Изучение архитектуры LLaMA, самой сильной английской модели открытого исходного кода, от принципа до исходного кода.
Введение:
LLaMA 65Bсделан изMeta ИИ (ранее Facebook AI) выпустила и анонсировала крупномасштабную языковую модель с открытым исходным кодом, состоящую из сотен миллиардов языков, которая вызвала настоящий переполох после ее выпуска (24 февраля 2023 г.). Появление LLaMA больше похоже на срыв в войне моделей. Несмотря на то, что между его производительностью и GPT-4 все еще существует разрыв, GPT-4 в конце концов представляет собой бизнес-модель с закрытым исходным кодом. Открытый исходный код серии LLaMA дал другим командам по всему миру возможность изучить и использовать сотни миллиардов. языковых моделей.
Прочитав эту статью, вы можете подумать, что LLaMA будет Открытый исходный коднеудивительно,из-за его Архитектура Можно сказать, что вы стоите на плечах гигантов и собираете яблоки.——По сути, можно сказать, что новая модель строится с использованием компонентов других моделей в качестве «строительных блоков».,Существенных инноваций не так много.,但这种敢于Открытый исходный Смелость и подход кода делают LLaMA подходящей для Открытого на большом языке Модель исходный код стал знаковой вехой в истории развития。

Introducing LLaMA: A foundational, 65-billion-parameter large language model Адрес открытого исходного кода LLaMA: https://github.com/facebookresearch/llama (llama находится в ветке кода llama_v1)
текст
«лама» на английском языке означает «лама», которая представляет собой вид верблюдовых и род альпака, распространенный в Южной Америке.

LLaMAоснован наtransformerАрхитектурабольшой язык Модель,То же, что и PaLM от Google.,против оригиналаtransformerАрхитектура Некоторый“небольшие улучшения”。общий,Оригинальный преобразователь Архитектураи в первой версии LLaMA имеет три основных отличия:
- Предварительная нормализация(Pre-Normalization)[кGPT3Вдохновлять]:Для улучшения стабильности во время тренировки,LLaMAНормализованныйtransformerподуровеньвходитьвместовыход,Конкретный используемый метод регуляризации:
RMSNorm。 - Функция активации SwiGLU [кPaLMВдохновлять]:LLaMAиспользовалиPaLMТакой же
SwiGLUфункция активации для замены оригиналаReLUулучшить Модель Эффект。подробно,LLaMA использует размерность как
вместо
。
- Кодирование вращательного положения(Rotary Embedding, Rotary Position Встраивание) [на основе GPTNeo]: LLaMA не использует кодирование абсолютной позиции (позиция BERT
、
кодирование является абсолютным позиционным кодированием),Скорееиспользовал Кодирование относительного положенияRoPE。
Кроме того, некоторые подробности обучения:
- LLaMAиспользовать
adamWоптимизатор,Установить гиперпараметры
,
。
- использоватьпланирование скорости обучения косинуса,Прямо сейчасфинальныйскорость обученияявляется крупнейшимскорость обученияиз10%。
- снижение весаустановлен на0.1。
- градиентная обрезкаустановлен на1。
- Горячий старт 2000 шагов(warmup)。
- Модели разных размеровиспользоватьдругойизскорость обученияиbatch size。
Давайте более подробно рассмотрим технические детали трех архитектурных отличий.
RMSNorm
Подробную информацию о процессе отправки см. в исходном документе.:Root Mean Square Layer Normalization
Предварительная нормализация(Pre-Normalization)Может сделать тренировочный процесс более стабильным,В этой конструкции первый уровень нормализации размещается перед слоем многоголового внимания.,Нормализация второго слоя переносится перед полносвязным слоем.,В то же время,shortcutустановить вmulti-attentionслой сFNNмежду слоями。Как показано ниже:
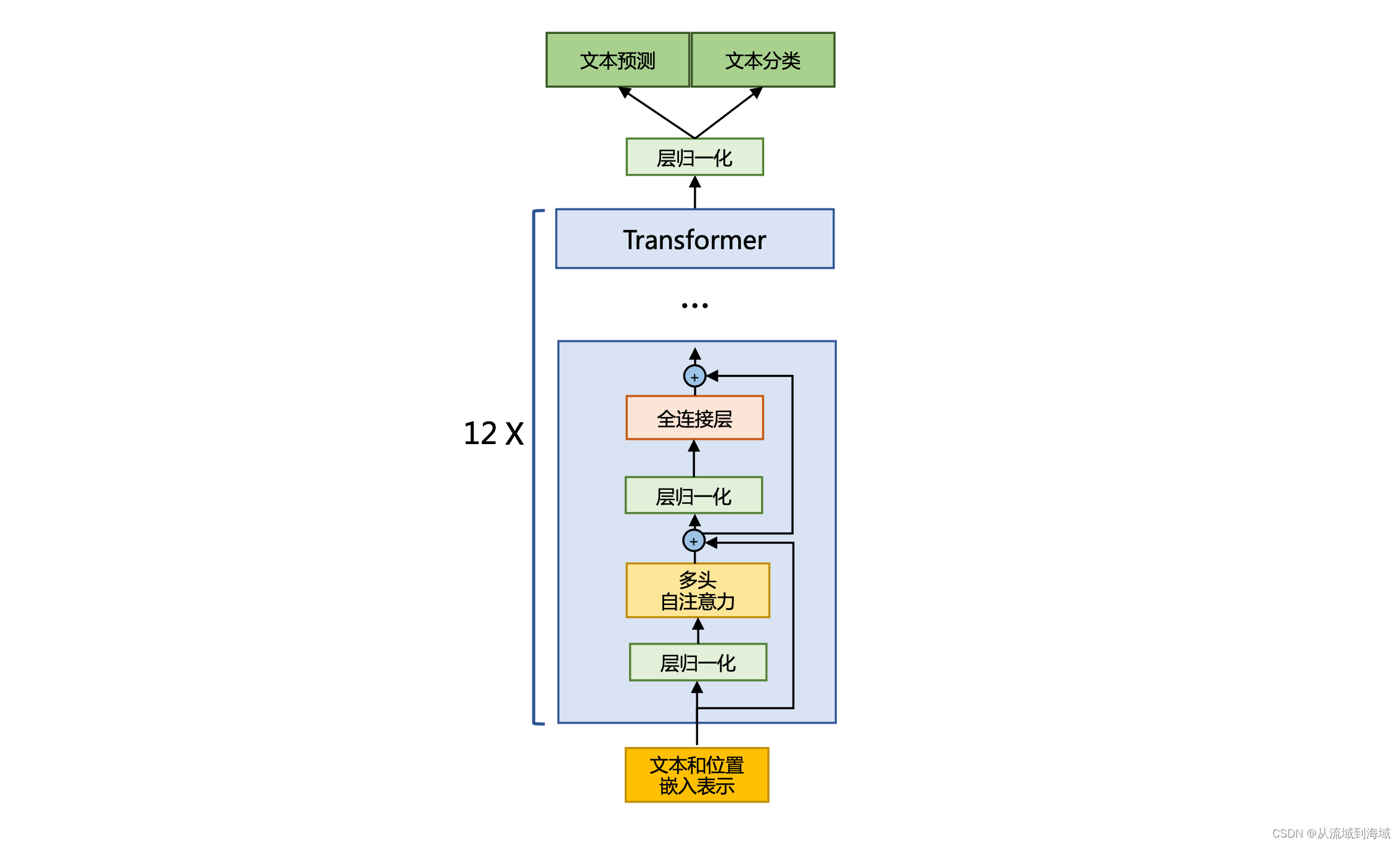
LLaMA использует RMSNorm в процессе нормализации для входного вектора.
, Формула расчета RMSnorm выглядит следующим образом:
По сравнению с исходным RMSNorm, LLaMA добавляет коэффициент масштабирования.
и параметр смещения
(Оба параметра являются изучаемыми), и в итоге мы получаем:
Реализация LLaMA RMSNorm в библиотеке HuggingFace Transformer выглядит следующим образом:
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
LlamaRMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps # eps Чтобы не брать обратную величину, знаменатель равен 0
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True) hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon) # weight обучаемый параметр, умноженный в конце, Прямо сейчас g_i
return (self.weight * hidden_states).to(input_dtype)Функция активации SwiGLU
Подробный процесс вывода см. в исходной статье.:GLU Variants Improve Transformer
Активация функции SwiGLU, используемая LLaMA, также используется во многих приложениях LLM, таких как PaLM. По сравнению с ReLU она может значительно улучшить многие наборы оценочных данных.
Полносвязный уровень LLaMA использует функцию активации Формула расчета SwiGLU выглядит следующим образом:
в
То есть сигмовидная функция.
функция в параметрах
Формы разные, когда значения разные, как показано ниже:
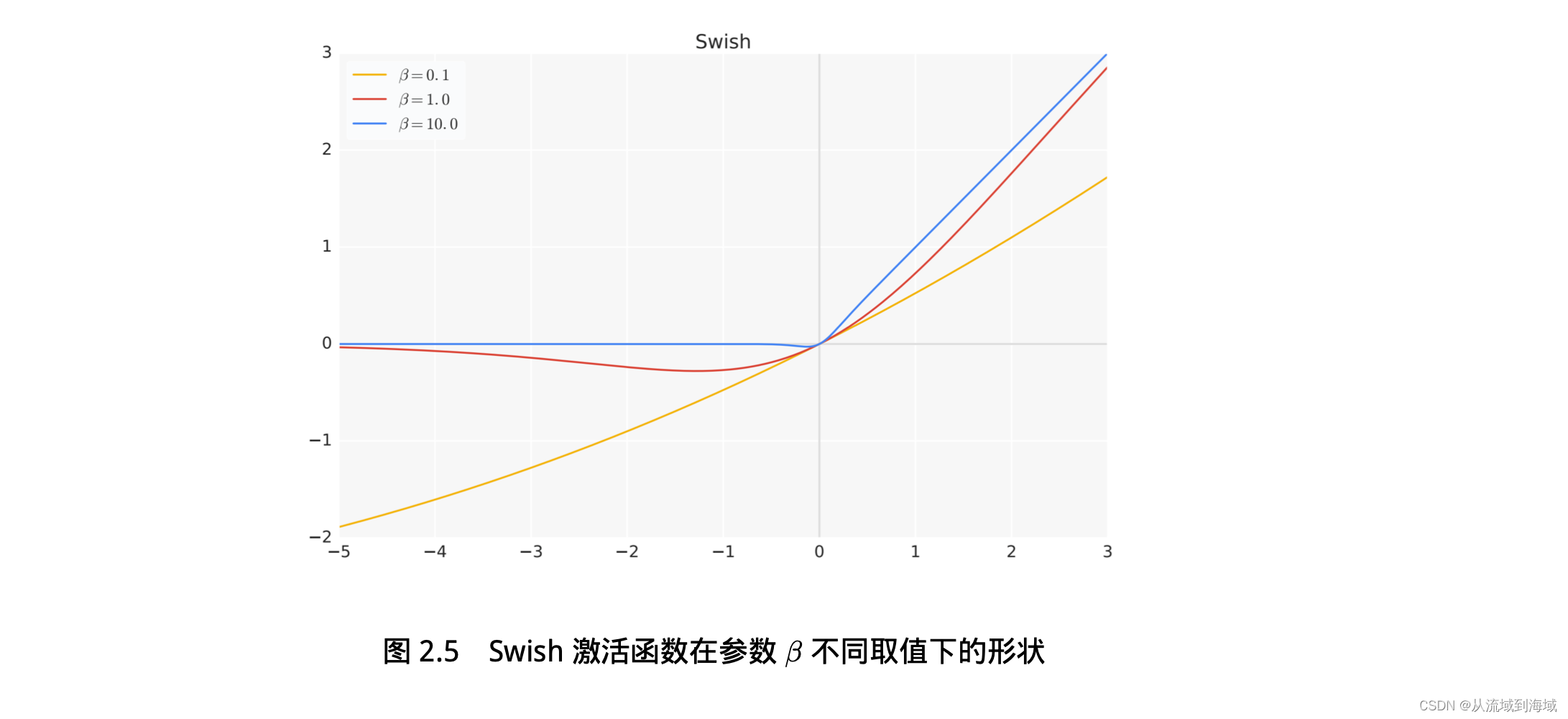
- когда
час,
- когда
час,
ПЛАМЯсередина
, размеры масштабируются до
:
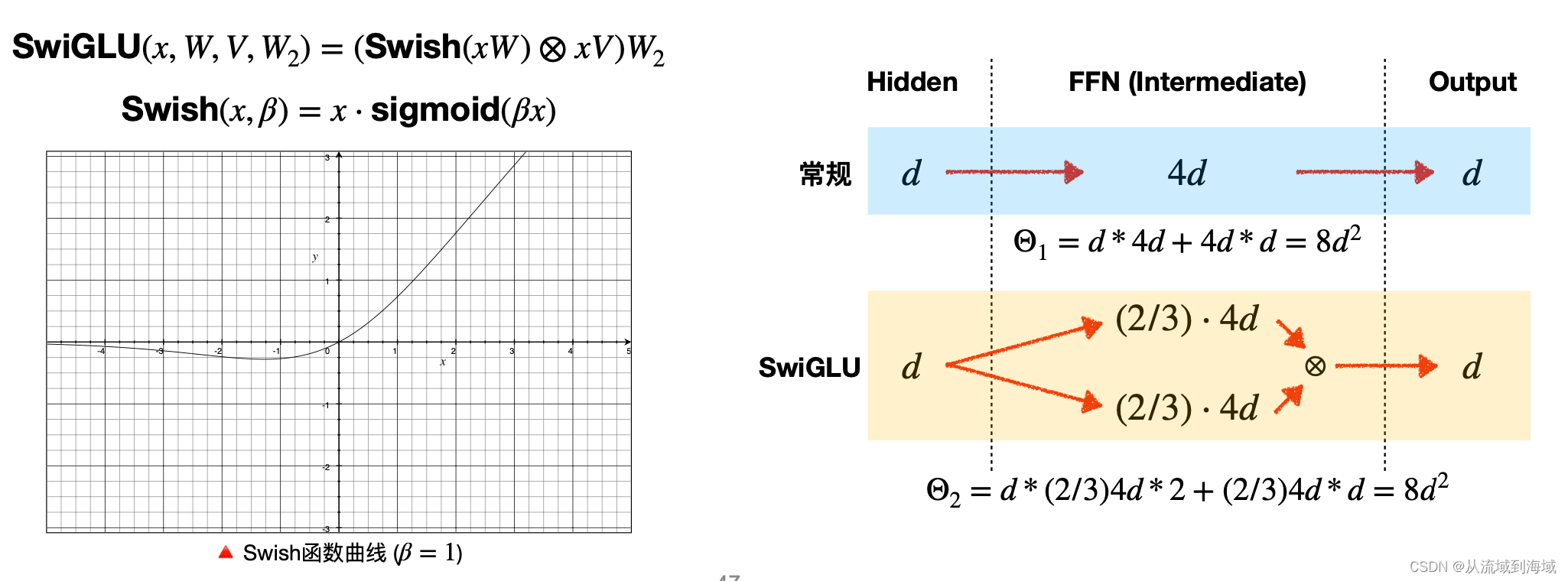
SwishGLUвведен в определенной степениМеханизм ворот,Экспериментальные результаты оригинальной статьи доказалиМетоды на основе стробирования обычно лучше, чем простые функции активации.(ReLU /GELU/Swish)
Кодирование поворотного положения RoPE (вложение поворотного положения)
Подробный процесс вывода см. в исходной статье.:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
LLaMA использует RoPE вместо исходного кодирования абсолютного положения (ссылаясь на кодировку BERT).
、
Кодирование позиции рассчитывается как фиксированное значение.,Позиция, представленная логически, также фиксирована),для достижения лучших результатов. Математический вывод RoPE основан на идее комплексных чисел.,Автор оригинала надеется использовать математические методы дляРеализация кодирования относительной позиции на основе кодирования абсолютной позиции,Идем дальше,Вектор существования
и
, информацию об абсолютном положении можно добавить к ним с помощью следующей операции:
и
Имей это
и
абсолютная информация о местоположении.
Выводится следующим образом:
(Подробный процесс вывода см. в исходном документе)
По геометрическому смыслу комплексного умножения,вышеПреобразование фактически соответствует операции вращения вектора.,отсюда и название“Кодирование вращательного положения”,Матричная форма может обеспечить другое понимание:
В соответствии с тем свойством, что внутренний продукт удовлетворяет линейной суперпозиции, RoPE в любом четном измерении может быть выражен как сращивание двумерного случая, а формула дополнительно преобразуется в:
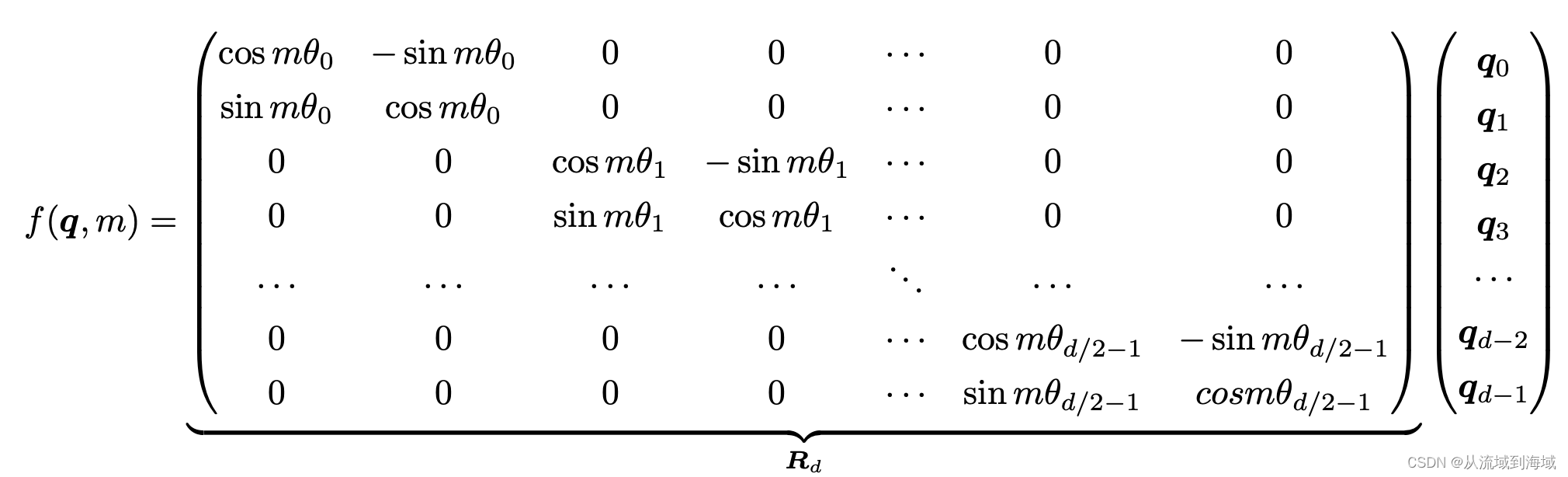
Вышеупомянутую разреженную матрицу можно умножить побитово, используя
Для ускорения вычислений кодовая реализация RoPE в библиотеке HuggingFace Transformer выглядит следующим образом:
class LlamaRotaryEmbedding(torch.nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))
self.register_buffer("inv_freq", inv_freq)
# Build here to make `torch.jit.trace` work.
self.max_seq_len_cached = max_position_embeddings
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device,
dtype=self.inv_freq.dtype)
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation
# in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
dtype = torch.get_default_dtype()
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
# This `if` block is unlikely to be run after we build sin/cos in `__init__`. # Keep the logic here just in case.
if seq_len > self.max_seq_len_cached:
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation
# in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1).to(x.device) self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype),
persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype),
persistent=False)
return (
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
)
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them. cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embedМодели LLaMA с разными масштабами параметров
На основе того, что мы объяснили ранее, можно реализовать полный декодер LLaMA. Код реализации в библиотеке HuggingFace Transformer выглядит следующим образом:
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = LlamaAttention(config=config)
self.mlp = LlamaMLP(
hidden_size=self.hidden_size,
intermediate_size=config.intermediate_size,
hidden_act=config.hidden_act,
)
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = False,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights,)
if use_cache:
outputs += (present_key_value,)
return outputsЗатем нажмите на архитектуру, чтобы реализовать всю модель LLaMA.
Meta выпустила в общей сложности 4 размера LLaMA. Подробная информация о моделях разных размеров следующая:
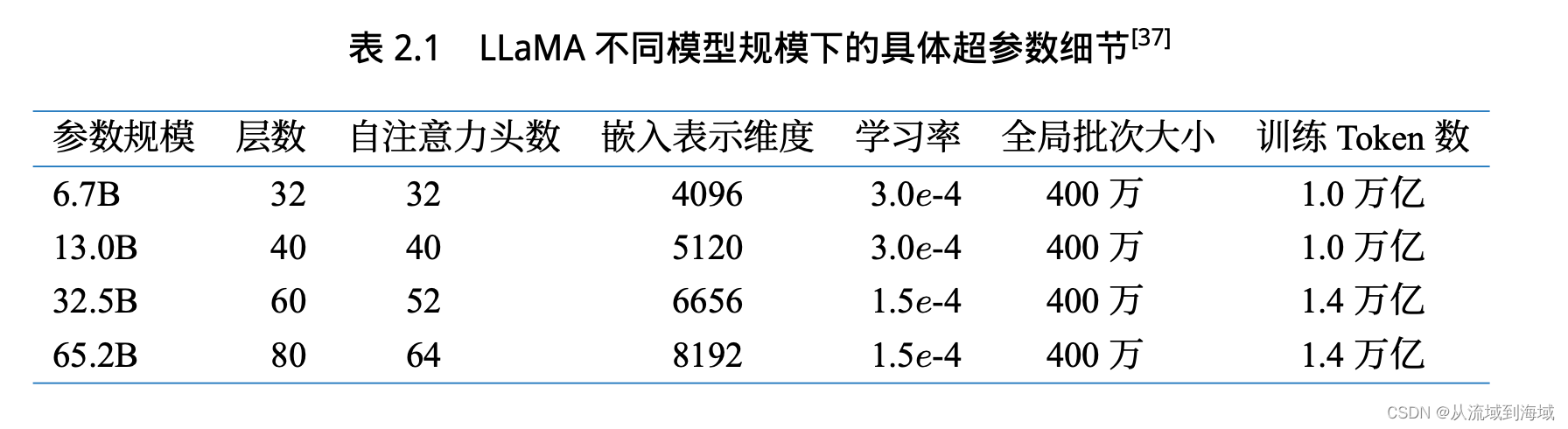
Предварительная тренировка
Набор данных перед обучением оказывает глубокое влияние на эффект модели. Соотношение и размер смешанного набора данных, используемого LLaMA, следующие:
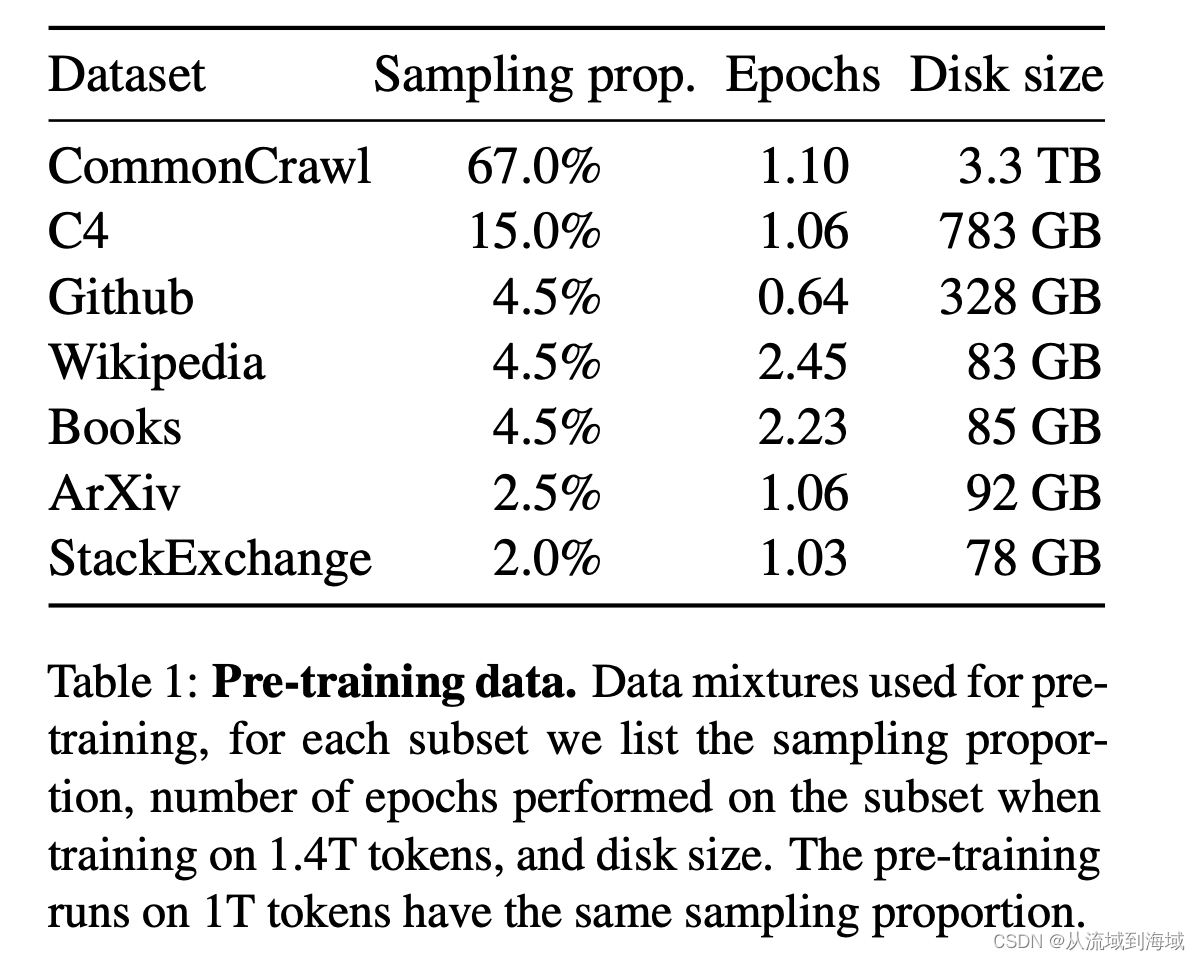
предварительная Набор данных подготовки после токенизации составляет 1,4Т токенов. Токен подготовки используется только один раз, но набор данных WikipediaиBooks обучается в течение 2 раундов.
Инструкция по тонкой настройке
В статье LLaMA первоначальный автор попытался выполнить простую настройку инструкций LLaMA, и результатом стало улучшение набора данных MMLU на 5,4%:
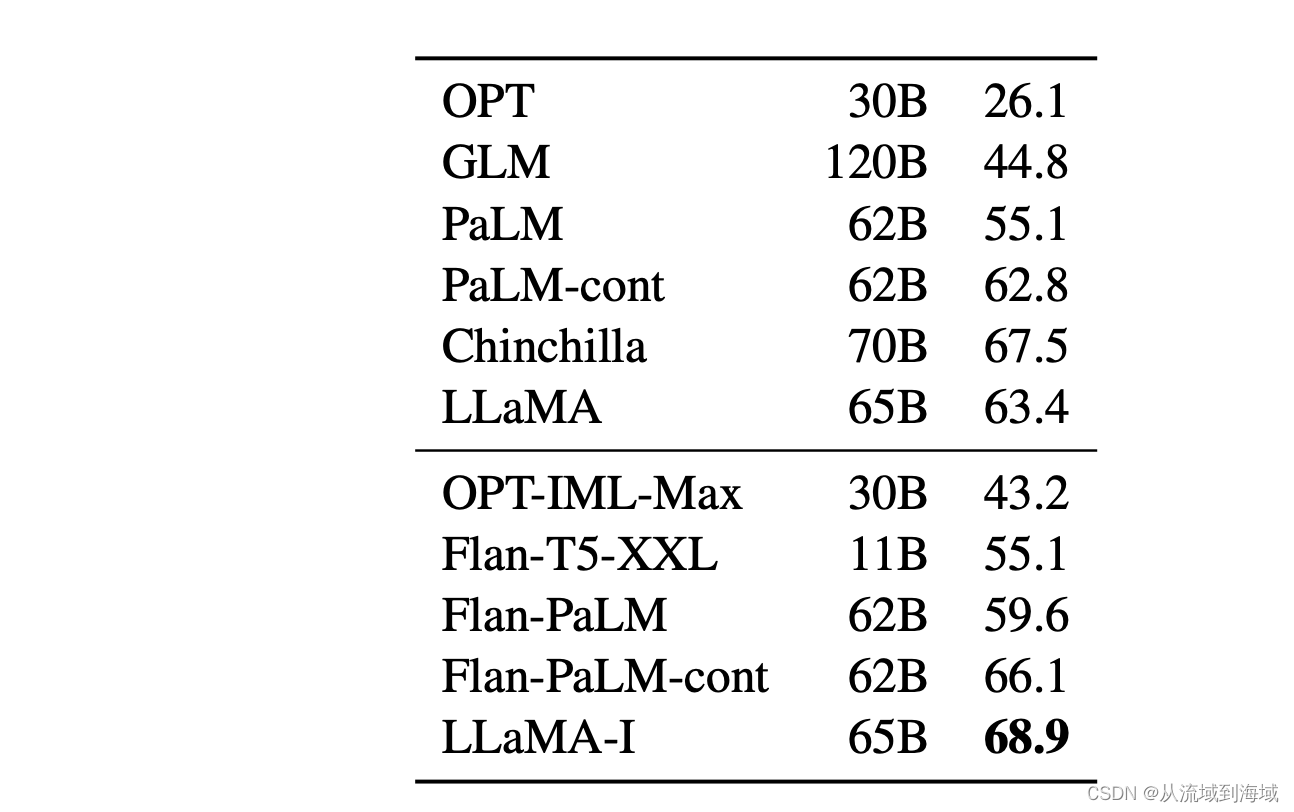
Тонкая настройка инструкцийиз Подробнее см.:Scaling Instruction-Finetuned Language Models,Автор использовал тот же процесс для сравнения эффектов Модели.
Заключение
На этом архитектурные исследования LLaMA заканчиваются.
По мере постепенного увеличения параметров большой Модели,Общей архитектуры Модели уже недостаточно, чтобы оказать решающее влияние на конечный результат.,Вместо этого некоторые мелкие детали набора данных определяют окончательный эффект Модели. Хотя у LLaMA нет особо ярких новинок.,Но некоторые из его экспериментальных выводов,Также сзадииз Модельдизайниобучение дает хорошиеиз Эталонное значение。как первый Открытый исходный Большая модель кода, выпущенная ведущими компаниями отрасли, LLaMA на самом деле играет роль Большой модели Открыто. исходный Основополагающая роль процесса кодирования.
Я надеюсь, что в будущем все больше и больше крупных моделей станут открытыми, а также надеюсь, что обработка естественного языка действительно сможет принести больше практических прорывов в производительность труда человека.
Ссылки
- LLaMA: Open and Efficient Foundation Language Models
- Introducing LLaMA: A foundational, 65-billion-parameter large language model
- Модель крупномасштабного языка: от принципа к практике (учебник Фудань НЛП)
- крупный масштабпредварительная Методика подготовки языка Модель и практика (Цуй Иминг Пекин·BAAI 26 августа 2023 г.)
- Root Mean Square Layer Normalization
- GLU Variants Improve Transformer
- ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
- Scaling Instruction-Finetuned Language Models


Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!

HTML можно преобразовать в word_html для отображения текстовых документов.
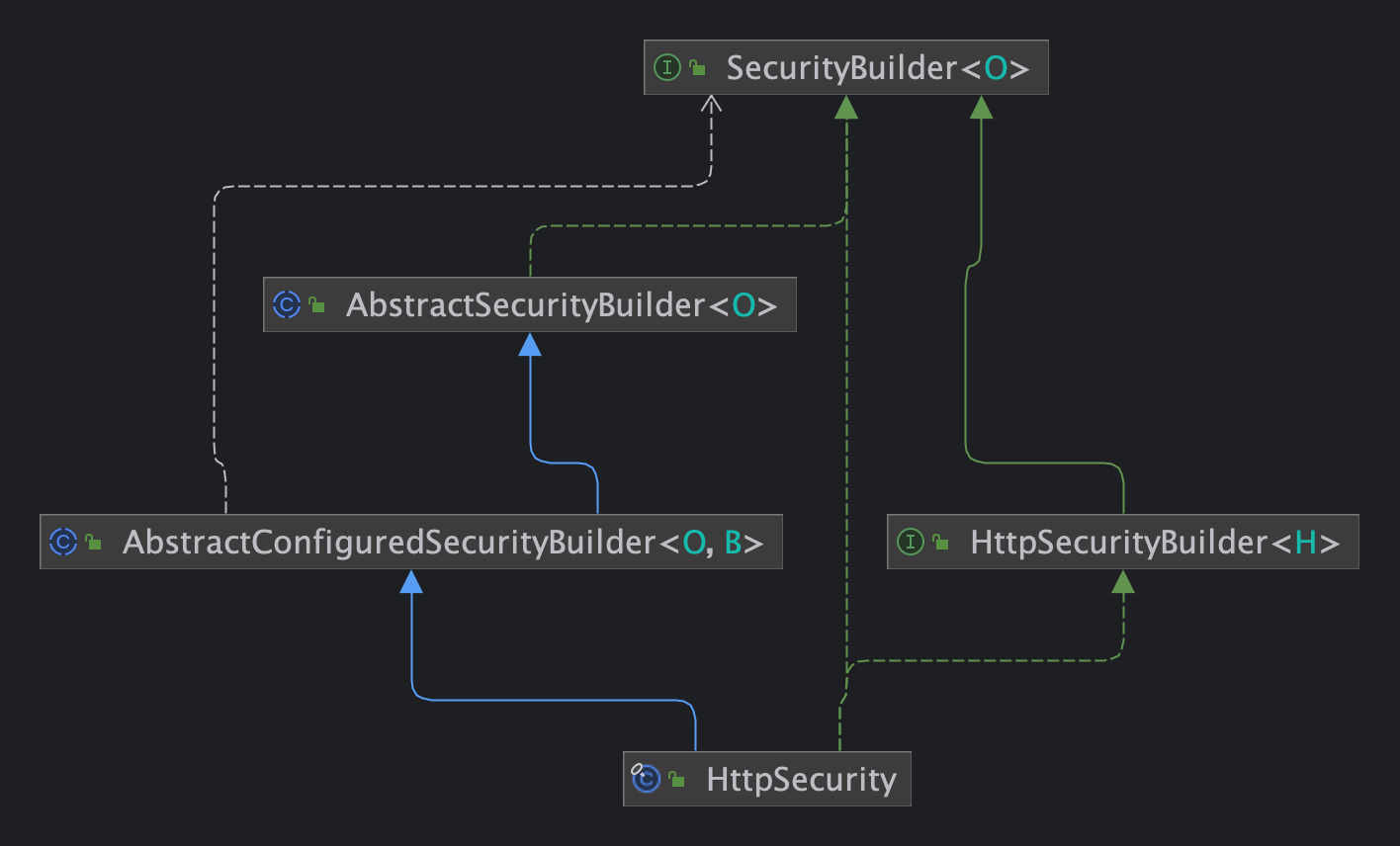
Статья Spring Security 6.x для быстрого понимания принципов настройки
Не забудьте изменить имя каждого модуля RUOYI один раз, чтобы избежать мошенничества ~~~
Научите вас шаг за шагом, как интегрировать систему обслуживания клиентов Hunyuan AI Q&A от 0 до 1.

Подробное объяснение Gzip: принципы и применение алгоритмов сжатия.

Скачать Tomcat - ссылка для скачивания на официальном сайте tomcat7, tomcat8, tomcat9
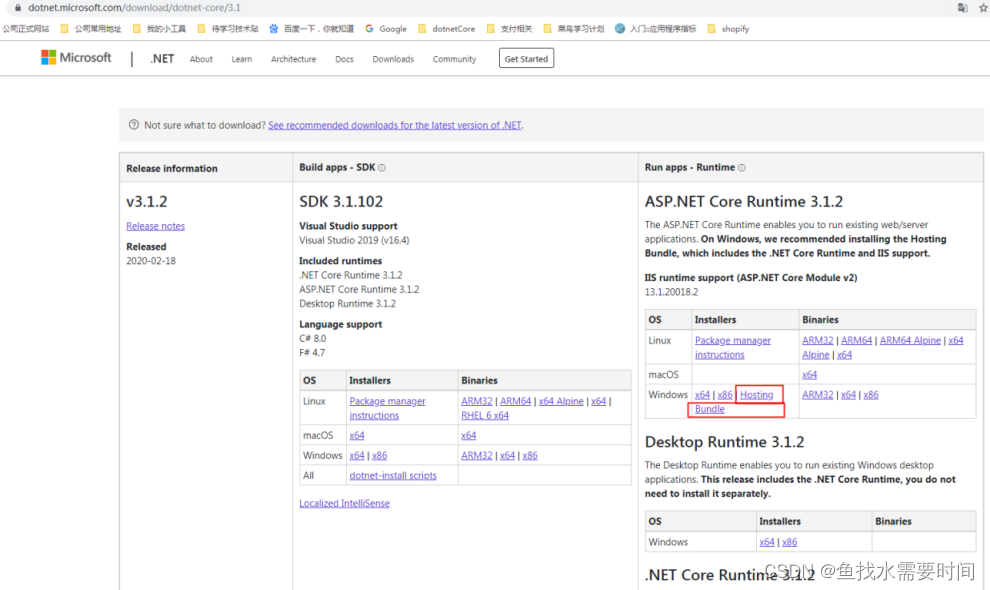
Развертывание IIS.NetCore
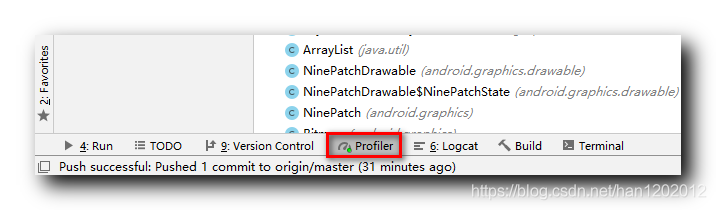
[Оптимизация памяти Android] Общие функции инструмента Android Profiler (мониторинг памяти | снимок памяти)

Встроенная в Springboot пользовательская конфигурация временного каталога, связанного с Tomcat.

Краткое руководство по началу работы с Element-UI
Руководство пользователя ГОРМ
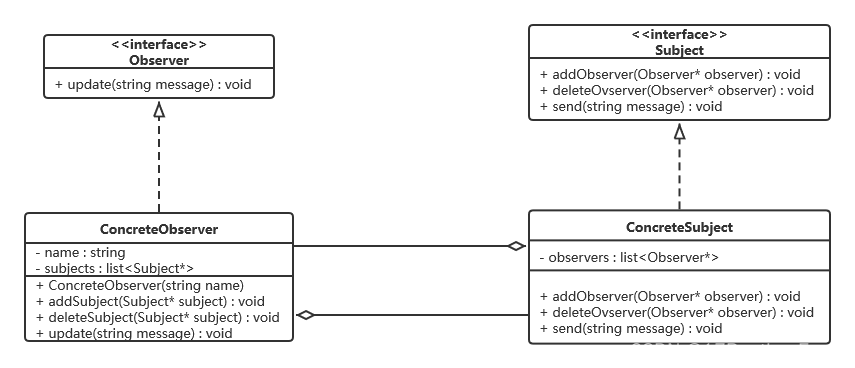
Одна статья для понимания артефакта развязки внутренних компонентов Spring Event (событие Spring)

Java перехватывает строку после определенного символа_java, как перехватить строку

Давайте кратко поговорим о технологии копирования на записи.

Выполнение собственных условий SQL-запроса в MyBatis Plus

Напоминание о выпуске общедоступной учетной записи WeChat (интерфейс сообщения шаблона общедоступной учетной записи WeChat)
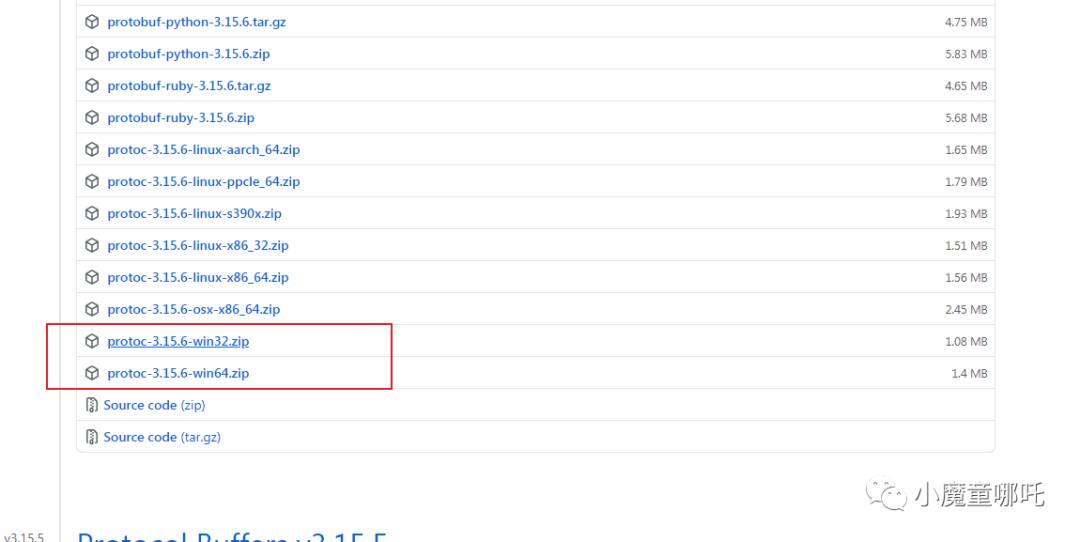
5 шагов для установки среды протокола

Наиболее полные коды состояния HTTP
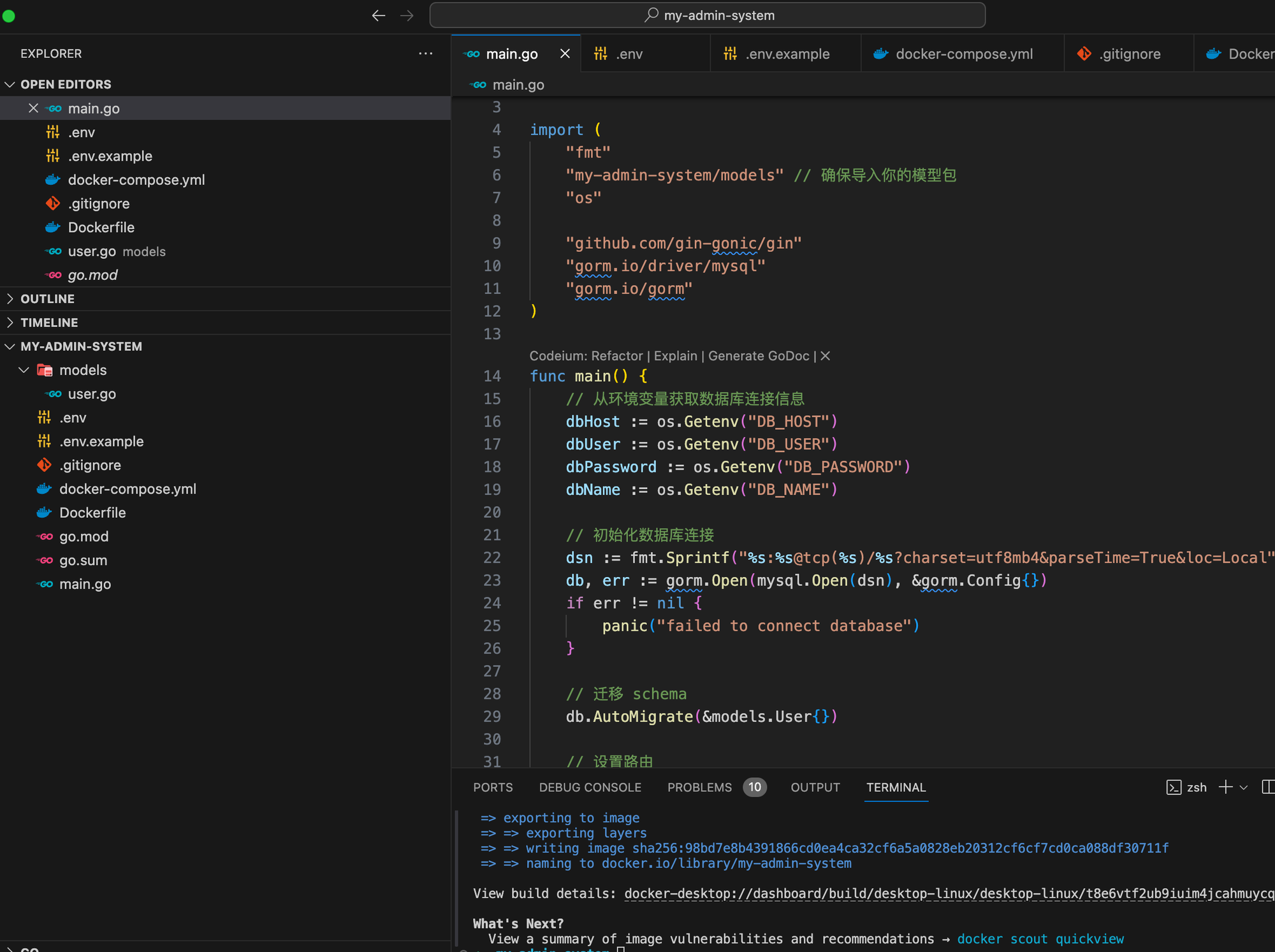
На основе языка Go мы шаг за шагом научим вас внедрять структуру системы управления серверной частью.
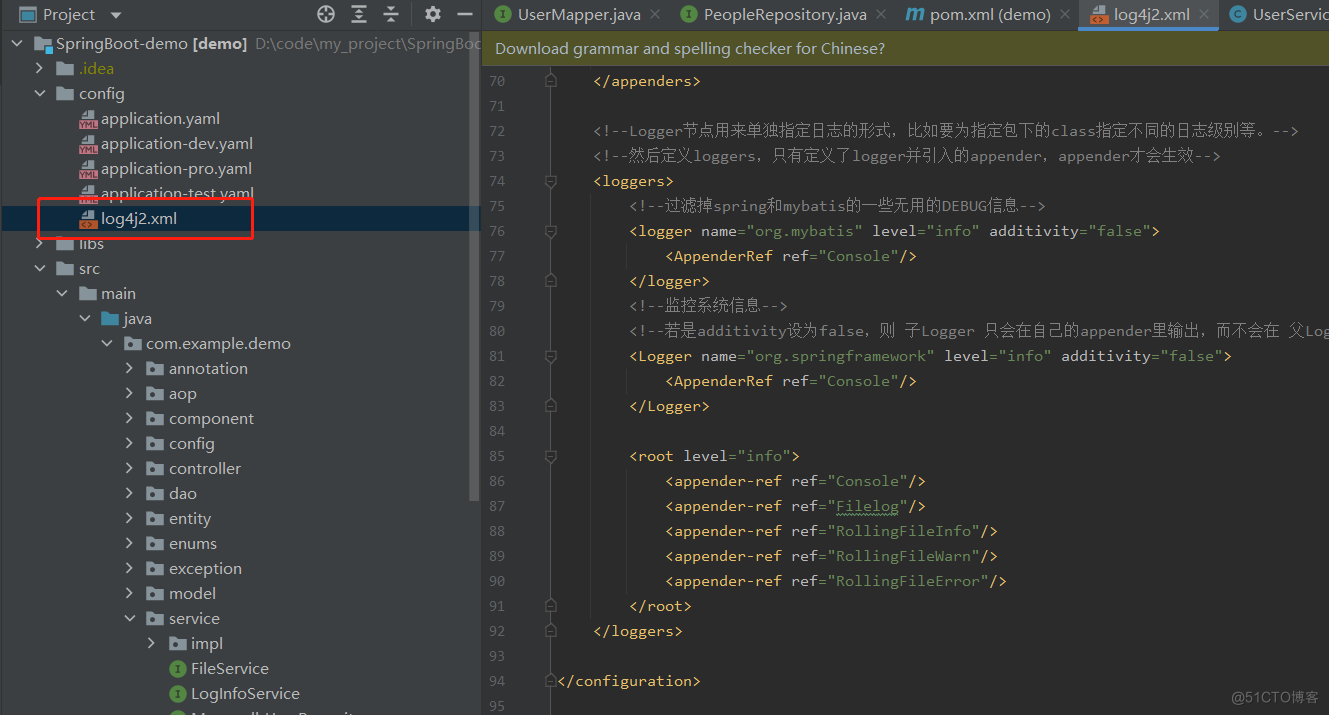
Эффективное управление журналами с помощью Spring Boot и Log4j2: подробное объяснение конфигурации

Что делать, если telnet не является внутренней или внешней командой [легко понять]

php-объект для анализа json_php json
