирует терабайты тестовых данных?
1. Практические вопросы
- Я просто хочу вставить много тестовых данных,Не пытаюсь проверить производительность,Существует ли автоматический способ генерировать уровень ТБ на основе тестовых данных?
- инструмент? Или есть что-то вроде тестового набора? ——Проблема возникает из-за Elasticsearch Китайское сообщество https://elasticsearch.cn/question/13129
2. Анализ проблемы
На самом деле, подобные вопросы часто задавались в сообществе и раньше. В реальных бизнес-сценариях, прежде чем станут доступны крупномасштабные данные, некоторые данные моделирования могут быть сконструированы и сгенерированы для таких целей, как тестирование производительности.
Реальные бизнес-сценарии обычно не беспокоятся о данных, включая, помимо прочего:
- генерироватьданные
- Бизнес-система производит данные
- Сбор и генерация Интернета, оборудования и т.д.изданные
- Другие сценарии, генерирующие данные.....
Проблема регрессии: как устроен Elasticsearch 8.X?
Решение, предложенное заклятым врагом эксперта сообщества, г-ном Вэнем, состоит в том, чтобы переиндексировать два образца данных взад и вперед, удваивая объем данных за одну операцию.
Фактически, заклятый враг Вэнь относится к следующим трем частям выборочных данных.
Так есть ли другие решения? В этой статье представлены два варианта.

3. Вариант 1: elasticsearch-faker конструирует данные
Введение в инструмент elasticsearch-faker 3.0
elasticsearch-faker — это инструмент командной строки для создания поддельных данных для Elasticsearch.
Он использует шаблоны для определения генерируемой структуры данных и использует заполнители в шаблоне для представления динамического контента, такого как случайные имена пользователей, числа, даты и т. д.
Эти заполнители будут заполнены случайно сгенерированными данными, предоставленными библиотекой Faker. При запуске инструмент генерирует документы на основе заданного шаблона и загружает их в индекс Elasticsearch для тестирования и разработки с целью проверки функциональности запросов и агрегатов Elasticsearch.
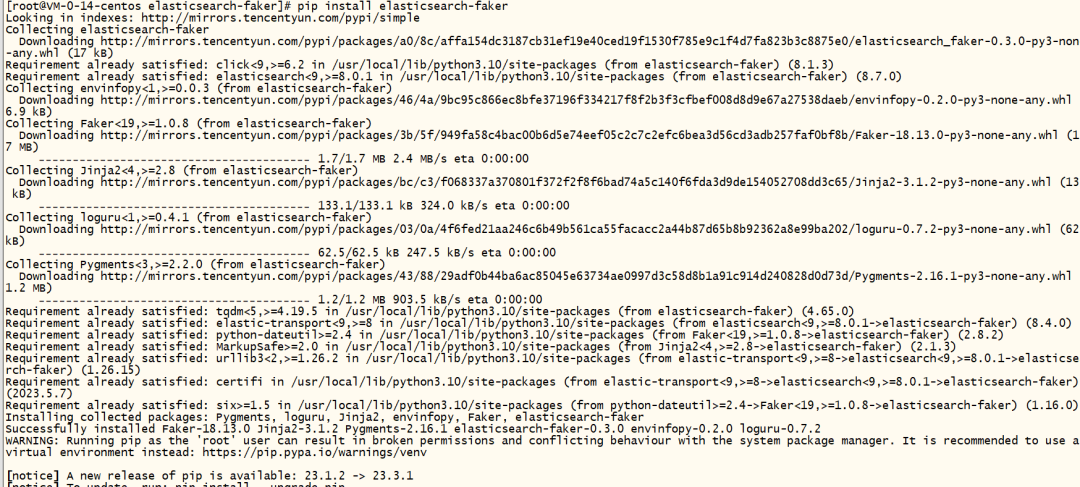
3.1 Шаг 1. Установите набор инструментов
https://github.com/thombashi/elasticsearch-faker#installation
pip install elasticsearch-faker
3.2 Шаг 2. Создайте сценарий запуска es_gen.sh
#!/bin/bash
# Установить переменные среды
export ES_BASIC_AUTH_USER='elastic'
export ES_BASIC_AUTH_PASSWORD='psdXXXXX'
export ES_SSL_ASSERT_FINGERPRINT='XXddb83f3bc4f9bb763583d2b3XXX0401507fdfb2103e1d5d490b9e31a7f03XX'
# вызов elasticsearch-faker Команда для генерации данных
elasticsearch-faker --verify-certs generate --doc-template doc_template.jinja2 https://172.121.10.114:9200 -n 1000
В то же время отредактируйте файл шаблона doc template.jinja2.
Шаблон выглядит следующим образом:
{
"name": "{{ user_name }}",
"userId": {{ random_number }},
"createdAt": "{{ date_time }}",
"body": "{{ text }}",
"ext": "{{ word }}",
"blobId": "{{ uuid4 }}"
}
3.3 Шаг 3: Запустите сценарий es_gen.sh
[root@VM-0-14-centos elasticsearch-faker]# ./es_gen.sh
document generator #0: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 1194.47docs/s]
[INFO] generate 1000 docs to test_index
[Results]
target index: test_index
completed in 10.6 secs
current store.size: 0.8 MB
current docs.count: 1,000
generated store.size: 0.8 MB
average size[byte]/doc: 831
generated docs.count: 1,000
generated docs/secs: 94.5
bulk size: 200

3.4 Шаг 4. Просмотрите результаты импортированных данных в Kibana.

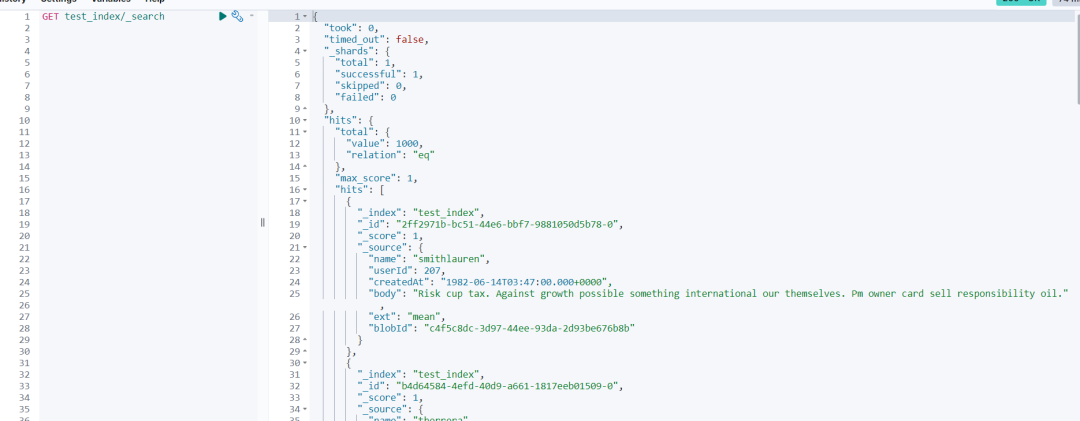
"hits": [
{
"_index": "test_index",
"_id": "2ff2971b-bc51-44e6-bbf7-9881050d5b78-0",
"_score": 1,
"_source": {
"name": "smithlauren",
"userId": 207,
"createdAt": "1982-06-14T03:47:00.000+0000",
"body": "Risk cup tax. Against growth possible something international our themselves. Pm owner card sell responsibility oil.",
"ext": "mean",
"blobId": "c4f5c8dc-3d97-44ee-93da-2d93be676b8b"
}
},
{
4. Используйте плагин генератора Logstash для генерации случайных выборочных данных.

4.1 Подготовьте среду
Убедитесь, что в вашей среде установлены Elasticsearch 8.X и Logstash 8.X. Elasticsearch должен быть настроен правильно и работать через HTTPS.
Кроме того, убедитесь, что соответствующие сертификаты для Elasticsearch правильно настроены в Logstash.
4.2 Генерация выборки данных
Мы будем использовать плагин ввода генератора Logstash для создания данных и плагин фильтра Ruby для генерации UUID и случайных строк.
4.3 Конфигурация Логсташа
Создайте файл конфигурации с именем logstash-random-data.conf и заполните следующее содержимое:
input {
generator {
lines => [
'{"regist_id": "UUID", "company_name": "RANDOM_COMPANY", "regist_id_new": "RANDOM_NEW"}'
]
count => 10
codec => "json"
}
}
filter {
ruby {
code => '
require "securerandom"
event.set("regist_id", SecureRandom.uuid)
event.set("company_name", "COMPANY_" + SecureRandom.hex(10))
event.set("regist_id_new", SecureRandom.hex(10))
'
}
}
output {
elasticsearch {
hosts => ["https://172.121.110.114:9200"]
index => "my_log_index"
user => "elastic"
password => "XXXX"
ccacert => "/www/elasticsearch_0810/elasticsearch-8.10.2/config/certs/http_ca.crt"
}
stdout { codec => rubydebug }
}
4.4 Анализ файлов конфигурации
- 1.Input
- a.generator плагиниспользуется длягенерироватьсобытиепоток。
- b.lines содержит строковый шаблон JSON, который определяет структуру каждого события.
- c.count указывает количество генерируемых документов.
- Для d.codec установлено значение json, чтобы сообщить Logstash ожидаемый формат ввода.
- 2.Filter
- Фильтр a.ruby используется для выполнения кода Ruby.
- б. UUID генерируется как Regist_id во фрагменте кода.
- c.company_name и regist_id_new заполняются случайными шестнадцатеричными строками.
- 3.Output
- а. Укажите хост, индекс, информацию для аутентификации пользователя и сертификат Elasticsearch.
- b.stdout Вывод предназначен для отладки, он выведет Logstash После обработки изсобытие.
4.5 Запуск Logstash
После сохранения файла конфигурации выполните следующую команду в терминале, чтобы запустить Logstash и сгенерировать данные:
$ bin/logstash -f logstash-random-data.conf
Результаты выполнения следующие:
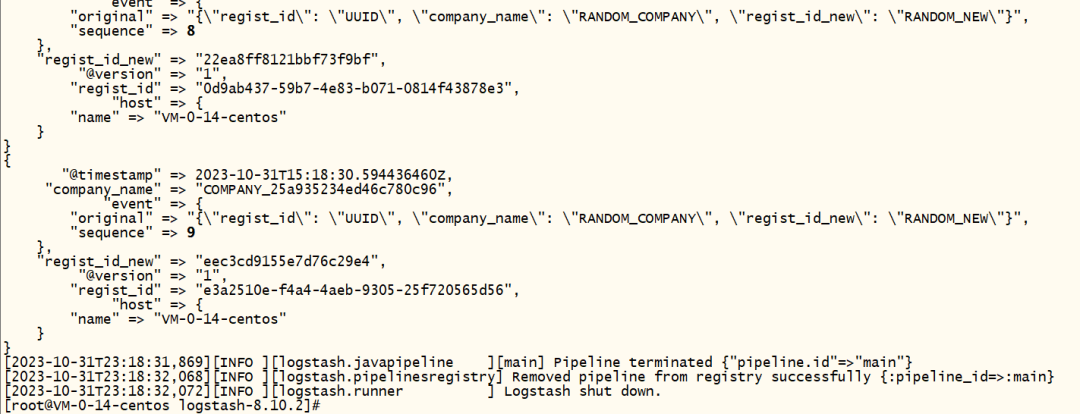
Результаты просмотра данных в кибане следующие:
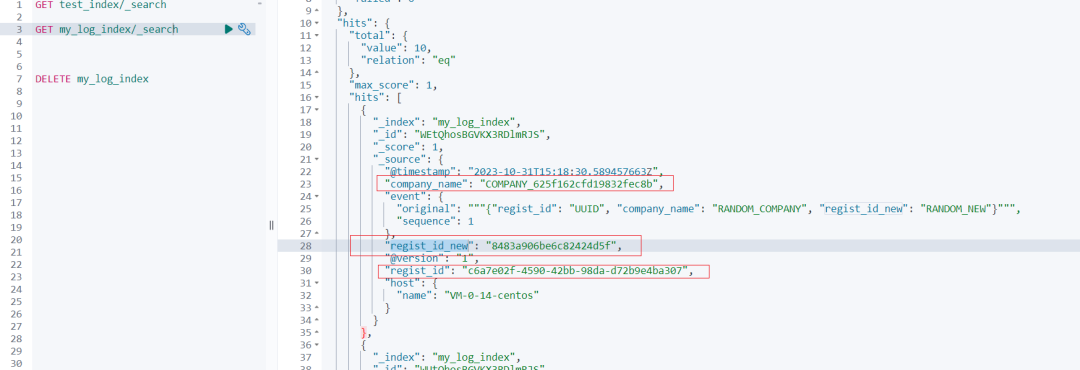
С помощью Logstash мы можем легко генерировать большие объемы случайных выборочных данных для тестирования и разработки Elasticsearch. Этот метод не только эффективен, но и гибок для генерации данных в различных форматах в соответствии с потребностями.
5. Резюме
Все вышеуказанные проверки были проверены с использованием версии Elasticsearch 8.10.2.
Фактически, в дополнение к двум решениям, приведенным в статье, существует множество других решений, таких как: esrally генерирует тестовые данные, использует Faker Python для реализации построения образцов данных, Common Crawl, Kaggle и другие веб-сайты предоставляют большие общедоступные наборы данных, который можно использовать в качестве источника тестовых данных.
Сталкивались ли вы с подобными проблемами и как вы их решили? Добро пожаловать, чтобы оставить сообщение и пообщаться.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
